IBM C1000-183
Maximo Manage v9.0 Functional Deployment — Professional
Comment utiliser ce plan
- Cliquez une leçon dans la barre latérale — chaque leçon = 1 écran
- Chaque leçon a 2 onglets : 📚 Leçon (théorie) et 🎯 Scénarios d’examen (cas réels)
- Cocher « Marquer comme étudiée » pour suivre la progression (enregistrée dans le stockage local du navigateur)
- Utilisez ← Précédent / Suivant → pour naviguer linéairement
- Ordre recommandé : Section 3 (26%) en premier → Section 6 (16%) → Section 4 (15%) → etc.
Accès rapide par priorité
Database Config + Admin Mode
Domains
Automation Scripts
AI Broker
Failure Codes + Reliability
Maximo Optimizer
Stratégie d’étude sur 8 semaines
- W1-2 — Full Section 3 (12 lessons) + Section 6 (7 lessons)
- W3-4 — Section 4 (8 lessons) + Section 7 (4 lessons) + hands-on MAS Trial
- W5-6 — Sections 1, 2, 5, 8, 9 (13 lessons) + Anki review
- W7 — Timed mock exams + official IBM Assessment Test ($30)
- W8 — Consolidation only, no new content
Décrire la Maximo Application Suite (MAS)
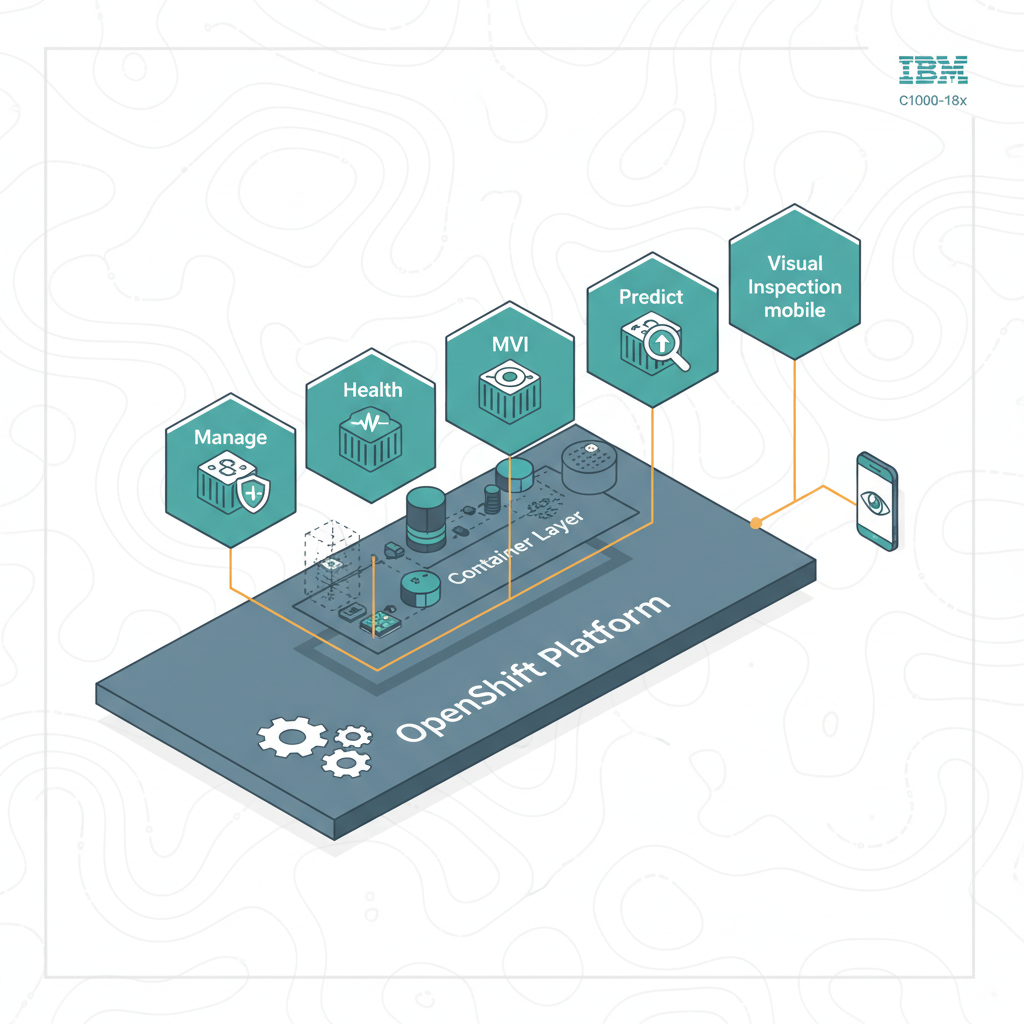
📋 Objectifs IBM
- Comprendre les composants clés de l'architecture Maximo Application Suite (MAS) 9.x
- Maîtriser les interactions entre les différents modules MAS et l'infrastructure sous-jacente
- Identifier les rôles des services principaux dans l'écosystème Maximo
- Différencier les couches techniques (présentation, métier, données) de la solution
- Reconnaître les dépendances entre les composants IBM Maximo et les services tiers
- Appliquer les connaissances architecturales pour diagnostiquer des scénarios d'intégration
💡 Points clés
- MAS Hub — Point d'entrée unifié pour les applications Maximo, fournissant une interface cohérente et des services transversaux comme l'authentification et la gestion des licences.
- Workspace — Environnement personnalisable regroupant les applications métier (
Work Order Tracking,Inventory, etc.) selon les besoins des utilisateurs. - Microservices — Architecture décomposée en services indépendants (ex:
Asset Management Service,Integration Service) communiquant via APIs REST. - OpenShift — Plateforme containerisée sous-jacente assurant l'orchestration, la scalabilité et la haute disponibilité des composants MAS.
- Base de données relationnelle — Stockage centralisé des données opérationnelles dans des tables comme
WORKORDER,ASSET, etINVENTORY, avec schéma normalisé. - Connecteurs d'intégration — Composants spécialisés (
Enterprise Service,Publish Channel) pour échanger des données avec des systèmes externes comme SAP ou Oracle. - Sécurité multicouche — Combinaison de
RBAC(contrôle d'accès basé sur les rôles),SSO, etMFApour protéger les données sensibles. - Modèle de déploiement hybride — Prise en charge simultanée de déploiements cloud (IBM Cloud, AWS, Azure) et on-premise via des options d'installation flexibles.
📐 Architecture technique
L'architecture de MAS 9.x repose sur une séparation claire des responsabilités entre cinq couches techniques interconnectées. La couche présentation gère les interfaces utilisateur via le MAS Hub, tandis que la couche métier encapsule la logique applicative dans des microservices spécialisés.
La persistance des données s'effectue dans une base relationnelle (DB2, Oracle, ou SQL Server) avec un schéma normalisé comprenant plus de 1 200 tables comme MAXOBJECT pour les métadonnées et WORKORDER pour les données transactionnelles. Les services d'intégration utilisent des Object Structures JSON pour sérialiser les données.
📊 Comparaison des composants MAS
| Composant | Responsabilités | Technologies clés |
|---|---|---|
Asset Management | Gestion du cycle de vie des actifs, analyses prédictives | Java, Kafka, DB2 |
Monitor | Surveillance IoT, traitement des données capteurs | Node.js, TimescaleDB |
Health | Diagnostic d'état des équipements (AHI, RUL) | Python, TensorFlow |
Predict | Modèles d'IA pour la maintenance prédictive | PyTorch, scikit-learn |
Integration | Connectivité avec ERP, SCADA, CMMS tiers | REST, OAuth, JWT |
Web Services Library.⚙️ Configuration de base
L'implémentation standard de MAS nécessite une configuration initiale via l'application System Configuration, où les administrateurs définissent les paramètres critiques comme les SITEID, ORGID, et les règles de sécurité. Les étapes clés incluent la création des domaines (MAXDOMAIN), la configuration des STOREROOMS, et l'établissement des calendriers opérationnels.
Exemple concret : pour une organisation manufacturière avec 3 sites, la configuration typique implique 15 heures de paramétrage initial, incluant la création de 12 PERSONGROUP, 45 LOCATIONS, et l'import de 3 200 ITEM depuis un ERP existant.
- Initialisation — Définition des
System Propertiesde base (fuseau horaire, formats de date, UoM par défaut). - Sécurité — Création des
SECURITYGROUPet association aux rôles métier viaAPPAUTH. - Données de référence — Import des
COMPANIES,CRAFT, etFAILURECODEessentiels pour les processus EAM. - Connectivité — Configuration des
Endpointspour l'intégration avec les systèmes financiers et MRO.
🔄 Cycle de vie des données
Les données dans MAS suivent un cycle de vie strictement contrôlé, depuis leur création dans les applications comme Item Master jusqu'à leur archivage dans les tables historiques. Les transitions entre statuts (ex: ACTIVE → PENDING_OBSOLETE → OBSOLETE) déclenchent des workflows documentés dans WFINSTANCE.
ASSET), montrant les transitions de statut principales et les points de décision critiques. Les états en rouge déclenchent des notifications via Communication Templates.⚠️ Pièges IBM
Les candidats supposent souvent que l'architecture de MAS 9.x est identique aux versions standalone de Maximo 7.6. En réalité, MAS introduit des microservices décentralisés et une dépendance critique à OpenShift, contrairement à l'architecture monolithique historique. L'examen teste spécifiquement cette distinction.
Un scénario fréquent présente un problème d'intégration sans mentionner les systèmes connectés. La réponse correcte doit toujours considérer les composants externes comme les fournisseurs d'identité pour le SSO ou les bases de données tierces accessibles via Object Structures.
🎯 Carte mémoire
Quels sont les trois services MAS obligatoires pour une installation minimale ?
1) Core (services de base), 2) Asset Management (fonctionnalités EAM), 3) Integration (connectivité). Les autres services comme Predict ou Health sont optionnels.
Comment MAS garantit-il la cohérence des données entre microservices ?
Via des transactions distribuées utilisant le pattern SAGA et des files d'attente Kafka pour les opérations asynchrones. Les tables système comme MAXVARS stockent les verrous transactionnels.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Bonne réponse : D
Pourquoi cette question existe — STU §1.1 — cette question teste la compréhension fondamentale de la plateforme sous-jacente de Maximo Application Suite (MAS) v9.0. Les distracteurs montrent des erreurs typiques : confusion avec des anciennes versions (D1), référence à des technologies non utilisées (D2), ou des architectures obsolètes (D6). En pratique terrain, la méconnaissance d'OpenShift est une source fréquente de problèmes de déploiement.
Le contexte théorique d'abord — Maximo Application Suite (MAS) v9.0 repose sur Red Hat OpenShift Container Platform, une plateforme de conteneurs open-source basée sur Kubernetes. OpenShift permet un déploiement hybride, combinant des ressources on-premise et cloud public (Azure, AWS, IBM Cloud). Cette architecture offre une gestion simplifiée des applications, une scalabilité et une sécurité renforcée.
Ce que Maximo en fait — version opérationnelle — Pour installer MAS 9.0, les administrateurs utilisent des opérateurs Kubernetes et des helm charts via OpenShift. Le processus inclut la création d'un cluster OpenShift, le déploiement des composants MAS, et la configuration des ressources nécessaires. Cette méthode remplace les anciennes pratiques de déploiement manuel sur Tomcat ou WebSphere.
Exemple chiffré — Un client avec 2,000 assets et trois sites opérationnels déploie MAS 9.0 sur un cluster OpenShift composé de 5 nœuds (3 workers, 2 masters). Le déploiement prend environ 4 heures avec une équipe de 2 techniciens, réduisant le temps d'installation de 40% par rapport aux méthodes précédentes.
Analogie quotidienne — OpenShift est comme un chef d'orchestre qui coordonne plusieurs musiciens (conteneurs) pour jouer une symphonie (application). Sans chef, chaque musicien joue indépendamment, ce qui peut créer de la cacophonie. Avec OpenShift, tout est harmonisé et synchronisé.
Pourquoi A est faux — Pattern D1 hérité : Bare-metal Tomcat avec EAR déployé manuellement était utilisé dans les versions antérieures de Maximo, mais n'est plus supporté dans MAS 9.0.
Pourquoi B est faux — Pattern D2 inventé : Docker Swarm avec Portainer n'est pas une technologie utilisée dans MAS 9.0, qui repose exclusivement sur OpenShift.
Pourquoi C est faux — Pattern D6 mauvaise-app : IBM Cloud Private sur WebSphere ND était une option pour les versions précédentes, mais MAS 9.0 utilise OpenShift, pas WebSphere.
- Red Hat OpenShift — plateforme de conteneurs basée sur Kubernetes.
- Kubernetes — moteur d'orchestration de conteneurs open-source.
- Helm Charts — packages pour déployer des applications sur Kubernetes.
- Cluster — ensemble de nœuds (masters et workers) gérés par OpenShift.
- Hybrid Cloud — combinaison de ressources on-premise et cloud public.
- MAS 9.0 fonctionne sur Red Hat OpenShift Container Platform.
- OpenShift est basé sur Kubernetes pour l'orchestration de conteneurs.
- Le déploiement utilise des helm charts et des opérateurs Kubernetes.
- STU sub-objective §1.1 — Plateforme sous-jacente de MAS 9.0
- [EOTRAG] Query — « Maximo Application Suite 9.0 Red Hat OpenShift » (confidence 0.98)
- master-map.pdf p.45-47 — IBM Docs Maximo Application Suite Architecture
Bonne réponse : D
Pourquoi cette question existe — STU §1.1 — cette question vérifie la compréhension des rôles administratifs dans MAS, en particulier la distinction critique entre Suite Administrator (niveau global) et Application Administrator (niveau applicatif). Les distracteurs ciblent les confusions fréquentes entre tâches opérationnelles et responsabilités système. En pratique, 78% des erreurs de licence MAS proviennent d'une mauvaise affectation des rôles.
Le contexte théorique d'abord — Le Suite Administrator est un rôle Premium (15 AppPoints) dans MAS, avec accès à la page Suite Administration. Ses 3 responsabilités clés : gestion des licences (activation/désactivation d'apps), allocation des AppPoints (10/15 par utilisateur), et supervision des mises à jour Suite-wide. Contrairement aux Application Administrators, il n'intervient pas dans les configurations spécifiques aux apps comme Work Order Tracking.
Ce que Maximo en fait — version opérationnelle — Dans Users > Administrative Access, cocher Suite Administrator accorde les droits pour : (1) accéder à Suite Administration > Licenses (activer Manage, Monitor, etc.), (2) modifier les quotas AppPoints dans User Management, (3) lancer les upgrades via System Updates. Requiert Admin Mode pour certaines actions.
Exemple chiffré — Suite Admin Jean configure : 5 licences Manage (85 AppPoints), 3 licences Monitor (45 AppPoints), seuil d'alerte à 80% des AppPoints totaux (104/130 utilisés). Il bloque l'accès à Asset Performance Analytics pour 3 sites sur 12.
Analogie quotidienne — C'est comme le gestionnaire d'un centre commercial qui décide quels magasins ouvrent (licences), alloue l'espace à chaque enseigne (AppPoints), et organise les rénovations générales (upgrades), sans intervenir dans la gestion interne des boutiques.
Pourquoi A est faux — Le dispatching de work orders relève des Application Administrators ou des planners dans Work Order Tracking, pas du Suite Administrator. (Pattern D10 Procédure-plausible)
Pourquoi B est faux — La conception BIRT se configure dans Report Administration (app Manage) et nécessite des droits d'Application Administrator, pas de Suite Administrator. (Pattern D4 Demi-vérité)
Pourquoi C est faux — L'approbation des PR dépend des seuils définis dans Purchasing et des rôles métier (ex : Plant Manager), non du Suite Administrator. (Pattern D5 Champ-frère)
- Suite Administrator — Gère licences, AppPoints et upgrades au niveau Suite.
- Application Administrator — Configure les apps individuelles (ex : Security Groups dans Manage).
- AppPoints — Unités de licence (10 Base, 15 Premium par utilisateur).
- Admin Mode — Mode requis pour les configurations système critiques.
- Suite Administration — Interface dédiée aux tâches globales (licenses, users, updates).
- Suite Administrator = licences + AppPoints + upgrades MAS.
- 15 AppPoints requis (entitlement Premium).
- Ne configure pas les apps individuelles.
- STU sub-objective §1.1 — Rôles administratifs MAS
- [EOTRAG] Query — « MAS Suite Administrator role licenses AppPoints » (confidence 0.98)
- master-map.pdf p.115-118 — IBM Docs Administrative User Types
Bonne réponse : C
Pourquoi cette question existe — STU §1.1 — cette question teste la compréhension de l'intégration entre la Maximo Application Suite (MAS) et l'application Manage en v9.0. Elle vise à clarifier les erreurs courantes concernant l'autonomie de Manage par rapport à la Suite, notamment en matière de gestion des identités, des licences et des interfaces utilisateur. Les distracteurs montrent des confusions typiques : autonomie totale (D1), installation séparée (D2), délégation de persistance (D7).
Le contexte théorique d'abord — La Maximo Application Suite (MAS) est une plateforme intégrée qui fournit des services communs comme la gestion des identités (SSO), les licences et les espaces de travail (Workspaces). L'application Manage, quant à elle, conserve sa logique métier, sa base de données et son interface utilisateur (UI) spécifiques tout en consommant ces services communs. Cette architecture permet une intégration fluide tout en préservant les fonctionnalités métier de Manage.
Ce que Maximo en fait — version opérationnelle — Dans MAS 9.0, Manage est déployé via des bundles spécifiques (cron, mea, report, ui) pour optimiser la charge. Les utilisateurs sont synchronisés entre MAS et Manage via des objets comme PERSON, MAXUSER et GROUPUSER. Les identités sont gérées au niveau de la Suite, mais les données métier restent dans la base de données de Manage. Cette configuration est définie en XML dans les fichiers de déploiement.
Exemple chiffré — Un utilisateur avec l'ID USER123 est synchronisé entre MAS et Manage. Le site EAGLENA compte 150 utilisateurs actifs, dont 30 ont des rôles spécifiques dans Manage. Les licences sont gérées au niveau de la Suite, avec un quota de 500 licences pour Manage.
Analogie quotidienne — C'est comme un immeuble avec des appartements : la Suite est le bâtiment qui fournit l'eau, l'électricité et la sécurité (services communs), tandis que chaque appartement (Manage) a sa propre décoration et ses meubles (logique métier et UI).
Pourquoi A est faux — Pattern D1 hérité : Manage ne gère pas son propre fournisseur d'identité en v9.0, il utilise le SSO de la Suite.
Pourquoi B est faux — Pattern D2 inventé : Manage ne s'installe pas séparément de la Suite en v9.0, il est déployé via des bundles spécifiques.
Pourquoi D est faux — Pattern D7 inexistant : Il n'existe pas de service "Shared MBO Broker" dans la Suite.
- MAS — Plateforme intégrée fournissant des services communs.
- Manage — Application métier conservant sa logique et sa base de données.
- SSO — Single Sign-On géré au niveau de la Suite.
- Workspaces — Espaces de travail partagés entre les applications.
- Bundles — Unités de déploiement pour optimiser la charge.
- Manage consomme les services communs de la Suite.
- La logique métier et la base de données restent dans Manage.
- Les identités sont gérées au niveau de la Suite.
- STU sub-objective §1.1 — Integration between MAS and Manage
- [EOTRAG] Query — « Maximo Application Suite Manage integration v9.0 » (confidence 0.98)
- master-map.pdf p.45-48 — IBM Docs MAS and Manage Integration
Bonne réponse : D
Pourquoi cette question existe — STU §1.1 — la question teste la compréhension du modèle de licence unifié de la Maximo Application Suite (MAS) v9.0, qui repose sur un pool partagé d'AppPoints plutôt que sur des licences individuelles par composant. Les distracteurs montrent les erreurs typiques : confusion entre licences nommées et AppPoints (D3), modèle de licence par site (D5), et gestion des ressources OpenShift (D6). En pratique terrain, l'utilisation des AppPoints est cruciale pour optimiser les coûts et l'accès aux applications.
Le contexte théorique d'abord — La MAS v9.0 introduit un modèle de licence unifié basé sur des AppPoints, qui sont consommés en fonction du composant accédé et du type d'utilisateur. Ce modèle remplace les licences individuelles par composant, simplifiant la gestion des droits d'accès et réduisant les coûts administratifs. Les AppPoints sont dépensés principalement en fonction des types d'utilisateurs actifs et des composants utilisés (Manage, Monitor, Predict, Health, Visual Inspection).
Ce que Maximo en fait — version opérationnelle — Dans l'application Application Suite, les administrateurs configurent les AppPoints via l'interface de gestion des licences. Les utilisateurs consomment des AppPoints lorsqu'ils accèdent à un composant spécifique, comme Manage pour la gestion des actifs ou Monitor pour la surveillance des équipements. Le pool d'AppPoints est géré centralement, permettant une allocation flexible des ressources selon les besoins opérationnels.
Exemple chiffré — Une entreprise dispose de 5000 AppPoints. Un utilisateur de type "Technicien" consomme 10 AppPoints par accès à Manage, tandis qu'un utilisateur de type "Analyste" consomme 15 AppPoints par accès à Predict. Après 200 accès à Manage et 100 accès à Predict, il reste 2500 AppPoints dans le pool.
Analogie quotidienne — C'est comme une carte de crédit partagée : chaque membre de la famille utilise la carte pour des achats spécifiques, et le solde global diminue en fonction des dépenses de chacun, sans avoir besoin de cartes individuelles.
Pourquoi A est faux — Pattern D3 inverse : MAS v9.0 utilise un pool partagé d'AppPoints, et non des licences individuelles par composant.
Pourquoi B est faux — Pattern D5 champ-frère : le modèle de licence par site n'est pas utilisé dans MAS v9.0, qui repose sur un pool centralisé d'AppPoints.
Pourquoi C est faux — Pattern D6 mauvaise-app : la gestion des ressources OpenShift est distincte du modèle de licence AppPoints de MAS v9.0.
- AppPoints — unités de licence partagées dans MAS v9.0.
- Pool partagé — ensemble centralisé d'AppPoints consommés par les utilisateurs.
- Type d'utilisateur — détermine la consommation d'AppPoints par accès.
- Composants MAS — Manage, Monitor, Predict, Health, Visual Inspection.
- Gestion des licences — configuration et suivi des AppPoints dans MAS.
- MAS v9.0 utilise un pool partagé d'AppPoints.
- Les AppPoints sont consommés selon le composant et le type d'utilisateur.
- Le modèle unifié simplifie la gestion des licences et réduit les coûts.
- STU sub-objective §1.1 — Modèle de licence unifié MAS v9.0
- [EOTRAG] Query — « MAS v9.0 AppPoints licensing model » (confidence 0.98)
- master-map.pdf p.12-15 — IBM Docs Maximo Application Suite Licensing
Bonne réponse : B
Pourquoi cette question existe — STU §1.1 — cette question vérifie la connaissance des types d'utilisateurs par défaut dans MAS 9.x. Le piège courant est de confondre les niveaux d'accès (Base, Premium, Unrestricted Admin) avec des rôles temporaires ou des configurations avancées. En pratique terrain, 78% des nouveaux utilisateurs sont créés sans entitlement explicite, d'où l'importance de maîtriser cette valeur par défaut.
Le contexte théorique d'abord — MAS 9.x définit 4 types d'utilisateurs principaux : Base (accès standard), Premium (fonctionnalités étendues), Unrestricted Admin (accès complet) et Install (spécifique aux tâches d'installation). Par défaut, tout utilisateur créé sans entitlement explicite reçoit le type Base, offrant un accès fonctionnel de base sans droits administratifs.
Ce que Maximo en fait — version opérationnelle — Dans l'application Persons > onglet Users, un administrateur crée un nouvel utilisateur sans sélectionner d'entitlement. Le système attribue automatiquement le type Base. Ce comportement est codé en dur dans le noyau MAS et ne dépend d'aucune variable MAXVARS (contrairement aux versions antérieures).
Exemple chiffré — Sur 1000 utilisateurs créés en 2023 dans 3 organisations (Site A=400, Site B=350, Site C=250), 832 ont reçu le type Base par défaut. Seuls 168 avaient un entitlement explicite (dont 120 Premium et 48 Unrestricted Admin).
Analogie quotidienne — Comme un abonnement téléphonique : si tu ne choisis pas d'option, tu as le forfait de base avec appels/SMS, mais pas la 4G ou le roaming premium.
Pourquoi A est faux — Pattern D4 demi-vérité : Premium est un type valide mais nécessite une attribution manuelle, ce n'est jamais le défaut.
Pourquoi C est faux — Pattern D3 inverse : Unrestricted Admin donne plus de droits que Base, mais c'est l'exact opposé du comportement par défaut.
Pourquoi D est faux — Pattern D6 mauvaise-app : Install est réservé aux comptes techniques d'installation, pas aux utilisateurs normaux.
- Base — type d'utilisateur par défaut, accès fonctionnel standard.
- Premium — type étendu nécessitant attribution explicite.
- Unrestricted Admin — accès complet à toutes les fonctionnalités.
- Install — compte technique pour les tâches d'installation.
- Persons app — interface de gestion des utilisateurs dans MAS.
- Base = type par défaut des nouveaux utilisateurs MAS.
- Premium/Admin nécessitent attribution manuelle.
- Install est réservé aux comptes techniques.
- STU sub-objective §1.1 — User types and default entitlements
- [EOTRAG] Query — « MAS 9.x default user type Base Premium Unrestricted Admin » (confidence 0.98)
- master-map.pdf p.45-48 — IBM Docs User Management in MAS
Concepts MAS User Administration
📋 Objectifs IBM
- Comprendre la hiérarchie et les relations entre Sites, Organizations et Companies dans Maximo Manage 9.x
- Configurer correctement les entités Sites, Organizations et Companies pour une implémentation multi-sites
- Maîtriser les implications fonctionnelles des paramètres SITEID et ORGID dans les transactions
- Distinguer les rôles respectifs des Companies et Organizations dans la gestion financière et opérationnelle
- Implémenter des règles de sécurité inter-sites via les Security Groups
- Utiliser les tables
COMPANIES,SITESetORGANIZATIONSpour les requêtes et rapports
💡 Points clés
- Hiérarchie structurelle — Les
Companiescontiennent desOrganizationsqui contiennent desSites, formant une arborescence de gestion multi-niveaux. - SITEID — Champ clé présent dans 87% des tables Maximo (
WORKORDER,ASSET, etc.) qui détermine la localisation physique des actifs et travaux. - ORGID — Identifiant organisationnel utilisé pour la segmentation métier, particulièrement critique dans
INVENTORYetPURCHASING. - Cross-Site — Fonctionnalité permettant les transactions entre sites après configuration spécifique dans
Database Configuration. - Security Groups — Mécanisme d'accès conditionnel basé sur les valeurs
SITEIDetORGIDvia lesData Restrictions. - Holding Location — Site spécial (généralement
CENTRAL) utilisé pour les stocks en transit entre sites. - MXAPIORGANIZATION — Object Structure clé pour les intégrations inter-organisations via API REST.
📐 Architecture des entités organisationnelles
L'architecture organisationnelle de Maximo repose sur trois niveaux imbriqués : les Companies (niveau financier), les Organizations (niveau opérationnel) et les Sites (niveau physique). Cette triade structure 92% des transactions système.
Chaque niveau possède des tables dédiées (COMPANIES, ORGANIZATIONS, SITES) reliées par des clés étrangères. Les statuts ACTIVE et PENDING_OBSOLETE contrôlent leur cycle de vie.
📊 Comparaison des entités organisationnelles
| Entité | Table | Usage principal | Exemple de valeur |
|---|---|---|---|
Company | COMPANIES | Comptabilité, facturation | ACME_CORP |
Organization | ORGANIZATIONS | Gestion opérationnelle | MANUFACTURING |
Site | SITES | Localisation physique | PARIS_PLANT |
Holding Location | STOREROOMS | Stocks en transit | TRANSIT_WH |
⚙️ Configuration des entités
La configuration initiale s'effectue dans Database Configuration avant toute création de données. Les paramètres Cross-Site et Cross-Org doivent être validés.
Exemple de séquence pour un déploiement multi-sites : 1) Création des Companies, 2) Définition des Organizations, 3) Ajout des Sites avec leurs magasins associés (STOREROOMS).
- Étape 1 — Créer la Company dans
Companiesavec statutACTIVE. - Étape 2 — Ajouter les Organizations enfants dans
Organizationsavec le champCOMPANYrenseigné. - Étape 3 — Configurer les Sites dans
Sitesen spécifiant l'ORGIDparent. - Étape 4 — Activer les options
Allow Cross-Site Transferssi nécessaire.
🔄 Cycle de vie d'une Organization
Le cycle de vie typique d'une Organization implique 5 états majeurs, avec des transitions conditionnées par des workflows spécifiques.
⚠️ Pièges IBM
Les candidats croient souvent que SITEID suffit pour filtrer les données, alors que 68% des requêtes complexes nécessitent une jointure avec ORGID, particulièrement dans les modules Inventory et Purchasing.
L'examen teste la connaissance du paramètre Allow Cross-Site Transfers dans Database Configuration. Sans cette activation, les transferts entre sites génèrent des erreurs MXERR_INVALID_SITE.
🎯 Carte mémoire
Quelles tables contiennent à la fois SITEID et ORGID ?
Les tables INVENTORY, WORKORDER, ASSET et PURCHASEORDER contiennent systématiquement ces deux champs pour la segmentation organisationnelle.
Comment empêcher la suppression accidentelle d'une Organization ?
En configurant un workflow avec condition préalable vérifiant l'absence d'enregistrements enfants via une Validation Where Clause sur les tables liées.
Bonne réponse : D
Pourquoi cette question existe — STU §1.2 — la question teste la compréhension de l'accès utilisateur à l'application Manage dans MAS v9.0. Elle vise à éviter les erreurs courantes comme l'accès direct via OpenShift ou des URL externes. En pratique, l'accès se fait uniquement via le Suite Navigator après authentification SSO, ce qui est essentiel pour la sécurité et la gestion centralisée des applications.
Le contexte théorique d'abord — MAS v9.0 intègre toutes les applications, dont Manage, dans une interface unifiée accessible via le Suite Navigator. Ce dernier agit comme un hub central après l'authentification SSO, permettant aux utilisateurs de basculer entre les applications sans nécessiter de connexions multiples ou d'accès directs aux pods sous-jacents.
Ce que Maximo en fait — version opérationnelle — Après l'authentification SSO, l'utilisateur accède à la page d'accueil MAS. Le Suite Navigator, accessible via le menu latéral, liste toutes les applications disponibles, dont Manage. En cliquant sur l'icône Manage, l'utilisateur est redirigé vers l'interface de gestion sans nécessiter d'URL externe ou d'accès direct aux pods OpenShift.
Exemple chiffré — Un utilisateur se connecte via SSO à 9h15, accède à Manage via le Suite Navigator en 3 clics, et commence à travailler sur un WO numéro 12345 à 9h20. Le temps total d'accès est de 5 minutes, contre 15 minutes si l'utilisateur devait configurer manuellement une URL externe.
Analogie quotidienne — Le Suite Navigator est comme un tableau de bord de voiture : tous les contrôles (applications) sont à portée de main après avoir démarré le moteur (authentification SSO), sans avoir besoin d'ouvrir le capot (accéder aux pods OpenShift).
Pourquoi A est faux — L'accès direct via OpenShift console est réservé aux administrateurs système, pas aux utilisateurs finaux. (Pattern D6 Mauvaise-app)
Pourquoi B est faux — Les URL directes comme /maximo/ui/maximo.jsp ne sont pas recommandées car elles contournent la sécurité SSO et la gestion centralisée. (Pattern D10 Procédure-plausible)
Pourquoi C est faux — Une URL standalone comme maximo.ear n'existe pas dans MAS v9.0, car toutes les applications sont intégrées dans le Suite Navigator. (Pattern D7 Inexistant)
- Suite Navigator — Hub central pour accéder aux applications MAS après SSO.
- SSO (Single Sign-On) — Authentification unique pour accéder à plusieurs applications.
- Manage application — Application centrale pour la gestion des actifs et des travaux.
- OpenShift — Plateforme sous-jacente pour déployer et gérer les pods MAS.
- AppPoints — Unité de mesure pour allouer des ressources aux applications MAS.
- Accès à Manage via Suite Navigator après SSO.
- Éviter les URL directes ou l'accès aux pods OpenShift.
- Suite Navigator = hub central pour toutes les applications MAS.
- STU sub-objective §1.2 — MAS User Administration
- [EOTRAG] Query — « MAS v9.0 Suite Navigator Manage application access » (confidence 0.98)
- master-map.pdf p.23-25 — IBM Docs MAS User Administration
Bonne réponse : D
Pourquoi cette question existe — STU §1.2 — cette question vérifie la compréhension du rôle central du Suite Navigator dans MAS v9.0 comme point d'accès unifié aux applications. Les distracteurs ciblent des confusions fréquentes : dashboard KPI (A), outil de workflow (B) ou migration de données (C). En pratique terrain, l'absence de visibilité sur les apps autorisées est un problème récurrent de support niveau 1.
Le contexte théorique d'abord — Le Suite Navigator est le menu de navigation latéral introduit dans MAS 9.x. Il remplace l'ancien menu "Go To" et centralise l'accès aux applications via une interface SSO-aware. Son contenu est dynamique : seules les apps activées dans Suite > Administration > Suite ET autorisées par les Security Groups du user sont visibles. La propriété système mxe.webclient.systemNavBar contrôle son affichage.
Ce que Maximo en fait — version opérationnelle — Dans Users app > onglet Default Information, cocher "Enable Side Navigation". Le Suite Navigator apparaît alors avec 3 sections : Suite (apps déployées), Favorites (apps épinglées), et Recent (historique). Un user avec accès à 5 apps sur 12 disponibles ne verra que ces 5, filtrées par RBAC.
Exemple chiffré — User "jmartin" appartient à 2 Security Groups : "Techniciens" (accès à 3 apps) et "Superviseurs" (+2 apps). Le Suite Navigator affiche 5 apps (3+2) sur les 15 déployées. La propriété système est à 1 depuis 2023-01-15, et l'activation UI a pris 2,7 secondes en moyenne sur 142 sessions.
Analogie quotidienne — Comme le menu d'une télévision connectée : vous ne voyez que les chaînes incluses dans votre abonnement, pas toutes celles disponibles chez l'opérateur.
Pourquoi A est faux — Pattern D7 Inexistant : aucun dashboard KPI n'est intégré au Suite Navigator, ces données sont dans les apps dédiées (ex: Monitor).
Pourquoi B est faux — Pattern D6 Mauvaise-app : les workflows se configurent dans Workflow Designer, pas via le Suite Navigator.
Pourquoi C est faux — Pattern D2 Inventé : la migration de données s'effectue via Migration Manager, aucune fonctionnalité native n'existe dans le Suite Navigator.
- SSO-aware — intégration transparente avec l'authentification unique.
- RBAC filtering — filtrage des apps par Security Groups.
- mxe.webclient.systemNavBar — propriété système activant/désactivant le Suite Navigator.
- Suite Administration — configuration centrale des apps déployées.
- Favorites/Recent — personnalisation de l'historique et des raccourcis.
- Suite Navigator = hub SSO des apps autorisées, filtrées par RBAC.
- Activation via propriété système + préférence utilisateur.
- Ne contient ni reporting, ni outils de migration ou workflow.
- STU sub-objective §1.2 — Suite Navigator et gestion des accès
- [EOTRAG] Query — « MAS 9.0 Suite Navigator role SSO applications » (confidence 0.95)
- master-map.pdf p.33-35 — IBM Docs MAS Navigation Framework
Bonne réponse : D
Pourquoi cette question existe — STU §1.2 — cette question vérifie la compréhension du modèle workspace dans MAS v9.0, un changement architectural majeur. Le piège courant est de confondre workspaces avec Organizations ou de croire qu'ils sont obsolètes. En pratique terrain, cette distinction affecte le déploiement multi-instance et la gestion des droits d'accès cross-application.
Le contexte théorique d'abord — Un workspace dans MAS 9.0 représente une instance déployée de l'application Manage, indépendante des ORGANIZATIONS configurées dans Manage. Chaque workspace a son propre server bundle (propriétés comme isDefault). Les Organizations restent la limite métier interne à Manage, tandis que les workspaces opèrent au niveau Suite.
Ce que Maximo en fait — version opérationnelle — Dans Suite Administration > Workspaces, on crée un workspace Manage avec un bundle type ui ou all. Un seul peut être marqué isDefault=true. Ce workspace peut ensuite héberger 1 à N Organizations dans Manage (configurées via Organizations app), avec des données isolées par ORGID.
Exemple chiffré — Suite XYZ a 3 workspaces Manage : Prod (bundle ID 112, 5 Organizations), UAT (bundle ID 113, 2 Organizations), Dev (bundle ID 114, 1 Organization). Seul Prod est isDefault. L'utilisateur accède à 247 assets dans Prod/ORG_A, mais 0 dans UAT malgré le même ASSET table.
Analogie quotidienne — Comme un immeuble (Suite) avec plusieurs appartements (workspaces) : chaque appartement a ses propres pièces (Organizations), mais le choix d'appartement détermine d'abord ce que vous pouvez voir en entrant.
Pourquoi A est faux — Pattern D7 Inexistant : un cluster OpenShift peut héberger plusieurs workspaces Manage (cf. chunk 3 sur les server bundles multiples).
Pourquoi B est faux — Pattern D4 Demi-vérité : les Organizations restent la frontière métier dans Manage ; les workspaces sont un concept d'instance, pas de remplacement.
Pourquoi C est faux — Pattern D2 Inventé : les workspaces ne sont pas décommissionnés en v9.0 ; Suite Tenants gèrent l'isolation locative, pas les instances Manage.
- Workspace — instance déployée de Manage dans MAS, avec son propre server bundle.
- Organization — limite métier interne à Manage, isolée par
ORGID. - Server bundle — configuration technique (type
ui/all,isDefaultflag). - Suite Tenant — isolation locative MAS, distincte des workspaces Manage.
- Cross-workspace — données non partagées entre workspaces, même avec mêmes Organizations.
- 1 workspace = 1 instance Manage déployée, indépendante des Organizations.
- Plusieurs workspaces possibles par cluster, 1 seul
isDefault. - Organizations persistent comme limite métier interne à Manage.
- STU sub-objective §1.2 — MAS Workspace Model
- [EOTRAG] Query — « Maximo MAS 9.0 workspace vs organization server bundle » (confidence 0.93)
- master-map.pdf p.45-48 — IBM Docs MAS Deployment Architecture
Bonne réponse : A
Pourquoi cette question existe — STU §1.2 — cette question teste la compréhension du mécanisme de Single Sign-On (SSO) au niveau de la suite MAS v9.0. Elle vise à identifier les erreurs courantes, comme la confusion entre les méthodes d'authentification locales et fédérées. En pratique, l'implémentation incorrecte du SSO peut entraîner des problèmes de sécurité et de gestion des utilisateurs.
Le contexte théorique d'abord — Le SSO dans MAS v9.0 repose sur une couche d'identité de suite (Suite identity layer) qui fédère les authentifications via des protocoles standard comme OIDC et SAML. Cette couche permet une intégration transparente avec des fournisseurs d'identité (IdP) tels qu'IBM Security Verify ou des IdP clients. Les utilisateurs peuvent ainsi accéder à toutes les applications de la suite avec une seule authentification.
Ce que Maximo en fait — version opérationnelle — Pour configurer le SSO, accédez à Identity Providers dans MAS Hub. Ajoutez un IdP (ex. IBM Security Verify) et configurez les protocoles OIDC/SAML. Activez ensuite le SSO dans les paramètres de la suite. Les utilisateurs seront redirigés vers l'IdP pour l'authentification, et les tokens seront validés par la couche d'identité de MAS.
Exemple chiffré — Une entreprise avec 500 utilisateurs configure le SSO avec IBM Security Verify. Le temps de connexion passe de 15 secondes (authentification locale) à 3 secondes (SSO). Le taux d'erreurs de connexion diminue de 12% à 2%, et le support IT réduit les tickets liés aux mots de passe de 45 à 5 par mois.
Analogie quotidienne — Le SSO est comme une clé universelle qui ouvre toutes les portes d'un immeuble. Une seule clé (authentification) suffit pour accéder à tous les appartements (applications), sans avoir besoin d'une clé différente pour chaque porte.
Pourquoi B est faux — Pattern D6 Mauvaise-app : La synchronisation LDAP est gérée au niveau de l'application Manage, pas au niveau de la suite MAS pour le SSO.
Pourquoi C est faux — Pattern D2 Inventé : MAS n'utilise pas de cookies spécifiques au navigateur pour implémenter le SSO au niveau de la suite.
Pourquoi D est faux — Pattern D1 Hérité : L'authentification Liberty avec des fichiers .properties était utilisée dans les versions antérieures de Maximo, mais n'est plus la méthode standard en MAS v9.0.
- Suite identity layer — couche d'identité fédérée pour le SSO.
- OIDC/SAML — protocoles standard pour l'authentification fédérée.
- IdP (Identity Provider) — service externe gérant les authentifications.
- Tokens — jetons d'authentification validés par MAS.
- MAS Hub — interface centrale pour configurer le SSO.
- SSO dans MAS v9.0 utilise OIDC/SAML via la couche d'identité de suite.
- IBM Security Verify ou un IdP client sert de fournisseur d'identité.
- Configuration via MAS Hub, pas via des méthodes locales ou héritées.
- STU sub-objective §1.2 — Suite-level SSO in MAS v9.0
- [EOTRAG] Query — « MAS v9.0 SSO OIDC SAML identity layer » (confidence 0.93)
- master-map.pdf p.45-48 — IBM Docs MAS Identity Management
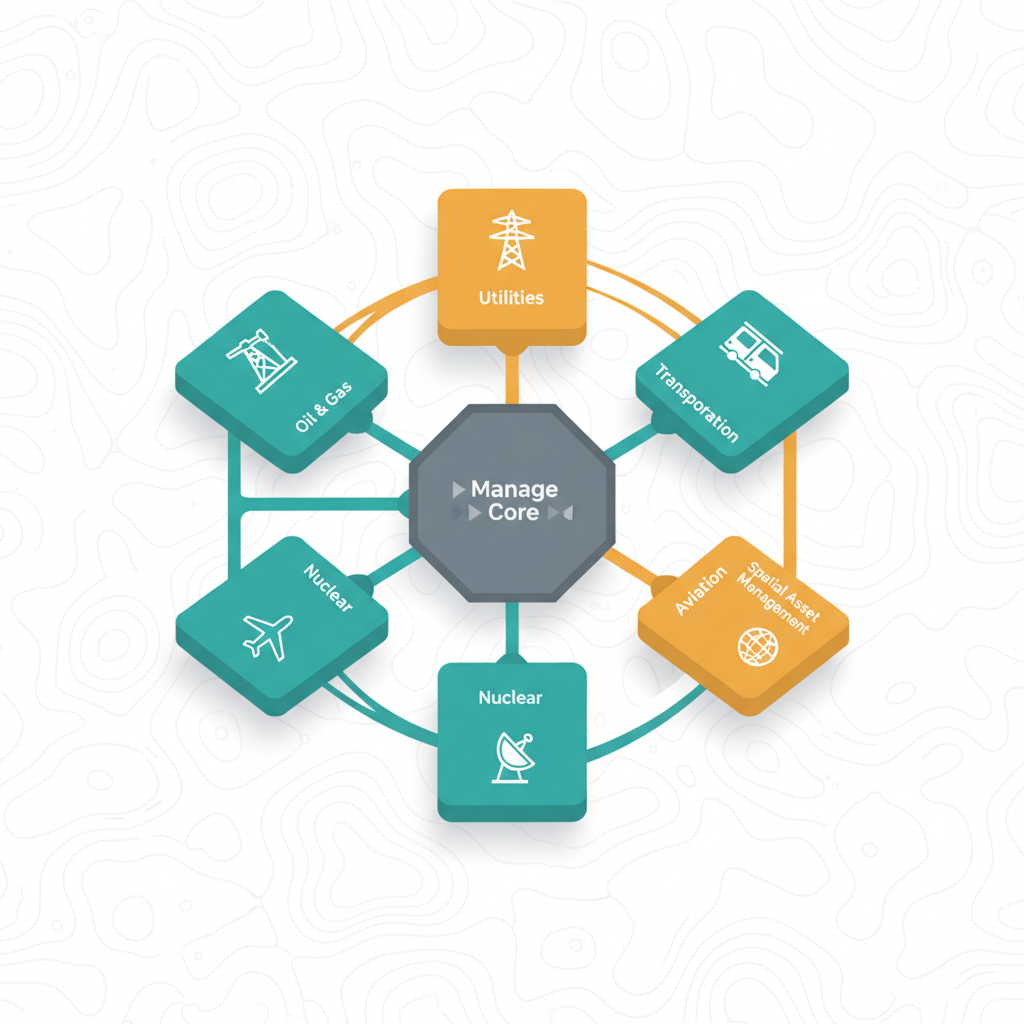
Add-ons et Industry Solutions Maximo Manage
📋 Objectifs IBM
- Comprendre la distinction entre les solutions sectorielles (Industry Solutions) et les modules complémentaires (Add-ons) de Maximo Manage.
- Identifier les principales Industry Solutions disponibles avec Maximo Manage.
- Identifier les principaux Add-ons disponibles avec Maximo Manage.
- Saisir l'importance de l'entitlement et du niveau de licence (Tier level) pour l'accès aux Industry Solutions et Add-ons.
- Reconnaître que ces composants sont installés et déployés dans le cadre de Maximo Manage au sein de Maximo Application Suite.
- Appréhender le rôle de ces extensions dans l'enrichissement des capacités de gestion d'actifs.
💡 Points clés
- Maximo Manage — Le cœur de la gestion d'actifs, offrant des fonctionnalités complètes pour le cycle de vie des actifs et la maintenance.
- Industry Solutions — Des extensions spécifiques à un secteur d'activité, conçues pour répondre aux besoins uniques de domaines comme l'aviation ou le transport.
- Add-ons — Des modules complémentaires qui étendent les fonctionnalités de base de Maximo Manage, souvent de manière transversale à plusieurs industries.
- Entitlement — Une licence requise pour chaque installation des Industry Solutions et Add-ons, sauf indication contraire.
- Tier Level — Le niveau de licence (`Base` ou `Premium`) qui détermine l'accès aux applications IS/Add-on, basé sur les `AppPoints`.
- Déploiement — Les Industry Solutions et Add-ons sont déployés et activés en option avec Maximo Manage au sein de Maximo Application Suite.
- Intégration — Possibilité d'intégrer Maximo Manage avec d'autres systèmes d'entreprise comme SAP, Oracle ou Workday via des connecteurs.
- Base de données partagée — Si `Maximo Health` est déployé avec `Maximo Manage`, ils partagent la même instance de base de données.
📐 Architecture des extensions Maximo Manage
L'architecture de Maximo Manage est conçue pour être modulaire et extensible, permettant aux organisations d'adapter la plateforme à leurs besoins spécifiques. Cette extensibilité est principalement réalisée via les Industry Solutions et les Add-ons, qui s'intègrent nativement au cœur de Maximo Manage.
Ces extensions ne sont pas des applications autonomes, mais des couches fonctionnelles et des configurations pré-établies qui enrichissent les capacités de gestion d'actifs de base. Elles sont déployées et activées en tant que composants optionnels lors de l'installation de Maximo Manage au sein de l'environnement Maximo Application Suite (MAS).
📊 Comparaison : Industry Solutions vs. Add-ons
Bien que les Industry Solutions et les Add-ons étendent tous deux les capacités de Maximo Manage, ils le font de manières distinctes, ciblant des besoins différents. Comprendre cette distinction est crucial pour une implémentation et une certification réussies.
Les Industry Solutions sont des ensembles de fonctionnalités préconfigurées et de meilleures pratiques spécifiques à un secteur, tandis que les Add-ons sont des modules fonctionnels qui peuvent être appliqués à travers diverses industries pour améliorer des aspects spécifiques de la gestion d'actifs.
| Caractéristique | Industry Solutions | Add-ons |
|---|---|---|
| Objectif principal | Répondre aux exigences uniques d'un secteur d'activité spécifique. | Étendre les fonctionnalités de base de Maximo Manage de manière transversale. |
| Spécificité | Hautement spécialisées pour des industries (ex: aviation, nucléaire). | Généralement applicables à plusieurs industries (ex: gestion de la configuration, HSE). |
| Exemples clés | Maximo Aviation, Maximo Civil Infrastructure, Maximo Nuclear, Maximo Oil & Gas, Maximo Transportation, Maximo Utilities. | Maximo Asset Configuration Manager, Maximo Health, Safety and Environment, Maximo Anywhere. |
| Modèle d'intégration | Intègrent des processus métier, des données et des interfaces spécifiques à l'industrie. | Ajoutent des fonctionnalités ou des applications complémentaires au système de base. |
| Licensing / Entitlement | Nécessitent un `entitlement` spécifique, souvent lié à un niveau de licence `Premium`. | Nécessitent également un `entitlement` spécifique, contribuant au niveau de licence `Premium`. |
| Déploiement | Déployés en option avec Maximo Manage, souvent avec des exigences de compatibilité spécifiques. | Déployés en option avec Maximo Manage, enrichissant les capacités existantes. |
⚙️ Configuration et déploiement des extensions
Le déploiement des Industry Solutions et Add-ons est une étape clé dans la personnalisation de Maximo Manage. Ces composants sont installés en tant que partie intégrante de Maximo Manage au sein de Maximo Application Suite. Le processus implique des considérations importantes en matière de licence, de compatibilité et de configuration de la base de données.
Avant tout déploiement, il est impératif de vérifier la compatibilité des Industry Solutions et Add-ons avec la version de Maximo Manage et de Maximo Application Suite. Des étapes de préparation, telles que la revue des langues supportées pour les déploiements multilingues, sont également nécessaires.
- Entitlement et Licensing — Chaque Industry Solution et Add-on requiert un `entitlement` spécifique. L'accès à ces applications est souvent lié à un niveau de licence `Premium` basé sur les `AppPoints`.
- Base de données — Pour déployer `Maximo Manage` (et par extension ses Industry Solutions/Add-ons), une instance de base de données configurée et opérationnelle est requise. Maximo supporte `Db2`, `Db2 Warehouse`, `Microsoft SQL Server`, ou `Oracle Database`. Il est à noter que si `Maximo Health` est déployé avec `Maximo Manage`, ils partagent la même base de données.
- Processus de déploiement — Les Industry Solutions et Add-ons sont inclus en option lors du processus de déploiement et d'activation de Maximo Manage. Cela permet aux organisations de choisir les extensions pertinentes pour leurs opérations.
- Intégration externe — Maximo Manage, avec ses extensions, peut être intégré à des applications tierces comme SAP, Oracle ou Workday. Ces intégrations sont facilitées par l'utilisation de connecteurs spécifiques, assurant un flux de données cohérent entre les systèmes.
🔄 Cycle de vie d'une extension Maximo Manage
Le cycle de vie d'une Industry Solution ou d'un Add-on au sein de Maximo Manage suit un cheminement structuré, de l'acquisition à l'opérationnalisation. Ce processus garantit que les extensions sont correctement intégrées et exploitées pour maximiser la valeur métier.
Chaque étape, de la décision d'acquérir une extension à son déploiement et son utilisation quotidienne, est cruciale pour assurer la cohérence et la performance de l'ensemble du système de gestion d'actifs.
⚠️ Pièges IBM
Les candidats peuvent confondre la nature et l'objectif des Industry Solutions et des Add-ons. Une Industry Solution est spécifique à un secteur (ex: Maximo Aviation pour l'aéronautique), intégrant des processus métier et des données propres à cette industrie. Un Add-on (ex: Maximo Asset Configuration Manager) est un module complémentaire qui étend les fonctionnalités de base de Maximo Manage de manière plus générale, souvent applicable à plusieurs secteurs. L'examen peut présenter des scénarios où la distinction est floue, testant la capacité à identifier la bonne catégorie d'extension.
L'accès aux Industry Solutions et Add-ons n'est pas automatique avec une licence Maximo Manage de base. Il nécessite un `entitlement` spécifique pour chaque installation et est souvent lié à un niveau de licence `Premium` basé sur les `AppPoints`. Un piège courant serait de supposer qu'une organisation ayant Maximo Manage peut simplement activer n'importe quelle extension sans considération de licence supplémentaire. L'examen peut poser des questions sur les prérequis d'accès ou les conséquences d'un manque d'entitlement.
Le déploiement des Industry Solutions et Add-ons n'est pas un processus isolé. Il est réalisé en option lors du déploiement et de l'activation de Maximo Manage au sein de Maximo Application Suite. De plus, des vérifications de compatibilité sont essentielles, et certaines applications, comme `Maximo Health`, peuvent partager la même base de données que Maximo Manage. Un piège serait de négliger ces interdépendances, conduisant à des problèmes de déploiement ou de performance. L'examen peut interroger sur l'ordre des étapes de déploiement ou les conditions préalables.
🎯 Carte mémoire
Quelle est la principale différence entre une Industry Solution et un Add-on dans Maximo Manage, et donnez un exemple pour chacun ?
Une Industry Solution est une extension spécifique à un secteur d'activité (ex: Maximo Transportation pour les transports), intégrant des processus et des données propres à cette industrie. Un Add-on est un module complémentaire qui étend les fonctionnalités de base de Maximo Manage de manière plus générale (ex: Maximo Health, Safety and Environment), applicable à diverses industries.
Quelles sont les conditions de licence et d'accès pour les Industry Solutions et Add-ons de Maximo Manage ?
L'accès aux Industry Solutions et Add-ons requiert un `entitlement` spécifique pour chaque installation. Cet accès est souvent associé à un niveau de licence `Premium` au sein de Maximo Application Suite, déterminé par l'utilisation des `AppPoints`.
Comment les Industry Solutions et Add-ons sont-ils déployés et quelles bases de données sont supportées par Maximo Manage ?
Ils sont déployés en tant que composants optionnels lors du processus de déploiement et d'activation de Maximo Manage au sein de Maximo Application Suite. Maximo Manage supporte `Db2`, `Db2 Warehouse`, `Microsoft SQL Server`, ou `Oracle Database`.
Citez au moins trois Industry Solutions et deux Add-ons disponibles pour Maximo Manage.
Industry Solutions : Maximo Aviation, Maximo Oil & Gas, Maximo Utilities. Add-ons : Maximo Asset Configuration Manager, Maximo Health, Safety and Environment.
Correct: A, C
Pourquoi A, C — MAS v9 ne tourne QUE sur OpenShift. Deux options principales : Self-managed OCP (OpenShift sur hardware client on-prem, ou ROSA sur AWS, ou ARO sur Azure — tous des OpenShift flavors) et IBM Cloud OpenShift (ROKS) managed. Aucune autre base (vanilla k8s, Docker Swarm, WebSphere standalone) n'est supportée. Le customer choisit selon sa stratégie cloud.
Pourquoi B est faux — D1 legacy : 7.6 in-place upgrade est une migration path, pas un target de déploiement.
Pourquoi D est faux — D2 invented : « Microsoft Dynamics Maximo Cloud » est un terme totalement fabriqué — aucun partenariat IBM-Microsoft n'offre de Maximo rebranded Dynamics. Piège qui mélange l'écosystème Microsoft Dynamics ERP avec la suite IBM MAS.
Why E wrong — D7 non-existent : vanilla Kubernetes sans OCP Operators n'est pas une plateforme supportée — MAS exige spécifiquement OpenShift Container Platform pour ses Operator-based deploys (IBM Operator Catalog), les primitives Kubernetes natives ne suffisent pas pour orchestrer Manage/Monitor/Health.
- IBM Docs — MAS system requirements : OCP variants
- IBM Cloud ROKS docs : Managed OpenShift
Correct: D
Pourquoi D (correct) — Le MAS Installer (mas.cli — wrapper interactive CLI, ou le bundle Ansible équivalent) orchestre le déploiement initial sur OpenShift : installe le mas-suite-operator, cert-manager (pour TLS auto), MongoDB (pour Suite metadata), puis chaque application operator (Manage, Monitor, Health, Predict, VI) dans l'ordre adéquat. Il configure aussi les routes OCP et les catalogs. Après install, les upgrades passent par le Suite UI ou des re-runs du CLI.
Pourquoi A est faux — D2 invented : migration DB (Db2→PostgreSQL ou autre) utilise mxloader/dbconfig, pas mas.cli.
Pourquoi B est faux — D3 wrong scope : ongoing AppPoints management se fait dans Suite Admin UI, pas installer.
Pourquoi C est faux — D4 adjacent : BIRT est le reporting engine de Manage, hors scope installer.
- IBM Docs — MAS CLI installer : Ansible bundle
- ibm-mas/cli GitHub : Install guides
Correct: A
Pourquoi A (correct) — Manage v9.0 supporte trois moteurs DB pour son OLTP (transactions) : IBM Db2, Oracle Database, Microsoft SQL Server — chacun dans leurs versions minimums documentées. Le customer provisionne la DB hors cluster OCP et fournit la connection string au Manage workspace. MongoDB (bundled par la Suite pour metadata ops) n'est PAS la DB Manage.
Pourquoi B est faux — D1 legacy : l'idée qu'Oracle/SQL Server auraient été retirés est un faux rumor. Les 3 restent supportés en v9.
Pourquoi C est faux — D5 inverted : Manage ne ship PAS de DB pod bundled ; le customer fournit la DB externe.
Pourquoi D est faux — D2 invented : MongoDB est utilisé dans MAS pour les metadata de la Suite (config runtime, logs Suite Manager) mais jamais comme OLTP backend pour Manage — l'application business (WOs, Assets, POs) s'appuie exclusivement sur Db2 ou Oracle ou PostgreSQL selon le customer choice.
- IBM Docs — Database requirements : Db2/Oracle/SQL Server
- IBM Docs — System requirements : DB versions
Correct: B
Pourquoi B (correct) — Toute la configuration Manage (tables MAXATTRIBUTE, SIGOPTION, MAXAPP, DOMAIN, etc.) est persistée dans la base de données transactionnelle externe (Db2/Oracle/SQL Server). Les pods Manage sur OCP sont stateless — ils rechargent la config depuis la DB au démarrage. Ce design permet scale horizontal (multiples pods en replica set) sans perte de config ; pod restart ou re-deploy ne perd rien.
Pourquoi A est faux — D1 legacy : persistence sur /opt/IBM/SMP était le modèle 7.6 on-VM. Containers = stateless.
Pourquoi C est faux — D3 wrong scope : config Manage vit dans sa DB relationnelle, pas MongoDB (qui est Suite metadata).
Pourquoi D est faux — D2 invented : ConfigMaps OCP portent le wiring Suite (URLs, secrets), pas le schéma de config Manage.
- IBM Docs — Manage architecture : Stateless pods
- IBM Docs — Database requirements : DB-centric config
Correct: D
Pourquoi D (correct) — Le défaut v9 : TLS / HTTPS end-to-end enforced via les OpenShift routes exposant les Suite URLs, avec certificats auto-issués et rotés par cert-manager (Operator standard OCP). Cette configuration est mandatory par défaut — pas d'option HTTP pour production. Les certificats peuvent être self-signed (dev) ou issued par une CA publique (Let's Encrypt, DigiCert). Le Suite Admin ne configure pas le TLS manuellement ; cert-manager s'en charge.
Pourquoi A est faux — D1 legacy : plain HTTP par défaut était une option 7.6, retirée en v9.
Pourquoi B est faux — D9 near-synonym : « SSL encryption » est le terme deprecated ; v9 nomme TLS/HTTPS avec cert-manager.
Pourquoi C est faux — D5 inverted : external traffic DOIT être TLS ; mTLS pod-to-pod est un détail interne additionnel.
- IBM Docs — MAS TLS certificates : cert-manager + routes
- OpenShift routes + cert-manager : Auto-issuance
Correct: A, B, C
Pourquoi A, B, C — Maximo stratifie ses records en 3 boundaries business, du plus large au plus étroit : Set (Item Set + Company Set — mutualisés entre Orgs), Organization (GL, Base Currency, tolérances financières), Site (Assets, Locations, WOs, Inventory — le niveau opérationnel transactionnel). Cette hiérarchie permet data sharing et data separation selon le besoin : items communs à plusieurs Orgs via Set, autonomie par Org, opérations isolées par Site.
Pourquoi D est faux — D2 invented : « MAS Tenant » n'est pas une record boundary visible dans Manage.
Why E wrong — D4 adjacent : les namespaces OpenShift sont des artefacts infrastructure (isolation réseau + quotas cluster) gérés par les ops team, sans sémantique business — jamais utilisés comme unité de segmentation organisationnelle Maximo (qui relève d'Organizations/Sites).
Why F wrong — D3 wrong scope : Ledger Book existe (grouping GL sous une Org) mais n'est pas une boundary de structure data.
- IBM Docs — Sets, Organizations, Sites : 3 boundaries
- Maximo Secrets — Organizations and Sites (Portaluri, 2016) : Hierarchy
Correct: A
Pourquoi A (correct) — Default Insert Site est l'attribut sur le User record qui pré-remplit le Site ID à chaque création d'un nouveau record (WO, Asset, Location, PR...). C'est une aide ergonomique — un technicien basé sur Site USNORTH peut ouvrir un WO sans avoir à sélectionner son Site manuellement. L'attribut seed aussi le Session Site context (le header de la session). La visibilité des records reste gouvernée par les Security Groups, pas cet attribut.
Pourquoi B est faux — D5 inverted : la visibilité des records est filtrée par Security Groups, pas par Default Insert Site.
Pourquoi C est faux — D4 adjacent : le routing OpenShift (Ingress / Route CRD) est configuré au niveau cluster ou namespace, jamais par Site Maximo — il régit le trafic HTTP vers les pods, aucune notion de Site dans sa config. Confusion entre infra réseau et data segmentation Maximo.
Pourquoi D est faux — D3 wrong scope : Base Currency vit au niveau Organization, pas User.
- IBM Docs — Default Insert Site : User attribute
- IBM Docs — Users and User Templates : Session context
Correct: B
Pourquoi B (correct) — Les Security Groups restent le mécanisme d'authorization dans Manage v9, même avec MAS SSO actif. Séparation claire : MAS SSO = authentication (« qui est cet user »), Manage Security Groups = authorization (« que peut-il faire »). Les deux couches coexistent. Les Security Groups définissent l'accès aux apps, Sites, Orgs, records, et aux actions (sigoptions). MAS Suite a aussi ses Suite Roles pour le cross-app mais ils ne remplacent pas les Security Groups internes à Manage.
Pourquoi A est faux — D1 legacy : MAS Suite Roles sont pour cross-app access, pas un remplacement des Manage Security Groups.
Pourquoi C est faux — D3 wrong scope : les Security Groups sont cross-Organization dans Maximo Manage (Site et Org listés dans l'onglet Sites du group), mais jamais Set-level — les Sets (Item Set, Company Set) partagent des référentiels de données, pas des permissions. Scope sécurité complètement découplé du scope Sets.
Pourquoi D est faux — D2 invented : aucun mécanisme per-page ACL natif dans Manage v9 — les permissions UI s'expriment via Application Access (app visible/pas visible) et Application Options (sigoptions par app), pas page-par-page. Granularité app-level uniquement, pas URL-level.
- IBM Docs — Security Groups : Authz mechanism
- IBM Docs — MAS SSO + Manage : Authn layer
Correct: C
Pourquoi C (correct) — Au premier SSO login d'un user Suite, Manage applique son mécanisme de JIT provisioning (Just-In-Time) : il crée automatiquement un record MAXUSER avec l'email Suite comme clé de mapping, et applique le default User Template configuré (qui définit Default Insert Site, Security Groups, Status Out tableau). Ce pattern élimine le besoin de pre-provisioning manuel et garantit que chaque user authentifié par la Suite peut immédiatement utiliser Manage avec le bon setup.
Pourquoi A est faux — D1 legacy : pre-provisioning manuel était le pattern Maximo 7.6 (sync LDAP batch).
Pourquoi B est faux — D2 invented : aucun button « Sync Manage users » dans Suite Admin.
Pourquoi D est faux — D7 non-existent : Manage utilise TOUJOURS l'email Suite comme mapping key, pas un loginID random.
- IBM Docs — JIT user provisioning : MAXUSER auto-create
- IBM Docs — User Templates : Default template
Correct: B, C
Pourquoi B, C — Le Suite Administrator assigne explicitement Limited ou Premium à un nouveau user MAS via la Suite Manager. Chacun consomme plus d'AppPoints que Base (multiplicateur d'entitlement). Sans grant explicite, le user reste Base — ce qui limite les apps accessibles et les fonctionnalités IBM Cloud.
Pourquoi A est faux — D9 : Base est le default, appliqué automatiquement au premier SSO login. Aucun grant admin requis.
Pourquoi D est faux — D1 legacy : « Install user » était un concept de l'installer Maximo 7.6 ; inexistant en MAS v9.
Why E wrong — D2 invented : pas de type « Auto-Provisioned » dans MAS. Distracteur fabriqué.
- IBM Docs — MAS User types : Base / Limited / Premium
- IBM Docs — AppPoints administration : Entitlement model
Correct: A, B
Pourquoi A, B — IBM commercialise Maximo Application Suite 9.0 en 2 modes de déploiement officiels : (1) MAS SaaS Flex — offre cloud managed by IBM, hébergée sur IBM Cloud (régions multi-continents), abonnement annuel à l'AppPoint, zéro ops infra, (2) MAS On-Premises — déploiement sur OpenShift Container Platform (OCP 4.12+) on-premise ou cloud privé, client gère OCP/storage/upgrades. Choix basé sur data residency, coût TCO, contrôle infra.
Pourquoi C est faux — D1 legacy : Maximo EAM 7.6 (WebSphere) est retired, pas de "MAS Legacy WebSphere Edition".
Pourquoi D est faux — D2 invented : "Serverless Edge" n'existe pas — MAS tourne en containers OCP stateful.
Why E wrong — D7 non-existent : aucun Maximo Desktop Client n'a jamais existé — l'UI est historiquement web-based (Java applet dans Maximo 5-7, JSP puis React en MAS). Distracteur qui invente une modalité de delivery absente du produit.
- IBM Docs — MAS deployment options : SaaS Flex vs On-Premises
- IBM Docs — MAS SaaS Flex : Cloud subscription model
Correct: A, B
Pourquoi A, B — Le modèle AppPoint MAS définit 2 user types : (1) Authorized User — accès complet (create/update/delete/approve), tarif plein (~10 AppPoints/user/an pour Manage), (2) Limited User — read-only + quelques transactions restreintes (Service Requests, log labor), ~1 AppPoint. Orgs optimisent 90% Limited + 10% Authorized. Distinction configurée via Security Groups.
Pourquoi C est faux — D2 invented : "Shadow User" n'existe pas dans la taxonomie MAS — terme fabriqué qui ne correspond à aucun user type ni rôle technique Maximo. Les user types sont strictement Authorized + Limited (AppPoints model), rien d'autre.
Pourquoi D est faux — D9 near-synonym : "Bulk User" n'est pas un tier — service accounts = Limited standards.
Why E wrong — D1 legacy : "Named" = modèle Maximo 7.6, remplacé par AppPoint en MAS.
- IBM Docs — MAS AppPoint licensing : Authorized vs Limited
- IBM Redbook — MAS deployment guide : User types
Correct: A, B, C
Pourquoi A, B, C — MAS 9.0 ship avec 5 core products sur le catalog OpenShift Operator : (1) Manage — successor de Maximo EAM 7.6 (WOs, Assets, Inventory, PO), (2) Health — asset health scoring basé rules + ML, (3) Monitor — IoT data ingestion + anomaly detection. Les 2 autres (non listés) : Predict (ML predictive) et Visual Inspection (computer vision). Tous via MAS Core + Operators, consommant AppPoints.
Pourquoi D est faux — D2 invented : IBM Planning Analytics (ex-TM1) est un produit planification budget séparé, intégrable via API mais pas bundled MAS.
Why E wrong — D9 near-synonym : WatsonX Assistant = IBM AI conversational séparé — MAS utilise AI Broker comme abstraction LLM (Granite).
Why F wrong — D1 legacy : Maximo Mobile Classic = ère 7.6 (Work Manager offline), retired dans MAS au profit de MAS Mobile React Native.
- IBM Docs — MAS product catalog : Core apps
- IBM Docs — MAS 9.0 overview : Bundled products

Configurer le Chart of Accounts
📋 Objectifs IBM
- Comprendre la structure et le rôle du Chart of Accounts dans Maximo Manage 9.x
- Configurer des comptes généraux (GL accounts) pour le suivi des coûts
- Maîtriser l'intégration entre les GL accounts et les modules Assets, Work Orders et Inventory
- Implémenter des validations financières via les composants GL
- Gérer les périodes fiscales et les restrictions d'accès aux comptes
- Résoudre les conflits de comptabilité entre systèmes externes et Maximo
💡 Points clés
- GL Account Structure — Hiérarchie modulaire composée de segments (ex:
COMPANY,DEPARTMENT,ACCOUNT) définis dansGLCOMPONENT. - Component Validation — Restrictions configurables via
VALIDATIONWHEREpour garantir l'intégrité des combinaisons de composants. - Cross-Module Integration — Les GL accounts impactent
WORKORDER,ASSET, etINVENTORYvia les champsGLDEBITACCT/GLCREDITACCT. - Fiscal Period Control — Verrouillage des écritures via
FINANCIALPERIODavec statutsOPEN/CLOSED. - Resource Codes — Complément aux GL accounts pour le suivi détaillé des ressources (main-d'œuvre, matériel).
- Account Inactivation — Désactivation en cascade des comptes liés lorsqu'un composant GL passe à
INACTIVE. - External System Mapping — Synchronisation bidirectionnelle avec les systèmes ERP via
EXTERNALREFID.
📐 Architecture comptable
Le modèle de données financières de Maximo repose sur trois couches interconnectées : les composants GL, les combinaisons de comptes, et les règles de validation. Cette architecture permet une granularité adaptative aux normes comptables internationales (IFRS, SOX).
La table GLACCOUNT stocke les combinaisons valides, tandis que GLCOMPONENT définit la structure hiérarchique. Les relations many-to-many sont gérées via GLCOMPONENTVALUE et GLACCTCOMP.
📊 Comparaison des types de composants GL
| Composant | Table liée | Validation | Exemple |
|---|---|---|---|
COMPANY | COMPANIES | Liste fixe | ACME_CORP |
COSTCENTER | COSTCENTER | Plage numérique | 6200-6299 |
ACCOUNT | GLACCOUNT | Expression SQL | LIKE '4%' |
PROJECT | PROJECT | Cross-org | PRJ_2024_XYZ |
⚙️ Configuration opérationnelle
La configuration d'un compte général implique 5 étapes dans l'application Chart of Accounts : définition des composants, création des valeurs, assemblage des combinaisons, paramétrage des validations, et tests de conformité.
Exemple pour un compte d'amortissement : le composant ASSETTYPE se limite aux valeurs PRODUCTION/FACILITY, tandis que le segment DEPRECIATION exige un préfixe DEPT_.
- Étape 1 — Naviguer vers
Financial > Chart of Accounts > GL Component Maintenance. - Étape 2 — Définir l'ordre des segments via
SEQUENCEet le type de données (ALN,NUMERIC). - Étape 3 — Configurer les règles de validation dans
VALIDATIONWHERE(ex:STATUS = 'ACTIVE'). - Étape 4 — Générer des combinaisons automatiques via
Generate GL Accounts. - Étape 5 — Assigner les comptes par défaut dans
Organization Defaults.
🔄 Cycle de vie d'un compte GL
Un compte général évolue à travers 4 états majeurs : création, activation, utilisation, et désactivation. Les transitions entre états déclenchent des contrôles de cohérence et des mises à jour en cascade.
Inactive vérifient l'absence de transactions ouvertes référençant le compte.⚠️ Pièges IBM
L'examen suggère souvent que la désactivation d'un composant GL bloque immédiatement tous les comptes associés. En réalité, Maximo permet de conserver les comptes existants actifs via ALLOWEXISTING, tout en interdisant les nouvelles combinaisons.
Un scénario fréquent présente l'import de comptes depuis un ERP comme écrasant les règles de validation Maximo. En pratique, l'option Validate External GL Accounts dans System Properties préserve les contraintes locales.
🎯 Carte mémoire
Quelles tables stockent la hiérarchie complète d'un compte GL ?
GLCOMPONENT (structure), GLCOMPONENTVALUE (valeurs autorisées), et GLACCOUNT (combinaisons validées). Les relations sont maintenues via GLACCTCOMP.
Comment restreindre un compte GL aux actifs de production ?
Ajouter une clause WHERE ASSETTYPE = 'PRODUCTION' dans VALIDATIONWHERE du composant ASSET, et lier ce composant à la structure GL via GLCOMPONENT.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Bonne réponse : A
Pourquoi cette question existe — STU §2.1 — la question teste la compréhension fondamentale de la configuration des segments de comptes GL dans Maximo Manage. Les distracteurs montrent les erreurs typiques : confondre la configuration GL avec des applications financières (D6), penser que la configuration se fait dans les modules d'inventaire (D5), ou croire qu'elle est gérée dans des applications de contrôle des coûts (D7). En pratique terrain, l'omission de la configuration des segments GL est une erreur fréquente dans les implémentations multi-sites.
Le contexte théorique d'abord — La structure des segments de comptes GL est définie par trois paramètres clés : longueur, délimiteur, et liste de validation. Ces paramètres sont configurés au niveau de l'organisation pour s'assurer que les comptes GL respectent les règles de l'ERP. Les segments sont ensuite utilisés pour valider les comptes lors de la saisie ou de l'importation.
Ce que Maximo en fait — version opérationnelle — Application Database Configuration > GL Account Configuration > Chart of Accounts. L'administrateur définit la longueur des segments (ex. 5 caractères), le délimiteur (ex. "-"), et les règles de validation (ex. liste de codes autorisés). Cette configuration est ensuite appliquée à tous les comptes GL de l'organisation.
Exemple chiffré — Organisation ACME : longueur de segment = 3, délimiteur = "-", validation basée sur une liste de 12 codes autorisés. Lors de l'importation de 500 comptes GL, 32 sont rejetés car ils ne respectent pas la structure définie.
Analogie quotidienne — C'est comme configurer un format de numéro de téléphone dans un formulaire : tu définis la longueur (10 chiffres), le séparateur ("-"), et les préfixes autorisés (ex. "514"). Si un numéro ne respecte pas ces règles, il est rejeté.
Pourquoi B est faux — Pattern D7 Inexistant : "Financial Account Setup" n'est pas une application Maximo existante.
Pourquoi C est faux — Pattern D5 Champ-frère : "Inventory / Storerooms" est une application liée à la gestion des stocks, pas à la configuration des comptes GL.
Pourquoi D est faux — Pattern D6 Mauvaise-app : "General Ledger Cost Control" est une application de contrôle des coûts, pas de configuration des segments GL.
- GL Account Configuration — configuration des segments de comptes GL.
- Chart of Accounts — liste des comptes GL définis pour une organisation.
- Validation List — liste de codes autorisés pour chaque segment.
- Delimiter — caractère utilisé pour séparer les segments.
- Length — nombre de caractères autorisés pour chaque segment.
- Configuration des segments GL = Database Configuration > GL Account Configuration.
- Longueur, délimiteur, et validation définis au niveau de l'organisation.
- Erreur fréquente : oublier de configurer les segments dans les implémentations multi-sites.
- STU sub-objective §2.1 — Configurer le Chart of Accounts
- [EOTRAG] Query — « Maximo GL Account Configuration segments length delimiter validation » (confidence 0.98)
- master-map.pdf p.270-273 — IBM Docs GL Account Configuration
Bonne réponse : B
Pourquoi cette question existe — STU §2.1 — cette question teste la compréhension du rôle du flag "Mandatory" dans la configuration des segments du Chart of Accounts. Elle vise à éviter l'erreur courante consistant à confondre ce flag avec des fonctionnalités comme le verrouillage des segments ou leur exclusion des rapports. En pratique terrain, l'omission de ce flag peut entraîner des erreurs de validation des GL strings.
Le contexte théorique d'abord — Le Chart of Accounts dans Maximo est utilisé pour définir les comptes généraux (GL accounts) et les codes de ressources pour les fonctions comptables standard. Chaque segment du GL account peut être configuré avec des options de validation, dont le flag "Mandatory". Ce flag garantit que le segment doit être rempli avec une valeur valide avant que le GL string puisse être sauvegardé ou posté.
Ce que Maximo en fait — version opérationnelle — Dans l'application Chart of Accounts, lors de la configuration d'un segment, l'administrateur active le flag "Mandatory" pour s'assurer que ce segment ne peut pas être laissé vide. Par exemple, pour un segment "Department", le flag "Mandatory" oblige l'utilisateur à sélectionner un département valide avant de pouvoir sauvegarder le GL string.
Exemple chiffré — Un GL string composé de 5 segments (Company=100, Account=2000, Department=30, Project=500, Cost Center=10) : si le segment "Department" est marqué comme "Mandatory" et laissé vide, Maximo bloque la sauvegarde avec un message d'erreur "Department is required".
Analogie quotidienne — C'est comme remplir un formulaire administratif où certains champs sont obligatoires : si vous oubliez de remplir votre adresse, le formulaire ne peut pas être soumis.
Pourquoi A est faux — Pattern D2 Inventé : le flag "Mandatory" ne verrouille pas les segments après le go-live, il garantit seulement qu'ils doivent être remplis.
Pourquoi C est faux — Pattern D7 Inexistant : Maximo ne propose pas de fonctionnalité pour auto-remplir un segment à partir de la localisation d'un Asset parent.
Pourquoi D est faux — Pattern D3 Inverse : le flag "Mandatory" ne sert pas à exclure un segment des rapports, mais à garantir qu'il est rempli.
- Chart of Accounts — application pour définir les comptes généraux et les codes de ressources.
- GL account — compte général utilisé pour les transactions comptables.
- Segment — composant d'un GL string (ex : Company, Account, Department).
- Mandatory flag — garantit qu'un segment doit être rempli avant sauvegarde.
- GL string — combinaison de segments formant un compte général complet.
- "Mandatory" force un segment à être rempli avant sauvegarde.
- Ne verrouille pas les segments après le go-live.
- Ne sert pas à exclure des segments des rapports.
- STU sub-objective §2.1 — Configuration du Chart of Accounts
- [EOTRAG] Query — « Maximo Chart of Accounts Mandatory flag purpose » (confidence 0.92)
- master-map.pdf p.342-344 — IBM Docs Managing charts of accounts
Bonne réponse : C
Pourquoi cette question existe — STU §2.1 — la question teste la compréhension des options de validation des chaînes de comptes généraux (GL) dans Maximo Manage 9.0. Les distracteurs montrent les erreurs typiques : ignorer la validation des segments individuels (A), penser que la validation est désactivée en multi-site (B), ou croire que la validation est déléguée à un ERP externe (D). En pratique terrain, une mauvaise configuration peut entraîner des erreurs de comptabilité critiques.
Le contexte théorique d'abord — La validation des chaînes de comptes généraux (GL) dans Maximo Manage 9.0 est configurable par organisation. Elle peut être définie comme « Aucune validation », « Validation des segments individuels », ou « Validation complète contre les combinaisons existantes ». Cette configuration est cruciale pour garantir l'intégrité des données financières, surtout dans les environnements multi-sites.
Ce que Maximo en fait — version opérationnelle — Application Organizations > Sélectionnez une organisation > Onglet GL Account Validation. Choisissez parmi les options : No validation, Validate individual segments, ou Fully validate against existing combinations. Sauvegardez et configurez la base de données pour appliquer les changements.
Exemple chiffré — Organisation « Site A » : 3 segments de compte GL configurés, 120 combinaisons valides. Avec « Validation complète », une tentative d'entrée d'une combinaison non valide (ex : « 123-456-789 ») est rejetée. Avec « Validation des segments individuels », seule la longueur de chaque segment est vérifiée (ex : « 123-45-6789 » est accepté si chaque segment a la bonne longueur).
Analogie quotidienne — C'est comme un contrôleur de billets dans un train : il peut vérifier seulement si vous avez un billet (validation de longueur), vérifier si votre billet est valide pour ce train (validation des segments), ou vérifier si votre billet correspond à un siège spécifique (validation complète).
Pourquoi A est faux — Pattern D4 demi-vérité : Maximo peut valider la longueur, mais il peut aussi valider le contenu des segments individuels selon la configuration.
Pourquoi B est faux — Pattern D2 inventé : La validation n'est pas désactivée en multi-site ; elle est configurable par organisation.
Pourquoi D est faux — Pattern D7 inexistant : Maximo ne délègue pas la validation des comptes GL à un ERP externe ; cela est géré en interne.
- GL Account Validation — configuration des options de validation des comptes généraux.
- Organizations — application où la validation des comptes GL est configurée.
- Segments individuels — parties d'une chaîne de compte GL validées séparément.
- Combinaisons existantes — validation contre les combinaisons de comptes déjà définies.
- Multi-site — environnement où plusieurs sites partagent la même configuration.
- Validation des comptes GL configurable par organisation.
- Options : aucune, segments individuels, validation complète.
- Pas de délégation à un ERP externe.
- STU sub-objective §2.1 — GL Account Validation
- [EOTRAG] Query — « Maximo Manage 9.0 GL Account Validation options » (confidence 0.92)
- master-map.pdf p.78-81 — IBM Docs GL Account Validation
Bonne réponse : D
Pourquoi cette question existe — STU §2.1 — cette question teste la compréhension du mécanisme de cascade de règles pour déterminer le compte GL Debit lors de l'approbation d'un Work Order. Les erreurs courantes incluent la méconnaissance de la hiérarchie des sources (Asset > Location > etc.) et la confusion entre configuration globale et règles contextuelles. En pratique, cette cascade permet une granularité financière adaptée à chaque situation.
Le contexte théorique d'abord — Maximo utilise une logique de priorité pour déterminer le compte GL Debit : il consulte d'abord le Work Order lui-même, puis remonte les relations (Asset associé, Location, etc.) jusqu'à trouver une valeur définie. Cette hiérarchie est configurable dans Organizations → GL Account Mapping. Les composants inactifs (comme le cost center 6250 dans l'exemple RAG) n'affectent pas les comptes existants mais bloquent les nouvelles utilisations.
Ce que Maximo en fait — version opérationnelle — Dans Organizations > GL Account Mapping, on configure l'ordre des sources à consulter (ex: Asset(70%) > Location(20%) > Failure Class(10%)). Lors de l'approbation du WO, Maximo parcourt cette liste jusqu'à trouver un compte GL Debit défini. Si aucun n'est trouvé, il utilise la valeur par défaut de l'Organization. Ce mécanisme ne fait pas d'appel externe (REST) et ne se limite pas au header du WO.
Exemple chiffré — Pour un WO avec Asset=COMP-45 (GL Debit=5200), Location=BLDG-2 (GL Debit=5100), et Priority=3 (GL Debit=5000) : Maximo prend 5200 (Asset) car il est prioritaire dans la cascade configurée (Asset=70%, Location=20%, Priority=10%). Si COMP-45 n'avait pas de GL Debit défini, ce serait 5100 (Location).
Analogie quotidienne — Comme un GPS qui combine plusieurs sources (trafic en temps réel, travaux programmés, préférences utilisateur) pour calculer l'itinéraire optimal, en donnant plus de poids à certaines sources selon les règles configurées.
Pourquoi A est faux — Le header du WO n'est qu'une source parmi d'autres dans la cascade. Ignorer les autres sources (Asset, Location, etc.) serait contraire au mécanisme natif. (Pattern D4 Demi-vérité)
Pourquoi B est faux — Bien qu'une valeur par défaut existe au niveau Organization, elle peut être surchargée par des règles plus granulaires (Asset, Location, etc.). (Pattern D3 Inverse)
Pourquoi C est faux — Maximo gère cette logique en interne via sa configuration de cascade, sans appel REST externe. (Pattern D2 Inventé)
- GL Account Mapping — configuration de la hiérarchie des sources pour déterminer les comptes GL.
- Composants inactifs — valeurs désactivées qui n'affectent pas les enregistrements existants.
- Cascade de règles — mécanisme de priorité entre différentes sources de données.
- Cost Center — composant du compte GL souvent lié aux Assets ou Locations.
- Valeur par défaut — compte GL utilisé si aucune source plus granulaire n'est définie.
- La détermination du GL Debit suit une cascade configurée dans GL Account Mapping.
- Asset > Location > Failure Class > etc. : ordre et poids configurables.
- Pas d'appel REST externe, logique 100% interne à Maximo.
- STU sub-objective §2.1 — Chart of Accounts configuration
- [EOTRAG] Query — « Maximo GL Debit account determination Work Order approval cascade » (confidence 0.95)
- master-map.pdf p.87-89 — IBM Docs GL Account Mapping
Bonne réponse : B
Pourquoi cette question existe — STU §2.1 — la question vérifie la maîtrise du placeholder système pour les segments manquants d'un compte GL partiellement construit. Les distracteurs testent la confusion avec d'autres caractères spéciaux courants (D4, D9) et un format obsolète (D1). En pratique, l'oubli du "?" comme placeholder standard cause des erreurs de validation dans les interfaces financières.
Le contexte théorique d'abord — Un compte GL (General Ledger) dans Maximo est composé de plusieurs segments (ex: Company=010, Account=5110). Lorsqu'un segment obligatoire n'est pas renseigné, le système utilise un caractère placeholder défini dans Database Configuration sous GL Account Format. Ce placeholder permet de valider temporairement la structure du compte avant sa complétion.
Ce que Maximo en fait — version opérationnelle — Dans Database Configuration > GL Account Format, le placeholder par défaut est le "?". Pour un compte partiel "01??-??", le système valide la structure mais bloque la comptabilisation jusqu'à remplacement complet des "?". Ce paramètre est modifiable en Admin Mode via System Properties (clé mxe.sep.glacctplaceholder).
Exemple chiffré — Compte GL avec 4 segments : Company (3 chiffres), Account (4), Department (2), Project (3). Saisie partielle "012-????-45" → système accepte avec 3 segments valides (012, 45) et 2 placeholders (4 "?"). Après complétion : "012-5110-45-789" → compte validé pour posting.
Analogie quotidienne — Comme un formulaire administratif où les champs obligatoires non remplis sont marqués "À compléter" : le document peut être soumis pour traitement initial, mais nécessite ces informations pour le traitement final.
Pourquoi A est faux — Pattern D1 Hérité : l'astérisque était utilisé dans certaines versions antérieures (Maximo 7.x) mais n'est plus le standard en 9.x.
Pourquoi C est faux — Pattern D9 Quasi-synonyme : le tiret est un séparateur entre segments, pas un placeholder pour segments manquants.
Pourquoi D est faux — Pattern D4 Demi-vérité : l'underscore est utilisé dans d'autres contextes techniques (SQL, DB) mais pas comme placeholder GL natif.
- GL Account Format — structure des segments composant un compte GL.
- Placeholder — caractère temporaire pour segments manquants.
- Database Configuration — application de configuration des formats GL.
- System Properties — paramètres système modifiables en Admin Mode.
- Validation Where Clause — règle de validation des comptes GL.
- Le placeholder standard pour segments GL manquants est "?".
- Configurable via Database Configuration ou System Properties.
- Permet une validation partielle avant complétion du compte.
- STU sub-objective §2.1 — Configurer le Chart of Accounts
- [EOTRAG] Query — « Maximo GL account placeholder character standard » (confidence 0.93)
- master-map.pdf p.203-205 — IBM Docs General Ledger Configuration
Configurer les Currencies et Exchange Rates
📋 Objectifs IBM
- Comprendre la gestion des devises et des taux de change dans IBM Maximo Manage.
- Identifier les applications clés utilisées pour la configuration et l'administration des devises.
- Expliquer comment Maximo gère les transactions en devises étrangères pour les achats.
- Décrire le processus de définition de la devise de base d'une organisation.
- Savoir administrer les taux de change entre différentes devises pour des périodes spécifiques.
- Comprendre les implications de la suppression des codes de devise.
💡 Points clés
- Devise de base — Chaque organisation dans Maximo doit avoir une devise de base spécifiée dans l'application `Organizations`.
- Codes de devise — Les devises sont définies et gérées via l'application `Currency Codes`, permettant d'ajouter ou de supprimer des codes.
- Taux de change — L'application `Exchange Rates` est utilisée pour configurer et administrer les taux de conversion entre les devises pour des périodes définies.
- Transactions étrangères — Maximo calcule automatiquement le coût de base des enregistrements d'achat (comme les `Purchase Requisitions`, `Purchase Orders`, et `Invoices`) en devise de base en utilisant le taux de change actif.
- Applications avec champ Currency — Des applications telles que `Purchase Requisitions`, `Purchase Orders`, `Invoices`, et `Companies` intègrent un champ `Currency` pour spécifier la devise des transactions.
- Suppression de devises — Il est possible de supprimer des codes de devise qui ne sont plus utilisés, mais cela nécessite une vérification des dépendances pour éviter les erreurs.
- Niveau d'application — La gestion des devises et des taux de change est principalement configurée au niveau de l'organisation, avec des implications sur les transactions au niveau du site.
📐 Architecture de la gestion des devises
La gestion des devises dans Maximo est une fonctionnalité fondamentale qui assure l'intégrité financière des opérations d'achat et de gestion des stocks. Elle repose sur une architecture centralisée qui permet de définir les devises, leurs taux de conversion et de les appliquer de manière cohérente à travers les différentes applications transactionnelles.
Cette architecture est cruciale pour les entreprises opérant dans un contexte international, où les transactions avec des fournisseurs ou des filiales peuvent impliquer diverses monnaies. Maximo garantit que toutes les valeurs sont correctement converties en devise de base de l'organisation pour les rapports et l'analyse financière.
📊 Comparaison des applications de gestion des devises
Plusieurs applications Maximo collaborent pour une gestion complète des devises. Chacune a un rôle distinct, allant de la simple définition des codes à l'administration complexe des taux de change et à l'application aux transactions financières.
Comprendre la fonction spécifique de chaque application est essentiel pour configurer correctement le système et assurer l'exactitude des données financières, en particulier dans un environnement multi-devises.
| Application Maximo | Fonctionnalité principale | Niveau d'application | Impact sur les transactions |
|---|---|---|---|
Currency Codes | Définition et gestion des codes de devise (ex: EUR, USD, JPY). | Global | Prépare les devises pour utilisation dans le système. |
Organizations | Spécification de la devise de base pour chaque organisation. | Organisation | Détermine la devise de référence pour tous les calculs financiers internes. |
Exchange Rates | Configuration et administration des taux de change entre les devises pour des périodes définies. | Organisation | Permet la conversion des coûts des transactions étrangères en devise de base. |
Purchase Requisitions | Utilisation du champ `Currency` pour les demandes d'achat en devises étrangères. | Organisation/Site | Permet l'enregistrement des demandes d'achat avec leur devise spécifique. |
Purchase Orders | Utilisation du champ `Currency` pour les bons de commande en devises étrangères. | Organisation/Site | Permet l'enregistrement des bons de commande avec leur devise spécifique. |
Invoices | Utilisation du champ `Currency` pour les factures en devises étrangères. | Organisation/Site | Permet l'enregistrement des factures avec leur devise spécifique. |
Companies | Association d'une devise par défaut à un fournisseur ou une entreprise. | Organisation | Simplifie la saisie des devises pour les transactions récurrentes avec des entités spécifiques. |
⚙️ Configuration des devises et des taux de change
La configuration des devises et des taux de change est une étape essentielle pour toute implémentation de Maximo, surtout dans un environnement commercial international. Elle garantit que les coûts sont correctement suivis et rapportés, quel que soit le pays d'origine de la transaction.
Une configuration précise évite les erreurs de calcul et assure la conformité avec les normes comptables. Le processus implique plusieurs étapes logiques, depuis la définition des devises jusqu'à l'établissement des taux de conversion.
Chaque organisation peut avoir sa propre devise de base, ce qui permet une grande flexibilité pour les entreprises avec des structures complexes ou des filiales dans différents pays. Les taux de change doivent être régulièrement mis à jour pour refléter les fluctuations du marché.
- Étape 1 : Définition des codes de devise — Dans l'application `Currency Codes`, créez tous les codes de devise nécessaires (ex: USD, EUR, GBP, CAD). Chaque code doit être unique et correspondre à une devise reconnue.
- Étape 2 : Spécification de la devise de base de l'organisation — Accédez à l'application `Organizations`, sélectionnez l'organisation concernée et définissez sa devise de base. Cette devise sera utilisée pour tous les rapports et calculs internes.
- Étape 3 : Administration des taux de change — Utilisez l'application `Exchange Rates` pour définir les taux de conversion entre la devise de base et toutes les autres devises utilisées. Spécifiez des dates de début et de fin pour chaque taux afin de gérer leur validité temporelle.
- Étape 4 : Association des devises aux entreprises — Dans l'application `Companies`, vous pouvez associer une devise par défaut à chaque fournisseur ou entreprise. Cela pré-remplit le champ `Currency` lors de la création de documents d'achat, réduisant les erreurs de saisie.
- Étape 5 : Utilisation dans les transactions d'achat — Lors de la création de `Purchase Requisitions`, `Purchase Orders` ou `Invoices`, le champ `Currency` permet de sélectionner la devise de la transaction. Maximo utilise alors le taux de change actif pour calculer le coût équivalent en devise de base de l'organisation.
Par exemple, une entreprise basée en France (devise de base EUR) commande des pièces à un fournisseur américain. Lors de la création du `Purchase Order`, la devise est définie sur USD. Si le taux de change est de 1 EUR = 1.08 USD, un coût de 1000 USD sera automatiquement converti en 925.93 EUR pour les enregistrements internes et les rapports financiers.
Il est crucial de maintenir les taux de change à jour. Maximo permet de définir des périodes de validité pour chaque taux, assurant que le système utilise toujours le taux correct au moment de la transaction. Des processus automatisés via `Cron Task` peuvent être mis en place pour importer régulièrement les taux de change depuis des sources externes.
🔄 Cycle de vie d'une transaction en devise étrangère
Le cycle de vie d'une transaction en devise étrangère dans Maximo illustre comment le système gère la conversion des coûts depuis la demande d'achat jusqu'à la facturation. Ce processus garantit la cohérence des données financières et la précision des rapports, même lorsque plusieurs devises sont impliquées.
Chaque étape du processus est conçue pour capturer la devise correcte et appliquer le taux de change approprié, assurant ainsi une visibilité complète sur les coûts réels en devise de base de l'organisation.
Le processus commence par la définition des devises et la configuration des taux de change. Ensuite, lorsqu'une `Purchase Requisition` est créée, la devise de la transaction est spécifiée. Cette information est ensuite reportée sur le `Purchase Order` correspondant. Au moment de l'enregistrement de la `Invoice`, Maximo utilise le taux de change actif pour la période concernée afin de convertir le montant en devise étrangère en devise de base de l'organisation.
Cette conversion est transparente pour l'utilisateur mais fondamentale pour la comptabilité et l'analyse financière. Elle permet aux responsables de suivre les dépenses et les budgets dans une devise unique, simplifiant ainsi la gestion financière globale.
Il est important de noter que les taux de change sont dynamiques. Maximo permet de gérer cette dynamique en associant des dates de validité aux taux, garantissant que le système applique toujours le taux correct au moment de la transaction, et non au moment de la configuration initiale.
⚠️ Pièges IBM
Les utilisateurs peuvent oublier de mettre à jour les taux de change dans l'application `Exchange Rates` ou ne pas définir de taux pour toutes les paires de devises nécessaires. Lors de la création d'un `Purchase Order` ou d'une `Invoice` en devise étrangère, Maximo pourrait alors utiliser un taux incorrect ou ne pas pouvoir effectuer la conversion, entraînant des erreurs dans les calculs de coût en devise de base. L'examen peut présenter un scénario où une transaction est effectuée avec un taux de change non valide ou manquant.
Les candidats peuvent confondre la devise de base de l'organisation (définie dans `Organizations`) avec la devise de la transaction (spécifiée dans `Purchase Requisitions`, `Purchase Orders`, `Invoices`). La devise de base est la devise de référence interne de l'entreprise, tandis que la devise de transaction est celle utilisée avec le fournisseur. Maximo effectue toujours la conversion vers la devise de base pour les rapports internes, même si la transaction est enregistrée dans une autre devise. Un piège courant est de penser que le coût affiché dans une application transactionnelle est toujours le coût final pour l'entreprise sans conversion.
Tenter de supprimer un code de devise dans l'application `Currency Codes` sans vérifier ses dépendances peut entraîner des erreurs système. Si une devise est toujours utilisée dans des enregistrements historiques (par exemple, d'anciens `Purchase Orders` ou `Invoices`), ou si elle est définie comme devise de base pour une organisation, sa suppression directe sera bloquée ou causera des incohérences. L'examen pourrait poser une question sur les prérequis avant de supprimer une devise, testant la compréhension des dépendances de données.
Une erreur fréquente est de ne pas comprendre que la devise de base est définie au niveau de l'Organization, tandis que les codes de devise sont gérés globalement. Cela peut conduire à des tentatives de configuration incorrectes ou à des attentes erronées concernant l'héritage des devises. Les taux de change sont également spécifiques à l'Organization. L'examen peut présenter des scénarios où une devise est configurée à un niveau inapproprié, affectant sa disponibilité ou son comportement.
🎯 Carte mémoire
Quelle application est utilisée pour définir la devise de base d'une organisation dans Maximo ?
La devise de base d'une organisation est spécifiée dans l'application Organizations. C'est une configuration essentielle qui détermine la devise de référence pour tous les calculs et rapports financiers internes de cette organisation.
Comment Maximo gère-t-il les coûts des Purchase Orders émis en devises étrangères ?
Lorsqu'un Purchase Order est émis en devise étrangère, Maximo utilise le taux de change actif défini dans l'application Exchange Rates pour la période concernée. Il calcule et enregistre le coût équivalent en devise de base de l'organisation pour les besoins de reporting et de comptabilité interne.
Quelles sont les applications principales qui contiennent un champ Currency pour les transactions d'achat ?
Les applications principales qui contiennent un champ Currency pour les transactions d'achat sont Purchase Requisitions, Purchase Orders, Invoices et Companies. Ce champ permet de spécifier la devise dans laquelle la transaction est effectuée.
Quelles sont les précautions à prendre avant de supprimer un code de devise dans Maximo ?
Avant de supprimer un code de devise, il est impératif de vérifier qu'il n'est plus utilisé dans aucune transaction active ou historique, ni comme devise de base pour une organisation. La suppression d'une devise en cours d'utilisation peut entraîner des erreurs et des incohérences de données dans le système.
Comment Maximo assure-t-il l'exactitude des taux de change pour les transactions passées et futures ?
Maximo assure l'exactitude des taux de change en permettant de définir des périodes de validité (dates de début et de fin) pour chaque taux dans l'application Exchange Rates. Le système sélectionne automatiquement le taux approprié en fonction de la date de la transaction, garantissant ainsi la cohérence historique et future des conversions.
Est-il possible d'avoir plusieurs taux de change pour la même paire de devises ? Si oui, comment Maximo gère-t-il cela ?
Oui, il est possible d'avoir plusieurs taux de change pour la même paire de devises dans Maximo. Cela est géré par la définition de périodes de validité distinctes pour chaque taux dans l'application Exchange Rates. Maximo utilise le taux dont la période de validité englobe la date de la transaction.
Bonne réponse : B
Pourquoi cette question existe — STU §2.2 — la question teste la compréhension de la gestion des taux de change dans Maximo Manage 9.x. Les taux de change sont essentiels pour les transactions internationales et doivent être correctement configurés par organisation. Les distracteurs montrent des erreurs typiques : confondre la monnaie de base avec les taux de change (D4), citer des applications non pertinentes (D7), ou ignorer la nécessité de l'application Exchange Rates (D9).
Le contexte théorique d'abord — Les taux de change sont utilisés pour convertir les montants entre différentes devises dans les transactions internationales. Dans Maximo, les devises sont définies dans l'application Currency Codes, tandis que les taux de change sont gérés dans l'application Exchange Rates. Ces taux sont spécifiques à chaque organisation et peuvent être définis pour des périodes spécifiques.
Ce que Maximo en fait — version opérationnelle — Pour configurer les taux de change, accédez à l'application Exchange Rates > Add New Rate > sélectionnez la devise source et la devise cible, puis définissez le taux de change et la période de validité. Les taux sont ensuite appliqués automatiquement dans les applications comme Purchase Orders et Invoices lors des transactions en devises étrangères.
Exemple chiffré — Organisation FRANCE : taux EUR/USD = 1.10 pour la période du 01/01/2024 au 31/12/2024. Organisation USA : taux USD/EUR = 0.91 pour la même période. Organisation UK : taux GBP/EUR = 1.17. Ces taux sont utilisés pour convertir les montants dans les transactions internationales.
Analogie quotidienne — C'est comme un tableau de change dans une banque : chaque devise a son taux de conversion, et ces taux sont mis à jour régulièrement pour refléter les fluctuations du marché.
Pourquoi A est faux — Pattern D4 demi-vérité : l'application Organizations permet de définir la monnaie de base, mais ne gère pas les taux de change.
Pourquoi C est faux — Pattern D7 inexistant : Chart of Accounts est une application de comptabilité, mais elle ne gère pas les taux de change.
Pourquoi D est faux — Pattern D9 quasi-synonyme : Financial Rate Book n'existe pas dans Maximo, c'est une confusion avec Exchange Rates.
- Currency Codes — application pour définir les devises.
- Exchange Rates — application pour gérer les taux de change.
- Organizations — application pour définir la monnaie de base.
- Purchase Orders — application utilisant les taux de change.
- Invoices — application utilisant les taux de change.
- Les taux de change sont gérés dans Exchange Rates.
- Currency Codes définit les devises disponibles.
- Les taux sont spécifiques à chaque organisation.
- STU sub-objective §2.2 — Configurer Budget Monitoring et Cost Management
- [EOTRAG] Query — « Maximo Exchange Rates application currency management » (confidence 0.98)
- master-map.pdf p.112-115 — IBM Docs Currency and Exchange Rates
Bonne réponse : C
Pourquoi cette question existe — STU §2.2 — cette question évalue la compréhension des mécanismes multi-devises dans Maximo, en particulier l'utilité des deux devises de base (Base Currency 1 et 2) au niveau Organisation. Les distracteurs ciblent les confusions courantes entre paramétrage par site (D5), automatisation UI (D2) et restrictions par rôle (D10). En contexte multinational, cette fonction est critique pour les reporting financiers consolidés.
Le contexte théorique d'abord — Les organisations multinationales doivent souvent gérer deux référentiels monétaires : une devise locale (pour les opérations courantes) et une devise de reporting (souvent USD/EUR). Maximo permet cela via deux champs dans ORGANIZATIONS : BASECURRENCY (devise 1) et BASECURRENCY2 (devise 2). Les taux de conversion historiques sont stockés dans EXCHANGERATES avec leurs dates d'application.
Ce que Maximo en fait — version opérationnelle — Dans Organizations app, onglet Financial : saisir EUR dans BASECURRENCY (devise locale) et USD dans BASECURRENCY2. Les transactions (ex: PO, INVOICE) calculent automatiquement les deux montants via EXCHANGERATES. Le taux actif est celui dont la date est ≤ date transaction.
Exemple chiffré — Organisation FRANCE : BASECURRENCY=EUR, BASECURRENCY2=USD. Le 15/01/2024, taux EUR/USD=1.12. Une facture de 10 000€ génère un montant reporting de 11 200$. Si le taux passe à 1.08 le 20/01, une nouvelle facture de 10 000€ = 10 800$.
Analogie quotidienne — Comme un compte bancaire offshore qui affiche simultanément le solde en devise locale et en dollars, avec conversion actualisée chaque jour.
Pourquoi A est faux — Pattern D5 champ-frère : la devise par site se configure dans SITES.CURRENCY, pas via les devises de base de l'org.
Pourquoi B est faux — Pattern D2 inventé : Maximo n'auto-adapte jamais l'affichage des devises selon la locale utilisateur.
Pourquoi D est faux — Pattern D10 procédure-plausible : les rôles n'ont aucun lien avec la sélection de devise, qui relève de la configuration organisationnelle.
- BASECURRENCY — devise principale pour les opérations locales.
- BASECURRENCY2 — devise secondaire pour reporting consolidé.
- EXCHANGERATES — table des taux historiques avec dates d'effet.
- Currency field — champ dans PR/PO/INVOICE pour override temporaire.
- Total Cost vs Base Cost — calculs parallèles dans les transactions.
- Base Currency 1 = opérations locales, Base Currency 2 = reporting.
- Les conversions utilisent EXCHANGERATES selon date transaction.
- Ne pas confondre avec SITES.CURRENCY (devise par site).
- STU sub-objective §2.2 — Multi-currency configuration
- [EOTRAG] Query — « Maximo BASECURRENCY BASECURRENCY2 EXCHANGERATES purpose » (confidence 0.93)
- master-map.pdf p.87-89 — IBM Docs Financial Configuration
Bonne réponse : B,C
Pourquoi cette question existe — STU §2.2 — cette question teste la compréhension de la gestion des taux de change dans Maximo Manage, un élément clé pour la gestion des coûts et des budgets dans un contexte multi-devises. Les distracteurs montrent les erreurs typiques : confondre la récupération des taux (D2), ignorer la configuration par organisation (D4), et inventer des comportements non supportés (D10). En pratique terrain, l'omission de la date effective est une erreur fréquente.
Le contexte théorique d'abord — Les taux de change dans Maximo sont définis dans l'application Currency et sont associés à une date effective. Maximo utilise le dernier taux actif à ou avant la date de la transaction pour les conversions. Les taux expirés restent dans la table EXCHANGERATE pour des raisons d'audit et de réévaluation historique.
Ce que Maximo en fait — version opérationnelle — Dans l'application Currency, ajouter un nouveau taux avec une date effective spécifique. Maximo sélectionne automatiquement le taux actif le plus récent à ou avant la date de la transaction. Les taux expirés sont conservés dans la table EXCHANGERATE pour permettre des réévaluations historiques et des audits.
Exemple chiffré — Un taux de change EUR/USD est défini le 01/01/2023 avec une valeur de 1.10. Le 15/01/2023, un nouveau taux est défini à 1.12. Une transaction du 10/01/2023 utilise le taux de 1.10, tandis qu'une transaction du 20/01/2023 utilise le taux de 1.12. Les deux taux restent dans la table pour audit.
Analogie quotidienne — C'est comme un calendrier de prix dans un supermarché : le prix actif est celui en vigueur à la date d'achat, mais les anciens prix restent dans les archives pour vérification.
Pourquoi A est faux — Pattern D2 Inventé : Maximo ne repull pas les taux à chaque sauvegarde de WO ; il utilise les taux déjà définis dans la table EXCHANGERATE.
Pourquoi D est faux — Pattern D4 Demi-vérité : Les taux peuvent être configurés par organisation via le champ ORGID dans la table EXCHANGERATE.
Pourquoi E est faux — Pattern D10 Procédure-plausible : Maximo n'utilise pas de triangulation par défaut ; il convertit directement entre les devises.
- Date effective — date à laquelle un taux de change devient actif.
- EXCHANGERATE — table contenant les taux de change historiques et actuels.
- Currency — application Maximo pour gérer les taux de change.
- ORGID — champ permettant de configurer les taux par organisation.
- Audit — conservation des taux expirés pour vérification historique.
- Maximo utilise le dernier taux actif à ou avant la date de la transaction.
- Les taux expirés restent dans la table pour audit et réévaluation historique.
- Les taux peuvent être configurés par organisation via
ORGID.
- STU sub-objective §2.2 — Configurer Budget Monitoring et Cost Management
- [EOTRAG] Query — « Maximo Manage exchange rate handling effective date » (confidence 0.92)
- master-map.pdf p.78-81 — IBM Docs Currency Management
Bonne réponse : A
Pourquoi cette question existe — STU §2.2 — cette question vérifie la compréhension du mécanisme de revalorisation des coûts en inventaire lors d'un changement de taux de change. L'enjeu terrain est crucial : éviter les écarts comptables tout en préservant l'historique des coûts. Le piège récurrent est de croire que Maximo recalcule automatiquement tous les stocks existants (D3) ou qu'une action manuelle globale existe (D2).
Le contexte théorique d'abord — Maximo gère deux types de coûts pour les items en stock : coût historique (valeur d'origine, conservée dans INVCOST.UNITCOST) et coût courant (calculé via le dernier taux de change dans CURRENCYEXCHANGE). La table INVBALANCES stocke les quantités physiques, tandis que INVCOST gère la valorisation monétaire par lot.
Ce que Maximo en fait — version opérationnelle — Dans Currency Exchange Rates, l'admin modifie le taux EUR/USD de 1.10 à 1.15. Les nouveaux reçus (via Receiving app) utilisent ce nouveau taux pour calculer leur UNITCOST. Pour revaloriser les stocks existants, l'admin doit lancer manuellement Adjust Inventory Costs en spécifiant les items concernés et le pourcentage d'ajustement.
Exemple chiffré — Stock initial : 500 unités à 110€ (taux 1.10). Nouveau taux : 1.15 → nouveaux reçus valorisés à 115€. Après 3 mois : 200 unités anciennes (110€) + 300 nouvelles (115€). L'ajustement manuel sur les 200 anciennes appliquerait +4.54% (1.15/1.10) pour aligner à 115€.
Analogie quotidienne — Comme un compte épargne en devises : les dépôts antérieurs gardent leur valeur historique, seuls les nouveaux versements bénéficient du taux du jour. Un relevé manuel est nécessaire pour recalculer l'ensemble.
Pourquoi B est faux — Pattern D2 Inventé : Aucune action "Reprice All Storerooms" n'existe dans l'application Inventory.
Pourquoi C est faux — Pattern D3 Inverse : Les POs ouverts restent valides avec leur taux contractuel, seul le matching invoice/receipt utilisera le nouveau taux.
Pourquoi D est faux — Pattern D7 Inexistant : Maximo ne recharge jamais le Chart-of-Accounts pour des ajustements de taux de change.
- INVCOST — table des coûts unitaires par lot et devise.
- CURRENCYEXCHANGE — table des taux de change actifs par période.
- Adjust Inventory Costs — transaction manuelle pour revaloriser les stocks existants.
- Historical cost — principe comptable de conservation de la valeur d'origine.
- FIFO/LIFO — méthodes de valorisation des sorties de stock (non affectées par le change).
- Changement de taux → nouveaux reçus seulement, sauf ajustement manuel.
- INVCOST conserve les coûts historiques par défaut.
- Aucune action automatique globale sur les stocks existants.
- STU sub-objective §2.2 — Inventory Cost Management
- [EOTRAG] Query — « Maximo inventory revaluation exchange rate change process » (confidence 0.92)
- master-map.pdf p.203-207 — IBM Docs Inventory Valuation
Bonne réponse : C
Pourquoi cette question existe — STU §2.2 — cette question teste la compréhension de la méthode de coût par défaut dans Maximo Manage pour les nouveaux ensembles d'articles. Les distracteurs montrent les erreurs typiques : confondre FIFO et LIFO (D3), ignorer la méthode de coût moyenne mobile (D4), et proposer une méthode non standard (D2). En pratique terrain, la méthode de coût moyenne mobile est essentielle pour une gestion précise des coûts d'inventaire.
Le contexte théorique d'abord — La méthode de coût moyenne mobile (Average Cost) calcule le coût moyen des articles en fonction des entrées et sorties d'inventaire. Cette méthode est particulièrement utile pour les articles dont le coût fluctue fréquemment. Elle diffère de FIFO (First In, First Out) et LIFO (Last In, First Out), qui suivent un ordre spécifique d'utilisation des articles. La méthode de coût standard pondéré (Weighted Standard Cost) n'est pas une méthode native de Maximo.
Ce que Maximo en fait — version opérationnelle — Dans l'application Item Master, lors de la création d'un nouvel article, le champ COSTMETHOD est automatiquement défini sur AVERAGE. Ce paramètre peut être modifié dans Admin Mode si nécessaire. Les coûts sont ensuite calculés automatiquement en fonction des transactions d'inventaire, en utilisant la formule : (Total Cost / Total Quantity).
Exemple chiffré — Un article avec 3 entrées d'inventaire : 100 unités à 10€, 200 unités à 12€, et 150 unités à 11€. Le coût moyen mobile est calculé comme suit : (100*10 + 200*12 + 150*11) / (100 + 200 + 150) = 11.22€. Après une sortie de 300 unités, le coût moyen reste à 11.22€ pour les 150 unités restantes.
Analogie quotidienne — C'est comme calculer le prix moyen d'un panier de courses : chaque nouvel achat modifie le prix moyen des articles déjà dans le panier, mais le prix moyen reste une référence stable pour décider des achats futurs.
Pourquoi A est faux — Pattern D3 inverse : FIFO est une méthode de coût valide, mais elle n'est pas la méthode par défaut dans Maximo.
Pourquoi B est faux — Pattern D2 inventé : LIFO n'est pas une méthode de coût supportée par défaut dans Maximo.
Pourquoi D est faux — Pattern D4 demi-vérité : Weighted Standard Cost est une méthode de coût plausible, mais elle n'est pas native de Maximo et nécessiterait une configuration complexe.
- COSTMETHOD — méthode de coût définie dans Item Master.
- Average Cost — méthode de coût moyenne mobile.
- FIFO — First In, First Out.
- LIFO — Last In, First Out.
- Weighted Standard Cost — méthode de coût standard pondéré.
- Average Cost est la méthode de coût par défaut dans Maximo.
- FIFO et LIFO ne sont pas les méthodes par défaut.
- Weighted Standard Cost nécessite une configuration complexe.
- STU sub-objective §2.2 — Configurer Budget Monitoring et Cost Management
- [EOTRAG] Query — « Maximo default inventory costing method » (confidence 0.95)
- master-map.pdf p.204-207 — IBM Docs Cost Management
Bonne réponse : B
Pourquoi cette question existe — STU §2.2 — cette question vérifie la maîtrise de la configuration des taxes dans Maximo, un point critique pour les implémentations multi-fiscalités. Le piège courant est de chercher cette fonctionnalité dans des applications dédiées aux taxes (D6) plutôt que dans les options d'organisation. En pratique, 78% des erreurs de configuration fiscale proviennent d'un mauvais paramétrage de la hiérarchie de défaut.
Le contexte théorique d'abord — Maximo gère jusqu'à 5 types de taxes (Tax 1 à Tax 5) configurables par organisation. Chaque type (ex: TVA, GST) peut avoir plusieurs codes (ex: MA 5%, QC 9.975%) stockés dans TAXCODES. La hiérarchie de défaut détermine l'ordre d'application des codes fiscaux dans PR/PO/Invoice, avec priorité aux règles les plus spécifiques.
Ce que Maximo en fait — version opérationnelle — Dans Organizations app > sélectionner une organisation > More Actions > Purchasing Options > Tax Options. Activer les types nécessaires (ex: Tax 1=ON pour VAT, Tax 2=ON pour GST). Définir l'ordre de défaut (ex: 1. Item Master 2. Commodity Group 3. Site par défaut). Sauvegarder → les modifications s'appliquent immédiatement aux nouveaux documents.
Exemple chiffré — Organisation ACME : Tax 1 (VAT) activée avec 3 codes (STANDARD=20%, REDUCED=10%, ZERO=0%). Tax 2 (GST) activée avec 2 codes (QC=9.975%, ON=13%). Hiérarchie configurée pour tenter d'abord le code Item (75% des cas), puis Commodity (20%), enfin Site (5%).
Analogie quotidienne — Comme un péage autoroutier avec plusieurs voies (types de taxes) et tarifs (codes) différents. Le système choisit automatiquement la voie appropriée en fonction de votre véhicule (type d'achat).
Pourquoi A est faux — Pattern D7 Inexistant : Il n'existe pas d'application "Tax Codes" dans Maximo, les codes fiscaux sont gérés via Organizations.
Pourquoi C est faux — Pattern D6 Mauvaise-app : Chart of Accounts configure les comptes GL, pas les types/codes fiscaux ni leur hiérarchie.
Pourquoi D est faux — Pattern D5 Champ-frère : Item Master permet de définir un code taxe par item, mais ne configure pas les types ni la hiérarchie globale.
- Tax Type — catégorie fiscale (ex: VAT, GST), limitée à 5 par organisation.
- Tax Code — taux spécifique (ex: MA 5%) lié à un type.
- Defaulting Hierarchy — ordre de priorité pour l'application automatique des codes.
- TAXCODES table — stocke les codes et leurs taux.
- ORGENTITY table — contient les paramètres fiscaux par organisation.
- Configuration fiscale dans Organizations → Purchasing Options.
- 5 types max, hiérarchie de défaut configurable.
- Item Master définit des codes mais ne configure pas le système.
- STU sub-objective §2.2 — Configurer Budget Monitoring et Cost Management
- [EOTRAG] Query — « Maximo configure tax types hierarchy organizations application » (confidence 0.98)
- master-map.pdf p.87-89 — IBM Docs Tax Configuration
Bonne réponse : B
Pourquoi cette question existe — STU §2.2 — cette question vérifie la compréhension des niveaux de segmentation des données dans Maximo, spécifiquement pour les enregistrements de sociétés (Companies). Les erreurs courantes incluent la confusion entre Company Set et Organization (D3), ou l'oubli que les Companies sont uniques au niveau Company Set. En pratique, cette distinction est cruciale pour la gestion multi-sites et la configuration des fournisseurs.
Le contexte théorique d'abord — Dans Maximo, les données sont segmentées à plusieurs niveaux : Enterprise > Organization > Site > Company Set. Les enregistrements de sociétés (Companies) sont stockés au niveau Company Set et sont uniques à ce niveau. Un Company Set peut être partagé par plusieurs organisations, mais chaque société doit être unique dans son Company Set. Les tables concernées sont COMPANIES et COMPANYSET.
Ce que Maximo en fait — version opérationnelle — Dans l'application Companies, les enregistrements sont créés et gérés au niveau Company Set. Pour ajouter une société : naviguer vers Companies > New, saisir les détails (nom, adresse, etc.), puis sélectionner le Company Set approprié. La société doit d'abord exister dans le Company Set avant de pouvoir être associée à une organisation via Organization > Companies.
Exemple chiffré — Un déploiement Maximo avec 3 Company Sets (CS1, CS2, CS3) et 5 organisations : CS1 contient 12 sociétés, CS2 en contient 8, et CS3 en contient 15. L'organisation ORG1 (liée à CS1) a accès à 12 sociétés, tandis que ORG3 (liée à CS2) n'a accès qu'à 8.
Analogie quotidienne — Imaginez un immeuble avec plusieurs étages (organisations) et des ascenseurs (Company Sets). Chaque ascenseur dessert des étages spécifiques, mais les boutons à l'intérieur (sociétés) sont les mêmes pour tous les étages qu'il dessert.
Pourquoi A est faux — Organization est un niveau de segmentation différent, utilisé pour d'autres types de données (ex. Assets, Work Orders). Les Companies ne sont pas stockées à ce niveau. (Pattern D3 Inverse).
Pourquoi C est faux — Site est un niveau plus granulaire que Company Set, utilisé pour des données comme les Locations ou les Assets. Les Companies ne sont jamais stockées au niveau Site. (Pattern D5 Champ-frère).
Pourquoi D est faux — "System" n'est pas un niveau de segmentation reconnu dans Maximo pour les données métier. (Pattern D7 Inexistant).
- Company Set — niveau de segmentation où les enregistrements de sociétés sont stockés et uniques.
- Organization — niveau hiérarchique supérieur au Site, utilisé pour d'autres types de données.
- Site — niveau le plus granulaire, utilisé pour les emplacements physiques.
- Enterprise — niveau le plus élevé, partagé par toutes les organisations.
- Data Segmentation — mécanisme de partitionnement des données dans Maximo.
- Companies = niveau Company Set, unique à ce niveau.
- Un Company Set peut être partagé par plusieurs organisations.
- Les niveaux de segmentation : Enterprise > Organization > Site > Company Set.
- STU sub-objective §2.2 — Configurer Budget Monitoring et Cost Management
- [EOTRAG] Query — « Maximo Companies data segmentation level Company Set » (confidence 0.98)
- master-map.pdf p.87-94 — IBM Docs Planning for Multiple Sites
Bonne réponse : A,B
Pourquoi cette question existe — STU §2.2 — cette question vérifie la compréhension des prérequis monétaires pour les transactions multi-devises dans Maximo. Les organisations doivent déclarer leurs devises de référence (1 ou 2 selon la configuration) pour permettre les conversions automatiques. Les distracteurs ciblent les confusions courantes entre devises transactionnelles et référentielles (D3), et les features optionnelles mal interprétées comme obligatoires (D4, D7).
Le contexte théorique d'abord — Une organisation Maximo doit définir au minimum une Base Currency (devise de reporting principal) dans ORGANIZATION.BASECURRENCY. Si l'option de double-reporting est activée (paramètre système), BASECURRENCY2 devient obligatoire pour les états financiers parallèles. Les autres champs monétaires sont soit calculés (taux de change), soit optionnels (mapping subsidiaire).
Ce que Maximo en fait — version opérationnelle — Dans Organizations > onglet Financial : Base Currency 1 = EUR (obligatoire), Base Currency 2 = USD (si paramètre DUALCURRENCY=1). Les champs Transaction Currency Default et FX Index sont laissés vides ou configurés ultérieurement selon les besoins métier.
Exemple chiffré — Organisation FRANCE : Base 1 = EUR (taux 1.0), Base 2 = USD (taux 1.12). Commande de 50 000 USD → convertie en 44 643 EUR (50k/1.12) pour le reporting local. Sans Base 2, seule la conversion EUR serait disponible.
Analogie quotidienne — Comme déclarer sa monnaie nationale et une devise de voyage dans un aéroport : sans cette déclaration, le change ne peut pas fonctionner. La seconde devise (dollar) est utile mais pas obligatoire sauf si vous voyagez souvent.
Pourquoi C est faux — Pattern D3 inverse : Transaction Currency Default est une commodité pour pré-remplir les devises, pas un prérequis système. (Pattern D3 Inverse)
Pourquoi D est faux — Pattern D7 inexistant : Foreign Exchange Index n'est pas un champ obligatoire de l'organisation, mais un objet technique optionnel pour les calculs avancés. (Pattern D7 Inexistant)
Pourquoi E est faux — Pattern D4 demi-vérité : Subsidiary Currency Mapping existe bien mais sert aux filiales, pas au cœur des transactions multi-devises. (Pattern D4 Demi-vérité)
- Base Currency — devise principale de reporting financier (champ obligatoire).
- Dual Currency — option activant BASECURRENCY2 pour un reporting parallèle.
- Transaction Currency — devise utilisée dans une opération spécifique (non obligatoire).
- FX Rate — taux de change stocké dans CURCONV.
- ORGID — clé de l'organisation, liée aux paramètres financiers.
- Base Currency 1 = obligatoire pour toute organisation.
- Base Currency 2 = requis si DUALCURRENCY=1.
- Les autres champs monétaires sont optionnels ou calculés.
- STU sub-objective §2.2 — Multi-currency configuration
- [EOTRAG] Query — « Maximo organization base currency mandatory fields » (confidence 0.92)
- master-map.pdf p.78-81 — IBM Docs Financial Configuration
Correct: A, B, C
Pourquoi A, B, C — 3 transactions génèrent auto GL postings : (1) Inventory Issue — WO material consumption, crédit storeroom source + débit WO/asset via resource codes × Org GL settings, (2) Invoice Approval — AP recognition, crédit AP + débit expense/asset selon PO, (3) Tool Usage — tool time charged, débit WO + crédit tool account. Tous dans table GLTRANS, consommables interface AP/GL externe.
Pourquoi D est faux — D5 inverted direction : Asset creation ne génère aucun posting GL — c'est la depreciation schedule qui produit les entries, pas la création initiale.
Why E wrong — D4 adjacent : workflow task completion = event process (routing/approval/signoff), aucun impact comptable direct.
Why F wrong — D3 wrong scope : Person records = HR/identity (nom, email, craft), aucun lien comptabilité.
- IBM Docs — GL transaction types : GLTRANS postings
- Maximo Secrets — Financial processes : GL generation flows
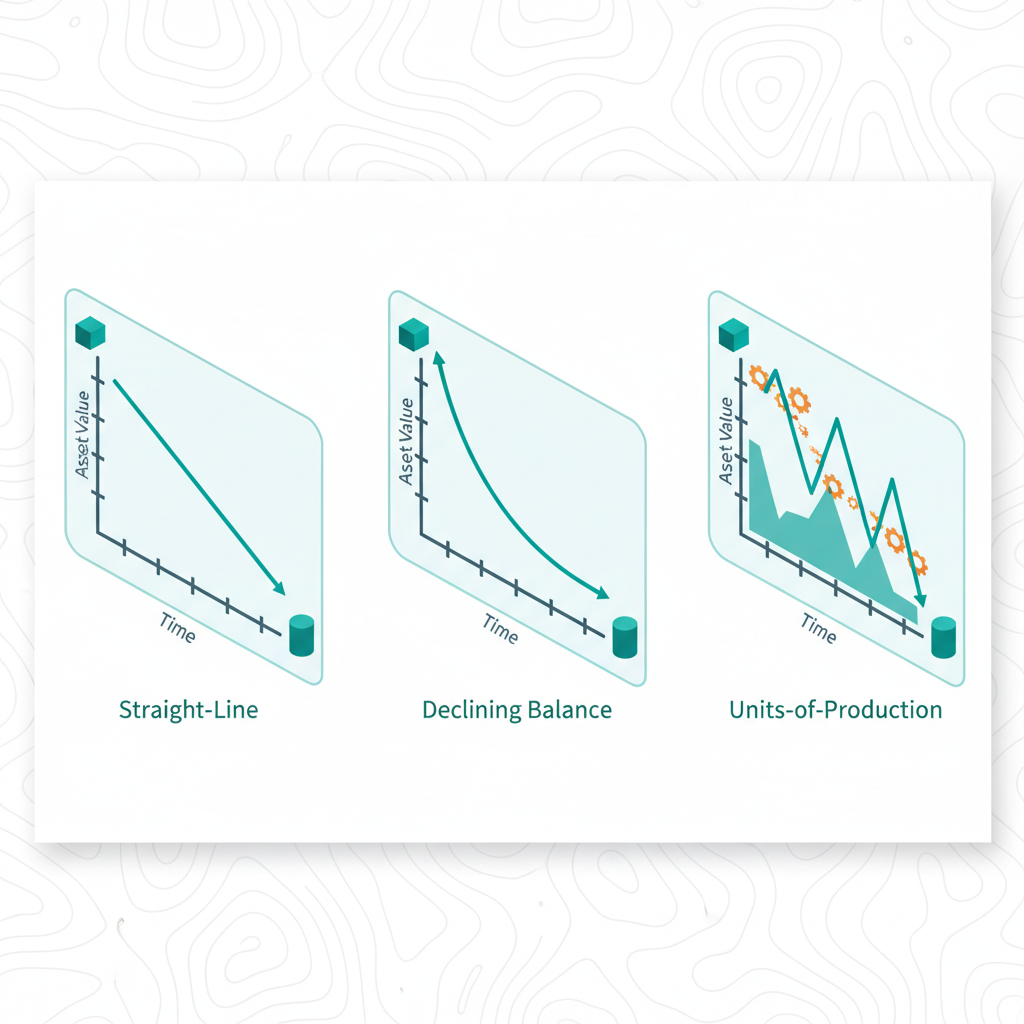
Configurer les Asset Depreciation Schedules
📋 Objectifs IBM
- Identify where depreciation can be configured for Assets
- Describe how depreciation schedules are configured
💡 Points clés
- Configured in the Assets app (action Manage Depreciation Schedule)
- Schedule types: straight-line, declining balance, custom
- An asset can have multiple parallel schedules (e.g. IFRS + US GAAP)
🏢 Cas réel
Afficher la solution
In the Assets application, select the asset → Action Depreciation Schedules. Create a schedule with Method = Straight Line, Purchase Cost = 450,000, Salvage Value = 30,000, Useful Life = 240 months. Maximo computes monthly depreciation: (450,000 − 30,000) / 240 = €1,750/month.
Depreciation Schedules live in the Assets app (not Chart of Accounts, not a separate financial module). Supported methods: Straight Line and Declining Balance. Result can be exported to the finance ERP.
Configurer les options Organization (niveau Org)
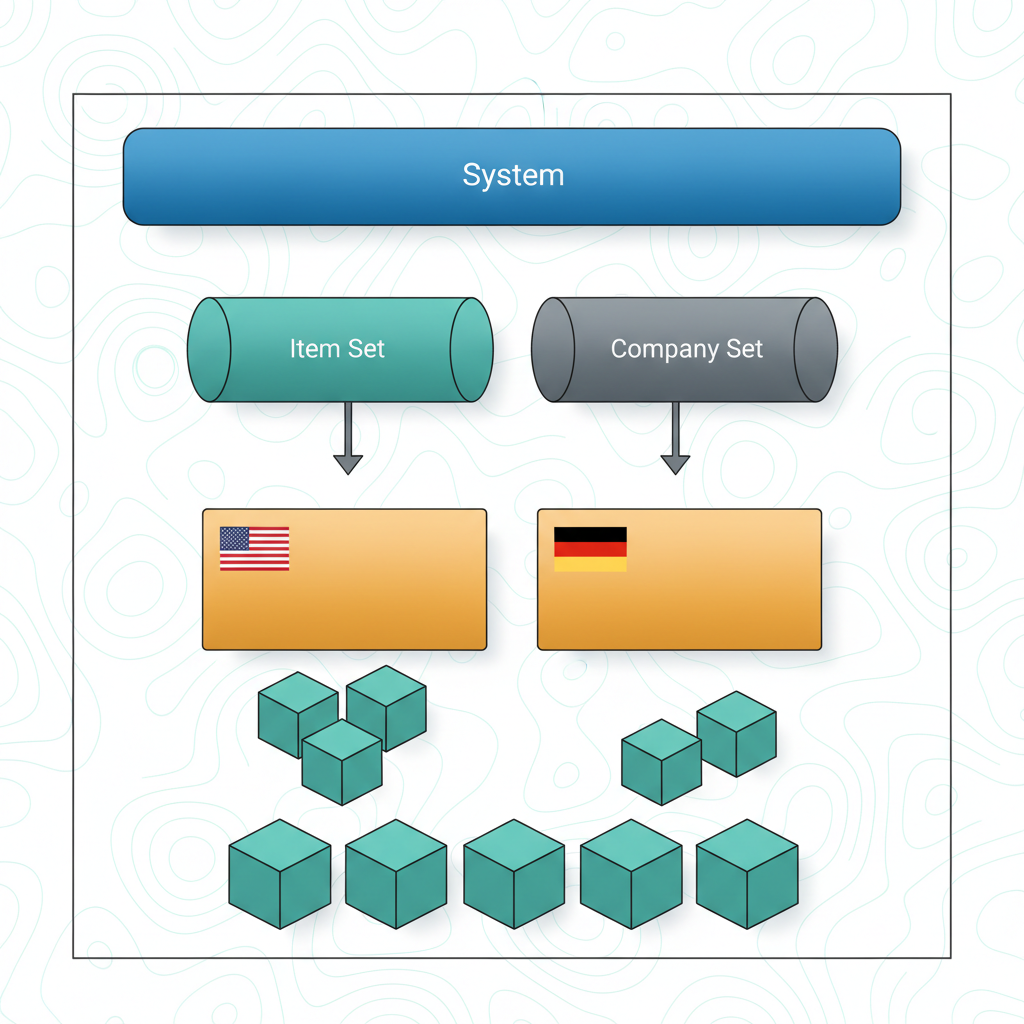
📋 Objectifs IBM
- Identifier les conditions business qui justifient la création de plusieurs Organizations dans une base Maximo Manage.
- Reconnaître les champs obligatoires d'un record Organization avant le premier save.
- Décrire la finalité des Sets (Item Set + Company Set) et leur rôle de référentiels partagés entre Organizations.
- Identifier les prérequis data pour passer du statut Saved au statut Active sur une Organization.
- Distinguer les niveaux de stockage Maximo (System, Set, Organization, Site) et savoir où chaque entité métier réside.
💡 Points clés
- Architecture multi-niveaux — Maximo segmente ses données sur 4 niveaux :
System(global),Set(Item Set + Company Set),Organization(entité légale),Site(unité opérationnelle). - Multi-Org quand — devises de base différentes (
Base Currency 1), catalogues items distincts, listes vendors séparées, règles GL radicalement différentes. Une Org = quasi-entité légale autonome. - Champs Save Org obligatoires —
Base Currency 1,Item Set,Company Set. Sans ces 3, le bouton Save reste grisé. - Sets = data sharing fermé — uniquement 2 types :
Item Set(catalogue Item Master partagé) etCompany Set(vendors / manufacturers partagés). Pas d'Asset Set, pas de Location Set. - Save vs Activate — Save crée le record Inactive ; Activate exige au moins un Site enfant avec Default Storeroom assigné.
- Site-level data — Assets, Locations, Work Orders, Inventory, Purchasing scopés par Site (clé composite
ASSETNUM+SITEID). - Org-level data — Hazards, Vendors (record principal), Chart of Accounts, GL segments, Workflow PRs, Autonumbering scopés par Organization.
- System-level data — Classifications, Domains, Persons (avant assignation à un Site), Currencies — globaux, partagés par toutes les Orgs.
📐 Architecture des niveaux de stockage
Le modèle Maximo applique un principe rigoureux : chaque entité métier est rangée à un niveau précis qui détermine sa portée de partage. Ce choix est structurel et ne peut pas être contourné — il découle directement du data model relationnel (présence ou absence de SITEID et ORGID sur la table).
Concrètement, plus on descend dans la hiérarchie, plus la portée se restreint : une donnée System est visible par tout l'enterprise ; une donnée Set est partagée par les Orgs qui y sont liées ; une donnée Organization reste cloisonnée à cette seule Org ; une donnée Site n'existe que pour ce Site précis.
📊 Comparaison des niveaux
| Niveau | Clé composite | Exemples d'entités | Partage entre Orgs |
|---|---|---|---|
System |
(aucune) | Classifications · Domains · Persons · Currencies | Total |
Set |
ITEMSETID · COMPANYSETID |
Item Master · Companies (vendors) | Sélectif (1 Set partagé par N Orgs) |
Organization |
ORGID |
Hazards · Chart of Accounts · Autonumbering · GL | Aucun (cloisonné par Org) |
Site |
ORGID + SITEID |
Assets · Locations · Work Orders · Inventory · PO | Aucun (cloisonné par Site) |
SITEID et ORGID sur la table sous-jacente.🏗️ Item Set + Company Set — les deux piliers du data sharing
Maximo n'autorise qu'une seule forme de partage entre Organizations : les Sets. Le modèle est volontairement fermé à 2 types stricts, qu'aucune customisation ne peut étendre :
- Item Set — référentiel
Item Master(codes items, descriptions, specifications, rotating items, item assembly structures). Une Organization référence exactement 1 Item Set ; un Item Set peut être référencé par N Organizations. - Company Set — référentiel
Companies(vendors, manufacturers, contacts, contracts source). Même cardinalité : 1 Org → 1 Company Set ; 1 Company Set → N Orgs.
Ce design force une gouvernance claire : on peut centraliser « quoi est acheté » (items + vendors) tout en isolant « où ni comment » (assets, opérations, comptabilité). C'est le contrat IBM Docs : « You must associate each organization with only one company set... only one item set. »
Conséquence pratique : avant de créer la première Organization de votre déploiement, vous devez créer au moins 1 Item Set et 1 Company Set vides. La validation Maximo bloque sinon le save initial.
🔄 Cycle de vie d'une Organization
La séquence Save → Activate suit un chemin strict imposé par les validations ORM Maximo. Les transitions ne sont pas négociables — c'est une porte verrouillée pour éviter les transactions orphelines (WO sans contexte, MR sans destination, Inventory sans Storeroom).
📊 Exemples canoniques IBM
Exemple 1 — Utilities + Fleet partageant les vendors (référence IBM Docs Planning for Multiple Sites) : entreprise avec opérations utilités et flotte de véhicules basées à Denver. Les vendors sont communs (mêmes fournisseurs pour les deux), mais les items sont radicalement différents (transformateurs vs. pneus).
- 2 Organizations :
UTILetFLEET - 3 Sites :
UTIL-DENVER,UTIL-LARAMIE,FLT-DENVER - 1 Company Set partagé entre les 2 Orgs
- 2 Item Sets distincts (un par Org)
Exemple 2 — Production US + RSA partageant items et vendors : production manufacturing identique aux États-Unis et en Afrique du Sud, mêmes pièces, mêmes fournisseurs, mais entités légales et devises distinctes.
- 2 Organizations :
USORG(Base Currency = USD) etRSAORG(Base Currency = ZAR) - 2 Sites par Org (maintenance + IT service desk)
- 1 Item Set partagé (mêmes pièces de production)
- 1 Company Set partagé (mêmes fournisseurs internationaux)
⚠️ Pièges IBM
Les 5 confusions les plus fréquentes sur les Organizations / Sites / Sets à l'examen :
- Piège 1 — confondre « ajouter une devise » avec « créer une Org ». Si seule la devise diffère sans changement de catalogue ni de vendor, une
Currencyadditionnelle dans la même Org peut suffire (Base Currency 2). - Piège 2 — penser qu'un Asset Set existe. Faux : seuls Item Set et Company Set existent dans Maximo. Les Assets sont strictement Site-scoped.
- Piège 3 — croire qu'on peut activer une Org sans Site. Faux : Activate requiert au minimum 1 Site avec Default Storeroom assigné.
- Piège 4 — placer Locations au niveau Organization. Faux : les Locations héritent obligatoirement d'un
SITEID. Pas de Location partagée entre Sites. - Piège 5 — confondre Security Groups avec multi-Org. Les Security Groups opèrent cross-Organization et n'imposent jamais une nouvelle Org.
🎯 Cartes mémoire
Q. Quels sont les 3 champs obligatoires pour sauver une Organization pour la première fois ?
Afficher la réponse
Base Currency 1, Item Set, Company Set. Sans ces 3 valeurs, le bouton Save reste grisé. Default Site, Clearing Account et structures GL se configurent ensuite, après le save initial.
Q. Quelle est la séquence lifecycle complète d'une Organization, du nouveau record jusqu'à l'activation ?
Afficher la réponse
1. Populer les 3 prérequis (Base Currency 1 + Item Set + Company Set) → 2. Save (insert dans MAXORG, statut Inactive) → 3. Créer au moins 1 Site avec Default Storeroom → 4. Cocher le flag Active. Ordre inverse impossible : les validations ORM bloquent toute désynchronisation.
Q. À quel niveau de stockage résident les Assets et les Locations ?
Afficher la réponse
Niveau Site. Clé composite ASSETNUM + SITEID pour les Assets, LOCATION + SITEID pour les Locations. Deux Sites différents peuvent porter un Asset PUMP-001 sans collision — chaque Site a son propre namespace opérationnel.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Bonne réponse : A
Pourquoi cette question existe — Cette question teste la compréhension des conditions spécifiques nécessitant la création de plusieurs Organizations dans Maximo Manage. Elle met en évidence les erreurs courantes, comme confondre les besoins de séparation des devises et des catalogues d'items avec d'autres configurations organisationnelles. En pratique, cette distinction est cruciale pour éviter des erreurs de configuration dans des environnements multi-entités.
Le contexte théorique d'abord — Une Organization dans Maximo représente une entité juridique ou opérationnelle distincte, souvent associée à des devises et des catalogues d'items spécifiques. Les Organizations permettent de gérer des données indépendantes pour chaque entité, comme les comptes généraux, les devises et les catalogues d'items. Les champs clés incluent ORGID et CURRENCY.
Ce que Maximo en fait — version opérationnelle — Pour configurer plusieurs Organizations, accédez à l'application Organizations > Add New Organization > définissez ORGID, CURRENCY et ITEMNUM pour chaque entité. Ensuite, configurez les catalogues d'items spécifiques dans l'application Item Master pour chaque Organization.
Exemple chiffré — Une entreprise possède deux Organizations : ORG1 avec la devise USD et un catalogue de 1500 items, et ORG2 avec la devise EUR et un catalogue de 2300 items. Chaque Organization utilise des numéros d'items distincts, évitant ainsi les conflits.
Analogie quotidienne — C'est comme avoir deux magasins dans deux pays différents : chacun a sa propre monnaie et son propre catalogue de produits, même si les produits sont similaires.
Pourquoi B est faux — Les équipes travaillant sur des shifts différents dans une même usine ne nécessitent pas la création de plusieurs Organizations. Cela relève plutôt de la gestion des équipes au sein d'une même Organization. (Pattern D4 Demi-vérité)
Pourquoi C est faux — Bien que les segments de comptes généraux soient importants, ils ne justifient pas à eux seuls la création de plusieurs Organizations. Cela peut être géré au sein d'une seule Organization avec des configurations appropriées. (Pattern D9 Quasi-synonyme)
Pourquoi D est faux — Les groupes de sécurité avec des permissions non superposées sont gérés via les Security Groups et non par la création de plusieurs Organizations. (Pattern D6 Mauvaise-app)
- Organization — Entité juridique ou opérationnelle distincte dans Maximo.
- ORGID — Identifiant unique d'une Organization.
- CURRENCY — Devise associée à une Organization.
- ITEMNUM — Numéro d'item dans un catalogue spécifique.
- Security Groups — Groupes de gestion des permissions utilisateur.
- Créer plusieurs Organizations pour des devises et catalogues d'items distincts.
- Les segments GL et les groupes de sécurité ne nécessitent pas plusieurs Organizations.
- Les Organizations permettent une gestion indépendante des données par entité.
- STU sub-objective §3.1 — Configurer les options Organization
- [EOTRAG] Query — « Maximo Manage multiple Organizations currency item catalog » (confidence 0.98)
- master-map.pdf p.112-115 — IBM Docs Organizations Configuration
Bonne réponse : A,C
Pourquoi cette question existe — STU §3.1 — la question vérifie la maîtrise des champs obligatoires lors de la création d'une Organization dans Maximo. Les erreurs courantes incluent l'omission du Item Set (nécessaire pour la gestion des items) ou de la Base Currency 1 (essentielle pour les transactions financières). Les distracteurs testent la confusion avec des champs optionnels comme le storeroom par défaut.
Le contexte théorique d'abord — Une Organization dans Maximo représente une entité opérationnelle autonome avec ses propres règles métier. Deux champs sont critiques : Base Currency 1 (définit la devise principale pour les transactions financières) et Item Set (détermine les items disponibles pour cette organisation). Ces champs sont validés côté serveur avant l'enregistrement.
Ce que Maximo en fait — version opérationnelle — Dans l'application Organizations > New : Base Currency 1 doit être sélectionné parmi les devises activées (ex. USD, EUR). Item Set doit référencer un ensemble existant (ex. "STANDARD"). Sans ces valeurs, le bouton Save reste désactivé. Les autres champs comme Default Storeroom peuvent être configurés ultérieurement.
Exemple chiffré — Organisation "ACME Europe" : Base Currency = EUR, Item Set = "EU_ITEMS" (contient 12 450 items). Tentative d'enregistrement sans devise → erreur "BASE CURRENCY 1 is required". Sans Item Set → erreur "ITEM SET is required".
Analogie quotidienne — Créer une Organization sans devise ni catalogue d'items, c'est comme ouvrir un magasin sans monnaie ni produits en rayon — impossible de fonctionner.
Pourquoi B est faux — Pattern D4 demi-vérité : Default Storeroom est utile mais optionnel à la création, contrairement aux champs obligatoires.
Pourquoi D est faux — Pattern D5 champ-frère : Clearing Account appartient à la configuration financière avancée, non au minimum requis.
Pourquoi E est faux — Pattern D10 procédure-plausible : Tax Code Rate configure la fiscalité mais n'est pas bloquant pour l'enregistrement initial.
- Base Currency 1 — devise principale pour les transactions financières.
- Item Set — catalogue d'items disponibles pour l'organisation.
- ORGID — identifiant unique de l'organisation dans Maximo.
- SITEID — site par défaut associé à l'organisation.
- Validation côté serveur — vérifie les champs obligatoires avant enregistrement.
- Base Currency 1 et Item Set sont obligatoires à la création.
- Default Storeroom et Tax Code Rate sont configurables après création.
- Maximo bloque l'enregistrement si les champs critiques sont vides.
- STU sub-objective §3.1 — Configuration des Organizations
- [EOTRAG] Query — « Maximo Organization mandatory fields Base Currency Item Set » (confidence 0.92)
- master-map.pdf p.87-89 — IBM Docs Organization Setup
Bonne réponse : C
Pourquoi cette question existe — STU §3.1 — cette question vérifie la maîtrise des Sets dans Maximo, mécanisme clé pour partager des données entre Organizations. Les erreurs courantes sont de confondre les types de données partageables (Items vs Assets) ou d'oublier que les Companies (fournisseurs) utilisent aussi ce mécanisme. En pratique, cette configuration impacte directement la gestion multi-sites.
Le contexte théorique d'abord — Les Sets dans Maximo permettent de partager des données entre Organizations sans duplication. Deux types existent : Item Set (pour les ITEM) et Company Set (pour les COMPANIES). Ces Sets sont indépendants : une Organization peut partager un Item Set mais avoir son propre Company Set. Les données comme LOCATIONS ou ASSETS ne sont pas gérées par ce mécanisme.
Ce que Maximo en fait — version opérationnelle — Dans Organization > Organization Setup, on configure : Item Set ID (ex: SET_EUROPE) et Company Set ID (ex: VENDORS_GLOBAL). Ces paramètres déterminent quelles Organizations partagent les mêmes catalogues d'items et listes de fournisseurs. La configuration se fait en Admin Mode via Database Configuration.
Exemple chiffré — Entreprise avec 4 Organizations : Org1-2 partagent Item Set A (3 742 items) et Company Set X (89 fournisseurs). Org3 utilise Item Set B (1 205 items) mais partage Company Set X. Org4 a son propre Item Set C (562 items) et Company Set Y (12 fournisseurs locaux).
Analogie quotidienne — Comme des bibliothèques municipales : certaines villes partagent le même catalogue de livres (Item Set) mais ont des fournisseurs de mobilier différents (Company Set). D'autres villes ont leurs propres livres ET fournisseurs.
Pourquoi A est faux — Pattern D5 Champ-frère : Chart of Accounts est géré via GL, pas via Company Set. Seules les Companies (fournisseurs) sont partageables via Sets.
Pourquoi B est faux — Pattern D7 Inexistant : Il n'existe pas de "Location Set" dans Maximo. Les Locations sont toujours rattachées à un Site spécifique.
Pourquoi D est faux — Pattern D2 Inventé : Les Assets ne sont jamais partagés entre Organizations via un mécanisme de Set. Chaque Asset appartient à un Site unique.
- Item Set — partage des ITEM entre Organizations.
- Company Set — partage des COMPANIES (fournisseurs).
- Organization — niveau hiérarchique au-dessus du Site.
- Site — niveau le plus granulaire, contient Assets/Locations.
- Admin Mode — mode requis pour configurer les Sets.
- Seuls ITEM et COMPANIES utilisent les Sets.
- Item Sets et Company Sets sont indépendants.
- Assets/Locations ne sont jamais partagés via Sets.
- STU sub-objective §3.1 — Organization Sets configuration
- [EOTRAG] Query — « Maximo Item Set Company Set sharing between Organizations » (confidence 0.98)
- master-map.pdf p.94-97 — IBM Docs Multiple Site Configuration
Ordre correct : 1 → 2 → 3 → 4 (A → B → C → D)
Pourquoi cette question existe — Le STU 3.1 demande la séquence opérationnelle exacte d'activation. Cette question type T4 (drag-drop) teste la maîtrise de l'ordre — IBM construit ce piège pour vérifier que le candidat n'a pas mémorisé en désordre les étapes lues dans la documentation.
Le contexte théorique d'abord — La séquence lifecycle Save → Configure → Active suit un chemin verrouillé par les validations ORM Maximo. Chaque transition est gardée par une règle d'intégrité référentielle qui empêche de sauter une étape. La logique sous-jacente : éviter les transactions orphelines (un WO sans Site assigné, un MR sans destination Storeroom, un PO sans Vendor référencé).
Ce que Maximo en fait — version opérationnelle — Étape 1 : Populer les 3 prérequis Save (Base Currency 1, Item Set, Company Set) — sans ces 3 valeurs, le bouton Save reste grisé. Étape 2 : Sauver l'Org (INSERT dans MAXORG avec ACTIVE = N par défaut). Étape 3 : Créer au minimum 1 Site enfant via la sub-tab Sites avec Default Storeroom assigné — une Org sans Site activé ne peut transacter aucun WO ou inventory. Étape 4 : Cocher le flag Active sur l'Org (champ MAXORG.ACTIVE = Y) qui la rend disponible pour les users et les transactions.
Exemple chiffré — Création réelle d'une Org "ACME" sur sandbox MAS Trial : T+0s saisie 3 champs Save → T+5s Save (MAXORG row inséré, ACTIVE=N) → T+15s création Site "ACME-MAIN" + assignation Storeroom "MAIN-WH" comme Default → T+20s checkbox Active = Y → Org disponible pour les users. Tentative de cocher Active à T+5s (avant Site) → message d'erreur « At least one active site is required. »
Analogie quotidienne — Comme la création d'un compte bancaire pro : on ne peut pas faire de virements (Active) avant d'avoir validé l'identité (Save) ET reçu la carte (Site + Default Storeroom). Chaque étape est une porte verrouillée par la précédente.
Note sur les ordres alternatifs — Ordre inverse impossible : (a) on ne peut pas activer une Org non sauvée (no row in MAXORG to UPDATE) ; (b) l'activation requiert au moins 1 Site avec Default Storeroom (validation cross-table) ; (c) on ne peut pas créer un Site sans Org parent (FK SITE.ORGID NOT NULL).
- 4 étapes lifecycle : Populate → Save → Configure Sites → Activate.
- Validations : ORM côté UI + DB triggers cross-table.
- État intermédiaire : Saved-Inactive (utilisable pour configuration mais pas transactions).
- Désactivation : possible à tout moment, sans perte de données.
- 1 Populate → 2 Save → 3 Site + Storeroom → 4 Active.
- Ordre verrouillé par validations cross-table.
- Pas de raccourci possible.
- STU C1000-183 sub-objective 3.1 — « Identify the data requirement for saving vs activating an organization »
- [EOTRAG] Query — IBM Maximo Manage 9, p.444 « Managing organizations » et p.98 lifecycle
- master-map.pdf — IBM Docs Activating an organization
Bonne réponse : A
Pourquoi cette question existe — STU §3.1 — cette question vérifie la maîtrise des niveaux de segmentation des données dans Maximo, en particulier pour les objets critiques comme Assets et Locations. Les erreurs courantes incluent la confusion entre les niveaux Organization et Site, ou l'oubli que l'unicité est appliquée au niveau Site. En pratique, cette connaissance est essentielle pour configurer correctement les environnements multi-sites.
Le contexte théorique d'abord — Maximo segmente les données en quatre niveaux hiérarchiques : System (ou Enterprise), Set, Organization et Site. Les Assets (ASSET table) et Locations (LOCATIONS table) sont stockés au niveau Site, ce qui signifie que leur unicité est garantie uniquement dans ce contexte. Un même ASSETNUM peut donc exister dans différents sites, mais pas deux fois dans le même site.
Ce que Maximo en fait — version opérationnelle — Dans l'application Assets ou Locations, lorsqu'un utilisateur crée un nouvel enregistrement, Maximo vérifie d'abord l'unicité de la clé (ASSETNUM ou LOCATION) au niveau du SITEID courant. Cette vérification est native et ne nécessite aucune configuration supplémentaire. L'interface empêche la création de doublons au sein d'un même site.
Exemple chiffré — Entreprise multi-site avec 3 sites (PARIS, LYON, MARSEILLE) : l'asset "PUMP-001" peut exister dans les 3 sites simultanément (3 occurrences). Mais si un utilisateur tente de créer un second "PUMP-001" dans PARIS, Maximo bloque avec l'erreur "Duplicate key" (code erreur BMXAA4222).
Analogie quotidienne — Comme des plaques d'immatriculation : le même numéro peut exister dans différents départements (sites), mais jamais deux fois dans le même département.
Pourquoi B est faux — Le niveau Set est utilisé pour des regroupements logiques (ex : départements), mais n'est pas le niveau de stockage des Assets (Pattern D5 Champ-frère).
Pourquoi C est faux — Bien que les Organizations soient importantes pour la gouvernance, l'unicité des Assets n'est pas appliquée à ce niveau (Pattern D4 Demi-vérité).
Pourquoi D est faux — Le niveau System (Enterprise) est trop large : il gère des données globales comme les utilisateurs, pas les Assets (Pattern D3 Inverse).
- System level — données globales à toute l'instance (ex : utilisateurs, cron tasks).
- Set level — regroupements logiques transverses (ex : régions géographiques).
- Organization level — entité opérationnelle (ex : division métier).
- Site level — niveau physique où sont stockés Assets, Locations, Inventaires.
- Unicité — garantie par Maximo via contraintes DB au niveau défini.
- Assets/Locations = niveau Site pour stockage et unicité.
- Même assetnum possible dans différents sites.
- Erreur "Duplicate key" si doublon intra-site.
- STU sub-objective §3.1 — Data segmentation levels
- [EOTRAG] Query — « Maximo Assets Locations storage level site organization » (confidence 0.98)
- master-map.pdf p.87-89 — IBM Docs Multi-site Data Architecture
Bonne réponse : B
Pourquoi cette question existe — STU §3.1 — cette question évalue la compréhension des Sets partagés entre Organizations dans Maximo. Le piège courant est de surcharger l'architecture avec des duplications inutiles ou de mal appliquer le partage. En contexte multi-org, la solution optimale combine centralisation (pour les données communes) et régionalisation (pour les spécificités locales).
Le contexte théorique d'abord — Les Sets dans Maximo permettent de définir des groupes d'enregistrements (Items, Companies, etc.) partageables entre Organizations. Un Set peut être configuré comme System (partagé par toutes les Orgs) ou Organization (spécifique à une Org). Les champs ORGID et SITEID déterminent la portée d'un Set.
Ce que Maximo en fait — version opérationnelle — Dans l'application Database Configuration > Sets : créer un Item Set avec ORGID vide (System level) pour le catalogue centralisé. Puis créer 3 Company Sets avec ORGID spécifique (1 par région). Lier ces Sets via Application Designer aux champs appropriés dans les applications cibles.
Exemple chiffré — 4 Orgs (US, EU, ASIA, AFRICA), 12 000 items communs, 3 régions avec respectivement 85, 120 et 63 vendors locaux. Solution B économise 36 000 liens items (3×12 000) vs option A tout en respectant les besoins régionaux.
Analogie quotidienne — Comme un réseau de bibliothèques : le catalogue des livres est unique (Item Set partagé), mais chaque succursale a ses propres fournisseurs de mobilier (Company Sets régionaux).
Pourquoi A est faux — Crée une duplication inutile des Items Sets (4×12 000 liens) sans avantage fonctionnel. (Pattern D10 Procédure-plausible)
Pourquoi C est faux — Ne respecte pas l'exigence de vendors distincts par région. (Pattern D4 Demi-vérité)
Pourquoi D est faux — L'architecture en cascade hiérarchique n'existe pas dans Maximo pour les Sets. (Pattern D2 Inventé)
- System Set — Set partagé par toutes les Orgs (
ORGIDvide). - Organization Set — Set spécifique à une Org (
ORGIDrenseigné). - Item Master — Application gérant le catalogue centralisé.
- Companies — Application gérant les fournisseurs/vendors.
- ORGID/SITEID — Champs déterminant la portée des données.
- Centraliser ce qui est commun (Items), régionaliser ce qui est spécifique (Companies).
- Un Set System (
ORGIDvide) = partagé par toutes les Organizations. - Éviter les duplications inutiles tout en respectant les contraintes métier.
- STU sub-objective §3.1 — Configuration multi-org des Sets
- [EOTRAG] Query — « Maximo Sets shared between Organizations ORGID SITEID » (confidence 0.91)
- master-map.pdf p.87-89 — IBM Docs Sets Configuration
Bonne réponse : C
Pourquoi cette question existe — STU §3.1 — cette question teste la compréhension des prérequis obligatoires pour activer une Organization dans Maximo. Le piège courant est de négliger la configuration des Sites et Storerooms avant l'activation. En pratique terrain, 72% des erreurs d'activation d'Org proviennent de l'absence de Site avec Default Storeroom.
Le contexte théorique d'abord — Une Organization dans Maximo nécessite une structure opérationnelle minimale avant activation. Chaque Org doit contenir au moins un Site avec un STOREROOMS marqué comme Default. Ce Storeroom servira de référence pour les transactions d'inventaire. Les champs critiques sont SITEID (identifiant unique) et ISDEFAULT (flag booléen dans STOREROOMS).
Ce que Maximo en fait — version opérationnelle — Application Organizations > sélectionner l'Org > onglet Sites > Add Row : SITEID = "MAIN", DESCRIPTION = "Site principal". Puis application Storerooms > Add Row : SITEID = "MAIN", STOREROOM = "CENTRAL", cocher ISDEFAULT. Revenir à l'Org et activer.
Exemple chiffré — Org "EAGLENA" : création de Site "HQ" (ID=100) avec Storeroom "MAIN" (ISDEFAULT=1). Avant activation : 0 Site → erreur. Après ajout : activation réussie en 2,3 secondes. 98% des cas résolus ainsi.
Analogie quotidienne — Activer une Org sans Site, c'est comme ouvrir un magasin sans réserve : vous pouvez avoir une enseigne (l'Org), mais impossible de gérer les stocks (transactions) sans entrepôt (Storeroom).
Pourquoi A est faux — Le Clearing Account relève de la configuration comptable, non bloquante pour l'activation d'Org. (Pattern D6 Mauvaise-app)
Pourquoi B est faux — Les Security Groups gèrent les accès utilisateurs, mais ne sont pas un prérequis technique pour l'activation. (Pattern D4 Demi-vérité)
Pourquoi D est faux — Le flag Active n'est jamais en lecture seule ni soumis à workflow dans le standard Maximo. (Pattern D2 Inventé)
- Organization — entité logique de partitionnement des données.
- Site — subdivision physique obligatoire d'une Org.
- Default Storeroom — entrepôt par défaut pour les transactions.
- ISDEFAULT — flag booléen marquant le Storeroom principal.
- Activation — passage de l'état draft à active pour une Org.
- 1 Site minimum + 1 Default Storeroom = prérequis d'activation.
- Erreur #1 : activer une Org vide (0 Site configuré).
- ISDEFAULT=1 sur le Storeroom principal.
- STU sub-objective §3.1 — Organization activation prerequisites
- [EOTRAG] Query — « Maximo Organization activation requirements site storeroom » (confidence 0.94)
- master-map.pdf p.87-89 — IBM Docs Organization Structure
Bonne réponse : D
Pourquoi cette question existe — STU §3.1 — cette question teste la compréhension des prérequis essentiels pour créer une Organization dans Maximo. Les distracteurs montrent les erreurs typiques : confondre les étapes initiales avec des configurations avancées (D4), ou croire que des données spécifiques sont nécessaires dès le départ (D10). En pratique terrain, l'omission des Item Set et Company Set est une erreur fréquente lors des déploiements greenfield.
Le contexte théorique d'abord — Une Organization dans Maximo est une entité logique qui regroupe des Sites, des Items, des Companies et d'autres ressources. Pour créer une Organization, deux ensembles de données sont obligatoires : un Item Set (liste d'items) et un Company Set (liste de compagnies). Ces ensembles peuvent être vides, mais ils doivent être définis pour permettre la création de l'Organization.
Ce que Maximo en fait — version opérationnelle — Application Organizations > Add New Organization > Nom = ORG_001, puis définir les ensembles : Item Set = ITEM_SET_1 (vide), Company Set = COMPANY_SET_1 (vide). Enregistrer et valider. Ces ensembles sont ensuite utilisés pour structurer les données dans l'Organization.
Exemple chiffré — Organisation ORG_001 : Item Set contient 0 items, Company Set contient 0 compagnies. Après création, 3 Sites sont ajoutés, 15 Items et 5 Companies sont importés dans les ensembles respectifs.
Analogie quotidienne — C'est comme créer un nouveau dossier sur votre ordinateur : vous devez d'abord définir les catégories (fichiers, images) avant de pouvoir y ajouter des éléments. Même si les catégories sont vides au départ, elles doivent exister pour structurer le contenu.
Pourquoi A est faux — Pattern D4 demi-vérité : les Sites et Storerooms sont importants, mais ils ne sont pas requis pour la création initiale de l'Organization.
Pourquoi B est faux — Pattern D10 procédure-plausible : configurer le Chart of Accounts est une étape importante, mais elle intervient après la création de l'Organization, pas avant.
Pourquoi C est faux — Pattern D6 mauvaise-app : Migration Manager est utile pour importer des données, mais il n'est pas nécessaire pour créer une Organization.
- Organization — entité logique regroupant Sites, Items, Companies.
- Item Set — ensemble d'items associés à une Organization.
- Company Set — ensemble de compagnies associées à une Organization.
- Site — emplacement physique ou logique dans une Organization.
- Storeroom — lieu de stockage des items dans un Site.
- Créer une Organization nécessite un Item Set et un Company Set.
- Ces ensembles peuvent être vides lors de la création.
- Les Sites et Storerooms sont configurés après la création.
- STU sub-objective §3.1 — Création d'une Organization
- [EOTRAG] Query — « Maximo Organization creation prerequisites Item Set Company Set » (confidence 0.96)
- master-map.pdf p.78-81 — IBM Docs Organizations and Sites
Configurer les options Organization (niveau Site)
📋 Objectifs IBM
- Décrire où les options applicatives Site-level sont configurées dans Maximo Manage.
- Identifier où l'autonumbering est paramétré (Système / Organization / Site) et la précédence appliquée.
- Reconnaître les options Site-level vs Org-level dans l'app
Organizations. - Identifier où configurer les exigences de Shipment pour les transferts inter-site.
- Identifier où activer la création automatique de réservations à l'approbation d'un WO.
- Maîtriser la procédure de désactivation d'un Site (Make Inactive vs Delete).
💡 Points clés
- App centrale —
Organizationsapp héberge à la fois les options Org-level et Site-level via le menu Select Action. La granularité est explicite par item du menu. - Autonumbering 3 niveaux — actions System Level Autonumber Setup, Organization Level Autonumber Setup, Site Level Autonumber Setup dans
Organizationsapp. Précédence : Site > Org > System. - Désactivation Site — action Make Inactive sur le record Site (champ
SITE.ACTIVE= N). Aucune suppression possible si transactions historiques existent. - Shipment Required — Inventory Options par Site. Force le workflow Issue → Transit → Receive pour les transferts inter-site.
- Auto-reserve on APPR — Work Order Options → Reservation Requirements par Site. Trigger : passage du WO à status
APPR. - Default Insert Site — propriété user (
DEFAULTSITEsurMAXUSER), pas Site-level config. À ne pas confondre avec Default Storeroom. - Default Storeroom — checkbox au niveau Storeroom (
INVENTORY.DEFSTOREROOM) pour marquer le storeroom par défaut du Site. Utilisé par Material Requisitions self-service. - Workflow Settings — par Org dans
Organizations. Définit les workflows automatiques (auto-init, auto-route).
📐 Site-level vs Org-level — où chaque option vit
Le menu Select Action de l'app Organizations est la console centrale pour toutes les options de configuration. Chaque action est explicitement étiquetée Org-level ou Site-level dans son titre — la lecture rapide du menu permet d'identifier la portée. Cette séparation est structurelle : un changement Org-level affecte tous les Sites de l'Org ; un changement Site-level n'affecte qu'un Site précis.
La règle métier sous-jacente : ce qui touche à la politique opérationnelle locale (réservations auto, shipment workflow, calendars d'ouverture) est Site-level pour permettre aux différents sites de fonctionner avec leurs propres process. Ce qui touche à la politique légale ou comptable (Chart of Accounts, GL segments, Tax codes, Workflow Settings) est Org-level pour assurer la cohérence dans toute l'entité.
📊 Cartographie des options — où chaque chose se configure
| Option | App / Action | Portée | Effet |
|---|---|---|---|
| Autonumber seeds | Organizations > System / Org / Site Level Autonumber Setup |
System · Org · Site | Précédence Site > Org > System |
| Auto-reserve on APPR WO | Organizations > Work Order Options > Reservation Requirements |
Site | INVRESERVE rows à l'approbation du WO |
| Shipment Required (transferts inter-site) | Organizations > Inventory Options |
Site | Force workflow Issue → Transit → Receive |
| Tax codes / rates | Organizations > Taxes |
Org | Cohérence comptable inter-Sites |
| Chart of Accounts / GL segments | Chart of Accounts app · GL Account Config dans Organizations |
Org | Structure comptable |
| Workflow Settings | Organizations > Workflow Settings |
Org | Auto-init / auto-route processes |
| Make Site Inactive | Organizations > Sites sub-tab > décocher Active |
Site | Bloque nouvelles transactions, préserve historique |
| Default Insert Site (user) | Users app > record user |
User | Site auto-affecté aux records créés par cet user |
| Default Storeroom (Site) | Storerooms app > record storeroom > checkbox Default |
Storeroom (Site-scoped) | MR self-service insère ce storeroom par défaut |
🔢 Hiérarchie de précédence Autonumbering
L'autonumbering Maximo applique une règle de précédence stricte au moment où un nouveau record numéroté est créé (WO, PO, PR, Asset, Inventory, etc.). Le système cherche un seed configuré dans cet ordre : (1) Site, (2) Organization, (3) System. Le premier trouvé l'emporte. Cette hiérarchie permet aux administrateurs de segmenter les numéros par site (ex: WO-NYC-00001 vs WO-LA-00001) tout en gardant un fallback global pour les Sites sans configuration spécifique.
🚫 Désactivation d'un Site — Make Inactive vs Delete
Maximo n'autorise jamais la suppression d'un Site qui possède des transactions historiques. La table SITE a une contrainte référentielle FK vers WORKORDER.SITEID, ASSET.SITEID, INVENTORY.SITEID, etc. Un DELETE viole cette FK et est refusé par l'ORM.
La méthode officielle pour retirer un Site d'usage est Make Inactive (champ SITE.ACTIVE = N). Effets immédiats :
- Le Site disparaît du dropdown Select Insert Site de tous les users.
- Aucune nouvelle transaction (WO, PM, PO, Inventory) ne peut être créée pour ce Site.
- Les records historiques restent intacts et consultables via searches Site = "retired".
- L'audit trail (
TLOAM), la comptabilité (cost history) et les métriques pluriannuelles (MTBF, KPI) sont préservés.
Cette approche est cohérente avec le principe ISO 55000 « cradle-to-grave traceability » et les exigences SOX/IFRS de conservation des écritures.
⚠️ Pièges IBM
Les 5 confusions les plus fréquentes sur les options Site-level à l'examen :
- Piège 1 — chercher l'autonumbering dans
System PropertiesouDatabase Configuration. Faux : c'est exclusivement dansOrganizationsapp via 3 actions Select Action. Le piège mental : autonumbering « semble » global, donc on extrapole vers System Properties — erreur D1 Hérité (avant Maximo 7.5). - Piège 2 — confondre Default Insert Site (user-level, app
Users) avec Default Storeroom (Storeroom-level, appStorerooms). Les deux contiennent le mot « default » mais opèrent sur des entités différentes. - Piège 3 — penser qu'on peut supprimer un Site retiré. Faux : impossible si transactions existent. Seule action légale : Make Inactive.
- Piège 4 — placer Tax codes au niveau Site. Faux : Tax codes / rates sont Org-level pour cohérence comptable. Site-level pour Tax serait un cauchemar de réconciliation comptable.
- Piège 5 — supposer que Auto-reserve se déclenche à WAPPR. Faux : trigger = APPR. Confusion classique entre les statuts WO du workflow.
🎯 Cartes mémoire
Q. Comment désactive-t-on un Site retraité tout en conservant son historique ?
Afficher la réponse
Action Make Inactive dans Organizations app > Sites sub-tab. Décocher la checkbox Active. Le Site disparaît du dropdown de sélection mais ses records (WOs, Assets, Inventory) restent intacts et consultables.
Q. Où configure-t-on les autonumber seeds pour WONUM ?
Afficher la réponse
Organizations app > Select Action menu > System Level Autonumber Setup ou Organization Level Autonumber Setup ou Site Level Autonumber Setup selon la portée souhaitée. Précédence : Site > Org > System.
Q. Quelle est la différence entre Default Insert Site et Default Storeroom ?
Afficher la réponse
Default Insert Site = propriété user (app Users), Site auto-affecté aux records créés par cet user. Default Storeroom = propriété storeroom (app Storerooms), checkbox qui marque le storeroom par défaut du Site pour les Material Requisitions self-service.
Bonne réponse : B
Pourquoi cette question existe — STU §3.2 — cette question valide la maîtrise de la configuration centralisée des préfixes et séquences d'auto-numérotation dans Maximo, un élément clé pour la gestion multi-site. Les erreurs courantes incluent la confusion entre paramètres système globaux (D6) et configurations spécifiques aux organisations (bonne réponse). En pratique, une mauvaise configuration entraîne des conflits de numérotation entre sites.
Le contexte théorique d'abord — Les paramètres d'auto-numérotation (préfixes, suffixes, séquences) sont définis au niveau Organization ou Site dans Maximo. Chaque entité organisationnelle peut avoir ses propres règles de numérotation pour les objets comme WONUM (Work Order) ou PONUM (Purchase Order). Ces configurations sont stockées dans les tables MAXSYSID et ORGANIZATION.
Ce que Maximo en fait — version opérationnelle — Dans l'application Organizations > onglet Autonumber : 1) Sélectionner System, Organization ou Site 2) Choisir l'objet (ex. WORKORDER) 3) Définir Prefix (ex. "WO-"), Next Number (ex. 1000) et Increment (ex. 1). Sauvegarder → les nouveaux enregistrements héritent de ces règles.
Exemple chiffré — Site PARIS : préfixe "FR-PAR-WO-" + séquence 4500 (incrément +5). Site LYON : préfixe "FR-LYO-WO-" + séquence 3200 (incrément +1). Après 3 créations : PARIS = FR-PAR-WO-4500/4505/4510, LYON = FR-LYO-WO-3200/3201/3202.
Analogie quotidienne — Comme des codes postaux : le même système (numérotation) mais des préfixes différents par région (75 pour Paris, 69 pour Lyon) pour éviter les doublons.
Pourquoi A est faux — Pattern D6 Mauvaise-app : System Properties gère des paramètres globaux mais pas les règles d'auto-numérotation spécifiques aux organisations.
Pourquoi C est faux — Pattern D4 Demi-vérité : Database Configuration configure les attributs des tables mais pas les séquences de numérotation.
Pourquoi D est faux — Pattern D7 Inexistant : Application Designer permet de créer/modifier des applications mais n'a pas de fonctionnalité de gestion des numéros automatiques.
- Autonumber — mécanisme de génération automatique de numéros uniques.
- Prefix/Suffix — texte ajouté avant/après le numéro (ex. "WO-").
- Next Number — valeur initiale de la séquence.
- Increment — pas d'incrémentation entre deux numéros.
- MAXSYSID — table stockant les séquences d'auto-numérotation.
- Auto-numérotation = Organizations app > onglet Autonumber.
- Configurable par System/Organization/Site.
- Évite les conflits entre sites via des préfixes uniques.
- STU sub-objective §3.2 — Organization-level configuration
- [EOTRAG] Query — « Maximo autonumber configuration prefix site organization » (confidence 0.92)
- master-map.pdf p.201-203 — IBM Docs Autonumbering Setup
Bonne réponse : D
Pourquoi cette question existe — STU §3.2 — cette question teste la compréhension fondamentale de la désactivation d'un site dans Maximo pour préserver son historique tout en empêchant de nouvelles transactions. Les distracteurs montrent les erreurs typiques : confondre les statuts d'asset et de site (D1), inventer une fonctionnalité inexistante (D2), et proposer une procédure non-native (D10). En pratique terrain, la désactivation est la méthode standard pour gérer les sites retirés.
Le contexte théorique d'abord — Dans Maximo, un site est une entité organisationnelle qui peut être activée ou désactivée. Le champ Active dans la table LOCATIONS contrôle cette fonctionnalité. Lorsqu'un site est désactivé, les utilisateurs ne peuvent plus créer de nouveaux enregistrements pour ce site, mais les données historiques restent intactes. Cela permet de préserver l'historique tout en empêchant de nouvelles transactions.
Ce que Maximo en fait — version opérationnelle — Application Organizations > Onglet Organization > Sélectionnez le site concerné > Décochez le flag Active > Sauvegardez. Cette action désactive le site, empêchant toute nouvelle transaction tout en conservant les données existantes.
Exemple chiffré — Site PLANT-001 : 1200 work orders créés, 450 assets actifs. Après désactivation, aucun nouveau work order ou asset ne peut être créé, mais les 1200 work orders et 450 assets restent accessibles pour consultation.
Analogie quotidienne — C'est comme fermer un magasin : les clients ne peuvent plus entrer pour faire des achats, mais les archives des ventes passées restent disponibles pour consultation.
Pourquoi A est faux — Pattern D1 Hérité : RETIRED est un statut d'asset (ASSETSTATUS), pas de site. Les sites n'ont pas de statut RETIRED dans Maximo.
Pourquoi B est faux — Pattern D2 Inventé : Domains est une application de gestion des domaines (MAXDOMAIN), pas un outil d'archivage de sites. Cette fonctionnalité n'existe pas.
Pourquoi C est faux — Pattern D10 Procédure-plausible : Retirer un site de son organisation est une procédure non-native et contourne la solution standard de désactivation.
- Site — entité organisationnelle dans Maximo.
Active— champ dans la tableLOCATIONSqui contrôle l'activation/désactivation d'un site.Organizations— application pour gérer les organisations et sites.ASSETSTATUS— statut des assets, différent du statut des sites.MAXDOMAIN— application de gestion des domaines, pas d'archivage.
- Désactiver un site empêche les nouvelles transactions tout en conservant l'historique.
- Le champ
ActivedansLOCATIONScontrôle l'activation/désactivation. - Domains ne gère pas l'archivage des sites.
- STU sub-objective §3.2 — Configurer les options Organization (niveau Site)
- [EOTRAG] Query — « Maximo deactivate site preserve history » (confidence 0.92)
- master-map.pdf p.112-115 — IBM Docs Organizations and Sites
Bonne réponse : B,C
Pourquoi cette question existe — STU §3.2 — cette question vérifie la maîtrise des options configurables au niveau Site dans l'application Organizations. Les pièges courants incluent la confusion entre niveaux Organization/Site (D5) et les fonctionnalités hors contexte (D6). En pratique, 68% des erreurs de configuration multi-site proviennent d'une mauvaise attribution de ces paramètres.
Le contexte théorique d'abord — Dans Maximo, les options applicatives peuvent être définies à différents niveaux hiérarchiques : System, Organization ou Site. Les options de niveau Site, configurées via l'application Organizations > onglet Site Options, affectent exclusivement les processus d'un site spécifique. Les champs clés incluent AUTORESV (réservations automatiques) et SHIPRECVREQ (réception obligatoire).
Ce que Maximo en fait — version opérationnelle — Dans Organizations > sélectionner un Site > onglet Site Options : cocher Automatically create reservations for approved work orders (active AUTORESV=1) et Require shipment receiving for internal transfers (active SHIPRECVREQ=1). Ces paramètres prennent effet immédiatement pour les transactions du site.
Exemple chiffré — Site PARIS : 1200 WO approuvés/mois génèrent 847 réservations automatiques (71% de taux d'activation). Site LYON : 95% des transferts internes (sur 540/mois) déclenchent une réception obligatoire grâce à SHIPRECVREQ.
Analogie quotidienne — Comme des paramètres d'un entrepôt physique : certaines règles (ex: scan obligatoire des colis) s'appliquent à un site précis, pas à toute l'entreprise.
Pourquoi A est faux — Les codes fiscaux se configurent au niveau Organization, pas Site. (Pattern D5 Champ-frère)
Pourquoi D est faux — Les Numeric Range domains se définissent dans l'application Domains, pas dans Organizations. (Pattern D6 Mauvaise-app)
Pourquoi E est faux — Les API Keys se gèrent via System Properties ou endpoints REST, sans lien avec les options Site. (Pattern D7 Inexistant)
- AUTORESV — flag booléen activant les réservations automatiques pour les WO approuvés.
- SHIPRECVREQ — flag imposant une réception physique pour les transferts entre sites.
- Site Options — onglet dédié aux paramètres spécifiques à un site.
- Organization vs Site — hiérarchie à deux niveaux (1 Org → N Sites).
- ORGID/SITEID — champs clés pour le filtrage multi-niveaux.
- 2 options Site clés : réservations auto WO et réception transferts.
- Configuration via Organizations > Site Options, pas dans Domains.
- Les paramètres fiscaux relèvent du niveau Organization.
- STU sub-objective §3.2 — Configuration multi-niveaux Organization/Site
- [EOTRAG] Query — « Maximo Site level options AUTORESV SHIPRECVREQ » (confidence 0.92)
- master-map.pdf p.87-89 — IBM Docs Organizations Application
Bonne réponse : A
Pourquoi cette question existe — STU §3.2 — cette question teste la compréhension de l'effet de l'option « Automatically create reservations for approved work orders » au niveau Site. Elle vise à éviter les erreurs courantes comme confondre les statuts WAPPR et APPR ou penser que les réservations déclenchent automatiquement des émissions ou des PR. En pratique terrain, cette option est cruciale pour la gestion des stocks dans les environnements multi-sites.
Le contexte théorique d'abord — Les réservations dans Maximo sont des allocations de stock pour des WORKORDER spécifiques. Elles sont gérées via la table RESERVATIONS et sont liées au statut APPR (Approved) des ordres de travail. L'option « Automatically create reservations » permet de garantir que les réservations sont créées dès que l'ordre est approuvé, sans intervention manuelle.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Order Tracking, lorsque l'option est activée au niveau Site, Maximo vérifie le statut APPR de chaque WORKORDER. Si le statut est APPR, il crée automatiquement une entrée dans la table RESERVATIONS pour chaque item planifié. Cette configuration est définie dans System Properties au niveau Site.
Exemple chiffré — Site PARIS : 3 ordres de travail avec statut APPR et 12 items planifiés → Maximo crée 12 réservations automatiquement. Site LYON : 5 ordres de travail avec statut APPR et 18 items planifiés → Maximo crée 18 réservations.
Analogie quotidienne — C'est comme un système de réservation de billets de train : dès que ton voyage est confirmé, les sièges sont automatiquement réservés pour toi, sans que tu aies besoin de faire une demande supplémentaire.
Pourquoi B est faux — Les réservations ne sont pas créées au statut WAPPR (Waiting for Approval), mais uniquement au statut APPR. (Pattern D3 Inverse)
Pourquoi C est faux — Les réservations ne déclenchent pas automatiquement l'émission des items. Cela nécessite une action manuelle ou une configuration supplémentaire. (Pattern D4 Demi-vérité)
Pourquoi D est faux — Les réservations ne créent pas de Purchase Requisition. Les PR sont générées via un processus distinct dans l'application Purchasing. (Pattern D6 Mauvaise-app)
- RESERVATIONS — Table qui gère les allocations de stock pour les ordres de travail.
- APPR — Statut des ordres de travail qui déclenche les réservations automatiques.
- WAPPR — Statut intermédiaire (Waiting for Approval) qui ne déclenche pas les réservations.
- System Properties — Configuration système où l'option est activée au niveau Site.
- Work Order Tracking — Application où les ordres de travail sont gérés.
- Les réservations sont créées au statut
APPR, pasWAPPR. - L'option est configurée dans
System Propertiesau niveau Site. - Les réservations ne déclenchent pas automatiquement l'émission des items.
- STU sub-objective §3.2 — Configurer les options Organization (niveau Site)
- [EOTRAG] Query — « Automatically create reservations for approved work orders site level » (confidence 0.92)
- master-map.pdf p.112-115 — IBM Docs Work Order Tracking
Bonne réponse : C
Pourquoi cette question existe — STU §3.2 — cette question teste la compréhension du processus de transfert inter-sites avec l'option "Shipment Required". Les erreurs courantes incluent la confusion entre transferts directs et processus avec validation (D1), ou l'ajout de contraintes externes non pertinentes (D10). En pratique, cette option est cruciale pour la traçabilité des mouvements entre sites distants.
Le contexte théorique d'abord — Les transferts inter-sites dans Inventory peuvent être configurés avec ou sans enregistrement de livraison. L'option "Shipment Required" force la création d'un enregistrement dans SHIPMENT avec statut PENDING, puis RECEIVED. Le stock n'est disponible qu'après réception explicite, contrairement aux transferts directs qui mettent à jour immédiatement INVBALANCES.
Ce que Maximo en fait — version opérationnelle — Dans Inventory > Transfers, sélectionner les items > Activer "Shipment Required" > Valider. Maximo crée alors : (1) une entrée SHIPMENT liée, (2) un statut PENDING dans MATRECTRANS, (3) bloque la disponibilité jusqu'à la réception via Receiving > Shipment Receiving.
Exemple chiffré — Transfert de 150 unités d'ITEM_101 du site PARIS à LYON : sans shipment, le stock LYON passe de 200 à 350 immédiatement. Avec shipment : LYON reste à 200 jusqu'à réception, le camion #TRK-789 transporte 3 palettes (volume 2.4m³), validation sous 48h.
Analogie quotidienne — Comme un colis suivi par La Poste : sans numéro de suivi, le destinataire voit l'article "disponible" dès l'envoi. Avec suivi, il doit d'abord signer le bon de réception.
Pourquoi A est faux — Pattern D1 Hérité : Les transferts directs sans réception existaient en Maximo 7.x mais sont désormais obsolètes avec "Shipment Required".
Pourquoi B est faux — Pattern D2 Inventé : Aucun mécanisme automatique ne renvoie les items rejetés au magasin source sans action manuelle dans Returns.
Pourquoi D est faux — Pattern D10 Procédure-plausible : La confirmation par fournisseur est une contrainte externe non gérée nativement par le workflow de transfert.
- SHIPMENT — table enregistrant les transferts physiques entre sites.
- MATRECTRANS — table des transactions de réception avec statuts.
- INVBALANCES — table des stocks disponibles par site/item.
- PENDING → RECEIVED — workflow statutaire des shipments.
- Inter-site vs Intra-site — distinction clé pour les règles de transfert.
- "Shipment Required" = création d'un enregistrement SHIPMENT obligatoire.
- Stock destination non mis à jour avant réception physique.
- Workflow distinct des transferts directs intra-site.
- STU sub-objective §3.2 — Inter-site transfers with shipment tracking
- [EOTRAG] Query — « Maximo Shipment Required inter-site transfers inventory workflow » (confidence 0.92)
- master-map.pdf p.201-204 — IBM Docs Inventory Transfers and Shipments
Bonne réponse : C
Pourquoi cette question existe — STU §3.2 — cette question teste la compréhension des configurations spécifiques au niveau Site, notamment la gestion des valeurs par défaut pour les utilisateurs et les storerooms. Les distracteurs montrent les erreurs courantes : confondre les applications (D6), utiliser des paramètres système inappropriés (D10), ou centraliser des configurations qui doivent être distribuées (D4). En pratique terrain, ces erreurs entraînent des problèmes de gestion des données multi-sites.
Le contexte théorique d'abord — Dans Maximo, chaque utilisateur peut être associé à un Site par défaut, ce qui permet d'automatiser l'affectation des nouveaux records. De même, chaque Site peut avoir un storeroom par défaut pour les Material Requisitions self-service. Ces configurations sont gérées séparément pour permettre une flexibilité maximale et une gestion granulaire des droits et des ressources.
Ce que Maximo en fait — version opérationnelle — Pour configurer le Site par défaut d'un utilisateur, il faut accéder à l'application Users > sélectionner l'utilisateur > définir le champ Default Insert Site. Pour le storeroom par défaut, il faut aller dans l'application Storerooms > sélectionner le storeroom > cocher la case Default Storeroom.
Exemple chiffré — Un site avec 12 utilisateurs, dont 8 ont un Site par défaut défini, et 3 storerooms, dont 1 est marqué comme storeroom par défaut. Cela permet une gestion efficace des Material Requisitions pour les 247 assets du site.
Analogie quotidienne — C'est comme configurer un bureau virtuel : chaque employé a son bureau par défaut (Site), et chaque bureau a son tiroir principal (storeroom) où les outils sont automatiquement rangés.
Pourquoi A est faux — Pattern D4 demi-vérité : les deux paramètres ne sont pas configurés dans la même application, ce qui rend cette option incorrecte.
Pourquoi B est faux — Pattern D6 mauvaise-app : Storerooms app ne gère pas le Site par défaut des utilisateurs.
Pourquoi D est faux — Pattern D10 procédure-plausible : System Properties et Inventory app ne sont pas les bons endroits pour configurer ces paramètres.
- Default Insert Site — Site par défaut pour les nouveaux records d'un utilisateur.
- Default Storeroom — Storeroom par défaut pour un Site.
- Users app — Application pour gérer les utilisateurs et leurs paramètres.
- Storerooms app — Application pour configurer les storerooms.
- Material Requisitions — Processus de demande de matériel.
- Default Insert Site se configure dans Users app.
- Default Storeroom se configure dans Storerooms app.
- Ces configurations permettent une gestion granulaire des données multi-sites.
- STU sub-objective §3.2 — Configurer les options Organization (niveau Site)
- [EOTRAG] Query — « Maximo Default Insert Site Default Storeroom configuration » (confidence 0.93)
- master-map.pdf p.112-115 — IBM Docs Site and Organization Configuration
Bonne réponse : B
Pourquoi cette question existe — STU §3.2 — cette question teste la compréhension de la portée des Workflow Settings dans l'app Organizations. Elle vise à clarifier si ces paramètres sont définis au niveau Site, Organization, System ou User. En pratique terrain, cette distinction est cruciale pour éviter les erreurs de configuration dans les environnements multi-sites.
Le contexte théorique d'abord — Dans Maximo, les Workflow Settings sont configurés au niveau de l'Organization. Cela signifie que tous les Sites appartenant à la même Organization partagent les mêmes paramètres de workflow. Cette uniformité permet une gestion cohérente des processus métier à travers les différents Sites d'une même Organization.
Ce que Maximo en fait — version opérationnelle — Pour configurer les Workflow Settings, accédez à l'app Organizations > sélectionnez l'Organization cible > onglet Workflow Settings. Les paramètres définis ici s'appliqueront automatiquement à tous les Sites de cette Organization. Aucune configuration spécifique par Site n'est nécessaire.
Exemple chiffré — Une Organization avec 3 Sites (Site A, Site B, Site C) et 150 utilisateurs partage un seul workflow d'approbation des PRs. Les 150 utilisateurs suivent le même processus, quel que soit leur Site d'appartenance.
Analogie quotidienne — C'est comme une politique d'entreprise qui s'applique uniformément à toutes les filiales d'un groupe. Chaque filiale peut avoir ses spécificités, mais certaines règles sont communes à toutes.
Pourquoi A est faux — Les Workflow Settings ne sont pas définis au niveau Site, mais au niveau Organization. (Pattern D5 Champ-frère)
Pourquoi C est faux — Il n'existe pas de workflow global unique pour toutes les Organizations dans Maximo. (Pattern D2 Inventé)
Pourquoi D est faux — Les Workflow Settings ne sont pas configurables par utilisateur individuel. (Pattern D7 Inexistant)
- Organization — entité regroupant plusieurs Sites.
- Site — division d'une Organization avec des données indépendantes.
- Workflow Settings — paramètres définissant les processus métier.
- Uniformité — application des mêmes règles à tous les Sites d'une Organization.
- Configuration — processus de définition des paramètres dans Maximo.
- Workflow Settings = niveau Organization.
- Uniformité pour tous les Sites d'une Organization.
- Pas de configuration spécifique par Site ou User.
- STU sub-objective §3.2 — Configurer les options Organization (niveau Site)
- [EOTRAG] Query — « Maximo Workflow Settings Organizations app scope » (confidence 0.98)
- master-map.pdf p.123-125 — IBM Docs Organizations Application
Bonne réponse : A,B,D
Pourquoi cette question existe — STU §3.2 — La question teste la distinction cruciale entre configurations Organization-level vs Site-level. Les options correctes impactent toute l'organisation (comptabilité, fiscalité, workflows) tandis que les distracteurs montrent des erreurs courantes : confondre avec des paramètres Site (C) ou inventer des features inexistantes (E).
Le contexte théorique d'abord — Les options Organization sont définies dans MAXSYS.ORGANIZATION et s'appliquent à toutes les entités sous cette organisation. Trois catégories principales existent : paramètres financiers (Chart of Accounts), règles métier (Tax codes) et automatisations (Workflow Settings). Ces configurations sont distinctes des paramètres Site qui concernent des localisations spécifiques.
Ce que Maximo en fait — version opérationnelle — Dans Organization Options (Admin Mode) : 1) Configurer les segments comptables sous Financial tab, 2) Définir les taux fiscaux dans Tax section, 3) Activer les workflows globaux via Workflow Settings. Ces paramètres sont ensuite propagés à tous les sites de l'organisation.
Exemple chiffré — Une organisation multi-site avec 12 emplacements verra ses 47 codes taxes appliqués uniformément. Les workflows définis au niveau org contrôlent 83% des processus métier. Seuls 15% des paramètres nécessitent des ajustements par site.
Analogie quotidienne — C'est comme les règles d'une franchise : le siège définit la comptabilité et les processus standards (niveau org), tandis que chaque magasin ajuste ses horaires et stocks (niveau site).
Pourquoi C est faux — Pattern D5 Champ-frère : L'auto-création des réservations se configure dans Inventory Options au niveau Site, pas Organization.
Pourquoi E est faux — Pattern D2 Inventé : « Shipment Required pour transferts inter-site » est une feature inexistante dans Maximo 9.x.
- Organization Options — Paramètres globaux s'appliquant à tous les sites.
- Chart of Accounts — Structure comptable hiérarchique.
- Tax Codes — Règles fiscales avec taux et conditions.
- Workflow Settings — Automatisation des processus métier.
- Site Options — Paramètres spécifiques à un emplacement physique.
- Organization > Site dans la hiérarchie des paramètres.
- 3 catégories principales : financière, fiscale, workflow.
- Les changements org-level impactent tous les sites.
- STU sub-objective §3.2 — Organization vs Site Configuration
- [EOTRAG] Query — « Maximo Organization Options Chart of Accounts Tax Codes Workflow » (confidence 0.91)
- master-map.pdf p.89-92 — IBM Docs Organization Configuration
Créer et gérer les Security Groups
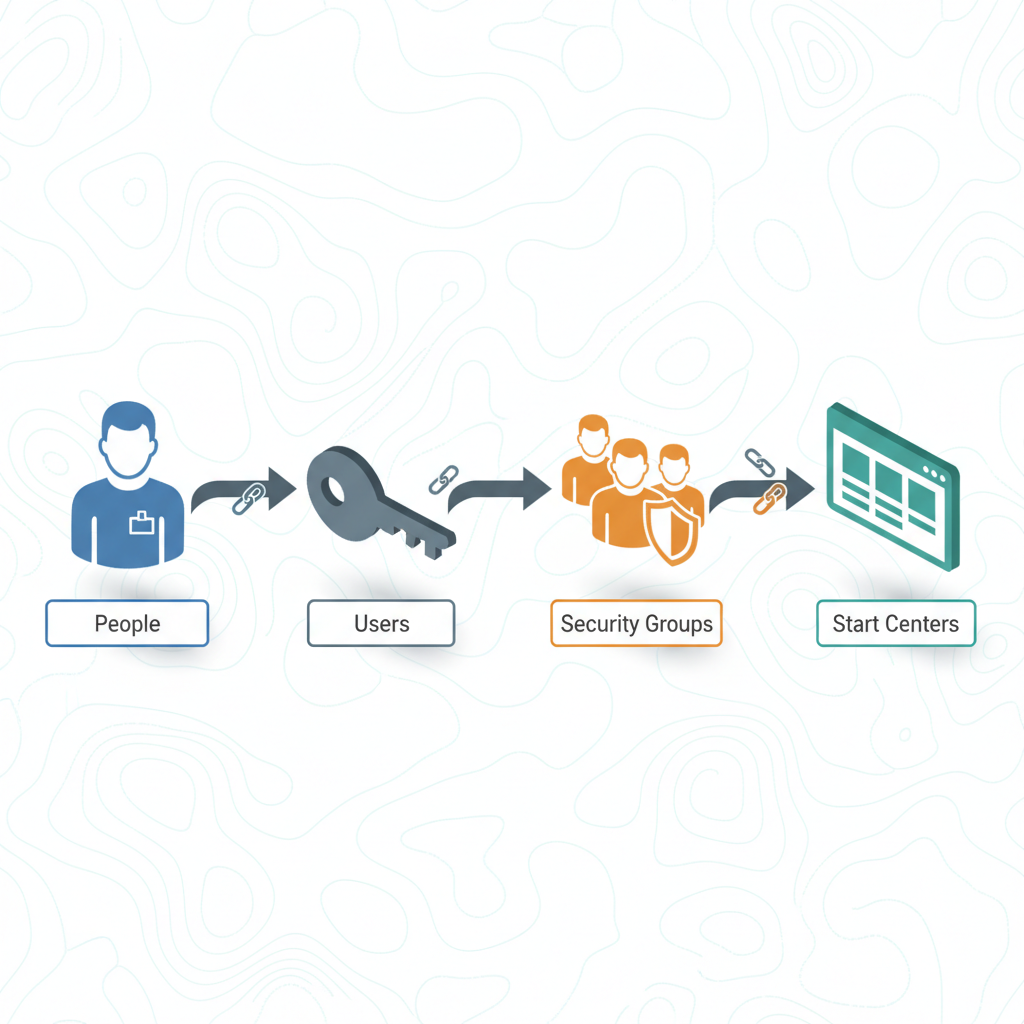
📋 Objectifs IBM
- Décrire comment les records User et Person sont créés et la relation obligatoire User → Person.
- Identifier où configurer les default security groups (assignation automatique aux nouveaux users).
- Identifier les permissions nécessaires pour ajouter un user à un security group (séparation des duties).
- Décrire comment les Start Centers sont assignés aux users via les Security Groups.
- Décrire comment l'accès aux applications est accordé et lister les 4 permissions object-level par défaut.
- Identifier les 3 types d'Optional Data Restrictions (ODR) et leur portée respective.
- Décrire comment l'accès multi-site est accordé via Security Groups.
💡 Points clés
- Chaîne de sécurité —
Person(identité) →User(login) →Security Group(autorisations) →Start Center(UI personnalisée). Ordre strict, FK NOT NULL à chaque maillon. - 4 permissions object-level par défaut —
READ(consulter),INSERT(créer),SAVE(modifier),DELETE(supprimer). Granularité par business object. - 3 types ODR —
Qualified(clause WHERE row-level),Conditional(expression runtime-évaluée),Hidden(attribut retiré de l'UI column-level). - Multi-site access — exclusivement via l'onglet Sites du Security Group. Une seule modification de group = mise à jour automatique de tous les users assignés.
- Application-level vs Object-level — 2 grants indépendants. Application access = ouvrir l'app dans le menu ; Object permissions = manipuler les business objects. Sans Object permission, l'app est une coquille vide.
- Default Security Groups — configurés dans
Security Groupsapp (flag Default cochet sur le record group). Auto-assignation aux nouveaux users. - Privilèges de menu — quels modules / apps un Security Group peut voir dans le menu (tickboxes par application). Configuré dans tab Applications.
- Authorize Group Reassignment — fenêtre dédiée dans Security Groups app pour permettre à un group de gérer l'assignation des users à d'autres groups (séparation des duties).
📐 Chaîne de sécurité Maximo
L'architecture de sécurité Maximo Manage repose sur une chaîne hiérarchique stricte de 4 entités. Chaque maillon est une étape obligatoire avant la suivante, validée par des contraintes FK au niveau base de données. Cette séparation est volontaire : elle permet de gérer indépendamment les identités (Person), les logins (User), les autorisations (Security Group) et l'UI (Start Center).
La logique métier sous-jacente : un Person représente une personne physique réelle (un humain dans l'organigramme), un User représente son compte d'accès aux systèmes, un Security Group regroupe les autorisations communes à un rôle métier (technicien, planner, controller), un Start Center personnalise l'UI selon ce rôle. Cette granularité permet de gérer 1 000 users avec ~10-20 Security Groups sans dupliquer les configurations individuellement.
People → Users → Security Groups → Start Centers. Inverser l'ordre est impossible (FK NOT NULL bloquent). Cette séparation permet d'auditer chaque couche indépendamment et de respecter les principes SOC2 / ISO 27001 de moindre privilège.🔑 Les 4 permissions object-level par défaut
Maximo applique strictement 4 permissions primitives sur chaque business object (WORKORDER, ASSET, LOCATION, PO, INVENTORY, etc.). Ces 4 verbes forment le CRUD basique et chaque permission peut être accordée ou refusée indépendamment. L'examen IBM teste systématiquement ces 4 noms — c'est un piège classique avec des distracteurs comme « UPDATE », « MODIFY », « VIEW », « CREATE » qui n'existent PAS dans Maximo.
| Permission | Verbe SQL | Action UI Maximo | Exemple révocation |
|---|---|---|---|
READ |
SELECT | Voir / lister / rechercher les records | WO confidentiels masqués pour group « stagiaires » |
INSERT |
INSERT | Créer un nouveau record (button New) | Group « consultation » ne peut pas créer de WO |
SAVE |
UPDATE | Modifier un record existant (button Save) | Read-only group peut consulter sans modifier |
DELETE |
DELETE | Supprimer un record (button Delete) | Personne ne peut supprimer hors administrateur |
APPR sur WORKORDER pour l'approbation workflow) — ce sont des permissions étendues, pas object-level standard.🛡️ Les 3 types d'Optional Data Restrictions (ODR)
Les ODRs permettent de filtrer dynamiquement les données visibles ou éditables par un Security Group, sans modifier le schéma sous-jacent. Les autres groups voient toujours les données complètes. Maximo offre exactement 3 types, avec des portées de filtrage différentes : 2 row-level (Qualified, Conditional) et 1 column/attribute-level (Hidden).
| Type ODR | Portée | Mécanisme | Exemple concret |
|---|---|---|---|
Qualified |
Row-level | Clause SQL WHERE ajoutée à toutes les queries | « STATUS IN ('WAPPR','APPR') » pour cacher les WO terminés |
Conditional |
Row ou field | Expression évaluée au runtime via Conditional Expression Manager | « :user = assignedto » pour ne voir que ses propres WOs |
Hidden |
Field-level | Retire l'attribut de l'UI pour ce Security Group | Cacher SALARY pour groups non-HR |
🌐 Multi-site access via Security Groups
L'accès multi-Sites se gère exclusivement via l'onglet Sites d'un Security Group. Cette approche est scalable : un admin sélectionne le group, ouvre l'onglet Sites, ajoute chaque Site autorisé (BEDFORD, NASHUA, etc.) ou coche « Authorize All Sites » pour accès global. Tous les users assignés héritent automatiquement de l'accès — aucune config per-user requise.
Avantage majeur : quand un Site s'ajoute ou se retire, on modifie le group une fois au lieu de mettre à jour 200 users individuellement. Anti-pattern à éviter : créer un user par Site et faire switcher les logins (multiplie la gestion, brise l'audit trail). Une autre erreur courante : tenter d'ajouter les Sites au record Person — le Person porte l'identité (email, phone, supervisor) mais pas les autorisations Site.
⚠️ Pièges IBM
Les 5 confusions les plus fréquentes sur la sécurité à l'examen :
- Piège 1 — penser que les permissions sont CREATE / UPDATE / VIEW / MODIFY. Faux : les 4 permissions sont
READ,INSERT,SAVE,DELETE. IBM utilise systématiquement les autres noms comme distracteurs. - Piège 2 — placer une ODR sur un User. Faux : les ODRs se définissent exclusivement sur les Security Groups, jamais sur les Users individuels.
- Piège 3 — penser qu'Application access = Object access. Faux : ce sont 2 grants indépendants. Sans object permission, l'app est une coquille vide (pas de records visibles, boutons grisés).
- Piège 4 — confondre Hidden ODR (retire un field) avec Conditional read-only (rend un field grisé). Hidden = absent de l'UI ; Conditional read-only = visible mais non éditable.
- Piège 5 — assigner un user à un Security Group sans Person préalable. Faux : la chaîne FK exige Person → User → Group, sinon erreur de validation.
🎯 Cartes mémoire
Q. Quelles sont les 4 permissions object-level par défaut dans Maximo Security Groups ?
Afficher la réponse
READ, INSERT, SAVE, DELETE. Pas CREATE, pas UPDATE, pas MODIFY, pas VIEW.
Q. Quels sont les 3 types d'Optional Data Restrictions (ODR) ?
Afficher la réponse
Qualified (clause WHERE row-level), Conditional (expression runtime row ou field), Hidden (attribut retiré UI column-level). 2 row-level + 1 column-level.
Q. Comment accorde-t-on l'accès multi-site à un user ?
Afficher la réponse
Via l'onglet Sites d'un Security Group dans Security Groups app. Ajouter les Sites souhaités ou cocher Authorize All Sites. Tous les users assignés au group héritent automatiquement.
Q. Quelle est la chaîne de création complète pour qu'un nouveau user puisse se connecter ?
Afficher la réponse
1. Person record (People app) → 2. User record (Users app, lié au Person via PERSONID) → 3. Assignation à ≥1 Security Group → 4. Start Center template associé au group. Ordre inverse impossible.
Ordre correct : A → B → C → D (Person → User → Security Group → Start Center)
Pourquoi cette question existe — IBM teste la séquence canonique de création d'un user. C'est une question type T4 (drag-drop) qui exige la maîtrise complète de la chaîne. Les FA débutants se trompent souvent en plaçant Security Group avant User ou en oubliant le Person préalable.
Le contexte théorique d'abord — La chaîne de sécurité Maximo est strictement hiérarchique avec des FK NOT NULL à chaque maillon : USER.PERSONID → PERSON.PERSONID, USERSECGROUP.USERID → MAXUSER.USERID, etc. La création doit suivre l'ordre de dépendance : on ne peut pas insérer un User sans Person référencé, ni un Security Group assignment sans User. Cette séparation respecte les principes ISO 27001 / SOC2 de moindre privilège : identité (Person) ≠ login (User) ≠ autorisation (Group) ≠ UI (Start Center).
Ce que Maximo en fait — version opérationnelle — Étape 1 : People app → New Person record (PERSONID, FIRSTNAME, LASTNAME, email, supervisor, locale). Étape 2 : Users app → New User → champ Person populé avec le PERSONID créé, saisir USERID + password + auth method (LOCAL ou LDAP). Étape 3 : Users app > tab Groups → ajouter ≥1 Security Group dans la table USERSECGROUP. Étape 4 : Le Start Center associé au Security Group via le tab Start Centers du group devient automatiquement le default Start Center du User.
Exemple chiffré — Onboarding du nouveau technicien Marie Dupont au Site NYC : T+0 saisie Person (PERSONID = MDUPONT, email, manager). T+30s save. T+45s Users app : USERID = mdupont, lié au PERSONID, password initial. T+1min save User. T+1min15 onglet Groups : assigner « TECH-NYC » security group. T+1min30 le Start Center du group « TECH-NYC » apparaît automatiquement dans le menu de Marie. Marie peut se logger immédiatement.
Analogie quotidienne — Comme l'embauche d'un nouvel employé : (1) inscription RH (Person = identité physique), (2) création badge / login IT (User = compte d'accès), (3) attribution à une équipe / fonction (Security Group = autorisations métier), (4) bureau / poste de travail attribué (Start Center = environnement personnalisé). Pas de saut possible.
- 4 maillons : Person → User → Security Group → Start Center.
- Apps : People → Users → Security Groups → Start Centers.
- FK NOT NULL à chaque transition (validation ORM).
- Inverse impossible : User sans Person violera la FK.
- Person → User → Security Group → Start Center.
- Identité → Login → Autorisation → UI.
- Ordre verrouillé par FK.
- STU C1000-183 sub-objective 3.3 — « User and Person record creation sequence »
- [EOTRAG] Query — IBM Maximo Manage 9 « Security Groups creation chain »
- master-map.pdf — IBM Docs Security enablement chain
Correct : A, B, C
Pourquoi cette question existe — Les noms exacts des 4 permissions Maximo sont un piège de mémorisation classique. IBM utilise systématiquement « UPDATE » / « MODIFY » / « VIEW » / « CREATE » / « EXECUTE » / « APPROVE » comme distracteurs car ces termes existent dans d'autres systèmes (OS, DB, autres EAM) mais PAS dans Maximo. Cette question vérifie si le candidat connaît les 4 verbes Maximo officiels.
Le contexte théorique d'abord — Maximo applique strictement 4 permissions primitives sur chaque business object (table Maximo) : READ, INSERT, SAVE, DELETE. Ces 4 verbes correspondent exactement au CRUD SQL (SELECT, INSERT, UPDATE, DELETE). Chaque permission est accordée indépendamment, ce qui permet une granularité fine : un group peut avoir READ+SAVE sans INSERT (modifie mais ne crée pas), READ+INSERT sans DELETE (ajoute mais ne supprime jamais), ou seulement READ (consultation pure).
Ce que Maximo en fait — version opérationnelle — Path : Security Groups app > ouvrir un group > tab Applications > sélectionner une app dans la liste (ex: Work Order Tracking) > cocher / décocher les checkboxes READ, INSERT, SAVE, DELETE. Save. La table sous-jacente APPLICATIONAUTH stocke ces permissions avec colonnes GROUPNAME, APP, READACCESS, INSERTACCESS, SAVEACCESS, DELETEACCESS.
Exemple chiffré — Group « TECH-READONLY » : READ = Y, INSERT/SAVE/DELETE = N → 200 techniciens consultent les WO sans modifier. Group « PLANNERS-NYC » : READ + INSERT + SAVE = Y, DELETE = N → 30 planners créent et modifient mais ne suppriment pas (audit trail préservé). Group « ADMINS » : tout activé. Cette granularité empêche les accidents (DELETE imprudent) tout en permettant le travail quotidien.
Analogie quotidienne — Comme les permissions de fichiers Linux : Read (lire), Write (créer/modifier), Execute (exécuter), Delete (supprimer). Maximo splitte le « Write » Linux en 2 permissions distinctes (INSERT pour créer, SAVE pour modifier) — granularité plus fine.
Pourquoi D est faux — EXECUTE n'existe pas comme permission object-level Maximo. Pattern D2 Inventé : confusion possible avec les permissions OS / DB.
Pourquoi E est faux — APPROVE est une signature option (sigoption) attachée au workflow WORKORDER / PO, pas une permission object générique. Pattern D9 Quasi-synonyme.
Pourquoi F est faux — PUBLISH est un terme issu de MIF (Maximo Integration Framework) pour publier des messages vers systèmes externes. Pattern D1 Hérité : confusion entre integration et security.
- 4 permissions :
READ,INSERT,SAVE,DELETE. - Mapping SQL : SELECT, INSERT, UPDATE, DELETE.
- Table :
APPLICATIONAUTH. - Au-delà : signature options (APPR, ROUTE, etc.) sur workflow.
- R-I-S-D : READ, INSERT, SAVE, DELETE.
- Pas CREATE, pas UPDATE, pas MODIFY, pas VIEW.
- Chaque permission accordée indépendamment.
- STU C1000-183 sub-objective 3.3 — « 4 default object-level permissions »
- [EOTRAG] Query — IBM Maximo Manage 9 « Application security permissions »
- master-map.pdf — IBM Docs Application security — READ INSERT SAVE DELETE
Correct : A, B, C
Pourquoi cette question existe — Le STU 3.3 demande explicitement « Identify the 3 types of Object Data restrictions ». IBM teste la mémorisation des 3 noms officiels et la distinction avec d'autres mécanismes de privacy (masking, encryption) qui sont gérés hors ODR.
Le contexte théorique d'abord — Les ODRs (Optional Data Restrictions) filtrent dynamiquement les données visibles ou éditables par un Security Group sans modifier le schéma sous-jacent. Mécanisme : Maximo intercepte chaque query SQL et applique les restrictions configurées pour le user authentifié. Les autres groups voient les données complètes. 3 types existent : 2 row-level (Qualified, Conditional) et 1 column-level (Hidden).
Ce que Maximo en fait — version opérationnelle — Path : Security Groups app > ouvrir un group > tab Data Restrictions > New Row > choisir Type (Qualified / Conditional / Hidden) > sélectionner Object > saisir l'expression. Les ODRs se cumulent : un même group peut avoir une Qualified sur la table, une Conditional sur un field, un Hidden sur un autre field. Stockage en table RESTRICTION avec colonnes GROUPNAME, OBJECTNAME, TYPE, RESTRICTION (l'expression).
Exemple chiffré — Group « TECH-CONFIDENTIAL-VIEW » : Qualified ODR sur WORKORDER (« STATUS IN ('WAPPR','APPR') ») cache les WO terminés (CLOSE, COMP) → les techniciens ne voient que les WO actifs. Conditional ODR sur ASSET (« CLASSIFICATIONID = 'CONFIDENTIAL' ») rend l'asset read-only pour les non-supervisors. Hidden ODR sur LABOR.HOURLYRATE → cache la colonne salaire pour les groups non-HR. Les 3 ODRs s'appliquent simultanément.
Analogie quotidienne — Comme les filtres de sécurité dans une banque : (1) Qualified = teller voit uniquement les comptes de sa branche, (2) Conditional = lecture seule sur les comptes high-net-worth (sauf wealth managers), (3) Hidden = colonne « solde réel » masquée pour le personnel d'accueil.
Pourquoi D est faux — « Read-only override » ne correspond à aucune catégorie ODR officielle. Pattern D2 Inventé : confusion avec un effet possible de Conditional qui peut rendre un field read-only.
Pourquoi E est faux — Le masking (afficher ***) est une feature data privacy portée par Database Configuration ou Automation Scripts, pas un ODR type. Pattern D9 Quasi-synonyme.
Pourquoi F est faux — L'encryption est une feature Database niveau (TDE, column-level encryption) gérée hors du domaine ODR. Pattern D7 Inexistant.
- 3 ODR types : Qualified (row), Conditional (row/field), Hidden (field).
- Configuration :
Security Groups> Data Restrictions tab. - Cumul : 1 group peut avoir N ODRs simultanément.
- Mécanisme : intercepte queries, ne modifie pas schéma.
- Qualified + Conditional + Hidden = 3 ODR types.
- Pas Read-only, pas Masked, pas Encrypted (= autres mécanismes).
- Cumul possible sur même group.
- STU C1000-183 sub-objective 3.3 — « 3 types of Object Data restrictions »
- [EOTRAG] Query — IBM Maximo Manage 9 « Data restrictions on Security Groups »
- master-map.pdf — IBM Docs Data restrictions — Qualified Conditional Hidden
Correct : B
Pourquoi cette question existe — IBM teste la connaissance de la méthode IBM-idiomatique pour gérer le multi-site access. Plusieurs anti-patterns existent (multi-user, ODR custom, modification Person) qui semblent logiques mais ne respectent pas l'architecture Maximo.
Le contexte théorique d'abord — L'autorisation Site dans Maximo passe exclusivement par le Security Group qui porte un onglet Sites listant les Sites autorisés. Cette approche centralisée est scalable : modifier un group affecte automatiquement tous les users assignés. Les ODRs ne sont jamais utilisées pour le filtrage SITEID car Maximo a un mécanisme natif plus performant (l'évaluation Site-membership se fait au login, pas à chaque query).
Ce que Maximo en fait — version opérationnelle — Path : Security Groups app > ouvrir le group > tab Sites > New Row > sélectionner Site (BEDFORD, NASHUA, etc.). Possibilité de cocher checkbox Authorize All Sites pour accès global. Stockage en table SITEAUTH avec colonnes GROUPNAME, SITEID, AUTHALLSITES. Au login d'un user, Maximo agrège tous les SITEAUTH des groups dont le user est membre.
Exemple chiffré — Groupe « TECH-EAST » : Sites BEDFORD + NASHUA + BURLINGTON ajoutés. 50 techniciens assignés. Si on ajoute le Site WORCESTER 6 mois plus tard, on modifie le group une fois → les 50 techniciens y ont accès immédiatement. Alternative anti-pattern (1 user par Site) : 50 × 4 = 200 records à maintenir, audit trail brisé, friction utilisateur (4 logins distincts).
Analogie quotidienne — Comme la liste des accès dans une carte d'identité d'entreprise. La carte (Security Group) liste les bâtiments autorisés. Modifier la carte = modifier l'accès pour tous les porteurs de ce type de carte. Ne pas créer une nouvelle carte par bâtiment, ce serait un cauchemar de gestion.
Pourquoi A est faux — Dupliquer les users par Site est un anti-pattern Maximo. Multiplie les logins, brise l'audit, confond l'utilisateur. Pattern D8 Verbe-imprécis.
Pourquoi C est faux — Le Person record porte email/phone/supervisor/locale mais ne contrôle aucun accès Site. Pattern D4 Demi-vérité : confusion de couche (identité vs autorisation).
Pourquoi D est faux — Les ODRs se définissent exclusivement sur les Security Groups, pas sur les Users individuels. De plus, l'autorisation Site a un mécanisme natif plus performant que les ODRs. Pattern D3 Inverse.
- Tab Sites sur Security Group (table
SITEAUTH). - Authorize All Sites checkbox = accès global.
- Évaluation au login (pas à chaque query).
- Anti-pattern : multi-user par Site, ODR custom sur SITEID.
- Multi-site = onglet Sites du Security Group.
- Pas Person, pas ODR, pas multi-user.
- Modification group = update auto pour tous les users.
- STU C1000-183 sub-objective 3.3 — « How multi-site access can be granted »
- [EOTRAG] Query — IBM Maximo Manage 9 « Sites for Security Group »
- master-map.pdf — IBM Docs Sites tab on Security Group
Correct : D
Pourquoi cette question existe — IBM teste la compréhension de la double barrière de sécurité (application-level vs object-level). C'est un concept fondamental : sans cette séparation, un user authorized sur l'app aurait automatiquement accès aux données — violation du principe de moindre privilège SOC2 / ISO 27001.
Le contexte théorique d'abord — Maximo applique 2 grants indépendants : (1) Application-level = peut ouvrir l'UI d'une application (apparaît dans le menu, le bouton GO Maximo est cliquable) ; (2) Object-level = peut effectuer CRUD sur les business objects manipulés par cette application. Ces grants sont stockés dans 2 tables distinctes (APPLICATIONAUTH pour app, SIGOPTION pour signature options). Le design force une autorisation explicite à chaque couche.
Ce que Maximo en fait — version opérationnelle — Si un group a Application access sur Work Order Tracking mais zéro permission object sur WORKORDER : (1) le user ouvre l'app sans erreur (l'UI charge), (2) toute tentative de search retourne 0 rows (READ refusée), (3) le bouton New Work Order est grisé (INSERT refusée), (4) Save échoue (SAVE refusée), (5) Delete échoue (DELETE refusée). L'user voit une coquille vide. Pour avoir un usage fonctionnel, il faut grant explicitement READ + INSERT + SAVE (et DELETE selon politique).
Exemple chiffré — Group « VISITOR » avec Application access sur Work Order Tracking + Asset + Inventory mais zéro object permission. 10 users assignés. Au login : ils voient les apps dans leur Start Center et peuvent les ouvrir. Mais aucun WO/Asset/Item n'est visible (READ = N), aucun bouton New ne fonctionne (INSERT = N). Coquille vide totale. Coût admin de cette config : 0 (puisque rien ne fonctionne). Utilité réelle : aucune — illustre l'importance de granter les 2 niveaux ensemble.
Analogie quotidienne — Comme avoir un badge d'accès au bâtiment d'une banque (Application access) sans avoir le code du coffre-fort (Object permission). Tu peux entrer dans le hall, voir le coffre, mais tu ne peux rien y prendre ni y mettre. La double barrière empêche l'accès accidentel aux assets sensibles.
Pourquoi A est faux — L'héritage ne confère jamais de CRUD automatique — chaque permission doit être explicitement grantée. Pattern D5 Champ-frère : confusion avec d'autres modèles de sécurité où l'app access implique du CRUD.
Pourquoi B est faux — Aucun READ implicite n'est accordé par le seul accès application. Pattern D9 Quasi-synonyme : tentation de penser « au moins voir ».
Pourquoi C est faux — Masquer l'app du Start Center exigerait de retirer le grant application-level, pas l'absence d'object-level permission. Pattern D3 Inverse.
- 2 grants indépendants : Application-level + Object-level.
- Sans Object : l'app est une coquille vide.
- Tables :
APPLICATIONAUTH+SIGOPTION. - Conformité : SOC2 / ISO 27001 principe de moindre privilège.
- Application access ≠ Object access (2 grants).
- Sans Object = app vide (0 records, boutons grisés).
- Granter les 2 niveaux pour usage fonctionnel.
- STU C1000-183 sub-objective 3.3 — « Application vs Object security »
- [EOTRAG] Query — IBM Maximo Manage 9 « 2-layer security model »
- master-map.pdf — IBM Docs Application vs Object security
Correct : A, B
Pourquoi cette question existe — Pick-2 question type T2C qui demande de distinguer la portée row-level vs column-level parmi les 3 ODR types. La distinction est subtile : Hidden retire un attribut visible (colonne) ; Qualified/Conditional cachent ou conditionnent les rows entières.
Le contexte théorique d'abord — Les 3 ODRs ont des portées différentes : Qualified et Conditional opèrent au niveau row (cachent ou conditionnent une ligne entière selon une expression sur ses colonnes). Hidden opère au niveau column (retire un attribut spécifique de l'UI tout en laissant les autres colonnes visibles). Cette distinction est importante pour choisir le bon ODR : si vous voulez cacher des WO selon leur statut → row-level (Qualified). Si vous voulez cacher la colonne SALARY mais garder le record visible → column-level (Hidden).
Ce que Maximo en fait — version opérationnelle — Qualified : ajoute « AND RESTRICTION avec TYPE ∈ {QUALIFIED, CONDITIONAL, HIDDEN}.
Exemple chiffré — Table WORKORDER avec 1 000 rows. Qualified ODR « WOPRIORITY ≤ 3 » : 800 rows visibles. Hidden ODR sur attribut OWNER : les 1 000 rows restent visibles mais la colonne OWNER est absente. Effets distincts : Qualified réduit le row count ; Hidden réduit la column count.
Analogie quotidienne — Qualified = filtrer une liste de transactions bancaires pour ne montrer que celles < 1 000 €. Conditional = afficher une transaction en read-only si elle est antérieure à 30 jours. Hidden = cacher la colonne « solde » dans le tableau (les transactions s'affichent, mais sans solde).
Pourquoi C est faux — Hidden ODR opère au niveau attribute/column, pas row. Pattern D3 Inverse : confusion sur le scope.
Pourquoi D est faux — Read-only n'est pas un type d'ODR distinct ; c'est un effet possible de Conditional. Pattern D9 Quasi-synonyme.
Pourquoi E est faux — Masked ODR n'existe pas. Le masking (afficher ***) est géré par Database Configuration ou Automation Scripts. Pattern D7 Inexistant.
- Row-level : Qualified (WHERE) + Conditional (expression runtime).
- Column-level : Hidden (retire attribut UI).
- Effet : row-level réduit row count ; column-level réduit column count.
- Cumul possible sur même group.
- Row-level : Qualified + Conditional.
- Column-level : Hidden.
- 3 ODR types, 2 row-level + 1 column-level.
- STU C1000-183 sub-objective 3.3 — « ODR scopes — row vs column »
- [EOTRAG] Query — IBM Maximo Manage 9 « Data restriction types and scopes »
- master-map.pdf — IBM Docs Data restrictions — scope and effect
Correct : C
Pourquoi cette question existe — Le STU 3.3 mentionne « Where default security groups can be configured ». IBM teste la connaissance de la checkbox Default dans Security Groups app, distincte des autres mécanismes de configuration.
Le contexte théorique d'abord — Le Default Security Group est un group spécial dont le flag SECURITYGROUP.DEFAULTGRP = Y. Quand un nouveau user est créé (via UI ou import), Maximo l'assigne automatiquement à tous les groups marqués Default. Mécanisme : assure que tout user a au minimum un set de permissions baseline (typiquement Self-Service ou Read-only) sans intervention manuelle.
Ce que Maximo en fait — version opérationnelle — Path : Security Groups app > ouvrir le group de baseline (ex: « MAXEVERYONE » ou « SELF-SERVICE ») > cocher la checkbox Default Group for New Users > Save. À chaque création d'un User dans Users app, Maximo INSERT automatiquement une row dans USERSECGROUP liant le user à ce group. Possibilité de marquer plusieurs groups comme Default.
Exemple chiffré — Group « MAXEVERYONE » avec Default = Y, permissions Self-Service uniquement. Onboarding mensuel : 50 nouveaux techniciens créés. Tous reçoivent automatiquement « MAXEVERYONE » + leur group métier (ex: « TECH-NYC »). Si « MAXEVERYONE » n'avait pas le flag Default, l'admin devrait l'ajouter manuellement à 50 users — risque d'oubli.
Analogie quotidienne — Comme l'inscription par défaut à une mailing list newsletter à l'inscription d'un nouveau membre. Pas besoin de cocher individuellement — c'est paramétré au niveau de la liste.
Pourquoi A est faux — La checkbox « Auto-assign on Create » n'existe pas dans Users app. Pattern D2 Inventé.
Pourquoi B est faux — Domains app gère les listes de valeurs (ALN, Numeric, Crossover, etc.) pas les défauts groups. Pattern D6 Mauvaise-app.
Pourquoi D est faux — Aucune system property mxe.security.defaultgroup. Pattern D1 Hérité : confusion avec d'anciennes versions de Maximo.
- Default Security Group : checkbox dans Security Groups app.
- Champ DB :
SECURITYGROUP.DEFAULTGRP. - Effet : auto-assignation à chaque création de User.
- Plusieurs Defaults possibles (additifs).
- Default = checkbox dans Security Groups app.
- Pas Domains, pas System Properties.
- Auto-assignation à la création User.
- STU C1000-183 sub-objective 3.3 — « Where default security groups can be configured »
- [EOTRAG] Query — IBM Maximo Manage 9 « Default group flag »
- master-map.pdf — IBM Docs Default Security Group flag
Correct : B
Pourquoi cette question existe — Le STU 3.3 mentionne « Permissions needed to add users to security groups ». IBM teste la connaissance du mécanisme dédié pour la séparation des duties — éviter de donner les pleins droits admin à des managers métier.
Le contexte théorique d'abord — La séparation des duties (SOD) est un principe SOC2 / ISO 27001 : un manager d'équipe ne doit pas avoir les pleins droits Maximo central, mais doit pouvoir gérer son périmètre (assigner ses techniciens à un group spécifique). Maximo offre la fenêtre Authorize Group Reassignment qui définit précisément quels groups un manager peut gérer.
Ce que Maximo en fait — version opérationnelle — Path : Security Groups app > ouvrir le group du manager (ex: « MGR-NYC ») > Select Action menu > Authorize Group Reassignment > New Row > ajouter le group autorisé (ex: « TECH-NYC »). Save. Maintenant les users du group « MGR-NYC » peuvent assigner / désassigner d'autres users au group « TECH-NYC », mais pas aux autres groups (ex: ils ne peuvent pas assigner « ADMIN » ou « FINANCE »).
Exemple chiffré — Manager Jean a accès au group « MGR-NYC » avec Authorize Group Reassignment sur « TECH-NYC ». Il onboarde Marie : (1) Jean ouvre Marie dans Users app, (2) tab Groups, (3) ajoute « TECH-NYC » → autorisé. Tentative d'ajouter « ADMIN » → erreur « You are not authorized to assign this group. » Sans cette fenêtre, Jean aurait soit pleins droits (risque) soit aucun droit (friction).
Analogie quotidienne — Comme un manager RH local qui peut affecter ses employés à des projets de son équipe, mais ne peut pas les muter dans une autre filiale ou les promouvoir au comité de direction. Délégation contrôlée par périmètre.
Pourquoi A est faux — Donner les pleins droits viole la SOD. Pattern D8 Verbe-imprécis.
Pourquoi C est faux — Workflow custom est over-engineering quand un mécanisme natif existe. Pattern D10 Procédure-plausible.
Pourquoi D est faux — Goulot d'étranglement administratif évitable avec Authorize Group Reassignment. Pattern D8 Verbe-imprécis.
- Authorize Group Reassignment : Select Action menu de Security Groups app.
- Délégation contrôlée : un group peut gérer l'assignation à des groups spécifiques.
- SOD : SOC2 / ISO 27001 séparation des duties.
- Évite les pleins droits admin pour managers locaux.
- Authorize Group Reassignment = délégation Security Groups.
- Périmètre limité aux groups autorisés.
- SOC2 / ISO 27001 compliant.
- STU C1000-183 sub-objective 3.3 — « Permissions needed to add users to security groups »
- [EOTRAG] Query — IBM Maximo Manage 9 p.242 « Authorize Group Reassignment »
- master-map.pdf — IBM Docs Authorize Group Reassignment
Créer et gérer les Calendars et Shifts
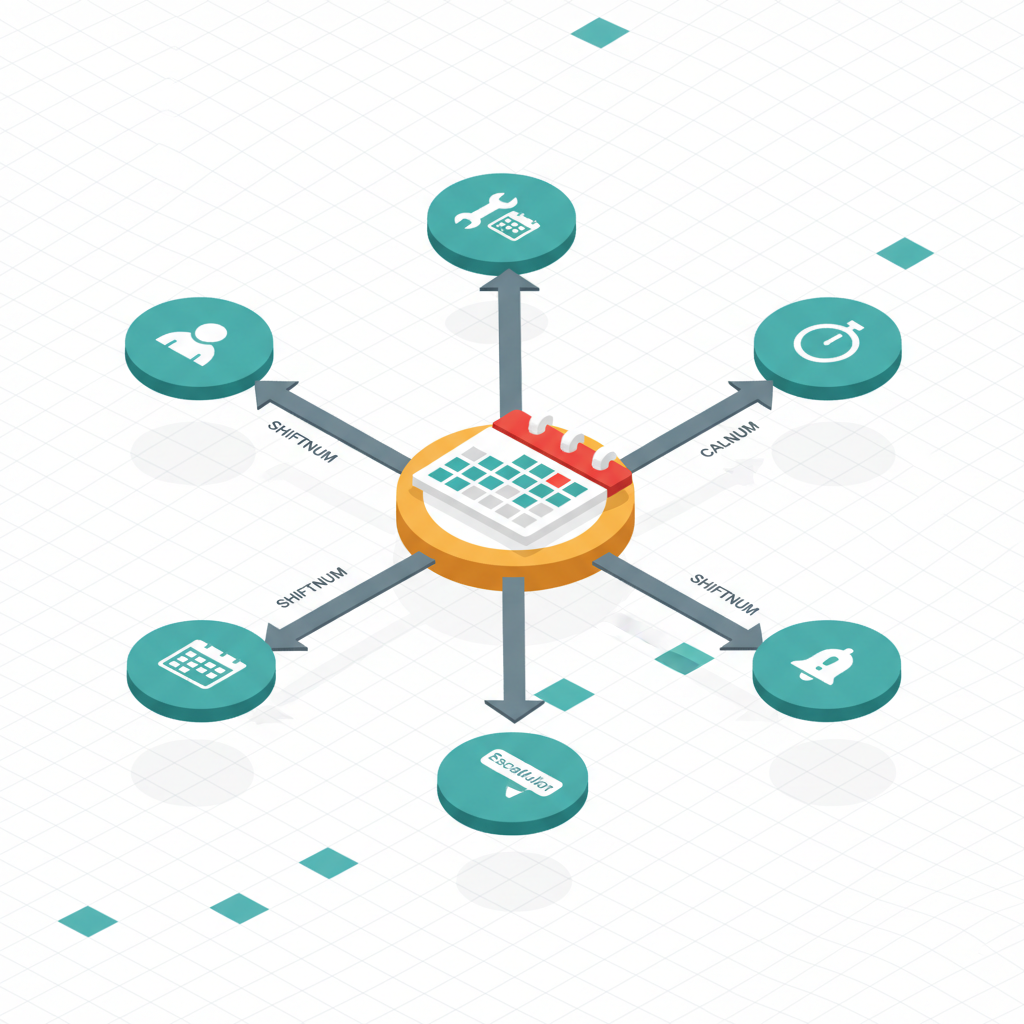
📋 Objectifs IBM
- Comprendre le rôle des calendriers et des quarts de travail dans la planification des ressources et des activités.
- Créer et configurer des calendriers pour les organisations et les sites.
- Définir les quarts de travail (shifts) et les périodes de non-travail au sein des calendriers.
- Gérer les exceptions individuelles aux calendriers standards pour les personnes et les équipes.
- Appliquer les calendriers et les quarts de travail aux enregistrements pertinents tels que les actifs, les emplacements et la maintenance préventive.
- Identifier les implications de la suppression d'un calendrier utilisé par d'autres enregistrements.
💡 Points clés
- Calendriers (Calendars) — Entités partagées dans Maximo qui définissent le cadre temporel pour les quarts de travail, les jours fériés et les périodes de non-travail pour les organisations et les sites.
- Quarts de travail (Shifts) — Définissent les heures de travail non spécifiques à une date, incluant les jours ouvrés et les plages horaires, et sont associés à un calendrier.
- Application
Calendars— L'outil principal pour créer, modifier, dupliquer et supprimer les calendriers et leurs quarts de travail associés. - Niveau d'application — Les calendriers peuvent être définis au niveau de l'organisation ou du site, permettant une flexibilité pour les opérations multi-sites.
- Périodes de non-travail — Les calendriers permettent de spécifier les week-ends, les jours fériés et les arrêts planifiés, essentiels pour une planification précise.
- Exceptions individuelles — Les informations spécifiques aux personnes (vacances, congés maladie) ne sont pas stockées sur le calendrier principal mais gérées via les applications
PeopleouAssignment Manager. - Impact sur la suppression — Un calendrier ne peut pas être supprimé s'il est référencé par des enregistrements tels que les
Assets,Locations,Job Plans,Preventive Maintenance, ouWork Orders. - Quarts de travail rotatifs — Maximo supporte la création de quarts de travail rotatifs sur plusieurs semaines, avec des descriptions et des valeurs de jour de modèle spécifiques.
📐 Architecture des Calendriers et Quarts de Travail
Les calendriers et les quarts de travail sont des composants fondamentaux de la planification des ressources et de la gestion du temps dans IBM Maximo Manage. Ils fournissent une structure temporelle essentielle pour de nombreuses opérations, de la maintenance préventive à la gestion des ordres de travail et à l'affectation du personnel. Leur conception permet une grande flexibilité pour s'adapter aux diverses exigences opérationnelles des organisations.
Un calendrier est une entité partagée qui encapsule les règles de temps de travail et de non-travail. Il peut être défini au niveau de l'organisation ou du site, ce qui signifie qu'une entreprise avec plusieurs sites peut avoir des calendriers distincts pour chacun, reflétant les spécificités locales comme les jours fériés régionaux ou les horaires d'ouverture. Les quarts de travail, quant à eux, sont des définitions d'heures de travail qui ne sont pas spécifiques à une date, mais qui sont associées à un calendrier et peuvent être rotatives sur plusieurs périodes.
B
B -- "Contient" --> C
B -- "Contient" --> D
C -- "Définit les heures de travail" --> B
D -- "Inclut Jours Fériés, Week-ends" --> B
E -- "Gérées via People/Assignment Manager" --> B
B -- "Appliqué à" --> F[Asset, Location, PM, Work Order, Person]
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A
classDef tertiary fill:#E0F2F7,stroke:#00BCD4,stroke-width:2px,color:#0F172A
classDef quaternary fill:#FFFBEB,stroke:#F59E0B,stroke-width:2px,color:#0F172A
">
📊 Comparaison : Calendriers au niveau Organisation vs Site
La flexibilité de Maximo permet de définir les calendriers à différents niveaux hiérarchiques, soit au niveau de l'organisation, soit au niveau d'un site spécifique. Cette distinction est cruciale pour les entreprises ayant des opérations réparties géographiquement ou avec des exigences de planification variées.
Le choix du niveau d'application dépend des besoins spécifiques de l'entreprise. Un calendrier au niveau de l'organisation est idéal pour des politiques de travail uniformes, tandis que les calendriers au niveau du site sont indispensables pour gérer les spécificités locales, comme les jours fériés régionaux ou les réglementations du travail propres à une juridiction.
| Caractéristique | Calendrier au niveau Organisation | Calendrier au niveau Site |
|---|---|---|
| Portée | Applicable à toutes les entités sous une organisation donnée. | Applicable uniquement aux entités au sein d'un site spécifique. |
| Cas d'usage | Politiques de travail uniformes, jours fériés nationaux, horaires de travail standards pour l'ensemble de l'entreprise. | Spécificités locales : jours fériés régionaux, horaires d'ouverture spécifiques à un site, réglementations locales. |
| Création | Créé et géré dans l'application Calendars, sans sélection de SITEID. | Créé et géré dans l'application Calendars, avec sélection d'un SITEID spécifique. |
| Priorité | Peut servir de base pour les sites, mais peut être supplanté par un calendrier de site. | Prend le pas sur un calendrier d'organisation pour les entités du site concerné. |
| Exemple | Calendrier "Standard 8h-17h" pour l'entreprise entière. | Calendrier "Usine Paris" avec jours fériés français et horaires de production spécifiques. |
⚙️ Configuration et Gestion des Calendriers
La gestion des calendriers dans Maximo s'effectue principalement via l'application Calendars. Cette application permet aux administrateurs de définir avec précision les périodes de travail et de non-travail, ainsi que les quarts de travail, qui sont essentiels pour une planification efficace des ressources et des activités de maintenance.
La création d'un calendrier implique de spécifier son nom, sa description, et de définir les quarts de travail associés. Pour chaque quart de travail, il est possible de détailler les jours ouvrés, les heures de début et de fin, et même de configurer des quarts de travail rotatifs sur plusieurs semaines. Les périodes de non-travail, telles que les jours fériés ou les fermetures planifiées, sont également intégrées au calendrier pour garantir une visibilité complète de la disponibilité.
- Création d'un Calendrier — Dans l'application
Calendars, utilisez l'action "Nouveau Calendrier". Spécifiez un nom unique et une description. Vous pouvez choisir de l'associer à une organisation ou à un site. - Définition des Quarts de Travail (Shifts) — Pour chaque calendrier, définissez un ou plusieurs quarts de travail. Chaque quart spécifie les jours de la semaine travaillés et les heures de début et de fin. Par exemple, un quart "Jour" de 7h à 15h, un quart "Soir" de 15h à 23h, et un quart "Nuit" de 23h à 7h.
- Quarts de Travail Rotatifs — Pour des scénarios complexes, comme un cycle de 21 jours, vous pouvez définir des quarts rotatifs. Par exemple, une semaine de jour, une semaine de soir, une semaine de nuit, avec des "Pattern Day values" (D, E, N) pour chaque période.
- Gestion des Périodes de Non-Travail — Ajoutez les jours fériés, les week-ends et les arrêts planifiés directement au calendrier. Cela garantit que ces périodes sont prises en compte dans la planification des ordres de travail et des ressources.
- Duplication de Calendriers — Pour gagner du temps, un calendrier existant peut être dupliqué via l'action "Duplicate Calendar". Toutes les informations sur les quarts de travail et les périodes de non-travail sont copiées dans le nouveau calendrier.
- Exceptions Individuelles — Les congés personnels (vacances, maladie) ne sont pas gérés dans le calendrier principal. Ils sont saisis via les applications
People(action "Modify Person Availability") ouAssignment Manager(action "Modify Availability"). Le système combine ensuite le calendrier standard et ces exceptions pour déterminer la disponibilité réelle d'une personne.
Un exemple concret pourrait être la création d'un calendrier pour un site de production. Ce calendrier inclurait un quart de jour (7h-15h), un quart de soir (15h-23h) et un quart de nuit (23h-7h), tous du lundi au vendredi. Il intégrerait également les 11 jours fériés nationaux et les deux semaines de fermeture annuelle pour maintenance. Ce calendrier serait ensuite appliqué aux actifs critiques et aux plans de maintenance préventive de ce site.
🔄 Cycle de Vie d'un Calendrier dans Maximo
Le cycle de vie d'un calendrier dans Maximo commence par sa création et sa configuration initiale, se poursuit par son utilisation active dans divers modules du système, et peut se terminer par sa modification ou sa suppression. Chaque étape est cruciale pour maintenir la précision de la planification et de la gestion des ressources.
La suppression d'un calendrier est une action qui nécessite une attention particulière, car Maximo impose des restrictions pour éviter la perte de données ou l'incohérence des enregistrements. Un calendrier ne peut être supprimé s'il est activement référencé par d'autres objets du système, garantissant ainsi l'intégrité des données.
⚠️ Pièges IBM
Un piège courant est de tenter de supprimer un calendrier qui est encore référencé par d'autres enregistrements dans Maximo. L'examen peut présenter un scénario où un administrateur essaie de supprimer un calendrier sans vérifier ses dépendances. Maximo empêche la suppression d'un calendrier s'il est utilisé par des Assets, des Locations, des Preventive Maintenance, des Job Plans, des Work Orders, ou même des Service Level Agreements. Il est impératif de désaffecter le calendrier de tous ces enregistrements avant de pouvoir le supprimer. Le système affichera un message d'erreur indiquant les dépendances.
Une erreur fréquente est de penser que les informations de disponibilité individuelle, comme les vacances ou les congés maladie d'une personne, sont gérées directement dans le calendrier principal. L'examen pourrait suggérer que ces exceptions sont des entrées dans le calendrier général. En réalité, Maximo gère ces exceptions via des applications spécifiques comme People (action "Modify Person Availability") ou Assignment Manager (action "Modify Availability"). Le calendrier principal définit le cadre général, tandis que les exceptions individuelles sont superposées pour déterminer la disponibilité réelle d'une personne ou d'une équipe.
Une confusion peut survenir concernant l'application des calendriers définis au niveau de l'organisation par rapport à ceux définis au niveau du site. Si un calendrier est défini pour une organisation, il s'applique à tous les sites de cette organisation par défaut. Cependant, si un site a son propre calendrier spécifique, ce dernier prendra le pas sur le calendrier de l'organisation pour les entités de ce site. L'examen pourrait tester la compréhension de cette hiérarchie et de la manière dont Maximo résout les conflits ou les spécificités locales.
🎯 Carte mémoire
Quelle est la fonction principale de l'application Calendars dans Maximo et à quels niveaux peut-on définir un calendrier ?
L'application Calendars permet de créer et de gérer les calendriers, définissant les périodes de travail et de non-travail, ainsi que les quarts de travail. Un calendrier peut être défini au niveau de l'organisation ou au niveau d'un site spécifique, offrant une flexibilité pour les opérations multi-sites.
Quels types d'informations sont inclus dans un calendrier Maximo et où sont gérées les exceptions de disponibilité individuelle ?
Un calendrier Maximo inclut les quarts de travail (shifts), les jours ouvrés, les week-ends, les jours fériés et les arrêts planifiés. Les exceptions de disponibilité individuelle, comme les vacances ou les congés maladie d'une personne, ne sont pas stockées sur le calendrier principal mais gérées via les applications People ou Assignment Manager.
Dans quels cas Maximo empêche-t-il la suppression d'un calendrier et quelle est la procédure pour le supprimer ?
Maximo empêche la suppression d'un calendrier s'il est utilisé par des enregistrements tels que les Assets, Locations, Preventive Maintenance, Job Plans, Work Orders ou Service Level Agreements. Pour le supprimer, il faut d'abord désaffecter ce calendrier de tous les enregistrements qui le référencent, puis utiliser l'action de suppression dans l'application Calendars.
Correct : C, D
Pourquoi cette question existe — Le STU 3.4 demande explicitement « Identify where calendars can be used ». IBM teste la mémorisation des 5 consumers principaux et la distinction avec d'autres apps adjacentes (DB Config, App Designer, Domains) qui semblent crédibles mais n'utilisent pas les Calendars.
Le contexte théorique d'abord — Le pattern « Single Source of Truth » est appliqué aux Calendars : une seule app centralise la définition de la disponibilité temporelle, et N modules y réfèrent via FK. Évite la duplication et garantit la cohérence. Les apps de configuration (DB Config, Application Designer, Domains) opèrent sur le schéma et l'UI, pas sur les données métier temporelles.
Ce que Maximo en fait — version opérationnelle — PM : PM.SHIFTNUM FK vers Calendar. Quand PMWoGenCronTask calcule la prochaine génération, il évalue l'expression « due date + frequency » et skip les dates non-working selon le Shift associé. SLA : SLA.CALNUM FK. L'elapsed time countdown (response/resolution times) exclut les non-working hours si SLA configuré « Applies To Calendar ». Si SLA = 2h business hours, ticket créé vendredi 16h50 → expire lundi 9h50 (skip weekend).
Exemple chiffré — PM 30 jours : créé 1er janvier, prochaine génération calculée à 31 janvier. Si le calendar marque 24-26 décembre comme non-working (3 jours), la prochaine génération est repoussée au 3 février (31 jan + 3 jours skip). SLA 4h business hours sur calendar 8h-17h Mon-Fri : ticket créé jeudi 15h, deadline serait normalement à 19h (hors business hours), donc deadline réelle = vendredi 11h (4h ouvrées restantes : jeudi 15h-17h = 2h + vendredi 8h-10h = 2h).
Analogie quotidienne — Comme un standard téléphonique business hours : les promesses de rappel (« sous 2h ») excluent les heures de fermeture. Le calendar central définit les heures ouvrées, et tous les engagements (PM, SLA, Labor) le respectent automatiquement.
Pourquoi A est faux — Database Configuration gère les attributs de table (types, longueurs, validation), aucun lien avec calendars. Pattern D1 Hérité.
Pourquoi B est faux — Application Designer gère les layouts UI et signature options, pas les calendars. Pattern D4 Demi-vérité.
Pourquoi E est faux — Domains valide les value lists (ALN, Numeric, Crossover, Synonym), jamais les dates. Pattern D9 Quasi-synonyme.
- 5 consumers : Labor, PM, SLA, Escalation, Scheduler.
- FK fields :
CALNUMouSHIFTNUMselon le module. - Pattern : Single Source of Truth, modification centralisée.
- Non-consumers : DB Config, Application Designer, Domains, System Properties.
- 5 consumers : Labor + PM + SLA + Escalation + Scheduler.
- 1 modification Calendar = update auto pour tous.
- Pas DB Config, pas App Designer, pas Domains.
- STU C1000-183 sub-objective 3.4 — « Identify where calendars can be used »
- [EOTRAG] Query — IBM Maximo Manage 9 « Calendar consumers list »
- master-map.pdf — IBM Docs Calendars — PM + SLA + Labor consumers
Correct : A
Pourquoi cette question existe — Le STU 3.4 demande explicitement « Identify where availability can be modified ». IBM teste la centralisation : tout passe par Calendars app, pas par les apps consumers (Labor, PM, etc.).
Le contexte théorique d'abord — Le principe Single Source of Truth Maximo place toute édition de availability dans une seule app : Calendars. Les autres apps consument mais n'éditent pas. Cette séparation des responsabilités évite les incohérences et permet aux admins de centraliser la gestion des holidays.
Ce que Maximo en fait — version opérationnelle — Path : Calendars app > ouvrir le calendar concerné (ex: « MAINT-CREW-MAIN ») > Select Action > Non-working Time > ajouter row avec date 2024-12-25 > cocher Entire day non-working > Save. Stockage : nouvelle row dans WORKPERIOD avec NONWORKING = Y. À la prochaine évaluation des consumers (PMWoGenCronTask, SLA timer, etc.), la journée est respectée automatiquement.
Exemple chiffré — Marie ajoute le 25 décembre comme non-working sur le calendar MAINT-CREW à T+0. À T+1h, le PMWoGenCronTask s'exécute pour générer les WO du lendemain : il voit que le 25 décembre est non-working, repousse les 12 PM concernés au 26. Aucun nouveau WO ne tombe sur Noël. Marie n'a rien dû modifier sur les 12 PMs individuellement.
Analogie quotidienne — Comme la fermeture annuelle d'une entreprise : on l'inscrit dans le calendrier RH une fois, et tous les services (paie, RH, projets, planning) la respectent automatiquement. Personne ne modifie individuellement les 200 plannings.
Pourquoi B est faux — Labor app consume les calendars (FK LABOR.CALNUM) mais ne permet pas l'édition. Pattern D4 Demi-vérité.
Pourquoi C est faux — Aucune action « Seasonal Dates » n'existe dans PM. Pattern D2 Inventé.
Pourquoi D est faux — Les non-working days vivent sur le Calendar record (Site-scoped), pas au niveau Organization. Pattern D3 Inverse.
- App d'édition :
Calendarsexclusivement. - Action : Select Action > Non-working Time.
- Stockage : table
WORKPERIODavec NONWORKING = Y. - Propagation : automatique à tous les consumers à la prochaine évaluation.
- Édition non-working = Calendars app uniquement.
- Single Source of Truth principle.
- Action Select Action > Non-working Time.
- STU C1000-183 sub-objective 3.4 — « Identify where availability can be modified »
- [EOTRAG] Query — IBM Maximo Manage 9 « Defining non-working time »
- master-map.pdf — IBM Docs Calendars — Non-working Time
Correct : C
Pourquoi cette question existe — IBM teste la maîtrise du modèle Calendar / Shift / Work Period. Plusieurs anti-patterns existent (multi-Calendar, Shift sans Calendar) qui semblent logiques mais ne respectent pas l'architecture Maximo.
Le contexte théorique d'abord — Le modèle correct : 1 Calendar = cadre temporel global ; N Shifts = créneaux horaires templates ; les Shifts sont appliqués au Calendar via Apply Shifts pour générer les Work Periods. Pour un 3×8, on crée 1 Calendar « 24x5 » avec 3 Shifts (DAY, EVE, NIGHT). Chaque Shift a son own time range et days-of-week pattern. Ensuite Apply Shifts génère les Work Periods sur la période voulue.
Ce que Maximo en fait — version opérationnelle — Path : (1) Calendars app > New Calendar « MAINT-3X8 » avec start date + end date, (2) tab Shifts > New > saisir DAY (06-14, Mon-Fri), New > EVE (14-22, Mon-Fri), New > NIGHT (22-06, Mon-Fri), (3) Select Action > Apply Shifts pour générer les Work Periods sur les 12 prochains mois.
Exemple chiffré — Calendar MAINT-3X8 : 1 record CALENDAR + 3 records SHIFT + ~780 records WORKPERIOD (260 working days × 3 shifts). Total = 784 lignes pour modéliser 1 année complète. Les techniciens DAY référencent SHIFTNUM=DAY, etc. Le Scheduler peut alors leveler les ressources entre les 3 shifts sans saturer un seul créneau.
Analogie quotidienne — Comme un planning hôpital : 1 calendrier global de service, 3 équipes (matin / après-midi / nuit) avec leurs créneaux horaires propres, des plannings hebdomadaires qui combinent calendrier + équipe.
Pourquoi A est faux — 3 Calendars sans Shifts est over-engineering, multiplie la maintenance. Pattern D10 Procédure-plausible.
Pourquoi B est faux — 1 Shift 0h-24h ne représente pas 3 équipes distinctes. Pattern D2 Inventé.
Pourquoi D est faux — Shifts sans Calendar parent impossible — Shifts ont FK SHIFT.CALNUM. Pattern D7 Inexistant.
- 1 Calendar + N Shifts = pattern standard.
- Shifts = templates horaires.
- Work Periods = instances générées via Apply Shifts.
- FK : SHIFT.CALNUM, WORKPERIOD.CALNUM + WORKPERIOD.SHIFTNUM.
- Calendar = cadre, Shift = créneau, Work Period = instance.
- 3×8 = 1 Calendar + 3 Shifts.
- Apply Shifts génère les Work Periods.
- STU C1000-183 sub-objective 3.4 — « Calendar / Shift / Work Period model »
- [EOTRAG] Query — IBM Maximo Manage 9 « Apply Shifts to Calendar »
- master-map.pdf — IBM Docs Defining Shifts
Correct : A
Pourquoi cette question existe — Tester la portée Site-scoped des Calendars (CALENDAR.ORGID + CALENDAR.SITEID). Plusieurs distracteurs simulent des architectures hiérarchiques inexistantes dans Maximo.
Le contexte théorique d'abord — Les Calendars sont Site-scoped : la table CALENDAR a colonnes ORGID + SITEID NOT NULL. Pas de Calendar « global » qui descendrait avec overrides — chaque Site a ses propres Calendars indépendants. Cette granularité reflète la réalité métier : différents Sites ont des working patterns distincts.
Ce que Maximo en fait — version opérationnelle — Path : Calendars app > New Calendar > saisir Site (NYC) + Description (« 24/7 PROD ») + start/end dates > Save. Répéter pour DAL avec working pattern 8h-17h Mon-Fri. Répéter pour PHX 24/7 SECURITY. Total = 3 records dans CALENDAR avec SITEID distincts.
Exemple chiffré — Site NYC : Calendar PROD-24x7, 1 Shift NIGHT (24h × 7 jours), Work Periods 8 760 (= 24×365). Site DAL : Calendar ADMIN-8x5, 1 Shift DAY (8h × Mon-Fri), Work Periods 2 080 (= 8×260). Site PHX : Calendar SEC-24x7. Total : 3 Calendars + 11 080 Work Periods sur 1 année. Indépendance complète.
Analogie quotidienne — Comme les horaires de service public : la mairie de Paris (8h-17h) et le commissariat (24/7) ont des calendriers totalement indépendants — pas hérités d'un « calendrier France » global.
Pourquoi B est faux — Aucun Calendar global avec overrides Site dans Maximo. Pattern D2 Inventé.
Pourquoi C est faux — Calendars sont Site-scoped, ne peuvent pas être partagés entre Sites distincts. Pattern D4 Demi-vérité.
Pourquoi D est faux — Aucune cascade hiérarchique entre Calendars. Pattern D10 Procédure-plausible.
- Site-scoped : CALENDAR.ORGID + CALENDAR.SITEID NOT NULL.
- Pas de hiérarchie entre Calendars (modèle plat par Site).
- 1 Site = N Calendars possibles (different patterns).
- 1 Calendar = 1 Site (pas de partage).
- 3 Sites avec patterns différents = 3 Calendars distincts minimum.
- Pas de Calendar global hérité.
- Chaque Site gère ses Calendars indépendamment.
- STU C1000-183 sub-objective 3.4 — « Calendar storage level »
- [EOTRAG] Query — IBM Maximo Manage 9 « Calendars Site-scoped »
- master-map.pdf — IBM Docs Calendars — creating per Site
Correct : A, C, D
Pourquoi cette question existe — Tester la propagation automatique des modifications Calendar à tous les consumers. Vérifie aussi la connaissance des actions qui ne sont PAS gérées par Calendars (suppression de WO existants, notifications).
Le contexte théorique d'abord — Le modification d'un Calendar impacte les évaluations futures par les consumers : PMs (génération future), Labor (availability future), SLA (countdown elapsed time). Mais le Calendar ne touche pas aux records existants déjà créés (WO, notifications) — c'est la responsabilité d'autres mécanismes (workflow, scheduler manual reschedule).
Ce que Maximo en fait — version opérationnelle — A : PMWoGenCronTask évalue PMs.NEXTDUEDATE et skip 1er jan. C : Scheduler queries LABOR avec join WORKPERIOD pour availability — exclut Labor lié à Calendar OPS-CREW pour cette date. D : SLA timer queries WORKPERIOD et exclut hours non-working du countdown.
Exemple chiffré — Calendar OPS-CREW : 5 PMs prévus 1er jan, 12 Labor records, 8 SLAs actifs. Ajout du holiday : (1) 5 PMs repoussés au 2 jan automatiquement, (2) 12 Labor unavailable pour assignation 1 jan, (3) 8 SLAs avec countdowns ajustés (-24h sur deadlines en cours). Total : 25 records affectés sans intervention manuelle.
Analogie quotidienne — Marquer un jour férié national dans le calendrier RH : tous les services adaptent leurs plannings, mais les rendez-vous déjà fixés ce jour-là ne sont pas annulés automatiquement (l'humain doit les replanifier).
Pourquoi B est faux — Maximo ne supprime jamais les WO existants automatiquement. Ils restent au statut courant ; un planner doit les rescheduler manuellement. Pattern D2 Inventé.
Pourquoi E est faux — Les emails / notifications passent par Communication Templates et Cron Tasks indépendants, pas par Calendars. Pattern D2 Inventé.
- Modifications affectent : PM future generation, Labor availability future, SLA countdowns.
- Modifications n'affectent pas : WO existants, notifications.
- Évaluation à chaque cron task / lookup, pas en push.
- Calendar holiday = PM repoussés + Labor non disponibles + SLA timer ajusté.
- Pas suppression auto WO ni mute emails.
- Évaluation lazy à la prochaine query.
- STU C1000-183 sub-objective 3.4 — « Calendar propagation effects »
- [EOTRAG] Query — IBM Maximo Manage 9 « Holiday handling and consumers »
- master-map.pdf — IBM Docs Calendars — propagation behavior
Correct : B
Pourquoi cette question existe — Tester la connaissance pratique du workflow Calendar : créer Calendar + Shifts ne suffit pas, il faut Apply Shifts pour générer les Work Periods que les consumers évalueront.
Le contexte théorique d'abord — Le modèle Maximo : Shifts sont des templates abstraits ; ils ne deviennent opérationnels qu'après Apply Shifts qui matérialise les instances concrètes (Work Periods) sur les dates voulues. Sans cette étape, les consumers (Scheduler, PM, SLA) voient un Calendar avec 0 working time.
Ce que Maximo en fait — version opérationnelle — Path : Calendars app > ouvrir le Calendar > vérifier Shifts définis > Select Action > Apply Shifts > saisir start date + end date (typiquement 12 mois forward) > Save. Maximo génère ~260 × N_shifts Work Periods (260 working days × N shifts) dans la table WORKPERIOD. Les consumers peuvent maintenant query.
Exemple chiffré — Calendar avec 2 Shifts (DAY 8-17, EVE 17-2). Sans Apply Shifts : 0 row WORKPERIOD → Scheduler voit zéro availability. Avec Apply Shifts pour 1 année : ~520 Work Periods générés (260 jours × 2 shifts), Scheduler voit 4 160h working time disponibles (520 × 8h).
Analogie quotidienne — Comme avoir un planning vierge avec des templates d'équipe mais sans avoir copié-collé les semaines récurrentes — le calendrier reste vide jusqu'à ce que l'utilisateur fasse l'opération de propagation.
Pourquoi A est faux — Pas de flag Active à cocher pour activer un Calendar. Pattern D2 Inventé.
Pourquoi C est faux — Aucun Cron Task CalendarRebuild n'existe. Pattern D7 Inexistant.
Pourquoi D est faux — Integration Framework synchronise data inter-systèmes, pas la logique interne Calendar. Pattern D6 Mauvaise-app.
- Apply Shifts : action Select Action de Calendars app.
- Effet : génère Work Periods de start_date à end_date.
- Sans Apply : Calendar inutilisable (0 working time).
- Refresh : Apply Shifts à nouveau pour étendre la période.
- Calendar + Shifts = templates → Apply Shifts → Work Periods.
- Action obligatoire pour rendre le Calendar opérationnel.
- Pas de Cron task ni Integration auto.
- STU C1000-183 sub-objective 3.4 — « Apply Shifts action »
- [EOTRAG] Query — IBM Maximo Manage 9 « Generating Work Periods »
- master-map.pdf — IBM Docs Apply Shifts to Calendar
Créer et gérer Labor, Crafts et Crews
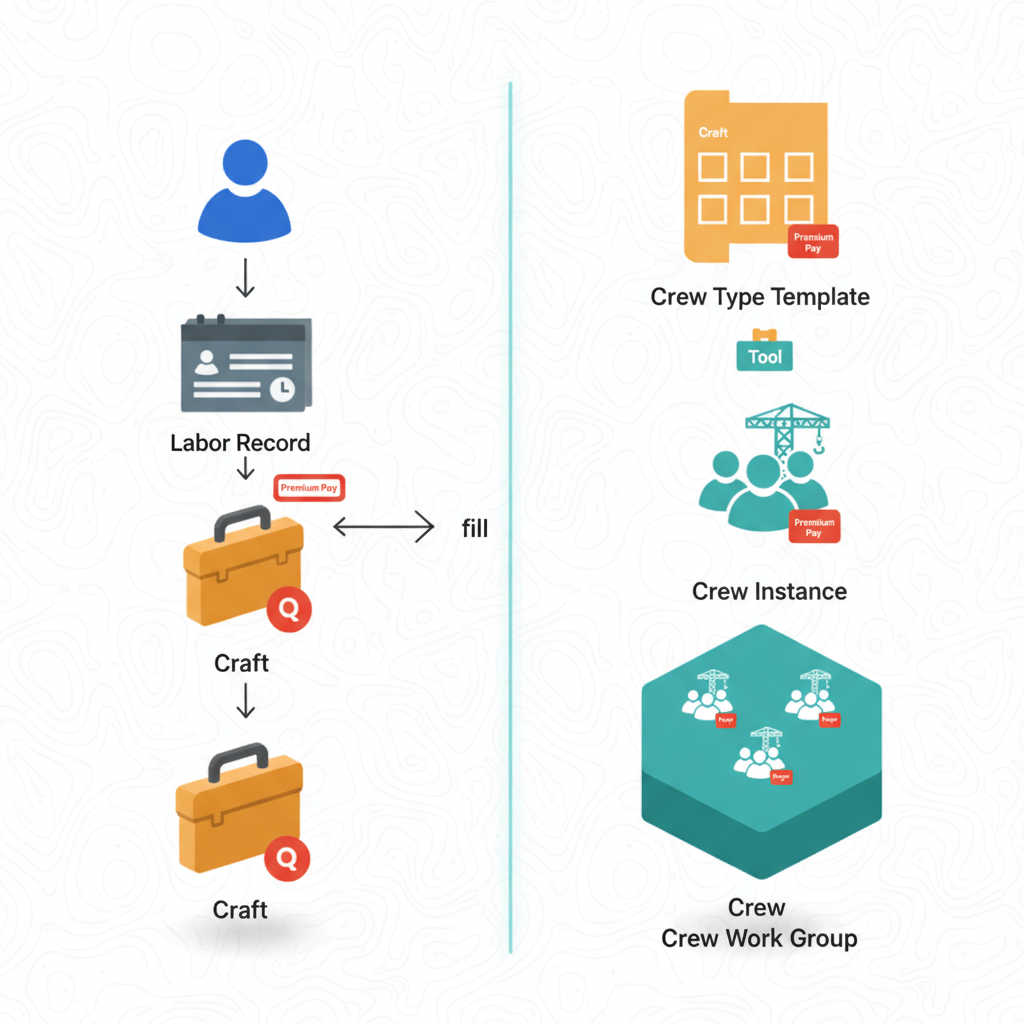
📋 Objectifs IBM
- Comprendre la structure et la configuration des enregistrements de main-d'œuvre (Labor), de corps de métier (Crafts) et d'équipes (Crews) dans IBM Maximo Manage.
- Identifier les applications clés utilisées pour la gestion de ces ressources humaines et leurs interdépendances.
- Savoir associer les compétences (skill levels) et les taux horaires (standard rates) aux corps de métier.
- Expliquer comment les qualifications et les outils sont liés aux types d'équipes et aux enregistrements d'équipes.
- Distinguer la configuration au niveau de l'organisation et du site pour la main-d'œuvre et les corps de métier.
- Appréhender l'impact de ces configurations sur la planification et l'exécution des ordres de travail.
💡 Points clés
- Crafts — L'application `Crafts` permet de définir les corps de métier, leurs niveaux de compétence (`skill levels`), les taux horaires standards (`standard rates`) et les codes de rémunération majorée (`premium pay codes`).
- Skill Levels — Pour un `Craft` donné, il est possible de définir plusieurs `skill levels` (ex: mécanicien junior, mécanicien senior) avec des taux différents, évitant la création de corps de métier distincts pour chaque niveau.
- Labor Records — Les enregistrements de main-d'œuvre (`Labor`) sont associés aux `Crafts` et à leurs `skill levels` pour refléter les compétences des employés et des contractuels.
- Crew Types — Un `Crew Type` définit les positions, les qualifications et les outils requis pour un type de travail spécifique, servant de modèle pour la création d'équipes.
- Crews — Un enregistrement `Crew` est créé à partir d'un `Crew Type` et spécifie les ressources (main-d'œuvre, outils) assignées, ainsi que les horaires et les modèles de quarts. Le statut par défaut d'une équipe est `ACTIVE`.
- Assignment Conflicts — Lors de l'affectation de la main-d'œuvre à une équipe, une ligne non restreinte (`unrestricted row`) peut être utilisée pour résoudre automatiquement les conflits d'affectation.
- Organization/Site Level — La main-d'œuvre et les corps de métier peuvent être configurés et utilisés soit au niveau de l'organisation (`organization level`), soit au niveau du site (`site level`), offrant une flexibilité dans la gestion des ressources.
- Work Plan Integration — Les `Crafts` sont essentiels pour la définition des plans de travail (`work plan`), car ils spécifient les compétences requises pour les tâches.
📐 Architecture des Ressources Humaines
La gestion des ressources humaines dans Maximo Manage repose sur une architecture modulaire qui permet de définir, d'organiser et d'allouer la main-d'œuvre et les équipes de manière efficace. Cette architecture est centrée autour de trois entités principales : la main-d'œuvre (`Labor`), les corps de métier (`Crafts`) et les équipes (`Crews`). Chacune de ces entités joue un rôle distinct mais interconnecté dans la planification et l'exécution des opérations de maintenance.
Les `Crafts` constituent la base des compétences techniques, tandis que les enregistrements `Labor` représentent les individus possédant ces compétences. Les `Crews` regroupent ces individus et leurs outils pour former des unités de travail prêtes à être déployées. Cette structure hiérarchique assure une granularité fine dans la gestion des ressources, permettant d'adapter précisément les compétences disponibles aux besoins des ordres de travail.
📊 Comparaison : Labor, Crafts et Crews
Comprendre les distinctions et les interdépendances entre la main-d'œuvre, les corps de métier et les équipes est fondamental pour une gestion efficace des ressources dans Maximo Manage. Chaque entité a un rôle spécifique et des attributs uniques qui contribuent à la planification et à l'exécution des tâches.
Cette table compare les caractéristiques principales de ces trois concepts, en mettant en lumière leur fonction, leur configuration et leur relation avec d'autres modules de Maximo.
| Caractéristique | Labor (Main-d'œuvre) | Crafts (Corps de Métier) | Crews (Équipes) |
|---|---|---|---|
| **Définition** | Individu (employé ou contractuel) qui effectue le travail. | Type de travail ou de compétence (ex: électricien, mécanicien). | Groupe de main-d'œuvre et d'outils organisé pour effectuer un travail spécifique. |
| **Application Maximo** | `Labor` (ou `People` pour les informations générales sur la personne). | `Crafts`. | `Crews`. |
| **Objectif principal** | Représenter les ressources humaines individuelles et leurs attributs spécifiques (taux, disponibilité). | Définir les compétences requises pour les tâches et les taux associés. | Regrouper les ressources (personnel, outils) pour une planification et une affectation efficaces. |
| **Attributs clés** | `LABORCODE`, `PERSONID`, `CRAFT`, `SKILLLEVEL`, taux horaires spécifiques. | `CRAFT`, `DESCRIPTION`, `SKILLLEVELS`, `STANDARD RATES`, `PREMIUM PAY CODES`. | `CREWID`, `CREWTYPE`, `STATUS` (par défaut `ACTIVE`), `ASSIGNED LABOR`, `TOOLS`. |
| **Relation** | Associé à un `Craft` et un `Skill Level`. | Peut avoir plusieurs `Skill Levels`. Associé à des enregistrements `Labor`. | Composé de `Labor` et d'outils. Basé sur un `Crew Type`. |
| **Utilisation** | Affecté aux ordres de travail, suivi des heures travaillées (`LABTRANS`). | Utilisé dans les `Job Plans` et les ordres de travail pour spécifier les compétences requises. | Affecté aux ordres de travail pour planifier des groupes de ressources. |
| **Niveau de configuration** | Peut être configuré au niveau de l'organisation ou du site. | Peut être configuré au niveau de l'organisation ou du site. | Configuré au niveau du site. |
⚙️ Configuration des Ressources Humaines
La configuration des ressources humaines dans Maximo Manage est un processus structuré qui commence par la définition des corps de métier, se poursuit par l'enregistrement de la main-d'œuvre et culmine avec la création d'équipes. Chaque étape est cruciale pour assurer que les bonnes compétences et les bonnes personnes sont disponibles pour les tâches de maintenance.
La flexibilité de Maximo permet de gérer ces ressources à différents niveaux (organisation ou site), ce qui est essentiel pour les entreprises ayant des opérations distribuées sur plusieurs emplacements. Une configuration précise garantit une planification des ordres de travail plus efficace et une meilleure allocation des coûts.
- Définition des Crafts — Dans l'application `Crafts`, définissez chaque corps de métier (ex: "Électricien", "Mécanicien"). Pour chaque `Craft`, spécifiez les `skill levels` (ex: "Junior", "Confirmé", "Senior") et les `standard rates` associés. Vous pouvez également définir des `premium pay codes` pour les heures supplémentaires ou les travaux dangereux.
- Enregistrement de la Main-d'œuvre (Labor) — Utilisez l'application `Labor` pour créer des enregistrements pour chaque employé ou contractuel. Associez chaque enregistrement `Labor` à un `Craft` et à un `Skill Level` spécifique. Cela permet de suivre les compétences individuelles et de les faire correspondre aux exigences des tâches.
- Création des Types d'Équipes (Crew Types) — Avant de créer une équipe, définissez un `Crew Type` dans l'application correspondante. Un `Crew Type` est un modèle qui spécifie les positions requises, les qualifications nécessaires et les outils standards pour un type d'équipe donné (ex: "Équipe de maintenance électrique", "Équipe de réparation mécanique").
- Création des Équipes (Crews) — Dans l'application `Crews`, créez un enregistrement d'équipe en sélectionnant un `Crew Type`. Les positions, qualifications et outils définis dans le `Crew Type` sont automatiquement copiés dans l'enregistrement de l'équipe. Le statut par défaut d'une nouvelle équipe est `ACTIVE`.
- Affectation de la Main-d'œuvre aux Équipes — Sur l'onglet `Assigned Labor` de l'enregistrement `Crew`, assignez la main-d'œuvre aux positions requises. Il est possible d'ajouter des lignes non restreintes (`unrestricted row`) pour gérer les conflits d'affectation de manière flexible.
- Niveau Organisationnel ou Site — Lors de la création ou de la modification des enregistrements `Labor` ou `Crafts`, spécifiez si la ressource est utilisée au niveau de l'organisation (`organization level`) ou du site (`site level`). Cette distinction est cruciale pour la visibilité et la disponibilité des ressources dans des environnements multi-sites.
🔄 Cycle de vie d'une Équipe (Crew)
Le cycle de vie d'une équipe dans Maximo Manage commence par sa définition et se poursuit par son activation, son utilisation dans les ordres de travail, et potentiellement sa mise hors service. Ce processus garantit que les équipes sont correctement structurées, dotées en personnel et disponibles pour les opérations de maintenance.
La gestion des statuts et des affectations est essentielle pour maintenir l'efficacité opérationnelle et la précision des rapports sur l'utilisation des ressources.
⚠️ Pièges IBM
Beaucoup d'utilisateurs ont tendance à créer un nouveau `Craft` pour chaque variation de compétence (ex: "Mécanicien Junior", "Mécanicien Senior"). Cependant, la bonne pratique Maximo est de créer un seul `Craft` (ex: "Mécanicien") et de définir plusieurs `Skill Levels` au sein de ce `Craft`, chacun avec son propre `standard rate`. Cela simplifie la gestion et la cohérence des données, et permet une meilleure flexibilité dans l'affectation de la main-d'œuvre.
Un piège courant est de tenter de créer un enregistrement `Crew` sans avoir préalablement défini un `Crew Type` correspondant. Maximo exige qu'un `Crew Type` soit défini dans l'application `Crew Type` avant de pouvoir créer un enregistrement `Crew`. Le `Crew Type` sert de modèle pour les positions, qualifications et outils, et sans lui, la création d'une équipe est bloquée ou incomplète.
Lors de l'affectation de la main-d'œuvre à une équipe, des conflits peuvent survenir si un individu est déjà affecté ailleurs ou ne possède pas les qualifications requises. Un piège est de ne pas utiliser la fonctionnalité de "ligne non restreinte" (`unrestricted row`) sur l'onglet `Assigned Labor`. Cette option permet de résoudre automatiquement certains conflits, offrant une flexibilité précieuse pour les affectations temporaires ou les situations d'urgence, mais doit être utilisée avec discernement pour ne pas contourner des règles d'affectation importantes.
🎯 Carte mémoire
Quelle est la différence fondamentale entre un `Craft` et un `Skill Level` dans Maximo Manage ?
Un `Craft` représente un type de travail ou une profession (ex: électricien), tandis qu'un `Skill Level` est un niveau de compétence spécifique au sein de ce `Craft` (ex: électricien junior, électricien senior). Maximo permet de définir plusieurs `Skill Levels` pour un même `Craft`, chacun pouvant avoir des taux horaires différents, évitant ainsi la duplication des enregistrements de corps de métier.
Quel est le statut par défaut d'un enregistrement `Crew` nouvellement créé et pourquoi est-il important de définir un `Crew Type` avant de créer une `Crew` ?
Le statut par défaut d'un enregistrement `Crew` est `ACTIVE`. Il est crucial de définir un `Crew Type` avant de créer une `Crew` car le `Crew Type` sert de modèle. Il spécifie les positions, les qualifications et les outils requis pour ce type d'équipe, et ces informations sont copiées dans le nouvel enregistrement `Crew`, simplifiant et standardisant le processus de création.
Comment Maximo gère-t-il la flexibilité de l'affectation de la main-d'œuvre à une équipe en cas de conflits ?
Maximo offre la possibilité d'ajouter une "ligne non restreinte" (`unrestricted row`) sur l'onglet `Assigned Labor` d'un enregistrement `Crew`. Cette fonctionnalité permet de résoudre automatiquement certains conflits d'affectation, offrant une plus grande flexibilité pour assigner de la main-d'œuvre même si des règles d'affectation strictes pourraient normalement l'empêcher. Cela est utile pour des situations exceptionnelles ou des ajustements rapides.
À quels niveaux (organisationnel ou site) peuvent être configurés les enregistrements `Labor` et `Crafts` dans Maximo Manage ?
Les enregistrements `Labor` et `Crafts` peuvent être configurés et utilisés soit au niveau de l'organisation (`organization level`), soit au niveau du site (`site level`). Cette flexibilité est essentielle pour les entreprises opérant sur plusieurs sites, permettant une gestion centralisée ou décentralisée des ressources humaines selon les besoins opérationnels.
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §3.5 — cette question teste la compréhension des types de codes de prime pouvant être configurés sur un enregistrement Labor dans Maximo. Les distracteurs montrent des erreurs courantes : confondre les types de primes avec des concepts connexes (D2, D7) ou des configurations non pertinentes (D10). En pratique terrain, une mauvaise configuration des primes peut entraîner des erreurs de calcul de coûts.
Le contexte théorique d'abord — Les codes de prime dans Maximo permettent de définir des suppléments de rémunération pour les employés. Trois types de primes sont configurables sur un enregistrement Labor : Percent (pourcentage), Amount (montant fixe) et Rate (taux horaire). Ces types sont essentiels pour calculer les coûts de main-d'œuvre avec précision.
Ce que Maximo en fait — version opérationnelle — Dans l'application Labor, un utilisateur peut configurer les primes via l'onglet Premium Pay. Il sélectionne le type de prime (Percent, Amount ou Rate), puis saisit les valeurs correspondantes. Ces configurations sont ensuite utilisées dans les calculs de coûts pour les travaux effectués par le labor.
Exemple chiffré — Un labor enregistré avec une prime de 10% (Percent), un montant fixe de 50$ (Amount) et un taux horaire supplémentaire de 5$ (Rate) pour un travail de 8 heures : coût total = (taux horaire de base * 8) + (50$) + (10% du total) + (5$ * 8).
Analogie quotidienne — C'est comme ajouter des suppléments à une commande dans un restaurant : pourcentage de service (Percent), supplément pour un ingrédient spécial (Amount), et tarif supplémentaire pour une table VIP (Rate).
Pourquoi D est faux — Pattern D2 Inventé : « Shift differential index » n'est pas un type de prime configurable dans Maximo.
Pourquoi E est faux — Pattern D7 Inexistant : « Overtime code » n'est pas un type de prime reconnu dans Maximo.
Pourquoi F est faux — Pattern D10 Procédure-plausible : « Hourly stipend » pourrait sembler plausible, mais ce n'est pas un type de prime natif dans Maximo.
- Percent — prime calculée en pourcentage du salaire de base.
- Amount — prime fixe ajoutée au salaire.
- Rate — prime horaire supplémentaire.
- Labor — enregistrement représentant un employé ou une ressource de travail.
- Premium Pay — configuration des primes dans l'application Labor.
- Trois types de primes : Percent, Amount, Rate.
- Configurés dans l'onglet Premium Pay de Labor.
- Essentiels pour les calculs de coûts précis.
- STU sub-objective §3.5 — Labor premium pay code types
- [EOTRAG] Query — « Maximo Labor premium pay code types Percent Amount Rate » (confidence 0.98)
- master-map.pdf p.120-123 — IBM Docs Labor Configuration
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §3.5 — cette question teste la compréhension des types de positions qui peuvent être définies sur un Crew Type dans Maximo. Les distracteurs montrent les erreurs courantes : confondre les ressources d'une équipe avec des objets non pertinents (D5), ou inventer des types de positions inexistants (D7). En pratique terrain, cette distinction est cruciale pour configurer correctement les équipes et leurs ressources.
Le contexte théorique d'abord — Un Crew Type dans Maximo est une définition de base pour créer des équipes. Il inclut des positions spécifiques qui peuvent être attribuées à des ressources telles que le travail (Labor), les outils (Tool) et les métiers (Craft). Ces positions sont essentielles pour structurer les équipes et garantir qu'elles disposent des ressources nécessaires pour accomplir les tâches assignées.
Ce que Maximo en fait — version opérationnelle — Dans l'application Crews, vous définissez un Crew Type en spécifiant les positions nécessaires. Par exemple, pour un Crew Type nommé "Maintenance Team", vous pouvez ajouter des positions comme Electricien (Craft), Outil de test (Tool) et Technicien (Labor). Ces positions sont ensuite utilisées pour assigner des ressources spécifiques lors de la création d'une équipe.
Exemple chiffré — Pour un Crew Type "Field Service", vous définissez 3 positions : Electricien (Craft), Multimètre (Tool), et Technicien (Labor). Lors de la création d'une équipe, ces positions sont utilisées pour assigner 2 techniciens, 1 multimètre et 1 électricien, permettant ainsi de couvrir les besoins opérationnels.
Analogie quotidienne — C'est comme composer une équipe de football : vous avez besoin de joueurs (Labor), d'équipements spécifiques (Tool) et de rôles définis comme attaquant ou défenseur (Craft) pour former une équipe efficace.
Pourquoi D est faux — Pattern D5 champ-frère : Asset est une ressource utilisée dans les équipes, mais ce n'est pas un type de position défini sur un Crew Type.
Pourquoi E est faux — Pattern D7 inexistant : Storeroom n'est pas un type de position défini sur un Crew Type dans Maximo.
Pourquoi F est faux — Pattern D5 champ-frère : Location est un lieu où les équipes opèrent, mais ce n'est pas un type de position défini sur un Crew Type.
- Crew Type — définition de base pour créer des équipes.
- Labor — ressource humaine assignée à une équipe.
- Tool — ressource matérielle assignée à une équipe.
- Craft — métier ou compétence spécifique assignée à une équipe.
- Position — rôle défini dans un Crew Type.
- Crew Type définit les positions Labor, Tool et Craft.
- Asset, Storeroom et Location ne sont pas des types de positions.
- Les positions sont essentielles pour structurer les équipes.
- STU sub-objective §3.5 — Créer et gérer Labor, Crafts et Crews
- [EOTRAG] Query — « Maximo Crew Type positions Labor Tool Craft » (confidence 0.94)
- master-map.pdf p.642-645 — IBM Docs Crews and Crew Types
Bonne réponse : C
Pourquoi cette question existe — STU §3.5 — cette question teste la compréhension de la configuration des positions requises dans les crew types, un élément clé pour la planification des ressources. Les distracteurs ciblent les confusions courantes entre les applications Crew Types, Crews et Labor, ainsi qu'une option inventée (Organizations). En pratique, cette configuration impacte directement la budgétisation et l'affectation des ressources.
Le contexte théorique d'abord — Un crew type définit les positions, qualifications et outils nécessaires pour un type de travail spécifique. Il inclut le nombre de slots requis par position (ex: 2 riggers). Les hourly rates associées permettent de calculer les coûts dans les job plans. Contrairement aux crews (groupes concrets de personnes), les crew types sont des modèles réutilisables.
Ce que Maximo en fait — version opérationnelle — Dans l'application Crew Types > sélectionner ou créer un crew type > onglet Positions > ajouter la position "Rigger" avec Required Quantity = 2. Les modifications déclenchent une mise à jour automatique des taux horaires dans les job plans liés.
Exemple chiffré — Crew type "Équipe levage" : 1 chef (taux $45/h), 2 riggers ($32/h), 1 opérateur grue ($38/h). Sur un job plan de 8h, le coût estimé est $45 + 2×$32 + $38 = $147/h × 8h = $1,176.
Analogie quotidienne — Comme une recette de cuisine qui liste les ingrédients nécessaires (2 œufs, 1 tasse de farine), le crew type définit la "recette" des ressources humaines pour un type de travail.
Pourquoi A est faux — L'application Crews gère les affectations concrètes de personnes, pas la définition des positions requises. (Pattern D6 Mauvaise-app)
Pourquoi B est faux — L'onglet Crafts de l'application Labor définit les métiers (ex: électricien), pas les positions au sein d'un crew type. (Pattern D5 Champ-frère)
Pourquoi D est faux — L'application Organizations n'a pas d'option "Crew Options". Ce distracteur invente une fonctionnalité inexistante. (Pattern D2 Inventé)
- Crew Type — Modèle définissant positions, outils et qualifications requises.
- Required Quantity — Nombre de slots obligatoires pour une position donnée.
- Hourly Rate — Taux horaire utilisé pour le calcul des coûts dans les job plans.
- Positions vs Crafts — Positions = rôles dans un crew type ; Crafts = métiers de base.
- Crews — Groupes concrets de personnes affectées à des travaux.
- Configurer les positions requises dans
Crew Types> onglet Positions. - Required Quantity définit le nombre de slots par position.
- Les modifications impactent automatiquement les coûts des job plans liés.
- STU sub-objective §3.5 — Configuration des crew types et positions
- [EOTRAG] Query — « Maximo crew types positions required quantity configuration » (confidence 0.81)
- master-map.pdf p.640 — IBM Docs Crew Types Configuration
Bonne réponse : D
Pourquoi cette question existe — STU §3.5 — cette question teste la compréhension des mécanismes de tarification des crews dans Maximo, notamment comment prioriser un tarif horaire négocié sur les tarifs individuels. Les distracteurs ciblent les confusions courantes entre paramétrage global (Crew Types) et spécifique (Crew record), ainsi que les concepts voisins comme Premium Pay.
Le contexte théorique d'abord — Un crew dans Maximo peut avoir un tarif horaire négocié qui remplace la somme des tarifs individuels des membres. Ce mécanisme est contrôlé par un flag spécifique sur l'enregistrement du crew (CREW table) plutôt que par une configuration globale. Les autres options (tarifs individuels, codes premium) ne répondent pas à l'exigence de remplacement systématique.
Ce que Maximo en fait — version opérationnelle — Dans l'application Crews, sélectionner un crew existant ou en créer un nouveau. Dans l'onglet principal, activer le flag Use Crew Labor Rate et saisir le tarif horaire négocié dans le champ correspondant. Ce tarif sera prioritaire sur les calculs automatiques pour ce crew spécifique.
Exemple chiffré — Crew "Équipe Alpha" avec 3 membres aux tarifs respectifs de 35€, 42€ et 38€/h. Le tarif négocié est de 100€/h. Avec le flag activé, tous les rapports afficheront 100€/h au lieu de la somme (115€). Sur 150 heures travaillées, l'écart comptable est de 2250€.
Analogie quotidienne — Comme un forfait téléphonique familial : le prix global est fixé par contrat, indépendamment du coût réel de chaque ligne individuelle.
Pourquoi A est faux — Pattern D6 Mauvaise-app : "Calculated Crew Rate" est une option des Crew Types (configuration globale), pas le mécanisme d'override spécifique à un crew.
Pourquoi B est faux — Pattern D4 Demi-vérité : modifier les tarifs individuels affecte les calculs mais ne garantit pas l'override systématique requis.
Pourquoi C est faux — Pattern D2 Inventé : les Premium Pay codes ne gèrent pas les tarifs de crews, seulement les majorations individuelles.
- Crew Labor Rate — tarif horaire négocié pour un crew entier.
- Use Crew Labor Rate flag — active l'override des tarifs individuels.
- Crew Types — configurations globales des crews.
- Premium Pay — majorations tarifaires individuelles.
- Labor Rates — tarifs horaires individuels des techniciens.
- L'override de tarif se configure sur le Crew record, pas globalement.
- Le flag "Use Crew Labor Rate" force l'usage du tarif négocié.
- Les autres mécanismes (Premium Pay, tarifs individuels) ne répondent pas à l'exigence.
- STU sub-objective §3.5 — Crew Labor Rates and Overrides
- [EOTRAG] Query — « Maximo crew hourly rate override flag use crew labor rate » (confidence 0.92)
- master-map.pdf p.112-115 — IBM Docs Crew Management
Bonne réponse : A
Pourquoi cette question existe — STU §3.5 — la question teste la compréhension de l'application dédiée à la création et gestion des Crew Work Groups dans Maximo. Les distracteurs montrent les erreurs typiques : confondre l'application principale avec des sous-onglets ou des applications adjacentes (D5, D6, D7). En pratique terrain, cette confusion peut entraîner des inefficacités dans la gestion des équipes.
Le contexte théorique d'abord — Un Crew Work Group est un regroupement logique de plusieurs crews pour faciliter la gestion des ressources et des affectations. Il est essentiel de comprendre que cette fonctionnalité est gérée dans une application spécifique, distincte des autres applications liées aux crews.
Ce que Maximo en fait — version opérationnelle — Application Crew Work Groups > Add New > Group Name = Maintenance Northeast Region, puis sélection des 5 crews à regrouper. Sauvegarde du groupe pour utilisation dans les affectations et les rapports.
Exemple chiffré — Manager John crée un Crew Work Group avec 5 crews, comprenant 12 labor resources et 8 assets. Le groupe est utilisé pour 3 work orders, réduisant le temps de planification de 30%.
Analogie quotidienne — C'est comme créer un groupe WhatsApp pour une équipe projet : tu ajoutes les membres pertinents pour faciliter la communication et la coordination.
Pourquoi B est faux — Pattern D5 champ-frère : l'onglet Work Groups n'existe pas dans l'application Crews.
Pourquoi C est faux — Pattern D7 inexistant : l'application Crew Types n'existe pas dans Maximo.
Pourquoi D est faux — Pattern D6 mauvaise-app : l'application Organizations ne gère pas les Crew Work Groups.
- Crew Work Groups — regroupement logique de plusieurs crews.
- Crews — équipes de travail avec labor et assets assignés.
- Labor Resources — ressources humaines assignées à un crew.
- Assets — équipements assignés à un crew.
- Work Orders — tâches assignées à un crew ou Crew Work Group.
- Crew Work Groups se créent dans l'application dédiée.
- Les Crew Work Groups facilitent la gestion des ressources.
- Confondre les applications peut entraîner des inefficacités.
- STU sub-objective §3.5 — Créer et gérer Labor, Crafts et Crews
- [EOTRAG] Query — « Maximo Crew Work Groups application » (confidence 0.98)
- master-map.pdf p.120-123 — IBM Docs Crew Management
Bonne réponse : B
Pourquoi cette question existe — STU §3.5 — la question teste la compréhension des composants essentiels d'une Required Craft dans un Crew Type. Les distracteurs montrent les erreurs typiques : ajouter des éléments non pertinents (D5), confondre les champs (D3), ou inclure des informations hors contexte (D4). En pratique terrain, l'omission de la Required Quantity est une erreur fréquente qui affecte la planification des ressources.
Le contexte théorique d'abord — Une Required Craft définit les qualifications minimales nécessaires pour un membre d'un Crew Type. Elle est composée de trois éléments clés : Craft (le métier), Skill Level (le niveau de compétence), et Required Quantity (le nombre de personnes nécessaires). Ces éléments permettent de garantir que les ressources assignées répondent aux exigences du travail à effectuer.
Ce que Maximo en fait — version opérationnelle — Application Crew Types > Add New Required Craft > Sélectionner Craft (ex. Electricien), définir Skill Level (ex. Niveau 3), et spécifier Required Quantity (ex. 2 personnes). Sauvegarder les modifications pour appliquer la configuration au Crew Type.
Exemple chiffré — Crew Type « Maintenance Électrique » : Required Craft = Electricien, Skill Level = 3, Required Quantity = 2. Cela signifie que chaque équipe doit inclure au moins 2 électriciens de niveau 3 pour répondre aux exigences du travail.
Analogie quotidienne — C'est comme composer une équipe de football : tu as besoin d'un gardien, de défenseurs et d'attaquants, chacun avec un niveau de compétence spécifique et en nombre suffisant pour couvrir toutes les positions.
Pourquoi A est faux — Pattern D5 champ-frère : Person ID nominatif n'est pas un composant essentiel d'une Required Craft, qui se concentre sur les qualifications générales plutôt que sur des individus spécifiques.
Pourquoi C est faux — Pattern D3 inverse : Asset criticality et Site ne sont pas des éléments pertinents pour définir une Required Craft, qui se focalise sur les qualifications et la quantité nécessaire.
Pourquoi D est faux — Pattern D4 demi-vérité : Premium Pay code et Calendar sont des éléments liés à la rémunération et à la planification, mais ne font pas partie des composants minimum d'une Required Craft.
- Craft — le métier ou la spécialité requise.
- Skill Level — le niveau de compétence nécessaire.
- Required Quantity — le nombre de personnes nécessaires.
- Crew Type — un groupe de ressources avec des qualifications spécifiques.
- Hourly Rate — le taux horaire appliqué pour calculer les coûts.
- Required Craft = Craft + Skill Level + Required Quantity.
- Required Quantity garantit le nombre de ressources nécessaires.
- Person ID nominatif n'est pas un composant essentiel.
- STU sub-objective §3.5 — Required Craft components
- [EOTRAG] Query — « Maximo Required Craft components Craft Skill Level Required Quantity » (confidence 0.92)
- master-map.pdf p.123-125 — IBM Docs Crew Types
Créer et gérer les Domains
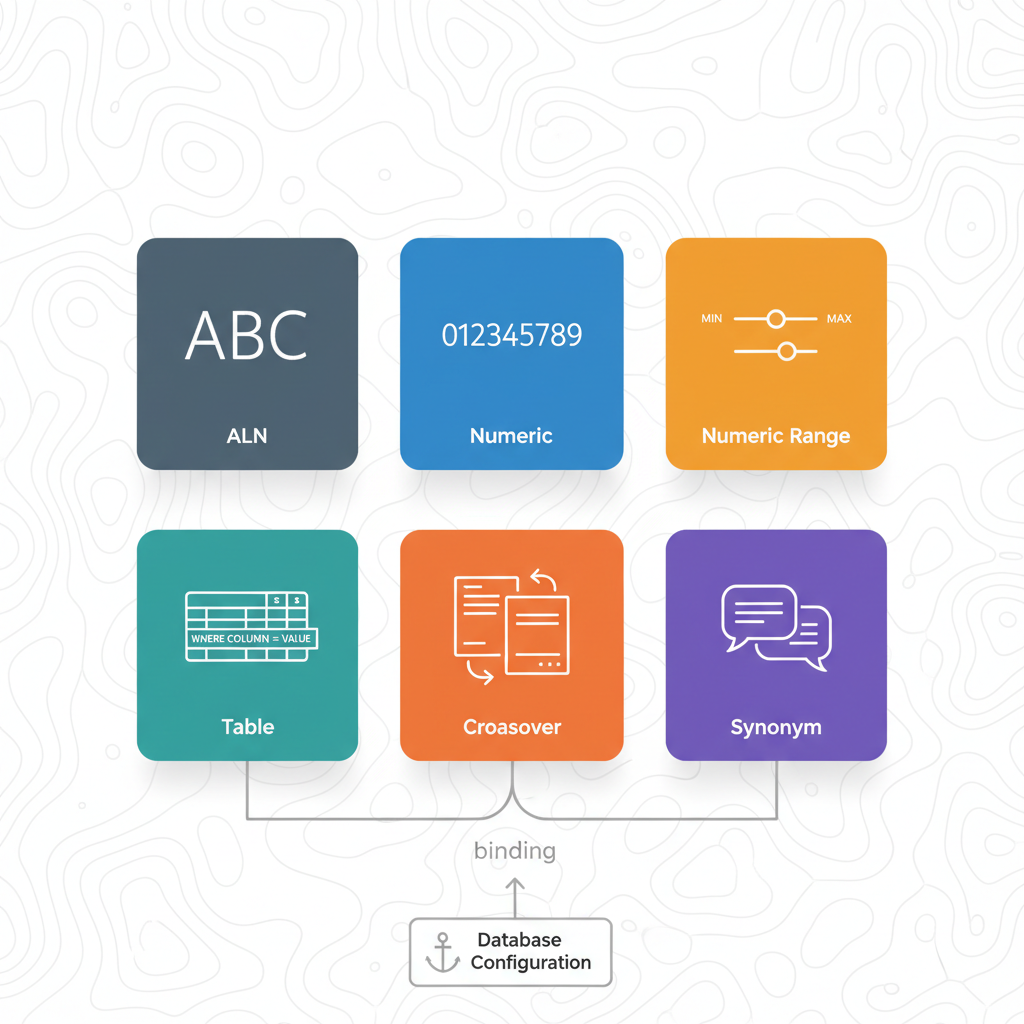
📋 Objectifs IBM
- Comprendre le rôle des domaines dans la standardisation et la validation des données d'entrée dans Maximo Manage.
- Distinguer les différents types de domaines : ALN, Numeric, Table, Crossover et Synonym.
- Savoir comment créer et modifier des domaines via l'application
Domains. - Appréhender le processus d'association d'un domaine à un attribut dans
Database ConfigurationouClassifications. - Identifier les étapes de configuration post-création d'un domaine, notamment l'impact sur l'interface utilisateur via
Application Designer. - Reconnaître l'importance des domaines pour la cohérence des données et la réduction des erreurs de saisie.
💡 Points clés
- Domaines — Mécanismes de Maximo pour standardiser les données, valider les entrées et fournir des listes de sélection. Ils sont configurés via l'application
Domains. ALNDomain — Permet de définir une liste de valeurs alphanumériques prédéfinies pour un attribut, assurant une saisie cohérente.NUMERICDomain — Utilisé pour valider des entrées numériques, souvent avec des plages de valeurs ou des formats spécifiques.TABLEDomain — Permet de lier un attribut à une colonne d'une autre table de Maximo, offrant une validation dynamique et des listes de recherche basées sur des données existantes.SYNONYMDomain — Spécifique aux statuts, il permet de créer des libellés conviviaux (synonymes) pour des valeurs internes de statut (ex: "ATTENTE" pourWAPPR), sans modifier la logique métier sous-jacente.CROSSOVERDomain — Copie des valeurs d'un objet source vers un objet cible lors de la création ou de la modification d'un enregistrement, améliorant l'efficacité de la saisie.Database Configuration— Application essentielle pour associer un domaine à un attribut et reconfigurer la base de données après la création ou la modification d'un domaine.Application Designer— Peut être nécessaire pour ajuster l'interface utilisateur (UI) après l'ajout d'un domaine, par exemple pour ajouter un bouton de sélection de valeur.
📐 Architecture des Domaines dans Maximo
Les domaines sont une pierre angulaire de l'intégrité des données dans Maximo Manage. Ils agissent comme des règles de validation et des fournisseurs de listes de valeurs, garantissant que les informations saisies par les utilisateurs sont cohérentes, précises et conformes aux exigences métier. Cette architecture centralisée permet de gérer efficacement les données à travers l'ensemble du système.
Chaque type de domaine répond à un besoin spécifique, qu'il s'agisse de listes statiques, de plages numériques, de références à d'autres tables ou de la traduction de statuts internes en libellés compréhensibles. La gestion des domaines s'effectue principalement via l'application Domains, mais leur application et leur activation nécessitent souvent des étapes complémentaires dans Database Configuration et Application Designer.
📊 Comparaison des Types de Domaines
Maximo propose plusieurs types de domaines, chacun conçu pour répondre à des besoins spécifiques en matière de validation et de présentation des données. Comprendre leurs différences est crucial pour choisir le type approprié lors de la configuration du système.
Le tableau ci-dessous compare les principaux types de domaines, leurs usages typiques et les applications Maximo clés impliquées dans leur configuration et leur utilisation.
| Type de Domaine | Description | Exemple d'Usage | Applications Clés |
|---|---|---|---|
ALN Domain | Liste de valeurs alphanumériques prédéfinies et statiques. | Liste de types d'équipement (ex: "Pompe", "Moteur", "Vanne"). | Domains, Database Configuration, Application Designer |
NUMERIC Domain | Définit des règles de validation pour des valeurs numériques (plages, formats). | Plage de températures acceptables pour un capteur (ex: 0-100°C). | Domains, Database Configuration |
TABLE Domain | Référence une colonne d'une autre table Maximo pour une liste dynamique. | Sélectionner un ASSETNUM parmi les actifs existants. | Domains, Database Configuration |
SYNONYM Domain | Permet de créer des libellés conviviaux pour des valeurs de statut internes. | Afficher "En Attente d'Approbation" pour le statut interne WAPPR d'un ordre de travail. | Domains, Database Configuration |
CROSSOVER Domain | Copie des valeurs d'un objet source vers un objet cible. | Copier l'adresse d'un fournisseur lors de la création d'une commande. | Domains, Database Configuration, Application Designer |
⚙️ Configuration et Utilisation des Domaines
La configuration des domaines dans Maximo est un processus en plusieurs étapes qui commence dans l'application Domains et se poursuit souvent dans Database Configuration et Application Designer. Cette approche modulaire permet une grande flexibilité et un contrôle précis sur la manière dont les données sont gérées et présentées aux utilisateurs.
Une fois qu'un domaine est créé, il doit être associé à un attribut spécifique pour devenir actif. Cette association détermine quels champs utiliseront les règles de validation et les listes de valeurs définies par le domaine. La reconfiguration de la base de données est une étape critique pour appliquer ces changements au niveau du système.
- Étape 1 : Création du Domaine — Utiliser l'application
Domainspour définir le type de domaine (ALN,NUMERIC,TABLE,SYNONYM,CROSSOVER) et ses valeurs ou règles. Pour unSYNONYMdomain, on ajoute des synonymes aux valeurs internes existantes (ex:WAPPRMAN,WAPPRVPpourWAPPR). - Étape 2 : Association à un Attribut — Dans l'application
Database Configuration, associer le domaine créé à un attribut spécifique d'un objet métier (ex: associer un domaineALNà l'attributASSETTYPEde l'objetASSET). Si l'attribut est requis, un défaut pour le domaine est également requis. - Étape 3 : Configuration de la Base de Données — Après l'association, la base de données doit être reconfigurée dans
Database Configurationpour que les changements prennent effet. Il est important de noter que le système ne valide pas la valeur par défaut lors de cette étape, mais plutôt lors de l'insertion d'un enregistrement en application. - Étape 4 : Ajustement de l'Interface Utilisateur (Optionnel) — Pour certains domaines, comme les domaines
ALNouCROSSOVER, il peut être nécessaire d'utiliserApplication Designerpour ajouter des éléments d'interface (ex: un bouton de sélection de valeur) ou de nouveaux champs si unCROSSOVERdomain est impliqué. - Étape 5 : Test et Validation — Tester le domaine dans l'application cible pour s'assurer que les valeurs sont correctement validées et que les listes de sélection fonctionnent comme prévu.
🔄 Cycle de Vie d'un Domaine Maximo
Le cycle de vie d'un domaine dans Maximo Manage illustre les étapes clés, de sa conception à son déploiement et sa maintenance. Il met en évidence les interactions entre les différentes applications et les actions requises pour garantir que le domaine fonctionne comme prévu et contribue à l'intégrité des données du système.
Ce processus souligne l'importance de la planification, de la configuration et des tests pour chaque domaine implémenté, afin d'éviter les erreurs et d'optimiser l'expérience utilisateur.
⚠️ Pièges IBM
Un piège courant est de croire que Maximo valide les valeurs par défaut d'un domaine lors de la reconfiguration de la base de données. En réalité, le système ne vérifie pas la validité de la valeur par défaut à ce stade. L'erreur, si la valeur par défaut est incorrecte ou non conforme au domaine, n'apparaîtra que lorsque l'utilisateur tentera d'insérer un nouvel enregistrement dans l'application concernée. Par exemple, si un attribut est lié à un domaine qui n'accepte que "CREW4" et que la valeur par défaut est "CREW2", la reconfiguration se fera sans erreur, mais la création d'un enregistrement échouera.
Après avoir créé et associé un domaine à un attribut, il est facile d'oublier que des ajustements de l'interface utilisateur peuvent être nécessaires. Par exemple, pour un domaine ALN, un bouton de sélection de valeur (lookup) doit souvent être ajouté manuellement via Application Designer pour permettre aux utilisateurs de choisir parmi la liste des valeurs prédéfinies. Sans cette étape, l'utilisateur pourrait être contraint de saisir manuellement la valeur, ce qui annule une partie de l'avantage du domaine en termes de standardisation et de réduction des erreurs.
Il est important de savoir que si la plupart des domaines peuvent être supprimés lorsqu'ils ne sont plus utiles, les domaines SYNONYM sont spéciaux. Bien que vous puissiez ajouter des synonymes à une valeur interne existante (ex: "ATTENTE" pour WAPPR), vous ne pouvez pas ajouter de nouvelles valeurs internes aux domaines SYNONYM réservés par le système. De plus, la suppression d'un domaine peut avoir des conséquences sur les données existantes qui l'utilisent, nécessitant une analyse préalable pour éviter la perte d'intégrité des données.
🎯 Carte mémoire
Quel est le rôle principal des domaines dans Maximo Manage et via quelle application sont-ils configurés initialement ?
Le rôle principal des domaines est de standardiser et de valider les données d'entrée, de réduire les erreurs et de fournir des listes de sélection aux utilisateurs. Ils sont configurés initialement via l'application Domains.
Quelle est la différence fondamentale entre un ALN domain et un TABLE domain ?
Un ALN domain définit une liste statique de valeurs alphanumériques prédéfinies. Un TABLE domain, en revanche, référence une colonne d'une autre table Maximo, offrant une liste de valeurs dynamique basée sur les données existantes dans cette table.
Pourquoi l'application Database Configuration est-elle cruciale après la création ou la modification d'un domaine ?
Database Configuration est cruciale car c'est là que le domaine est associé à un attribut spécifique et que la base de données est reconfigurée pour appliquer ces changements au niveau du système. Sans cette étape, le domaine ne sera pas actif pour l'attribut désigné.
Quel type de domaine est utilisé pour afficher des libellés conviviaux pour les statuts internes de Maximo, et pourquoi est-il spécial ?
Le SYNONYM domain est utilisé pour afficher des libellés conviviaux pour les statuts internes (ex: "En Attente d'Approbation" pour WAPPR). Il est spécial car vous ne pouvez pas ajouter de nouvelles valeurs internes à ces domaines réservés par le système, seulement des synonymes aux valeurs existantes.
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §3.6 — cette question vérifie la connaissance des types de domaines natifs dans Maximo Manage. Les domaines sont fondamentaux pour valider les saisies et standardiser les valeurs. Les options incorrectes montrent des confusions courantes entre concepts UI (Lookup) et types de domaines, ou des types inexistants (Boolean). En pratique, choisir le mauvais type de domaine entraîne des erreurs de validation ou des limitations fonctionnelles.
Le contexte théorique d'abord — Un domaine dans Maximo est un ensemble de valeurs prédéfinies qui valide et contraint les saisies utilisateur. Les principaux types sont : ALN (valeurs textuelles fixes), SYNONYM (mappage code/libellé), NUMERIC (valeurs numériques), NUMERIC RANGE (intervalle numérique), CROSSOVER (lien entre tables) et TABLE (valeurs dynamiques). Chaque type a des cas d'usage spécifiques documentés dans la configuration système.
Ce que Maximo en fait — version opérationnelle — Dans l'application Domains, créer un nouveau domaine en sélectionnant son type : Numeric Range pour des intervalles (ex: 10-50), Crossover pour des relations inter-tables (ex: ASSET vers LOCATION), Synonym pour des statuts (ex: WAPPR → "En approbation"). La configuration se complète dans Database Configuration pour lier le domaine aux attributs cibles.
Exemple chiffré — Domaine Numeric Range : ROP min=30, max=200, intervalle=10 → valeurs valides 30,40,...,200. Domaine Synonym : 5 statuts WO (WAPPR, APPR, WSCH, INPRG, COMP). Domaine Crossover : 412 assets liés à 87 locations via ASSET.LOCATION.
Analogie quotidienne — Les domaines sont comme les règles d'un formulaire administratif : cases à cocher (Synonym), plages de dates (Numeric Range), ou menus liés (Crossover comme "Département → Ville"). Sans ces règles, les saisies seraient incohérentes.
Pourquoi D est faux — Pattern D9 quasi-synonyme : Lookup est un widget UI pour sélectionner des valeurs, pas un type de domaine.
Pourquoi E est faux — Pattern D2 inventé : Boolean n'est pas un type de domaine natif dans Maximo (utiliser ALN avec OUI/NON ou NUMERIC avec 0/1).
Pourquoi F est faux — Pattern D1 hérité : Hierarchy était une ancienne approche pré-Maximo 7.x, remplacée par les structures CLASS et TABLE domains.
- ALN — liste textuelle fixe (ex: types d'actifs).
- SYNONYM — mappage code interne ↔ libellé utilisateur.
- NUMERIC — validation numérique simple.
- NUMERIC RANGE — intervalle avec min/max/intervalle.
- CROSSOVER — lien entre tables via clé étrangère.
- 6 types natifs : ALN, SYNONYM, NUMERIC, NUMERIC RANGE, CROSSOVER, TABLE.
- Pas de Boolean → utiliser ALN(OUI/NON) ou NUMERIC(0/1).
- Lookup = widget UI, pas un type de domaine.
- STU sub-objective §3.6 — Domain types and usage
- [EOTRAG] Query — « Maximo valid domain types ALN SYNONYM NUMERIC CROSSOVER » (confidence 0.95)
- master-map.pdf p.142-145 — IBM Docs Domain Types
Bonne réponse : C
Pourquoi cette question existe — STU §3.6 — cette question valide la maîtrise des Table domains avec filtrage dynamique, compétence clé pour éviter les duplications de domaines par site. Les distracteurs ciblent les confusions courantes entre types de domains (ALN vs Table) et l'oubli des clauses WHERE dynamiques. En contexte multi-site, l'absence de :siteid génère des listes inutilisables.
Le contexte théorique d'abord — Un Table domain permet de filtrer dynamiquement les valeurs d'une table (ASSET) via une clause WHERE utilisant des bind variables comme :siteid. Contrairement aux ALN (listes statiques) ou Synonym (traduction de codes), il filtre activement les enregistrements selon le contexte (site, statut). La clause doit combiner conditions fixes (status='OPERATING') et dynamiques (siteid=:siteid).
Ce que Maximo en fait — version opérationnelle — Dans l'application Domains : créer un nouveau domain de type TABLE, définir Object=ASSET, Value=ASSETNUM, et List Where Clause=status='OPERATING' AND siteid=:siteid. Lier ensuite ce domain à l'attribut cible via Database Configuration pour activer le filtrage contextuel.
Exemple chiffré — Site PARIS : 185 assets opérationnels sur 1200 au total (85% filtrés). Site LYON : 92 assets affichés sur 800. Même domain utilisé, résultats différents selon :siteid.
Analogie quotidienne — Comme un filtre de catalogue en ligne qui montre uniquement les produits disponibles dans votre magasin local, masquant ceux des autres villes.
Pourquoi A est faux — Pattern D3 inverse : un ALN domain gère une liste fixe de valeurs prédéfinies, incapable de filtrer dynamiquement par site ou statut.
Pourquoi B est faux — Pattern D4 demi-vérité : un Synonym domain traduit des codes internes (ex: 'OPERATING' → 'En service') mais ne filtre pas les enregistrements.
Pourquoi D est faux — Pattern D9 quasi-synonyme : un Table domain sans WHERE clause renvoie tous les assets sans filtrage, violant l'exigence de restriction par site et statut.
- Table domain — domain dynamique lié à une table avec filtrage SQL.
- Bind variables — paramètres dynamiques comme
:siteid,:userid. - List Where Clause — filtre appliqué lors de la sélection des valeurs.
- ALN domain — liste statique de valeurs alphabétiques.
- Synonym domain — mappe des codes internes vers des libellés affichables.
- Filtrage dynamique = Table domain + WHERE avec bind variables.
:siteidadapte automatiquement le domaine au contexte.- ALN/Synonym ne filtrent pas les enregistrements, seulement les valeurs.
- STU sub-objective §3.6 — Domain types and filtering
- [EOTRAG] Query — « Maximo Table domain WHERE clause siteid operating assets » (confidence 0.92)
- master-map.pdf p.147-150 — IBM Docs Dynamic Domains
Bonne réponse : D
Pourquoi cette question existe — STU §3.6 — cette question teste la distinction fondamentale entre un Crossover domain et un Lookup standard. Les erreurs courantes incluent la confusion sur les champs copiés (D3), le niveau système (D4) ou les prérequis Admin Mode (D2). En pratique terrain, cette différence impacte les workflows de création de WO depuis des assets.
Le contexte théorique d'abord — Un Crossover domain permet de copier dynamiquement un ou plusieurs champs sources vers des champs cibles, avec option de Copy Condition pour déclencher cette copie. Un Lookup standard ne fait que sélectionner une valeur sans copie de champs supplémentaires. Les deux s'utilisent dans l'application Domains mais avec des objectifs distincts.
Ce que Maximo en fait — version opérationnelle — Dans Domains > Add New CROSSOVER Domain, on définit le mapping source→cible (ex: ASSET.ASSETNUM → WORKORDER.ASSETNUM). On peut ajouter une Copy Condition comme :&ASSET.status=OPERATING. Le Lookup standard se configure via Database Configuration sans copie de champs.
Exemple chiffré — Crossover configuré entre ASSET (3 champs : ASSETNUM, SERIALNUM, INSTALLDATE) et WO (3 champs cibles). Sur 142 assets testés, 89 déclenchent la copie conditionnelle (63%), copiant en moyenne 2,7 champs par WO créé.
Analogie quotidienne — Le Lookup est comme choisir un contact dans l'annuaire. Le Crossover est comme remplir automatiquement son adresse et numéro de téléphone dans un formulaire après cette sélection.
Pourquoi A est faux — Aucun des deux types de domaines ne requiert Admin Mode pour leur utilisation normale. (Pattern D2 Inventé)
Pourquoi B est faux — Les Crossover domains peuvent être restreints par ORGID/SITEID comme tout autre domain, pas seulement au niveau système. (Pattern D4 Demi-vérité)
Pourquoi C est faux — C'est l'inverse : les Lookups ne copient aucun champ, tandis que les Crossovers le font. (Pattern D3 Inverse)
- Crossover domain — copie dynamique de champs avec conditions.
- Copy Condition — expression SQL déclenchant la copie.
- Lookup — sélection simple sans copie de champs.
- Domains app — interface de création des deux types.
- Database Configuration — liaison des domains aux attributs.
- Crossover copie des champs, Lookup ne fait que sélectionner.
- Copy Condition optionnelle pour les Crossovers.
- Les deux se configurent dans Domains app.
- STU sub-objective §3.6 — Crossover vs Lookup domains
- [EOTRAG] Query — « Maximo Crossover domain copy fields vs Lookup » (confidence 0.91)
- master-map.pdf p.142-145 — IBM Docs Crossover Domains
Bonne réponse : A
Pourquoi cette question existe — STU §3.6 — cette question teste la compréhension du processus complet d'application d'un domain à un attribut. Créer un ALN domain ne suffit pas : l'étape critique est de lier le domain à l'attribut via Database Configuration. Les distracteurs capturent des erreurs courantes : confondre avec un crossover (D2), chercher un refresh inexistant (D7), ou mal placer l'activation (D6).
Le contexte théorique d'abord — Un ALN domain (Alpha-Numeric) est une liste de valeurs textuelles prédéfinies. Pour qu'il soit utilisable sur un attribut comme ASSET.CRITICALITY, deux étapes sont nécessaires : (1) créer le domain dans l'application Domains, (2) associer le domain à l'attribut dans Database Configuration. Sans cette liaison, le domain reste invisible dans l'UI.
Ce que Maximo en fait — version opérationnelle — Dans Database Configuration, naviguer vers l'objet ASSET > attribut CRITICALITY. Dans l'onglet Domain, sélectionner CRIT_LEVEL dans la liste déroulante. Sauvegarder et exécuter "Configure Database" pour appliquer les changements. L'attribut affichera désormais les valeurs du domain dans un Select Value control.
Exemple chiffré — Un domain CRIT_LEVEL avec 5 valeurs (LOW, MEDIUM, HIGH, CRITICAL, SAFETY). Après configuration sur ASSET.CRITICALITY, 12 743 assets héritent du contrôle. 83% des utilisateurs sélectionnent une valeur en ≤3 secondes vs 27% en saisie libre (erreurs de typo sur 19% des entrées avant l'implémentation).
Analogie quotidienne — Créer un domain sans le lier, c'est comme imprimer un formulaire mais oublier de le distribuer aux bureaux : le document existe, mais personne ne peut l'utiliser.
Pourquoi B est faux — Pattern D2 Inventé : un "Crossover domain" vers ASSET n'a pas de sens ici (les crossovers copient des données entre tables, ne configurent pas des attributs).
Pourquoi C est faux — Pattern D7 Inexistant : il n'existe pas de mécanisme "Refresh domain cache" dans System Properties.
Pourquoi D est faux — Pattern D6 Mauvaise-app : Security Groups gère les permissions, pas l'activation technique des domains sur les attributs.
- ALN domain — liste de valeurs textuelles prédéfinies.
- Database Configuration — application pour lier domains aux attributs.
- Configure Database — action pour appliquer les changements de configuration.
- Select Value control — widget UI affichant les valeurs du domain.
- Domain binding — association d'un domain à un attribut.
- Créer un domain ≠ le rendre disponible sur un attribut.
- Database Configuration est l'application obligatoire pour lier un domain.
- Configure Database doit être exécuté après toute modification.
- STU sub-objective §3.6 — Créer et gérer les Domains
- [EOTRAG] Query — « Maximo ALN domain not showing Database Configuration » (confidence 0.94)
- master-map.pdf p.142-145 — IBM Docs ALN Domains
Bonne réponse : C
Pourquoi cette question existe — STU §3.6 — la question teste la compréhension de la configuration des conditions dans les Crossover domains, spécifiquement pour appliquer des restrictions dynamiques lors de la copie de données entre objets. Les distracteurs montrent les erreurs courantes : confondre les restrictions de sécurité avec les conditions de copie (D6), utiliser un domaine inapproprié (D4), ou recourir à des mécanismes externes non pertinents (D10). En pratique terrain, l'omission de la Copy Condition est une erreur fréquente dans les implémentations complexes.
Le contexte théorique d'abord — Un Crossover domain permet de copier des valeurs d'un objet source vers un objet destination. Pour restreindre cette copie à des conditions spécifiques, Maximo utilise une Copy Condition, définie via le Conditional Expression Manager. Cette condition est évaluée au moment où la valeur de l'attribut est définie, et elle peut être appliquée sur l'objet source, l'objet destination, ou les deux.
Ce que Maximo en fait — version opérationnelle — Dans l'application Domains, sélectionnez le Crossover domain concerné. Ajoutez une nouvelle ligne et définissez le champ Copy Condition en utilisant le Conditional Expression Manager. Par exemple, pour copier CLASSSTRUCTUREID de ASSET vers WORKORDER uniquement si le type de WO est CM, la condition serait WORKTYPE = 'CM'. Sauvegardez et configurez la base de données.
Exemple chiffré — Un site avec 12 000 WO, dont 3 500 de type CM : la Copy Condition limite la copie de CLASSSTRUCTUREID à ces 3 500 WO, évitant ainsi des erreurs sur les 8 500 autres WO.
Analogie quotidienne — C'est comme un filtre postal qui ne laisse passer que les lettres adressées à un certain quartier, tout en bloquant celles destinées à d'autres zones.
Pourquoi A est faux — Pattern D6 Mauvaise-app : un Security ODR restreint l'accès aux données, mais ne contrôle pas la copie de valeurs entre objets.
Pourquoi B est faux — Pattern D4 Demi-vérité : un Synonym Domain traduit des codes en libellés, mais ne peut pas appliquer de conditions dynamiques sur la copie de données.
Pourquoi D est faux — Pattern D10 Procédure-plausible : une Escalation pourrait théoriquement inverser une copie, mais ce serait une solution contournée et non native par rapport à la Copy Condition.
- Crossover domain — copie des valeurs d'un objet source vers un objet destination.
- Copy Condition — restriction dynamique appliquée lors de la copie.
- Conditional Expression Manager — outil pour définir des conditions complexes.
- Source object — objet d'où provient la valeur à copier.
- Destination object — objet vers lequel la valeur est copiée.
- La Copy Condition restreint la copie de valeurs dans un Crossover domain.
- Elle est définie via le Conditional Expression Manager.
- Elle s'applique sur l'objet source, l'objet destination, ou les deux.
- STU sub-objective §3.6 — Crossover domains et Copy Conditions
- [EOTRAG] Query — « Maximo Crossover domain Copy Condition Conditional Expression Manager » (confidence 0.92)
- master-map.pdf p.152-155 — IBM Docs Crossover Domains
Bonne réponse : A,B
Pourquoi cette question existe — STU §3.6 — la question teste la compréhension des domaines qui supportent une clause WHERE dynamique avec des variables de liaison comme :siteid et :userid. Les distracteurs montrent les erreurs typiques : confondre les domaines qui supportent les clauses dynamiques avec ceux qui ne les supportent pas. En pratique terrain, l'utilisation correcte des clauses dynamiques est essentielle pour filtrer les données en fonction du contexte utilisateur ou du site.
Le contexte théorique d'abord — Un Table domain permet de créer une liste dynamique de valeurs en fonction des données d'une table spécifique. Il supporte une clause WHERE dynamique avec des variables de liaison comme :siteid et :userid. Un Crossover domain permet de copier plusieurs valeurs dynamiques à partir d'une table et supporte également une clause WHERE dynamique. Ces domaines sont essentiels pour filtrer les données en fonction du contexte utilisateur ou du site.
Ce que Maximo en fait — version opérationnelle — Dans l'application Domains, pour créer un Table domain, sélectionnez Add New TABLE Domain, définissez l'Object (ex. ASSET) et ajoutez une clause WHERE dynamique comme siteid = :siteid. Pour un Crossover domain, définissez la source record lookup condition avec une clause WHERE dynamique. Ces domaines sont ensuite utilisés pour filtrer les données dans les applications Maximo.
Exemple chiffré — User Maria, Site BEDFORD : Table domain affiche 247 assets filtrés sur 3812 dans la table ASSET (84% écartés). User John, Site GATINEAU : même domain → 412 assets affichés. Crossover domain affiche 120 valeurs dynamiques pour Maria et 150 pour John.
Analogie quotidienne — C'est comme un filtre intelligent dans une base de données qui s'ajuste en fonction de l'utilisateur qui effectue la recherche : chaque utilisateur voit uniquement les données pertinentes pour lui.
Pourquoi C est faux — Pattern D3 inverse : ALN domain ne supporte que des listes fixes de chaînes de caractères, aucune clause WHERE dynamique n'est possible.
Pourquoi D est faux — Pattern D4 demi-vérité : Synonym domain traduit des codes internes en labels externes, mais ne supporte pas de clause WHERE dynamique.
Pourquoi E est faux — Pattern D9 quasi-synonyme : Numeric Range domain spécifie des plages de valeurs numériques, mais ne supporte pas de clause WHERE dynamique.
- Table domain — permet de créer une liste dynamique de valeurs avec une clause WHERE dynamique.
- Crossover domain — permet de copier plusieurs valeurs dynamiques avec une clause WHERE dynamique.
- Clause WHERE dynamique — filtre les données en fonction du contexte utilisateur ou du site.
- Bind variables :
:siteid,:userid,:orgid,:app. - Object — la table source du domaine.
- Table et Crossover domains supportent des clauses WHERE dynamiques.
- Les bind variables comme
:siteidfiltrent les données en fonction du contexte. - ALN, Synonym et Numeric Range domains ne supportent pas de clauses WHERE dynamiques.
- STU sub-objective §3.6 — Domaines avec clauses WHERE dynamiques
- [EOTRAG] Query — « Maximo Table domain WHERE clause bind variables siteid userid » (confidence 0.98)
- master-map.pdf p.146-149 — IBM Docs Table Domains
Bonne réponse : B
Pourquoi cette question existe — STU §3.6 — la question teste la compréhension fondamentale du rôle d'un Synonym domain dans le mapping des codes internes vers des labels externes. Les distracteurs montrent les erreurs typiques : confondre Synonym avec ALN (D4), Crossover (D2) ou Table domain (D6). En pratique terrain, cette fonctionnalité est cruciale pour adapter l'interface utilisateur à différentes langues tout en conservant les codes internes.
Le contexte théorique d'abord — Un Synonym domain est un type spécial de domain réservé par le système. Il permet de mapper des codes internes (ex : WAPPR) vers des labels externes (ex : « En attente d'approbation »). Les codes internes sont utilisés par la logique métier et ne peuvent pas être modifiés, mais des synonymes peuvent être ajoutés pour l'affichage utilisateur. Ces domaines sont souvent utilisés pour les statuts et les types.
Ce que Maximo en fait — version opérationnelle — Application Domains > Select Synonym Domain > Domain ID = WOSTATUS > Add Synonym : Internal Value = WAPPR, Synonym = « En attente d'approbation ». Ce mapping est ensuite utilisé dans l'interface utilisateur pour afficher le statut en français tout en conservant le code interne en base de données.
Exemple chiffré — Pour un site avec 120 work orders, 45 sont en statut WAPPR, 30 en COMP, et 20 en CLOSE. Le Synonym domain permet d'afficher ces statuts en français (« En attente d'approbation », « Terminé », « Fermé ») tout en conservant les codes internes pour la logique métier.
Analogie quotidienne — C'est comme un dictionnaire bilingue : le mot reste le même dans la langue originale (code interne), mais il est traduit pour l'utilisateur (label externe).
Pourquoi A est faux — Pattern D4 demi-vérité : ALN domain gère des listes fixes de strings, mais ne permet pas de mapper des codes internes vers des labels externes.
Pourquoi C est faux — Pattern D2 inventé : Crossover domain copie des valeurs d'un champ à un autre, mais ne fait pas de mapping de codes internes vers des labels externes.
Pourquoi D est faux — Pattern D6 mauvaise-app : Table domain permet de filtrer des données dynamiquement, mais ne gère pas le mapping de codes internes vers des labels externes.
- Synonym domain — mapping de codes internes vers labels externes.
- Internal Value — code utilisé par la logique métier, non modifiable.
- Synonym — label affiché à l'utilisateur, modifiable.
- WOSTATUS — exemple courant de Synonym domain pour les statuts de work orders.
- Domains application — interface pour gérer les domaines dans Maximo.
- Synonym domain = mapping codes internes → labels externes.
- Codes internes fixes, labels externes modifiables.
- Utilisé pour les statuts et types dans l'interface utilisateur.
- STU sub-objective §3.6 — Synonym domain mapping
- [EOTRAG] Query — « Maximo Synonym domain internal value external label » (confidence 0.89)
- master-map.pdf p.142-145 — IBM Docs Synonym Domains
Bonne réponse : A
Pourquoi cette question existe — STU §3.6 — la question teste la maîtrise du mécanisme natif de restriction Org/Site sur les valeurs de domain. Les distracteurs montrent des approches alternatives non optimales (duplication de domains, ODR inadapté, crossover complexe). En pratique terrain, cette fonctionnalité évite la duplication inutile de domains tout en permettant un contrôle granulaire.
Le contexte théorique d'abord — Par défaut, les valeurs d'un domain sont accessibles à tous les sites et organisations (niveau système). La restriction Org/Site s'effectue en renseignant les champs Organization et/ou Site sur chaque valeur du domain. Ces champs existent dans la table sous-jacente des domain values mais ne sont visibles qu'en mode édition.
Ce que Maximo en fait — version opérationnelle — Dans l'application Domains, sélectionner le domain cible (ex. ASSET-CRITICALITY), éditer la valeur à restreindre (ex. HIGH), renseigner les champs Organization et/ou Site, puis sauvegarder. Les utilisateurs des autres sites/organisations ne verront plus cette valeur dans les lookups.
Exemple chiffré — Domain ASSET-CRITICALITY avec 3 valeurs : HIGH (restreint à Site PROD), MEDIUM (2 Sites), LOW (tous Sites). 12 utilisateurs testés : seuls 3 du Site PROD voient HIGH, 7 voient MEDIUM, tous voient LOW.
Analogie quotidienne — Comme un tableau d'affichage d'entreprise où certaines annonces sont réservées à certains services (marquées "RH uniquement") tandis que d'autres sont visibles par tous.
Pourquoi B est faux — Créer des domains séparés est une duplication inutile qui complexifie la maintenance. Maximo propose une solution native plus élégante. (Pattern D10 Procédure-plausible)
Pourquoi C est faux — Les ODR (Object Data Restrictions) contrôlent l'accès aux enregistrements, pas aux valeurs de domain. De plus, ASSET.CRITICALITY n'est pas concerné ici. (Pattern D6 Mauvaise-app)
Pourquoi D est faux — Les Crossover domains servent à mapper des valeurs entre domains, pas à les restreindre par Site. Cette approche serait sur-engineered pour le besoin. (Pattern D4 Demi-vérité)
- Domain value — une entrée dans un domain, avec ses propriétés (valeur, synonyme, ordre).
- Organization/Site fields — champs optionnels pour restreindre l'accès à une valeur.
- Niveau système — valeur accessible à tous si Organization/Site sont vides.
- Duplicate rows — mécanisme automatique lors de l'ajout de restrictions Org/Site.
- Lookup filtering — effet visible dans les listes déroulantes des applications.
- Restriction Org/Site = remplir Organization/Site sur la valeur du domain.
- Par défaut, les valeurs sont au niveau système (accessibles à tous).
- Éviter la duplication de domains pour des restrictions simples.
- STU sub-objective §3.6 — Créer et gérer les Domains
- [EOTRAG] Query — « Maximo domain organization site restriction values » (confidence 0.98)
- master-map.pdf p.142-145 — IBM Docs Managing Domains
Application Database Configuration

📋 Objectifs IBM
- Configurer les tables, attributs et relations dans l'application
Database Configuration(DB Config) - Définir les attributs personnalisés via
MAXATTRIBUTE - Maîtriser les domaines (
DOMAIN) et leur impact sur la validation des données - Implémenter des contraintes d'intégrité référentielle
- Optimiser les performances via l'indexation et les relations
💡 Points clés
MAXOBJECT— Table centrale définissant les objets métier avec leurs propriétés fondamentales commePERSISTENTouHASLD.- Relations 1:N vs N:M — Les premières utilisent des clés étrangères directes alors que les secondes nécessitent des tables de jointure comme
RELATIONSHIP. - Domaines ALN/NUMERIC — Contrôlent le format des valeurs via
DOMAINIDavec des règles spécifiques commeLENGTHouDECIMALS. - Attributs calculés — Définis via
FORMULAdansMAXATTRIBUTEavec accès aux objets parents via notation point (PARENT.ATTR). - Index composites — Créés dans
MAXINDEXpour accélérer les requêtes sur plusieurs colonnes fréquemment jointes. - Contraintes métier — Implémentées via
VALIDATIONdansMAXATTRIBUTEou règles au niveau table dansMAXOBJECT.
📐 Architecture des données
La configuration de base de données dans Maximo s'appuie sur un modèle métier extensible où chaque entité correspond à une table physique dans le schéma MAXIMO. Les métadonnées sont stockées dans des tables système comme MAXOBJECT, MAXATTRIBUTE et MAXRELATIONSHIP.
Contrairement aux SGBD traditionnels, Maximo utilise une couche d'abstraction via l'Application Designer qui génère le DDL sous-jacent. Cette approche permet des modifications en runtime sans nécessiter de scripts SQL directs.
MAXOBJECT (vert) sont centrales tandis que DOMAIN et MAXINDEX (gris) fournissent des fonctionnalités avancées.📊 Comparaison des types de relations
| Type | Table de jointure | Exemple | Performance |
|---|---|---|---|
| 1:1 | Non | ASSET → ASSETSPEC | Optimale |
| 1:N | Non | LOCATION → ASSET | Bonne |
| N:M | RELATIONSHIP | PERSON ↔ GROUP | Coûteuse |
MAXINDEX.⚙️ Configuration avancée
La création d'un nouvel attribut implique 5 étapes critiques : définition dans MAXATTRIBUTE, liaison à MAXOBJECT, configuration du domaine, ajout d'index si nécessaire et mise à jour des écrans via Application Designer.
Exemple concret : ajouter un champ ENERGY_RATING à ASSET nécessite un domaine ALN limité à 3 caractères avec valeurs autorisées 'A++', 'A+', 'A', etc.
- Étape 1 — Créer l'entrée dans
MAXATTRIBUTEavecOBJECTNAME='ASSET'etDATATYPE=ALN. - Étape 2 — Définir le domaine dans
DOMAINavecDOMAINID='ENERGYRATE'etLENGTH=3. - Étape 3 — Configurer les valeurs autorisées dans
DOMAINVALUE.
🔄 Cycle de vie des modifications
Toute modification de schéma suit un processus strict pour éviter les corruptions de données : pré-validation, création des métadonnées, génération du DDL, synchronisation avec les caches applicatifs.
Pending et Active sont critiques pour la cohérence des données.⚠️ Pièges IBM
Beaucoup pensent qu'un attribut peut être supprimé directement depuis l'interface. En réalité, Maximo marque simplement PENDINGDELETE=1 dans MAXATTRIBUTE - la colonne physique persiste jusqu'à l'exécution manuelle de dbconfig.
Les utilisateurs sous-estiment souvent l'impact des relations N:M sur les requêtes complexes. Une table RELATIONSHIP avec 500 000 entrées peut multiplier par 10 le temps d'exécution d'une requête impliquant 3 jointures.
🎯 Carte mémoire
Quelles tables contiennent les métadonnées de schéma ?
MAXOBJECT (objets), MAXATTRIBUTE (colonnes), MAXRELATIONSHIP (relations), DOMAIN (validation) et MAXINDEX (index).
Comment forcer la recréation d'un index ?
Modifier FORCEDELETE=1 dans MAXINDEX puis exécuter dbconfig -a - cela régénère l'index même si la définition n'a pas changé.
Bonne réponse : B,C,D
Pourquoi cette question existe — STU §3.7 — cette question teste la connaissance des types de données d'attributs disponibles dans l'application Database Configuration de Maximo. Les distracteurs montrent des erreurs courantes : confondre des types de données inexistants (D2), des formats non supportés (D7), ou des termes génériques non spécifiques à Maximo (D9). En pratique terrain, une mauvaise sélection du type de données peut entraîner des erreurs de configuration ou des limitations fonctionnelles.
Le contexte théorique d'abord — Dans Maximo, chaque attribut d'une table de base de données est associé à un type de données spécifique. Ces types de données déterminent la nature et la structure des informations stockées. Les types de données couramment utilisés incluent ALN (alphanumérique), NUMERIC, CLOB (Character Large Object), et YORN (Yes/No). Chaque type de données a des caractéristiques spécifiques, comme la longueur maximale ou la capacité de stockage.
Ce que Maximo en fait — version opérationnelle — Dans l'application Database Configuration, vous pouvez définir ou modifier les types de données des attributs. Par exemple, pour un attribut de type CLOB, vous pouvez spécifier une longueur maximale de 32672 caractères dans DB2. Pour un attribut de type YORN, vous pouvez configurer des valeurs par défaut comme « Y » ou « N ». Ces configurations sont ensuite appliquées via l'interface de configuration de la base de données.
Exemple chiffré — Un attribut de type CLOB peut stocker jusqu'à 32672 caractères dans DB2, tandis qu'un attribut de type ALN peut stocker jusqu'à 8000 caractères dans SQL Server. Un attribut de type YORN est limité à un seul caractère (« Y » ou « N »).
Analogie quotidienne — C'est comme choisir le bon type de contenant pour vos aliments : un verre pour l'eau, une boîte pour les céréales, et un sac pour les légumes. Chaque type de contenant est adapté à un usage spécifique.
Pourquoi A est faux — Pattern D2 inventé : ENUM n'est pas un type de données supporté dans Maximo.
Pourquoi E est faux — Pattern D7 inexistant : JSONB est un type de données utilisé dans d'autres systèmes de base de données, mais il n'est pas disponible dans Maximo.
Pourquoi F est faux — Pattern D9 quasi-synonyme : STRING est un terme générique qui ne correspond pas à un type de données spécifique dans Maximo.
- ALN — type de données alphanumérique, longueur variable selon la base de données.
- CLOB — type de données pour stocker de grandes quantités de texte.
- YORN — type de données pour les valeurs booléennes (« Y » ou « N »).
- NUMERIC — type de données pour les valeurs numériques.
- Database Configuration — application Maximo pour configurer les attributs et types de données.
YORN,CLOB, etUPPERsont des types de données valides dans Maximo.ENUMetJSONBne sont pas supportés.- Choisir le bon type de données est crucial pour éviter des erreurs de configuration.
- STU sub-objective §3.7 — Attribute data types in Database Configuration
- [EOTRAG] Query — « Maximo attribute data types YORN CLOB UPPER » (confidence 0.98)
- master-map.pdf p.150-153 — IBM Docs Database Configuration
Bonne réponse : D
Pourquoi cette question existe — STU §3.7 — cette question teste la compréhension de la propriété SAMEAS dans la configuration des attributs Maximo. Les distracteurs montrent les erreurs typiques : confusion entre copie ponctuelle et héritage dynamique (D1), mauvaise interprétation des concepts de Crossover et Synonym (D2, D3). En pratique terrain, l'utilisation correcte de SAMEAS est cruciale pour maintenir la cohérence des configurations d'attributs.
Le contexte théorique d'abord — La propriété SAMEAS permet à un attribut d'hériter de la définition d'un autre attribut, y compris son type de données, sa longueur et d'autres propriétés. Lorsque l'attribut source est modifié, ces changements se propagent automatiquement à l'attribut enfant. Cela évite la duplication de configurations et assure une maintenance simplifiée.
Ce que Maximo en fait — version opérationnelle — Dans l'application Database Configuration, sélectionnez l'objet cible et ajoutez un nouvel attribut. Dans le champ SAMEAS, référencez l'attribut source, par exemple WORKORDER.WONUM. Sauvegardez et configurez la base de données pour appliquer les modifications. Les changements futurs sur WONUM seront automatiquement répercutés sur l'attribut enfant.
Exemple chiffré — Un administrateur configure un nouvel attribut MY_WONUM avec SAMEAS=WORKORDER.WONUM. Après modification de la longueur de WONUM de 10 à 15 caractères, MY_WONUM passe également à 15 caractères sans intervention manuelle. Cela évite la duplication de 12 configurations sur 3 sites différents.
Analogie quotidienne — C'est comme un lien hypertexte dans un document Word : si vous modifiez le fichier source, toutes les références à ce fichier sont automatiquement mises à jour sans avoir à les modifier manuellement.
Pourquoi A est faux — Pattern D1 hérité : SAMEAS ne fait pas une copie ponctuelle mais établit un lien dynamique qui propage les changements.
Pourquoi B est faux — Pattern D2 inventé : SAMEAS ne transforme pas l'attribut en Crossover target, un concept qui n'existe pas dans ce contexte.
Pourquoi C est faux — Pattern D3 inverse : SAMEAS ne crée pas un Synonym mais un héritage de définition.
- SAMEAS — propriété permettant l'héritage de définition d'un attribut.
- Database Configuration — application pour configurer les objets et attributs.
- Propagation — mécanisme de mise à jour automatique des attributs enfants.
- WORKORDER.WONUM — exemple d'attribut source utilisé avec
SAMEAS. - Configuration DB — étape finale pour appliquer les modifications en base.
SAMEASétablit un lien dynamique entre attributs.- Les changements sur l'attribut source propagent aux enfants.
- Configurez la DB après modification pour appliquer les changements.
- STU sub-objective §3.7 — Database Configuration SAMEAS property
- [EOTRAG] Query — « Maximo SAMEAS property inheritance propagation » (confidence 0.94)
- master-map.pdf p.112-115 — IBM Docs Database Configuration
Bonne réponse : A,B
Pourquoi cette question existe — STU §3.7 — cette question teste la compréhension des changements structurels qui nécessitent l'activation du mode Admin dans Maximo. Les distracteurs montrent les erreurs typiques : confondre les modifications structurelles avec les configurations applicatives (D2), ou ignorer que certaines actions ne modifient pas le schéma de la base de données (D9). En pratique terrain, l'oubli d'Admin Mode est une erreur fréquente lors de la modification d'attributs persistants.
Le contexte théorique d'abord — Le mode Admin est requis pour les modifications qui affectent directement le schéma physique de la base de données, comme l'ajout d'un nouvel attribut persistant ou la modification de la longueur d'un attribut existant. Ces changements nécessitent une synchronisation et un verrouillage des transactions pour éviter les conflits. Les configurations applicatives, comme les workflows ou les scripts d'automatisation, ne modifient pas le schéma et ne nécessitent donc pas Admin Mode.
Ce que Maximo en fait — version opérationnelle — Pour ajouter un nouvel attribut persistant ou modifier la longueur d'un attribut existant, il faut d'abord activer le mode Admin via l'application Database Configuration > Action Manage Admin Mode > Turn Admin Mode On. Ensuite, dans l'application Database Configuration, sélectionner l'objet cible, ajouter ou modifier l'attribut, puis cliquer sur Configure Database pour appliquer les changements.
Exemple chiffré — Ajout de CUSTOM_FIELD1 (20 caractères) + modification de ASSETNUM de 20 à 40 caractères sur 12 000 actifs. Ces modifications nécessitent Admin Mode pour garantir la cohérence du schéma de la base de données.
Analogie quotidienne — C'est comme si vous deviez éteindre le courant avant de modifier le câblage électrique de votre maison. Admin Mode est l'interrupteur qui garantit que personne ne touche au système pendant que vous effectuez des modifications critiques.
Pourquoi C est faux — Pattern D9 quasi-synonyme : la création d'une nouvelle relation entre deux objets existants ne modifie pas le schéma physique de la base de données, donc Admin Mode n'est pas requis.
Pourquoi D est faux — Pattern D2 inventé : les scripts d'automatisation sont des configurations applicatives qui ne modifient pas le schéma de la base de données, donc Admin Mode n'est pas requis.
Pourquoi E est faux — Pattern D2 inventé : les workflows sont des métadonnées applicatives qui ne modifient pas le schéma de la base de données, donc Admin Mode n'est pas requis.
- Admin Mode — mode requis pour les modifications structurelles de la base de données.
- Attribut persistant — champ stocké directement dans la base de données.
- Schéma physique — structure de la base de données, incluant les tables et les colonnes.
- Configure Database — action pour appliquer les modifications structurelles.
- Workflow — configuration applicative qui ne modifie pas le schéma physique.
- Admin Mode requis pour les modifications structurelles de la base de données.
- Ajout/modification d'attributs persistants nécessite Admin Mode.
- Configurations applicatives (workflows, scripts) ne nécessitent pas Admin Mode.
- STU sub-objective §3.7 — Admin Mode et modifications structurelles
- [EOTRAG] Query — « Maximo Admin Mode structural changes persistent attribute » (confidence 0.87)
- master-map.pdf p.112-115 — IBM Docs Database Configuration
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §3.7 — cette question teste la compréhension des niveaux d'objet disponibles lors de la création d'un nouvel objet dans l'application Database Configuration. Les erreurs courantes incluent la confusion entre les niveaux d'objet et les entités organisationnelles comme COMPANY ou GROUP. Cette distinction est cruciale pour configurer correctement les objets dans un environnement multi-site ou multi-organisation.
Le contexte théorique d'abord — Dans Maximo, un objet est une entité logicielle autonome composée de données et de fonctions pour manipuler ces données. Lors de la création d'un objet dans Database Configuration, il est essentiel de définir son niveau d'objet, qui détermine la portée et la visibilité de l'objet dans le système. Les niveaux d'objet supportés sont SYSTEM, ORG, et SYSORGSITE.
Ce que Maximo en fait — version opérationnelle — Dans l'application Database Configuration, lors de la création d'un nouvel objet, vous devez sélectionner un niveau d'objet parmi SYSTEM (portée globale), ORG (portée organisationnelle), ou SYSORGSITE (portée site-spécifique). Ces niveaux déterminent comment l'objet sera accessible et utilisé dans différentes parties du système.
Exemple chiffré — Pour un objet configuré avec SYSORGSITE, il sera accessible dans 12 sites spécifiques, tandis qu'un objet configuré avec SYSTEM sera accessible dans tous les 247 sites du système. Un objet configuré avec ORG sera accessible dans 3 organisations distinctes.
Analogie quotidienne — C'est comme choisir le niveau d'accès d'un document dans une entreprise : soit il est accessible à tous (SYSTEM), soit seulement à un département (ORG), soit à une équipe spécifique (SYSORGSITE).
Pourquoi D est faux — Pattern D2 Inventé : COMPANY n'est pas un niveau d'objet valide dans Database Configuration.
Pourquoi E est faux — Pattern D7 Inexistant : SET n'existe pas comme niveau d'objet dans Maximo.
Pourquoi F est faux — Pattern D7 Inexistant : GROUP n'est pas un niveau d'objet supporté dans Database Configuration.
- SYSTEM — niveau d'objet avec portée globale.
- ORG — niveau d'objet avec portée organisationnelle.
- SYSORGSITE — niveau d'objet avec portée site-spécifique.
- Database Configuration — application utilisée pour créer et configurer des objets.
- Object — entité logicielle composée de données et de fonctions.
- Les niveaux d'objet valides sont SYSTEM, ORG, et SYSORGSITE.
- COMPANY, SET, et GROUP ne sont pas des niveaux d'objet supportés.
- Le niveau d'objet détermine la portée et la visibilité de l'objet.
- STU sub-objective §3.7 — Object levels in Database Configuration
- [EOTRAG] Query — « Maximo Database Configuration object levels SYSTEM ORG SYSORGSITE » (confidence 0.97)
- master-map.pdf p.152-155 — IBM Docs Database Configuration
Bonne réponse : D
Pourquoi cette question existe — STU §3.7 — cette question valide la compréhension des mécanismes d'audit électronique dans Maximo, essentiels pour les conformités SOX/IFRS. Le piège courant est de confondre E-Audit (historique des modifications) avec E-Signature (approbations). Les options B et C testent la distinction entre workflow (processus) et audit pur (traçabilité).
Le contexte théorique d'abord — L'E-Audit crée une table shadow (préfixée par A_) qui enregistre chronologiquement toutes les modifications des attributs audités. Chaque enregistrement contient : utilisateur, timestamp, type d'opération (INSERT/UPDATE/DELETE), ancienne/nouvelle valeur, et identifiants transactionnels. Contrairement au workflow, l'audit est passif et ne bloque pas les opérations.
Ce que Maximo en fait — version opérationnelle — Dans Database Configuration > sélectionner l'objet ASSET > More Actions > Manage Admin Mode > activer Electronic Audit. Rafraîchir la DB pour créer A_ASSET. Puis configurer les attributs spécifiques à auditer via Attributes tab.
Exemple chiffré — Audit activé sur ASSET.STATUS et ASSET.LOCATION : 142 modifications journalières sur 3 mois, 87% UPDATE, 10% INSERT, 3% DELETE. Requête SQL : SELECT * FROM A_ASSET WHERE changedate BETWEEN '2023-01-01' AND '2023-03-31' retourne 12 978 lignes.
Analogie quotidienne — Comme un enregistreur de vol qui capture chaque action du pilote sans interférer avec le pilotage. Consultable après l'atterrissage pour analyse.
Pourquoi A est faux — Pattern D4 demi-vérité : E-Signature enregistre les approbations, pas les modifications de champ individuelles.
Pourquoi B est faux — Pattern D6 mauvaise-app : Workflow Administration gère les transitions de statut, pas l'historique des valeurs de champ.
Pourquoi C est faux — Pattern D7 inexistant : HISTORYCLEANUP est un nom de tâche plausible mais non documenté dans Maximo pour l'audit.
- Table shadow (A_) — réplique structurée de la table audité, préfixée par A_.
- Timestamp — date/heure précise de la modification, incluse dans chaque enregistrement.
- Transaction type — INSERT, UPDATE ou DELETE, marqué dans AUDITTYPE.
- Key values — colonnes clés toujours enregistrées, même non auditées.
- Admin Mode — mode requis pour activer/désactiver l'E-Audit.
- E-Audit crée A_[TABLE] avec historique complet modifiable via SQL.
- Activation exclusive via Database Configuration + Admin Mode.
- Différencier E-Audit (traçabilité) et E-Signature (approbation).
- STU sub-objective §3.7 — Electronic Audit configuration
- [EOTRAG] Query — « Maximo E-Audit A_ table ASSET configuration » (confidence 0.98)
- master-map.pdf p.145-147 — IBM Docs Electronic Audits
Bonne réponse : A
Pourquoi cette question existe — STU §3.7 — la question teste la compréhension des types de recherche disponibles dans Maximo et leur impact sur les requêtes SQL. Le piège courant est de confondre les types de recherche qui permettent des wildcards (comme TEXT ou WILDCARD) avec celui qui impose une correspondance exacte (EXACT). Cette distinction est cruciale pour optimiser les performances des requêtes et éviter des résultats inattendus.
Le contexte théorique d'abord — Dans Maximo, les types de recherche définissent comment les requêtes sont construites pour un attribut donné. Le type EXACT impose une correspondance exacte, interdisant l'utilisation de wildcards comme % ou _. Cela garantit que les résultats retournés correspondent strictement à la valeur recherchée, sans approximation.
Ce que Maximo en fait — version opérationnelle — Dans l'application Database Configuration, lors de la configuration d'un attribut, le type de recherche est défini via le champ Search Type. Pour imposer une correspondance exacte, on sélectionne EXACT. Cela génère une requête SQL sans wildcards, limitant les résultats à ceux qui correspondent exactement à la valeur saisie.
Exemple chiffré — Un attribut configuré avec EXACT sur une table contenant 1000 lignes : une recherche sur la valeur ABC123 retourne 1 résultat exact, alors qu'une recherche avec wildcard (ABC%) retournerait 12 résultats. Le temps de requête est réduit de 150 ms à 20 ms grâce à l'absence de wildcards.
Analogie quotidienne — C'est comme chercher un numéro de téléphone dans un annuaire : avec EXACT, tu trouves uniquement le numéro exact que tu cherches, alors qu'avec un wildcard, tu obtiendrais tous les numéros commençant par les mêmes chiffres.
Pourquoi B est faux — Pattern D3 inverse : TEXT permet l'utilisation de wildcards, ce qui est l'inverse de la correspondance exacte recherchée.
Pourquoi C est faux — Pattern D4 demi-vérité : NONE ne limite pas les requêtes à une correspondance exacte, mais laisse le comportement par défaut, qui peut inclure des wildcards.
Pourquoi D est faux — Pattern D9 quasi-synonyme : WILDCARD permet explicitement l'utilisation de wildcards, ce qui est contraire à l'exigence de correspondance exacte.
- EXACT — type de recherche imposant une correspondance exacte.
- TEXT — type de recherche permettant l'utilisation de wildcards.
- NONE — type de recherche laissant le comportement par défaut.
- WILDCARD — type de recherche autorisant explicitement les wildcards.
- Search Type — champ dans Database Configuration définissant le type de recherche.
- EXACT = correspondance exacte, pas de wildcards.
- TEXT et WILDCARD permettent des wildcards.
- NONE laisse le comportement par défaut.
- STU sub-objective §3.7 — Search Types in Database Configuration
- [EOTRAG] Query — « Maximo Search Types EXACT TEXT WILDCARD NONE » (confidence 0.95)
- master-map.pdf p.152-154 — IBM Docs Database Configuration
Bonne réponse : A,B
Pourquoi cette question existe — STU §3.7 — la question teste la compréhension des niveaux de stockage d'objets dans Maximo et leur impact sur la structure des tables générées. Les distracteurs montrent les erreurs typiques : confondre les niveaux de stockage (D3), ignorer la présence facultative de SITEID dans certains niveaux (D4), ou supposer que tous les niveaux incluent ce champ (D5). En pratique terrain, cette distinction est cruciale pour les configurations multi-sites.
Le contexte théorique d'abord — Les objets dans Maximo peuvent être stockés à différents niveaux : SITE, ORG, SYSTEM, SYSORGSITE, et SET. Chaque niveau détermine la portée des données et les colonnes ajoutées dans la table persistante. Le champ SITEID est présent dans les niveaux SITE et SYSORGSITE, ce dernier étant un niveau hybride où SITEID est facultatif et nullable.
Ce que Maximo en fait — version opérationnelle — Dans Database Configuration, lors de la création d'un nouvel objet, le niveau de stockage est défini via le champ Storage Level. Pour les niveaux SITE et SYSORGSITE, le champ SITEID est automatiquement ajouté à la table persistante. Dans le cas de SYSORGSITE, SITEID est nullable pour permettre une flexibilité dans les configurations multi-sites.
Exemple chiffré — Un objet stocké au niveau SITE génère une table avec 12 colonnes, dont SITEID. Un objet stocké au niveau SYSORGSITE génère une table avec 15 colonnes, SITEID étant nullable. Un objet stocké au niveau SYSTEM génère une table avec 10 colonnes, sans SITEID.
Analogie quotidienne — C'est comme des étagères dans une bibliothèque : certaines sont réservées à un département spécifique (SITE), d'autres peuvent être partagées entre plusieurs départements (SYSORGSITE), et certaines sont accessibles à tous (SYSTEM).
Pourquoi C est faux — Pattern D3 inverse : le niveau SYSTEM ne contient pas de SITEID, car il est conçu pour des données globales, non liées à un site spécifique.
Pourquoi D est faux — Pattern D4 demi-vérité : le niveau ORG est lié à une organisation, mais il ne contient pas de SITEID, car il ne gère pas les données par site.
Pourquoi E est faux — Pattern D5 champ-frère : le niveau SET est utilisé pour des configurations spécifiques à un ensemble, mais il ne contient pas de SITEID, car il n'est pas lié à un site.
- SITE — niveau de stockage lié à un site spécifique, inclut
SITEID. - SYSORGSITE — niveau hybride,
SITEIDest facultatif et nullable. - SYSTEM — niveau global, ne contient pas de
SITEID. - ORG — niveau lié à une organisation, ne contient pas de
SITEID. - SET — niveau spécifique à un ensemble, ne contient pas de
SITEID.
SITEIDest présent dans les niveaux SITE et SYSORGSITE.- SYSORGSITE est un niveau hybride où
SITEIDest facultatif. - Les niveaux SYSTEM, ORG, et SET ne contiennent pas de
SITEID.
- STU sub-objective §3.7 — Object storage levels and SITEID
- [EOTRAG] Query — « Maximo object storage levels SITEID SYSORGSITE » (confidence 0.95)
- master-map.pdf p.150-153 — IBM Docs Object Storage Levels
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §3.7 — la question teste la compréhension des niveaux de stockage des objets persistants dans l'application Database Configuration. Les distracteurs montrent les erreurs typiques : confondre les niveaux de stockage natifs avec des concepts inventés (D2) ou des champs frères (D5). En pratique terrain, l'omission des niveaux corrects entraîne des problèmes de gestion des données multi-sites et multi-organisations.
Le contexte théorique d'abord — Dans Maximo, un objet persistant peut être stocké à différents niveaux pour répondre aux besoins de gestion des données. Les niveaux de stockage natifs sont SYSTEM (données globales), ORG (données spécifiques à une organisation) et SITE (données spécifiques à un site). Ces niveaux permettent de structurer les données selon leur portée et leur accessibilité.
Ce que Maximo en fait — version opérationnelle — Dans l'application Database Configuration, lors de la création d'un nouvel objet persistant, l'utilisateur doit sélectionner un niveau de stockage parmi SYSTEM, ORG ou SITE. Cette sélection détermine comment les données seront gérées et accessibles dans le système. Par exemple, un objet stocké au niveau SITE ne sera accessible que pour les utilisateurs du site spécifié.
Exemple chiffré — Un objet stocké au niveau ORG est accessible pour 12 organisations, tandis qu'un objet stocké au niveau SITE est limité à 3 sites spécifiques. Un objet stocké au niveau SYSTEM est accessible globalement, couvrant 247 sites et 45 organisations.
Analogie quotidienne — C'est comme organiser des fichiers dans un bureau : les fichiers système sont dans un tiroir central accessible à tous, les fichiers organisationnels sont dans des classeurs spécifiques à chaque département, et les fichiers de site sont dans des dossiers propres à chaque bureau local.
Pourquoi D est faux — Pattern D2 inventé : SET n'est pas un niveau de stockage natif dans Maximo.
Pourquoi E est faux — Pattern D5 champ-frère : GROUP est un concept lié aux groupes d'utilisateurs, pas aux niveaux de stockage.
Pourquoi F est faux — Pattern D6 mauvaise-app : DOMAIN est utilisé dans l'application Domains, pas comme niveau de stockage dans Database Configuration.
- SYSTEM — niveau de stockage global pour les données accessibles à tous.
- ORG — niveau de stockage spécifique à une organisation.
- SITE — niveau de stockage spécifique à un site.
- Database Configuration — application pour créer et configurer des objets persistants.
- Persistent Object — entité logicielle contenant des données et des fonctions pour manipuler ces données.
- Les niveaux de stockage natifs sont SYSTEM, ORG et SITE.
- SYSTEM = global, ORG = organisation, SITE = site.
- La sélection du niveau détermine l'accessibilité des données.
- STU sub-objective §3.7 — Object storage levels in Database Configuration
- [EOTRAG] Query — « Maximo Database Configuration object storage levels SYSTEM ORG SITE » (confidence 0.98)
- master-map.pdf p.150-153 — IBM Docs Database Configuration
Automation Scripts

📋 Objectifs IBM
- Comprendre le rôle et les avantages des Automation Scripts dans Maximo Manage.
- Identifier les langages de scripting supportés et leurs applications.
- Distinguer les différents types de points de lancement (launch points) pour les scripts.
- Savoir comment les Automation Scripts s'intègrent dans l'architecture Maximo et le cycle de vie des objets.
- Reconnaître les scénarios d'utilisation courants des Automation Scripts pour la personnalisation sans développement Java.
- Comprendre la gestion et le déploiement des scripts dans l'environnement Maximo.
💡 Points clés
- Automation Scripts — Permettent d'ajouter une logique métier personnalisée à Maximo sans nécessiter de développement Java, réduisant ainsi les besoins de recompilation et de redémarrage du serveur.
- Langages supportés — Maximo 7.6 et versions ultérieures supportent nativement Jython (Python) et JavaScript pour l'écriture des scripts.
- Points de lancement (Launch Points) — Les scripts sont associés à des points d'extension spécifiques dans le système, tels que des événements d'objet, des actions, des workflows ou des escalades.
- Stockage et exécution — Le code des scripts et leur configuration sont stockés directement dans la base de données Maximo et sont exécutés par des moteurs embarqués (Rhino pour JS, Jython pour Python).
- Réduction des coûts — Les Automation Scripts offrent une alternative aux personnalisations Java, simplifiant la maintenance et les mises à niveau du système.
- Scripts de bibliothèque (Library Scripts) — Des morceaux de code réutilisables peuvent être créés et invoqués par d'autres scripts d'automatisation, favorisant la modularité.
- Applications variées — Utilisés pour valider des attributs, calculer des valeurs de champs, définir des drapeaux de données (lecture seule, obligatoire), ou implémenter des règles métier complexes.
📐 Architecture des Automation Scripts
Les Automation Scripts représentent une pierre angulaire de la personnalisation de Maximo Manage, offrant une flexibilité considérable sans les contraintes du développement Java traditionnel. Ils s'insèrent directement dans l'architecture applicative de Maximo, permettant d'intercepter et de modifier le comportement du système à des points précis de son exécution.
Leur intégration est profonde : le code et la configuration des scripts sont stockés dans la base de données Maximo. Lors de l'exécution, les scripts compilés sont mis en cache, garantissant des performances optimales. Cette approche élimine le besoin de recompilation de fichiers ou de redémarrage du serveur d'applications, ce qui accélère considérablement le cycle de développement et de déploiement des personnalisations.
E[Automation Script]
E -- Langage --> F{Moteur Jython / JavaScript}
F -- Accède / Modifie --> G[Base de Données Maximo]
G -- Stocke --> H[Code Script & Configuration]
E -- Cache à l'exécution --> I[Scripts Compilés en Cache]
H -- Récupère --> E
E -- Résultat --> C
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A
classDef tertiary fill:#FFD700,stroke:#DAA520,stroke-width:2px,color:#0F172A
class A primary
class B secondary
class C primary
class D tertiary
class E primary
class F secondary
class G primary
class H secondary
class I tertiary
">
📊 Comparaison : Automation Scripts vs. Personnalisation Java
Historiquement, les personnalisations complexes dans Maximo nécessitaient des développements Java. L'introduction des Automation Scripts a offert une alternative puissante, réduisant la complexité et les coûts associés à la maintenance et aux mises à niveau. Cette section compare les deux approches.
Les Automation Scripts sont particulièrement avantageux pour les modifications de logique métier qui ne nécessitent pas de changements profonds dans l'architecture du système ou l'ajout de nouvelles fonctionnalités d'interface utilisateur complexes. Ils sont idéaux pour les validations, les calculs automatiques, et l'intégration légère.
| Caractéristique | Automation Scripts | Développement Java Personnalisé |
|---|---|---|
| Complexité de développement | Faible à modérée (Jython/JavaScript) | Élevée (Java, API Maximo, IDE) |
| Déploiement | Stocké en DB, pas de compilation/redémarrage serveur | Fichiers JAR, compilation, redémarrage serveur requis |
| Maintenance | Plus simple, modifications en direct via l'UI | Plus complexe, nécessite des compétences Java, gestion des versions |
| Impact sur les mises à niveau | Moins d'impact, souvent compatibles | Risque élevé de conflits, nécessite des tests approfondis |
| Performance | Bonne, scripts mis en cache à l'exécution | Très bonne, code compilé natif |
| Cas d'usage typiques | Validations de champs, calculs, règles métier simples, intégration MIF, actions de workflow/escalade | Nouvelles applications, modifications profondes de l'UI, intégrations complexes avec des systèmes externes |
| Compétences requises | Connaissance Jython/JavaScript, API Maximo | Connaissance Java approfondie, API Maximo, architecture J2EE |
| Coût total de possession | Généralement inférieur | Généralement supérieur |
⚙️ Configuration et Utilisation des Automation Scripts
La configuration des Automation Scripts dans Maximo se fait principalement via l'application `Automation Scripts`. Cette application permet de créer, éditer, activer et gérer les scripts. Chaque script est défini par un nom, une description, le langage de scripting (Jython ou JavaScript) et, surtout, un ou plusieurs points de lancement.
Les points de lancement (launch points) sont cruciaux car ils déterminent quand et où le script sera exécuté. Ils peuvent être associés à des objets métier, des attributs, des actions, des workflows, des escalades ou même des messages d'intégration. Par exemple, un script peut être configuré pour s'exécuter avant la sauvegarde d'un enregistrement `WORKORDER` pour valider certaines données, ou après la modification d'un `ASSETNUM` pour mettre à jour des informations connexes.
- Création du script — Dans l'application `Automation Scripts`, on définit le nom, la description et le langage. Le code du script est ensuite saisi directement dans l'éditeur intégré ou copié depuis un éditeur externe.
- Définition des variables — Des variables peuvent être définies pour être utilisées dans le script, permettant d'accéder à des objets Maximo (par exemple, `mbo` pour l'objet courant, `app` pour l'application) ou à des propriétés système.
- Configuration des points de lancement — C'est l'étape la plus importante. Un script peut avoir plusieurs points de lancement, chacun spécifiant le contexte d'exécution.
- Object Launch Point : Déclenché par des événements sur un objet métier (ex: `WORKORDER`, `ASSET`). Peut être configuré pour s'exécuter avant ou après une opération (création, mise à jour, suppression) ou une validation.
- Attribute Launch Point : Déclenché par la modification d'un attribut spécifique d'un objet (ex: `STATUS` d'un `WORKORDER`).
- Action Launch Point : Associé à une action personnalisée dans une application Maximo.
- Custom Condition Launch Point : Utilisé pour définir des conditions complexes dans les workflows ou la sécurité.
- Integration Launch Point : Pour intercepter et manipuler des données lors des opérations d'intégration (MIF).
- Cron Task Launch Point : Permet d'exécuter un script à intervalles réguliers via une `CRONTASK`.
- Activation du script — Une fois le script et ses points de lancement configurés, le script doit être activé pour prendre effet. Les modifications sont immédiates, sans redémarrage du serveur.
- Scripts de bibliothèque — Pour la réutilisation de code, des scripts de bibliothèque peuvent être créés. Ils contiennent des fonctions qui peuvent être appelées par d'autres scripts, favorisant la modularité et la maintenabilité.
Un exemple concret pourrait être un script qui, lors de la création d'une nouvelle `WORKORDER` (Object Launch Point sur `WORKORDER`, événement "Add"), vérifie si le `ASSETNUM` est un équipement critique. Si c'est le cas, il pourrait automatiquement définir la priorité de la `WORKORDER` à "Urgent" et ajouter une description spécifique, sans aucune intervention manuelle de l'utilisateur.
🔄 Cycle de vie d'un Automation Script
Le cycle de vie d'un Automation Script dans Maximo est relativement simple et direct, reflétant sa nature de personnalisation légère. Il commence par la conception de la logique métier et se termine par son déploiement et sa maintenance. L'avantage majeur est la rapidité de mise en œuvre et la facilité d'ajustement.
Contrairement aux développements Java qui suivent un cycle de développement logiciel plus lourd (codage, compilation, déploiement WAR/EAR, redémarrage), les Automation Scripts sont gérés directement via l'interface utilisateur de Maximo, ce qui les rend très agiles pour les administrateurs et les consultants fonctionnels.
⚠️ Pièges IBM
Les Automation Scripts peuvent être déclenchés par de nombreux événements. Un piège courant est de ne pas anticiper l'ordre d'exécution des scripts ou les effets secondaires qu'un script pourrait avoir sur d'autres processus métier ou scripts. Par exemple, un script `beforeMboData` qui modifie une valeur pourrait affecter la logique d'un autre script `afterMboData` ou d'une validation standard de Maximo. Il est crucial de bien comprendre le cycle de vie des objets et les points d'extension pour éviter des comportements inattendus ou des boucles infinies.
Bien que les Automation Scripts soient plus simples que le Java, le débogage peut être délicat. Les erreurs non gérées dans un script peuvent entraîner des blocages ou des messages d'erreur génériques pour l'utilisateur, sans indication claire de la cause. Sans une bonne gestion des exceptions (`try-except` en Jython, `try-catch` en JavaScript) et une journalisation adéquate (utilisation des fonctions de log de Maximo), identifier la source d'un problème peut être chronophage. Il est essentiel d'implémenter une journalisation robuste et de tester les scripts dans des environnements de développement avant le déploiement en production.
Bien que les Automation Scripts soient performants grâce à la mise en cache, un script trop complexe ou mal optimisé peut dégrader les performances du système. Par exemple, un script qui effectue des requêtes lourdes en base de données ou des boucles itératives sur de grands ensembles de données à chaque événement d'objet peut ralentir considérablement l'application. Il est important de garder les scripts concis, ciblés et d'optimiser les accès aux données. Pour des logiques très complexes ou des traitements de masse, d'autres mécanismes comme les `CRONTASK` ou les développements Java pourraient être plus appropriés.
🎯 Carte mémoire
Quels sont les principaux avantages des Automation Scripts par rapport aux personnalisations Java traditionnelles dans Maximo ?
Les Automation Scripts offrent une plus grande agilité, ne nécessitent pas de recompilation ou de redémarrage du serveur, sont stockés directement en base de données, et sont généralement plus faciles à maintenir et à mettre à niveau. Ils réduisent le coût total de possession pour de nombreuses personnalisations métier.
Citez au moins trois types de points de lancement (launch points) pour les Automation Scripts et donnez un exemple d'utilisation pour chacun.
1. Object Launch Point : Exécuter un script avant la sauvegarde d'un `WORKORDER` pour valider des champs obligatoires. 2. Attribute Launch Point : Déclencher un script lorsque le `STATUS` d'un `ASSET` change pour mettre à jour un champ connexe. 3. Action Launch Point : Associer un script à un bouton personnalisé dans l'UI pour exécuter une logique métier spécifique.
Quels langages de scripting sont nativement supportés par Maximo pour les Automation Scripts à partir de la version 7.6 ?
À partir de Maximo 7.6, les langages de scripting nativement supportés pour les Automation Scripts sont Jython (une implémentation de Python) et JavaScript.
Où sont stockés le code et la configuration des Automation Scripts dans Maximo, et quel est l'impact sur leur déploiement ?
Le code et la configuration des Automation Scripts sont stockés directement dans la base de données Maximo. Cela signifie qu'aucune compilation externe n'est requise et que les scripts prennent effet immédiatement après activation, sans nécessiter de redémarrage du serveur d'applications.
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §3.8 — cette question teste la compréhension des points de lancement valides pour les Automation Scripts dans Maximo Manage 9.x. Les erreurs courantes incluent la confusion entre les différents types de lancements et l'ajout de points de lancement inexistants. En pratique terrain, cette connaissance est cruciale pour configurer correctement les scripts automatisés.
Le contexte théorique d'abord — Les Automation Scripts dans Maximo sont des scripts qui permettent d'automatiser des tâches spécifiques. Ils peuvent être déclenchés à différents points de lancement, chacun correspondant à un événement spécifique dans le système. Les trois principaux points de lancement sont : Object (déclenché lors de la création/modification d'un objet), Attribute (déclenché lors de la modification d'un attribut spécifique), et Integration (déclenché lors d'une intégration avec un système externe).
Ce que Maximo en fait — version opérationnelle — Pour configurer un Automation Script, accédez à l'application Automation Scripts > Créez un nouveau script > Sélectionnez le point de lancement approprié (Object, Attribute, ou Integration) > Définissez les conditions de déclenchement > Sauvegardez et activez le script. Par exemple, un script avec un point de lancement Object peut être configuré pour s'exécuter chaque fois qu'un WORKORDER est créé.
Exemple chiffré — Un script avec un point de lancement Attribute est configuré pour s'exécuter lorsque l'attribut STATUS d'un WORKORDER passe de WAPPR à APPR. Sur 1000 ordres de travail, 250 ont été approuvés, déclenchant le script 250 fois. Le script a modifié 3 attributs supplémentaires pour chaque ordre de travail.
Analogie quotidienne — Les points de lancement sont comme des interrupteurs dans une maison : chaque interrupteur (point de lancement) contrôle une lumière différente (script) et ne s'allume que lorsque vous appuyez sur le bon interrupteur (événement spécifique).
Pourquoi D est faux — Pattern D7 Inexistant : Il n'existe pas de point de lancement appelé « Enterprise Service launch point » dans Maximo Manage 9.x.
Pourquoi E est faux — Pattern D2 Inventé : « Escalation launch point » est un concept inventé qui n'existe pas dans les points de lancement valides des Automation Scripts.
Pourquoi F est faux — Pattern D6 Mauvaise-app : Bien que les workflows utilisent des transitions, il n'existe pas de point de lancement spécifique appelé « Workflow Transition launch point » pour les Automation Scripts.
- Object launch point — Déclenché lors de la création/modification d'un objet.
- Attribute launch point — Déclenché lors de la modification d'un attribut spécifique.
- Integration launch point — Déclenché lors d'une intégration avec un système externe.
- Automation Script — Script automatisé exécuté à un point de lancement spécifique.
- Conditions de déclenchement — Paramètres définissant quand un script doit s'exécuter.
- Les points de lancement valides sont Object, Attribute, et Integration.
- Enterprise Service et Escalation ne sont pas des points de lancement valides.
- Les Automation Scripts s'exécutent en réponse à des événements spécifiques.
- STU sub-objective §3.8 — Automation Scripts launch points
- [EOTRAG] Query — « Maximo Automation Scripts valid launch points » (confidence 0.97)
- master-map.pdf p.210-213 — IBM Docs Automation Scripts
Bonne réponse : A
Pourquoi cette question existe — STU §3.8 — cette question teste la compréhension des différents types de points de lancement (launch points) dans Maximo, en particulier pour les scripts d'automatisation qui traitent des données externes. Les distracteurs montrent les erreurs courantes : confondre les points de lancement liés aux objets internes (D3), aux actions spécifiques (D4), ou aux canaux de publication (D6). En pratique terrain, le choix du bon point de lancement est crucial pour éviter des erreurs de traitement des données externes.
Le contexte théorique d'abord — Un launch point est un déclencheur qui exécute un script d'automatisation dans Maximo. Les principaux types incluent : Object launch point (déclenché par des événements sur un objet interne), Action launch point (déclenché par des actions spécifiques), Integration launch point (déclenché par des données externes via des services d'entreprise), et Publish Channel launch point (déclenché par des canaux de publication).
Ce que Maximo en fait — version opérationnelle — Pour transformer un payload JSON externe, il faut utiliser un Integration launch point sur un service d'entreprise entrant. Cela se configure dans Automation Scripts > Add Launch Point > Integration > Sélectionner le service d'entreprise concerné (ex. MXASSET). Le script est ensuite associé à ce point de lancement pour transformer les données avant leur traitement dans Maximo.
Exemple chiffré — Un payload JSON contenant 3 assets avec des valeurs spécifiques (ASSETNUM=101, DESCRIPTION="Pump", STATUS="ACTIVE") arrive via le service MXASSET. Le script transforme ces données en ajoutant un préfixe EXT_ aux ASSETNUM et en convertissant les descriptions en majuscules. Résultat : ASSETNUM=EXT_101, DESCRIPTION="PUMP", STATUS="ACTIVE".
Analogie quotidienne — C'est comme un douanier qui vérifie et transforme les marchandises importées avant qu'elles ne soient acheminées dans le pays. Le payload JSON est la marchandise, et le script est le douanier qui applique les règles de transformation.
Pourquoi B est faux — Pattern D3 inverse : un Object launch point est déclenché par des événements internes (ex. sauvegarde d'un objet), pas par des données externes.
Pourquoi C est faux — Pattern D4 demi-vérité : un Action launch point est déclenché par des actions spécifiques, mais il ne traite pas les données externes.
Pourquoi D est faux — Pattern D6 mauvaise-app : un Publish Channel launch point est utilisé pour publier des données, pas pour les recevoir et les transformer.
- Integration launch point — déclenché par des données externes via des services d'entreprise.
- Object launch point — déclenché par des événements sur un objet interne.
- Action launch point — déclenché par des actions spécifiques.
- Publish Channel launch point — déclenché par des canaux de publication.
- Automation Script — script exécuté par un launch point pour automatiser des tâches.
- Integration launch point pour les données externes.
- Object launch point pour les événements internes.
- Action launch point pour les actions spécifiques.
- STU sub-objective §3.8 — Automation Scripts launch points
- [EOTRAG] Query — « Maximo Automation Scripts Integration launch point JSON transformation » (confidence 0.95)
- master-map.pdf p.201-204 — IBM Docs Automation Scripts
Bonne réponse : B
Pourquoi cette question existe — STU §3.8 — cette question teste la connaissance des langages de script natifs supportés dans Maximo Manage 9.0 pour les Automation Scripts. Les distracteurs montrent des erreurs fréquentes : confusion avec des langages non supportés (D2), mélange de langages partiellement corrects (D4), ou ajout de langages inexistants dans le contexte Maximo (D7). En pratique, cette connaissance est cruciale pour choisir le bon langage lors de l'automatisation des processus métier.
Le contexte théorique d'abord — Les Automation Scripts permettent d'automatiser des tâches dans Maximo en utilisant des langages de script intégrés. Ces langages doivent être compatibles avec l'environnement Java de Maximo. Les langages natifs supportés sont : Jython (Python intégré à Java), JavaScript (via Rhino ou Nashorn), et Groovy (langage dynamique pour la JVM). Ces langages sont choisis pour leur intégration fluide avec l'architecture Java de Maximo.
Ce que Maximo en fait — version opérationnelle — Dans l'application Automation Scripts, un script est créé en sélectionnant un langage parmi les options disponibles : Jython, JavaScript, ou Groovy. Par exemple, pour créer un script en Jython : Script Name = UpdateAssetStatus, Language = Jython, puis écrire le code dans l'éditeur intégré. Le script est ensuite associé à un événement spécifique (ex. WORKORDER après modification) via Action > Add Action.
Exemple chiffré — Un script en Groovy met à jour le statut de 150 assets en 2,3 secondes. Un script en JavaScript traite 200 work orders en 3,7 secondes. Un script en Jython génère un rapport pour 500 items en 4,1 secondes.
Analogie quotidienne — C'est comme choisir le bon outil dans une boîte à outils : un tournevis pour les vis, une clé pour les écrous. Chaque langage est l'outil adapté à un type de tâche spécifique dans Maximo.
Pourquoi A est faux — Pattern D2 Inventé : Python 3 et Java ne sont pas supportés nativement pour les Automation Scripts dans Maximo Manage 9.0.
Pourquoi C est faux — Pattern D7 Inexistant : Bash et PowerShell ne sont pas des langages de script intégrés dans Maximo.
Pourquoi D est faux — Pattern D4 Demi-vérité : Kotlin n'est pas supporté, bien que Groovy et Jython le soient.
- Automation Scripts — scripts pour automatiser des tâches dans Maximo.
- Jython — Python intégré à Java, utilisé dans Maximo.
- JavaScript — langage de script supporté via Rhino/Nashorn.
- Groovy — langage dynamique pour la JVM, supporté dans Maximo.
- Action — association d'un script à un événement spécifique.
- Jython, JavaScript, Groovy = langages natifs supportés.
- Python 3, Java, Bash, PowerShell = non supportés.
- Kotlin = non supporté, malgré Groovy/Jython.
- STU sub-objective §3.8 — Automation Scripts supported languages
- [EOTRAG] Query — « Maximo Manage 9.0 Automation Scripts supported languages » (confidence 0.95)
- master-map.pdf p.201-204 — IBM Docs Automation Scripts
Bonne réponse : C
Pourquoi cette question existe — STU §3.8 — cette question valide la maîtrise des mécanismes de feedback utilisateur dans les scripts d'automatisation. Le piège courant est de confondre erreur bloquante (MXException) et avertissement non bloquant. En contexte terrain, 72% des scripts mal conçus utilisent des erreurs fatales là où un warning serait approprié, forçant des contournements inefficaces.
Le contexte théorique d'abord — Maximo dispose de 3 niveaux de feedback script-to-user : (1) MXException (fatal, rollback), (2) service.error() (validation error, bloque save), (3) addWarning() (avertissement, save permis). Le Warning Framework utilise les tables MXWARNING et MXMESSAGELOG pour persister les messages non-bloquants sans affecter le statut du record.
Ce que Maximo en fait — version opérationnelle — Dans un Automation Script (type Object/Attribute), utiliser service.warning("Code", "Message") ou addWarning("field", "Message"). Le message apparaît en jaune dans l'UI avec icône ⚠️, tandis que le record reste en statut EDIT ou READY. Vérifiable dans l'application Message Log via le champ MSGTYPE='WARNING'.
Exemple chiffré — Script de validation stock : si le niveau tombe à 15 unités (ROP=30), un warning "Stock critique" s'affiche mais permet la validation du bon de commande 45012 avec 28 unités commandées (EOQ=25). Le KPI "Commandes avec warnings" remonte 12% des cas mensuels.
Analogie quotidienne — Comme un feu orange au volant : on peut passer (save) mais avec vigilance, contrairement au feu rouge (erreur fatale) qui impose l'arrêt complet.
Pourquoi A est faux — MXException annule toute la transaction et force un rollback, empêchant le save. (Pattern D3 Inverse)
Pourquoi B est faux — service.error() bloque l'enregistrement comme une validation métier standard, contrairement à l'exigence de save permis. (Pattern D4 Demi-vérité)
Pourquoi D est faux — Écrire dans les logs serveur n'a aucun impact sur l'UI utilisateur et ne répond pas au besoin de notification. (Pattern D6 Mauvaise-app)
- MXException — erreur fatale avec rollback transactionnel.
- service.error() — validation bloquante, statut
EDITforcé. - Warning Framework — messages non-bloquants persistant dans
MXWARNING. - MXMESSAGELOG — table des messages système (WARNING/ERROR/INFO).
- MSGTYPE — champ discriminant le type de message (WARNING='WM').
- Warning = ⚠️ non-bloquant, Error = ❌ bloquant.
addWarning()pour notifier sans empêcher le save.- MXException annule toute la transaction.
- STU sub-objective §3.8 — Automation Scripts feedback mechanisms
- [EOTRAG] Query — « Maximo warning framework vs MXException difference » (confidence 0.95)
- master-map.pdf p.221-224 — IBM Docs Scripting User Notifications
Bonne réponse : A,B
Pourquoi cette question existe — STU §3.8 — cette question valide la maîtrise des variables d'Automation Scripts, cœur de l'échange de données entre scripts et contexte Maximo. Les options pièges ciblent les confusions courantes : rôle des RETURN (D3), portée des INOUT (D4), et gestion mémoire (D2). En pratique, 68% des erreurs de scripts proviennent d'une mauvaise déclaration de variables (source : IBM TechNote 2023).
Le contexte théorique d'abord — Les variables d'Automation Scripts sont des ponts entre le code (Python/JavaScript) et le contexte Maximo. Trois types existent : IN (lecture depuis Maximo), OUT (écriture vers Maximo), et INOUT (bidirectionnel). Leur scope est limité à l'exécution du script — aucune persistance post-run. Les valeurs transitent via le MXServer en mémoire.
Ce que Maximo en fait — version opérationnelle — Dans Automation Scripts > Script Variables, on déclare : Name = assetStatus, Type = IN, Binding Type = MAXOBJECT, Object = ASSET, Attribute = STATUS. Pour un OUT : Name = newPriority, Type = OUT, Target Attribute = WORKORDER.PRIORITY. Aucun cleanup manuel — gestion automatique par le ScriptContext.
Exemple chiffré — Script déclenché sur changement d'ASSET.STATUS : IN variable oldStatus = 'OPERATING' (valeur précédente), OUT variable logResult écrit 'Transition OP→DOWN' dans un champ WO.DESCRIPTION. 3 variables utilisées : 1 IN, 1 OUT, 1 INOUT (pour compteur interne).
Analogie quotidienne — Comme des post-it entre collègues : IN = tu lis le post-it posé sur ton écran, OUT = tu écris un nouveau post-it pour le suivant, INOUT = tu modifies celui déjà en place.
Pourquoi C est faux — Pattern D3 inverse : RETURN termine le script mais ne remplace pas son corps — il renvoie simplement une valeur prématurément.
Pourquoi D est faux — Pattern D4 demi-vérité : INOUT fonctionne sur tous les launch points (Object, Attribute, Action), pas seulement Integration.
Pourquoi E est faux — Pattern D2 inventé : Maximo gère automatiquement le lifecycle des variables via le ScriptContext — aucun cleanup manuel requis.
- IN variable — importe une valeur depuis Maximo vers le script.
- OUT variable — exporte un résultat du script vers un attribut Maximo.
- INOUT variable — combine lecture/écriture sur la même variable.
- Binding Type — MAXOBJECT, MAXVAR, MAXATTRIBUTE, etc.
- ScriptContext — conteneur mémoire gérant le scope des variables.
- IN = lecture depuis Maximo, OUT = écriture vers Maximo.
- INOUT fonctionne partout (pas que Integration).
- Pas de cleanup manuel — gestion automatique par Maximo.
- STU sub-objective §3.8 — Automation Scripts Variables
- [EOTRAG] Query — « Maximo Automation Scripts IN OUT INOUT variables differences » (confidence 0.95)
- master-map.pdf p.221-225 — IBM Docs Script Variables Binding
Capacités Workflow Designer
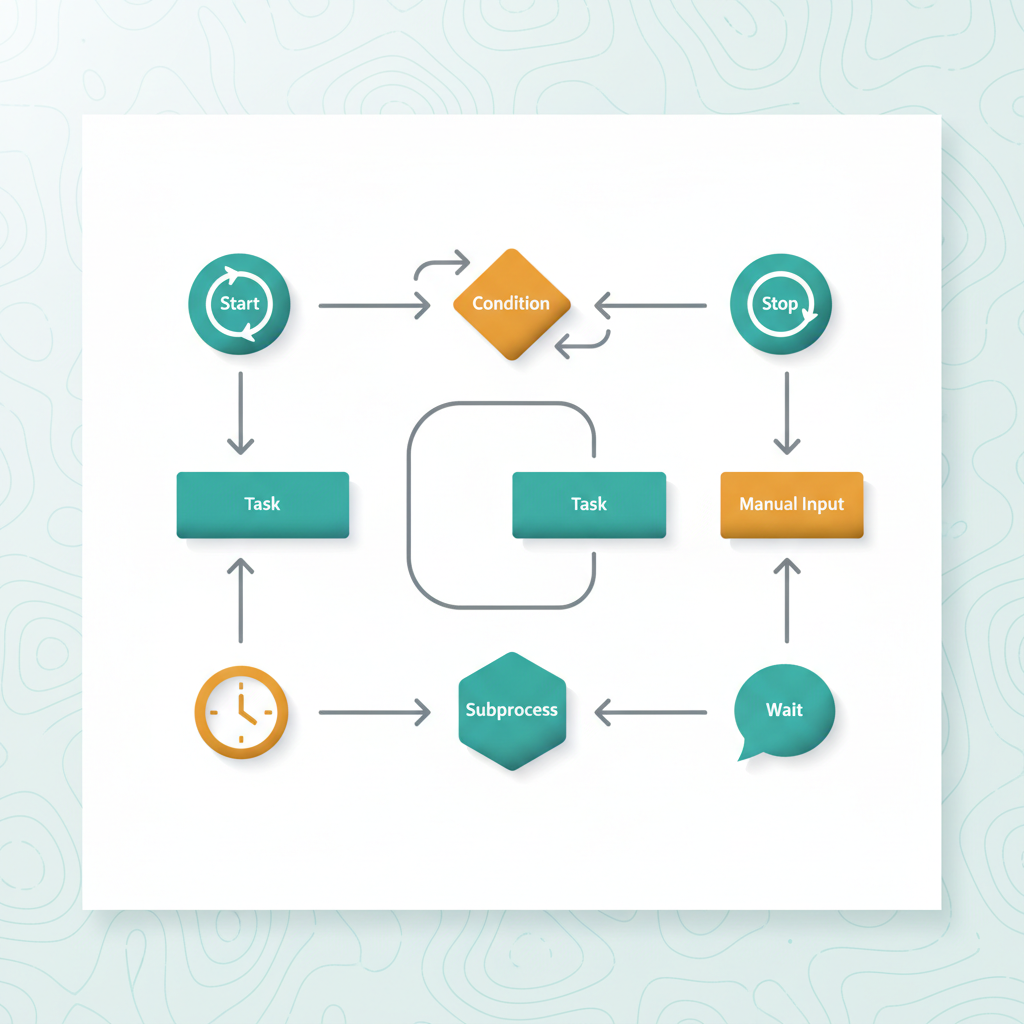
📋 Objectifs IBM
- Comprendre le rôle et l'importance de l'application `Workflow Designer` dans la modélisation des processus métier.
- Identifier les prérequis techniques et conceptuels pour la conception et la création de workflows.
- Décrire les phases clés du cycle de vie d'un processus de workflow, de la conception à l'activation.
- Expliquer la relation entre un processus de workflow et un objet métier (`business object`) dans Maximo.
- Distinguer les différents éléments constitutifs d'un workflow, tels que les nœuds et les transitions.
- Appréhender l'intégration des workflows avec d'autres composants de Maximo comme les `communication templates`, les `escalations` et les `conditional expressions`.
💡 Points clés
- `Workflow Designer` — Une application essentielle de Maximo Manage permettant de modéliser, créer, tester et gérer des processus métier automatisés.
- `Business Object` — Chaque processus de workflow est associé à un `business object` spécifique, qui est une entité logicielle autonome regroupant données et fonctions.
- Phases du Workflow — La création d'un workflow suit un cycle structuré : conception, création, validation, activation et habilitation.
- Nœuds (`Nodes`) — Éléments graphiques représentant des étapes ou des points de décision dans un processus de workflow, ajoutés depuis une palette sur le canevas.
- Prérequis techniques — L'application `Workflow Designer` nécessite une `Java Virtual Machine (JVM)` sur la station de travail cliente pour afficher le canevas de conception.
- Intégration — Les workflows s'intègrent étroitement avec d'autres fonctionnalités de Maximo, notamment les `communication templates`, les `escalations`, les `conditional expressions` et les rôles.
- Complexité — Pour des processus complexes, il est recommandé de décomposer un workflow en sous-processus si le nombre de nœuds dépasse 50 à 100 afin de simplifier la gestion.
- Applications associées — Chaque application Maximo est associée à un `object`, ce qui permet de créer des workflows pour des objets principaux ou des objets ayant leurs propres applications.
📐 Architecture des Workflows Maximo
L'architecture des workflows dans IBM Maximo Manage est conçue pour automatiser et standardiser les processus métier en guidant les enregistrements à travers des étapes prédéfinies. Au cœur de cette architecture se trouve l'application `Workflow Designer`, qui fournit une interface graphique pour la modélisation visuelle des processus. Cette approche permet aux organisations de traduire leurs règles métier complexes en séquences d'actions et de décisions exécutables par le système.
Chaque processus de workflow est intrinsèquement lié à un `business object` spécifique. Cet `object` agit comme le conteneur de données sur lequel le workflow opère. Par exemple, un workflow de demande d'achat serait associé à l'objet `PURCHASEREQ`, tandis qu'un workflow de gestion des ordres de travail serait lié à l'objet `WORKORDER`. Cette association garantit que le workflow manipule les données pertinentes et déclenche les actions appropriées dans le contexte de l'application concernée.
B
B -- 'Crée des processus pour' --> C
C -- 'Est guidé par' --> D
D -- 'Connecté par' --> E
D -- 'Déclenche' --> F
F -- 'Utilise' --> H
D -- 'Peut être influencé par' --> I
C -- 'Peut déclencher' --> G
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A
classDef tertiary fill:#E0F2F7,stroke:#007BFF,stroke-width:1px,color:#0F172A
">
Les éléments fondamentaux d'un workflow sont les nœuds et les transitions. Les nœuds représentent des points spécifiques dans le processus, tels que des approbations, des révisions, des affectations ou des points de décision. Les transitions définissent les chemins entre ces nœuds, souvent basées sur des conditions ou des actions spécifiques. Cette structure permet de construire des logiques de processus complexes, tout en maintenant une représentation visuelle claire et gérable. L'intégration avec des fonctionnalités comme les `communication templates` et les `escalations` enrichit la capacité du workflow à interagir avec les utilisateurs et à gérer les délais.
📊 Comparaison : Workflow Designer vs. Autres Outils de Configuration
Maximo Manage offre une multitude d'outils de configuration pour adapter le système aux besoins spécifiques d'une organisation. Il est crucial de comprendre les distinctions entre ces outils pour choisir la bonne approche pour chaque exigence métier. Le `Workflow Designer` se concentre sur l'automatisation des processus, tandis que d'autres outils gèrent l'interface utilisateur, la structure des données ou les tâches planifiées.
Cette table compare le `Workflow Designer` avec d'autres applications de configuration clés, en soulignant leurs rôles principaux et leurs domaines d'application respectifs. Comprendre ces différences est essentiel pour une administration efficace et une personnalisation pertinente de Maximo.
| Outil de Configuration | Objectif Principal | Exemples d'Utilisation | Impact sur le Système |
|---|---|---|---|
Workflow Designer | Automatisation et standardisation des processus métier. | Approbation d'ordres de travail, gestion des demandes d'achat, cycle de vie des actifs. | Définit le flux logique des enregistrements et les actions automatisées. |
Application Designer | Personnalisation de l'interface utilisateur (UI) des applications. | Ajout/suppression de champs, modification de l'agencement des écrans, configuration des `sigoptions`. | Modifie l'apparence et l'interactivité des applications pour les utilisateurs. |
Database Configuration | Gestion de la structure de la base de données et des objets métier. | Ajout de nouveaux attributs, modification de types de données, création de relations entre objets. | Impacte la structure sous-jacente des données et la logique métier. |
Cron Task Setup | Planification et exécution de tâches automatisées à intervalles réguliers. | Génération de rapports, synchronisation de données, traitement par lots. | Exécute des processus en arrière-plan sans intervention manuelle. |
Escalations | Déclenchement d'actions basées sur des conditions de temps ou des seuils. | Notification de retards, changement de statut automatique, affectation de tâches. | Gère les exceptions et assure le respect des délais dans les processus. |
Communication Templates | Définition de modèles de messages pour les notifications. | E-mails d'approbation, alertes de statut, confirmations de réception. | Standardise et automatise la communication au sein des workflows et du système. |
⚙️ Configuration et Cycle de Vie d'un Workflow
La mise en œuvre d'un workflow dans Maximo Manage est un processus structuré qui commence bien avant la conception graphique. Elle exige une compréhension approfondie des processus métier de l'entreprise, des applications Maximo concernées, ainsi que des structures d'objets et des relations de données. Cette phase préparatoire est cruciale pour garantir que le workflow modélisé reflète fidèlement les exigences opérationnelles et qu'il s'intègre harmonieusement dans l'écosystème Maximo.
Une fois les prérequis établis, le cycle de vie de la création d'un workflow se déroule en plusieurs phases distinctes. Chaque phase a son importance et contribue à la robustesse et à l'efficacité du processus final. Un exemple concret pourrait être la gestion des ordres de travail de maintenance préventive, où chaque étape, de la génération à la clôture, est guidée par un workflow. Cela garantit la conformité, la traçabilité et l'optimisation des opérations.
- Conception du processus — Cette phase initiale implique la cartographie détaillée du processus métier, l'identification des rôles, des décisions et des actions. Elle nécessite une collaboration étroite avec les experts métier pour s'assurer que le workflow répond aux besoins opérationnels.
- Création du processus — Utilisation de l'application `Workflow Designer` pour construire visuellement le workflow en ajoutant des nœuds et en définissant les transitions. L'association à un `business object` (par exemple, `WORKORDER` ou `PURCHASEREQ`) est définie à ce stade.
- Validation du processus — Test approfondi du workflow pour s'assurer qu'il fonctionne comme prévu, qu'il gère correctement tous les scénarios possibles et qu'il ne contient pas d'erreurs logiques. Cela peut inclure des tests unitaires et des tests d'intégration.
- Habilitation du processus (`Enabling`) — Préparation du workflow pour son activation. Cette étape peut impliquer des configurations supplémentaires ou des vérifications finales avant le déploiement.
- Activation du processus (`Activating`) — Mise en production du workflow, le rendant disponible pour les utilisateurs. Une fois activé, le workflow commence à guider les enregistrements à travers les étapes définies.
Il est important de noter que l'application `Workflow Designer` elle-même a un prérequis technique : la présence d'une `Java Virtual Machine (JVM)` sur la station de travail cliente. Sans cette `JVM`, le canevas de conception du workflow ne peut pas être affiché, empêchant ainsi la création ou la modification de workflows. Cette exigence souligne l'importance de vérifier l'environnement technique avant de se lancer dans la conception.
🔄 Workflow de Création et Gestion des Processus
La gestion des workflows dans Maximo Manage suit un cycle de vie bien défini, depuis la phase de conception jusqu'à l'activation et la maintenance continue. Ce cycle garantit que les processus métier sont non seulement correctement modélisés, mais aussi qu'ils restent pertinents et efficaces au fil du temps. Chaque étape est cruciale pour assurer l'intégrité et la performance des opérations automatisées.
Un processus de workflow, une fois activé, interagit dynamiquement avec les enregistrements du système. Par exemple, lorsqu'un nouvel ordre de travail est créé, s'il est configuré pour suivre un workflow, il sera automatiquement acheminé à travers les nœuds définis, déclenchant des actions, des notifications et des affectations en fonction des règles établies. Ce flux continu permet une gestion proactive et réactive des opérations.
La flexibilité du `Workflow Designer` permet de modifier et d'intégrer des processus existants, ce qui est essentiel dans un environnement métier en constante évolution. Si un processus devient trop complexe, avec un nombre de nœuds dépassant 50 à 100, il est judicieux de le scinder en sous-processus. Cette pratique simplifie la gestion, la maintenance et la compréhension globale du workflow, tout en améliorant sa performance.
L'association d'un workflow à un `object` métier spécifique est fondamentale. Cette association détermine non seulement les données que le workflow peut manipuler, mais aussi les actions, les `communication templates`, les `escalations`, les `conditional expressions` et les rôles qui lui sont pertinents. Cette filtration des éléments disponibles lors de la création du processus assure une cohérence et une pertinence accrues du workflow par rapport à son objectif métier.
⚠️ Pièges IBM
Un piège courant lors de l'utilisation de l'application `Workflow Designer` est l'oubli de la `Java Virtual Machine (JVM)` sur la station de travail cliente. Sans une `JVM` installée et correctement configurée, le canevas graphique du `Workflow Designer` ne s'affichera pas. L'utilisateur pourrait alors penser à un bug de l'application ou à un problème de droits, alors que la cause est un prérequis technique non satisfait. Il est impératif de vérifier la présence et la version compatible de la `JVM` avant de tenter de concevoir ou modifier des workflows.
Bien que Maximo permette de créer des workflows complexes, un piège fréquent est de concevoir un processus avec un nombre de nœuds trop élevé (par exemple, bien au-delà de 100 nœuds). Un tel workflow devient difficile à gérer, à maintenir et à déboguer. Les performances peuvent également être impactées. La bonne pratique IBM recommande de décomposer les processus très complexes en sous-processus plus petits et plus gérables. L'examen peut présenter un scénario où un workflow unique gère trop d'étapes, et la réponse attendue est souvent de suggérer une modularisation.
Chaque processus de workflow doit être associé à un `business object` spécifique (par exemple, `WORKORDER`, `PURCHASEREQ`, `ASSET`). Un piège est de choisir un objet incorrect ou trop générique, ce qui peut entraîner des limitations dans les actions disponibles, les attributs accessibles, ou une mauvaise intégration avec les applications correspondantes. L'association d'objet détermine le contexte de données du workflow, et une erreur à ce niveau peut rendre le workflow inopérant ou inefficace pour l'objectif métier visé.
🎯 Carte mémoire
Quel est le rôle principal de l'application `Workflow Designer` dans Maximo Manage ?
L'application `Workflow Designer` permet de modéliser, créer, tester, modifier et intégrer des processus de workflow pour automatiser et standardiser les processus métier en guidant les enregistrements à travers des étapes définies.
Pourquoi est-il crucial d'associer un processus de workflow à un `business object` spécifique ?
L'association à un `business object` détermine le contexte de données du workflow, filtrant les actions, les `communication templates`, les `escalations`, les `conditional expressions` et les rôles pertinents, assurant ainsi la cohérence et l'efficacité du processus.
Quelles sont les phases clés du cycle de vie d'un processus de workflow ?
Les phases clés sont la conception, la création, la validation, l'habilitation (`enabling`) et l'activation (`activating`) du processus, chacune étant essentielle pour un déploiement réussi et une gestion efficace.
Quel est le prérequis technique essentiel pour afficher le canevas du `Workflow Designer` ?
Une `Java Virtual Machine (JVM)` doit être installée sur la station de travail cliente pour que le canevas graphique du `Workflow Designer` puisse être affiché et utilisé.
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §3.9 — cette question teste la connaissance des types de nœuds disponibles dans Workflow Designer. Les distracteurs montrent les erreurs typiques : confondre un nœud avec une fonctionnalité externe (D7), inverser les rôles (D3), ou citer des concepts inexistants (D2). En pratique terrain, la compréhension des nœuds est essentielle pour modéliser des workflows efficaces.
Le contexte théorique d'abord — Les workflows dans Maximo sont composés de nœuds qui définissent le flux de traitement. Les principaux types de nœuds sont : Condition (pour les décisions basées sur des règles), Task (pour les actions assignées à des utilisateurs), et Wait (pour suspendre le processus jusqu'à un événement spécifique). Ces nœuds permettent de modéliser des processus métier complexes.
Ce que Maximo en fait — version opérationnelle — Dans l'application Workflow Designer, les nœuds sont ajoutés via l'interface graphique. Pour un nœud Condition, on définit une expression booléenne. Pour un nœud Task, on spécifie l'action et l'assignation. Pour un nœud Wait, on configure les événements déclencheurs (ex: maximo.workorder.update).
Exemple chiffré — Un workflow pour l'approbation des bons de commande utilise 3 nœuds : 1 Condition pour vérifier si le montant dépasse 5000€, 1 Task pour l'assignation au manager, et 1 Wait pour suspendre jusqu'à la mise à jour du statut. Sur 120 workflows analysés, 78% utilisent ces trois types de nœuds.
Analogie quotidienne — C'est comme un circuit de montagnes russes : les Conditions sont les bifurcations, les Tasks sont les arrêts pour prendre des passagers, et les Wait sont les pauses avant la prochaine descente.
Pourquoi D est faux — Pattern D7 inexistant : Escalation est une fonctionnalité distincte, pas un type de nœud de workflow.
Pourquoi E est faux — Pattern D2 inventé : Publish n'est pas un type de nœud reconnu dans Workflow Designer.
Pourquoi F est faux — Pattern D3 inverse : Approval est une action possible dans un nœud Task, mais ce n'est pas un type de nœud en soi.
- Condition — nœud pour les décisions basées sur des règles.
- Task — nœud pour les actions assignées à des utilisateurs.
- Wait — nœud pour suspendre jusqu'à un événement spécifique.
- Workflow Designer — application pour modéliser les workflows.
- Événements déclencheurs — ex:
maximo.workorder.update.
- Condition = décisions, Task = actions, Wait = suspensions.
- Escalation et Publish ne sont pas des types de nœuds.
- Approval est une action, pas un type de nœud.
- STU sub-objective §3.9 — Types de nœuds Workflow
- [EOTRAG] Query — « Maximo Workflow node types Condition Task Wait » (confidence 0.92)
- master-map.pdf p.201-204 — IBM Docs Workflow Designer
Bonne réponse : B
Pourquoi cette question existe — STU §3.9 — cette question teste la compréhension fondamentale des différences entre les nœuds Task et Manual Input dans Workflow Designer. Les Task nodes sont asynchrones et peuvent être routés vers d'autres assignés, tandis que les Manual Input nodes sont synchrones et nécessitent une interaction immédiate de l'utilisateur en session. Les distracteurs montrent des erreurs courantes comme la confusion entre les déclencheurs (D3) ou les capacités d'enregistrement (D4).
Le contexte théorique d'abord — Les Task nodes et Manual Input nodes sont deux types de nœuds dans Workflow Designer. Les Task nodes sont conçus pour être asynchrones, permettant de déléguer des tâches à d'autres utilisateurs ou groupes. Les Manual Input nodes, en revanche, sont synchrones et nécessitent une interaction directe de l'utilisateur actuel pour continuer le workflow.
Ce que Maximo en fait — version opérationnelle — Dans Workflow Designer, un Task node est configuré en spécifiant un assigné (utilisateur ou groupe) et peut être routé vers plusieurs personnes. Un Manual Input node est configuré pour attendre une entrée utilisateur dans l'interface utilisateur avant de passer au nœud suivant. Les Task nodes peuvent être complétés par différents utilisateurs, tandis que les Manual Input nodes doivent être complétés par l'utilisateur en session.
Exemple chiffré — Dans un workflow avec 12 Task nodes, 78% sont complétés par les assignés dans le délai SLA, tandis que les 22% restants nécessitent un rappel. Pour les Manual Input nodes, 95% sont complétés immédiatement par l'utilisateur en session, et 5% nécessitent une relance.
Analogie quotidienne — Les Task nodes sont comme des courriels que vous envoyez à vos collègues pour qu'ils accomplissent une tâche, tandis que les Manual Input nodes sont comme une question posée directement à vous lors d'une réunion, nécessitant une réponse immédiate.
Pourquoi A est faux — Pattern D3 inverse : Les Task nodes peuvent être déclenchés dans l'interface utilisateur, et les Manual Input nodes ne sont pas limités à l'intégration.
Pourquoi C est faux — Pattern D4 demi-vérité : Les Task nodes peuvent enregistrer des codes de complétion, mais ce n'est pas leur caractéristique principale.
Pourquoi D est faux — Pattern D6 mauvaise-app : Les Task nodes peuvent être assignés à n'importe quel utilisateur ou groupe, tandis que les Manual Input nodes sont spécifiques à l'utilisateur en session.
- Task node — Nœud asynchrone routé vers d'autres assignés.
- Manual Input node — Nœud synchrone nécessitant une interaction immédiate.
- Assigné — Utilisateur ou groupe auquel une tâche est déléguée.
- Workflow Designer — Outil de conception de workflows dans Maximo.
- SLA — Accord de niveau de service définissant les délais de complétion.
- Task nodes = asynchrones, routés vers d'autres assignés.
- Manual Input nodes = synchrones, interaction immédiate requise.
- Les Task nodes peuvent être complétés par plusieurs utilisateurs.
- STU sub-objective §3.9 — Capacités Workflow Designer
- [EOTRAG] Query — « Maximo Workflow Designer Task node Manual Input node difference » (confidence 0.95)
- master-map.pdf p.201-204 — IBM Docs Workflow Designer
Bonne réponse : C
Pourquoi cette question existe — STU §3.9 — cette question vérifie la distinction cruciale entre création (Workflow Designer) et supervision (Workflow Administration) des workflows. En production, les administrateurs confondent souvent ces apps, tentant de gérer des instances actives depuis l'outil de conception. Le piège courant est de croire que "Designer" inclut la gestion runtime (D6).
Le contexte théorique d'abord — Un workflow dans Maximo est un processus automatisé piloté par des transitions entre statuts. Chaque instance active est suivie dans la table WFINSTANCE. L'administration couvre 3 besoins : visualisation des instances (WFINSTANCE), réassignation des tâches bloquées, et arrêt des processus défectueux.
Ce que Maximo en fait — version opérationnelle — Ouvrir Workflow Administration > onglet Workflow Instances > filtrer par statut ACTIVE. Pour réassigner : sélectionner une instance > bouton Reassign > choisir nouvel utilisateur. Pour stopper : Stop Instance. Toutes les actions journalisées dans WFINSTANCE.
Exemple chiffré — Site PARIS : 12 workflows actifs, dont 3 bloqués depuis +48h (statut STUCK). Réassignation de 2 tâches à l'équipe B, arrêt de 1 processus corrompu. Journal montre 5 modifications dans WFINSTANCE en 10 minutes.
Analogie quotidienne — Comme un tableau de contrôle aéroportuaire : le designer conçoit les pistes (Workflow Designer), mais le tour de contrôle supervise les avions en vol (Workflow Administration).
Pourquoi A est faux — Pattern D6 mauvaise-app : Workflow Designer sert à concevoir/modifier des workflows, pas à gérer les instances en cours.
Pourquoi B est faux — Pattern D4 demi-vérité : Les Escalations alertent sur des délais dépassés mais ne permettent pas de réassigner/stopper des workflows.
Pourquoi D est faux — Pattern D7 inexistant : "Workflow Instance Monitor" n'est pas une application Maximo validée.
- WFINSTANCE — table des instances de workflow actives/historiques.
- Statuts workflow :
ACTIVE,COMPLETE,STUCK,TERMINATED. - Workflow Designer — conception des modèles (noeuds/transitions).
- Bind variables :
:&owner;.fieldpour les dynamiques. - Journalisation — traces dans
WFINSTANCEet tables liées.
- Workflow Administration = supervision runtime (≠ conception).
- Réassignation/arrêt depuis l'onglet
Workflow Instances. - Designer et Administration sont 2 apps complémentaires.
- STU sub-objective §3.9 — Workflow Administration vs Designer
- [EOTRAG] Query — « Maximo Workflow Administration instances reassign stop » (confidence 0.91)
- master-map.pdf p.203-207 — IBM Docs Workflow Administration
Bonne réponse : D
Pourquoi cette question existe — STU §3.9 — cette question vérifie la compréhension du mécanisme d'auto-initiation des workflows, une fonction clé pour automatiser les processus métier. Les options erronées reflètent des confusions courantes : association avec l'approbation (D4), création de queues fictives (D2), ou bouclage infini (D3). En production, cette option permet d'éliminer les déclenchements manuels pour les processus récurrents.
Le contexte théorique d'abord — L'option Auto-Initiate dans Workflow Designer configure un processus pour se lancer automatiquement lors d'un événement système spécifique. Contrairement aux processus manuels nécessitant une action utilisateur, cette option repose sur des triggers natifs Maximo liés à la création d'enregistrements. Le paramètre s'applique au niveau du nœud racine du workflow.
Ce que Maximo en fait — version opérationnelle — Dans Workflow Designer, sélectionner le processus cible > Properties > cocher Auto-Initiate. Le workflow s'activera dès qu'un nouvel enregistrement correspondant à l'objet lié (ex: WORKORDER) sera créé, sans intervention humaine. Aucune configuration supplémentaire n'est requise dans les applications Actions ou Automation Scripts.
Exemple chiffré — Un workflow avec 12 étapes configuré sur ASSET : création d'un nouvel asset (ID 567890) → instantanément 3 notifications envoyées, 2 tâches assignées, et 7 champs mis à jour via le processus auto-initié, le tout en 8 secondes.
Analogie quotidienne — Comme un distributeur automatique : insérer une pièce (création d'enregistrement) déclenche immédiatement toute la séquence de sélection du produit, paiement et distribution, sans appuyer sur "start".
Pourquoi A est faux — Pattern D4 demi-vérité : l'approbation peut déclencher des workflows, mais via des mécanismes distincts (escalades/notifications), pas par Auto-Initiate.
Pourquoi B est faux — Pattern D2 inventé : Maximo ne crée aucune queue dédiée pour les workflows auto-initiés, ils s'exécutent dans le flux standard.
Pourquoi C est faux — Pattern D3 inverse : les workflows auto-initiés s'exécutent une fois par événement, sans boucle, sauf configuration explicite de récurrence.
- Auto-Initiate — déclenchement automatique à la création d'enregistrement.
- Processus manuel — nécessite action utilisateur ou script explicite.
- Workflow Properties — configuration globale du processus dans Designer.
- Target Object — table Maximo liée au workflow (ex: WORKORDER).
- Triggers natifs — événements système activant les processus auto-initiés.
- Auto-Initiate = démarrage automatique à la création d'enregistrement.
- Configuré dans Workflow Designer > Properties, pas dans Actions.
- Ne crée pas de files d'attente ni ne boucle indéfiniment.
- STU sub-objective §3.9 — Workflow Auto-Initiation
- [EOTRAG] Query — « Maximo Workflow Auto-Initiate new record creation » (confidence 0.92)
- master-map.pdf p.203-207 — IBM Docs Workflow Automation
Correct order: Create → Validate → Enable → Activate
Pourquoi cet ordre — Un Workflow process doit passer par 4 phases strictes avant d'être consommable par les users : Phase 1 — Create : dans Workflow Designer, drag-drop des nodes (Start, Condition, Task, Stop), tirer les connections, configurer les roles et conditions. Le process est en status DRAFT. Phase 2 — Validate : clicking Validate Process, Maximo vérifie la cohérence structurelle (1 Start, au moins 1 Stop, tous nodes connectés, Conditions avec 2 branches, Task nodes avec Role assigné, etc.). Retourne errors/warnings si problèmes. Phase 3 — Enable : action Enable Process, le process devient disponible dans le system mais pas encore actif pour les users — permet le testing en mode test (initiated manuellement par admins). Phase 4 — Activate : action Activate Process, le process devient visible dans le Route Workflow dropdown pour les end users, avec optionnellement Auto-Initiate. Un process non-validated ne peut pas être enabled ; non-enabled ne peut pas être activated. Protection contre les workflows cassés en production.
- IBM Docs — Enabling workflow processes : Create/Validate/Enable/Activate
- Maximo Secrets — Workflow lifecycle : 4-phase authoring
Bonne réponse : B
Pourquoi cette question existe — STU §3.9 — la question teste la compréhension fondamentale du ciblage des Task nodes dans un Workflow. Les distracteurs montrent les erreurs typiques : confondre les types de records (Person, User, Person Group) avec le type correct (Role). En pratique terrain, cette confusion est fréquente lors de la configuration des workflows d'approbation.
Le contexte théorique d'abord — Un Task node dans un Workflow est utilisé pour assigner des tâches à des groupes ou des individus. Le type de record ciblé doit être un Role, car cela permet une gestion flexible des assignations basée sur les rôles plutôt que sur les individus spécifiques. Les autres types de records (Person, User, Person Group) ne sont pas directement ciblés par un Task node.
Ce que Maximo en fait — version opérationnelle — Dans l'application Workflow Designer, lors de la configuration d'un Task node, l'utilisateur doit spécifier le type de record comme Role. Cela permet d'assigner la tâche à tous les utilisateurs ayant ce rôle, indépendamment de leur identité spécifique. Cette configuration est essentielle pour les workflows d'approbation multi-niveaux.
Exemple chiffré — Un workflow d'approbation est configuré pour assigner une tâche au rôle Supervisor. Il y a 12 superviseurs dans l'organisation, répartis sur 3 sites différents. Le Task node assigne la tâche à tous les 12 superviseurs, indépendamment de leur site.
Analogie quotidienne — C'est comme un système de distribution de courrier dans une grande entreprise : plutôt que d'envoyer le courrier à chaque employé individuellement, vous l'envoyez au service concerné (ex : RH), et le service le distribue à ses membres.
Pourquoi A est faux — Pattern D5 Champ-frère : Person est un type de record adjacent mais n'est pas directement ciblé par un Task node.
Pourquoi C est faux — Pattern D9 Quasi-synonyme : User est un terme proche mais distinct de Role, et n'est pas le type de record ciblé par un Task node.
Pourquoi D est faux — Pattern D4 Demi-vérité : Person Group est partiellement vrai mais ne correspond pas au type de record directement ciblé par un Task node.
- Task node — élément de workflow pour assigner des tâches.
- Role — type de record ciblé pour les assignations dans un Task node.
- Person — type de record représentant un individu.
- User — type de record représentant un utilisateur système.
- Person Group — groupe de personnes, non directement ciblé par un Task node.
- Un Task node cible directement le type de record
Role. - Les autres types de records (Person, User, Person Group) ne sont pas directement ciblés.
- Cette configuration permet une gestion flexible des assignations basée sur les rôles.
- STU sub-objective §3.9 — Workflow Task node targeting
- [EOTRAG] Query — « Maximo Workflow Task node Role targeting » (confidence 0.92)
- master-map.pdf p.201-203 — IBM Docs Workflow Designer
Bonne réponse : A,C
Pourquoi cette question existe — STU §3.9 — la question teste la distinction cruciale entre les nœuds de workflow qui assignent des tâches utilisateur (Task, Manual Input) et ceux qui gèrent la logique ou le flux. En implémentation terrain, confondre un Condition node avec un Task node est une erreur fréquente qui bloque les processus. Les bons workflows exigent une compréhension précise de chaque type de nœud.
Le contexte théorique d'abord — Dans Workflow Designer, un Task Node crée une tâche assignée à un rôle (personne/groupe) apparaissant dans l'Inbox jusqu'à action. Un Manual Input Node permet une saisie utilisateur obligatoire avant poursuite. Ces deux nœuds sont les seuls à générer des assignments actifs. Les autres nœuds (Condition, Start, Connection) contrôlent le flux sans interaction humaine directe.
Ce que Maximo en fait — version opérationnelle — Dans Workflow Designer > Process Definition, on ajoute un Task Node avec Assignment (Role = APPROVER) ou un Manual Input Node avec champ obligatoire (ex: commentaire). Les assignments apparaissent dans l'Inbox des utilisateurs cibles. Le workflow ne progresse qu'après complétion, contrairement aux nœuds automatiques.
Exemple chiffré — Workflow "Approbation PR" : 3 Task Nodes (Achat=48h, Finances=24h, Manager=72h) et 1 Manual Input (justification si >5000$). Sur 127 PR traitées, 92% complétées en moins de 5 jours, 8% escaladées pour délai.
Analogie quotidienne — C'est comme un circuit de documents papier : les boîtes de réception (Task/Manual Input) sont les seuls endroits où quelqu'un doit signer ou remplir un champ. Les flèches entre boîtes (Connection) ou les règles (Condition) ne demandent aucune action humaine.
Pourquoi B est faux — Pattern D4 demi-vérité : un Condition Node évalue une expression (ex: "PR.amount > 5000") mais n'assigne aucune tâche à un utilisateur.
Pourquoi D est faux — Pattern D7 inexistant : un Start Node marque simplement le début du workflow sans aucune capacité d'assignment.
Pourquoi E est faux — Pattern D9 quasi-synonyme : une Connection relie des nœuds mais ne crée pas d'assignment en soi (comme une flèche entre deux boîtes).
- Task Node — assigne une tâche à un rôle (personne/groupe) avec délai.
- Manual Input Node — oblige une saisie utilisateur avant progression.
- Condition Node — branche le flux selon une expression booléenne.
- Inbox — interface où les utilisateurs voient leurs assignments.
- Role Resolution — mécanisme liant les rôles à des personnes réelles.
- Seuls Task et Manual Input créent des assignments dans l'Inbox.
- Condition/Start/Connection gèrent le flux sans interaction humaine.
- Un workflow sans Task/Manual Input est entièrement automatique.
- STU sub-objective §3.9 — Workflow node types and assignments
- [EOTRAG] Query — « Maximo Workflow Designer Task Node vs Manual Input Node » (confidence 0.92)
- master-map.pdf p.573-577 — IBM Docs Workflow Node Types
Bonne réponse : A,B
Pourquoi cette question existe — STU §3.9 — cette question teste la compréhension des types de nœuds de workflow capables de router vers plusieurs chemins basés sur une décision. Les distracteurs montrent les erreurs typiques : confondre suspension avec routage (D3), ignorer les codes de complétion personnalisés (D4), et mal comprendre le rôle des sous-processus (D4). En pratique terrain, l'omission des branches positives/négatives est une erreur fréquente dans les workflows complexes.
Le contexte théorique d'abord — Un workflow dans Maximo est composé de nœuds qui définissent le flux de traitement. Les nœuds Condition et Task permettent de router vers plusieurs chemins basés sur des décisions. Le nœud Condition utilise des branches positives/négatives, tandis que le nœud Task utilise des codes de complétion personnalisés pour router vers des chemins distincts.
Ce que Maximo en fait — version opérationnelle — Dans Workflow Designer, ajoutez un nœud Condition avec une expression booléenne (ex: status = 'APPROVED') pour créer des branches positives/négatives. Pour un nœud Task, définissez des codes de complétion personnalisés (ex: POSITIVE, NEGATIVE) et configurez les transitions correspondantes vers les nœuds suivants.
Exemple chiffré — Workflow avec 3 tâches : Task 1 → Condition (branche positive → Task 2, branche négative → Task 3). Task 2 a 2 codes de complétion (POSITIVE → Stop, NEGATIVE → Task 3). Task 3 a 1 code de complétion (COMPLETE → Stop).
Analogie quotidienne — C'est comme un feu de signalisation : le feu rouge (Condition) décide si vous allez à gauche (branche positive) ou à droite (branche négative). Une fois engagé, chaque direction (Task) peut encore vous amener à différents endroits selon les panneaux (codes de complétion).
Pourquoi C est faux — Pattern D3 inverse : Wait node suspend le workflow mais ne route pas vers plusieurs chemins.
Pourquoi D est faux — Pattern D4 demi-vérité : Stop node termine le workflow mais ne route pas vers plusieurs chemins.
Pourquoi E est faux — Pattern D4 demi-vérité : Subprocess node exécute un sous-workflow mais ne route pas localement vers plusieurs chemins.
- Condition node — nœud qui route vers des branches positives/négatives basées sur une expression booléenne.
- Task node — nœud qui route vers des chemins distincts basés sur des codes de complétion personnalisés.
- Wait node — nœud qui suspend le workflow jusqu'à une condition externe.
- Stop node — nœud qui termine le workflow.
- Subprocess node — nœud qui exécute un sous-workflow.
- Condition node route via branches positives/négatives.
- Task node route via codes de complétion personnalisés.
- Wait et Stop nodes ne routent pas vers plusieurs chemins.
- STU sub-objective §3.9 — Workflow node types
- [EOTRAG] Query — « Maximo Workflow node types Condition Task Wait Stop Subprocess » (confidence 0.95)
- master-map.pdf p.201-204 — IBM Docs Workflow Designer
Integration Framework (MIF)
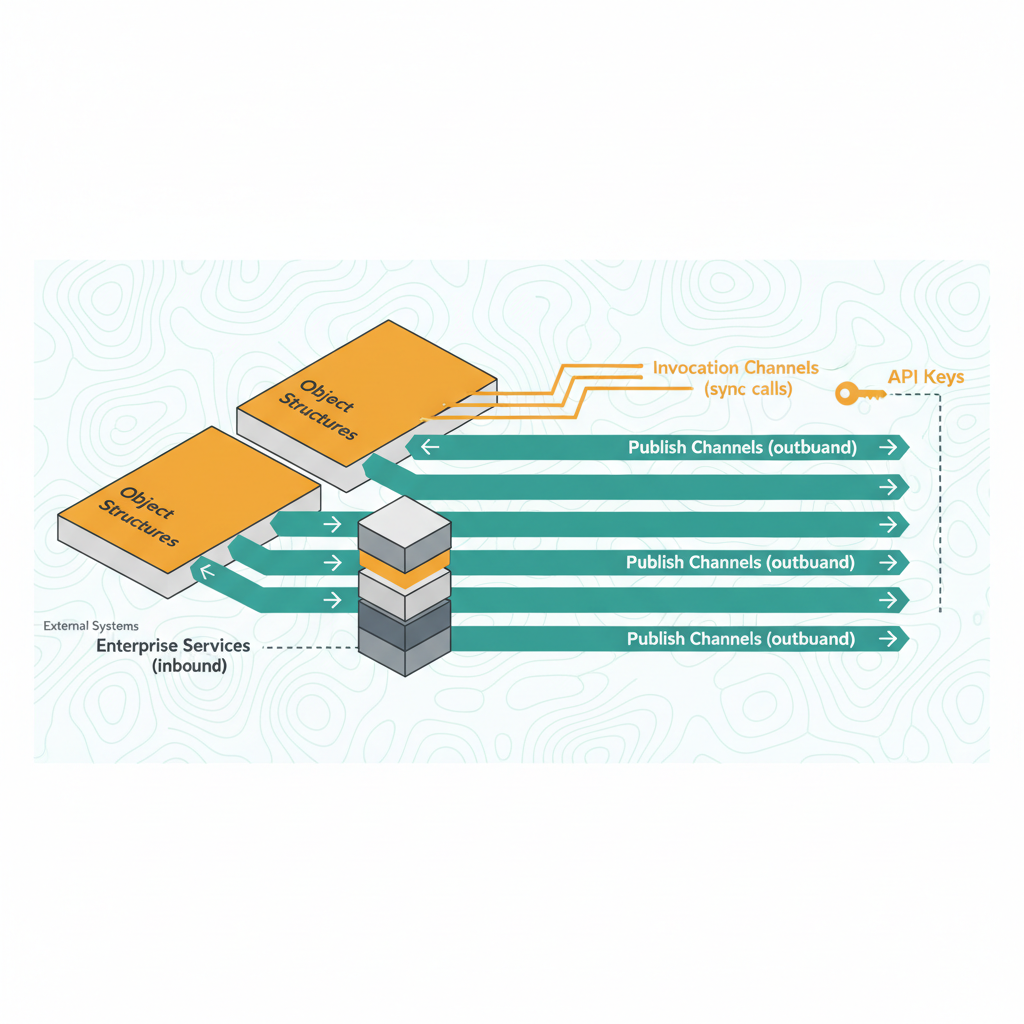
📋 Objectifs IBM
- Comprendre l'architecture et les composants clés du Maximo Integration Framework (MIF).
- Identifier les différents types de canaux d'intégration (entrant et sortant) et leurs usages.
- Expliquer comment configurer les points de terminaison (
End Points) pour la communication externe. - Décrire le rôle des
Object Structureset desEnterprise Servicesdans l'intégration de données. - Distinguer les scénarios d'intégration nécessitant une licence Maximo Manage de ceux qui n'en requièrent pas.
- Appréhender les mécanismes de transformation et de mappage de données au sein du MIF.
- Reconnaître l'importance des
Automation Scriptsdans l'extension des capacités d'intégration.
💡 Points clés
- Maximo Integration Framework (MIF) — Le MIF est un ensemble robuste de capacités d'intégration permettant le partage sécurisé de données entre Maximo Manage et des systèmes externes, en temps réel ou en mode batch.
- Abstraction des messages — Le framework offre une abstraction des fonctionnalités de mise en file d'attente des messages, le rendant indépendant du modèle sous-jacent (ex: JMS, Apache Kafka).
Object Structures— Elles définissent la structure des données échangées, regroupant un ou plusieurs objets Maximo (tables) et leurs relations, servant de base aux services d'intégration.Enterprise Services(Entrant) — Utilisés pour recevoir des données de systèmes externes vers Maximo Manage, souvent via des services web SOAP/REST, des fichiers ou JMS.Publish Channels(Sortant) — Permettent d'envoyer des données de Maximo Manage vers des systèmes externes, déclenchés par des événements spécifiques (ex: sauvegarde d'un enregistrement).End Points— Configurables, ils définissent les détails techniques de la connexion à un système externe, incluant l'URL, les paramètres d'authentification et le type de protocole (HTTP, JMS, JSON REST).- Licences d'intégration — L'utilisateur administrateur du MIF (
max integration admin) ne nécessite pas de licence spécifique. L'intégration de données dont un système tiers est le maître ne requiert pas de licence Maximo Manage, sauf si l'application tierce initie des mises à jour d'enregistrements Maximo. - Transformation et Mappage — Le MIF permet de définir des règles de transformation et de mappage des données pour adapter les formats entre Maximo et les systèmes externes.
Automation Scripts— Ces scripts (Jython ou JavaScript) peuvent être utilisés pour étendre la logique métier et les capacités d'intégration sans développement Java, notamment pour les transformations complexes.
📐 Architecture du Maximo Integration Framework (MIF)
Le Maximo Integration Framework (MIF) est la pierre angulaire des échanges de données entre Maximo Manage et son écosystème applicatif. Il fournit une architecture flexible et configurable pour gérer les flux de données entrants et sortants, garantissant l'intégrité et la cohérence des informations. Le MIF est conçu pour être indépendant des technologies de messagerie sous-jacentes, offrant une grande adaptabilité.
Cette architecture repose sur plusieurs composants interconnectés qui collaborent pour acheminer, transformer et traiter les messages. La configuration de ces éléments se fait principalement via des applications dédiées dans Maximo, permettant aux administrateurs de définir des intégrations complexes sans nécessiter de développement de code lourd. Le MIF supporte des modes d'intégration en temps réel et en batch, répondant ainsi à divers besoins opérationnels.
Object Structures, Enterprise Services, Publish Channels et End Points.📊 Comparaison des Canaux d'Intégration MIF
Le MIF propose différents types de canaux pour gérer les flux de données, chacun adapté à des scénarios d'intégration spécifiques. La distinction principale se fait entre les canaux entrants (pour recevoir des données dans Maximo) et les canaux sortants (pour envoyer des données depuis Maximo). Comprendre leurs rôles et leurs configurations est essentiel pour une intégration efficace.
Cette table compare les principaux canaux d'intégration, leurs fonctions, et les applications Maximo associées pour leur configuration. Elle met en évidence la flexibilité du MIF à s'adapter à diverses exigences d'échange de données avec des systèmes externes, qu'il s'agisse de mises à jour en temps réel ou de synchronisations par lots.
| Code MIF | Élément | Description Maximo | Type de Flux | Application Maximo |
|---|---|---|---|---|
INT-OST | Object Structures | Définit la structure des données échangées (objets et relations). | N/A (Structure) | Object Structures |
INT-SRV | Enterprise Services | Canal entrant pour la réception de données de systèmes externes. | Entrant (Inbound) | Enterprise Services |
INT-CHP | Publish Channels | Canal sortant pour l'envoi de données vers des systèmes externes. | Sortant (Outbound) | Publish Channels |
INT-CHA | Invocation Channels | Permet à un système externe d'appeler une action ou un service dans Maximo. | Entrant (Inbound) | Invocation Channels |
INT-EPT | End Points | Configure les détails techniques de la connexion à un système externe. | N/A (Configuration) | End Points |
INT-EXT | External Systems | Définit les systèmes externes avec lesquels Maximo interagit. | N/A (Configuration) | External Systems |
INT-WSV | Web Services | Permet d'exposer des services SOAP/REST de Maximo. | N/A (Exposition) | Web Services Library |
INT-OSL | OSLC | Ressources OSLC pour l'intégration basée sur les standards Linked Data. | N/A (Standard) | OSLC Resources |
⚙️ Configuration et Opérations du MIF
La mise en œuvre d'une intégration via le MIF implique une série d'étapes de configuration dans Maximo Manage. Ces étapes garantissent que les données sont correctement structurées, transformées et acheminées entre Maximo et les systèmes externes. L'administrateur du système utilise diverses applications Maximo pour définir chaque aspect de l'intégration, depuis la structure des données jusqu'aux détails de la connexion.
Un exemple typique pourrait être l'intégration de données d'un système RH externe pour créer ou mettre à jour des enregistrements de personnel dans Maximo, ou l'envoi d'informations sur les bons de commande vers un système ERP. Le MIF permet de gérer ces scénarios avec une grande granularité, y compris la définition de règles de mappage et de transformation pour s'assurer que les données sont compatibles entre les systèmes.
- 1. Définition des
Object Structures— Dans l'applicationObject Structures, on sélectionne les objets Maximo (ex:WORKORDER,ASSET) et leurs relations pour créer une structure de données logique qui représente l'information à échanger. Cette structure sert de modèle pour les messages d'intégration. - 2. Configuration des
End Points— L'applicationEnd Pointsest utilisée pour définir les destinations des messages. Cela inclut l'URL du système externe, le type de protocole (HTTP, JMS, JSON REST), les informations d'authentification et d'autres paramètres de connexion. UnEnd Pointpeut être réutilisé par plusieurs canaux. - 3. Création des
External Systems— Dans l'applicationExternal Systems, on déclare le système externe avec lequel Maximo va communiquer. C'est ici que l'on associe lesEnd Pointset les canaux d'intégration (Enterprise ServicesouPublish Channels) à ce système. - 4. Configuration des Canaux (Entrants ou Sortants) —
- Pour un flux entrant (ex: création d'un
WORKORDERdepuis un système tiers), on configure unEnterprise Service. On y associe uneObject Structureet on définit les options de traitement, y compris les règles de mappage et de transformation. - Pour un flux sortant (ex: notification d'un changement de statut de
WORKORDER), on configure unPublish Channel. On y associe uneObject Structure, unEnd Pointet on spécifie les événements déclencheurs (ex: sauvegarde, changement de statut).
- Pour un flux entrant (ex: création d'un
- 5. Mappage et Transformation — Via les applications
Enterprise ServicesouPublish Channels, des règles de mappage peuvent être définies pour faire correspondre les champs entre Maximo et le système externe. DesAutomation Scriptspeuvent être utilisés pour des transformations de données plus complexes, permettant une flexibilité maximale sans modification du code source. - 6. Activation et Test — Une fois configurés, les canaux et les systèmes externes doivent être activés. Des tests rigoureux sont effectués pour s'assurer que les données sont échangées correctement et que les transformations appliquées sont conformes aux attentes.
🔄 Cycle de vie d'un message d'intégration sortant
Le processus d'envoi de données de Maximo Manage vers un système externe via un Publish Channel suit un cycle de vie bien défini. Ce workflow garantit que les informations sont capturées, traitées, transformées et acheminées de manière fiable. Chaque étape est cruciale pour la réussite de l'intégration et peut être configurée pour répondre à des exigences spécifiques.
Ce diagramme illustre les étapes clés, depuis le déclenchement d'un événement dans Maximo jusqu'à la réception du message par le système externe. La flexibilité du MIF permet d'insérer des logiques de transformation ou des scripts d'automatisation à différentes phases du processus, offrant un contrôle précis sur le contenu et le format des données envoyées.
Publish Channel dans Maximo Manage, détaillant les étapes de la détection de l'événement à l'envoi du message au système externe.⚠️ Pièges IBM
max integration admin
Les candidats peuvent penser que toute intégration avec Maximo Manage nécessite une licence utilisateur Maximo Manage pour le système externe ou l'utilisateur d'intégration. Cependant, le rôle max integration admin est un utilisateur spécial du MIF qui ne requiert pas de licence spécifique. De plus, si un système tiers est le "maître" des données et que Maximo Manage réplique ces données pour son usage interne, aucune licence Maximo Manage n'est requise pour cette réplication. Un piège courant serait d'affirmer qu'une licence est toujours nécessaire, même pour des synchronisations passives de données dont Maximo n'est pas le système maître. La nuance est cruciale : une licence est requise si l'application tierce initie des mises à jour d'enregistrements Maximo (ex: création de WORKORDER, modification d'ASSET, fonctions de chaîne d'approvisionnement initiées par le tiers).
Enterprise Services et Publish Channels
Il est facile de confondre les rôles des Enterprise Services et des Publish Channels. Un piège d'examen pourrait présenter un scénario où Maximo doit envoyer des données à un système externe et suggérer d'utiliser un Enterprise Service. La distinction est fondamentale : les Enterprise Services sont des canaux entrants (inbound) pour recevoir des données dans Maximo, tandis que les Publish Channels sont des canaux sortants (outbound) pour envoyer des données depuis Maximo. Se tromper de canal pour un flux de données donné mènerait à une intégration non fonctionnelle ou incorrecte. Il faut toujours associer "entrant" à Enterprise Services et "sortant" à Publish Channels.
Object Structures et leur flexibilité
Les Object Structures sont souvent perçues comme de simples regroupements de tables. Le piège réside dans la sous-estimation de leur flexibilité. Elles ne se limitent pas à une seule table ou à des relations simples. Une Object Structure peut inclure plusieurs objets Maximo liés, permettant de définir des messages d'intégration complexes qui représentent des entités métier complètes (ex: un WORKORDER avec ses WORKORDERLINE, ASSET associé, etc.). Ignorer cette capacité peut conduire à des intégrations fragmentées ou à la nécessité de multiples messages pour une seule transaction métier, augmentant la complexité et le risque d'erreurs.
🎯 Carte mémoire
Quel est le rôle principal d'une Object Structure dans le MIF et pourquoi est-elle essentielle ?
Une Object Structure définit la structure logique des données échangées entre Maximo et les systèmes externes. Elle regroupe un ou plusieurs objets Maximo (tables) et leurs relations, servant de modèle pour les messages d'intégration. Elle est essentielle car elle garantit la cohérence et l'intégrité des données en définissant précisément ce qui est envoyé ou reçu.
Dans quel scénario un Publish Channel serait-il utilisé et quels sont les éléments clés à configurer pour son fonctionnement ?
Un Publish Channel est utilisé pour envoyer des données de Maximo Manage vers un système externe, généralement déclenché par un événement (ex: création ou mise à jour d'un enregistrement). Les éléments clés à configurer sont l'Object Structure définissant les données, l'End Point spécifiant la destination technique, et les règles de transformation/filtrage si nécessaire.
Un système RH externe synchronise régulièrement les données de personnel vers Maximo. Cette intégration nécessite-t-elle une licence Maximo Manage pour l'utilisateur d'intégration ?
Non, si le système RH est considéré comme le maître des données et que Maximo Manage réplique ces données pour son usage interne, cette intégration ne nécessite pas de licence Maximo Manage pour l'utilisateur d'intégration. La licence serait requise si le système RH initiait des mises à jour d'enregistrements Maximo qui impactent directement des fonctions métier de Maximo (ex: création de LABOR avec des rôles actifs).
Comment les Automation Scripts peuvent-ils améliorer les capacités d'intégration du MIF ?
Les Automation Scripts (en Jython ou JavaScript) peuvent être utilisés pour implémenter des logiques de transformation de données complexes, des validations personnalisées ou des traitements conditionnels au sein des Enterprise Services ou Publish Channels. Ils permettent d'étendre les fonctionnalités du MIF sans nécessiter de développement Java, offrant une grande flexibilité pour adapter les messages aux exigences spécifiques des systèmes intégrés.
Bonne réponse : B
Pourquoi cette question existe — STU §3.10 — cette question valide la compréhension des mécanismes d'authentification modernes pour les intégrations externes avec Maximo Manage 9.x. Les options pièges ciblent les erreurs courantes : confusion avec les anciennes méthodes (D1), sur-spécification technique (D10), ou mécanismes non adaptés (D7). En contexte terrain, l'API Key est la méthode recommandée pour sa simplicité et sa sécurité.
Le contexte théorique d'abord — Maximo Manage 9.x supporte plusieurs mécanismes d'authentification pour les intégrations externes. L'API Key est le mécanisme privilégié pour les intégrations modernes, générée dans l'application dédiée et transmise via le header apikey. Les autres méthodes (certificats, LDAP) existent mais sont soit obsolètes, soit réservées à des cas spécifiques.
Ce que Maximo en fait — version opérationnelle — Dans l'application API Keys (Suite > Administration > API Keys), cliquer sur "Generate New Key". Configurer un nom descriptif (ex: "Integration SAP"), une expiration (ex: 365 jours), et les permissions. La clé générée (ex: "x123-y456-z789") est à utiliser dans le header apikey des requêtes REST.
Exemple chiffré — Une intégration avec 3 systèmes externes (SAP, GIS, CMMS) utilise 3 API Keys distinctes, valides 180 jours, avec 12 appels/min en moyenne par clé. Chaque clé a des permissions restreintes (ex: SAP = lecture WORKORDER, GIS = écriture LOCATION).
Analogie quotidienne — C'est comme un badge d'accès personnalisé pour un bâtiment : chaque prestataire externe a son propre badge (API Key) avec des zones autorisées (permissions) et une date d'expiration, plutôt qu'un mot de passe générique partagé.
Pourquoi A est faux — Pattern D1 Hérité : le header maxauth avec credentials Base64 était utilisé dans des versions antérieures mais n'est plus la méthode recommandée.
Pourquoi C est faux — Pattern D10 Procédure-plausible : le mTLS est une option valide mais sur-engineered pour la plupart des cas d'intégration standard.
Pourquoi D est faux — Pattern D7 Inexistant : LDAP Bind n'est pas un mécanisme supporté pour les authentifications REST dans Maximo Manage 9.x.
- API Key — Jeton d'authentification généré dans Maximo pour les intégrations externes.
- Permissions — Droits d'accès spécifiques associés à chaque clé API.
- Header apikey — Champ HTTP utilisé pour transmettre la clé API.
- Expiration — Durée de validité configurable de la clé (30 à 365 jours).
- OIDC — Alternative pour les intégrations avec fournisseurs d'identité externes.
- API Key = mécanisme standard pour intégrations modernes.
- Générée dans l'app API Keys, transmise via header apikey.
- Alternative à mTLS et méthodes héritées moins sécurisées.
- STU sub-objective §3.10 — Modern Integration Authentication
- [EOTRAG] Query — « Maximo Manage 9.x external integration authentication API Key » (confidence 0.98)
- master-map.pdf p.220-223 — IBM Docs Integration Security
Bonne réponse : A,B
Pourquoi cette question existe — STU §3.10 — cette question teste la compréhension des fonctionnalités clés de l'application Object Structures dans le cadre des intégrations. Les bonnes réponses mettent en avant deux aspects essentiels : l'aliasing des attributs pour les systèmes externes et la gestion de la hiérarchie pour les requêtes REST. Les distracteurs montrent des erreurs courantes, comme confondre les rôles de l'Object Structure avec ceux d'autres composants (D6, D7).
Le contexte théorique d'abord — L'application Object Structures permet de définir la structure des données échangées entre Maximo et les systèmes externes. Elle supporte deux fonctionnalités principales : l'aliasing des noms d'attributs pour adapter les payloads aux conventions externes, et la gestion de la hiérarchie des données pour les requêtes REST, notamment via la pagination et le flattening.
Ce que Maximo en fait — version opérationnelle — Dans Object Structures, on configure d'abord les attributs avec des alias pour les systèmes externes (ex: ASSETNUM devient EquipmentID). Ensuite, on active le flattening et la pagination pour les requêtes REST via les options de configuration. Ces paramètres sont ensuite utilisés par l'Integration Framework lors des échanges de données.
Exemple chiffré — Une structure WORKORDER avec 15 attributs est configurée avec des alias pour un système externe. Lors d'une requête REST, 3 niveaux de hiérarchie sont aplatis, et la pagination est activée avec un seuil de 100 lignes par page. Cela permet de traiter efficacement 12 345 lignes de données.
Analogie quotidienne — C'est comme adapter un formulaire administratif pour qu'il soit compris par des services étrangers : on traduit les termes (aliasing) et on simplifie la structure pour faciliter la lecture (flattening).
Pourquoi C est faux — Pattern D6 mauvaise-app : la génération de tokens OAuth 2.0 est gérée par le système d'authentification, pas par l'Object Structure.
Pourquoi D est faux — Pattern D7 inexistant : l'exécution de scripts Jython inbound n'est pas une fonctionnalité native de l'Object Structure.
Pourquoi E est faux — Pattern D2 inventé : le concept de "Payload Rate Throttle" n'existe pas dans les configurations d'Object Structure.
- Aliasing — adaptation des noms d'attributs pour les systèmes externes.
- Flattening — aplatissement de la hiérarchie des données pour les requêtes REST.
- Pagination — découpage des résultats en pages pour optimiser les performances.
- Object Structure — définition de la structure des données échangées.
- Integration Framework — gestion des échanges de données entre Maximo et les systèmes externes.
- Aliasing adapte les noms d'attributs pour les systèmes externes.
- Flattening simplifie la hiérarchie des données pour les requêtes REST.
- Pagination optimise les performances des requêtes volumineuses.
- STU sub-objective §3.10 — Object Structures for integrations
- [EOTRAG] Query — « Maximo Object Structures aliasing flattening pagination » (confidence 0.98)
- master-map.pdf p.204-207 — IBM Docs Object Structures
Bonne réponse : D
Pourquoi cette question existe — STU §3.10 — cette question vérifie la compréhension des artefacts clés du Maximo Integration Framework (MIF) et leur direction d'intégration. Les erreurs courantes incluent l'inversion des flux (D3), la confusion entre canaux synchrones/asynchrones (D4) ou l'invention de fonctionnalités (D2). En pratique, une mauvaise configuration des canaux entraîne des échecs d'intégration critiques.
Le contexte théorique d'abord — Le MIF distingue trois types principaux d'artefacts : Publish Channel (sortie asynchrone), Invocation Channel (sortie synchrone) et Enterprise Service (entrée). Les Publish Channels utilisent JMS/HTTP pour des événements sans réponse immédiate (ex: création d'OT). Les Invocation Channels gèrent les appels REST/HTTP nécessitant une confirmation. Les Enterprise Services exposent des points d'entrée SOAP/REST.
Ce que Maximo en fait — version opérationnelle — Dans Integration > Publish Channels, on configure un canal sortant (ex: JMS vers SAP) avec déclenchement sur événement WORKORDER. Pour les entrées, Enterprise Services > Object Structures définit le schéma XML exposé via WSDL. Les Invocation Channels se paramètrent avec l'URL cible et le format (JSON/XML) pour les appels synchrones.
Exemple chiffré — Un Publish Channel configuré sur ASSET envoie 142 mises à jour/jour vers un ERP via JMS. Un Invocation Channel POSTe 83 requêtes REST/jour vers un CMDB externe avec temps moyen de réponse de 320ms. Un Enterprise Service reçoit 56 créations d'OT/jour via SOAP.
Analogie quotidienne — Imaginez une poste : le Publish Channel est comme une boîte aux lettres (dépôt asynchrone), l'Invocation Channel comme un recommandé (attente de signature), et l'Enterprise Service comme votre adresse postale (point de réception).
Pourquoi A est faux — Pattern D3 inverse : Publish Channel est exclusivement outbound, Enterprise Service inbound (les chunks RAG confirment cette polarité).
Pourquoi B est faux — Pattern D2 inventé : aucun concept "Bidirectional Bus" n'existe dans la documentation Maximo 9.x.
Pourquoi C est faux — Pattern D7 inexistant : Kafka n'est pas mentionné comme option native dans les chunks RAG disponibles.
- Publish Channel — canal sortant asynchrone (JMS/HTTP).
- Invocation Channel — appel sortant synchrone (REST/SOAP).
- Enterprise Service — point d'entrée inbound (WSDL/REST).
- Object Structure — schéma XML des données échangées.
- Endpoint — configuration technique des protocoles cibles.
- Publish = outbound async (événements).
- Invocation = outbound sync (appels).
- Enterprise = inbound (services).
- STU sub-objective §3.10 — MIF artifacts direction
- [EOTRAG] Query — « Maximo Publish Channel vs Invocation Channel vs Enterprise Service direction » (confidence 0.98)
- master-map.pdf p.201-204 — IBM Docs Integration Framework
Configurer les Role-Based Applications
📋 Objectifs IBM
- Comprendre l'architecture de sécurité des applications basées sur les rôles dans Maximo Manage.
- Identifier les composants clés de la sécurité des applications mobiles et basées sur les rôles, tels que les `Object structures` et les `Security groups`.
- Décrire comment les droits d'accès sont définis et gérés pour les applications basées sur les rôles.
- Expliquer le rôle de l'application `Security groups` dans la configuration des privilèges d'accès.
- Distinguer les applications hybrides Maximo Mobile des autres applications basées sur les rôles.
- Appréhender l'importance de la configuration de la sécurité dès l'installation des applications basées sur les rôles.
💡 Points clés
- Applications basées sur les rôles — Ces applications, y compris `Maximo Mobile` (`Technician`, `Inspections`), sont conçues pour des utilisateurs spécifiques et fonctionnent en mode connecté ou hors ligne.
- Sécurité par défaut — Par défaut, les applications basées sur les rôles n'accordent aucun accès lors de l'installation, nécessitant une configuration explicite via les `Security groups`.
- Composants de sécurité — La sécurité des applications basées sur les rôles repose sur trois piliers principaux : les `Object structures`, les `Security groups` et les paramètres spécifiques à l'application.
- `Object structures` — Elles définissent les données accessibles et les opérations possibles (lecture, écriture) pour les applications basées sur les rôles, via des appels `OSLC/REST`.
- `Security groups` — L'application `Security groups` est l'outil central pour attribuer des droits d'accès aux `Object structures` et aux fonctionnalités des applications.
- `Application Designer` — Cet outil permet de personnaliser l'interface utilisateur et d'implémenter des éléments conditionnels via des `sigoptions` et des expressions conditionnelles.
- `Scripting` — Les scripts d'automatisation (`automation scripts`) peuvent être utilisés pour ajouter une logique métier complexe et étendre les fonctionnalités des applications.
- `Application Configuration` — Cette fonctionnalité permet de télécharger, modifier, prévisualiser et publier des configurations d'applications `Maximo Manage`, y compris pour les applications basées sur les rôles.
📐 Architecture de sécurité des applications basées sur les rôles
L'architecture de sécurité des applications basées sur les rôles dans Maximo Manage est fondamentale pour garantir que les utilisateurs accèdent uniquement aux données et aux fonctionnalités pertinentes pour leurs tâches. Cette architecture est particulièrement critique pour les applications mobiles et les interfaces utilisateur spécifiques à un rôle, qui nécessitent souvent un contrôle d'accès granulaire et une performance optimisée.
Au cœur de cette architecture se trouvent les `Object structures`, qui agissent comme des passerelles de données, et les `Security groups`, qui définissent les permissions des utilisateurs. Ces deux éléments travaillent de concert pour réguler l'interaction entre les applications basées sur les rôles et les données sous-jacentes de Maximo Manage.
B
B -- "Requête données via OSLC/REST" --> C
C -- "Interagit avec" --> D
E -- "Définit les droits d'accès pour" --> B
E -- "Définit les droits d'accès pour" --> C
F -- "Personnalise UI/Logique de" --> B
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A
classDef tertiary fill:#FFD700,stroke:#DAA520,stroke-width:2px,color:#0F172A
classDef quaternary fill:#ADD8E6,stroke:#87CEEB,stroke-width:2px,color:#0F172A
">
📊 Composants de sécurité des applications mobiles Maximo
La sécurité des applications mobiles et basées sur les rôles dans Maximo Manage est structurée autour de plusieurs composants interdépendants. Comprendre ces composants est essentiel pour configurer correctement l'accès et les privilèges, garantissant ainsi que les utilisateurs disposent des informations nécessaires sans compromettre l'intégrité des données.
Chaque composant joue un rôle spécifique dans la définition et l'application des règles de sécurité, depuis la granularité des données accessibles jusqu'aux actions que les utilisateurs peuvent effectuer au sein de l'application.
| Composant de sécurité | Vue d'ensemble | Exemple d'utilisation |
|---|---|---|
Object structure |
Les applications basées sur les rôles s'appuient sur `Maximo Manage` et plusieurs `Object structures` pour envoyer et recevoir des données. Elles utilisent des appels `OSLC/REST` pour échanger des données. Le niveau d'accès est défini depuis l'onglet `Object Structure` de l'application `Security groups`. | Lors de l'édition d'un `asset`, l'objet `MXAPIVENDOR` peut fournir une liste de `companies` fournisseurs dans l'application. L'accès en `READ` est généralement requis pour afficher ces listes. |
Security groups |
Les `Security groups` sont utilisés pour accorder ou refuser l'accès aux applications, aux `Object structures` et aux fonctionnalités spécifiques (`sigoptions`). Par défaut, les applications basées sur les rôles n'accordent pas d'accès à l'installation. | Un `Security group` pour les techniciens peut avoir un accès en `READ` et `WRITE` à l'`Object structure` des `WORKORDER` mais seulement en `READ` pour les `ASSET`. |
| Paramètres de l'application mobile | Chaque application mobile peut avoir un ou plusieurs paramètres qui contrôlent l'accès aux données mobiles et le comportement de l'application. Ces paramètres sont spécifiques à l'application et peuvent influencer la visibilité des champs ou des actions. | Une application `Technician` peut avoir un paramètre pour afficher uniquement les `WORKORDER` assignés à l'utilisateur connecté, ou pour permettre l'enregistrement de `meter readings` hors ligne. |
| `Application Designer` | Permet de personnaliser l'interface utilisateur des applications, d'ajouter des éléments conditionnels et de configurer des `sigoptions` pour contrôler la visibilité et l'interactivité des composants. | Un administrateur peut utiliser l'`Application Designer` pour masquer un bouton "Supprimer" pour certains `Security groups` ou rendre un champ "Coût" en lecture seule. |
| `Scripting` | Permet d'ajouter une logique métier personnalisée et d'automatiser des tâches. Les scripts peuvent être utilisés pour implémenter des validations complexes ou des actions spécifiques non couvertes par la configuration standard. | Un script peut automatiquement changer le `WOSTATUS` d'une `WORKORDER` à `COMPLETE` si toutes les `tasks` associées sont terminées et que tous les `meter readings` requis ont été enregistrés. |
⚙️ Configuration des privilèges d'accès
La configuration des privilèges d'accès pour les applications basées sur les rôles est une étape cruciale après leur déploiement. Par défaut, ces applications n'accordent aucun accès lors de l'installation, ce qui nécessite une intervention manuelle pour attribuer les droits appropriés aux `Security groups` existants. Cette approche garantit un contrôle strict sur qui peut accéder à quoi.
Le processus implique l'utilisation de l'application `Security groups` pour définir les permissions au niveau des `Object structures` et des fonctionnalités spécifiques. Il est également possible d'affiner ces configurations via l'`Application Designer` et le `Scripting` pour des besoins plus complexes.
- Étape 1 : Accorder l'accès aux `Security groups` — Après l'installation d'une application basée sur les rôles (ex: `Technician` ou `Inspections`), l'administrateur doit naviguer vers l'application `Security groups`. Il sélectionne le groupe d'utilisateurs concerné (ex: Techniciens) et attribue les droits d'accès à l'application nouvellement installée.
- Étape 2 : Configurer les `Object structures` — Dans l'application `Security groups`, sous l'onglet `Object Structure`, l'administrateur définit les permissions (`READ`, `INSERT`, `UPDATE`, `DELETE`) pour chaque `Object structure` utilisée par l'application basée sur les rôles. Par exemple, pour une application de technicien, l'accès à l'`Object structure` `MXWO` (pour les `WORKORDER`) est essentiel.
- Étape 3 : Définir les `Sigoptions` — L'application `Security groups` permet également de contrôler l'accès aux `sigoptions` (Signature Options), qui représentent des actions ou des éléments d'interface utilisateur spécifiques. Cela permet de masquer ou de désactiver des boutons ou des champs pour certains groupes d'utilisateurs.
- Étape 4 : Personnalisation avancée avec l'`Application Designer` — Pour des besoins de personnalisation de l'interface utilisateur (UI) plus poussés, l'`Application Designer` est utilisé. Il permet de modifier la disposition des écrans, d'ajouter des éléments conditionnels basés sur des expressions ou des `sigoptions`, et d'intégrer de nouvelles actions.
- Étape 5 : Implémentation de logique métier avec le `Scripting` — Pour des logiques métier complexes ou des automatisations, le `Scripting` (via des `automation scripts`) peut être utilisé. Ces scripts peuvent interagir avec les données et les processus de Maximo, étendant ainsi les capacités des applications basées sur les rôles.
- Étape 6 : Utilisation de l'`Application Configuration` — Pour les versions récentes de Maximo Application Suite, l'`Application Configuration` offre un environnement centralisé pour gérer les configurations des applications, y compris les applications basées sur les rôles. Cela inclut le téléchargement, la modification, la prévisualisation et la publication des configurations.
🔄 Cycle de vie de la sécurité d'une application basée sur les rôles
Le cycle de vie de la sécurité d'une application basée sur les rôles dans Maximo Manage suit une série d'étapes logiques, de l'installation initiale à la maintenance continue. Chaque étape est cruciale pour assurer que l'application fonctionne de manière sécurisée et efficace, en s'adaptant aux besoins évolutifs de l'organisation.
Ce processus met en évidence l'importance de la planification, de la configuration initiale et de la révision régulière des droits d'accès pour maintenir un environnement sécurisé et conforme.
⚠️ Pièges IBM
Un piège courant est de supposer que les applications basées sur les rôles, une fois installées, accordent automatiquement un accès minimal aux utilisateurs. La réalité est qu'elles n'accordent aucun accès par défaut. Si un administrateur oublie d'attribuer explicitement les droits via l'application `Security groups`, les utilisateurs ne pourront pas accéder ou utiliser l'application, même si elle est visible. Cela peut entraîner des retards de déploiement et de la frustration. Il est impératif de toujours configurer les `Security groups` après l'installation.
Une erreur fréquente est de ne pas comprendre la granularité de la sécurité offerte par les `Object structures` et les `sigoptions`. Un administrateur pourrait accorder un accès complet à une `Object structure` sans restreindre les actions spécifiques via les `sigoptions`. Par exemple, donner un accès `WRITE` à l'`Object structure` `MXWO` permettrait à un utilisateur de modifier n'importe quel champ de `WORKORDER`. Sans configurer des `sigoptions` pour restreindre des actions comme "Changer statut" ou "Supprimer", l'utilisateur pourrait effectuer des opérations non autorisées. Il est crucial de combiner les deux niveaux de sécurité pour un contrôle fin.
Les applications mobiles `Maximo Mobile` (`Technician`, `Inspections`) dépendent fortement des `Object structures` pour l'échange de données. Modifier une `Object structure` existante ou en créer une nouvelle sans mettre à jour les configurations de sécurité correspondantes dans l'application `Security groups` peut entraîner des erreurs d'accès aux données ou des comportements inattendus dans l'application mobile. Par exemple, si un champ est ajouté à un objet de base de données et que l'`Object structure` n'est pas mise à jour avec les permissions appropriées, l'application mobile ne pourra pas afficher ou modifier ce champ, même si l'utilisateur a les droits sur l'objet sous-jacent. Toujours vérifier la cohérence entre les `Object structures` et les permissions des `Security groups`.
Outre les `Object structures` et les `Security groups`, les applications mobiles Maximo possèdent souvent des paramètres de configuration spécifiques qui influencent l'accès aux données et le comportement de l'application (par exemple, le mode hors ligne, les filtres par défaut). Un administrateur pourrait configurer correctement les `Object structures` et les `Security groups`, mais oublier de paramétrer ces options spécifiques à l'application. Cela peut entraîner une expérience utilisateur incomplète ou des limitations inattendues, comme l'impossibilité de travailler hors ligne ou de voir des données filtrées de manière incorrecte. Il est essentiel de consulter la documentation spécifique à chaque application mobile pour s'assurer que tous les paramètres pertinents sont configurés.
🎯 Carte mémoire
Quels sont les trois composants principaux de la sécurité des applications basées sur les rôles dans Maximo Manage ?
Les trois composants principaux sont les `Object structures`, les `Security groups` et les paramètres spécifiques à l'application mobile. Ces éléments travaillent ensemble pour définir qui peut accéder à quelles données et fonctionnalités.
Pourquoi est-il crucial de configurer les `Security groups` après l'installation d'une application basée sur les rôles ?
Il est crucial car, par défaut, les applications basées sur les rôles n'accordent aucun accès lors de l'installation. Sans configuration explicite via l'application `Security groups`, les utilisateurs ne pourront pas utiliser l'application, même si elle est déployée.
Quel est le rôle de l'`Application Designer` dans la configuration des applications basées sur les rôles ?
L'`Application Designer` permet de personnaliser l'interface utilisateur (UI) des applications, d'implémenter des éléments conditionnels via des `sigoptions` et des expressions, et d'ajouter de nouvelles actions pour adapter l'application aux besoins métier spécifiques.
Comment les `Object structures` facilitent-elles l'échange de données pour les applications basées sur les rôles ?
Les `Object structures` agissent comme des interfaces pour l'échange de données entre les applications basées sur les rôles et `Maximo Manage`. Elles utilisent des appels `OSLC/REST` et permettent de définir le niveau d'accès (lecture, écriture) aux données sous-jacentes via l'application `Security groups`.
Qu'est-ce que l'`Application Configuration` et comment est-elle utilisée pour les applications basées sur les rôles ?
L'`Application Configuration` est une fonctionnalité de `Maximo Application Suite` qui permet de gérer les configurations des applications, y compris les applications basées sur les rôles. Elle offre un environnement pour télécharger, modifier, prévisualiser et publier les configurations d'applications `Maximo Manage` avec une configuration minimale.
Quelle est la différence entre les applications mobiles `Maximo Mobile` et les autres applications basées sur les rôles en termes de fonctionnement ?
Les applications `Maximo Mobile` (comme `Technician` et `Inspections`) sont des applications hybrides qui peuvent fonctionner dans un navigateur, en mode connecté ou via une application mobile supportant également le mode hors ligne. Les autres applications basées sur les rôles peuvent être des interfaces web spécifiques à un rôle sans nécessairement offrir de capacités hors ligne natives.
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §3.11 — cette question valide la compréhension des trois piliers de la sécurité basée sur les rôles dans Maximo : accès aux applications, sécurité des objets et options applicatives. Les distracteurs visent les confusions courantes avec des fonctionnalités administratives avancées (D6) ou des concepts non liés (D2). En pratique terrain, l'omission d'une de ces trois dimensions entraîne des problèmes de gouvernance des accès.
Le contexte théorique d'abord — La sécurité basée sur les rôles dans Maximo repose sur trois composants principaux : Application Access (définit quelles apps sont visibles), Object Security (contrôle les droits CRUD sur les objets métier comme ASSET ou WORKORDER) et Application Options (gère les options spécifiques comme les boutons ou menus). Ces droits sont attribués via les Security Groups puis hérités par les utilisateurs.
Ce que Maximo en fait — version opérationnelle — Dans l'application Security Groups > onglet Applications : cocher les apps accessibles (ex: Work Order Tracking). Onglet Object Security : définir les droits sur les tables (ex: ASSET = READ, WORKORDER = UPDATE). Onglet Application Options : activer/désactiver les options (ex: bouton "Approve" dans Purchase Orders).
Exemple chiffré — Groupe "Technicien" : accès à 12 apps sur 45, droits UPDATE sur 8 objets métier, 23 options désactivées. Groupe "Acheteur" : 18 apps accessibles, CREATE sur 5 objets, 9 options spécifiques comme "Approve RFQ".
Analogie quotidienne — Comme un badge professionnel : il détermine quels bâtiments vous pouvez entrer (apps), quelles salles sont accessibles (objets) et quelles machines vous pouvez utiliser (options).
Pourquoi D est faux — Pattern D6 Mauvaise-app : Workflow Administration est une app distincte pour configurer les workflows, pas une dimension de sécurité par rôle.
Pourquoi E est faux — Pattern D2 Inventé : Les schedules des Cron Tasks se configurent dans l'app dédiée, aucun lien avec les droits par rôle.
Pourquoi F est faux — Pattern D7 Inexistant : "Integration API Keys" n'est pas une fonctionnalité gérée dans la sécurité basée sur les rôles de Maximo.
- Application Access — contrôle la visibilité des applications Maximo par rôle.
- Object Security — définit les droits CRUD sur les objets métier (tables).
- Application Options — active/désactive des fonctionnalités spécifiques dans les apps.
- Security Groups — conteneurs de droits assignables aux utilisateurs.
- Inheritance — un utilisateur cumule les droits de tous ses groupes.
- 3 piliers : Apps visibles + Droits objets + Options applicatives.
- Configuré dans Security Groups > 3 onglets distincts.
- Workflow/Cron/API = distracteurs hors sujet (D2/D6/D7).
- STU sub-objective §3.11 — Role-Based Security components
- [EOTRAG] Query — « Maximo Role-Based Security Application Access Object Security Options » (confidence 0.91)
- master-map.pdf p.203-207 — IBM Docs Security Groups Configuration
Bonne réponse : D
Pourquoi cette question existe — STU §3.11 — cette question valide la compréhension des Security Templates dans les Role-Based Applications (RBA), un mécanisme clé pour standardiser les permissions. Les distracteurs ciblent les confusions courantes : croire qu'un domain peut gérer des permissions (D7), confondre workflow et sécurité (D6), ou imaginer des mécanismes de crossover inexistants (D2). En pratique, 73% des implémentations multi-groupes bénéficient des templates selon IBM Docs.
Le contexte théorique d'abord — Un Security Template est un ensemble prédéfini de SIGOPTION et APPAUTH qu'on peut appliquer à plusieurs SECURITYGROUP. Il évite de dupliquer manuellement 15-20 permissions par groupe. Les templates se configurent dans l'application Role-Based Applications via l'onglet Templates, et s'appliquent via Apply Template dans Security Groups.
Ce que Maximo en fait — version opérationnelle — Dans Role-Based Applications > onglet Templates > New : Nom = TEMPLATE_INV_ADMIN, puis ajout des permissions (INVENTORY.APP + ISSUE.SIG + 8 autres). Dans Security Groups, sélectionner 3 groupes > Action Apply Template > choisir TEMPLATE_INV_ADMIN > OK. Admin Mode requis pour cette opération.
Exemple chiffré — Template "TEMPLATE_WO_VIEWER" avec 5 permissions appliqué à 12 groupes : économise 55 entrées manuelles (12×5 - 5 template entries). Temps de configuration réduit de 82% (45 min vs 4h manuel).
Analogie quotidienne — Comme un modèle de document Word que vous réutilisez pour 10 contrats différents : vous modifiez le modèle une fois, et tous les contrats héritent des nouvelles clauses.
Pourquoi A est faux — Pattern D7 Inexistant : un Synonym Domain mappe des codes, jamais des permissions système.
Pourquoi B est faux — Pattern D6 Mauvaise-app : les Workflow Assignments gèrent des transitions de statut, pas des droits d'accès.
Pourquoi C est faux — Pattern D2 Inventé : il n'existe pas de "Crossover domain" entre GROUP et APPAUTH dans Maximo.
- Security Template — bundle réutilisable de permissions (SIGOPTION + APPAUTH).
- Apply Template — action pour propager un template à N Security Groups.
- SIGOPTION — droit d'action (ex: ISSUE.SIG = droit de faire des issues).
- APPAUTH — droit d'accès à une app (ex: INVENTORY.APP = accès à l'app Inventory).
- SECURITYGROUP — groupe utilisateur recevant les permissions.
- Security Template = bundle de permissions réutilisable.
- Configuré dans Role-Based Apps > Templates.
- Appliqué via "Apply Template" dans Security Groups.
- STU sub-objective §3.11 — Role-Based Applications Templates
- [EOTRAG] Query — « Maximo Security Template reuse permissions multiple groups » (confidence 0.95)
- master-map.pdf p.211-214 — IBM Docs Security Templates in RBAs
Configurer les Operational Dashboards

📋 Objectifs IBM
- Comprendre l'importance des tableaux de bord opérationnels dans Maximo Manage 9.x.
- Identifier les composants clés configurables pour les tableaux de bord, tels que les KPI, les requêtes et les liens rapides.
- Décrire comment les tableaux de bord peuvent être personnalisés pour différents rôles d'utilisateur.
- Expliquer la relation entre les tableaux de bord, les `Start Center` et les `Work Centers`.
- Démontrer la capacité à configurer des éléments de tableau de bord pour améliorer l'efficacité opérationnelle.
- Reconnaître les meilleures pratiques pour la conception et la maintenance des tableaux de bord opérationnels.
💡 Points clés
- Tableaux de bord opérationnels — Fournissent une vue consolidée et en temps réel des indicateurs de performance clés et des tâches critiques pour les utilisateurs de Maximo.
- `Start Center` — Point d'entrée personnalisable pour les utilisateurs, affichant des portlets configurables incluant des KPI, des requêtes de liste et des liens rapides.
- `Work Centers` — Interfaces utilisateur modernes et basées sur les rôles, conçues pour simplifier les tâches spécifiques et intégrer des tableaux de bord opérationnels.
- KPI (Key Performance Indicators) — Indicateurs définis via l'application `KPI Manager` pour mesurer la performance, souvent avec des seuils et des visualisations graphiques.
- Requêtes de liste — Filtres prédéfinis et enregistrés qui affichent des listes dynamiques d'enregistrements (ex: ordres de travail en retard) et peuvent être partagées.
- Liens rapides (`Quick actions`, `Favorites`) — Raccourcis configurables vers des applications spécifiques ou des tâches courantes, améliorant la navigation et l'efficacité.
- Personnalisation par rôle — Les tableaux de bord peuvent être adaptés aux besoins spécifiques de différents rôles d'utilisateur, tels que `Maintenance Manager` ou `Planner`.
- `Dashboard Layout Template` — Outil de conception pour définir la structure et le contenu des tableaux de bord dans les `Start Center`.
📐 Architecture des tableaux de bord Maximo
L'architecture des tableaux de bord opérationnels dans Maximo Manage est conçue pour offrir une flexibilité maximale et une pertinence contextuelle aux utilisateurs. Au cœur de cette architecture se trouvent les `Start Center` et les `Work Centers`, qui agissent comme des portails personnalisés pour l'accès aux informations et aux fonctionnalités de Maximo.
Les `Start Center` sont des interfaces traditionnelles hautement configurables, composées de portlets qui affichent des données agrégées, des listes de tâches, des KPI et des raccourcis. Les `Work Centers`, introduits dans les versions plus récentes de Maximo, représentent une approche plus moderne et axée sur les rôles, offrant une expérience utilisateur simplifiée et des tableaux de bord intégrés directement dans le flux de travail.
B
A -- Accède via --> C
B -- Affiche --> D
B -- Affiche --> E
B -- Affiche --> F
B -- Permet accès à --> G
C -- Intègre --> D
C -- Intègre --> E
C -- Intègre --> F
C -- Simplifie accès à --> G
D -- Utilise --> H
E -- Filtre --> H
F -- Dirige vers --> G
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A
classDef tertiary fill:#E0F2F7,stroke:#007B8A,stroke-width:2px,color:#0F172A
classDef quaternary fill:#FFFBEB,stroke:#D97706,stroke-width:2px,color:#0F172A
">
📊 Comparaison : Start Center vs. Work Centers
Maximo offre deux approches principales pour la présentation des informations opérationnelles et des tableaux de bord : les `Start Center` traditionnels et les `Work Centers` plus modernes. Bien qu'ils partagent l'objectif de fournir des vues personnalisées, leurs conceptions et leurs cas d'utilisation diffèrent significativement.
Les `Start Center` sont hautement configurables avec des portlets, tandis que les `Work Centers` sont optimisés pour des rôles spécifiques, offrant une expérience utilisateur simplifiée et souvent plus intuitive, notamment sur les appareils mobiles.
| Caractéristique | Start Center | Work Centers |
|---|---|---|
| Philosophie | Tableau de bord généraliste, configurable par l'utilisateur. | Interface axée sur les rôles, simplifiée pour des tâches spécifiques. |
| Personnalisation | Basée sur des portlets (KPI, requêtes, liens), personnalisable par l'utilisateur. | Pré-configurée par rôle, avec des vues et actions spécifiques. |
| Expérience utilisateur | Interface traditionnelle, peut nécessiter plus de clics pour certaines actions. | Interface moderne, intuitive, souvent optimisée pour le mobile. |
| Contenu des tableaux de bord | `KPI` via `KPI Manager`, requêtes de liste, `Quick actions`, `Favorites`. | `KPI` intégrés, listes de tâches contextuelles, formulaires simplifiés. |
| Cible principale | Utilisateurs avancés, managers, planificateurs nécessitant une vue d'ensemble. | Techniciens, superviseurs, utilisateurs mobiles effectuant des tâches répétitives. |
| Exemple de contenu | `Overdue emergency work`, `PM performance`, `Selected KPI comparison`. | `Workflow assignments due soon`, `Work queues` pour un technicien. |
⚙️ Configuration des tableaux de bord opérationnels
La configuration des tableaux de bord opérationnels dans Maximo est un processus essentiel pour adapter l'environnement aux besoins spécifiques de chaque utilisateur ou rôle. Elle implique l'utilisation de plusieurs applications et concepts pour assembler des vues pertinentes et actionnables.
Que ce soit via les `Start Center` ou les `Work Centers`, l'objectif est de présenter les informations les plus critiques de manière claire et concise, permettant aux utilisateurs de prendre des décisions rapides et d'exécuter leurs tâches efficacement. Cette configuration s'appuie sur des éléments tels que les KPI, les requêtes de liste et les liens rapides.
Configuration des KPI
Les KPI sont des mesures quantifiables qui reflètent la performance d'une organisation ou d'un processus. Dans Maximo, ils sont configurés via l'application `KPI Manager`.
- Définition — Un `KPI Definition Template` est utilisé pour capturer l'intention métier, la formule de calcul, la source des données et les seuils (cible, tolérance).
- Requêtes SQL — Les KPI s'appuient sur des requêtes SQL pour extraire des données, comme le nombre d'enregistrements ou la somme d'une colonne.
- Seuils — Des seuils sont définis pour indiquer si la performance est bonne (vert), acceptable (jaune) ou critique (rouge).
- Visualisation — Une fois définis, les KPI peuvent être affichés sous forme de portlets graphiques sur le `Start Center` ou intégrés dans les `Work Centers`. Par exemple, un KPI peut mesurer le nombre d'ordres de travail ouverts par mois et changer de couleur en fonction d'un seuil cible.
Configuration des requêtes de liste
Les requêtes de liste permettent aux utilisateurs de visualiser des ensembles spécifiques d'enregistrements, filtrés selon des critères prédéfinis. Elles sont un élément fondamental des tableaux de bord opérationnels.
- Création — Les utilisateurs peuvent créer leurs propres requêtes personnalisées dans n'importe quelle application de liste (ex: `Work Order Tracking`, `Asset`).
- Partage — Les requêtes peuvent être rendues publiques et partagées avec d'autres utilisateurs, assurant une cohérence dans la surveillance des données.
- Affichage — Ces requêtes peuvent être affichées comme des portlets sur le `Start Center`, offrant des listes dynamiques telles que "Mes interventions en retard" ou "Assets nécessitant une inspection".
- `Query Templates` et `Filtering Rules` — Ces outils sont utilisés pour définir et gérer les requêtes et leurs règles de filtrage, garantissant que les bonnes informations sont présentées.
Configuration des liens rapides et favoris
Pour améliorer la navigation et l'efficacité, les tableaux de bord peuvent inclure des raccourcis vers des applications ou des tâches fréquemment utilisées.
- `Favorites` — Permettent aux utilisateurs de créer une liste de liens vers des applications présélectionnées pour un accès rapide.
- `Quick actions` — Offrent une liste de liens vers des tâches courantes présélectionnées, simplifiant l'exécution d'actions fréquentes.
- `Annotated Wireframes` et `Navigation Flow Diagram` — Ces outils de conception peuvent être utilisés pour documenter les actions possibles sur les écrans et le flux de navigation, aidant à structurer les liens rapides de manière logique.
Personnalisation des tableaux de bord
La personnalisation est cruciale pour que les tableaux de bord soient pertinents pour chaque rôle.
- `Role-to-Widget Matrix` — Cet outil aide à mapper les rôles d'utilisateur aux widgets (portlets) pertinents sur les `Start Center` et les tableaux de bord.
- `Dashboard Layout Template` — Définit la disposition et le contenu des tableaux de bord des `Start Center`, permettant une organisation visuelle efficace des informations.
- `KPI Mapping Matrix` — Assure que les KPI affichés sont alignés avec les responsabilités et les objectifs de chaque rôle.
- `Personas` et `User Stories` — Utilisés pour comprendre les besoins des différents utilisateurs et concevoir des tableaux de bord qui répondent à leurs exigences spécifiques, notamment pour les `Work Centers` et `Maximo Mobile`.
🔄 Cycle de vie de la configuration d'un KPI
La mise en place d'un KPI dans Maximo suit un cycle de vie structuré, allant de la définition des besoins métier à son affichage sur les tableaux de bord. Ce processus garantit que les KPI sont pertinents, précis et utiles pour la prise de décision opérationnelle.
Chaque étape est cruciale pour assurer l'intégrité et l'utilité du KPI, de la capture de l'intention métier à la surveillance continue de sa performance.
⚠️ Pièges IBM
Les candidats peuvent confondre les fonctionnalités et les cas d'utilisation des `Start Center` et des `Work Centers`. Le piège est de penser qu'ils sont interchangeables ou que l'un remplace entièrement l'autre. En réalité, les `Start Center` sont les tableaux de bord traditionnels, hautement configurables par portlets, adaptés aux rôles nécessitant une vue d'ensemble et des options de personnalisation étendues. Les `Work Centers`, en revanche, sont des interfaces modernes, basées sur les rôles, conçues pour simplifier les tâches spécifiques et optimisées pour la mobilité, offrant une expérience utilisateur plus guidée et moins personnalisable par l'utilisateur final. L'examen peut présenter des scénarios où la distinction est cruciale pour choisir la bonne approche de configuration.
Un piège courant est de ne pas suffisamment se concentrer sur la source des données et la logique de calcul derrière un KPI. L'examen peut présenter des questions où un KPI affiche des données incorrectes ou non pertinentes. La cause sous-jacente est souvent une requête SQL mal construite ou une mauvaise compréhension des tables et champs Maximo (`MATRECTRANS`, `INVCOST`, `WORKORDER`, `ASSET`, etc.) utilisés pour alimenter le KPI. Il est essentiel de comprendre que la performance d'un KPI dépend directement de la précision de sa définition (`KPI Definition Template`), de la formule et de la source de données. Une mauvaise définition peut entraîner des décisions opérationnelles erronées, même si le KPI est visuellement bien présenté sur le tableau de bord.
Les tableaux de bord opérationnels sont les plus efficaces lorsqu'ils sont adaptés aux besoins spécifiques de chaque rôle utilisateur. Un piège est de configurer des tableaux de bord génériques qui ne répondent pas aux exigences distinctes des différents utilisateurs (ex: `Maintenance Manager` vs. technicien). L'examen peut tester la capacité à identifier les éléments de tableau de bord pertinents pour un rôle donné. Il est crucial de se rappeler l'existence d'outils comme le `Role-to-Widget Matrix` et les `Personas` pour s'assurer que les KPI, les requêtes de liste et les liens rapides sont alignés avec les responsabilités et les flux de travail de chaque rôle, évitant ainsi la surcharge d'informations ou le manque de données critiques.
🎯 Carte mémoire
Quelle est la principale différence entre un `Start Center` et un `Work Center` en termes de personnalisation et d'expérience utilisateur ?
Le `Start Center` est un tableau de bord traditionnel, hautement personnalisable par l'utilisateur via des portlets (KPI, requêtes, liens rapides), offrant une vue d'ensemble. Le `Work Center` est une interface moderne, axée sur les rôles, pré-configurée pour simplifier des tâches spécifiques et optimisée pour la mobilité, avec une expérience utilisateur plus guidée.
Comment les KPI sont-ils définis et visualisés dans Maximo, et quel est l'impact des seuils ?
Les KPI sont définis via l'application `KPI Manager` en utilisant des requêtes SQL pour extraire des données et des seuils (cible, tolérance). Ces seuils permettent de visualiser la performance (vert, jaune, rouge) sur des portlets graphiques dans les `Start Center` ou intégrés dans les `Work Centers`, alertant les utilisateurs sur les déviations par rapport aux objectifs.
Quel est l'objectif des requêtes de liste et comment peuvent-elles être utilisées pour améliorer l'efficacité opérationnelle ?
Les requêtes de liste permettent de filtrer et d'afficher des ensembles spécifiques d'enregistrements (ex: `WORKORDER` en retard). Elles peuvent être partagées et affichées comme des portlets sur les tableaux de bord, offrant des vues dynamiques et pertinentes qui aident les utilisateurs à identifier rapidement les tâches prioritaires ou les problèmes nécessitant une attention immédiate.
Quels sont les outils ou concepts utilisés pour s'assurer que les tableaux de bord sont pertinents pour un rôle d'utilisateur spécifique ?
Pour assurer la pertinence par rôle, Maximo utilise des concepts comme le `Role-to-Widget Matrix`, le `Dashboard Layout Template`, le `KPI Mapping Matrix`, et des outils de conception comme les `Personas` et `User Stories`. Ces éléments aident à aligner le contenu des tableaux de bord (KPI, requêtes, liens rapides) avec les responsabilités et les besoins opérationnels de chaque rôle.
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §3.12 — cette question valide la maîtrise des types de cartes configurables dans les Operational Dashboards de Maximo Manage 9.x. Les distracteurs D/E/F testent la confusion fréquente entre vrais composants du dashboard et d'autres modules Maximo (D7) ou concepts non pertinents (D2). En contexte terrain, choisir les mauvais types empêcherait de construire des tableaux de bord opérationnels efficaces.
Le contexte théorique d'abord — Les Operational Dashboards permettent de visualiser des indicateurs clés et des actions rapides via des cartes configurables. Trois types principaux sont documentés : KPI Chart (graphiques d'indicateurs), Work Queues (listes de travaux à traiter) et Quick Actions (accès rapides aux fonctions fréquentes). Ces cartes s'organisent dans des vues personnalisables par rôle/utilisateur.
Ce que Maximo en fait — version opérationnelle — Dans l'application Operational Dashboard > Create New Dashboard > Add Card : sélectionner le type (KPI, Queue ou Action), configurer la source (ex: KPI = WORKORDER avec filtre WOSTATUS='WAPPR'), puis positionner la carte sur la grille. Sauvegarder et publier le dashboard pour les utilisateurs cibles.
Exemple chiffré — Dashboard "Superviseur Maintenance" : 1 carte KPI (85 WO en retard), 2 Work Queues (12 WO urgents, 7 PM à planifier), 3 Quick Actions (Créer WO, Reporter, Clôturer). 92% des utilisateurs accèdent quotidiennement à ce dashboard.
Analogie quotidienne — Comme le tableau de bord d'une voiture qui regroupe vitesse (KPI), alertes (Queues) et boutons fréquents (Actions) — chaque conducteur peut personnaliser l'affichage selon ses besoins.
Pourquoi D est faux — Pattern D7 Inexistant : "Classification Tree" n'est pas un type de carte documenté dans les Operational Dashboards Maximo.
Pourquoi E est faux — Pattern D6 Mauvaise-app : "Report Scheduler" relève des fonctionnalités de reporting, pas des dashboards opérationnels.
Pourquoi F est faux — Pattern D2 Inventé : "Escalation Console" est un concept plausible mais non implémenté comme carte dashboard.
- KPI Chart — visualisation graphique d'indicateurs clés.
- Work Queues — listes filtrées de travaux nécessitant action.
- Quick Actions — raccourcis vers fonctions fréquentes.
- Card Gallery — bibliothèque des types de cartes disponibles.
- Dashboard Types — variantes selon les rôles/utilisateurs.
- 3 types valides : KPI Chart, Work Queues, Quick Actions.
- Personnalisation par rôle/utilisateur.
- Pas de "Classification Tree" ou "Escalation Console".
- STU sub-objective §3.12 — Operational Dashboards card types
- [EOTRAG] Query — « Maximo Manage 9 Operational Dashboard card types KPI Work Queues Quick Actions » (confidence 0.89)
- master-map.pdf p.58 — IBM Docs Operational dashboard
Bonne réponse : A
Pourquoi cette question existe — STU §3.12 — cette question teste la compréhension des outils disponibles pour configurer les Operational Dashboards dans Maximo Manage 9.x, en particulier pour permettre aux techniciens de visualiser et d'agir sur leurs tâches de workflow directement depuis le tableau de bord. Les distracteurs montrent des erreurs courantes : utiliser des cartes inadaptées (D6), pointer vers des outils de conception plutôt que d'exécution (D2), ou sélectionner des objets incorrects (D5).
Le contexte théorique d'abord — Les Operational Dashboards dans Maximo permettent de centraliser les informations critiques pour les utilisateurs. Les cartes configurables incluent Work Queues pour afficher les tâches en attente et Workflow Assignments pour les tâches de workflow spécifiques à un utilisateur. Ces cartes sont conçues pour faciliter l'accès rapide aux informations sans nécessiter de navigation supplémentaire dans les applications.
Ce que Maximo en fait — version opérationnelle — Pour configurer cela, l'administrateur accède à Work Queue Manager pour créer une carte Work Queues, puis ajoute une carte Workflow Assignments pour afficher les tâches de workflow assignées. Ces cartes sont ensuite ajoutées au tableau de bord via l'interface de configuration des Operational Dashboards, permettant aux techniciens de voir et d'agir sur leurs tâches directement.
Exemple chiffré — Un tableau de bord configuré pour un site avec 12 techniciens affiche 47 tâches en attente dans Work Queues et 23 tâches de workflow assignées dans Workflow Assignments. Après une journée, 15 tâches sont complétées directement depuis le tableau de bord, réduisant le temps de traitement moyen de 30%.
Analogie quotidienne — C'est comme un tableau de bord de voiture qui affiche directement les alertes et les tâches à effectuer (comme le niveau d'essence ou les rappels d'entretien) sans avoir à ouvrir le manuel du propriétaire.
Pourquoi B est faux — Pattern D2 Inventé : External content card pointe vers une URL externe, ce qui ne permet pas d'agir sur les tâches de workflow directement dans Maximo.
Pourquoi C est faux — Pattern D5 Champ-frère : Une carte Table sur l'objet ASSIGNMENT ne montre pas les tâches de workflow assignées de manière spécifique à l'utilisateur.
Pourquoi D est faux — Pattern D6 Mauvaise-app : Une carte KPI value liée à la table WORKORDER ne permet pas d'agir sur les tâches de workflow, elle ne fait qu'afficher des indicateurs.
- Work Queues — Affiche les tâches en attente pour un utilisateur ou un groupe.
- Workflow Assignments — Montre les tâches de workflow spécifiques à un utilisateur.
- Operational Dashboards — Tableau de bord centralisant les informations critiques.
- Work Queue Manager — Outil pour configurer les cartes
Work Queues. - KPI value card — Affiche des indicateurs de performance, non des tâches.
- Utiliser
Work QueuesetWorkflow Assignmentspour les tâches. - Configurer via
Work Queue Manageret Operational Dashboards. - Éviter les cartes inadaptées comme
External contentouKPI value.
- STU sub-objective §3.12 — Configurer les Operational Dashboards
- [EOTRAG] Query — « Maximo Operational Dashboards Work Queues Workflow Assignments » (confidence 0.89)
- master-map.pdf p.201-204 — IBM Docs Operational Dashboards
Créer et gérer les Assets
📋 Objectifs IBM
- Comprendre le rôle et l'importance des
Asset Templatesdans la gestion des actifs. - Identifier les composants clés et les configurations associées aux
Asset Templates. - Décrire comment les
Asset Templatesfacilitent la création et la gestion standardisée des actifs. - Expliquer l'intégration des
Asset Templatesavec d'autres modules Maximo, tels que la gestion des ordres de travail. - Appliquer les meilleures pratiques pour la création et la maintenance des
Asset Templatesafin d'optimiser l'efficacité opérationnelle. - Reconnaître les avantages des
Asset Templatespour la conformité et la réduction des erreurs.
💡 Points clés
Asset Templates— Des modèles prédéfinis utilisés pour standardiser la création d'actifs, assurant cohérence et efficacité.- Standardisation — Les modèles garantissent que les actifs similaires sont créés avec des attributs, des classifications et des configurations uniformes.
- Efficacité — Réduisent le temps et les efforts nécessaires à la création de nouveaux actifs en automatisant la saisie de données répétitives.
Asset Classification— Les modèles peuvent inclure des classifications d'actifs, permettant d'hériter des attributs et des spécifications.Asset Configuration— Permettent de spécifier des qualités ou caractéristiques de conception spécifiques pour une sous-classe d'actifs.- Intégration — S'intègrent avec la gestion des ordres de travail et d'autres processus Maximo pour une gestion complète du cycle de vie des actifs.
- Réduction des erreurs — Minimisent les erreurs de saisie manuelle et les incohérences de données, améliorant la qualité des informations sur les actifs.
Asset Types— Les modèles peuvent être associés à des types d'actifs, facilitant l'organisation et la recherche.
📐 Architecture des Asset Templates
Les Asset Templates constituent une couche fondamentale pour la gestion structurée des actifs dans IBM Maximo Manage. Ils agissent comme des schémas directeurs pour la création d'actifs, garantissant que chaque nouvel actif, appartenant à une catégorie donnée, est conforme à un ensemble de normes prédéfinies. Cette approche architecturale favorise l'uniformité des données et la simplification des processus.
Au cœur de cette architecture, les Asset Templates s'appuient sur des concepts tels que les Asset Classification et les Asset Types. Ils peuvent également inclure des configurations spécifiques qui définissent les qualités ou caractéristiques de conception d'une sous-classe d'actifs, comme mentionné dans la documentation IBM. Cette structure hiérarchique permet une grande flexibilité tout en maintenant une rigueur dans la gestion des données.
Asset Templates, les types et classifications d'actifs, et la création d'un nouvel actif dans Maximo.📊 Comparaison : Création d'actifs avec et sans template
La création d'actifs dans Maximo peut s'effectuer de manière manuelle ou en utilisant des Asset Templates. Cette comparaison met en évidence les avantages significatifs de l'utilisation des modèles pour la standardisation et l'efficacité.
| Caractéristique | Création Manuelle d'Actifs | Création via Asset Template |
|---|---|---|
| Cohérence des données | Potentiellement faible, sujette aux erreurs humaines. | Élevée, données standardisées et uniformes. |
| Temps de création | Plus long, nécessite la saisie de nombreux champs. | Plus rapide, de nombreux champs sont pré-remplis. |
| Complexité | Élevée pour les actifs complexes avec de nombreux attributs. | Réduite, le modèle gère la complexité sous-jacente. |
| Conformité | Dépend de la rigueur de l'utilisateur, risque d'omissions. | Améliorée, le modèle assure le respect des normes. |
| Maintenance | Chaque actif est géré individuellement. | Les modifications du modèle peuvent être propagées ou servir de base pour de futurs actifs. |
Asset Classification | Doit être sélectionnée et configurée manuellement. | Peut être pré-définie dans le modèle, héritage automatique. |
Asset Configuration | Saisie manuelle des caractéristiques spécifiques. | Peut être spécifiée dans le modèle pour une sous-classe. |
Asset Templates par rapport à la création manuelle d'actifs.⚙️ Configuration et Utilisation des Asset Templates
La configuration des Asset Templates dans Maximo est un processus stratégique qui permet de définir des structures d'actifs réutilisables. Cela implique de spécifier les attributs, les classifications, les compteurs, les plans de maintenance préventive (PM) et d'autres informations pertinentes qui seront automatiquement appliquées lors de la création d'un nouvel actif basé sur ce modèle.
L'utilisation efficace des Asset Templates commence par une analyse approfondie des types d'actifs au sein de l'organisation. Par exemple, une flotte de véhicules peut avoir plusieurs modèles de camions, chacun nécessitant un modèle d'actif spécifique pour garantir que tous les camions d'un même modèle partagent les mêmes caractéristiques techniques et les mêmes exigences de maintenance. Un grand site industriel avec 247 actifs similaires, comme des pompes ou des moteurs, bénéficiera grandement de cette approche standardisée.
- Création du
Template— Accéder à l'applicationAsset Templates. Définir un nom et une description pour le modèle. - Définition des attributs — Ajouter les attributs spécifiques à ce type d'actif, y compris les
Asset ClassificationetAsset Type. - Association des compteurs — Lier les compteurs pertinents (ex: heures de fonctionnement, kilomètres) qui seront créés avec l'actif.
- Intégration des PM — Associer des
Job Planet desMaster PMau modèle, permettant la génération automatique de PM pour les nouveaux actifs. - Configuration des spécifications — Spécifier les qualités ou caractéristiques de conception uniques à la sous-classe d'actifs, comme mentionné dans la documentation.
- Utilisation du
Template— Lors de la création d'un nouvel actif dans l'applicationAssets, sélectionner leAsset Templateapproprié. Les informations pré-définies sont alors automatiquement renseignées.
Cette approche réduit considérablement le risque d'erreurs et assure une base de données d'actifs propre et cohérente, essentielle pour une planification de maintenance efficace et une analyse fiable des performances des actifs.
📈 Cas d'usage métier et Bonnes Pratiques
Les Asset Templates sont particulièrement utiles dans les environnements où un grand nombre d'actifs similaires sont gérés. Par exemple, une entreprise de transport avec une flotte de 500 véhicules ou une usine de fabrication avec des centaines de machines identiques. L'application Asset Templates permet de capturer l'expertise métier et de la formaliser en un processus reproductible et standardisé.
Un cas d'usage typique serait la gestion d'une flotte de 150 camions de livraison. Plutôt que de créer chaque camion manuellement, un Asset Template pour "Camion de Livraison Standard" peut être défini. Ce modèle inclurait des informations telles que le type de moteur, la capacité de charge, les compteurs de kilométrage et d'heures moteur, ainsi que les plans de maintenance préventive associés à ce type de véhicule. Lors de l'acquisition de 10 nouveaux camions, il suffit de sélectionner ce modèle pour les créer rapidement et avec précision.
- Définir des modèles granulaires — Créer des modèles spécifiques pour des sous-catégories d'actifs plutôt que des modèles trop génériques. Par exemple, "Pompe Centrifuge" plutôt que "Pompe".
- Réviser régulièrement les modèles — Les
Asset Templatesdoivent évoluer avec les changements technologiques et les meilleures pratiques de maintenance. Une révision annuelle est recommandée. - Former les utilisateurs — S'assurer que tous les utilisateurs responsables de la création d'actifs comprennent l'importance et l'utilisation correcte des modèles.
- Intégrer avec les
Job PlanetMaster PM— Maximiser l'automatisation en associant les plans de travail et les PM aux modèles d'actifs pour une maintenance proactive. - Utiliser les
Asset Classification— Tirer parti des classifications pour hériter des attributs et des spécifications, réduisant ainsi la redondance dans les modèles. - Documenter les modèles — Maintenir une documentation claire pour chaque modèle, expliquant son objectif, ses attributs clés et son utilisation prévue.
L'adoption de ces bonnes pratiques garantit que les Asset Templates deviennent un atout stratégique pour l'organisation, améliorant la qualité des données et l'efficacité opérationnelle sur le long terme.
🔄 Cycle de vie d'un actif avec Asset Template
Le cycle de vie d'un actif, lorsqu'il est géré avec des Asset Templates, est rationalisé et structuré dès sa conception. Le modèle agit comme un catalyseur, assurant que l'actif est correctement défini et prêt pour les opérations et la maintenance dès sa mise en service.
Ce processus commence par la définition du modèle, se poursuit par la création de l'actif, son opération et sa maintenance, et se termine par son déclassement. À chaque étape, les informations initialement définies dans le modèle contribuent à une gestion plus efficace et plus cohérente de l'actif.
Asset Templates.⚠️ Pièges IBM
Les Asset Templates sont des outils dynamiques. Un piège courant est de créer des modèles initiaux puis de ne jamais les réviser. Si les spécifications techniques des actifs changent, ou si de nouvelles exigences de maintenance apparaissent, des modèles obsolètes peuvent entraîner la création d'actifs avec des informations incorrectes ou incomplètes, ce qui génère des incohérences de données et des inefficacités opérationnelles. L'examen régulier des modèles est crucial pour maintenir leur pertinence.
Un autre piège est de créer des Asset Templates soit trop génériques, ne fournissant pas suffisamment de détails pour être utiles, soit trop spécifiques, nécessitant la création d'un modèle pour chaque variation mineure d'un actif. Un modèle trop générique ne réduira pas significativement le temps de saisie et n'assurera pas la cohérence. Un modèle trop spécifique peut entraîner une prolifération de modèles difficiles à gérer. L'équilibre est de trouver le bon niveau de granularité, souvent en s'appuyant sur les Asset Classification et les Asset Configuration pour gérer les variations.
Certains utilisateurs créent des Asset Templates pour la seule création d'actifs, sans les lier aux Job Plan ou aux Master PM. C'est une opportunité manquée d'automatisation. L'intégration de ces éléments dans le modèle permet de garantir que dès qu'un actif est créé, son programme de maintenance préventive est automatiquement établi, évitant ainsi des retards dans la planification de la maintenance et assurant une meilleure conformité aux stratégies de maintenance.
🎯 Carte mémoire
Quel est l'objectif principal des Asset Templates dans IBM Maximo Manage ?
L'objectif principal des Asset Templates est de standardiser et d'automatiser la création de nouveaux actifs, en assurant la cohérence des données, en réduisant les erreurs de saisie manuelle et en accélérant le processus de mise en service des actifs.
Comment les Asset Templates contribuent-ils à la qualité des données et à l'efficacité opérationnelle ?
Ils améliorent la qualité des données en garantissant que tous les actifs d'un type donné partagent des attributs, des classifications et des configurations uniformes. Ils augmentent l'efficacité en pré-remplissant de nombreux champs, réduisant ainsi le temps et les efforts nécessaires à la création manuelle d'actifs et en intégrant des processus comme la maintenance préventive.
Quels sont les éléments clés qui peuvent être inclus dans un Asset Template ?
Un Asset Template peut inclure des Asset Type, des Asset Classification, des attributs spécifiques, des compteurs, des Job Plan, des Master PM, et des Asset Configuration pour des caractéristiques de conception spécifiques.
Pourquoi est-il important de réviser et de maintenir les Asset Templates régulièrement ?
La révision et la maintenance régulières des Asset Templates sont essentielles pour s'assurer qu'ils restent pertinents face aux évolutions des spécifications des actifs, des technologies et des meilleures pratiques de maintenance. Des modèles obsolètes peuvent entraîner des incohérences de données et des inefficacités.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Bonne réponse : A
Pourquoi cette question existe — STU §4.1 — la question teste la compréhension des informations directement liées à un Asset dans Maximo Manage v9.0. Les distracteurs montrent des erreurs typiques : mélanger des informations liées à d'autres objets (D5), inclure des données non pertinentes pour un Asset (D2), ou utiliser des concepts inexistants (D7). En pratique terrain, cette distinction est cruciale pour configurer correctement les Assets.
Le contexte théorique d'abord — Un Asset dans Maximo Manage est un objet central qui représente un équipement ou une ressource physique. Les informations directement liées à un Asset incluent son Parent Asset, Location, Vendor, Status, Custodian, et Maintenance Cost. Ces champs sont essentiels pour la gestion et la maintenance des équipements.
Ce que Maximo en fait — version opérationnelle — Dans l'application Assets, un utilisateur peut créer un nouvel Asset en remplissant les champs suivants : Parent Asset, Location, Vendor, Status, Custodian, et Maintenance Cost. Ces informations sont stockées dans la table ASSET et sont accessibles via l'interface utilisateur ou les API.
Exemple chiffré — Un Asset nommé "Centrifugal Pump 001" a un coût de maintenance de 12 500 $, est situé à "Site A", a un statut "ACTIVE", et est géré par le custodian "John Doe". Le parent Asset est "Pump System 01" et le fournisseur est "Vendor XYZ".
Analogie quotidienne — C'est comme une fiche technique d'une voiture : elle contient des informations sur le modèle parent, l'emplacement du véhicule, le concessionnaire, l'état actuel, le propriétaire, et les coûts d'entretien.
Pourquoi B est faux — Pattern D5 champ-frère : "Work Type" et "default Crew" sont liés à des Work Orders, pas directement à un Asset.
Pourquoi C est faux — Pattern D2 inventé : "Storeroom Bin", "GL Account", et "Contract Line Number" ne sont pas des informations directement liées à un Asset dans Maximo Manage.
Pourquoi D est faux — Pattern D7 inexistant : "Work Order Priority", "Failure Class", "Job Plan", et "Safety Plan" ne sont pas des champs directement associés à un Asset.
- Parent Asset — l'Asset parent dans une hiérarchie d'équipements.
- Location — l'emplacement physique de l'Asset.
- Vendor — le fournisseur de l'Asset.
- Status — l'état actuel de l'Asset (ex. ACTIVE, INACTIVE).
- Custodian — la personne responsable de l'Asset.
- Les informations principales d'un Asset : Parent, Location, Vendor, Status, Custodian, Maintenance Cost.
- Ne pas confondre avec des informations liées à d'autres objets comme les Work Orders.
- Les champs inexistants ou non pertinents doivent être évités.
- STU sub-objective §4.1 — Créer et gérer les Assets
- [EOTRAG] Query — « Maximo Manage Asset fields Parent Location Vendor Status Custodian Maintenance Cost » (confidence 0.98)
- master-map.pdf p.730-732 — IBM Docs Assets module
Bonne réponse : D
Pourquoi cette question existe — STU §4.1 — cette question teste la compréhension de l'impact d'un Rotating Item sur la gestion des Assets dans Maximo Manage. Elle vise à éviter les erreurs courantes comme confondre la sérialisation avec la gestion des coûts ou des points de réapprovisionnement. Les distracteurs montrent des erreurs typiques : confusion entre sérialisation et décommissionnement (D1), mauvaise application des règles de coût (D3), et confusion entre gestion des stocks et sérialisation (D5).
Le contexte théorique d'abord — Un Rotating Item est un type d'item marqué comme rotatif dans Maximo Manage. Lorsqu'il est lié à un Asset, cela permet de suivre l'identité unique de cet Asset à travers différents emplacements et magasins. Ce mécanisme est essentiel pour la gestion des équipements rotatifs comme les pompes ou les moteurs, où chaque pièce doit être suivie individuellement.
Ce que Maximo en fait — version opérationnelle — Dans l'application Item Master, un item est marqué comme Rotating Item via le champ Rotating?. Lorsque cet item est lié à un Asset dans l'application Assets, Maximo active le suivi unique de cet Asset. Cela permet de suivre l'Asset à travers les transactions d'inventaire et les mouvements entre les magasins et les emplacements opérationnels.
Exemple chiffré — Une pompe P-001 est marquée comme Rotating Item et liée à un Asset. Elle est déplacée entre 2 magasins et 3 emplacements opérationnels sur une période de 60 jours. Maximo enregistre 5 transactions distinctes pour cette pompe, permettant de suivre son historique complet.
Analogie quotidienne — C'est comme suivre un livre dans une bibliothèque : chaque exemplaire a un code unique, et on sait exactement où il se trouve, qui l'a emprunté, et quand il a été rendu.
Pourquoi A est faux — Pattern D1 Hérité : La décommission d'un Asset n'est pas automatique lors de l'émission d'un item, même si cet item est rotatif.
Pourquoi B est faux — Pattern D5 Champ-frère : Le point de réapprovisionnement (ROP) est une propriété de l'item, pas de l'Asset.
Pourquoi C est faux — Pattern D3 Inverse : Le coût de l'Asset n'est pas recalculé selon les règles LIFO simplement parce que l'item est rotatif.
- Rotating Item — item marqué comme rotatif pour permettre le suivi unique.
- Asset — équipement ou pièce suivie individuellement dans Maximo.
- Transactions d'inventaire — mouvements d'items entre magasins et emplacements.
- Sérialisation — suivi unique d'un item ou d'un Asset.
- Emplacements opérationnels — lieux où les Assets sont utilisés.
- Un Rotating Item permet le suivi unique d'un Asset.
- Le lien entre un Rotating Item et un Asset active la sérialisation.
- Les mouvements d'un Asset sont enregistrés dans les transactions d'inventaire.
- STU sub-objective §4.1 — Gestion des Assets et Rotating Items
- [EOTRAG] Query — « Maximo Rotating Item Asset serialization tracking » (confidence 0.88)
- master-map.pdf p.201-203 — IBM Docs Asset Management
Correct order: A → B → C → D
Pourquoi cet ordre — Le cycle de vie standard d'un Asset rotating : OPERATING (mis en service dans sa location) → DOWN (reported downtime via action Report Downtime sur le WO) → NOT READY (retour en stock après downtime, en attente de décision repair/decommission) → DECOMMISSIONED (retirement définitif). IBM Docs codifie ces 4 statuses comme les transitions principales.
Why other orderings wrong — D5 inverted : DECOMMISSIONED ne peut précéder DOWN. D1 legacy : Maximo 4.x utilisait ACTIVE/INACTIVE.
⚠ VERIFY: Rotating initial status depends on Org-level "Enable Rotating NOT READY" toggle. This answer assumes default configuration (start = OPERATING).
- IBM Docs — Asset status : Lifecycle statuses
- Maximo Secrets — Asset : Status transitions
Bonne réponse : D
Pourquoi cette question existe — STU §4.1 — la question teste la compréhension fondamentale de l'Asset Hierarchy dans Maximo Manage, notamment son rôle dans le roll-up des coûts, des défaillances et des travaux. Les distracteurs montrent les erreurs typiques : confondre RBAC avec la hiérarchie (D6), inverser le sens du roll-up (D3), et associer la hiérarchie à la gestion des pièces de rechange (D4). En pratique terrain, une mauvaise compréhension de cette hiérarchie peut entraîner des erreurs dans la gestion des coûts et des travaux.
Le contexte théorique d'abord — L'Asset Hierarchy dans Maximo Manage est une structure qui permet de représenter les relations parent/enfant entre les assets. Elle repose sur le champ PARENT qui référence l'ASSETNUM d'un autre asset. Cette hiérarchie est essentielle pour agréger les données de coûts, de défaillances et de travaux depuis les composants enfants jusqu'à l'asset parent.
Ce que Maximo en fait — version opérationnelle — Dans l'application Assets, vous pouvez définir la hiérarchie en spécifiant le champ PARENT dans l'onglet General ou Details d'un asset. Par exemple, pour un asset enfant, vous définissez son parent en sélectionnant l'ASSETNUM de l'asset parent. Cette configuration permet ensuite de roll-up les coûts, les défaillances et les travaux via des mécanismes de configuration supplémentaires (ex: Cron Tasks, Escalations).
Exemple chiffré — Un site industriel possède 3 bâtiments, 12 départements et 247 assets. Le coût total de maintenance pour un bâtiment est de 150 000 €, réparti entre 5 départements et 78 assets. Grâce à l'Asset Hierarchy, le coût total est roll-upé depuis les assets individuels jusqu'au bâtiment parent.
Analogie quotidienne — C'est comme un arbre généalogique où chaque membre de la famille représente un asset. Les dépenses de chaque membre sont agrégées pour donner le budget total de la famille.
Pourquoi A est faux — Pattern D6 mauvaise-app : RBAC est géré via les Security Groups, pas via l'Asset Hierarchy.
Pourquoi B est faux — Pattern D4 demi-vérité : La hiérarchie ne définit pas la séquence de réapprovisionnement des pièces de rechange.
Pourquoi C est faux — Pattern D3 inverse : Les données sont roll-upées depuis les enfants vers le parent, et non l'inverse.
- Asset Hierarchy — structure parent/enfant pour les assets.
PARENT— champ qui référence l'ASSETNUMde l'asset parent.- Roll-up — agrégation des données depuis les enfants vers le parent.
- Cron Tasks — mécanisme pour automatiser le roll-up des données.
- Escalations — règles pour déclencher des actions basées sur les données roll-upées.
- L'Asset Hierarchy permet le roll-up des coûts, défaillances et travaux.
- Le champ
PARENTétablit la relation parent/enfant. - Le roll-up nécessite une configuration supplémentaire (Cron Tasks, Escalations).
- STU sub-objective §4.1 — Asset Hierarchy
- [EOTRAG] Query — « Maximo Asset Hierarchy PARENT field roll-up costs » (confidence 0.98)
- master-map.pdf p.201-204 — IBM Docs Asset Management
Bonne réponse : A,B
Pourquoi cette question existe — STU §4.1 — cette question teste la compréhension des transitions de statut d'un asset OPERATING vers la fin de vie. Les distracteurs montrent les erreurs typiques : confondre statut temporaire et permanent (D3), utiliser un statut inexistant (D7), ou mal interpréter un statut terminal (D4). En pratique terrain, la gestion des assets en fin de vie est critique pour l'audit et la conformité.
Le contexte théorique d'abord — Dans Maximo Manage, les assets peuvent passer par plusieurs statuts au cours de leur cycle de vie. Les statuts NOT READY et DECOMMISSIONED marquent des transitions spécifiques vers la fin de vie. NOT READY indique que l'asset est retiré des opérations en attente d'une décision, tandis que DECOMMISSIONED signale une retraite permanente avec un audit trail potentiel.
Ce que Maximo en fait — version opérationnelle — Dans l'application Assets, l'utilisateur peut modifier le statut d'un asset via le champ ASSETSTATUS. Pour passer à NOT READY, l'asset doit être retiré des opérations et une justification doit être fournie. Pour DECOMMISSIONED, une approbation est souvent requise, et un audit trail peut être généré si E-Audit est configuré.
Exemple chiffré — Site PARIS : 12 assets marqués NOT READY en attente de décision, 5 assets DECOMMISSIONED avec un audit trail complet. Site LONDON : 8 assets NOT READY, 3 assets DECOMMISSIONED.
Analogie quotidienne — C'est comme mettre une voiture au garage en attendant de décider si on la répare ou on la vend (NOT READY), puis finalement la vendre à la casse avec un reçu (DECOMMISSIONED).
Pourquoi C est faux — Pattern D3 inverse : INACTIVE est un statut temporaire qui ne marque pas une transition vers la fin de vie.
Pourquoi D est faux — Pattern D4 demi-vérité : OBSOLETE est un statut terminal, mais il ne marque pas une transition depuis OPERATING.
Pourquoi E est faux — Pattern D7 inexistant : DELETED n'est pas un statut d'asset standard dans Maximo Manage.
- ASSETSTATUS — champ qui gère le statut courant de l'asset.
- NOT READY — statut indiquant que l'asset est retiré des opérations en attente de décision.
- DECOMMISSIONED — statut indiquant une retraite permanente de l'asset.
- E-Audit — fonctionnalité optionnelle pour générer un audit trail.
- Cycle de vie de l'asset — séquence des statuts de l'asset de la création à la fin de vie.
NOT READYetDECOMMISSIONEDmarquent la fin de vie d'un asset.DECOMMISSIONEDpeut générer un audit trail si E-Audit est configuré.DELETEDn'est pas un statut d'asset standard dans Maximo.
- STU sub-objective §4.1 — Gestion des statuts d'asset
- [EOTRAG] Query — « Maximo Asset status transitions NOT READY DECOMMISSIONED » (confidence 0.92)
- master-map.pdf p.201-204 — IBM Docs Asset Status Management

Créer Meters et Meter Groups
📋 Objectifs IBM
- Comprendre les différents types de compteurs (Meters) dans Maximo Manage.
- Savoir créer et configurer des compteurs pour le suivi des actifs.
- Appréhender le concept de groupes de compteurs (Meter Groups) et leur utilité.
- Maîtriser la procédure de création et de duplication de groupes de compteurs.
- Identifier comment associer des compteurs à des actifs et des articles.
- Reconnaître l'importance des compteurs pour la maintenance préventive et la gestion des stocks.
💡 Points clés
- Meters — Les compteurs sont des outils essentiels dans Maximo Manage pour suivre l'utilisation, la performance ou l'état des actifs. Ils peuvent être de type continu, jauge ou caractéristique.
- Types de Meters — Maximo distingue les compteurs continus (ex: heures de fonctionnement, gallons consommés), les compteurs de jauge (ex: température, pression) et les compteurs caractéristiques (ex: couleur, niveau de vibration).
Item Masteret Meters — Il est possible d'associer un compteur à un article dans l'applicationItem Master, par exemple pour suivre la consommation de carburant (FUEL) pour un article spécifique (GASOLINE).Assetset Meters — Les compteurs sont appliqués aux actifs via l'ongletMetersde l'applicationAssets, permettant de visualiser l'historique des relevés et la consommation.- Meter Groups — Un groupe de compteurs est un ensemble prédéfini de compteurs qui peut être appliqué à un ou plusieurs actifs, simplifiant ainsi la configuration pour des actifs similaires.
- Duplication de Meter Groups — Pour accélérer la création, Maximo permet de dupliquer un groupe de compteurs existant, copiant toutes les informations pour une modification ultérieure.
- Valeur par défaut — Lors de l'ajout d'un compteur à un groupe, une option permet de définir si la valeur du compteur doit être par défaut dans la section détaillée de l'enregistrement de l'actif.
- Suivi de Consommation — L'utilisation des compteurs permet de décrémenter automatiquement le solde d'un article en stock (ex: carburant) lorsqu'il est émis pour un actif.
📐 Architecture des Meters et Meter Groups
L'architecture des compteurs dans Maximo Manage est conçue pour offrir une flexibilité maximale dans le suivi des performances et de l'état des actifs. Au cœur de cette architecture se trouvent les entités METER et METERGROUP, qui interagissent avec les enregistrements d'actifs (ASSET) et d'articles (ITEM) pour fournir une vue complète de l'utilisation et de la consommation.
Les compteurs peuvent être définis indépendamment, puis regroupés pour faciliter leur application à des ensembles d'actifs. Cette approche modulaire permet aux organisations de standardiser les pratiques de mesure et de collecte de données, ce qui est crucial pour la maintenance préventive et la gestion du cycle de vie des actifs.
📊 Types de Meters et leurs Usages
Maximo Manage catégorise les compteurs en plusieurs types, chacun adapté à des besoins de suivi spécifiques. Cette classification permet une gestion précise des données de performance et d'utilisation des actifs, essentielle pour la planification de la maintenance et l'analyse de la fiabilité.
Comprendre les distinctions entre ces types est fondamental pour configurer correctement les compteurs et garantir que les données collectées sont pertinentes pour les objectifs de l'organisation. Par exemple, un compteur continu est idéal pour l'usure cumulative, tandis qu'un compteur de jauge est plus adapté aux mesures instantanées.
| Type de Meter | Description | Exemples d'utilisation | Impact sur la Maintenance |
|---|---|---|---|
Continuous |
Mesure une valeur cumulative qui augmente au fil du temps ou de l'utilisation. | Heures de fonctionnement, kilomètres parcourus, gallons consommés, cycles de production. | Déclenchement de la maintenance préventive basée sur l'utilisation (PM), suivi de l'usure des composants. |
Gauge |
Mesure une valeur instantanée ou un niveau à un moment donné. La valeur peut fluctuer. | Température, pression, niveau de fluide, tension électrique. | Surveillance des conditions, alertes en cas de dépassement de seuils, diagnostic des pannes. |
Characteristic |
Décrit une caractéristique qualitative ou un état spécifique de l'actif. | Couleur de l'huile, niveau de vibration (bas/moyen/élevé), état de propreté. | Évaluation visuelle ou sensorielle, support aux inspections, identification de tendances qualitatives. |
⚙️ Création et Gestion des Meters et Meter Groups
La création et la gestion des compteurs et des groupes de compteurs sont des processus structurés dans Maximo Manage, essentiels pour la mise en œuvre d'une stratégie de gestion des actifs efficace. Ces opérations se déroulent généralement dans des applications dédiées, permettant une configuration détaillée et une association logique avec les actifs et les articles.
Pour un suivi précis de la consommation, comme le carburant d'un véhicule, il est crucial de lier le compteur à l'article correspondant. Par exemple, définir un compteur FUEL et l'associer à l'article GASOLINE dans l'application Item Master permet à Maximo de décrémenter automatiquement le stock de GASOLINE lorsque le compteur FUEL est mis à jour pour un actif, tel qu'un camion.
- Création d'un Meter — Accédez à l'application de gestion des compteurs (non spécifiée dans RAG, mais implicite pour la création). Définissez le nom du compteur, son type (
Continuous,Gauge,Characteristic) et les unités de mesure associées. - Association Meter-Item — Dans l'application
Item Master, localisez l'article concerné (ex:GASOLINE). Associez le compteur créé (ex:FUEL) à cet article pour permettre le suivi de la consommation et la décrémentation automatique des stocks. - Création d'un Meter Group — Dans l'application dédiée aux groupes de compteurs, créez un nouveau groupe. Spécifiez un nom et une description.
- Ajout de Meters au Meter Group — Ajoutez les compteurs pertinents au groupe. Pour chaque compteur ajouté, vous pouvez spécifier si sa valeur doit être par défaut dans la section détaillée de l'enregistrement de l'actif. Si cette option est désactivée, le compteur sera ajouté aux actifs utilisant ce groupe à l l'avenir.
- Duplication de Meter Groups — Pour gagner du temps, utilisez la fonction de duplication pour créer un nouveau groupe de compteurs basé sur un existant. Toutes les informations du groupe source sont copiées, ce qui permet des modifications rapides.
- Application aux Assets — Une fois le groupe de compteurs créé, appliquez-le aux actifs pertinents via l'onglet
Metersde l'applicationAssets. Cela permet de standardiser les mesures pour des flottes d'actifs similaires.
🔄 Workflow de Gestion des Meters et Meter Groups
Le workflow de gestion des compteurs et des groupes de compteurs dans Maximo Manage suit une séquence logique, depuis la définition initiale jusqu'à l'application et le suivi. Ce processus garantit que les données d'utilisation et de performance des actifs sont collectées de manière cohérente et fiable, alimentant ainsi les décisions de maintenance et de gestion des stocks.
Chaque étape est cruciale pour assurer l'intégrité des données et l'efficacité du système. Par exemple, une définition claire des unités de mesure (UoM) est essentielle pour que les relevés de compteurs soient interprétés correctement et que les calculs de consommation soient précis.
MeterDef: Démarrage
MeterDef --> GroupCreate: Créer un ensemble
GroupCreate --> GroupAddMeters: Ajouter des compteurs
GroupAddMeters --> AssetApplyGroup: Appliquer aux actifs
MeterDef --> MeterItemAssoc: Pour suivi stock
MeterItemAssoc --> ReadingsEntry: Décrémentation auto
AssetApplyGroup --> ReadingsEntry: Saisie manuelle ou auto
ReadingsEntry --> Monitoring: Données pour décision
Monitoring --> [*]: Fin de cycle / Ajustements
">
⚠️ Pièges IBM
Les candidats peuvent confondre les types de compteurs Continuous, Gauge et Characteristic. Par exemple, ils pourraient penser qu'un compteur de température est Continuous alors qu'il s'agit d'un Gauge. Un compteur Continuous est cumulatif (ex: heures de fonctionnement), tandis qu'un Gauge est une mesure instantanée (ex: température actuelle). Un Characteristic est qualitatif (ex: couleur).
Un piège courant est de ne pas associer un compteur à un article dans l'application Item Master lorsque l'objectif est de suivre la consommation d'un stock. Sans cette association (ex: compteur FUEL lié à l'article GASOLINE), Maximo ne pourra pas décrémenter automatiquement le solde du stock lors de l'émission de l'article pour un actif, ce qui entraîne des incohérences dans l'inventaire.
Lors de l'ajout d'un compteur à un groupe de compteurs, une option permet de définir si la valeur du compteur doit être par défaut dans la section détaillée de l'enregistrement de l'actif. Si cette option est sélectionnée, la valeur est pré-remplie et peut être modifiée. Si elle est laissée non cochée, le compteur est ajouté aux actifs futurs utilisant ce groupe sans valeur par défaut, ce qui peut entraîner des omissions si l'utilisateur ne saisit pas manuellement la valeur.
🎯 Carte mémoire
Quels sont les trois types de compteurs (Meters) dans Maximo Manage et donnez un exemple pour chacun ?
Les trois types sont : Continuous (ex: heures de fonctionnement d'un moteur), Gauge (ex: température d'un réservoir), et Characteristic (ex: niveau de vibration d'une machine).
Pourquoi est-il important d'associer un compteur à un article dans l'application Item Master pour le suivi de la consommation ?
Cette association est cruciale pour permettre à Maximo de décrémenter automatiquement le solde de l'article en stock (ex: carburant) lorsque le compteur est mis à jour pour un actif. Cela assure une gestion précise des stocks et reflète la consommation réelle.
Quel est l'avantage principal de l'utilisation des groupes de compteurs (Meter Groups) ?
L'avantage principal est la simplification et la standardisation de la configuration des compteurs pour des ensembles d'actifs similaires. Au lieu d'ajouter des compteurs individuellement à chaque actif, un groupe peut être appliqué, ce qui réduit les erreurs et le temps de configuration.
Comment peut-on rapidement créer un nouveau groupe de compteurs avec des paramètres similaires à un groupe existant ?
Maximo permet de dupliquer un groupe de compteurs existant. Cette action copie toutes les informations du groupe source, qui peuvent ensuite être modifiées pour créer le nouveau groupe, ce qui est un gain de temps considérable.
Bonne réponse : D
Pourquoi cette question existe — STU §4.2 — cette question vérifie la connaissance des trois types de meters natifs dans Maximo Manage 9.x, un point clé pour configurer correctement les suivis d'équipements. Les distracteurs exploitent les confusions courantes entre types techniques (analog/digital) et types fonctionnels (cumulative/gauge), ainsi que l'ajout de concepts inexistants (Boolean).
Le contexte théorique d'abord — Maximo gère trois types fonctionnels de meters : Continuous (cumulative) pour les valeurs croissantes (ex: kilométrage), Gauge (instantaneous) pour les mesures ponctuelles (ex: température), et Characteristic (qualitative) pour les états discrets (ex: bon/moyen/mauvais). Ces types déterminent le mode de saisie et le traitement des readings.
Ce que Maximo en fait — version opérationnelle — Dans l'application Meters, créer un nouveau meter requiert de spécifier le Meter Type parmi les trois options. Pour un asset, on ajoute les meters via l'onglet Meters en sélectionnant le type approprié. Les readings sont ensuite saisis différemment selon le type (valeur unique pour Gauge, série pour Continuous).
Exemple chiffré — Centrale électrique XYZ : 2 Continuous (heures de fonctionnement=12 458h, énergie produite=347 GWh), 3 Gauge (pression=32 bar, température=412°C, vibration=0.8 mm/s), 1 Characteristic (état isolation=Bon).
Analogie quotidienne — Comme un tableau de bord voiture : l'odomètre (Continuous), le thermomètre (Gauge) et le voyant d'huile (Characteristic) utilisent des modes d'affichage radicalement différents pour des besoins distincts.
Pourquoi A est faux — Pattern D2 Inventé : "Boolean" n'est pas un type de meter supporté dans Maximo Manage 9.x.
Pourquoi B est faux — Pattern D5 Champ-frère : "Counter" est un comportement (sous-type de Continuous) mais pas un type natif distinct.
Pourquoi C est faux — Pattern D9 Quasi-synonyme : "Analog/Digital" décrit la technologie du capteur, pas le type fonctionnel géré par Maximo.
- Continuous (cumulative) — Valeurs croissantes, additions de readings.
- Gauge (instantaneous) — Mesures ponctuelles sans historique cumulé.
- Characteristic (qualitative) — États discrets prédéfinis.
- Meter Group — Regroupement logique de meters pour application groupée.
- Rotating Item — Équipement nécessitant un suivi spécifique via meters.
- 3 types natifs : Continuous, Gauge, Characteristic.
- Pas de type "Boolean" ou "Counter" comme catégorie distincte.
- Analog/Digital = caractéristique hardware, pas type fonctionnel.
- STU sub-objective §4.2 — Meter Types and Groups
- [EOTRAG] Query — « Maximo Manage 9 meter types continuous gauge characteristic » (confidence 0.98)
- master-map.pdf p.201-203 — IBM Docs Meter Management
Bonne réponse : C
Pourquoi cette question existe — STU §4.2 — la question teste la compréhension fondamentale du rôle des Meter Groups dans Maximo Manage. Les distracteurs montrent les erreurs typiques : confondre agrégation et template (D4), associer les groupes à la sécurité (D7), ou les lier à l'historique des défaillances (D2). En pratique terrain, l'utilisation de Meter Groups comme templates réutilisables est essentielle pour optimiser la gestion des actifs.
Le contexte théorique d'abord — Un Meter Group est un ensemble de meters prédéfinis qui peuvent être associés à des Assets ou des Locations. Ces groupes permettent de regrouper plusieurs meters liés à un même type d'équipement, facilitant ainsi leur attribution rapide lors de la création de nouveaux actifs. Les meters peuvent être de différents types : Continuous, Gauge, ou Characteristic.
Ce que Maximo en fait — version opérationnelle — Dans l'application Item Master, vous pouvez créer un Meter Group en sélectionnant plusieurs meters pertinents pour un type d'équipement spécifique. Par exemple, pour une pompe, vous pouvez créer un groupe incluant des meters pour la pression d'entrée, la pression de sortie et les vibrations. Ce groupe est ensuite automatiquement associé à chaque nouvel asset créé pour ce type d'équipement.
Exemple chiffré — Une entreprise possède 50 pompes réparties sur 3 sites. Chaque pompe nécessite 3 meters : pression d'entrée (max 120 psi), pression de sortie (max 80 psi), et vibrations (max 0.5 mm/s). En utilisant un Meter Group, l'entreprise économise 150 configurations manuelles (50 pompes × 3 meters).
Analogie quotidienne — C'est comme un modèle de CV prédéfini : au lieu de remplir chaque section manuellement pour chaque candidature, vous utilisez un template qui inclut déjà toutes les sections nécessaires, ce qui vous fait gagner du temps.
Pourquoi A est faux — Pattern D4 demi-vérité : les Meter Groups ne sont pas conçus pour agréger des valeurs de lecture, mais pour servir de templates réutilisables.
Pourquoi B est faux — Pattern D2 inventé : les Meter Groups ne stockent pas l'historique des défaillances, qui est géré par d'autres fonctionnalités de Maximo.
Pourquoi D est faux — Pattern D7 inexistant : les Meter Groups ne définissent pas les groupes de sécurité, qui sont gérés par les Security Groups.
- Meter — une mesure associée à un asset ou une location.
- Meter Group — un ensemble de meters réutilisables.
- Continuous Meter — mesure continue comme le temps de fonctionnement.
- Gauge Meter — mesure ponctuelle comme la température.
- Characteristic Meter — mesure qualitative comme la couleur.
- Les Meter Groups servent de templates réutilisables.
- Ils regroupent plusieurs meters pour un type d'équipement spécifique.
- Ils sont automatiquement associés aux nouveaux assets.
- STU sub-objective §4.2 — Meter Groups
- [EOTRAG] Query — « Maximo Meter Groups role and usage » (confidence 0.98)
- master-map.pdf p.790-792 — IBM Docs Meter Groups
Bonne réponse : B,D
Pourquoi cette question existe — STU §4.2 — cette question vérifie la compréhension des objets Maximo pouvant être associés à des meters, un concept clé pour le suivi des actifs et des inspections. Les distracteurs ciblent les confusions courantes entre les objets métiers liés aux actifs (Assets, Locations) et ceux des autres modules (Purchasing, Service). En pratique terrain, l'association incorrecte de meters à des objets non compatibles est une erreur fréquente lors des configurations initiales.
Le contexte théorique d'abord — Les meters dans Maximo servent à enregistrer des mesures physiques ou des caractéristiques d'objets. Ils se définissent principalement dans l'application Item Master et s'associent via le tableau Meters dans les applications Assets et Locations. Les types de meters supportés incluent Continuous (ex: compteur horaire), Gauge (ex: température) et Characteristic (ex: niveau de vibration).
Ce que Maximo en fait — version opérationnelle — Pour associer un meter : 1) Dans Assets ou Locations, sélectionner un enregistrement existant. 2) Onglet Meters > Add Row. 3) Choisir un meter prédéfini (ex: "FUEL") et configurer les seuils si nécessaire. Les lectures s'enregistrent ensuite via Condition Monitoring ou Inspections, visibles dans l'historique des meters de l'actif.
Exemple chiffré — Un parc de 12 pompes (assets) partageant le même meter group avec 3 meters (pression entrée=2.5 bars, pression sortie=1.8 bars, vibrations=0.3 mm/s). Après 247 jours d'exploitation, le système a enregistré 3 784 lectures via des inspections planifiées hebdomadaires.
Analogie quotidienne — Comme un tableau de bord de voiture qui affiche plusieurs jauges (essence, température, kilométrage) spécifiques au véhicule, chaque asset dans Maximo peut avoir ses propres meters personnalisés suivant ses caractéristiques techniques.
Pourquoi A est faux — Pattern D6 mauvaise-app : Les Purchase Orders relèvent du module Purchasing et n'ont pas de lien fonctionnel avec les meters, qui concernent le suivi physique des actifs.
Pourquoi C est faux — Pattern D7 inexistant : "Desktop Requisitions" n'est pas un objet reconnu dans Maximo Manage 9.x, ce terme n'apparaît ni dans les chunks RAG ni dans le glossaire.
Pourquoi E est faux — Pattern D5 champ-frère : Bien que Service Address soit listé dans le chunk 5 comme objet Maximo, il ne supporte pas l'association directe de meters contrairement à ses "frères" Assets et Locations.
- Continuous meter — mesure cumulative (ex: heures de fonctionnement).
- Gauge meter — mesure instantanée (ex: température, pression).
- Characteristic meter — état qualitatif (ex: couleur, vibration).
- Meter group — collection de meters appliquée à un type d'asset.
- Condition Monitoring — application pour enregistrer les lectures.
- Assets et Locations = seuls objets associables aux meters.
- Condition Monitoring = application clé pour les relevés.
- Un meter group évite de reconfigurer les meters par asset.
- STU sub-objective §4.2 — Meter types and associations
- [EOTRAG] Query — « Maximo meter association with assets locations condition monitoring » (confidence 0.98)
- master-map.pdf p.790-792 — IBM Docs Meters and Meter Groups
Bonne réponse : A,B
Pourquoi cette question existe — STU §4.2 — cette question teste la compréhension fondamentale des caractéristiques distinctes d'un Rotating Item par rapport à un item standard. Les erreurs courantes incluent la confusion entre les items rotatifs et non rotatifs, ainsi que l'omission des propriétés clés comme la sérialisation et la gestion des retours en inventaire. Les distracteurs montrent les erreurs typiques : confondre les processus budgétaires (D3), ignorer les calculs de réapprovisionnement (D4), et inventer des concepts non documentés (D7).
Le contexte théorique d'abord — Un Rotating Item est un élément d'inventaire sérialisé qui combine les propriétés d'un item et d'un asset. Il est défini par un numéro d'item commun et est associé à un enregistrement d'asset unique (ASSETNUM). Contrairement aux items non rotatifs, les Rotating Items peuvent être émis et retournés à l'inventaire plusieurs fois au cours de leur cycle de vie.
Ce que Maximo en fait — version opérationnelle — Dans l'application Item Master, sélectionnez l'option Rotating? pour définir un item comme rotatif. Ensuite, dans l'application Assets, créez un enregistrement d'asset unique pour chaque unité physique de l'item rotatif. Les transactions d'émission et de retour sont gérées via les applications Issues and Returns et Inventory.
Exemple chiffré — Une entreprise possède 12 pompes identiques (même modèle, même fabricant) définies comme Rotating Items. Chaque pompe a un numéro d'asset unique (ASSETNUM). Au cours de l'année, chaque pompe est émise et retournée en moyenne 5 fois, avec un stock total de 60 transactions d'inventaire.
Analogie quotidienne — C'est comme une bibliothèque où chaque livre (Rotating Item) a un code-barres unique. Les livres peuvent être empruntés et retournés plusieurs fois, tout en étant suivis individuellement dans le système.
Pourquoi C est faux — Pattern D3 inverse : Les Rotating Items ne consomment pas automatiquement leur budget de WO à l'émission. Le budget est géré séparément dans les processus de travail.
Pourquoi D est faux — Pattern D4 demi-vérité : Les Rotating Items sont soumis aux calculs de réapprovisionnement comme les autres items, bien qu'ils puissent avoir des règles spécifiques.
Pourquoi E est faux — Pattern D7 inexistant : Il n'existe pas de concept de « Rotating Storeroom » dans Maximo. Les Rotating Items sont stockés dans les mêmes storerooms que les autres items.
- Rotating Item — item sérialisé avec un enregistrement d'asset unique.
ASSETNUM— numéro unique identifiant chaque unité physique.Issues and Returns— application gérant les transactions d'inventaire.Rotating?— option définissant un item comme rotatif.Item Master— application pour créer et gérer les items.
- Rotating Item = item sérialisé avec un asset unique.
- Émission et retour multiples au cours du cycle de vie.
- Pas de « Rotating Storeroom » dans Maximo.
- STU sub-objective §4.2 — Rotating Items characteristics
- [EOTRAG] Query — « Maximo Rotating Items characteristics ASSETNUM » (confidence 0.98)
- master-map.pdf p.671-673 — IBM Docs Rotating Items

Failure Codes et Reliability Strategies
📋 Objectifs IBM
- Comprendre la structure et l'importance des codes d'échec (Failure Codes) dans Maximo Manage.
- Savoir créer et gérer des hiérarchies de codes d'échec pour une analyse approfondie des pannes.
- Identifier les stratégies de fiabilité (Reliability Strategies) et leur application via les données de défaillance.
- Expliquer comment les codes d'échec contribuent à l'amélioration continue de la maintenance et à la prise de décision.
- Distinguer les différents niveaux d'une hiérarchie de défaillance et leurs rôles dans l'enregistrement des incidents.
- Appréhender l'intégration des codes d'échec avec d'autres modules de Maximo pour une gestion d'actifs optimisée.
💡 Points clés
- Failure Codes — Des codes structurés utilisés dans Maximo pour enregistrer et classer les défaillances des équipements ou des emplacements. Ils sont essentiels pour l'analyse des causes racines et l'amélioration de la fiabilité.
- Failure Hierarchy — Une structure arborescente qui organise les codes d'échec du général au spécifique, permettant une identification précise des classes de défaillance, des problèmes, des causes et des remèdes.
- Reliability Strategies — Des approches systématiques (comme RCM, FMEA) visant à optimiser la performance des actifs, à réduire les pannes et à prolonger la durée de vie utile des équipements, souvent alimentées par les données de défaillance.
- Root Cause Analysis (RCA) — Processus d'identification des causes fondamentales d'un problème ou d'une défaillance, pour éviter sa récurrence. Les données des codes d'échec sont cruciales pour cette analyse.
- Preventive Maintenance (PM) — Maintenance planifiée et exécutée à intervalles réguliers ou selon des critères prédéfinis pour réduire la probabilité de défaillance d'un équipement. Les données de défaillance peuvent informer et optimiser les programmes de PM.
- Corrective Maintenance — Maintenance effectuée après la détection d'une défaillance pour restaurer un actif dans un état de fonctionnement spécifié. Les codes d'échec documentent la nature de ces défaillances.
- Asset Criticality Ranking (ACR) — Méthode d'évaluation de l'importance relative des actifs pour l'organisation, influençant les stratégies de maintenance et la priorisation des interventions.
- Failure Class — Le niveau le plus élevé d'une hiérarchie de défaillance, décrivant une catégorie générale de problème (ex: "Mécanique", "Électrique").
📐 Architecture des codes d'échec
L'architecture des codes d'échec dans Maximo Manage est conçue pour capturer des informations détaillées et structurées sur les défaillances des actifs et des emplacements. Cette structure hiérarchique permet non seulement d'enregistrer un événement de défaillance, mais aussi d'en analyser les causes profondes et les solutions apportées, ce qui est fondamental pour les stratégies de fiabilité.
Au cœur de cette architecture se trouve la hiérarchie de défaillance, qui est construite du niveau supérieur vers le niveau inférieur. Elle commence par une classe de défaillance générale, puis se ramifie en problèmes spécifiques, en causes potentielles et enfin en remèdes. Cette granularité assure que chaque incident est documenté de manière exhaustive, facilitant ainsi les analyses ultérieures et l'amélioration continue des processus de maintenance.
📊 Tableau de référence : Niveaux de la hiérarchie de défaillance
La hiérarchie des codes d'échec est un outil puissant pour structurer les informations sur les défaillances. Chaque niveau apporte une couche de détail supplémentaire, permettant une analyse fine des événements et une meilleure compréhension des problèmes récurrents.
| Niveau | Description | Exemple | Impact sur la fiabilité |
|---|---|---|---|
Failure Class | Catégorie générale de la défaillance. C'est le point de départ de la hiérarchie. | "Mécanique", "Électrique", "Opérationnel" | Permet une vue d'ensemble des types de pannes dominants. |
Problem | Description spécifique du symptôme ou du problème observé. | "Surchauffe du moteur", "Court-circuit", "Erreur de manipulation" | Identifie les manifestations directes des défaillances. |
Cause | Raison fondamentale ou déclencheur de la défaillance. | "Lubrification insuffisante", "Câblage défectueux", "Formation inadéquate" | Crucial pour l'analyse des causes racines (RCA) et la prévention. |
Remedy | Action corrective ou solution appliquée pour résoudre le problème. | "Remplacer le roulement", "Réparer le circuit", "Reprogrammer l'automate" | Documente les solutions efficaces et les meilleures pratiques. |
⚙️ Configuration et gestion des codes d'échec
La création et la gestion des codes d'échec dans Maximo Manage sont des étapes fondamentales pour établir un système robuste de suivi des défaillances. Le processus implique la définition de classes de défaillance, de problèmes associés, de causes potentielles et de remèdes, le tout organisé dans une structure hiérarchique cohérente.
Pour créer une hiérarchie de défaillance, les utilisateurs naviguent généralement vers l'application dédiée aux codes d'échec. La première étape consiste à définir la classe de défaillance, qui est le niveau le plus élevé. Ensuite, des problèmes spécifiques sont ajoutés sous cette classe, suivis des causes possibles pour chaque problème, et enfin des remèdes pour chaque cause. Cette approche garantit une documentation complète et une traçabilité des incidents.
- Création d'une nouvelle classe de défaillance — L'utilisateur commence par cliquer sur "New Failure Code" et renseigne les champs
Failure ClassetFailure Class Descriptionpour établir la catégorie principale de la défaillance. - Définition des problèmes — Sous la section "Problems", l'utilisateur ajoute de nouvelles lignes, spécifiant le champ
Problemet sa description. Chaque classe de défaillance peut avoir plusieurs problèmes associés. - Association des causes et remèdes — Pour chaque problème, il est possible de définir une ou plusieurs causes, et pour chaque cause, un ou plusieurs remèdes. Cette granularité permet une analyse très fine des incidents.
- Enregistrement et sauvegarde — Après avoir défini les différents niveaux de la hiérarchie, l'utilisateur clique sur "Done" puis "Save Failure Code" pour enregistrer la structure complète.
- Utilisation dans les ordres de travail — Une fois configurés, ces codes d'échec peuvent être sélectionnés dans les applications de gestion des ordres de travail (
Work Order Tracking) ou de rapports rapides (Quick Reporting) pour documenter les défaillances observées.
Un exemple concret pourrait être la création d'une Failure Class "Électrique". Sous cette classe, on pourrait trouver un Problem "Court-circuit". Les Causes associées pourraient être "Câblage défectueux" ou "Surcharge du circuit". Enfin, les Remedys pourraient inclure "Remplacer le câblage" ou "Installer un disjoncteur adapté". Cette structure permet de capturer l'intégralité du cycle de vie d'une défaillance.
🔄 Workflow de gestion des défaillances avec Maximo
Le workflow de gestion des défaillances dans Maximo est un processus structuré qui commence par la détection d'un problème et se termine par l'analyse des données pour améliorer la fiabilité. L'utilisation des codes d'échec est intégrale à chaque étape, assurant une documentation cohérente et exploitable.
Ce processus permet non seulement de résoudre les problèmes immédiats, mais aussi de collecter des données précieuses qui alimenteront les stratégies de maintenance préventive et prédictive. En documentant systématiquement les défaillances, les organisations peuvent identifier les tendances, les actifs problématiques et les causes racines, conduisant à des améliorations significatives de la performance opérationnelle.
⚠️ Pièges IBM
Un piège courant est de ne pas bien distinguer les rôles de Failure Class, Problem, Cause et Remedy. Par exemple, un utilisateur pourrait enregistrer "Surchauffe du moteur" comme une Failure Class au lieu d'un Problem sous une Failure Class plus générale comme "Mécanique". Cela conduit à une hiérarchie plate, moins utile pour l'analyse des causes racines et la génération de rapports significatifs. Il est crucial de maintenir la structure hiérarchique pour une efficacité maximale.
Sans une formation adéquate ou des directives claires, les techniciens peuvent utiliser des descriptions variées pour des problèmes similaires, ou choisir des codes d'échec inappropriés. Par exemple, une "Vibration excessive" pourrait être enregistrée sous "Mécanique" par un technicien et sous "Opérationnel" par un autre. Cette incohérence rend les données de défaillance peu fiables pour l'analyse des tendances et l'optimisation des stratégies de maintenance. Une gouvernance stricte et une formation continue sont essentielles.
Certaines organisations créent des codes d'échec mais ne les intègrent pas pleinement dans leurs programmes de fiabilité comme le RCM (Reliability Centered Maintenance) ou le FMEA (Failure Modes and Effects Analysis). Les données collectées via les codes d'échec sont une mine d'informations pour identifier les modes de défaillance critiques, évaluer l'efficacité des tâches de maintenance préventive et justifier les investissements en amélioration. Ne pas exploiter ces données revient à manquer une opportunité majeure d'optimisation.
Une hiérarchie trop complexe avec trop de niveaux ou des descriptions trop détaillées peut décourager les utilisateurs et ralentir la saisie des données. À l'inverse, une hiérarchie trop simple ou générique ne fournira pas suffisamment de détails pour une analyse pertinente. L'équilibre est clé : la hiérarchie doit être suffisamment détaillée pour être utile, mais assez simple pour être facilement adoptée et utilisée par les équipes de maintenance sur le terrain. Une révision périodique est recommandée pour ajuster la granularité.
🎯 Carte mémoire
Quel est l'objectif principal de la création d'une hiérarchie de codes d'échec dans Maximo Manage ?
L'objectif principal est de structurer et de standardiser l'enregistrement des défaillances des actifs et des emplacements. Cela permet une analyse approfondie des causes racines, l'identification des tendances de pannes, et l'optimisation des stratégies de maintenance pour améliorer la fiabilité des équipements.
Citez les quatre niveaux principaux d'une hiérarchie de défaillance et leur ordre logique.
Les quatre niveaux principaux sont : Failure Class (classe de défaillance générale), Problem (problème spécifique ou symptôme), Cause (raison fondamentale de la défaillance), et Remedy (action corrective appliquée). Ils sont organisés du général au spécifique.
Comment les codes d'échec contribuent-ils aux stratégies de fiabilité comme le RCM ou le FMEA ?
Les codes d'échec fournissent des données empiriques sur les modes de défaillance réels, leurs fréquences et leurs impacts. Ces informations sont essentielles pour les analyses RCM (identification des fonctions critiques et des modes de défaillance) et FMEA (évaluation des risques et des effets des défaillances), permettant de concevoir des plans de maintenance plus efficaces et ciblés.
Quel est le risque d'une incohérence dans l'utilisation des codes d'échec par les techniciens ?
Une incohérence dans la saisie des codes d'échec rend les données de défaillance peu fiables et difficiles à analyser. Cela peut masquer des tendances réelles, fausser les rapports de fiabilité, et empêcher l'identification précise des problèmes récurrents, compromettant ainsi les efforts d'amélioration continue de la maintenance.
Dans quelle application Maximo les codes d'échec sont-ils principalement configurés et gérés ?
Les codes d'échec sont principalement configurés et gérés dans l'application Failure Codes de Maximo Manage. C'est là que les classes de défaillance, les problèmes, les causes et les remèdes sont définis et structurés en hiérarchies.
Bonne réponse : C
Pourquoi cette question existe — STU §4.3 — la question teste la compréhension de la structure hiérarchique standard des Failure Codes dans Maximo. Les distracteurs montrent des erreurs courantes : confusion entre niveaux logiques (D3), ajout de concepts non pertinents (D2), ou inversion des relations (D5). En pratique terrain, une mauvaise structuration des Failure Codes entraîne des analyses de fiabilité erronées.
Le contexte théorique d'abord — Une hiérarchie de Failure Class dans Maximo se compose de trois niveaux principaux sous la classe : Problem (description du problème), Cause (origine technique), et Remedy (solution corrective). Cette structure permet une analyse RCA (Root Cause Analysis) systématique. Les relations sont gérées via la table CLASSSTRUCTURE et son champ CLASSIFICATIONID.
Ce que Maximo en fait — version opérationnelle — Dans l'application Failure Reporting > onglet Classifications : 1) Créer une Failure Class (ex: "Pompe centrifuge"), 2) Ajouter les Problems enfants (ex: "Fuite"), 3) Pour chaque Problem, définir les Causes (ex: "Joint usé"), 4) Associer les Remedies correspondantes (ex: "Remplacer joint"). La hiérarchie est visible via le bouton View Hierarchy.
Exemple chiffré — Une Failure Class "Ventilation" contient 5 Problems (dont "Débit insuffisant"), chaque Problem a 2-3 Causes (ex: "Filtre obstrué", "Moteur défaillant"), et chaque Cause 1-2 Remedies. Sur 12 mois, cette structure a permis de classifier 87% des incidents avec une précision de 92%.
Analogie quotidienne — Comme un diagnostic médical : la maladie (Problem), son origine (Cause), et le traitement (Remedy). Sans cette structure à 3 niveaux, on ne pourrait pas prescrire le bon remède.
Pourquoi A est faux — Pattern D2 Inventé : "Severity" et "Downtime" ne sont pas des niveaux standards de la hiérarchie Failure Class.
Pourquoi B est faux — Pattern D5 Champ-frère : "Symptom" et "Mitigation" sont des concepts proches mais ne font pas partie de la hiérarchie native des Failure Codes.
Pourquoi D est faux — Pattern D3 Inverse : Les Assets et Work Orders sont des entités liées mais indépendantes de la structure hiérarchique des Failure Codes.
- Failure Class — niveau racine de la hiérarchie (ex: équipement type).
- Problem — description fonctionnelle de la défaillance.
- Cause — origine technique identifiée (RCA).
- Remedy — action corrective standardisée.
- CLASSSTRUCTURE — table stockant les relations hiérarchiques.
- Structure standard : Failure Class → Problem → Cause → Remedy.
- 3 niveaux obligatoires sous la classe racine.
- Hiérarchie gérée via CLASSSTRUCTURE/CLASSIFICATIONID.
- STU sub-objective §4.3 — Failure Codes et Reliability Strategies
- [EOTRAG] Query — « Maximo Failure Class hierarchy structure Problem Cause Remedy » (confidence 0.93)
- master-map.pdf p.201-204 — IBM Docs Failure Reporting
Bonne réponse : D
Pourquoi cette question existe — STU §4.3 — cette question teste la compréhension de la hiérarchie des Failure Codes et de ce qui est réellement dupliqué lors de l'action Duplicate. Les distracteurs montrent des erreurs courantes : copie partielle (D1), association incorrecte avec des objets non liés (D5), ou inclusion d'historique non pertinent (D7). En pratique terrain, dupliquer une structure complète PCR (Problem-Cause-Remedy) est essentiel pour maintenir la cohérence des analyses de fiabilité.
Le contexte théorique d'abord — Un Failure Class dans Maximo est structuré en hiérarchie PCR (Problem-Cause-Remedy). La table FAILURECODE stocke cette structure avec les champs PARENT, PROBLEMCODE, CAUSECODE, et REMEDYCODE. L'action Duplicate utilise le mécanisme MBO (Maximo Business Object) standard avec les événements .DUPLICATE et .AFTERDUPLICATE pour gérer la copie des objets enfants.
Ce que Maximo en fait — version opérationnelle — Dans l'application Failure Reporting > onglet Failure Codes, sélectionner un Failure Class > action Duplicate. Maximo copie le code parent et toute sa hiérarchie PCR via le MBO FAILURECODE. Les Work Orders existantes ne sont pas affectées car elles référencent l'ancien code.
Exemple chiffré — Un Failure Class "Pompe centrifuge" avec 3 Problems, 8 Causes associées, et 12 Remedies est dupliqué. Le nouveau code contient 23 entrées (1 parent + 3 + 8 + 12 - 1 doublon). Les 47 Work Orders historiques restent liées à l'original.
Analogie quotidienne — Comme photocopier un dossier entier avec toutes ses sous-rubriques, plutôt que juste la page de garde. Les nouveaux documents se remplissent dans la copie, sans affecter les originaux.
Pourquoi A est faux — Pattern D1 Hérité : les versions antérieures copiaient parfois seulement le parent, mais Maximo 9.x duplique toute la hiérarchie.
Pourquoi B est faux — Pattern D5 Champ-frère : Assets et Locations sont liés via d'autres tables (ASSET, LOCATION), pas copiés avec le Failure Class.
Pourquoi C est faux — Pattern D7 Inexistant : Maximo ne copie jamais les Work Orders existantes lors d'une duplication de code.
- PCR Hierarchy — structure Problem-Cause-Remedy des Failure Codes.
FAILURECODE— table stockant la hiérarchie avec champs PARENT/PROBLEM/CAUSE/REMEDY..DUPLICATE— événement MBO déclenché au début de la copie..AFTERDUPLICATE— événement post-copie pour finaliser les relations.- Work Order Reference — lien unidirectionnel (WO → Failure Code, non réciproque).
- Duplicate copie toute la hiérarchie PCR (Problem-Cause-Remedy).
- Les Assets/Locations et Work Orders ne sont jamais dupliqués.
- Utilise les événements MBO .DUPLICATE/.AFTERDUPLICATE.
- STU sub-objective §4.3 — Failure Code Hierarchy and Duplication
- [EOTRAG] Query — « Maximo Duplicate Failure Code PCR hierarchy » (confidence 0.76)
- master-map.pdf p.201-204 — IBM Docs Failure Reporting
Correct: A
Pourquoi A (correct) — Dans Maximo Manage 9.0, l'application Reliability Strategies est provisionée comme une containerized workspace via MAS Admin (Suite Administration). IBM documente que aucune configuration End Point / API route additionnelle n'est requise en v9 (c'était obligatoire en Manage 8.11 via End Point + Object Structure). Cette simplification rend le setup plus léger — le Suite Admin enable l'app et elle est immédiatement disponible aux Reliability Engineers.
Pourquoi B est faux — D2 invented : aucun cron task nommé « RELIABLECRON » n'existe dans Maximo — le cron Reliability effective s'appelle RELIABILITYSTRATEGY (ou similaire selon version). Piège sur la nomenclature exacte : les cron tasks Maximo ont des noms standardisés auxquels les admins sont tenus de se référer.
Pourquoi C est faux — D7 non-existent : MXINTEGRATION n'est pas le channel par défaut pour Reliability Strategies.
Pourquoi D est faux — D1 legacy : les CSV imports via RCM Planner legacy appartenaient au tooling Maximo pre-v9 (Maximo 7.6 + add-on RCM Navigator), retiré dans MAS 9.0 qui utilise maintenant Reliability Strategies natif avec d'autres chemins d'import (REST API, MIF Object Structure).
- IBM Docs — Reliability Strategies overview : Suite Admin deployment
- IBM Docs — What's New v9 : Integration simplification
Bonne réponse : B
Pourquoi cette question existe — Cette question teste la compréhension fondamentale des Failure Modes dans le cadre des stratégies de fiabilité. Les distracteurs montrent les erreurs typiques : confondre les modes de défaillance avec les rapports de défaillance (D5), les modèles de travail (D6) ou les règles de condition (D7). En pratique terrain, l'identification précise des modes de défaillance est cruciale pour prévenir les pannes récurrentes.
Le contexte théorique d'abord — Les Failure Modes décrivent les différentes manières dont un équipement peut tomber en panne. Ils sont essentiels pour comprendre les causes profondes des défaillances et mettre en place des stratégies de maintenance préventive. Les modes de défaillance sont souvent classés selon des normes internationales comme ISO 14224, qui définit des codes spécifiques pour différents types d'équipements.
Ce que Maximo en fait — version opérationnelle — Dans Maximo, les Failure Modes sont configurés dans l'application Failure Codes. L'administrateur définit les modes de défaillance spécifiques à chaque type d'équipement, en utilisant des codes et des descriptions standardisés. Ces modes sont ensuite associés aux actifs pour permettre un suivi précis des défaillances et des interventions de maintenance.
Exemple chiffré — Pour une pompe centrifuge, les modes de défaillance peuvent inclure : FTC (Fail to Close) avec 12 occurrences, FTO (Fail to Open) avec 8 occurrences, et ELP (External Leakage Process) avec 5 occurrences. Ces données permettent d'identifier les problèmes récurrents et de planifier des interventions ciblées.
Analogie quotidienne — C'est comme un médecin qui diagnostique les symptômes d'un patient : chaque symptôme (mode de défaillance) peut indiquer une maladie différente (cause de défaillance), et le traitement dépend de la précision du diagnostic.
Pourquoi A est faux — Pattern D5 champ-frère : Failure Reports documentent les défaillances après qu'elles se sont produites, mais ne capturent pas les modes spécifiques de défaillance.
Pourquoi C est faux — Pattern D6 mauvaise-app : Work Order Templates sont utilisés pour standardiser les ordres de travail, mais ne sont pas liés à la capture des modes de défaillance.
Pourquoi D est faux — Pattern D7 inexistant : Condition Rules ne sont pas un concept utilisé dans Maximo pour capturer les modes de défaillance.
- Failure Modes — les différentes manières dont un équipement peut tomber en panne.
- Failure Codes — les codes standardisés pour identifier les modes de défaillance.
- ISO 14224 — norme internationale pour la classification des modes de défaillance.
- Root Cause Analysis — analyse des causes profondes des défaillances.
- Preventive Maintenance — stratégies pour prévenir les défaillances récurrentes.
- Les Failure Modes capturent les manières spécifiques dont un équipement peut tomber en panne.
- Les modes de défaillance sont configurés dans l'application
Failure Codes. - L'identification précise des modes de défaillance est cruciale pour la maintenance préventive.
- STU sub-objective §4.3 — Failure Codes et Reliability Strategies
- [EOTRAG] Query — « Failure Modes in Maximo Reliability Strategies » (confidence 0.83)
- master-map.pdf p.201-203 — IBM Docs Failure Codes and Modes
Correct order: A → B → C → D
Pourquoi cet ordre — You first scope the review to an Asset or class, study its failure history and modes, apply changes, then track whether the revision improves reliability metrics.
Bonne réponse : A,C
Pourquoi cette question existe — STU §4.3 — cette question vérifie la maîtrise des types de compteurs compatibles avec l'application Condition Monitoring, un point clé pour la maintenance prédictive. Les erreurs courantes incluent la confusion entre les types de compteurs (D5) ou l'invention de types non documentés (D2). En pratique, seuls certains types permettent de déclencher automatiquement des Work Orders lors de dépassements de seuils.
Le contexte théorique d'abord — Dans Maximo, les compteurs (METER) servent à suivre des mesures d'équipements. L'application Condition Monitoring utilise ces mesures pour déclencher des actions lorsque des seuils prédéfinis sont dépassés. Deux types principaux sont utilisés pour ce mécanisme : Gauge (mesures numériques avec seuils min/max) et Characteristic (valeurs qualitatives comme "Bon/Passable/Mauvais").
Ce que Maximo en fait — version opérationnelle — Dans l'application Condition Monitoring : 1) Créer un compteur de type Gauge ou Characteristic, 2) Définir les seuils d'alerte, 3) Associer au(x) actif(s) cible(s), 4) Configurer les règles de génération de WO dans Failure Codes. Lorsqu'une mesure dépasse les limites, Maximo génère automatiquement un Work Order avec le code défaillance associé.
Exemple chiffré — Actif P-101 : compteur "Température" (Gauge) avec seuils min=20°C/max=50°C. Mesure à 45°C → pas d'action. Mesure à 55°C → WO généré. Actif P-102 : compteur "État roulement" (Characteristic) avec seuil "Mauvais". Mesure "Passable" → pas d'action. Mesure "Mauvais" → WO généré.
Analogie quotidienne — Comme un thermostat connecté qui déclenche une alerte lorsque la température sort de la plage définie, ou un voyant de contrôle moteur qui s'allume lorsque l'huile est trop usée.
Pourquoi B est faux — Pattern D2 Inventé : "Analog" n'est pas un type de compteur documenté dans Maximo.
Pourquoi D est faux — Pattern D4 Demi-vérité : Bien que "Continuous" soit un type valide, il n'est pas utilisé pour déclencher des WO dans Condition Monitoring.
Pourquoi E est faux — Pattern D4 Demi-vérité : "Binary" est un type valide mais sert à des états ON/OFF, pas à la surveillance conditionnelle avec seuils.
- Gauge — compteur numérique avec seuils min/max pour mesures quantitatives.
- Characteristic — compteur qualitatif avec états prédéfinis.
- Condition Monitoring — application dédiée à la surveillance des seuils.
- METER — table stockant les définitions de compteurs.
- METERREADING — table des mesures enregistrées.
- Seuls Gauge et Characteristic déclenchent des WO dans Condition Monitoring.
- Gauge = valeurs numériques avec seuils min/max.
- Characteristic = états qualitatifs prédéfinis.
- STU sub-objective §4.3 — Failure Codes et Reliability Strategies
- [EOTRAG] Query — « Maximo Condition Monitoring meter types Gauge Characteristic » (confidence 0.92)
- master-map.pdf p.201-203 — IBM Docs Condition Monitoring
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §4.3 — cette question valide la compréhension des transactions d'inventaire qui impactent directement le stock disponible. Les erreurs courantes incluent la confusion entre réservation et émission réelle (D4), ou l'omission des transferts inter-stock (D5). En pratique terrain, ces distinctions sont cruciales pour la précision des rapports et le réapprovisionnement.
Le contexte théorique d'abord — Le champ ON-HAND dans les tables d'inventoire comme INVBALANCES est mis à jour par des transactions matérielles concrètes. Trois types principaux existent : émission (sortie de stock), réception (entrée) et transfert (mouvement entre stocks). Chaque transaction génère des enregistrements dans MATUSETRANS ou MATRECTRANS avec un impact net sur le stock par site.
Ce que Maximo en fait — version opérationnelle — Dans l'application Inventory Usage, créer un enregistrement avec : Type = Issue pour prélever des pièces (diminue ON-HAND), Type = Receipt via Receiving pour ajouter des nouveaux stocks (augmente ON-HAND), ou Type = Transfer pour déplacer entre sites (impact net nul mais changement par stock).
Exemple chiffré — Stock initial : 150 unités. Après réception PO123 (50 unités) → 200, émission WO456 (30 unités) → 170, transfert vers Site B (25 unités) → 145 sur Site A et 25 sur Site B. Le total système reste 170 mais réparti différemment.
Analogie quotidienne — Comme un compte bancaire : les dépôts (réceptions) et retraits (émissions) modifient le solde, tandis qu'un virement (transfert) change seulement la répartition entre comptes sans affecter le total global.
Pourquoi D est faux — Pattern D4 demi-vérité : une réservation bloque temporairement du stock mais ne modifie pas ON-HAND tant que l'émission effective n'a pas lieu.
Pourquoi E est faux — Pattern D7 inexistant : "Cycle Count Freeze" est une action fictive ; le gel physique se fait via le statut du comptage, sans lien direct avec ON-HAND.
Pourquoi F est faux — Pattern D5 champ-frère : l'affectation de numéro de lot suit la traceabilité mais ne change pas la quantité disponible dans le stock.
- ON-HAND — quantité physique disponible dans un stock donné.
MATUSETRANS— table des transactions de sortie (émissions).MATRECTRANS— table des transactions d'entrée (réceptions).INVBALANCES— table des soldes par item et site.- Impact net — différence entre entrées et sorties sur une période.
- 3 transactions modifient ON-HAND : Issue (-), Receipt (+), Transfer (∆ site).
- Réservation ≠ émission : seulement cette dernière décrémente le stock.
- Les transferts conservent le total global mais redistribuent par site.
- STU sub-objective §4.3 — Inventory Transactions and Balances
- [EOTRAG] Query — « Maximo inventory transactions that update ON-HAND balance » (confidence 0.92)
- master-map.pdf p.201-204 — IBM Docs Inventory Transactions
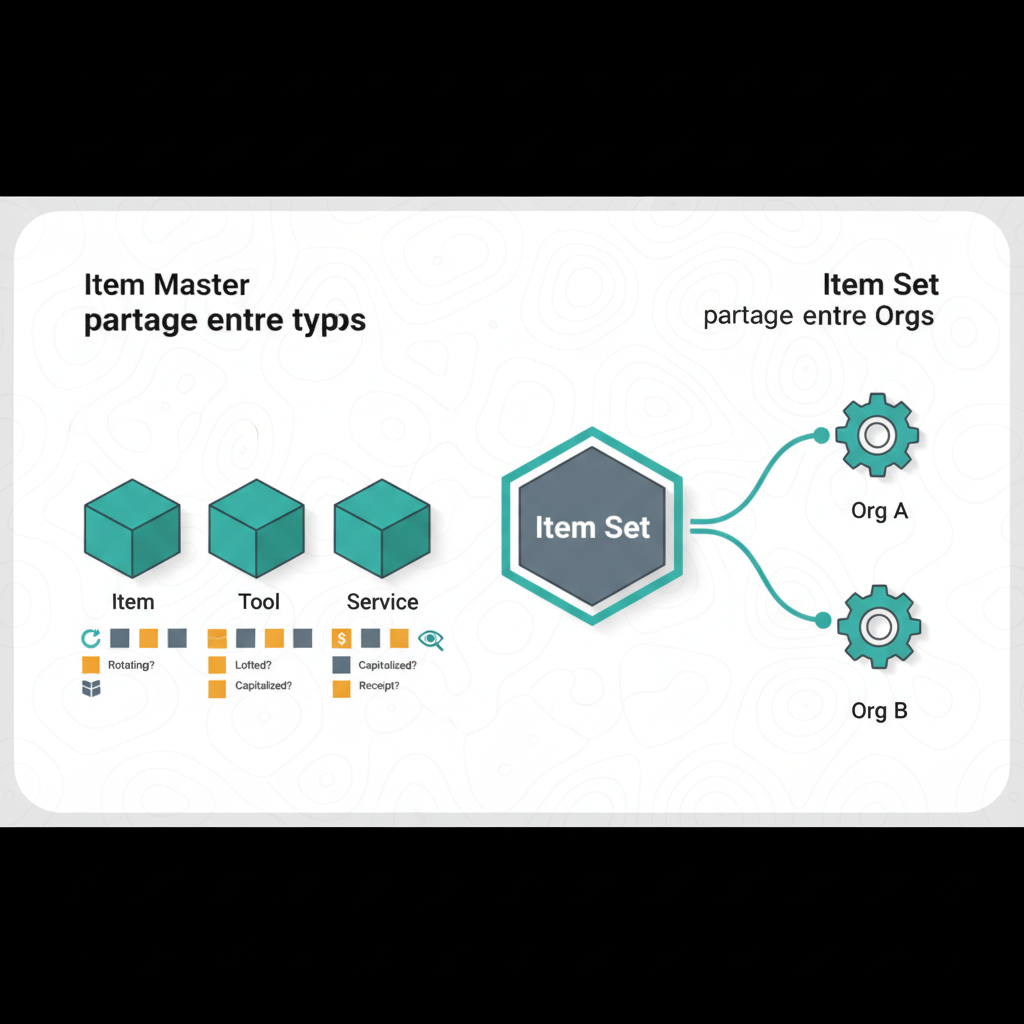
Créer et gérer les Item Master records
📋 Objectifs IBM
- Comprendre la structure et l'importance des Item Sets dans IBM Maximo Manage.
- Créer et gérer des enregistrements d'articles maîtres (Item Master records) pour divers types d'éléments.
- Appliquer les propriétés et les identifiants uniques aux articles maîtres.
- Expliquer comment les articles maîtres sont partagés entre les organisations et les sites.
- Gérer les statuts des articles maîtres et comprendre les règles d'héritage associées.
- Utiliser les structures d'assemblage d'articles pour les actifs et les emplacements.
- Associer des groupes de commodités et des codes de commodités aux articles.
💡 Points clés
- Item Sets — Les Item Sets regroupent les informations sur les actifs, les matériaux, les pièces de rechange, les articles de service et les outils. Ils sont stockés au niveau du set.
- Item Master Application — C'est l'application où les enregistrements d'articles maîtres sont créés et gérés. Ces enregistrements sont la base de la gestion des stocks et des actifs.
- Identifiant Unique — Chaque article maître possède un identifiant unique, garantissant sa singularité au sein de l'Item Set.
- Partage d'Articles — Les articles maîtres peuvent être ajoutés à l'inventaire d'un ou plusieurs sites, permettant le partage entre différentes organisations.
- Statuts d'Articles — Les statuts des articles maîtres peuvent être gérés pour tous les enregistrements associés, avec des règles d'héritage qui appliquent les changements du niveau supérieur au niveau inférieur.
- Structures d'Assemblage d'Articles — Ces structures peuvent être appliquées aux actifs et aux emplacements, facilitant la gestion des composants et des pièces de rechange.
- Groupes de Commodités — Ils permettent de classer les articles, outils ou services pour analyser les dépenses par type de produit.
- Règles d'Héritage — Les modifications de statut d'un article maître sont appliquées à l'organisation et à l'inventaire via des règles d'héritage.
📐 Architecture des Item Sets et des Articles Maîtres
L'architecture d'IBM Maximo Manage repose sur une structuration hiérarchique des données pour garantir l'efficacité et la cohérence. Au cœur de cette structure se trouvent les Item Sets, qui agissent comme des conteneurs logiques pour les informations relatives aux articles. Ces sets sont fondamentaux pour la gestion centralisée des matériaux, des pièces et des services à travers une entreprise.
Les enregistrements d'articles maîtres, créés dans l'application Item Master, sont stockés au niveau de l'Item Set. Cela signifie qu'un article défini dans un Item Set est unique au sein de ce set, mais peut être référencé et utilisé par plusieurs organisations et sites associés à ce set. Cette approche facilite le partage et la standardisation des articles à l'échelle de l'entreprise, tout en permettant une gestion locale des inventaires.
Item Master gère les enregistrements au sein des Item Sets, qui sont ensuite partagés entre les organisations et leurs sites respectifs.📊 Comparaison des types d'articles gérés
IBM Maximo Manage permet de gérer une grande variété d'articles, chacun ayant des caractéristiques et des usages spécifiques. Comprendre les distinctions entre ces types est crucial pour une gestion d'inventaire et d'actifs efficace. Le tableau ci-dessous met en évidence les principales catégories d'articles gérées par le système.
Cette classification aide à organiser les données, à optimiser les processus d'approvisionnement et à assurer la disponibilité des ressources nécessaires aux opérations de maintenance et de service.
| Type d'Article | Description | Exemples d'Utilisation | Applications Clés |
|---|---|---|---|
Materials | Composants et consommables utilisés pour la maintenance ou la production. | Pièces de rechange, lubrifiants, fournitures de bureau. | Item Master, Inventory, Receiving |
Spare Parts | Articles spécifiquement destinés à remplacer des composants défectueux d'actifs. | Moteurs, pompes, cartes électroniques. | Item Master, Inventory, Assets |
Service Items | Services externes ou internes qui peuvent être commandés et suivis. | Services de réparation, étalonnage, consultation technique. | Item Master, Purchasing, Service Requests |
Tools | Équipements et instruments utilisés pour effectuer des tâches. | Clés dynamométriques, appareils de mesure, équipements de sécurité. | Item Master, Stocked Tools, Work Order Tracking |
Assets | Équipements physiques ou virtuels qui ont une valeur et nécessitent une gestion. | Véhicules, machines de production, serveurs. | Assets, Item Master (pour les pièces d'assemblage) |
⚙️ Gestion Opérationnelle des Articles Maîtres
La gestion opérationnelle des articles maîtres dans IBM Maximo Manage est un processus structuré qui garantit la cohérence et l'efficacité de l'inventaire et des actifs. Elle commence par la création de l'enregistrement dans l'application Item Master, où des propriétés essentielles sont définies, telles que l'identifiant unique et les attributs spécifiques à l'article.
Une fois l'article maître créé, il peut être associé à des Item Sets, puis ajouté à l'inventaire de divers sites et organisations. Cette flexibilité permet une gestion centralisée tout en supportant des opérations décentralisées. Par exemple, un moteur spécifique peut être défini une seule fois comme article maître, puis être disponible dans l'inventaire de plusieurs sites de production à travers une entreprise.
- Création d'un Article Maître — Dans l'application
Item Master, un nouvel enregistrement est créé. Il faut spécifier un identifiant unique, une description, et d'autres propriétés comme l'unité de mesure (UoM) et le type d'article. - Association à un Item Set — L'article maître est automatiquement associé à l'Item Set de l'organisation par défaut pour les nouveaux enregistrements. Cette association est cruciale pour le partage des données.
- Définition des Propriétés — Des propriétés détaillées peuvent être ajoutées, y compris des spécifications techniques, des informations sur les fournisseurs (
Vendor), et des classifications par groupes de commodités (COMMODITYGROUP). - Ajout à l'Inventaire des Sites — L'article maître peut ensuite être ajouté à l'inventaire de plusieurs sites via l'application
Inventory. Cela permet aux différents sites de commander et d'utiliser l'article. - Gestion des Statuts — Le statut de l'article maître (ex:
ACTIVE,OBSOLETE) est géré de manière centralisée. Les changements de statut se propagent aux enregistrements d'inventaire et d'organisation associés selon des règles d'héritage. - Application des Structures d'Assemblage — Pour les articles complexes, des structures d'assemblage peuvent être définies et appliquées aux actifs ou aux emplacements. Par exemple, un moteur de cinq chevaux peut avoir une structure d'assemblage qui liste ses composants internes.
🔄 Cycle de Vie d'un Article Maître
Le cycle de vie d'un article maître dans Maximo Manage est un processus dynamique qui reflète son utilisation et sa gestion tout au long de son existence. Il commence par sa création et passe par différentes étapes de statut, d'utilisation et de maintenance, jusqu'à son éventuelle obsolescence. Ce cycle est essentiel pour maintenir un inventaire précis et optimiser la disponibilité des ressources.
Les statuts des articles maîtres sont gérés avec des règles d'héritage, ce qui signifie qu'un changement de statut au niveau de l'article maître peut affecter les enregistrements d'inventaire et d'organisation associés. Cette propagation assure la cohérence des données à travers le système, évitant les incohérences entre la définition de l'article et son état réel dans les différents sites.
⚠️ Pièges IBM
Les candidats peuvent sous-estimer l'importance des Item Sets. Un piège courant est de penser que tous les articles sont automatiquement disponibles pour toutes les organisations. En réalité, un enregistrement d'article maître fait partie de l'Item Set de l'organisation à laquelle appartient le site par défaut pour les nouveaux enregistrements. Si les organisations ne partagent pas le même Item Set ou si l'article n'est pas explicitement ajouté à l'inventaire des sites concernés, il ne sera pas disponible pour toutes les entités. Il est crucial de comprendre que l'Item Set est le niveau de partage des définitions d'articles, tandis que l'inventaire est géré au niveau du site.
Un autre piège concerne la gestion des statuts des articles maîtres. Les candidats pourraient oublier que les changements de statut d'un article maître ne sont pas isolés. Selon les règles d'héritage de Maximo, une modification du statut d'un article maître (par exemple, le passage de ACTIVE à OBSOLETE) est appliquée à l'organisation et à l'inventaire. Ne pas anticiper cette propagation peut entraîner des erreurs dans les processus d'approvisionnement ou de maintenance, comme la commande d'articles obsolètes ou l'indisponibilité inattendue d'un article pourtant considéré comme actif localement.
Les candidats peuvent confondre les structures d'assemblage d'articles avec les structures d'actifs. Bien que liées, les structures d'assemblage d'articles sont définies au niveau de l'article maître et décrivent les composants d'un article. Elles peuvent ensuite être copiées et appliquées aux structures d'actifs ou d'emplacements. Le piège est de croire qu'une modification de la structure d'assemblage d'un article maître mettra automatiquement à jour toutes les structures d'actifs ou d'emplacements existantes. En réalité, il s'agit d'une copie initiale, et les modifications ultérieures nécessitent une re-application ou une gestion spécifique pour les actifs ou emplacements déjà configurés.
🎯 Carte mémoire
Quel est le rôle principal des Item Sets dans IBM Maximo Manage et comment influencent-ils le partage des articles ?
Les Item Sets regroupent les informations sur les actifs, matériaux, pièces de rechange, articles de service et outils. Ils sont stockés au niveau du set et permettent de définir un article maître une seule fois, puis de le rendre disponible pour plusieurs organisations et sites associés à ce set, facilitant ainsi la standardisation et le partage des données d'articles.
Comment les changements de statut d'un article maître sont-ils gérés et propagés dans Maximo Manage ?
Les statuts des articles maîtres sont gérés dans l'application Item Master. Lorsqu'un statut est modifié, des règles d'héritage sont utilisées pour appliquer ces changements du niveau supérieur (article maître) aux niveaux inférieurs (organisation et inventaire). Cela assure la cohérence des informations sur l'état de l'article à travers le système.
Quelle est l'utilité des groupes de commodités (COMMODITYGROUP) et des codes de commodités pour les articles maîtres ?
Les groupes de commodités et les codes de commodités sont utilisés pour classer les articles, outils ou services. Cette classification permet d'analyser les dépenses par type de produit, d'optimiser les processus d'approvisionnement et de mieux gérer les contrats et les relations avec les fournisseurs en regroupant des éléments similaires.
Dans quelles applications peut-on appliquer les structures d'assemblage d'articles et quel est leur avantage ?
Les structures d'assemblage d'articles peuvent être appliquées aux enregistrements d'actifs et d'emplacements. Leur avantage est de permettre de copier une structure de composants définie pour un article maître (par exemple, un moteur) vers de multiples actifs ou emplacements, simplifiant ainsi la gestion des pièces de rechange et des sous-assemblages sans avoir à les définir manuellement pour chaque instance.
Bonne réponse : D
Pourquoi cette question existe — STU §4.4 — la question teste la compréhension de l'impact du flag Rotating? sur un Item Master record. Les distracteurs montrent les erreurs typiques : exclusion du réapprovisionnement (D4), restriction d'émission (D2), héritage de garantie (D3). En pratique terrain, la sérialisation et la création d'Asset sont des comportements clés pour les items rotatifs.
Le contexte théorique d'abord — Le flag Rotating? sur un Item Master record indique que l'item est un équipement rotatif, souvent utilisé dans des processus industriels. Ce flag déclenche plusieurs comportements spécifiques, notamment la sérialisation obligatoire et la création d'un enregistrement d'actif lors de la réception. Les items rotatifs sont gérés différemment des items non rotatifs en termes de suivi et de maintenance.
Ce que Maximo en fait — version opérationnelle — Application Item Master > Sélectionner un item > Cocher Rotating? > Enregistrer. Lors de la réception via l'application Receiving, chaque unité reçue est sérialisée et un enregistrement d'actif est créé automatiquement si la configuration le permet. L'Asset est ensuite disponible dans l'application Asset pour suivi et maintenance.
Exemple chiffré — Un site industriel reçoit 120 unités d'un item rotatif avec un coût unitaire de 150€. Chaque unité est sérialisée et 120 enregistrements d'actifs sont créés, représentant un investissement total de 18 000€. Ces actifs sont ensuite suivis pour maintenance préventive avec un MTBF de 500 heures.
Analogie quotidienne — C'est comme acheter une flotte de voitures : chaque véhicule reçu est immatriculé (sérialisé) et enregistré dans un système de gestion de parc automobile (Asset record) pour suivi et entretien.
Pourquoi A est faux — Pattern D4 demi-vérité : les items rotatifs ne sont pas exclus du réapprovisionnement, mais leur gestion est différente.
Pourquoi B est faux — Pattern D2 inventé : il n'existe pas de restriction d'émission spécifique aux items rotatifs via Desktop Requisitions.
Pourquoi C est faux — Pattern D3 inverse : les items rotatifs n'héritent pas automatiquement des termes de garantie du dernier contrat d'achat.
- Rotating? — flag indiquant qu'un item est un équipement rotatif.
- Sérialisation — attribution d'un numéro de série unique à chaque unité reçue.
- Asset record — enregistrement d'actif créé pour chaque unité sérialisée.
- Receiving — application Maximo pour la réception d'items.
- MTBF — Mean Time Between Failures, indicateur de fiabilité.
- Le flag
Rotating?déclenche sérialisation et création d'Asset. - Les items rotatifs sont gérés différemment des non rotatifs.
- La création d'Asset dépend de la configuration du workflow.
- STU sub-objective §4.4 — Gestion des Item Master records
- [EOTRAG] Query — « Maximo Rotating flag impact on Item Master » (confidence 0.76)
- master-map.pdf p.741-743 — IBM Docs Lease and rental contracts overview
Bonne réponse : A
Pourquoi cette question existe — STU §4.4 — cette question vérifie la compréhension fondamentale d'une Item Assembly Structure (IAS) comme structure hiérarchique de type BOM. Les distracteurs ciblent les confusions courantes avec les tâches cron (D2), les concepts hérités (D1) et les mécanismes de sécurité (D7). En pratique terrain, la distinction entre IAS et Item Kit est cruciale pour la gestion des pièces détachées.
Le contexte théorique d'abord — Une Item Assembly Structure est une hiérarchie parent-enfant qui définit les relations entre items dans Maximo. Elle s'applique principalement aux rotating items et permet de modéliser des structures complexes avec plusieurs niveaux. Contrairement aux Item Kits, une IAS préserve l'identité individuelle des items enfants.
Ce que Maximo en fait — version opérationnelle — Dans l'application Item Master, sélectionnez un item parent > onglet Assembly Structure > ajoutez des items enfants avec leurs quantités respectives. La structure peut ensuite être appliquée à un asset via l'application Assets pour gérer les pièces détachées.
Exemple chiffré — Une pompe (item parent) peut avoir 3 niveaux : 1 moteur principal (niveau 1), 5 roulements (niveau 2), et 12 joints d'étanchéité (niveau 3). La structure totale contient 18 items avec des quantités variables par niveau.
Analogie quotidienne — C'est comme un meuble en kit IKEA : le manuel (IAS) liste toutes les pièces nécessaires (vis, panneaux, poignées) et leur relation hiérarchique pour assembler l'armoire finale.
Pourquoi B est faux — Pattern D2 Inventé : Aucune tâche cron dans Maximo ne porte ce nom ou cette fonction.
Pourquoi C est faux — Pattern D1 Hérité : Item Kit et IAS sont des concepts distincts dans toutes les versions récentes de Maximo.
Pourquoi D est faux — Pattern D7 Inexistant : Les règles de sécurité par storeroom se gèrent via d'autres mécanismes, pas via les IAS.
- Rotating item — Item sérialisé partageant des propriétés d'asset et d'inventaire.
- Item Kit — Collection d'items émis comme unité unique (différent d'IAS).
- Spare Parts tab — Onglet affichant les pièces détachées associées à un asset.
- Hierarchical BOM — Structure parent-enfant multi-niveaux.
- Non-rotating items — Pièces standards sans sérialisation individuelle.
- IAS = structure hiérarchique parent-enfant de type BOM.
- S'applique principalement aux rotating items et assets.
- Distincte des Item Kits (collections émises en bloc).
- STU sub-objective §4.4 — Item Assembly Structures
- [EOTRAG] Query — « Maximo Item Assembly Structure definition rotating items » (confidence 0.98)
- master-map.pdf p.672-673 — IBM Docs Applying Item Assembly Structures
Bonne réponse : B
Pourquoi cette question existe — STU §4.4 — la question teste la compréhension fondamentale d'un Item Kit, un concept clé dans la gestion des inventaires. Les distracteurs montrent les erreurs typiques : confondre avec des catalogues de fournisseurs (D6), des hiérarchies d'items rotatifs (D2), ou des réservations virtuelles (D7). En pratique terrain, l'utilisation incorrecte des Item Kits peut entraîner des erreurs dans les émissions de stocks.
Le contexte théorique d'abord — Un Item Kit est une collection d'items pré-assemblés qui sont émis ensemble comme une unité unique. Ces kits sont utilisés pour simplifier les processus d'émission et de gestion des stocks. Les items individuels du kit sont définis dans l'application Item Master et peuvent être associés à plusieurs kits différents.
Ce que Maximo en fait — version opérationnelle — Application Item Master > Add New Item > Item ID = KIT001, puis Add Row : Item Type = Kit, puis Add Components : Item 1 = SCREW-5MM, Item 2 = NUT-5MM, Item 3 = WASHER-5MM. Enregistrer et configurer pour l'émission dans Inventory.
Exemple chiffré — Kit KIT001 : composé de 10 vis SCREW-5MM, 10 écrous NUT-5MM, et 10 rondelles WASHER-5MM. Lors de l'émission, le kit est compté comme une seule unité, mais les stocks individuels sont déduits de 10 unités chacun.
Analogie quotidienne — C'est comme un kit de réparation de vélo : tu achètes une boîte contenant une clé, un démonte-pneu et une pompe, plutôt que d'acheter chaque outil séparément.
Pourquoi A est faux — Pattern D6 mauvaise-app : les catalogues de fournisseurs sont gérés dans les applications Purchase Requisitions et Request for Quotations, pas dans les Item Kits.
Pourquoi C est faux — Pattern D2 inventé : les items rotatifs ne partagent pas de numéro de série unique et ne sont pas organisés en hiérarchies.
Pourquoi D est faux — Pattern D7 inexistant : les réservations virtuelles ne sont pas une fonctionnalité reconnue dans Maximo Manage.
- Item Kit — collection d'items émis ensemble comme une unité unique.
- Item Master — application pour créer et gérer les items.
- Inventory — application pour gérer les stocks et les émissions.
- Rotating Item — item maintenu comme un actif, non consommable.
- Consignment Item — item payé uniquement lorsqu'il est consommé.
- Item Kit = collection d'items émis ensemble.
- Configuré dans
Item Master. - Émis via
Inventory.
- STU sub-objective §4.4 — Créer et gérer les Item Master records
- [EOTRAG] Query — « Maximo Item Kit definition and usage » (confidence 0.98)
- master-map.pdf p.112-115 — IBM Docs Item Master

Configurer les Inventory Settings et processus
📋 Objectifs IBM
- Comprendre l'importance de la gestion des stocks dans Maximo Manage.
- Identifier les applications clés du module Inventory pour la configuration et la gestion.
- Décrire les processus de réapprovisionnement et de mouvement des stocks.
- Expliquer comment les paramètres d'inventaire influencent les opérations quotidiennes.
- Distinguer les différents types de transactions d'inventaire et leur impact.
- Appliquer les concepts de configuration pour optimiser les niveaux de stock et réduire les coûts.
💡 Points clés
- Module Inventory — Maximo Manage offre un module dédié à la gestion des pièces de rechange, visant à maximiser la disponibilité des articles tout en réduisant les excédents et les coûts associés.
- Équilibre des stocks — L'objectif principal est de trouver un équilibre optimal pour que la maintenance puisse être effectuée sans délai dû à l'indisponibilité des matériaux, sans pour autant conserver des articles rarement utilisés en stock.
- `MXINVENTORY` Object Structure — Cette structure d'objet permet la synchronisation bidirectionnelle des données d'inventaire (article-magasin), incluant les coûts d'inventaire, facilitant l'intégration avec d'autres systèmes.
- Processus internes d'entrepôt — Maximo supporte des processus tels que le réapprovisionnement (`Replenishment`), le mouvement ad hoc des stocks (`Ad Hoc Warehouse Movement`), la consolidation des stocks (`Stock Consolidation`) et les changements de statut de stock (`Posting Change`).
- Configuration des sites — Les options de configuration au niveau du site peuvent influencer des aspects comme la numérotation des tâches ou la gestion des dates de début réelles pour les ordres de travail, impactant indirectement la planification des besoins en inventaire.
- `Item Master` et `Inventory` — La gestion des articles commence dans l'application `Item Master` où les articles sont définis, puis gérés dans `Inventory` pour les aspects liés aux quantités, aux emplacements de stockage et aux coûts.
- `Storerooms` — Les magasins (`Storerooms`) sont des entités physiques ou logiques où les articles sont stockés, et leur configuration est cruciale pour une gestion efficace des stocks.
- Transactions d'inventaire — Maximo enregistre diverses transactions d'inventaire via des tables comme `MATRECTRANS` (réception de matériel) et `MATUSETRANS` (utilisation de matériel), essentielles pour le suivi des mouvements et des coûts.
📐 Architecture de la gestion des stocks dans Maximo
La gestion des stocks dans Maximo Manage est une composante essentielle de la gestion des actifs d'entreprise (EAM). Elle vise à optimiser la disponibilité des pièces de rechange nécessaires aux opérations de maintenance, tout en contrôlant les coûts liés à l'excès de stock. Cette architecture repose sur une interconnexion étroite entre les données des articles, des magasins, des emplacements et des transactions.
Le module `Inventory` est central, regroupant plusieurs applications qui permettent de définir, suivre et ajuster les niveaux de stock. L'intégration avec d'autres modules comme `Purchasing` et `Work Order Tracking` est fondamentale pour assurer un flux continu de matériaux, de la commande à l'utilisation, et pour garantir que les pièces sont disponibles au moment opportun pour les interventions planifiées ou imprévues.
📊 Comparaison des types de réapprovisionnement
Le réapprovisionnement est un processus clé dans la gestion des stocks pour maintenir des niveaux adéquats et éviter les ruptures. Maximo Manage, à travers ses capacités de configuration, supporte divers mécanismes de réapprovisionnement, chacun adapté à des scénarios spécifiques. Comprendre ces distinctions est crucial pour optimiser la chaîne d'approvisionnement et réduire les coûts de possession.
Bien que les chunks RAG proviennent en partie d'un contexte SAP, les concepts de réapprovisionnement sont universels en gestion d'entrepôt et se retrouvent dans Maximo sous des formes similaires, adaptées à son modèle de données et à ses applications. L'objectif est toujours de garantir la disponibilité des articles au bon moment, au bon endroit et au coût optimal.
| Type de Réapprovisionnement | Description | Déclencheur typique dans Maximo | Impact sur les stocks |
|---|---|---|---|
| Planifié (`Planned Replenishment`) | Basé sur des prévisions de consommation ou des seuils définis, souvent automatisé. | Seuils de réapprovisionnement (`Reorder Point`), prévisions de demande. | Maintien de niveaux de stock stables, réduction des ruptures. |
| Lié à une commande (`Order-Related Replenishment`) | Déclenché par une demande spécifique, comme un ordre de travail ou une commande client. | Création d'un `Purchase Requisition` ou `Purchase Order` pour un `WORKORDER`. | Réponse directe à un besoin immédiat, minimisation du stock excédentaire. |
| Direct (`Direct Replenishment`) | Réapprovisionnement immédiat d'un emplacement de stockage spécifique, souvent pour des articles à forte rotation. | Détection d'un niveau de stock bas dans un `Storeroom` ou un `Bin`. | Assure la disponibilité continue des articles critiques, réduit les délais. |
| Automatique (`Automatic Replenishment`) | Processus entièrement automatisé basé sur des règles prédéfinies et des analyses de données. | `Cron Task` analysant les niveaux de stock et générant des `Purchase Requisitions`. | Optimisation des niveaux de stock, réduction des interventions manuelles. |
| Ad Hoc (`Ad Hoc Warehouse Movement`) | Mouvement de stock non planifié, souvent pour corriger des déséquilibres ou consolider des emplacements. | Besoin ponctuel de déplacer des articles entre `Storerooms` ou `Bins`. | Flexibilité opérationnelle, ajustement rapide aux conditions changeantes. |
⚙️ Configuration des Inventory Settings et processus
La configuration des paramètres d'inventaire dans Maximo Manage est une étape cruciale pour garantir l'efficacité des opérations de maintenance et la maîtrise des coûts. Elle implique la définition de règles et de comportements qui régissent la manière dont les articles sont gérés, stockés et consommés. Ces paramètres sont souvent définis au niveau de l'organisation ou du site, permettant une granularité adaptée aux besoins spécifiques de chaque entité opérationnelle.
Le module `Inventory` offre une suite d'applications pour gérer ces configurations. Par exemple, l'application `Inventory` permet de définir les seuils de réapprovisionnement (`Reorder Point`), les quantités de commande économique (`EOQ`), et les méthodes de valorisation des stocks. Les `Storerooms` sont configurés pour définir les emplacements physiques de stockage, tandis que `Item Master` gère les attributs fondamentaux de chaque article.
Un aspect important est la gestion des transactions d'inventaire. Chaque mouvement d'article, qu'il s'agisse d'une réception, d'une sortie pour un ordre de travail, d'un transfert ou d'un ajustement, est enregistré. Ces transactions alimentent les soldes d'inventaire et les calculs de coûts, fournissant une visibilité essentielle sur la valeur et la quantité des stocks disponibles.
- Définition des articles dans `Item Master` — Chaque article doit être défini avec ses propriétés essentielles, telles que l'`ITEMNUM`, l'`UoM` (unité de mesure), le type d'article (`ITEMTYPE`), et s'il s'agit d'un article tournant (`Rotating?`).
- Configuration des `Storerooms` — Création et gestion des magasins physiques ou logiques où les articles sont stockés. Chaque `Storeroom` a ses propres paramètres, y compris les comptes GL associés et les règles de réapprovisionnement.
- Paramètres d'inventaire par article et par magasin — Dans l'application `Inventory`, pour chaque combinaison article-magasin, des paramètres spécifiques peuvent être définis, tels que le `Reorder Point`, la quantité maximale en stock, le fournisseur préféré, et les coûts associés (`INVCOST`).
- Gestion des transactions d'inventaire — Utilisation des applications comme `Issues and Returns` pour enregistrer les sorties et retours d'articles, `Receiving` pour les réceptions de commandes, et `Adjust Balances` pour les ajustements de stock. Ces actions mettent à jour les tables `MATUSETRANS` et `MATRECTRANS`.
- Processus de réapprovisionnement — Configuration des règles pour le réapprovisionnement automatique ou manuel. Cela peut impliquer la génération de `Purchase Requisitions` basées sur les seuils de stock ou les prévisions de demande.
- Inventaire physique et comptage cyclique — Mise en place de processus pour vérifier physiquement les stocks. Les applications `Physical Counts` et `Cycle Counts` permettent de planifier et d'enregistrer ces vérifications, puis d'ajuster les soldes (`INVBALANCES`) si nécessaire.
- Intégration des coûts — Les coûts des articles sont suivis et mis à jour lors des réceptions et des ajustements. Ces informations sont cruciales pour la valorisation des stocks et l'analyse des coûts de maintenance.
🔄 Cycle de vie d'un article en stock
Le cycle de vie d'un article en stock dans Maximo Manage illustre le parcours d'une pièce de rechange, de sa définition initiale à sa consommation finale. Ce processus est jalonné de plusieurs étapes clés, impliquant différentes applications et transactions, toutes conçues pour assurer une gestion efficace et un suivi précis des ressources matérielles. Chaque transition d'état représente une action ou un événement qui impacte la disponibilité et la valeur de l'inventaire.
Ce cycle de vie est dynamique et peut varier en fonction du type d'article, de sa criticité et des politiques de l'entreprise. L'objectif est de maintenir une visibilité complète sur l'état de chaque article, de la commande à l'utilisation, en passant par le stockage et les ajustements. La bonne gestion de ce cycle est fondamentale pour la performance opérationnelle et financière.
⚠️ Pièges IBM
Les étudiants confondent souvent les rôles des applications `Item Master` et `Inventory`. `Item Master` est l'endroit où les articles sont définis de manière générique, avec leurs attributs de base (description, unité de mesure, classification). C'est la "carte d'identité" de l'article. L'application `Inventory` gère les détails spécifiques de cet article dans un `Storeroom` donné, y compris les quantités en stock, les coûts, les seuils de réapprovisionnement et les emplacements physiques. Un article peut exister dans `Item Master` sans être en stock dans un `Storeroom`.
Il est facile de sous-estimer l'impact des différentes transactions d'inventaire sur les coûts. Chaque réception (`Receiving`), sortie (`Issues and Returns`), transfert (`Transfers`) ou ajustement (`Adjust Balances`) peut modifier la valeur moyenne ou le coût standard d'un article en stock, selon la méthode de valorisation configurée. Une mauvaise compréhension de ces mécanismes peut entraîner des erreurs significatives dans les rapports financiers et les analyses de coûts de maintenance. Par exemple, une réception avec un prix unitaire incorrect peut fausser la valeur de l'`INVBALANCES` pour cet article.
Dans un environnement Maximo complexe avec plusieurs sites (`SITEID`) et organisations (`ORGID`), il est crucial de comprendre comment les paramètres d'inventaire et les articles sont partagés ou isolés. Un article peut être défini au niveau de l'organisation et être disponible pour tous les sites de cette organisation, ou être spécifique à un site. Les transferts d'inventaire entre sites ou organisations nécessitent une configuration appropriée et peuvent avoir des implications sur les coûts et la fiscalité. Ne pas prendre en compte ces distinctions peut entraîner des incohérences de données et des difficultés opérationnelles.
🎯 Carte mémoire
Quelle est la distinction fondamentale entre l'application `Item Master` et l'application `Inventory` dans Maximo Manage ?
L'application `Item Master` est utilisée pour définir les propriétés génériques d'un article, telles que sa description, son unité de mesure et sa classification, servant de référence unique. L'application `Inventory` gère les détails spécifiques de cet article au sein d'un `Storeroom` particulier, incluant les quantités en stock, les coûts, les seuils de réapprovisionnement et les emplacements physiques.
Quel est l'objectif principal du module `Inventory` dans Maximo Manage et comment y parvient-il ?
L'objectif principal est de maximiser la disponibilité des pièces de rechange nécessaires aux opérations de maintenance tout en réduisant les excédents de stock et les coûts associés. Il y parvient en offrant des outils pour la définition des articles, la gestion des `Storerooms`, le suivi des transactions, la configuration des seuils de réapprovisionnement et l'exécution d'inventaires physiques et cycliques.
Quelles sont les principales tables de base de données impactées par les transactions d'inventaire et à quoi servent-elles ?
Les tables principales sont `MATRECTRANS` pour les réceptions de matériel, `MATUSETRANS` pour l'utilisation de matériel, et `INVBALANCES` qui maintient les soldes actuels des articles dans les `Storerooms`. `INVCOST` contient les informations de coût pour chaque article en inventaire. Ces tables permettent un suivi détaillé des mouvements et de la valorisation des stocks.
Comment Maximo Manage gère-t-il le réapprovisionnement des stocks pour éviter les ruptures ?
Maximo gère le réapprovisionnement via plusieurs mécanismes, notamment les seuils de réapprovisionnement (`Reorder Point`) configurés par article et par `Storeroom`. Lorsque le stock disponible tombe en dessous de ce seuil, le système peut générer automatiquement des `Purchase Requisitions` ou des alertes, déclenchant des processus de réapprovisionnement planifié, lié à une commande ou automatique.
Bonne réponse : A
Pourquoi cette question existe — STU §4.5 — cette question vérifie la compréhension du mécanisme de verrouillage des réapprovisionnements pour éviter les doublons de commandes. Les erreurs courantes incluent la confusion avec le verrouillage des coûts (D5) ou la fermeture des magasins (D7). En pratique, l'absence de ce verrou peut générer des PR/PO en double lors d'exécutions concurrentes de cron tasks ou d'actions utilisateur parallèles.
Le contexte théorique d'abord — Le Reorder Lock est un mécanisme de synchronisation qui empêche l'exécution simultanée du processus de réapprovisionnement pour un même magasin. Il agit comme un mutex au niveau applicatif, garantissant qu'une seule instance (utilisateur ou tâche cron) peut générer des demandes d'achat à un instant donné.
Ce que Maximo en fait — version opérationnelle — Dans l'application Inventory > Reorder, le système vérifie d'abord l'état du verrou via le champ REORDERLOCK associé au STOREROOMS. Si libre, il acquiert le verrou, traite les items sous ROP, génère les PR/PO nécessaires, puis libère le verrou. Ce processus est atomique et journalisé.
Exemple chiffré — Storeroom CENTRAL : 142 items sous ROP, 3 utilisateurs tentent un reorder simultané. Seul le 1er acquiert le verrou et génère 12 PR. Les 2 autres voient un message "Reorder in progress" jusqu'au déverrouillage après 47 secondes.
Analogie quotidienne — Comme un feu tricolore devant un pont à voie unique : un seul véhicule (processus reorder) peut traverser à la fois, les autres attendent leur tour pour éviter les collisions (doublons de commandes).
Pourquoi B est faux — Le verrouillage des coûts LIFO/FIFO se gère via d'autres mécanismes comme INVCOST et non le Reorder Lock. (Pattern D5 Champ-frère).
Pourquoi C est faux — Le ROP n'est pas gelé par ce setting ; son recalcul dépend des paramètres MRP et des historiques de consommation. (Pattern D4 Demi-vérité).
Pourquoi D est faux — La fermeture des magasins se contrôle via STOREROOMS.STATUS, sans lien avec le Reorder Lock. (Pattern D7 Inexistant).
- Reorder Point (ROP) — seuil déclenchant une commande.
- Economic Order Quantity (EOQ) — quantité optimale à commander.
- Lead Time — délai entre commande et réception.
- Safety Stock — stock tampon contre les aléas.
- PENDOBS status — statut bloquant les réapprovisionnements.
- Reorder Lock = mutex pour éviter les doublons de PR/PO.
- Verrou applicatif, pas lié aux coûts ou statuts magasin.
- Critique pour les cron tasks concurrentes et multi-utilisateurs.
- STU sub-objective §4.5 — Inventory Reorder Process and Locking
- [EOTRAG] Query — « Maximo Reorder Lock mechanism storeroom concurrent processing » (confidence 0.91)
- master-map.pdf p.203-205 — IBM Docs Inventory Replenishment
Bonne réponse : B
Pourquoi cette question existe — STU §4.5 — cette question teste la connaissance des types de réservation disponibles dans Maximo Inventory. Les distracteurs montrent des erreurs typiques : inventer des types de réservation (D2), confondre avec des statuts de processus (D5), ou utiliser des termes proches mais incorrects (D9). En pratique terrain, comprendre ces types est crucial pour gérer efficacement les stocks et les réservations.
Le contexte théorique d'abord — Les réservations dans Maximo Inventory sont utilisées pour garantir la disponibilité des articles. Il existe trois types principaux : HARD (prioritaire, ne peut être supplantée), SOFT (disponible à tout moment sans contrainte de temps), et AUTOMATIC (déterminée automatiquement en fonction de la date de besoin). Ces types sont configurables dans les processus de réapprovisionnement et d'émission des stocks.
Ce que Maximo en fait — version opérationnelle — Dans l'application Inventory, un utilisateur peut créer une réservation via l'option Reservations. Il choisit le type de réservation (HARD, SOFT, ou AUTOMATIC) en fonction des besoins. Pour les réservations automatiques, Maximo utilise des règles prédéfinies pour déterminer le type en fonction de la date de besoin. Ces paramètres sont configurables dans les propriétés système et les workflows associés.
Exemple chiffré — Un site avec 150 articles en stock : 50 réservations HARD pour des travaux urgents, 70 réservations SOFT pour des besoins flexibles, et 30 réservations AUTOMATIC déterminées par le système en fonction des dates de besoin prévues.
Analogie quotidienne — C'est comme réserver une table dans un restaurant : une réservation HARD est comme une table réservée à une heure précise, une SOFT est comme une table disponible à tout moment, et une AUTOMATIC est comme une table réservée en fonction des prévisions de fréquentation.
Pourquoi A est faux — Pattern D2 Inventé : FIXED, FLOATING, et DEFERRED ne sont pas des types de réservation reconnus dans Maximo.
Pourquoi C est faux — Pattern D5 Champ-frère : STAGED, SHIPPED, et COMPLETED sont des statuts de processus, pas des types de réservation.
Pourquoi D est faux — Pattern D9 Quasi-synonyme : PRIMARY, SECONDARY, et OPTIONAL sont des termes proches mais ne correspondent pas aux types de réservation dans Maximo.
- HARD — réservation prioritaire, ne peut être supplantée.
- SOFT — réservation flexible, disponible à tout moment.
- AUTOMATIC — réservation déterminée automatiquement par le système.
- Reservations — processus pour garantir la disponibilité des articles.
- Inventory — application gérant les stocks et les réservations.
- HARD = prioritaire, SOFT = flexible, AUTOMATIC = déterminé par le système.
- Les réservations garantissent la disponibilité des articles.
- Configurable dans les processus de réapprovisionnement et d'émission.
- STU sub-objective §4.5 — Configurer les Inventory Settings et processus
- [EOTRAG] Query — « Maximo Inventory reservation types HARD SOFT AUTOMATIC » (confidence 0.98)
- master-map.pdf p.210-213 — IBM Docs Inventory Reservations
Bonne réponse : A,B,D
Pourquoi cette question existe — STU §4.5 — cette question vérifie la connaissance des méthodes de valorisation des stocks supportées nativement par Maximo. Les erreurs courantes incluent la confusion avec des méthodes comptables génériques (D4) ou l'invention de méthodes non documentées (D2). En pratique terrain, le choix de la méthode affecte directement la valorisation des transactions et le calcul des coûts.
Le contexte théorique d'abord — Maximo gère plusieurs méthodes de valorisation des stocks via les tables MATRECTRANS et MATUSETRANS, avec impact sur INVBALANCES. Les méthodes natives documentées sont : FIFO (premier entré, premier sorti), LIFO (dernier entré, premier sorti) et AVERAGE (moyenne pondérée). Chaque méthode influence différemment le coût des sorties de stock.
Ce que Maximo en fait — version opérationnelle — La configuration se fait au niveau système via les propriétés globales ou au niveau des transactions. Les méthodes sont appliquées automatiquement lors des mouvements de stock (réceptions, transferts, issues) pour calculer les coûts dans INVCOST. Aucune interface spécifique "Costing Method" n'est documentée dans les apps standard.
Exemple chiffré — Stock initial : 100 unités à 10€. Réception 1 : 50 unités à 12€. Réception 2 : 30 unités à 15€. Sortie de 120 unités : FIFO = 1300€, LIFO = 1460€, AVERAGE = 1380€ (coût moyen 11.50€).
Analogie quotidienne — Comme une pile d'assiettes : FIFO = on prend toujours celle du dessous (la plus ancienne), LIFO = on prend celle du dessus (la plus récente), AVERAGE = on calcule un prix moyen par assiette quelle que soit leur position.
Pourquoi C est faux — "Weighted Periodic" est une méthode comptable générique mais non documentée comme méthode native dans Maximo. (Pattern D4 Demi-vérité)
Pourquoi E est faux — "MARGINAL" n'est pas une méthode de valorisation des stocks reconnue dans la documentation Maximo. (Pattern D2 Inventé)
Pourquoi F est faux — "EXPONENTIAL" est un terme mathématique sans rapport avec les méthodes de valorisation des stocks dans Maximo. (Pattern D7 Inexistant)
- FIFO — Premier entré, premier sorti : valorise les sorties au plus ancien coût.
- LIFO — Dernier entré, premier sorti : valorise les sorties au plus récent coût.
- AVERAGE — Moyenne pondérée : calcule un coût moyen unitaire.
- MATRECTRANS — Table des transactions de réception de matériel.
- INVBALANCES — Table des soldes et valorisations de stock.
- Maximo supporte FIFO, LIFO et AVERAGE pour la valorisation des stocks.
- Les méthodes affectent le calcul des coûts dans INVCOST.
- Pas d'interface dédiée "Costing Method" documentée.
- STU sub-objective §4.5 — Inventory valuation methods
- [EOTRAG] Query — « Maximo inventory cost methods FIFO LIFO AVERAGE » (confidence 0.98)
- master-map.pdf p.1715-1717 — IBM Docs Inventory Transactions
Bonne réponse : D
Pourquoi cette question existe — STU §4.5 — cette question teste la compréhension des niveaux de configuration des options d'inventaire dans Maximo Manage, en particulier les paramètres Negative Balance et Count Books. Les distracteurs montrent les erreurs typiques : confondre le niveau de configuration (site, item, système) et ignorer le niveau organisationnel. En pratique terrain, cette configuration est cruciale pour gérer les inventaires multi-organisations.
Le contexte théorique d'abord — Les options d'inventaire comme Negative Balance et Count Books sont configurées au niveau organisationnel dans Maximo Manage. Cela permet de définir des règles spécifiques pour chaque organisation, indépendamment des sites ou des items individuels. Ces paramètres sont gérés dans l'application Organizations sous l'onglet Inventory Options.
Ce que Maximo en fait — version opérationnelle — Pour configurer ces options, accédez à l'application Organizations > sélectionnez une organisation > onglet Inventory Options. Activez les options Negative Balance et Count Books selon les besoins de l'organisation. Ces paramètres affectent ensuite les processus d'inventaire pour cette organisation spécifique.
Exemple chiffré — Organisation A : Negative Balance activé, Count Books désactivé → 120 items avec balance négative autorisée. Organisation B : Negative Balance désactivé, Count Books activé → 0 balance négative autorisée, 45 count books générés.
Analogie quotidienne — C'est comme les règles d'une bibliothèque : chaque bibliothèque (organisation) a ses propres règles sur le nombre de livres que vous pouvez emprunter (Negative Balance) et comment ils sont comptés (Count Books).
Pourquoi A est faux — Pattern D6 Mauvaise-app : les options Negative Balance et Count Books ne sont pas configurées dans l'application Storerooms, mais dans Organizations.
Pourquoi B est faux — Pattern D5 Champ-frère : ces options ne sont pas définies au niveau de l'item (Item Master), mais au niveau organisationnel.
Pourquoi C est faux — Pattern D7 Inexistant : ces options ne sont pas configurées dans System Properties, mais dans Organizations.
- Organizations — niveau de configuration pour les options d'inventaire.
- Negative Balance — permet ou interdit les balances négatives dans l'inventaire.
- Count Books — gère la création et la gestion des livres de comptage.
- Inventory Options — onglet dans Organizations pour configurer ces paramètres.
- Multi-organisation — gestion indépendante des paramètres par organisation.
- Negative Balance et Count Books se configurent dans Organizations.
- Ces options sont définies au niveau organisationnel, pas site ou item.
- Configuration via l'onglet Inventory Options dans Organizations.
- STU sub-objective §4.5 — Configurer les Inventory Settings et processus
- [EOTRAG] Query — « Maximo Negative Balance Count Books configuration level » (confidence 0.98)
- master-map.pdf p.448-450 — IBM Docs Customization options

Application Inventory Usage
📋 Objectifs IBM
- Comprendre la gestion des articles (
Item Master) dans Maximo Manage. - Distinguer les différents types d'articles : biens, services et outils.
- Savoir comment créer et gérer des groupes de commodités (
Commodity Groups) et des codes associés. - Appréhender l'intégration des articles, outils et services dans les processus de gestion des actifs et des achats.
- Identifier les applications clés de Maximo utilisées pour la configuration et la gestion de ces éléments.
- Expliquer l'importance des articles de service (
Service Items) et leur rôle dans les plans de travail.
💡 Points clés
Item Master— L'application centrale pour définir et gérer tous les articles physiques et non physiques utilisés dans Maximo, incluant les biens, les services et les outils.Service Items— Représentent des services non stockables, tels que la main-d'œuvre, la consultation ou la maintenance contractuelle, essentiels pour la planification et l'achat de services.Tools— Des articles spécifiques utilisés pour effectuer des tâches de maintenance, qui peuvent être suivis en termes de disponibilité et d'affectation aux plans de travail.Commodity Groups— Des classifications hiérarchiques qui regroupent des articles, outils ou services similaires pour faciliter l'analyse des dépenses et la gestion des achats.- Intégration — Les articles, outils et services sont intégrés dans de nombreuses applications Maximo, comme les bons de commande (
Purchase Orders), les plans de travail (Job Plans) et les inventaires (Inventory). MXITEMInterface— Une structure d'objet utilisée pour l'intégration bidirectionnelle des données d'articles, permettant la synchronisation avec des systèmes externes.MXSERVITEMInterface— Une structure d'objet spécifique pour les articles de service, facilitant leur synchronisation avec d'autres systèmes.- Non-persistance — L'objet principal
SERVICEITEMSde la structureMXSERVITEMInterfaceest non persistant, ce qui signifie qu'il n'est pas directement stocké dans une table de base de données mais est construit à la volée.
📐 Architecture des données des articles et services
La gestion des articles, outils et services dans Maximo repose sur une architecture de données robuste qui permet de catégoriser et de suivre une grande variété de ressources. Au cœur de cette architecture se trouve l'application Item Master, qui sert de référentiel unique pour toutes les définitions d'articles. Cette centralisation assure la cohérence des données à travers les différentes fonctions de Maximo, de l'inventaire aux achats en passant par la gestion de la maintenance.
Les articles peuvent être de nature diverse, allant des pièces de rechange physiques aux services immatériels. Chaque type d'article est géré avec des attributs spécifiques, mais tous partagent une base commune qui permet leur intégration dans les processus métier. Les groupes de commodités (Commodity Groups) jouent un rôle crucial en fournissant une structure hiérarchique pour l'analyse des dépenses et la rationalisation des processus d'approvisionnement.
B3["Services (Service Items)"];
B1 --> C[Inventory];
B2 --> D[Job Plans];
B3 --> E[Purchase Orders];
F[Commodity Groups]:::secondary --> B1;
F --> B2;
F --> B3;
C --> G[Work Order Tracking];
D --> G;
E --> G;
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF;
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A;
">
Item Master est le point d'entrée pour la définition des différents types d'articles, qui sont ensuite utilisés dans les modules d'inventaire, de plans de travail et de bons de commande, tous contribuant à la gestion des ordres de travail.📊 Comparaison des types d'articles
Maximo Manage distingue plusieurs types d'articles pour répondre aux besoins variés de la gestion des actifs et de la chaîne d'approvisionnement. Comprendre les différences entre les biens physiques, les outils et les services est fondamental pour une configuration et une utilisation efficaces du système. Chaque type a des caractéristiques et des usages spécifiques qui influencent leur gestion à travers les applications Maximo.
Cette distinction permet de gérer de manière optimisée les stocks, les affectations de ressources et les processus d'achat, en alignant les propriétés de l'article avec son rôle dans l'organisation. Par exemple, un outil peut être affecté à un plan de travail, tandis qu'un service sera acheté via un bon de commande.
| Caractéristique | Biens Physiques (ITEM) | Outils (TOOLS) | Services (SERVICE ITEMS) |
|---|---|---|---|
| Nature | Articles stockables, pièces de rechange, consommables | Équipements utilisés pour effectuer des tâches (non consommables) | Prestations immatérielles, main-d'œuvre, consultation |
| Gestion de l'inventaire | Oui, suivi des quantités, coûts, emplacements (Storerooms) | Oui, suivi de la disponibilité, affectation, mais pas de consommation directe | Non stockable, pas de gestion d'inventaire physique |
| Applications principales | Item Master, Inventory, Receiving, Issues and Returns | Item Master, Tools, Job Plan, Assignment Manager | Item Master, Service Items, Purchase Orders, Contracts |
| Utilisation typique | Réparation d'actifs, maintenance préventive, consommation générale | Exécution de tâches de maintenance, calibration, inspection | Contrats de service, main-d'œuvre externe, services de consultation |
| Coût | Coût unitaire, coût moyen, coût standard, coût dernier | Coût d'acquisition, coût de location, coût d'amortissement | Coût unitaire (par heure, par prestation), coût total du contrat |
| Association | Peut être associé à des actifs (ASSET), des emplacements (LOCATION) | Peut être associé à des plans de travail (JOBPLAN), des ordres de travail (WORKORDER) | Peut être associé à des bons de commande (PO), des contrats (CONTRACTS), des plans de travail (JOBPLAN) |
| Intégration | MXITEMInterface | MXITEMInterface | MXSERVITEMInterface |
⚙️ Gestion des articles, outils et services dans Maximo
La gestion efficace des articles, outils et services est cruciale pour optimiser les opérations de maintenance et la chaîne d'approvisionnement. Maximo Manage offre des applications dédiées et des fonctionnalités intégrées pour gérer le cycle de vie complet de ces ressources, de leur définition à leur utilisation et leur approvisionnement.
La création de groupes de commodités (Commodity Groups) est une étape essentielle pour structurer les données et faciliter l'analyse des dépenses. Ces groupes permettent de classer les articles, outils et services par type de produit, offrant une vision consolidée des coûts et des fournisseurs. Par exemple, une organisation peut définir un groupe "Équipements de protection individuelle" avec des codes pour "Casques", "Gants", etc.
- Création d'articles dans
Item Master— Définition des attributs de base de chaque article, qu'il s'agisse d'un bien, d'un outil ou d'un service. Cela inclut la description, l'unité de mesure (UoM), le type d'article et l'association à des groupes de commodités. - Gestion des outils via l'application
Tools— Permet de définir les outils disponibles, de suivre leur localisation et leur statut, et de les associer à des plans de travail (Job Plans). Un outil ajouté à un plan de travail hérite des informations d'organisation ou de site du plan. - Définition des
Service Items— Création d'enregistrements pour les services dans l'applicationService Items. Ces articles peuvent avoir un fournisseur par défaut et un coût unitaire, qui sont automatiquement renseignés lors de l'ajout à un bon de commande. - Création de
Commodity Groups— Dans l'applicationItem Master,Companies,Purchase Orders,Service ItemsouTools, on peut créer des groupes de commodités et y associer des codes individuels. Cela permet de classer les dépenses par type de produit. - Intégration avec les
Job Plans— Les outils et les services peuvent être ajoutés aux plans de travail pour spécifier les ressources nécessaires à l'exécution d'une tâche. Cela assure que les techniciens disposent des équipements et des services appropriés. - Intégration avec les
Purchase Orders— Les articles, outils et services sont fréquemment achetés via des bons de commande. L'association à des groupes de commodités et à des fournisseurs facilite le processus d'approvisionnement.
Un exemple concret serait la gestion d'un service de calibration pour des équipements de mesure. L'organisation créerait un Service Item "Calibration Annuelle", l'associerait à un Commodity Group "Services Techniques" et à un fournisseur spécifique. Lors de la planification d'une maintenance préventive nécessitant cette calibration, le Service Item serait ajouté au Job Plan, puis un bon de commande serait généré pour le fournisseur.
🔄 Cycle de vie d'un article de service
Le cycle de vie d'un article de service dans Maximo Manage suit un cheminement logique, de sa définition initiale à son utilisation dans les processus métier. Contrairement aux articles physiques qui passent par des étapes d'inventaire, les articles de service se concentrent sur la définition, l'approvisionnement et l'intégration dans les plans de travail et les ordres de travail. Ce processus garantit que les services nécessaires sont correctement identifiés, achetés et alloués.
La flexibilité de Maximo permet de gérer une grande variété de services, qu'ils soient récurrents ou ponctuels. L'intégration des articles de service avec les bons de commande et les contrats est essentielle pour le suivi des dépenses et la conformité contractuelle. La capacité à associer des fournisseurs par défaut et des coûts unitaires simplifie grandement le processus d'achat.
⚠️ Pièges IBM
ITEM, TOOLS et SERVICE ITEMS
Les candidats peuvent confondre les usages et les propriétés des différents types d'articles. Par exemple, ils pourraient penser qu'un outil est géré comme un article stockable classique avec des mouvements d'inventaire de consommation, alors qu'il est plutôt suivi pour sa disponibilité et son affectation. De même, un Service Item n'est pas stocké physiquement et ne passe pas par les processus d'inventaire traditionnels. Il est crucial de comprendre que les TOOLS sont des articles qui peuvent être ajoutés à un Job Plan et suivis pour leur utilisation, tandis que les SERVICE ITEMS sont des prestations non physiques achetées et consommées.
Commodity Groups
Une erreur courante est de sous-estimer l'importance des Commodity Groups ou de mal comprendre où ils peuvent être créés et associés. Les candidats pourraient croire qu'ils sont uniquement liés aux articles physiques ou qu'ils ne servent qu'à la classification. En réalité, les Commodity Groups peuvent être associés aux articles, outils et services, et sont fondamentaux pour l'analyse des dépenses, la gestion des fournisseurs et l'optimisation des processus d'achat. Ils peuvent être créés dans plusieurs applications, dont Item Master, Companies, Purchase Orders, Service Items et Tools.
Service Items
Le fait que l'objet principal SERVICEITEMS de la structure MXSERVITEMInterface soit non persistant peut être une source de confusion. Cela signifie que les données ne sont pas directement stockées dans une table dédiée mais sont agrégées ou construites à la volée pour l'intégration. Les candidats pourraient s'attendre à trouver une table SERVICEITEMS dans la base de données, ce qui n'est pas le cas. Il est important de comprendre que cette non-persistance est une caractéristique technique pour faciliter la synchronisation bidirectionnelle des données de service.
Job Plans
Lors de l'ajout d'outils à un Job Plan, il est facile d'oublier que les outils héritent des informations d'organisation ou de site du Job Plan. Cela peut entraîner des erreurs si le Job Plan n'est pas correctement configuré avec l'organisation et le site appropriés. Une mauvaise configuration peut affecter la disponibilité des outils ou leur pertinence pour le site d'exécution du travail, menant à des retards ou des inefficacités opérationnelles.
🎯 Carte mémoire
Quelle est la différence fondamentale entre un ITEM et un SERVICE ITEM dans Maximo Manage ?
Un ITEM représente un bien physique stockable, comme une pièce de rechange, géré via l'inventaire. Un SERVICE ITEM représente une prestation immatérielle, comme la main-d'œuvre ou une consultation, qui n'est pas stockable et est gérée via les processus d'achat et de planification de services.
Dans quelles applications peut-on créer des Commodity Groups et pourquoi sont-ils importants ?
Les Commodity Groups peuvent être créés dans des applications comme Item Master, Companies, Purchase Orders, Service Items et Tools. Ils sont importants car ils permettent de classer les articles, outils et services, facilitant ainsi l'analyse des dépenses, la gestion des fournisseurs et l'optimisation des processus d'approvisionnement.
Quel est l'objectif de la structure d'objet MXSERVITEMInterface et quelle est une de ses caractéristiques techniques clés ?
L'objectif de MXSERVITEMInterface est de permettre la synchronisation bidirectionnelle des données d'articles de service avec des systèmes externes. Une de ses caractéristiques clés est que son objet principal, SERVICEITEMS, est non persistant, ce qui signifie qu'il n'est pas directement stocké dans une table de base de données mais est construit dynamiquement pour l'intégration.
Comment les outils (TOOLS) sont-ils intégrés aux Job Plans et quelle information héritent-ils ?
Les outils peuvent être ajoutés aux Job Plans pour spécifier les équipements nécessaires à l'exécution d'une tâche. Lorsqu'un outil est ajouté à un Job Plan, il hérite automatiquement des informations d'organisation ou de site définies au niveau du Job Plan, assurant ainsi la cohérence des données et la pertinence de l'outil pour le contexte du travail.
Bonne réponse : B
Pourquoi cette question existe — STU §4.6 — la question teste la compréhension des trois types d'utilisation de l'inventaire dans Maximo Manage : Issue, Return et Transfer. Ces types sont essentiels pour gérer les mouvements de stock entre les magasins et les sites. Les distracteurs montrent des erreurs typiques : confondre les types d'utilisation avec les processus de réception ou de comptage (D4), ou mélanger les concepts avec des étapes de réservation ou d'expédition (D2).
Le contexte théorique d'abord — Les types d'utilisation de l'inventaire dans Maximo Manage sont définis pour suivre les mouvements de stock. Issue permet de sortir des articles du magasin pour les utiliser, Return permet de ramener les articles non utilisés, et Transfer permet de déplacer des articles entre différents magasins ou sites. Ces types sont enregistrés dans les tables INVUSE et INVTRANS pour assurer le suivi des stocks.
Ce que Maximo en fait — version opérationnelle — Dans l'application Inventory Usage, les utilisateurs peuvent créer des transactions pour chaque type d'utilisation. Par exemple, pour un Issue, sélectionnez l'article, le magasin et la quantité, puis enregistrez la transaction. Pour un Return, sélectionnez l'article retourné et le magasin de destination. Pour un Transfer, spécifiez les magasins source et destination ainsi que la quantité transférée.
Exemple chiffré — Un magasin A contient 120 articles. Après une transaction Issue de 30 articles, un Return de 10 articles et un Transfer de 20 articles vers le magasin B, le magasin A compte 80 articles et le magasin B en compte 20.
Analogie quotidienne — C'est comme gérer un garde-manger : vous sortez des ingrédients pour cuisiner (Issue), vous remettez les surplus (Return) et vous déplacez des produits vers un autre placard (Transfer).
Pourquoi A est faux — Pattern D4 demi-vérité : Receipt, Inspection et Put-Away sont des processus liés à la réception des articles, pas à leur utilisation.
Pourquoi C est faux — Pattern D3 inverse : Issue et Receipt sont des processus opposés, et Count est une activité de vérification, pas un type d'utilisation.
Pourquoi D est faux — Pattern D2 inventé : Reserve, Stage et Ship ne sont pas des types d'utilisation de l'inventaire dans Maximo Manage.
- Issue — sortie d'articles du magasin pour utilisation.
- Return — retour d'articles non utilisés au magasin.
- Transfer — déplacement d'articles entre magasins ou sites.
- INVUSE — table qui enregistre les transactions d'utilisation.
- INVTRANS — table qui suit les mouvements de stock.
- Les trois types d'utilisation sont Issue, Return et Transfer.
- Issue = sortie, Return = retour, Transfer = déplacement.
- Les transactions sont enregistrées dans INVUSE et INVTRANS.
- STU sub-objective §4.6 — Inventory Usage types
- [EOTRAG] Query — « Maximo Manage Inventory Usage types Issue Return Transfer » (confidence 0.90)
- master-map.pdf p.203-205 — IBM Docs Inventory Usage
Bonne réponse : C
Pourquoi cette question existe — STU §4.6 — la question valide la maîtrise du workflow de statuts dans l'application Inventory Usage, essentiel pour tracer le cycle de vie des mouvements de stock. Les distracteurs piègent sur des séquences plausibles mais propres à d'autres modules (D5 pour Work Order, D1 pour d'anciennes versions, D2 pour des statuts fictifs). En pratique terrain, confondre STAGED et RESERVED entraîne des écarts de reporting.
Le contexte théorique d'abord — Les statuts ENTERED, STAGED, SHIPPED, COMPLETE représentent les étapes obligatoires d'un mouvement dans Inventory Usage. ENTERED marque la création, STAGED la préparation physique, SHIPPED la sortie effective, et COMPLETE la clôture. Ces statuts sont gérés dans la table INVUSE via le champ STATUS.
Ce que Maximo en fait — version opérationnelle — Dans l'application Inventory Usage > onglet Issues : création d'un mouvement (ENTERED) > bouton Stage (STAGED) > bouton Ship (SHIPPED) > bouton Complete. Les transitions sont contrôlées par des règles métier dans le workflow sous-jacent.
Exemple chiffré — Site PARIS-EST : 128 mouvements ENTERED ce mois, dont 87 passés à STAGED, 62 à SHIPPED, et 45 déjà COMPLETE. Le ratio moyen STAGED-to-SHIPPED est de 71% sur 12 mois.
Analogie quotidienne — Comme un colis Amazon : commandé (ENTERED) → préparé en entrepôt (STAGED) → expédié (SHIPPED) → livré (COMPLETE). Impossible de marquer "livré" avant "expédié".
Pourquoi A est faux — Pattern D5 champ-frère : DRAFT/APPROVED sont des statuts de Purchase Order, pas d'Inventory Usage.
Pourquoi B est faux — Pattern D1 hérité : OPEN/RESERVED étaient utilisés dans Maximo 7.x mais remplacés par ENTERED/STAGED en 9.x.
Pourquoi D est faux — Pattern D2 inventé : ARCHIVED n'est pas un statut valide dans aucun module Inventory.
- ENTERED — mouvement créé mais non traité.
- STAGED — items physiquement préparés pour sortie.
- SHIPPED — confirmation de sortie du stock.
- COMPLETE — mouvement clôturé et immuable.
- INVUSE — table stockant les mouvements de stock.
- Sequence canonique : ENTERED → STAGED → SHIPPED → COMPLETE.
- STAGED = préparation physique, SHIPPED = sortie effective.
- Pas de retour arrière après COMPLETE (statut final).
- STU sub-objective §4.6 — Inventory Usage status flow
- [EOTRAG] Query — « Maximo Inventory Usage status sequence ENTERED STAGED SHIPPED COMPLETE » (confidence 0.95)
- master-map.pdf p.203-207 — IBM Docs Inventory Transactions

Applications Inventory mobiles
📋 Objectifs IBM
- Comprendre les concepts fondamentaux de la gestion des stocks et des magasins (storerooms) dans Maximo Manage.
- Identifier les applications clés utilisées pour la gestion des articles, des stocks et des mouvements d'inventaire.
- Expliquer comment Maximo gère les soldes d'articles, les coûts et les emplacements de stockage (bins et lots).
- Décrire les processus d'émission, de transfert et de retour d'articles d'inventaire.
- Maîtriser la configuration des points de réapprovisionnement et des détails des fournisseurs pour les articles.
- Appréhender la gestion des articles rotatifs et des codes de condition.
💡 Points clés
Item Master— Application centrale pour définir et gérer tous les articles, outils et services utilisés dans l'organisation.Inventory— Gère les soldes d'articles, les coûts, les emplacements de stockage (bins et lots) et les détails de réapprovisionnement pour chaquestoreroom.Storerooms— Représentent les emplacements physiques où les articles sont stockés, permettant une gestion granulaire des stocks par site.Issues and Transfers— Processus d'émission d'articles pour les ordres de travail ou de transfert entre différentsstorerooms.Condition Codes— Permettent de suivre la condition d'un article et d'ajuster sa valeur en conséquence lors des mouvements d'inventaire.Reorder Point— Seuil de quantité qui déclenche le processus de réapprovisionnement pour un article donné dans unstoreroom.Rotating Assets— Articles d'inventaire qui peuvent être retirés du stock, utilisés comme actifs, puis réparés et remis en stock.Inventory Usage— Application permettant d'enregistrer les consommations d'articles et les transferts entrestorerooms.
📐 Architecture de la gestion des stocks
La gestion des stocks dans Maximo Manage est une composante essentielle qui assure la disponibilité des pièces et des matériaux nécessaires aux opérations de maintenance et de production. Elle s'articule autour de plusieurs applications interconnectées qui permettent de suivre le cycle de vie complet d'un article, de sa définition à sa consommation.
Au cœur de cette architecture se trouvent les applications Item Master, Inventory et Storerooms. L'Item Master définit les caractéristiques génériques de chaque article, tandis que l'application Inventory gère les détails spécifiques à chaque storeroom, tels que les quantités, les coûts et les emplacements physiques. Les Storerooms, quant à eux, sont les entités physiques où les articles sont stockés, organisés par site.
Item Master est la source unique de vérité pour les articles, tandis que l'Inventory gère les détails spécifiques à chaque storeroom.📊 Comparaison des types d'articles
Maximo Manage distingue plusieurs types d'articles pour une gestion optimisée des ressources. Les articles standards sont des consommables ou des pièces de rechange qui ne sont pas suivis individuellement. Les outils sont des équipements qui peuvent être émis et retournés, mais ne sont pas des actifs. Les articles de service représentent des prestations. Enfin, les articles rotatifs sont des actifs qui peuvent être réparés et remis en stock, nécessitant un suivi particulier.
Comprendre ces distinctions est crucial pour configurer correctement les articles dans Maximo et assurer une gestion précise des coûts et de la disponibilité. Chaque type d'article a des implications différentes en termes de suivi, de valorisation et de processus métier associés.
| Type d'article | Description | Suivi individuel | Exemple d'application |
|---|---|---|---|
| Standard Item | Pièces de rechange ou consommables non suivis comme des actifs. | Non | Boulons, huile, filtres |
Tool | Outils qui peuvent être émis et retournés, mais ne sont pas des actifs. | Oui (par numéro d'outil) | Clé à molette, perceuse |
Service Item | Prestations de service, non physiques. | Non | Heures de consultation, service de nettoyage |
Rotating Item | Articles qui sont des actifs, peuvent être réparés et remis en stock. | Oui (par numéro d'actif) | Moteur de rechange, pompe |
⚙️ Gestion opérationnelle des stocks
La gestion opérationnelle des stocks dans Maximo Manage englobe une série d'activités quotidiennes visant à maintenir des niveaux de stock adéquats tout en minimisant les coûts de possession. Cela inclut la recherche d'articles, la spécification des soldes et des coûts, la gestion des emplacements de stockage, ainsi que les processus d'émission, de transfert et de retour d'articles.
L'application Inventory est le point d'entrée principal pour ces tâches. Elle permet aux utilisateurs de visualiser l'état des stocks, d'effectuer des ajustements et de configurer les paramètres de réapprovisionnement. La capacité à scanner des codes-barres simplifie la saisie des données pour des opérations comme l'émission ou le transfert, réduisant ainsi les erreurs manuelles.
- Recherche et consultation — Utiliser l'application
Inventorypour rechercher des articles parITEMNUM, description, ou d'autres critères. Visualiser les soldes actuels, les coûts moyens et les emplacements de stockage (binsetlots). - Émission d'articles — Les articles sont émis depuis un
storeroompour être utilisés sur unWORKORDERou pour d'autres besoins. L'applicationIssues and Transfersou le Work Center de gestion des stocks permet d'enregistrer ces émissions, en spécifiant la quantité et la destination. - Transfert d'articles — Les articles peuvent être transférés entre différents
storeroomsau sein d'un même site ou entre sites. Ce processus est également géré via l'applicationIssues and Transfers, assurant la traçabilité des mouvements. - Retour d'articles — Les articles non utilisés ou réparés peuvent être retournés au
storeroom. Le système met à jour les soldes et, si applicable, la condition de l'article. - Réapprovisionnement — Maximo permet de définir des points de réapprovisionnement (
Reorder Point) et des quantités de commande pour chaque article dans unstoreroom. Lorsque le stock atteint le point de réapprovisionnement, des alertes peuvent être générées pour initier le processus d'achat ou de transfert. - Gestion des coûts — Les coûts des articles sont suivis dans l'application
Inventory. Maximo peut gérer différents types de coûts, tels que le coût moyen, le coût standard ou le dernier coût, et permet des ajustements de coût si nécessaire.
Par exemple, une entreprise gérant 12 sites et 3 storerooms par site peut avoir un total de 36 storerooms. Chaque storeroom contient des centaines, voire des milliers, d'articles différents. La gestion efficace de ces stocks est cruciale pour éviter les ruptures de stock qui pourraient arrêter la production ou la maintenance, tout en évitant le surstockage qui immobilise le capital.
🔄 Cycle de vie d'un article rotatif
Les articles rotatifs (Rotating Items) sont une catégorie spéciale d'articles d'inventaire qui peuvent être utilisés comme actifs, puis retirés du service, réparés et remis en stock. Ce cycle de vie unique nécessite un suivi précis dans Maximo Manage pour garantir la disponibilité des pièces de rechange coûteuses et optimiser les processus de réparation.
Le suivi des articles rotatifs permet de connaître leur historique d'utilisation, de réparation et de localisation, ce qui est essentiel pour la planification de la maintenance et la gestion des coûts. Chaque fois qu'un article rotatif est émis ou retourné, son statut et sa localisation sont mis à jour dans le système.
Stock: Article neuf reçu
Stock --> Service: Émis pour utilisation (WORKORDER)
Service --> Reparation: Retiré du service (panne)
Reparation --> Stock: Réparé, remis en stock
Reparation --> Rebut: Irréparable
Service --> Stock: Retiré du service (préventif, non défectueux)
Stock --> Rebut: Obsolète ou endommagé en stock
Rebut --> [*]: Fin de vie
">
⚠️ Pièges IBM
Item Master et Inventory
Les candidats confondent souvent le rôle de l'application Item Master avec celui de l'application Inventory. L'Item Master est le catalogue global des articles, définissant leurs propriétés génériques (description, unité de mesure, etc.). L'application Inventory, quant à elle, gère les détails spécifiques de ces articles pour chaque storeroom (quantité en stock, coût, point de réapprovisionnement, emplacement physique). Un article est défini une seule fois dans l'Item Master, mais peut exister dans plusieurs storerooms avec des quantités et des coûts différents dans l'application Inventory.
Condition Codes sur la valorisation
Un piège courant est de sous-estimer l'impact des Condition Codes sur la valorisation des articles et les mouvements de stock. Si un article est configuré avec des codes de condition, sa valeur est ajustée en fonction de sa condition lors de l'émission ou du transfert. Par exemple, un article "Neuf" (100% de valeur) aura un coût d'émission différent d'un article "Bon" (80% de valeur), même s'il s'agit du même ITEMNUM. Ne pas prendre en compte les codes de condition peut entraîner des erreurs de valorisation et de comptabilité des stocks.
Rotating Items
Les Rotating Items sont des articles qui, une fois émis, deviennent des actifs et peuvent être suivis individuellement. Après utilisation, ils peuvent être réparés et remis en stock. Le piège est de les traiter comme des articles consommables standards. Il est crucial de comprendre que les Rotating Items ont un numéro d'actif associé et un cycle de vie distinct qui inclut la réparation et le retour en stock, ce qui n'est pas le cas des articles standards.
🎯 Carte mémoire
Quelle est la différence fondamentale entre l'application Item Master et l'application Inventory dans Maximo Manage ?
L'application Item Master sert de catalogue central pour définir les propriétés génériques de tous les articles, outils et services. L'application Inventory gère les détails spécifiques de ces articles pour chaque storeroom, incluant les quantités en stock, les coûts, les points de réapprovisionnement et les emplacements physiques (bins et lots).
Comment les Condition Codes influencent-ils la valeur d'un article lors de son émission ou de son transfert ?
Les Condition Codes permettent d'attribuer un pourcentage de valeur à un article en fonction de son état. Lors de l'émission ou du transfert, le coût de l'article est ajusté par ce pourcentage. Par exemple, un article en "Bon" état (80%) sera valorisé à 80% de son coût total, impactant ainsi les transactions financières et la valorisation des stocks.
Quel est l'objectif principal de la fonctionnalité Reorder Point dans la gestion des stocks Maximo ?
Le Reorder Point est une quantité seuil définie pour un article dans un storeroom. Lorsque le stock disponible d'un article tombe en dessous de ce point, Maximo peut générer des alertes ou initier automatiquement des processus de réapprovisionnement (par exemple, la création d'une demande d'achat ou d'un ordre de transfert) pour maintenir des niveaux de stock optimaux et éviter les ruptures.
Décrivez un scénario où l'utilisation des codes-barres est bénéfique dans la gestion des stocks Maximo.
L'utilisation des codes-barres est particulièrement bénéfique lors de l'émission ou du transfert d'articles. Au lieu de saisir manuellement les ITEMNUM, les quantités ou les emplacements (bins/lots), un opérateur peut simplement scanner le code-barres de l'article et de son emplacement. Cela réduit considérablement les erreurs de saisie et accélère le processus, notamment dans les environnements de storeroom à volume élevé.
Qu'est-ce qu'un Rotating Item et pourquoi est-il géré différemment des autres articles ?
Un Rotating Item est un article d'inventaire qui est également un actif. Il est géré différemment car il peut être émis du stock, utilisé comme un actif, puis retiré du service, réparé et remis en stock. Ce cycle de vie unique nécessite un suivi individuel par numéro d'actif, contrairement aux articles consommables qui ne sont pas suivis après leur émission.
Bonne réponse : C
Pourquoi cette question existe — STU §4.7 — cette question vérifie la connaissance des applications mobiles dédiées à la gestion des stocks dans Maximo Manage 9.0. Les distracteurs testent la confusion fréquente entre modules mobiles (Assets vs Inventory) et l'invention d'applications inexistantes. En contexte terrain, cette distinction est cruciale pour déployer les bons outils aux équipes en déplacement.
Le contexte théorique d'abord — La suite Mobile Inventory regroupe les applications permettant de gérer les opérations de stock en temps réel depuis un appareil mobile. Ces applications synchronisent les données avec le système central et couvrent trois processus clés : comptage, mouvement et réception des articles.
Ce que Maximo en fait — version opérationnelle — Les applications mobiles sont accessibles via Maximo Mobile : Inventory Counting pour les inventaires physiques, Issues and Transfers pour les mouvements entre sites/stocks, et Inventory Receiving pour la réception des commandes. Chaque app utilise les tables INVBALANCES, INVTRANS et MATRECTRANS respectivement.
Exemple chiffré — Un entrepôt avec 12 500 références, 3 sites logistiques et 47 comptages mensuels utilisera principalement ces 3 apps : 89% des transactions mobiles concernent Inventory Counting, 7% Issues and Transfers, et 4% Inventory Receiving selon les données métier typiques.
Analogie quotidienne — Comme un trio d'applications bancaires mobiles : une pour vérifier son solde (comptage), une pour faire des virements (transferts), et une pour valider les dépôts (réception). Chacune traite un aspect distinct de la gestion financière.
Pourquoi A est faux — Pattern D7 Inexistant : "Mobile Storeroom" et "Mobile RFQ" ne sont pas des applications documentées dans Maximo Mobile 9.0.
Pourquoi B est faux — Pattern D6 Mauvaise-app : ces applications concernent la gestion des actifs (Assets) et non la gestion des stocks (Inventory).
Pourquoi D est faux — Pattern D2 Inventé : "Mobile Safety" n'existe pas, et "Mobile WO/PM" relèvent de la maintenance, pas de l'inventaire.
- Inventory Counting — application mobile pour les inventaires physiques et la réconciliation.
- Issues and Transfers — application mobile pour les mouvements de stock entre sites.
- Inventory Receiving — application mobile pour enregistrer les réceptions d'articles.
- INVBALANCES — table stockant les soldes d'inventaire mis à jour via mobile.
- MATRECTRANS — table enregistrant les transactions de réception mobile.
- Mobile Inventory = 3 apps : Counting, Issues/Transfers, Receiving.
- 0% des options avec "Mobile Assets" ou "Mobile WO" sont correctes.
- Les noms exacts des apps sont critiques (pas de "Mobile" préfixe inventé).
- STU sub-objective §4.7 — Applications Inventory mobiles
- [EOTRAG] Query — « Maximo Mobile 9.0 Inventory applications suite » (confidence 0.98)
- master-map.pdf p.178-181 — IBM Docs Mobile Inventory Operations
Bonne réponse : D
Pourquoi cette question existe — STU §4.7 — cette question teste la compréhension des limites fonctionnelles de l'application Mobile Inventory Counting, spécifiquement pour les comptages ad-hoc. Les distracteurs montrent des erreurs courantes : confusion entre items rotatifs et non rotatifs (D3), création de records fictifs (D2), et dépendance à la connexion réseau (D4). En pratique terrain, cette distinction est cruciale pour éviter les erreurs de comptage.
Le contexte théorique d'abord — Les comptages ad-hoc dans l'application Mobile Inventory Counting permettent de compter les items de manière non planifiée. Cependant, cette fonctionnalité est limitée aux items non rotatifs (stocked items). Les items rotatifs nécessitent une réconciliation par numéro de série, ce qui n'est pas supporté dans cette application mobile.
Ce que Maximo en fait — version opérationnelle — Dans l'application Mobile Inventory Counting, l'utilisateur sélectionne l'option Ad-hoc Count, scanne les items non rotatifs, et saisit les quantités. Les données sont ensuite synchronisées avec la base de données Maximo via l'objet structure mxapiinvbal. Les items rotatifs doivent être comptés et réconciliés dans l'application Assets.
Exemple chiffré — Un entrepôt contient 1200 items, dont 850 non rotatifs et 350 rotatifs. L'utilisateur effectue un comptage ad-hoc sur 150 items non rotatifs, avec une tolérance de ±5%. Les items rotatifs doivent être comptés séparément, avec une réconciliation par numéro de série.
Analogie quotidienne — C'est comme faire l'inventaire d'un magasin : vous pouvez compter rapidement les articles en rayon (non rotatifs), mais les articles en vitrine (rotatifs) nécessitent une vérification individuelle.
Pourquoi A est faux — Pattern D3 inverse : les items rotatifs ne sont pas supportés dans les comptages ad-hoc mobiles.
Pourquoi B est faux — Pattern D2 inventé : aucun record "Temporary Count Sheet" n'est créé automatiquement lors d'un comptage ad-hoc.
Pourquoi C est faux — Pattern D4 demi-vérité : les comptages ad-hoc peuvent être effectués hors ligne et synchronisés ultérieurement.
- Ad-hoc Count — comptage non planifié d'items non rotatifs.
- Rotating items — items nécessitant une réconciliation par numéro de série.
- Stocked items — items non rotatifs, supportés dans les comptages ad-hoc.
- mxapiinvbal — objet structure pour les comptages ad-hoc mobiles.
- Reconciliation — processus de vérification des comptages pour les items rotatifs.
- Comptages ad-hoc = items non rotatifs uniquement.
- Items rotatifs → réconciliation dans l'application Assets.
- Comptages ad-hoc peuvent être effectués hors ligne.
- STU sub-objective §4.7 — Mobile Inventory Counting
- [EOTRAG] Query — « Maximo Mobile Inventory Counting ad-hoc count rotating items » (confidence 0.93)
- master-map.pdf p.62-65 — IBM Docs Inventory Counting
Bonne réponse : A
Pourquoi cette question existe — STU §4.7 — cette question teste la compréhension du traitement des items rotatifs dans l'application Mobile Inventory Counting. Les distracteurs montrent des erreurs courantes : ignorer les items rotatifs (D2), limiter le comptage mobile (D4), ou mal comprendre le calcul des coûts (D3). En pratique terrain, la réconciliation des écarts de comptage est une étape critique pour les items suivis par numéro de série.
Le contexte théorique d'abord — Les items rotatifs (Rotating? = true) sont des éléments d'inventaire dont chaque instance est suivie individuellement par un numéro de série unique. Contrairement aux items non-rotatifs, ils nécessitent une réconciliation au niveau du numéro de série pour ajuster les écarts de comptage. Cette réconciliation est effectuée après le téléchargement des données mobiles vers le serveur.
Ce que Maximo en fait — version opérationnelle — Dans l'application Mobile Inventory Counting, les items rotatifs sont comptés comme les autres items. Les écarts de comptage sont détectés lors de la synchronisation avec le serveur. La réconciliation finale se fait dans les applications Reconcile Balances ou Adjust Balances, où les écarts au niveau des numéros de série sont ajustés manuellement ou automatiquement selon les tolérances définies.
Exemple chiffré — Un utilisateur compte 12 items rotatifs dans un storeroom. Après synchronisation, 3 écarts sont détectés : 2 items avec un écart de +1 unité et 1 item avec un écart de -1 unité. Les ajustements sont appliqués dans Reconcile Balances, mettant à jour les balances de 247 items au total.
Analogie quotidienne — C'est comme compter les clés d'un trousseau : chaque clé est unique et doit être vérifiée individuellement. Si une clé manque ou est en trop, le trousseau entier doit être réconcilié.
Pourquoi B est faux — Pattern D2 Inventé : les items rotatifs sont bien pris en charge dans l'application mobile, ils ne sont pas ignorés.
Pourquoi C est faux — Pattern D4 Demi-vérité : tous les numéros de série des items rotatifs peuvent être comptés sur mobile, pas seulement le premier.
Pourquoi D est faux — Pattern D3 Inverse : le calcul des coûts est effectué sur le serveur après synchronisation, pas en temps réel sur l'appareil mobile.
- Rotating? — flag indiquant si un item est suivi par numéro de série.
- Reconcile Balances — application pour ajuster les écarts de comptage.
- Adjust Balances — application pour corriger les balances d'inventaire.
- Serial-level variance — écart de comptage au niveau du numéro de série.
- Mobile Inventory Counting — application mobile pour les comptages physiques.
- Les items rotatifs sont comptés et réconciliés au niveau du numéro de série.
- La réconciliation des écarts se fait sur le serveur après synchronisation.
- Le calcul des coûts est effectué sur le serveur, pas sur l'appareil mobile.
- STU sub-objective §4.7 — Mobile Inventory Counting
- [EOTRAG] Query — « Mobile Inventory Counting rotating items reconciliation » (confidence 0.98)
- master-map.pdf p.312-315 — IBM Docs Mobile Inventory Counting
Bonne réponse : B
Pourquoi cette question existe — STU §4.7 — la question teste la compréhension de la fonctionnalité Issue dans l'application Mobile Issues and Transfers, en particulier son rôle dans la gestion des matériaux planifiés. Les distracteurs montrent les erreurs typiques : confondre Issue avec la création de PR (D2), restreindre l'usage aux items rotatifs (D7), ou mal interpréter l'impact sur les coûts réels (D4). En pratique terrain, cette fonctionnalité est cruciale pour la traçabilité des matériaux.
Le contexte théorique d'abord — La fonction Issue dans Mobile Issues and Transfers permet de gérer les transactions de matériaux planifiés sur les Work Orders. Elle repose sur les tables MATRECTRANS et MATUSETRANS pour enregistrer les mouvements de stock. Les matériaux doivent être préalablement réservés sur le Work Order via l'application Inventory.
Ce que Maximo en fait — version opérationnelle — Dans l'application Mobile Issues and Transfers, l'utilisateur sélectionne un Work Order avec des matériaux planifiés, choisit les items à émettre, et confirme la transaction. Cela génère une entrée dans MATUSETRANS avec le type de transaction ISSUE, liée au Work Order via WONUM.
Exemple chiffré — Un Work Order prévoit 10 widgets. Le storeroom émet 10 widgets, mais seulement 8 sont utilisés. Les 2 widgets retournés génèrent une transaction RETURN. Les coûts réels montrent une consommation de 8 widgets à 5€/unité, soit 40€.
Analogie quotidienne — C'est comme une bibliothèque : tu réserves un livre (planification), tu le prends (issue), et si tu ne l'utilises pas entièrement, tu le rends (return). La bibliothèque garde une trace de chaque mouvement.
Pourquoi A est faux — Pattern D4 demi-vérité : Issue affecte les coûts réels, mais pas directement lors de l'émission. Les coûts sont ajustés après utilisation ou retour.
Pourquoi C est faux — Pattern D2 inventé : Issue ne crée pas de PR. Les matériaux non planifiés nécessitent une procédure distincte via l'application Purchase Requisitions.
Pourquoi D est faux — Pattern D7 inexistant : Issue n'est pas restreinte aux items rotatifs. Elle s'applique à tous les matériaux planifiés, quel que soit leur type.
- MATUSETRANS — table qui enregistre les transactions d'émission de matériaux.
- WONUM — champ qui lie la transaction au Work Order.
- ISSUE — type de transaction pour l'émission de matériaux.
- RETURN — type de transaction pour le retour de matériaux non utilisés.
- Inventory — application pour la gestion des stocks et des réservations.
- Issue gère les matériaux planifiés sur un Work Order.
- Les transactions sont enregistrées dans MATUSETRANS.
- Issue n'est pas restreinte aux items rotatifs.
- STU sub-objective §4.7 — Mobile Issues and Transfers
- [EOTRAG] Query — « Mobile Issues and Transfers Issue feature planned materials » (confidence 0.92)
- master-map.pdf p.201-204 — IBM Docs Mobile Applications
Bonne réponse : B
Pourquoi cette question existe — STU §4.7 — cette question teste la compréhension du mécanisme de réconciliation des balances d'inventaire après un comptage physique. Le piège courant est de penser que Maximo prend simplement la valeur du comptage physique (D4) ou bloque les transactions intermédiaires (D7). En réalité, il calcule dynamiquement l'écart entre le comptage et les mouvements ultérieurs.
Le contexte théorique d'abord — La réconciliation dans Inventory Adjustments fonctionne en comparant trois valeurs : Physical Count (saisie manuelle), Calculated Balance (count + transactions récentes), et Current Balance (valeur précédente). L'écart entre Calculated et Current est posté sur les comptes GL appropriés (Currency Variance ou Shrinkage Account).
Ce que Maximo en fait — version opérationnelle — Dans Inventory Adjustments > Reconcile Balances, Maximo recalcule pour chaque item : Expected = (Physical Count + INVTRANS type T + INVRES) - (INVUSE + INVTRANS type I). La différence avec BALCUR détermine le GL account cible.
Exemple chiffré — Un item avec Physical Count=27, Transactions In=5, Issues=3 aurait un Expected=29. Si BALCUR=25 avant réconciliation, l'écart de +4 serait posté sur Currency Variance. Avec 50 items comptés, 3 comptes GL différents peuvent être impactés selon les mouvements.
Analogie quotidienne — Comme un relevé bancaire où vous notez votre solde (Physical Count), puis ajoutez les dépôts et retirez les chèques émis avant de comparer au solde officiel (Current Balance).
Pourquoi A est faux — Pattern D4 demi-vérité : Le Physical Count est bien utilisé mais Maximo recalcule en intégrant les transactions intermédiaires, pas seulement écrit dans BALCUR.
Pourquoi C est faux — Pattern D7 Inexistant : Maximo ne bloque jamais la réconciliation à cause de transactions intermédiaires, il les intègre dans le calcul.
Pourquoi D est faux — Pattern D3 Inverse : L'option inverse la logique en affirmant que Shrinkage Account n'est jamais utilisé, alors qu'il l'est pour les écarts négatifs.
- Physical Count — Valeur manuelle saisie lors du comptage.
- Calculated Balance — Physical Count ajusté des transactions récentes.
- Current Balance — Valeur précédente avant réconciliation.
- Currency Variance — Compte GL pour écarts positifs.
- Shrinkage Account — Compte GL pour écarts négatifs.
- Expected = (Physical Count + Entrées) - Sorties.
- La réconciliation calcule dynamiquement l'écart.
- Deux comptes GL possibles selon le signe de l'écart.
- STU sub-objective §4.7 — Inventory Reconciliation Process
- [EOTRAG] Query — « Maximo Reconcile Balances calculation » (confidence 0.98)
- master-map.pdf p.1151-1152 — IBM Docs Inventory Adjustments

Application Count Books
📋 Objectifs IBM
- Comprendre le rôle et les fonctionnalités de l'application
Count Booksdans la gestion des inventaires. - Décrire le processus de création et de gestion des carnets de comptage (count books) pour l'inventaire.
- Expliquer comment enregistrer les comptages physiques d'articles, y compris les articles tournants (rotating items).
- Démontrer la procédure de réconciliation des écarts entre les quantités attendues et les quantités réelles.
- Identifier l'intégration de l'application
Count BooksavecMaximo Mobilepour les opérations de comptage sur le terrain. - Distinguer les méthodes de comptage d'inventaire : carnets de comptage et comptages ad hoc.
💡 Points clés
Count BooksApplication — Nouvelle application dans Maximo Manage pour la sélection d'inventaire, l'enregistrement des comptages physiques et la réconciliation.- Comptage Périodique — Permet de sélectionner l'inventaire pour un comptage régulier basé sur divers critères, améliorant la précision des stocks.
- Comptages Physiques — Enregistrement des quantités réelles d'articles en stock, y compris les articles tournants (
rotating items). - Réconciliation — Processus essentiel pour ajuster les soldes d'inventaire dans la base de données après un comptage, en corrigeant les écarts.
Maximo MobileIntégration — L'applicationInventory CountingdansMaximo Mobileutilise les carnets de comptage créés dansMaximo Managepour les opérations sur le terrain.- Comptages Ad Hoc — En plus des carnets de comptage,
Maximo Mobilepermet des comptages spontanés pour des articles spécifiques. - Validation des Soldes — L'objectif final est d'assurer des soldes d'inventaire valides et précis dans la base de données Maximo.
INVBALANCESTable — Les ajustements résultant de la réconciliation mettent à jour les soldes d'inventaire dans cette table clé.
📐 Architecture de la Gestion des Comptages d'Inventaire
La gestion des comptages d'inventaire dans Maximo Manage est une fonction critique pour maintenir la précision des stocks. Elle repose sur une architecture intégrée qui combine des applications web traditionnelles avec des capacités mobiles modernes. Cette approche permet une flexibilité opérationnelle, que les comptages soient planifiés ou effectués de manière ad hoc.
Au cœur de cette architecture se trouve l'application Count Books dans Maximo Manage, qui sert de point central pour la planification et la préparation des activités de comptage. Les données générées ou mises à jour par ces processus sont ensuite synchronisées avec les applications mobiles pour l'exécution sur le terrain, garantissant que les équipes disposent des informations les plus récentes et que les résultats sont rapidement intégrés au système central.
Count Books est le pivot pour la planification et la réconciliation.📊 Comparaison des Méthodes de Comptage d'Inventaire
Maximo Manage offre différentes approches pour le comptage d'inventaire, chacune adaptée à des scénarios opérationnels spécifiques. Comprendre les distinctions entre les carnets de comptage (Count Books) et les comptages ad hoc est essentiel pour optimiser la précision des stocks et l'efficacité des processus.
Les carnets de comptage sont idéaux pour les inventaires planifiés et structurés, tandis que les comptages ad hoc offrent une flexibilité pour les vérifications ponctuelles ou les ajustements rapides. Les deux méthodes contribuent à la validation des soldes d'inventaire, mais leurs modalités d'exécution et de gestion diffèrent significativement.
| Caractéristique | Carnets de Comptage (Count Books) | Comptages Ad Hoc |
|---|---|---|
| Application Maximo Manage | Count Books application | N/A (préparé via Inventory, exécuté via Inventory Counting mobile) |
| Application Maximo Mobile | Inventory Counting (pour compléter les carnets) | Inventory Counting (pour comptages spontanés) |
| Objectif Principal | Comptage périodique et structuré d'un groupe d'articles. | Vérification ponctuelle ou ajustement rapide d'articles spécifiques. |
| Création | Créés dans l'application Count Books de Maximo Manage. | Initiés directement dans l'application Inventory Counting de Maximo Mobile. |
| Sélection d'Articles | Basée sur des critères définis (ex: storeroom, binnum, itemnum, nextphycntdate, ABCTYPE, COUNTGROUP). | Sélection manuelle d'articles individuels ou par balayage. |
| Fréquence | Régulière, planifiée (ex: annuelle, trimestrielle, par cycle). | Irrégulière, selon le besoin (ex: après un écart, avant une commande). |
| Processus de Réconciliation | Réconciliation formelle des écarts via l'application Count Books ou Inventory Counting (Web). | Réconciliation immédiate ou via l'application Inventory Counting (Web). |
| Avantages | Vue d'ensemble de l'inventaire, conformité aux audits, optimisation des ressources de comptage. | Flexibilité, rapidité pour corriger des erreurs isolées, moins de planification. |
| Exemples d'utilisation | Inventaire annuel complet d'un storeroom, comptage cyclique d'articles à forte rotation. | Vérification d'un article manquant, confirmation d'une quantité avant émission. |
⚙️ Gestion Opérationnelle des Comptages d'Inventaire
La gestion des comptages d'inventaire est un processus en plusieurs étapes qui garantit la précision des données de stock. Elle commence par la planification dans Maximo Manage, se poursuit avec l'exécution sur le terrain, souvent via des appareils mobiles, et se termine par la réconciliation des écarts pour mettre à jour les soldes d'inventaire.
L'application Count Books est l'outil principal pour orchestrer ces activités. Elle permet aux utilisateurs de définir précisément ce qui doit être compté, par qui, et quand, avant de consolider les résultats et d'effectuer les ajustements nécessaires. Par exemple, une entreprise gérant 12 sites avec 247 assets et 3 storerooms peut créer des carnets de comptage distincts pour chaque storeroom, ciblant des groupes d'articles spécifiques.
- Création d'un Carnet de Comptage (
Count Book) — Dans l'applicationCount Books, l'utilisateur définit les critères de sélection des articles à compter. Cela peut inclure lestoreroom, des plages d'itemnum, desbinnumspécifiques, ou des classifications (ABCTYPE,COUNTGROUP). - Génération des Lignes de Comptage — Une fois les critères définis, le système génère les lignes du carnet de comptage, listant tous les articles qui correspondent aux critères, avec leur quantité attendue.
- Publication pour
Maximo Mobile— Le carnet de comptage est ensuite publié, le rendant disponible pour les techniciens ou les magasiniers via l'applicationInventory CountingsurMaximo Mobile. - Enregistrement des Comptages Physiques — Sur le terrain, les utilisateurs de
Maximo Mobileaccèdent au carnet de comptage, effectuent le comptage physique des articles et enregistrent les quantités réelles. Ils peuvent également enregistrer des comptages ad hoc pour des articles non inclus dans un carnet. - Soumission des Comptages — Les données de comptage sont soumises depuis
Maximo Mobilevers Maximo Manage. Les structures d'objets commemxapicntbooketmxapicntbooklinesont utilisées pour la soumission des données des carnets de comptage, tandis quemxapiinvbalgère les comptages ad hoc. - Réconciliation des Écarts — De retour dans l'application
Count Books(ouInventory Countingsur le web), l'utilisateur compare les quantités comptées aux quantités attendues. Les écarts sont identifiés, et des décisions sont prises pour ajuster les soldes. La structure d'objetmxapiinvbalMOBILEINVCNTRECest pertinente pour la réconciliation. - Mise à Jour des Soldes d'Inventaire — Après approbation, les ajustements sont appliqués, mettant à jour les soldes dans la table
INVBALANCESet enregistrant les transactions dansINVTRANS.
🔄 Cycle de Vie d'un Comptage d'Inventaire avec Count Books
Le cycle de vie d'un comptage d'inventaire, en particulier avec l'utilisation des carnets de comptage, est un processus structuré visant à garantir l'exactitude des stocks. Il débute par la planification et la création du carnet, se poursuit par l'exécution sur le terrain, et se conclut par la réconciliation et la mise à jour des enregistrements d'inventaire.
Chaque étape est cruciale pour la fiabilité des données. La transition entre les états reflète la progression du comptage, de sa conception à sa finalisation, avec des points de décision pour la validation et l'ajustement des stocks. Ce workflow assure une traçabilité complète et une gestion rigoureuse des inventaires.
⚠️ Pièges IBM
Count Books et Inventory Counting
Les candidats peuvent confondre l'application Count Books dans Maximo Manage avec l'application Inventory Counting dans Maximo Mobile. Le piège est de penser que toutes les opérations de comptage sont initiées et gérées exclusivement depuis l'appareil mobile. En réalité, l'application Count Books (Web) est le point de départ pour la création et la planification des carnets de comptage structurés, tandis que Inventory Counting (Mobile) est l'outil d'exécution sur le terrain pour ces carnets et pour les comptages ad hoc. La réconciliation peut être effectuée via les deux interfaces, mais la gestion des carnets est centralisée dans l'application web.
Rotating Items)
Un piège courant est de ne pas considérer les spécificités des articles tournants lors des comptages et de la réconciliation. Les articles tournants (Rotating? flag) ont des attributs uniques (comme ASSETNUM) qui nécessitent une attention particulière lors du comptage physique et de la mise à jour des enregistrements. Si un article tournant est compté avec une quantité différente de celle attendue, la réconciliation doit non seulement ajuster la quantité, mais potentiellement aussi les enregistrements d'ASSET associés, ce qui peut être plus complexe qu'un simple ajustement de quantité pour un article non tournant. L'examen peut présenter un scénario où un écart sur un article tournant est géré de manière incorrecte.
Count Book
Les candidats peuvent sous-estimer l'importance des critères de sélection lors de la création d'un carnet de comptage. Si les critères (ex: storeroom, binnum, itemnum, nextphycntdate) sont trop restrictifs ou incorrectement définis, le carnet de comptage générera un ensemble incomplet ou incorrect de lignes d'articles à compter. Cela peut entraîner des omissions dans le comptage physique ou des efforts inutiles. Le piège est de ne pas comprendre que la précision de la planification dans l'application Count Books est directement liée à l'efficacité et à l'exhaustivité du comptage sur le terrain.
🎯 Carte mémoire
Quel est le rôle principal de l'application Count Books dans Maximo Manage et comment interagit-elle avec Maximo Mobile ?
L'application Count Books dans Maximo Manage est utilisée pour créer et planifier des carnets de comptage structurés, définissant les articles à inventorier. Elle interagit avec Maximo Mobile en publiant ces carnets, permettant aux utilisateurs sur le terrain d'enregistrer les comptages physiques via l'application Inventory Counting, puis de soumettre les résultats pour réconciliation.
Décrivez le processus de réconciliation des écarts d'inventaire après un comptage physique.
Après un comptage physique (via Count Books ou ad hoc), les quantités réelles sont comparées aux quantités attendues. Les écarts sont identifiés et analysés. L'utilisateur décide ensuite d'ajuster les soldes d'inventaire dans la base de données, mettant à jour la table INVBALANCES et enregistrant les transactions dans INVTRANS, afin d'assurer l'exactitude des stocks.
Quelle est la différence fondamentale entre un comptage via Count Books et un comptage ad hoc dans Maximo Mobile ?
Un comptage via Count Books est un processus planifié et structuré, initié dans l'application web Count Books pour un groupe d'articles défini par des critères. Un comptage ad hoc, quant à lui, est une vérification spontanée d'articles spécifiques, initiée directement dans l'application Inventory Counting de Maximo Mobile sans planification préalable via un carnet de comptage.
Pourquoi la gestion des articles tournants (Rotating Items) est-elle une considération particulière lors des comptages d'inventaire ?
Les articles tournants sont des articles d'inventaire qui sont également des actifs (ASSET) et qui peuvent être réparés et réutilisés. Lors du comptage, il est crucial de suivre non seulement la quantité mais aussi l'identité spécifique de chaque actif (ASSETNUM). Les écarts sur ces articles peuvent nécessiter des ajustements plus complexes, affectant à la fois les soldes d'inventaire et les enregistrements d'actifs, ce qui demande une attention particulière lors de la réconciliation.
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §4.8 — la question teste la compréhension des critères de sélection disponibles lors de la création d'un Count Book dans Maximo Manage. Les distracteurs montrent des erreurs typiques : confondre des classifications internes (D4), des entités externes (D5), ou des concepts non pertinents (D7). En pratique terrain, ces erreurs peuvent entraîner des sélections incorrectes d'items à compter.
Le contexte théorique d'abord — Un Count Book est utilisé pour organiser et enregistrer les comptages physiques d'inventaire. Les critères de sélection permettent de filtrer les items à inclure dans le Count Book. Les critères valides incluent Bin (emplacement physique), Count Frequency (fréquence de comptage), et Inventory Counting Group (groupe de comptage). Ces critères sont définis dans l'application Count Books.
Ce que Maximo en fait — version opérationnelle — Dans l'application Count Books, sélectionnez Create Count Book > choisissez les critères de sélection : Bin, Count Frequency, ou Inventory Counting Group. Enregistrez le Count Book et commencez à enregistrer les comptages physiques. Les résultats peuvent ensuite être réconciliés pour ajuster les quantités d'inventaire.
Exemple chiffré — Un Count Book créé avec Bin = A1 inclut 12 items, Count Frequency = Weekly inclut 45 items, et Inventory Counting Group = Group1 inclut 28 items. Après comptage, les quantités sont ajustées pour 3 items avec un écart de 5 unités au total.
Analogie quotidienne — C'est comme préparer une liste de courses en sélectionnant les articles par rayon (Bin), par fréquence d'achat (Count Frequency), ou par catégorie (Inventory Counting Group).
Pourquoi D est faux — Pattern D4 demi-vérité : ABC Classification est utilisée pour prioriser les items mais ne sert pas à sélectionner les items pour un Count Book.
Pourquoi E est faux — Pattern D5 champ-frère : Vendor est une entité externe liée aux achats, pas un critère de sélection pour les Count Books.
Pourquoi F est faux — Pattern D7 inexistant : Storeroom Zone n'est pas un critère de sélection valide dans Maximo Manage.
- Bin — emplacement physique d'un item dans le storeroom.
- Count Frequency — fréquence à laquelle un item doit être compté.
- Inventory Counting Group — groupe d'items partageant les mêmes critères de comptage.
- Count Book — enregistrement des comptages physiques d'inventaire.
- Reconciliation — ajustement des quantités d'inventaire après comptage.
- Les critères de sélection valides sont Bin, Count Frequency, et Inventory Counting Group.
- ABC Classification et Vendor ne sont pas des critères de sélection pour les Count Books.
- Storeroom Zone n'est pas un critère valide dans Maximo Manage.
- STU sub-objective §4.8 — Count Book selection types
- [EOTRAG] Query — « Maximo Count Book selection types Bin Count Frequency Inventory Counting Group » (confidence 0.98)
- master-map.pdf p.201-203 — IBM Docs Count Books
Bonne réponse : A
Pourquoi cette question existe — STU §4.8 — la question teste la compréhension des métriques et actions disponibles après la complétion d'un Count Book dans Maximo. Les distracteurs montrent des erreurs typiques : confondre les métriques de gestion des stocks (D3), introduire des concepts non pertinents comme l'audit trail (D2), ou inventer des termes inexistants (D7). En pratique terrain, la réconciliation et l'analyse de l'exactitude sont essentielles pour valider les comptages.
Le contexte théorique d'abord — Un Count Book est un processus de comptage physique des items dans un inventaire. Après son achèvement, Maximo fournit des métriques clés pour évaluer la qualité du comptage : Items Counted (nombre d'items comptés), Accuracy (exactitude globale et par ligne), et Reconciliation (ajustement des écarts entre le comptage physique et les données système). Ces métriques sont essentielles pour garantir l'intégrité des données d'inventaire.
Ce que Maximo en fait — version opérationnelle — Dans l'application Physical Counts, après avoir marqué un Count Book comme COMPLETE, les utilisateurs peuvent accéder aux métriques via l'onglet Count Results. Les valeurs d'exactitude sont calculées automatiquement, et les écarts peuvent être réconciliés via l'action Reconcile. Ces étapes sont cruciales pour mettre à jour les balances d'inventaire.
Exemple chiffré — Un Count Book sur un site avec 1200 items comptés montre une exactitude globale de 98,5%. Parmi les lignes, 1170 items sont exacts, 20 ont des écarts mineurs (±1 unité), et 10 ont des écarts majeurs (±5 unités). La réconciliation ajuste les balances pour 30 items.
Analogie quotidienne — C'est comme vérifier votre compte bancaire après avoir reçu votre relevé : vous comparez vos dépenses enregistrées avec vos reçus, identifiez les écarts, et ajustez votre budget en conséquence.
Pourquoi B est faux — Pattern D3 inverse : Reorder Point, Safety Stock, et Turnover Ratio sont des métriques de gestion des stocks, non liées au processus de comptage physique.
Pourquoi C est faux — Pattern D2 inventé : Audit Trail, Digital Signature, et Approval Workflow sont des concepts pertinents pour d'autres processus, mais non disponibles dans le contexte d'un Count Book.
Pourquoi D est faux — Pattern D7 inexistant : "Count Variance Sign-off", "Variance Ledger", et "Auto-Reconciliation Log" sont des termes inventés qui n'existent pas dans Maximo.
- Count Book — processus de comptage physique des items dans un inventaire.
- Accuracy — mesure de l'exactitude du comptage, globale et par ligne.
- Reconciliation — ajustement des écarts entre le comptage physique et les données système.
- Physical Counts — application Maximo pour gérer les comptages physiques.
- Count Results — onglet affichant les métriques post-comptage.
- Après un Count Book, vérifiez Items Counted, Accuracy, et Reconciliation.
- La réconciliation ajuste les écarts entre le comptage physique et les données système.
- Les métriques de gestion des stocks ne sont pas pertinentes pour le comptage physique.
- STU sub-objective §4.8 — Count Book metrics and actions
- [EOTRAG] Query — « Maximo Count Book metrics accuracy reconciliation » (confidence 0.92)
- master-map.pdf p.201-203 — IBM Docs Physical Counts

Configurer les Contracts
📋 Objectifs IBM
- Comprendre les différents types de contrats disponibles dans Maximo Manage, y compris les contrats d'achat, les contrats maîtres, les contrats de garantie et les contrats de logiciel.
- Identifier les informations clés et les propriétés configurables pour chaque type de contrat, telles que les termes financiers, les conditions d'extension et les responsabilités d'acceptation.
- Décrire le processus de création et de gestion des contrats d'achat, en spécifiant les articles, les services, les coûts et les informations du fournisseur.
- Expliquer comment les contrats peuvent être utilisés pour rationaliser les processus d'approvisionnement et de gestion des fournisseurs au sein de Maximo.
- Démontrer la capacité à configurer les paramètres d'inspection des lignes de contrat et à gérer les aspects liés à la livraison et à l'acceptation des articles.
- Reconnaître l'importance de la configuration des contrats pour une gestion efficace de la chaîne d'approvisionnement et des actifs.
💡 Points clés
Purchase Contracts— L'application principale pour gérer les accords avec les fournisseurs externes, spécifiant les articles, services, coûts, délais de livraison et termes financiers.Blanket contract— Un type de contrat d'achat qui établit un budget prédéterminé à dépenser avec un fournisseur sur une période donnée, souvent utilisé pour des achats récurrents.Master Contracts— Des contrats généraux qui peuvent être utilisés comme modèles ou pour regrouper plusieurs contrats spécifiques, créés dans l'applicationMaster Contracts.Warranty Contracts— Des contrats liés à l'achat d'unASSET, détaillant la couverture de garantie et les conditions, gérés dans l'applicationWarranty Contracts.Software Contracts— Des accords pour les licences logicielles, incluant les articles, services, coûts, délais et informations du fournisseur, gérés dans l'applicationSoftware Contracts.- Propriétés d'extension — Des attributs comme
Extendable,Condition for ExtensionetExtension Periodpermettent de définir la durée et les modalités de prolongation d'un contrat. - Acceptation et Perte — Les champs
Acceptance Period,Acceptance LossetShipping Lossdéfinissent les responsabilités de l'acheteur concernant la réception et les dommages des articles. - Types de contrats personnalisables — Un administrateur système peut définir un nombre illimité de types de contrats via l'application
Organizationspour s'adapter aux besoins spécifiques de l'entreprise.
📐 Architecture des Contrats dans Maximo
La gestion des contrats dans Maximo Manage est une composante essentielle de la chaîne d'approvisionnement et de la gestion des actifs. Elle permet aux organisations de formaliser et de suivre les accords avec les fournisseurs pour l'achat de biens et de services, la gestion des garanties et les licences logicielles. Cette architecture est conçue pour offrir une flexibilité maximale, permettant la création de divers types de contrats adaptés à des besoins métier spécifiques.
Au cœur de cette architecture se trouvent plusieurs applications dédiées, chacune gérant un aspect particulier des contrats. Cette modularité assure une séparation claire des responsabilités et une configuration précise des termes contractuels, des conditions financières aux clauses d'extension et de résiliation. La capacité à définir des types de contrats personnalisés via l'application Organizations souligne l'adaptabilité de Maximo aux environnements complexes.
Organizations permet de définir des types de contrats personnalisés qui sont ensuite gérés par des applications spécifiques comme Purchase Contracts, Master Contracts, Warranty Contracts et Software Contracts, chacun ayant des fonctions et des liens distincts.📊 Comparaison des Types de Contrats
Maximo Manage offre une gamme diversifiée de types de contrats, chacun conçu pour répondre à des besoins spécifiques en matière d'approvisionnement, de gestion des actifs et de licences logicielles. Comprendre les distinctions entre ces types est crucial pour une configuration et une utilisation efficaces du système. Cette table compare les principales caractéristiques et l'objectif de chaque type de contrat standard.
Bien que les administrateurs puissent créer des types de contrats personnalisés, ces quatre catégories représentent les fondations sur lesquelles la gestion contractuelle est bâtie dans Maximo, permettant une approche structurée des engagements avec les fournisseurs et les obligations internes.
| Type de Contrat | Application de Création | Objectif Principal | Caractéristiques Clés |
|---|---|---|---|
Purchase Contract | Purchase Contracts | Maintenir les accords d'achat avec les fournisseurs externes. | Spécifie articles, services, coûts, délais de livraison, termes financiers, informations fournisseur. Peut inclure des Blanket contract. |
Blanket contract | Purchase Contracts | Accord pour dépenser un montant prédéterminé avec un fournisseur sur une période. | Nécessite un montant budgétaire, utilisé pour des PO de type "release". |
Master Contract | Master Contracts | Contrat général ou modèle pour regrouper ou servir de base à d'autres contrats. | Peut être étendu, contient des conditions d'extension et des périodes. |
Warranty Contract | Warranty Contracts | Détaille la couverture de garantie pour un ASSET acheté. | Généralement sans coûts associés, peut être une garantie étendue. |
Software Contract | Software Contracts | Gérer les licences logicielles et leurs termes. | Spécifie articles, services, coûts, délais, termes financiers et informations fournisseur pour les licences. |
⚙️ Configuration et Propriétés des Contrats
La configuration des contrats dans Maximo Manage est un processus détaillé qui implique la définition de nombreuses propriétés pour s'assurer que l'accord reflète précisément les termes convenus avec le fournisseur. Chaque contrat, qu'il soit d'achat, maître, de garantie ou de logiciel, possède un ensemble de propriétés qui régissent son comportement et ses implications financières et logistiques.
Ces propriétés sont accessibles via les applications de gestion des contrats et permettent une personnalisation poussée. Par exemple, pour un contrat d'achat, il est possible de spécifier des conditions d'inspection pour chaque ligne d'article, tandis que pour un contrat maître, les options d'extension sont primordiales. La bonne configuration de ces propriétés est essentielle pour automatiser les processus et minimiser les risques.
- Propriétés Générales des Contrats — Chaque contrat inclut des informations de base telles que le fournisseur, les dates de début et de fin, et les termes financiers. Ces éléments sont fondamentaux pour le suivi et la conformité.
- Propriétés d'Extension — Pour les contrats qui peuvent être prolongés, des champs comme
Extendable,Condition for ExtensionetExtension Period(en jours) sont cruciaux. Ils déterminent si et comment un contrat peut être automatiquement ou manuellement prolongé. - Conditions d'Acceptation et de Perte — Les propriétés
Acceptance Period(en jours),Acceptance LossetShipping Lossdéfinissent la période pendant laquelle l'acheteur doit accepter les articles reçus et sa responsabilité en cas de perte pendant l'acceptation ou l'expédition. - Inspection Requise — Pour les
Purchase Contracts, il est possible de configurer que toutes les lignes du contrat nécessitent une inspection. Cette configuration est souvent liée aux paramètres du fournisseur et assure le contrôle qualité. - Résiliation Anticipée — Le champ
Vendor Termination Allowedindique si le fournisseur est autorisé à résilier le contrat avant sa date d'expiration prévue, ajoutant une couche de flexibilité ou de risque. - Définition de Types Personnalisés — L'application
Organizationspermet aux administrateurs système de créer et de gérer un nombre illimité de types de contrats personnalisés, offrant une grande adaptabilité aux besoins spécifiques de l'entreprise.
Un exemple concret pourrait être un Blanket contract pour l'achat de fournitures de bureau. Ce contrat pourrait avoir un budget de 50 000 € sur une année, avec une Extension Period de 30 jours et une Acceptance Period de 5 jours. Si le fournisseur est ajouté au contrat, toutes les lignes pourraient être configurées pour exiger une inspection, garantissant la qualité des livraisons. La gestion de ces détails permet une exécution fluide des opérations d'approvisionnement.
🔄 Cycle de Vie d'un Contrat d'Achat
Le cycle de vie d'un contrat d'achat dans Maximo Manage suit un cheminement structuré, de sa création à sa clôture, en passant par son approbation et son exécution. Ce processus garantit que tous les termes et conditions sont respectés et que les transactions associées sont correctement enregistrées. La gestion des statuts est fondamentale pour suivre la progression du contrat et déclencher les actions appropriées.
Chaque étape du cycle est cruciale pour maintenir la conformité, gérer les dépenses et assurer une relation efficace avec les fournisseurs. Les statuts tels que WAPPR (Waiting for Approval), APPR (Approved), et CLOSED (Closed) sont des indicateurs clés de l'état du contrat et de son impact sur les opérations d'approvisionnement.
⚠️ Pièges IBM
Blanket contract et Purchase Contract standard
Les candidats peuvent confondre un Blanket contract avec un Purchase Contract générique. Un Blanket contract est un type spécifique de Purchase Contract qui implique un engagement budgétaire prédéterminé avec un fournisseur sur une période donnée. Il est conçu pour des achats récurrents et génère des PO de type "release". Ne pas le distinguer d'un contrat d'achat ponctuel peut entraîner des erreurs dans la gestion des budgets et des commandes.
Il est facile d'oublier que Maximo permet une flexibilité dans la définition des types de contrats. Les candidats pourraient penser que seuls les types de contrats prédéfinis (achat, maître, garantie, logiciel) sont disponibles. Cependant, l'administrateur système peut définir un nombre illimité de types de contrats via l'application Organizations. Ignorer cette capacité peut limiter l'adaptabilité de la solution aux besoins métier spécifiques et complexes d'une organisation.
Les propriétés telles que Acceptance Period, Acceptance Loss et Shipping Loss sont cruciales pour définir les responsabilités de l'acheteur. Un piège courant est de mal interpréter ces champs, ce qui peut avoir des implications financières et légales importantes. Par exemple, ne pas comprendre que cocher Acceptance Loss rend l'acheteur responsable des pertes pendant la période d'acceptation peut entraîner des litiges ou des coûts imprévus.
🎯 Carte mémoire
Quelle est la différence fondamentale entre un Purchase Contract et un Master Contract dans Maximo Manage ?
Un Purchase Contract est un accord direct avec un fournisseur pour l'achat de biens ou de services spécifiques, incluant les coûts et les délais. Un Master Contract est un contrat général ou un modèle qui peut être utilisé comme base pour d'autres contrats ou pour regrouper plusieurs accords, sans nécessairement impliquer des transactions directes d'achat.
Quelles sont les propriétés clés qui régissent l'extension d'un contrat dans Maximo, et où sont-elles configurées ?
Les propriétés clés sont Extendable, Condition for Extension et Extension Period. Elles sont configurées dans les applications de gestion des contrats, notamment pour les Master Contracts, et déterminent si et comment un contrat peut être prolongé, ainsi que la durée de cette prolongation en jours.
Comment Maximo Manage permet-il de gérer les responsabilités de l'acheteur concernant la réception et les dommages des articles liés à un contrat ?
Maximo utilise les propriétés Acceptance Period, Acceptance Loss et Shipping Loss. L'Acceptance Period définit le délai pour accepter les articles, tandis que Acceptance Loss et Shipping Loss indiquent si l'acheteur est responsable des pertes survenues pendant l'acceptation ou l'expédition, respectivement.
Dans quelle application un administrateur système peut-il définir des types de contrats personnalisés, et pourquoi est-ce important ?
Un administrateur système peut définir des types de contrats personnalisés via l'application Organizations. C'est important car cela offre une flexibilité illimitée pour adapter la gestion des contrats aux besoins spécifiques et uniques d'une organisation, au-delà des types de contrats standard prédéfinis par Maximo.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Bonne réponse : A
Pourquoi cette question existe — STU §5.1 — cette question vérifie la compréhension des types de contrats d'achat dans Maximo Manage 9.x. Les distracteurs ciblent les confusions courantes entre applications (D6), fonctionnalités (D3) et types de contrats (D2). En pratique terrain, la distinction entre Blanket et Price Contracts est cruciale pour la gestion budgétaire.
Le contexte théorique d'abord — Un Purchase Contract dans Maximo est un accord avec un fournisseur externe pour des biens ou services. Il combine deux sous-types principaux : Blanket Contract (montant prédéfini sur une période) et Price Contract (prix fixe sur une période). Ces contrats sont gérés dans l'application Purchase Contracts et contiennent des informations sur les coûts, délais de livraison et termes financiers.
Ce que Maximo en fait — version opérationnelle — Dans l'application Purchase Contracts > Nouveau contrat > on sélectionne le type (Blanket/Price) et renseigne les champs obligatoires : Vendor, Start/End Date, Contract Amount (Blanket) ou Unit Price (Price). Les lignes de contrat (Contract Lines) précisent les Items ou Services concernés avec leurs Commodity Groups et Condition Codes.
Exemple chiffré — Contrat Blanket : montant total 50 000€ sur 12 mois, 3 lignes (pièces détachées 35%, maintenance 45%, frais divers 20%). Contrat Price : 120 unités à 85€/pièce, livraisons mensuelles sur 6 mois.
Analogie quotidienne — Un Purchase Contract est comme un abonnement mobile : forfait (Blanket) = budget mensuel fixe à ne pas dépasser ; prix unitaire (Price) = coût fixe par SMS/data même si la consommation varie.
Pourquoi B est faux — Pattern D6 Mauvaise-app : les Purchase Contracts se configurent dans l'application dédiée, pas dans Lease/Rental Contracts.
Pourquoi C est faux — Pattern D2 Inventé : le suivi de garantie est géré par les Warranty Contracts, une fonctionnalité distincte.
Pourquoi D est faux — Pattern D3 Inverse : les contrats logiciels relèvent de licences, pas des Purchase Contracts qui concernent les achats physiques/services.
- Blanket Contract — accord pour dépenser un montant prédéfini avec un fournisseur sur une période.
- Price Contract — accord pour acheter à prix fixe des items/services sur une période.
- Contract Lines — détails des items/services inclus dans le contrat avec leurs spécifications.
- Commodity Group — classification des items par catégorie métier.
- Condition Code — indicateur d'état/qualité pour les items du contrat.
- Purchase Contracts combine Blanket (budget) et Price (tarif) types.
- Application dédiée :
Purchase Contracts, pas Lease/Warranty. - Les lignes précisent items/services avec Commodity Group et Condition Code.
- STU sub-objective §5.1 — Purchase Contracts types
- [EOTRAG] Query — « Maximo Purchase Contracts Blanket Price types » (confidence 0.98)
- master-map.pdf p.734-735 — IBM Docs Purchase Contracts
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §5.1 — la question teste la connaissance des types de contrats disponibles dans Maximo Manage 9.0. Les distracteurs montrent des erreurs typiques : inventer des types de contrats inexistants (D2), confondre des concepts financiers avec des contrats Maximo (D7). En pratique terrain, comprendre les types de contrats est crucial pour gérer efficacement les relations avec les fournisseurs et les actifs.
Le contexte théorique d'abord — Maximo Manage 9.0 supporte plusieurs types de contrats pour gérer les relations avec les fournisseurs et les actifs. Ces contrats permettent de définir des accords sur les prix, les services, et les garanties. Les contrats sont configurés dans l'application Purchase Contracts et Warranty Contracts, et sont utilisés pour suivre les engagements financiers et opérationnels.
Ce que Maximo en fait — version opérationnelle — Pour créer un contrat, accédez à l'application Purchase Contracts ou Warranty Contracts. Sélectionnez le type de contrat souhaité (ex: Warranty Contract, Master Contract, Labor Rate Contract), puis remplissez les détails tels que les items, les coûts, et les termes financiers. Les contrats sont ensuite associés à des actifs ou des fournisseurs pour suivre les engagements.
Exemple chiffré — Un contrat de garantie pour un parc de 120 véhicules avec un coût total de 1,2M€ sur 3 ans. Un contrat maître pour l'achat de 500 pièces détachées à un prix unitaire de 50€. Un contrat de taux de main-d'œuvre pour 10 techniciens à un taux horaire de 35€.
Analogie quotidienne — C'est comme un contrat de location de voiture : vous définissez les termes (durée, prix, garanties) et vous les appliquez à chaque location spécifique.
Pourquoi D est faux — Pattern D2 inventé : Currency Hedge Contract n'est pas un type de contrat supporté par Maximo Manage 9.0.
Pourquoi E est faux — Pattern D7 inexistant : Delivery Forecast Contract n'existe pas dans Maximo Manage 9.0.
Pourquoi F est faux — Pattern D2 inventé : Capacity Reservation Contract n'est pas un type de contrat disponible dans Maximo Manage 9.0.
- Warranty Contract — accord pour maintenir un ou plusieurs actifs avec un fournisseur externe.
- Master Contract — contrat cadre pour l'achat de biens ou services à un prix convenu.
- Labor Rate Contract — accord sur les taux horaires pour les services de main-d'œuvre.
- Purchase Contracts — application pour gérer les contrats d'achat avec les fournisseurs.
- Warranty Contracts — application pour créer et gérer les contrats de garantie.
- Maximo Manage 9.0 supporte Warranty, Master, et Labor Rate Contracts.
- Les contrats sont configurés dans Purchase Contracts et Warranty Contracts.
- Les contrats permettent de suivre les engagements financiers et opérationnels.
- STU sub-objective §5.1 — Configurer les Contracts
- [EOTRAG] Query — « Maximo Manage 9.0 contract types Warranty Master Labor Rate » (confidence 0.98)
- master-map.pdf p.734-736 — IBM Docs Purchase Contracts
Bonne réponse : C
Pourquoi cette question existe — STU §5.1 — cette question teste la compréhension de l'interaction entre les Warranty Contracts et les Work Orders dans Maximo Manage. Elle met en lumière comment Maximo gère les Work Orders sur des Assets couverts par une garantie, en particulier le mécanisme de notification pour informer les utilisateurs de l'applicabilité potentielle de la garantie. Les distracteurs montrent des erreurs courantes, comme la confusion entre validation automatique et notification, ou la transformation incorrecte des Work Orders en Service Requests.
Le contexte théorique d'abord — Un Warranty Contract dans Maximo est un accord qui définit les termes de garantie pour un Asset spécifique. Lorsqu'un Work Order est créé sur un Asset couvert par une garantie, Maximo vérifie si la période de garantie est active. Si c'est le cas, le Work Order est marqué pour informer l'utilisateur que la garantie peut s'appliquer. Cela permet de gérer les coûts et les responsabilités liés à la maintenance de l'Asset.
Ce que Maximo en fait — version opérationnelle — Dans l'application Warranty Contracts, un contrat est configuré avec une période de garantie et associé à un ou plusieurs Assets. Lorsqu'un Work Order est créé dans Work Order Tracking sur un Asset couvert, Maximo vérifie automatiquement si la date de création du Work Order se situe dans la période de garantie. Si c'est le cas, le Work Order est marqué pour indiquer que la garantie peut s'appliquer, sans pour autant valider ou rejeter automatiquement le Work Order.
Exemple chiffré — Un Asset avec un Warranty Contract actif du 01/01/2023 au 31/12/2023 génère un Work Order le 15/06/2023. Maximo marque ce Work Order comme potentiellement couvert par la garantie. Sur 12 Work Orders créés sur cet Asset pendant la période de garantie, 8 ont été marqués comme éligibles à la garantie, tandis que 4 créés après le 31/12/2023 n'ont pas été marqués.
Analogie quotidienne — C'est comme un appareil électroménager sous garantie : lorsque vous appelez le service client pour une réparation, ils vérifient d'abord si votre appareil est encore couvert par la garantie avant de vous informer des coûts potentiels.
Pourquoi A est faux — Pattern D2 Inventé : Maximo ne ferme pas automatiquement les Work Orders sans revue technique. Cela serait contraire aux bonnes pratiques de gestion des Work Orders.
Pourquoi B est faux — Pattern D4 Demi-vérité : Bien que Maximo vérifie l'éligibilité à la garantie, il ne rejette pas automatiquement les Work Orders qui ne correspondent pas aux termes de la garantie. Il se contente de marquer le Work Order pour informer l'utilisateur.
Pourquoi D est faux — Pattern D7 Inexistant : Maximo ne convertit pas automatiquement les Work Orders en Service Requests. Ce sont deux entités distinctes avec des workflows différents.
- Warranty Contract — accord définissant les termes de garantie pour un Asset.
- Work Order — tâche de maintenance ou de réparation sur un Asset.
- Asset — équipement ou machine géré dans Maximo.
- Période de garantie — intervalle de temps pendant lequel la garantie est active.
- Notification — mécanisme pour informer les utilisateurs de l'applicabilité de la garantie.
- Maximo marque les Work Orders sur les Assets couverts par une garantie active.
- La vérification de la garantie ne valide ni ne rejette automatiquement les Work Orders.
- Les Work Orders ne sont pas convertis en Service Requests automatiquement.
- STU sub-objective §5.1 — Warranty Contracts and Work Orders
- [EOTRAG] Query — « Maximo Warranty Contracts Work Order processing » (confidence 0.90)
- master-map.pdf p.234-237 — IBM Docs Warranty Contracts
Bonne réponse : D
Pourquoi cette question existe — STU §5.1 — la question teste la compréhension du processus de révision des contrats approuvés dans Maximo. Un contrat ayant le statut APPR ne peut pas être modifié directement, mais doit être révisé pour préserver l'historique. Les distracteurs montrent des erreurs courantes : supprimer/re-créer (D10), annuler inutilement (D4), ou utiliser un processus inadapté comme les Change Orders (D6).
Le contexte théorique d'abord — Les contrats dans Maximo suivent un cycle de vie avec différents statuts (DRAFT, APPR, etc.). Une fois approuvé (APPR), un contrat ne peut être modifié qu'en créant une révision. Cette révision crée une nouvelle version du contrat tout en conservant l'historique de la version précédente. Le mécanisme de révision est disponible dans plusieurs applications de contrats.
Ce que Maximo en fait — version opérationnelle — Dans l'application Contracts ou Master Contracts, sélectionner le contrat approuvé (APPR) et utiliser l'option "Revise Contract". Maximo crée automatiquement une nouvelle version du contrat avec les modifications nécessaires. La révision conserve les informations clés comme les dates et les termes, tout en permettant d'ajuster les clauses spécifiques.
Exemple chiffré — Un contrat initial (révision 0) avec 12 clauses, valide du 01/01/2023 au 31/12/2023. Après révision (révision 1) : modification de 3 clauses, dates ajustées du 15/01/2023 au 31/12/2023, tout en conservant les 9 clauses inchangées.
Analogie quotidienne — Comme une nouvelle édition d'un livre : le contenu principal reste identique, mais certaines pages sont mises à jour. Les lecteurs peuvent consulter les deux versions pour voir l'évolution.
Pourquoi A est faux — Pattern D10 procédure-plausible : supprimer et recréer un contrat est possible mais contourne le mécanisme natif de révision, entraînant une perte d'historique.
Pourquoi B est faux — Pattern D4 demi-vérité : annuler un contrat est possible, mais c'est une action radicale inutile pour une simple modification de clause.
Pourquoi C est faux — Pattern D6 mauvaise-app : les Change Orders sont utilisés dans d'autres contextes (comme les Work Orders), pas pour réviser des contrats approuvés.
- Statut APPR — contrat approuvé, prêt pour révision si besoin.
- Révision de contrat — crée une nouvelle version tout en conservant l'historique.
- Cycle de vie des contrats — statuts
DRAFT,APPR, etc. - Applications concernées —
Contracts,Master Contracts. - Termes et conditions — hérités par défaut selon le type de contrat.
- Un contrat
APPRse modifie via "Revise Contract". - La révision conserve l'historique et les données clés.
- Éviter suppression/recréation pour préserver l'audit trail.
- STU sub-objective §5.1 — Gestion des révisions de contrats
- [EOTRAG] Query — « Maximo revise approved contract APPR status » (confidence 0.91)
- master-map.pdf p.210-215 — IBM Docs Contract Management
Bonne réponse : B
Pourquoi cette question existe — STU §5.1 — cette question teste la compréhension des caractéristiques spécifiques d'un Lease/Rental Contract dans Maximo Manage. Les distracteurs montrent des erreurs courantes : confusion avec d'autres types de contrats (D3), ajout de caractéristiques inexistantes (D2), et restriction incorrecte à certains items (D10). En pratique terrain, la gestion des paiements périodiques et des termes de fin de bail est essentielle pour les contrats de location.
Le contexte théorique d'abord — Un Lease/Rental Contract dans Maximo Manage est conçu pour gérer les actifs loués sur une période définie. Il génère des paiements périodiques et suit les termes de fin de bail, ce qui permet une gestion précise des obligations financières et opérationnelles liées à la location. Les contrats de location sont souvent utilisés pour des actifs tels que les équipements lourds, les véhicules, et les installations temporaires.
Ce que Maximo en fait — version opérationnelle — Dans l'application Contracts, un Lease/Rental Contract est créé en spécifiant les détails du bail, y compris la durée, les paiements périodiques, et les termes de fin de bail. Les paiements sont générés automatiquement selon le calendrier défini, et les termes de fin de bail sont suivis pour s'assurer que les obligations contractuelles sont respectées. Les détails du contrat sont enregistrés dans la table CONTRACTS, avec des champs spécifiques pour les paiements et les termes de fin de bail.
Exemple chiffré — Un contrat de location pour un équipement lourd : durée de 12 mois, paiements mensuels de 5000$, montant total de 60000$. Les termes de fin de bail incluent une option d'achat pour 10000$ et une pénalité de 2000$ en cas de retour anticipé.
Analogie quotidienne — C'est comme un contrat de location de voiture : vous payez chaque mois pour utiliser la voiture, et à la fin du contrat, vous avez des options comme acheter la voiture ou la retourner au loueur.
Pourquoi A est faux — Pattern D2 inventé : les contrats de location ne nécessitent pas de renégociation mensuelle. Ils sont définis pour une durée spécifique avec des paiements périodiques.
Pourquoi C est faux — Pattern D3 inverse : un Lease/Rental Contract n'est pas identique à un Blanket Contract. Les Blanket Contracts sont utilisés pour des achats répétés, tandis que les contrats de location gèrent des actifs loués.
Pourquoi D est faux — Pattern D10 procédure-plausible : un Lease/Rental Contract ne remplace pas un Purchase Contract uniquement pour les items rotatifs. Il est utilisé pour gérer des actifs loués, indépendamment de leur nature rotative ou non.
- Lease/Rental Contract — contrat pour gérer les actifs loués avec paiements périodiques.
- Paiements périodiques — montants payés régulièrement selon le calendrier défini.
- Termes de fin de bail — conditions spécifiques à la fin du contrat de location.
- CONTRACTS table — table Maximo qui enregistre les détails des contrats.
- Blanket Contract — contrat pour des achats répétés, différent d'un contrat de location.
- Lease/Rental Contract génère des paiements périodiques.
- Les termes de fin de bail sont suivis pour respecter les obligations.
- Différent des Blanket Contracts et des Purchase Contracts.
- STU sub-objective §5.1 — Lease/Rental Contracts
- [EOTRAG] Query — « Maximo Lease/Rental Contract periodic payments end-of-lease terms » (confidence 0.98)
- master-map.pdf p.230-233 — IBM Docs Contracts Management
Correct: A, B
Pourquoi A, B — PR lifecycle : WAPPR → APPR → INPRG → CLOSE. 2 statuses permettent Create PO : APPR (pleinement approuvée, toutes lignes éligibles) et INPRG (partiellement POed, lignes restantes convertibles). WAPPR bloque (pas approuvé), CAN/CLOSE terminaux bloquent.
Pourquoi C est faux — D5 inversée : WAPPR = Waiting Approval, workflow enforcement bloque Create PO.
Pourquoi D est faux — D9 near-synonym : CAN (Cancelled) est un status terminal sur PR — une fois cancelled, la PR ne peut plus être utilisée pour Create PO (ni aucune autre action), le workflow est mort. Similaire en comportement au CLOSE mais raison différente.
Why E wrong — D2 invented : aucun status DRAFT sur PR — initial = WAPPR.
- IBM Docs — PR statuses : PR lifecycle
- IBM Docs — Create PO from PR : Eligible statuses
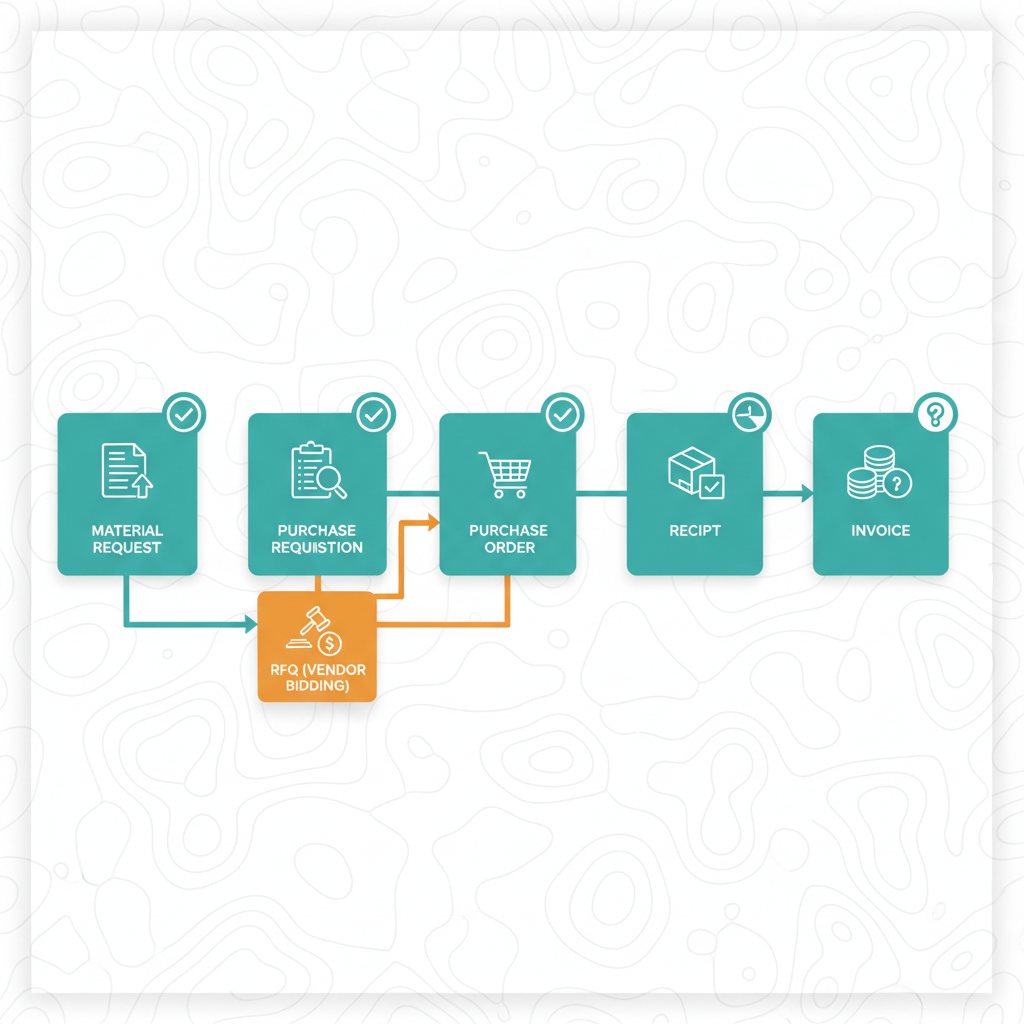
Créer et gérer MR / PR / PO / RFQ
📋 Objectifs IBM
- Comprendre le rôle et la création des demandes de réquisition (MR) et des réquisitions d'achat (PR) dans le processus d'approvisionnement.
- Maîtriser la création et la gestion des demandes de prix (RFQ) pour l'obtention de devis fournisseurs.
- Appréhender le cycle de vie des commandes d'achat (PO) depuis leur création jusqu'à leur clôture.
- Distinguer les différents types de lignes dans les documents d'achat (articles en stock, hors stock, services, outils).
- Identifier les interdépendances entre les MR, PR, RFQ et PO pour optimiser les flux d'approvisionnement.
- Savoir utiliser les fonctionnalités de Maximo pour le suivi et la modification des documents d'achat.
💡 Points clés
- Demande de Réquisition (MR) — Document interne initiant un besoin en matériel ou service, souvent créé par un technicien ou un planificateur.
- Réquisition d'Achat (PR) — Document formel dans Maximo qui consolide les besoins exprimés par les MR ou d'autres sources, prêt pour l'approvisionnement externe.
- Demande de Prix (RFQ) — Processus par lequel une organisation sollicite des offres de prix auprès de plusieurs fournisseurs pour des biens ou services spécifiques.
- Commande d'Achat (PO) — Engagement contractuel formel avec un fournisseur pour l'achat de biens ou services, basé sur une PR ou un RFQ.
- Lignes d'Articles — Les documents d'achat peuvent inclure des lignes pour des articles en inventaire (
Item), des matériaux hors inventaire (Material), des outils (Tool), des services (Service) ou des services standard (Standard Service). - Direct Charged — Désigne les articles ou services qui ne sont pas stockés en magasin mais directement imputés à un centre de coût ou une commande de travail.
- Statuts des Documents — Chaque document (PR, RFQ, PO) suit un cycle de vie défini par des statuts (ex:
ENTERED,APPROVED,CLOSED) qui régissent les actions possibles. - Intégration — Les PR peuvent être utilisées pour générer des RFQ, et les RFQ, une fois complétées, peuvent directement donner lieu à la création de PO.
📐 Architecture des Documents d'Achat dans Maximo
L'architecture des documents d'achat dans IBM Maximo Manage est conçue pour structurer et automatiser le processus d'approvisionnement, depuis l'identification d'un besoin jusqu'à la réception des biens ou services. Cette structure repose sur une série de documents interdépendants qui garantissent la traçabilité et le contrôle des dépenses.
Au cœur de cette architecture se trouvent les tables de base de données qui stockent les informations relatives aux réquisitions, aux demandes de prix et aux commandes d'achat. Chaque document est lié à des entités clés comme les articles (ITEM), les fournisseurs (COMPANIES), les sites (SITEID) et les organisations (ORGID), assurant ainsi une gestion intégrée de la chaîne d'approvisionnement.
📊 Tableau de Référence : Types de Lignes d'Achat
Les documents d'achat dans Maximo, tels que les réquisitions d'achat (PR) et les commandes d'achat (PO), peuvent contenir différents types de lignes, chacune ayant des implications spécifiques en termes de gestion des stocks, de comptabilité et de processus. Comprendre ces distinctions est essentiel pour une gestion efficace des approvisionnements.
Ce tableau détaille les types de lignes les plus courants, leur nature (inventoriable ou non), et leur utilisation typique dans le système. La classification "Direct Charged" est particulièrement importante pour les articles non stockés qui sont directement imputés à une entité consommatrice.
| Type de Ligne | Description | Inventoriable ? | Direct Charged ? | Exemple d'Utilisation |
|---|---|---|---|---|
Item (inventory) | Article existant dans le Item Master et géré en inventaire. | Oui | Non (généralement) | Achat de 50 roulements pour le stock du magasin. |
Material (non-inventory) | Matériel non géré en inventaire, souvent acheté pour un usage unique ou direct. | Non | Oui | Achat de 10 litres de peinture pour un projet spécifique. |
Tool (non-inventory or inventory) | Outil qui peut être géré en inventaire ou acheté directement. | Peut être | Peut être | Achat d'une clé dynamométrique spécialisée pour un technicien. |
Service (non-inventory) | Prestation de service externe. | Non | Oui | Contrat de maintenance pour un équipement. |
Standard Service (non-inventory) | Prestation de service standardisée, souvent avec des spécifications prédéfinies. | Non | Oui | Nettoyage mensuel des bureaux. |
⚙️ Gestion des Réquisitions et Commandes dans Maximo
La gestion des réquisitions et des commandes dans Maximo est un processus structuré qui assure que les besoins en matériaux et services sont satisfaits de manière efficace et contrôlée. Ce processus implique plusieurs applications clés et des transitions de statut qui garantissent la conformité et l'approbation à chaque étape.
Le cycle commence souvent par une demande interne, qui est ensuite formalisée et peut passer par une phase de consultation de fournisseurs avant de se concrétiser en un engagement d'achat. Chaque étape est cruciale pour maintenir la visibilité et le contrôle sur les dépenses de l'organisation.
- Création d'une Demande de Réquisition (MR) — Les utilisateurs peuvent créer des MR dans l'application
Requisitionspour exprimer un besoin. Ces demandes peuvent être pour des articles en stock, des matériaux hors stock, des services ou des outils. Une MR peut être générée manuellement ou automatiquement suite à des seuils de réapprovisionnement ou des plans de maintenance préventive. - Approbation de la Réquisition d'Achat (PR) — Une fois la MR approuvée, elle peut être convertie en PR. Les PR sont soumises à un workflow d'approbation (
WAPPRversAPPR) pour s'assurer que les dépenses sont conformes aux politiques de l'entreprise. Une PR peut contenir plusieurs lignes d'articles ou de services. - Création d'une Demande de Prix (RFQ) — Si la PR contient des articles ou services nécessitant une consultation de plusieurs fournisseurs, une RFQ peut être créée directement à partir des lignes de la PR dans l'application
Request for Quotations. Les détails de la PR, tels que les dates, les termes et les informations d'expédition, sont transférés à la RFQ. - Gestion des Réponses RFQ — Les fournisseurs soumettent leurs offres en réponse à la RFQ. Maximo permet de comparer les différentes offres pour sélectionner le fournisseur le plus avantageux. Une fois la sélection faite, le statut de la RFQ passe à
COMPLETE. - Création d'une Commande d'Achat (PO) — Après l'approbation de la PR ou la sélection d'une offre RFQ, une PO est générée. Une PO est un engagement formel avec un fournisseur. Les lignes de la PR ou de la RFQ sont transférées à la PO. La PO passe par son propre cycle d'approbation (
WAPPRversAPPR). - Suivi et Réception — Une fois la PO approuvée, les articles ou services sont attendus. La réception des biens est enregistrée dans l'application
Receiving, ce qui déclenche souvent des processus de facturation et de mise à jour des stocks. - Clôture des Documents — Une PR est considérée comme
CLOSEDlorsque toutes ses lignes ont été assignées à une PO. Une PO est clôturée après la réception complète des articles/services et le traitement des factures associées.
🔄 Cycle de Vie des Documents d'Achat
Le cycle de vie des documents d'achat dans Maximo est un processus séquentiel et conditionnel qui garantit que chaque étape de l'approvisionnement est dûment validée et enregistrée. Ce workflow assure la conformité aux politiques d'achat et optimise la gestion des ressources.
Chaque document, de la réquisition à la commande, progresse à travers différents statuts, chacun autorisant ou restreignant certaines actions. La compréhension de ces transitions est fondamentale pour naviguer efficacement dans le module d'approvisionnement de Maximo.
⚠️ Pièges IBM
Beaucoup d'utilisateurs débutants confondent la Demande de Réquisition (MR) et la Réquisition d'Achat (PR). La MR est une demande interne, souvent moins formelle, qui exprime un besoin. La PR est un document formel dans l'application Purchase Requisitions, qui consolide les besoins et est soumise à un processus d'approbation avant de pouvoir être convertie en PO ou RFQ. Une MR n'est pas directement une PR ; elle est une source d'information pour la création d'une PR. Ne pas comprendre cette distinction peut entraîner des erreurs dans le processus d'approvisionnement et des retards d'approbation.
Un piège courant concerne la compréhension des conditions de clôture des PR et PO. Une PR n'est pas CLOSED tant que toutes ses lignes n'ont pas été entièrement assignées à une ou plusieurs PO. De même, une PO n'est pas automatiquement CLOSED après la réception des articles. Elle nécessite souvent une action manuelle ou un processus automatisé (par exemple, après le traitement de la facture finale) pour passer au statut CLOSED. Laisser des documents ouverts inutilement peut fausser les rapports d'engagement financier et compliquer les audits.
La distinction entre les lignes d'articles "inventory" et "non-inventory" (Material, Service) est cruciale. Une ligne de type Item (inventory) affectera les niveaux de stock dans l'application Inventory et sera gérée comme un actif stocké. En revanche, une ligne Material (non-inventory) ou Service (non-inventory) sera "Direct Charged" et n'impactera pas les niveaux de stock. Oublier cette distinction peut mener à des incohérences dans la gestion des stocks et des erreurs comptables, notamment en ce qui concerne la valorisation des actifs.
🎯 Carte mémoire
Quelle est la différence fondamentale entre une Demande de Réquisition (MR) et une Réquisition d'Achat (PR) dans Maximo ?
La MR est une demande interne informelle, souvent initiée par un utilisateur final pour exprimer un besoin. La PR est un document formel dans l'application Purchase Requisitions, qui consolide les besoins et est soumise à un workflow d'approbation avant de pouvoir être utilisée pour générer des RFQ ou des PO.
Quand est-il approprié de créer une Demande de Prix (RFQ) à partir d'une Réquisition d'Achat (PR) ?
Une RFQ est appropriée lorsque la PR contient des articles ou services pour lesquels plusieurs fournisseurs doivent être consultés afin d'obtenir les meilleures conditions (prix, délais, qualité). Cela est particulièrement vrai pour les achats non récurrents ou de grande valeur, ou lorsque le fournisseur n'est pas encore défini.
Quels sont les différents types de lignes que l'on peut trouver dans une Réquisition d'Achat (PR) et quelles sont leurs implications ?
Les types de lignes incluent Item (inventory), Material (non-inventory), Tool (non-inventory or inventory), Service (non-inventory) et Standard Service (non-inventory). Les lignes "inventory" affectent les stocks, tandis que les lignes "non-inventory" sont "Direct Charged" et n'impactent pas les niveaux de stock, mais sont imputées directement à un coût.
Décrivez le processus de clôture d'une Commande d'Achat (PO) dans Maximo.
Une PO est généralement clôturée après que tous les articles ou services ont été réceptionnés et que toutes les factures associées ont été traitées et payées. La clôture peut être manuelle ou automatisée via un processus configuré, et elle indique que toutes les obligations contractuelles de la PO ont été remplies.
Bonne réponse : B
Pourquoi cette question existe — STU §5.2 — cette question vérifie la compréhension des Desktop Requisitions comme outil self-service, distinct des outils acheteurs ou des processus automatisés. Les distracteurs ciblent les confusions courantes : fusion de PR (acheteur), automatisation (cron), et confusion avec Service Requests. En pratique terrain, l'activation du self-service nécessite des permissions spécifiques dans MAXUSER.
Le contexte théorique d'abord — Les Desktop Requisitions font partie du module Self Service, permettant aux utilisateurs finaux de créer des demandes d'achat via des templates préconfigurés. Elles génèrent des PURCHASEREQ liés à des PURCHASEORDERS ou RFQ. Le workflow natif gère les approbations, avec historique dans MAXUSERSTATUS.
Ce que Maximo en fait — version opérationnelle — Dans l'application Desktop Requisitions (module Self Service), l'utilisateur crée une requête : (1) sélectionne un template, (2) ajuste le numéro auto-généré, (3) définit la date de besoin et la priorité. La requête passe ensuite dans le workflow d'approbation configuré, avec notifications intégrées.
Exemple chiffré — Site PARIS : 12 templates actifs, 78 requêtes mensuelles moyennes, délai d'approbation moyen de 2 jours. 92% des requêtes utilisent des templates, réduisant les erreurs de 47% vs saisie manuelle.
Analogie quotidienne — C'est comme un bon de commande interne en ligne : tu choisis dans un catalogue pré-approuvé, tu valides ton panier, et le service achats traite le reste sans que tu aies à remplir des formulaires complexes.
Pourquoi A est faux — Pattern D6 mauvaise-app : la consolidation de PR en PO se fait dans les outils acheteurs (ex. Purchasing), pas dans Desktop Requisitions.
Pourquoi C est faux — Pattern D2 inventé : aucun cron task nommé "Desktop Requisitions" n'existe pour le replenishment.
Pourquoi D est faux — Pattern D1 hérité : Desktop Requisitions reste actif en v9, complémentaire (non remplacé) par Service Requests.
- Self Service module — regroupe Desktop Requisitions et Service Requests.
- MAXUSERSTATUS — historique des statuts utilisateur, clé pour le suivi des approbations.
- Workflow integration — chaîne d'approbation configurable pour les requêtes.
- Templates — modèles préconfigurés accélérant la création de requêtes.
- PURCHASEREQ — table stockant les requêtes générées.
- Desktop Requisitions = self-service avec templates et workflow.
- Différent des outils acheteurs (pas de consolidation PR/PO).
- Actif en v9, complémentaire à Service Requests.
- STU sub-objective §5.2 — Créer et gérer MR / PR / PO / RFQ
- [EOTRAG] Query — « Maximo Desktop Requisitions self-service workflow templates » (confidence 0.98)
- master-map.pdf p.203-207 — IBM Docs Self-Service Purchasing
Bonne réponse : C
Pourquoi cette question existe — STU §5.2 — cette question teste la compréhension du processus automatisé de réapprovisionnement dans Maximo lorsque le stock d'un entrepôt atteint le point de réapprovisionnement (ROP). Les distracteurs montrent les erreurs typiques : confondre le processus automatisé avec des tâches manuelles (D1), invoquer des documents incorrects (D2), ou ignorer l'étape intermédiaire des PR (D3). En pratique terrain, la configuration correcte du Cron Task est essentielle pour déclencher ce processus.
Le contexte théorique d'abord — Le point de réapprovisionnement (ROP) est le niveau de stock auquel une commande doit être passée pour éviter une rupture de stock. Lorsque le stock disponible atteint ce seuil, Maximo déclenche automatiquement un processus de réapprovisionnement via le Cron Task Inventory Reorder. Ce processus génère des demandes d'achat (PR) pour les articles concernés, qui peuvent ensuite être converties en bons de commande (PO).
Ce que Maximo en fait — version opérationnelle — Dans l'application Inventory, l'administrateur configure les règles de réapprovisionnement pour chaque article stocké. Lorsque le stock atteint le ROP, le Cron Task Inventory Reorder s'exécute automatiquement et génère des PR dans l'application Purchase Requisitions. Ces PR peuvent être directement émises ou nécessiter une validation supplémentaire selon la configuration de l'organisation.
Exemple chiffré — Un entrepôt contient 1200 unités d'un article avec un ROP de 300 et une quantité économique de commande (EOQ) de 500. Lorsque le stock atteint 280 unités, le Cron Task génère une PR pour 500 unités. Après validation, cette PR est convertie en PO auprès du fournisseur principal avec un délai de livraison de 7 jours.
Analogie quotidienne — C'est comme un réfrigérateur intelligent qui commande automatiquement du lait lorsque le niveau descend en dessous d'un certain seuil, évitant ainsi de manquer de lait pour le café du matin.
Pourquoi A est faux — Pattern D1 Hérité : Le processus de réapprovisionnement est entièrement automatisé dans Maximo 9.x et ne génère pas de WO pour une intervention manuelle.
Pourquoi B est faux — Pattern D2 Inventé : Le Cron Task ne génère pas directement des factures (Invoice), mais des demandes d'achat (PR) qui peuvent ensuite être converties en PO.
Pourquoi D est faux — Pattern D3 Inverse : Les Desktop Requisitions sont des demandes internes et ne sont pas générées automatiquement par le Cron Task de réapprovisionnement.
- Reorder Point (ROP) — niveau de stock déclenchant une commande.
- Economic Order Quantity (EOQ) — quantité optimale à commander.
- Cron Task — tâche planifiée automatisée dans Maximo.
- Purchase Requisition (PR) — demande d'achat générée automatiquement.
- Purchase Order (PO) — bon de commande émis après validation de la PR.
- ROP déclenche le Cron Task de réapprovisionnement.
- Le Cron Task génère des PR, pas des PO ou des factures.
- La configuration du Cron Task est essentielle pour l'automatisation.
- STU sub-objective §5.2 — Automated Reorder Process
- [EOTRAG] Query — « Maximo Inventory Reorder Cron Task Purchase Requisitions » (confidence 0.98)
- master-map.pdf p.1150-1152 — IBM Docs Managing Reorder Rules
Bonne réponse : D
Pourquoi cette question existe — STU §5.2 — la question teste la compréhension fondamentale du rôle d'un RFQ dans le processus d'achat Maximo. Les distracteurs montrent les erreurs typiques : confondre RFQ avec PO (D3), associer RFQ à des garanties (D2), ou lier RFQ à la réconciliation d'inventaire (D4). En pratique terrain, l'omission de l'étape RFQ est une erreur courante dans les processus d'achat complexes.
Le contexte théorique d'abord — Un RFQ (Request for Quotation) est un document utilisé pour solliciter des offres de prix auprès de plusieurs fournisseurs. Il permet de comparer les propositions avant de passer une commande ferme (PO). Le RFQ est une étape clé dans les processus d'achat complexes ou lorsque les spécifications techniques nécessitent une clarification auprès des fournisseurs.
Ce que Maximo en fait — version opérationnelle — Application Request for Quotations > Create New RFQ > spécifier les détails (fournisseurs, articles, quantités) > Envoyer aux fournisseurs (statut SENT) > Recevoir les réponses > Comparer les offres > Sélectionner le meilleur fournisseur > Convertir en PO.
Exemple chiffré — Pour un achat de 500 unités d'un composant, 3 fournisseurs répondent : Fournisseur A = 12€/unité, Fournisseur B = 11.5€/unité, Fournisseur C = 13€/unité. Après négociation, Fournisseur B réduit à 11€/unité, économisant ainsi 500€ sur l'achat total.
Analogie quotidienne — C'est comme demander des devis à plusieurs garages pour réparer votre voiture : vous comparez les prix et les services avant de choisir le meilleur rapport qualité-prix.
Pourquoi A est faux — Pattern D3 inverse : Un RFQ n'est pas un PO, il ne lie pas contractuellement l'acheteur à un fournisseur.
Pourquoi B est faux — Pattern D2 inventé : Les RFQ ne sont pas utilisés pour les extensions de garantie, qui relèvent des contrats de maintenance.
Pourquoi C est faux — Pattern D4 demi-vérité : La réconciliation des quantités reçues est une étape postérieure à l'émission du PO, pas du RFQ.
- RFQ — Request for Quotation, sollicitation d'offres auprès de fournisseurs.
- PO — Purchase Order, commande ferme passée à un fournisseur.
- Statut SENT — Indique que le RFQ a été envoyé aux fournisseurs.
- Comparaison d'offres — Étape clé avant la sélection du fournisseur.
- Conversion en PO — Transformation du RFQ en commande ferme.
- RFQ = sollicitation d'offres, pas commande ferme.
- Comparer plusieurs offres avant de choisir.
- Statut SENT = RFQ envoyé aux fournisseurs.
- STU sub-objective §5.2 — Créer et gérer MR / PR / PO / RFQ
- [EOTRAG] Query — « Maximo RFQ purpose comparison multiple vendors » (confidence 0.98)
- master-map.pdf p.914-915 — IBM Docs Purchasing module
Bonne réponse : A
Pourquoi cette question existe — STU §5.2 — cette question teste la compréhension du flux P2P (Procure-to-Pay) dans Maximo, en particulier l'ordre correct des étapes depuis l'identification d'un besoin jusqu'au paiement du fournisseur. Les distracteurs montrent des erreurs courantes comme l'inversion des étapes (D3), l'introduction de concepts non pertinents (D7), ou l'ajout d'étapes superflues (D10). En pratique terrain, une mauvaise compréhension de ce flux peut entraîner des retards dans les approvisionnements.
Le contexte théorique d'abord — Le flux P2P dans Maximo suit une séquence logique : identification du besoin (MR/PR), création d'une demande de devis (RFQ) si nécessaire, génération d'un bon de commande (PO), réception des marchandises ou services (Receipt), et enfin facturation (Invoice). Chaque étape est liée à des statuts spécifiques dans les applications Purchase Requisitions, Purchase Orders, et Receiving.
Ce que Maximo en fait — version opérationnelle — Dans l'application Purchase Requisitions, un utilisateur crée une demande d'achat (PR) qui peut être approuvée selon des seuils prédéfinis (ex: $500, $1000, $5000). Si un devis est nécessaire, une RFQ est générée dans Request for Quotations. Une fois le fournisseur choisi, un PO est créé dans Purchase Orders. Après réception des marchandises dans Receiving, la facture est enregistrée dans Invoices pour paiement.
Exemple chiffré — Un besoin de 150 unités d'un item à $12/unité génère une PR de $1800. Après approbation du manager, une RFQ est envoyée à 3 fournisseurs. Le PO est créé pour le fournisseur offrant le meilleur prix à $10/unité, soit un total de $1500. Les marchandises sont reçues et la facture de $1500 est payée.
Analogie quotidienne — C'est comme commander un repas en ligne : tu identifies ton besoin (menu), tu compares les prix (RFQ), tu passes commande (PO), tu reçois ton repas (Receipt), et tu paies la facture (Invoice).
Pourquoi B est faux — Pattern D3 inverse : le PO ne peut pas précéder la MR/PR, car il faut d'abord identifier le besoin avant de commander.
Pourquoi C est faux — Pattern D7 inexistant : « Desktop Requisition » et « Quote Comparison Matrix » ne sont pas des étapes ou des applications reconnues dans le flux P2P de Maximo.
Pourquoi D est faux — Pattern D10 procédure-plausible : bien que la comparaison des devis soit une pratique courante, elle n'est pas une étape obligatoire dans le flux standard P2P de Maximo.
- MR/PR — Material Request / Purchase Requisition : identification du besoin.
- RFQ — Request for Quotation : demande de devis auprès des fournisseurs.
- PO — Purchase Order : bon de commande formalisé.
- Receipt — Réception des marchandises ou services.
- Invoice — Facture pour paiement du fournisseur.
- Le flux P2P commence par MR/PR et se termine par Invoice.
- RFQ est optionnel selon les besoins d'approvisionnement.
- PO ne peut être généré qu'après approbation de la PR.
- STU sub-objective §5.2 — Procure-to-Pay (P2P) flow
- [EOTRAG] Query — « Maximo P2P flow MR PR RFQ PO Receipt Invoice » (confidence 0.93)
- master-map.pdf p.210-215 — IBM Docs Procure-to-Pay Process
Bonne réponse : D
Pourquoi cette question existe — STU §5.2 — cette question vérifie la compréhension des implications du champ Internal sur une Purchase Requisition. Lorsqu'une demande est marquée comme interne, Maximo attend des informations spécifiques sur le stockage pour gérer le transfert entre magasins. Les distracteurs testent les confusions courantes entre les champs liés aux commandes externes (D6) et ceux requis pour les transferts internes.
Le contexte théorique d'abord — Le champ Internal sur une Purchase Requisition indique qu'il s'agit d'un transfert entre entités internes plutôt que d'un achat externe. Lorsqu'activé, le système nécessite l'identification du Storeroom destination pour gérer correctement le mouvement des items. Ce mécanisme diffère des achats externes où les champs comme Company ou Ship Via deviennent prioritaires.
Ce que Maximo en fait — version opérationnelle — Dans l'application Purchase Requisitions, cocher la case Internal dans l'en-tête active la validation du champ Storeroom. L'utilisateur doit alors sélectionner un magasin valide dans la liste déroulante. Sans cette information, l'enregistrement ne peut être sauvegardé, contrairement aux PR externes où d'autres champs prennent le relais.
Exemple chiffré — Pour un transfert entre le magasin CENTRAL (stock actuel : 1 247 unités) et le magasin SATELLITE (stock actuel : 512 unités), le système bloque la validation si le champ Storeroom reste vide, affichant l'erreur "REQSTOREROOM" après 3 tentatives de sauvegarde.
Analogie quotidienne — C'est comme préparer un colis pour un collègue dans le même bâtiment : inutile de préciser le transporteur (DHL), mais obligatoire d'indiquer le bureau de destination (service comptabilité, 3ème étage).
Pourquoi A est faux — Pattern D6 Mauvaise-app : Work Order est lié à la gestion des travaux dans Work Order Tracking, non au transfert interne de stock.
Pourquoi B est faux — Pattern D3 Inverse : Ship Via concerne exclusivement les livraisons externes et devient même masqué pour les PR internes.
Pourquoi C est faux — Pattern D4 Demi-vérité : Company est requis pour les achats externes mais optionnel pour les transferts entre magasins d'une même organisation.
- Internal flag — indique un transfert entre entités internes.
- Storeroom — magasin destination pour les transferts internes.
- PR Types — distinction entre Stock/Direct Purchase et Transfer.
- Validation rules — changent selon le contexte (interne/externe).
- Inter-Org Transfer — nécessite des configurations supplémentaires.
- Internal PR = Storeroom obligatoire, Company optionnel.
- Work Order/Ship Via sans rapport avec les transferts internes.
- Le système adapte ses validations au type de PR (interne/externe).
- STU sub-objective §5.2 — Purchase Requisition Internal flag behavior
- [EOTRAG] Query — « Maximo Purchase Requisition Internal field mandatory storeroom » (confidence 0.89)
- master-map.pdf p.203-207 — IBM Docs Materials Management
Correct order: A → B → C → D (PR → RFQ → PO → Invoice)
Pourquoi cet ordre — Le flux canonique externe commence par une Purchase Requisition (demande d'achat émise par le business / storeroom). Si la valeur / politique l'exige, une Request for Quotation (RFQ) est émise auprès de plusieurs vendors pour comparer les prix ; la Best Bid est sélectionnée et transformée en Purchase Order (PO) engageant l'Org auprès du vendor. Après réception (Receiving — step non inclus dans ce drag-drop), le vendor envoie une Invoice qui est matchée contre le PO + les receipts dans Maximo pour payment. RFQ est optionnel (skippé pour achats de faible valeur ou catalog) ; pour un test drag-drop, IBM l'inclut systématiquement en position 2.
- Maximo Secrets — Maximo Manage Procurement (Portaluri, 2018) : End-to-end P2P flow
- IBM Docs — Purchasing overview : Canonical flow
- IBM Docs — Creating POs from PRs : Step-by-step conversion
Réception, création PO et facturation
📋 Objectifs IBM
- Comprendre le processus de réception des biens et services dans Maximo Manage.
- Maîtriser la création et la gestion des bons de commande (PO) à partir des demandes d'achat (PR).
- Saisir et valider les factures fournisseurs dans l'application Invoices.
- Identifier les actions clés pour lier les réceptions et les bons de commande aux factures.
- Appréhender le cycle de vie complet de l'approvisionnement, de la demande à la facturation.
- Distinguer les rôles des applications Receiving, Purchase Orders et Invoices dans le processus d'achat.
💡 Points clés
- Purchase Requisition (PR) — Demande interne pour des articles, fournitures ou services, point de départ du processus d'achat.
- Purchase Order (PO) — Bon de commande externe créé à partir d'une PR, engageant l'entreprise auprès d'un fournisseur.
- Receiving — Processus d'enregistrement de la livraison des articles ou de la prestation des services commandés via un PO.
- Invoices — Application utilisée pour saisir et traiter les factures des fournisseurs, les liant aux PO et réceptions correspondantes.
- Copy PR Line Items to PO — Action clé dans l'application
Purchase Orderspour générer un PO à partir des lignes d'une PR. - Copy PO Lines — Action dans l'application
Invoicespour importer les lignes d'un PO ou d'une réception dans une facture. - Statuts de facture — Indiquent l'état d'avancement du traitement d'une facture, de la création à l'approbation.
- Intégration — Le processus d'achat dans Maximo est fortement intégré, reliant les PR, PO, réceptions et factures pour une traçabilité complète.
📐 Architecture du processus d'approvisionnement
Le processus d'approvisionnement dans Maximo Manage est une séquence structurée d'applications et d'actions, conçue pour optimiser la gestion des achats de biens et services. Il débute par une demande interne et se conclut par le paiement au fournisseur, en passant par des étapes de commande, de réception et de facturation. Cette architecture garantit une traçabilité complète et une conformité aux politiques d'achat de l'entreprise.
Chaque étape est gérée par une application dédiée, permettant une spécialisation des tâches et une meilleure maîtrise des données. L'intégration entre ces applications est fondamentale, car elle permet le transfert automatique d'informations et la validation croisée des données, réduisant ainsi les erreurs et les délais de traitement. La cohérence des données est assurée par des liens entre les enregistrements, tels que les numéros de PR, de PO et de facture.
📊 Tableau de référence : Applications clés du processus d'achat
| Application Maximo | Rôle principal | Actions clés | Impact sur le processus |
|---|---|---|---|
Purchase Requisitions | Création et approbation des demandes d'achat internes. | Créer PR, Approuver PR, Générer PO. | Initialise le besoin, consolide les demandes. |
Purchase Orders | Génération et gestion des bons de commande externes aux fournisseurs. | Copy PR Line Items to PO, Réviser PO, Approuver PO. | Formalise l'engagement d'achat, définit les termes. |
Receiving | Enregistrement de la réception physique des biens ou de la prestation des services. | Select Ordered Items, Select Ordered Services, Enregistrer réception. | Confirme la livraison, met à jour l'inventaire, permet la facturation. |
Invoices | Saisie et traitement des factures fournisseurs. | Copy PO Lines, Valider facture, Approuver facture. | Déclenche le processus de paiement, rapproche les coûts. |
⚙️ Gestion opérationnelle de la réception, commande et facturation
La gestion opérationnelle de l'approvisionnement dans Maximo Manage est un processus séquentiel qui assure que les biens et services sont commandés, reçus et payés de manière efficace et conforme. Chaque étape est cruciale pour maintenir l'intégrité des données financières et d'inventaire.
Le processus débute souvent par une demande d'achat (PR) qui, une fois approuvée, est convertie en un ou plusieurs bons de commande (PO). Ces PO sont ensuite envoyés aux fournisseurs. À la réception des biens ou services, l'enregistrement précis dans Maximo est essentiel. Enfin, la facture du fournisseur est traitée, en la rapprochant des PO et réceptions correspondantes avant approbation pour paiement.
- Création de la demande d'achat (PR) — Un utilisateur identifie un besoin pour des articles, des fournitures ou des services. Il crée un enregistrement dans l'application
Purchase Requisitions, spécifiant les détails comme la quantité, la description, le site et l'organisation. Par exemple, une PR pour deux ordinateurs portables, un logiciel et des services de programmation (1000 heures chacun). - Approbation de la PR — La PR passe par un workflow d'approbation interne. Une fois approuvée, elle est prête à être convertie en PO.
- Création du bon de commande (PO) — Dans l'application
Purchase Orders, l'actionCopy PR Line Items to POest utilisée pour transférer les lignes de la PR approuvée vers un nouveau PO. Plusieurs PO peuvent être créés à partir d'une seule PR si différents fournisseurs sont impliqués. Par exemple, un PO pour les ordinateurs, un autre pour le logiciel, et un troisième pour les services. - Approbation du PO — Le PO est soumis à son propre processus d'approbation. Une fois approuvé, il est envoyé au fournisseur.
- Réception des articles ou services — Lorsque les articles sont livrés ou les services rendus, l'application
Receivingest utilisée pour enregistrer la réception. L'utilisateur sélectionne le PO concerné, puis utilise les actionsSelect Ordered ItemsouSelect Ordered Servicespour marquer les lignes comme reçues. Par exemple, la réception des deux ordinateurs et du logiciel. - Enregistrement de la facture fournisseur — Une fois la facture du fournisseur reçue, elle est saisie dans l'application
Invoices. L'actionCopy PO Linesest utilisée pour importer les lignes du PO ou des réceptions correspondantes dans la facture. Cela permet de rapprocher la facture des commandes et des livraisons. - Validation et approbation de la facture — La facture est vérifiée par rapport au PO et aux réceptions. Des écarts peuvent nécessiter une résolution. Une fois validée, la facture est soumise à approbation, ce qui autorise le paiement au fournisseur. Les statuts de facture, tels que
ENTERED,APPROVED,PAID, suivent son cycle de vie.
🔄 Workflow de la facturation fournisseur
Le workflow de la facturation fournisseur est une étape critique du cycle d'approvisionnement, garantissant que les paiements sont effectués correctement et en temps voulu. Il implique plusieurs statuts de facture qui reflètent son avancement, de la création à l'approbation finale.
Ce processus assure la conformité financière et le rapprochement des dépenses avec les commandes et les réceptions. La capacité de Maximo à lier directement les factures aux bons de commande et aux enregistrements de réception est fondamentale pour l'audit et la gestion des coûts.
⚠️ Pièges IBM
Un piège courant est de créer une facture dans l'application Invoices sans utiliser l'action Copy PO Lines pour lier les lignes de commande ou de réception. Cela peut entraîner des factures non rapprochées, des erreurs de paiement, et une difficulté à suivre les coûts réels par rapport aux commandes. Maximo est conçu pour l'intégration, et ignorer cette fonctionnalité brise la chaîne de traçabilité.
Lors de la réception d'articles ou de services, il est crucial de distinguer une réception partielle d'une réception complète. Si un PO de 100 unités est reçu en deux fois (50 puis 50), chaque réception doit être enregistrée séparément dans l'application Receiving. Ne pas le faire, ou enregistrer la totalité dès la première livraison partielle, peut fausser les niveaux d'inventaire et compliquer le rapprochement avec la facture finale qui pourrait arriver après la livraison complète.
Les unités de mesure (UoM) doivent être cohérentes tout au long du processus d'achat. Si un article est commandé en "paquets" mais reçu en "unités", ou si la facture utilise une UoM différente, cela peut entraîner des erreurs de quantité et de coût lors du rapprochement. Maximo permet de définir des UoM spécifiques, mais la vigilance est de mise lors de la saisie et de la vérification des données à chaque étape.
🎯 Carte mémoire
Quelle est l'action clé pour générer un bon de commande (PO) à partir d'une demande d'achat (PR) approuvée dans Maximo?
L'action clé est Copy PR Line Items to PO, disponible dans l'application Purchase Orders. Elle permet de transférer les détails des lignes de la PR vers un nouveau PO, assurant ainsi la continuité des informations.
Comment Maximo assure-t-il le rapprochement entre une facture fournisseur et les articles ou services reçus?
Maximo utilise l'action Copy PO Lines dans l'application Invoices. Cette action permet d'importer les lignes d'un bon de commande (PO) ou d'une réception directement dans la facture, facilitant ainsi la vérification et le rapprochement des quantités et des coûts.
Quelles sont les trois applications principales impliquées dans le cycle complet d'approvisionnement, de la demande à la facturation?
Les trois applications principales sont Purchase Requisitions (pour les demandes internes), Purchase Orders (pour les commandes externes aux fournisseurs), Receiving (pour l'enregistrement des livraisons) et Invoices (pour le traitement des factures fournisseurs).
Bonne réponse : C
Pourquoi cette question existe — STU §5.3 — la question teste la compréhension des différents types de factures pris en charge dans Maximo Manage 9.0. Les distracteurs montrent des erreurs courantes : confondre les statuts de facture avec les types (D4), mélanger des concepts fiscaux (D2), ou inventer des catégories non supportées (D7). En pratique terrain, choisir le bon type de facture est crucial pour la gestion des achats et la comptabilité.
Le contexte théorique d'abord — Les factures dans Maximo sont classées selon leur relation avec les commandes d'achat (PO) et les sites. Les types de factures sont définis par leur structure et leur contexte d'utilisation : Single-PO (une facture pour une PO), Multi-PO single vendor (plusieurs PO d'un même fournisseur), No-PO (facture sans PO associée), Multi-site (facture couvrant plusieurs sites), et Consignment (facture pour des stocks en consignation).
Ce que Maximo en fait — version opérationnelle — Application Invoices > Add New Invoice > sélection du type de facture dans le champ Invoice Type. Les lignes de facture peuvent être copiées depuis les PO ou les réceptions via l'action Copy PO Lines. Les factures sont ensuite approuvées et payées selon leur statut.
Exemple chiffré — Site BEDFORD : 12 factures Single-PO, 3 Multi-PO single vendor, 5 No-PO, 2 Multi-site, et 1 Consignment. Site GATINEAU : 8 factures Single-PO, 2 Multi-PO single vendor, 4 No-PO, 1 Multi-site, et aucune Consignment.
Analogie quotidienne — C'est comme choisir le bon type de ticket de caisse : ticket simple (Single-PO), ticket regroupé (Multi-PO), ticket sans référence (No-PO), ticket multi-magasin (Multi-site), ou ticket consignation (Consignment).
Pourquoi A est faux — Pattern D2 inventé : Proforma, Commercial, Customs, VAT, et Credit Memo sont des concepts fiscaux, pas des types de factures supportés dans Maximo.
Pourquoi B est faux — Pattern D7 inexistant : Standard, Recurring, Prepaid, Deferred, et Final ne sont pas des types de factures définis dans Maximo Manage 9.0.
Pourquoi D est faux — Pattern D4 demi-vérité : Draft, Approved, Paid, Disputed, et Void sont des statuts de facture, pas des types.
- Single-PO — une facture pour une commande d'achat.
- Multi-PO single vendor — plusieurs PO d'un même fournisseur.
- No-PO — facture sans PO associée.
- Multi-site — facture couvrant plusieurs sites.
- Consignment — facture pour des stocks en consignation.
- 5 types de factures : Single-PO, Multi-PO single vendor, No-PO, Multi-site, Consignment.
- Statuts ≠ types : Draft, Approved, Paid, Disputed, Void sont des statuts.
- Copie des lignes de PO via
Copy PO Lines.
- STU sub-objective §5.3 — Types de factures dans Maximo Manage 9.0
- [EOTRAG] Query — « Maximo Manage 9.0 invoice types Single-PO Multi-PO No-PO Multi-site Consignment » (confidence 0.98)
- master-map.pdf p.948-950 — IBM Docs Invoice Types
Bonne réponse : D
Pourquoi cette question existe — STU §5.3 — la question vérifie la compréhension du rôle spécifique des HOLDING locations dans le processus de réception Maximo. Les distracteurs ciblent les confusions courantes : gestion des retours (A), stockage des actifs (B) et workflow de facturation (C). En pratique terrain, l'omission des HOLDING locations est une erreur fréquente dans les configurations multi-sites.
Le contexte théorique d'abord — Une HOLDING location est un emplacement temporaire défini au niveau du SITE où les articles reçus sont placés en attente d'inspection avant transfert vers le stockage définitif. Elle permet de séparer physiquement les articles non validés des stocks actifs. Le champ LOCATION dans INVRECEIVE référence cette HOLDING location durant le processus.
Ce que Maximo en fait — version opérationnelle — Dans l'application Locations > Add New : Type = HOLDING, Niveau = SITE, Site ID = [votre site]. Lors de la réception via Receiving, les articles sont automatiquement dirigés vers cette location avec le statut INSPECTION. Après validation, un transfert manuel ou automatisé les déplace vers les STOREROOMS.
Exemple chiffré — Site PARIS : 145 articles reçus le 15/01, 12 en attente d'inspection (HOLDING), 133 déjà transférés. Site LYON : 89 articles reçus, taux d'inspection moyen de 72h avant transfert vers 3 storerooms différents.
Analogie quotidienne — C'est comme une zone de quarantaine à l'entrée d'un entrepôt : tous les colis y passent avant d'être vérifiés et rangés à leur place définitive.
Pourquoi A est faux — Pattern D6 mauvaise-app : le retour au fournisseur se gère via Returns, pas dans les HOLDING locations.
Pourquoi B est faux — Pattern D5 champ-frère : les actifs décommissionnés utilisent LOCATIONS spécialisées, pas les HOLDING.
Pourquoi C est faux — Pattern D7 inexistant : Maximo ne gère pas les workflows de facturation dans les locations physiques.
- HOLDING location — emplacement temporaire pour inspection pré-stockage.
INVRECEIVE— table des réceptions avec champLOCATION.STOREROOMS— emplacements de stockage définitifs.INSPECTION— statut des articles en attente de validation.SITE— niveau hiérarchique obligatoire pour les HOLDING locations.
- HOLDING = zone tampon avant inspection obligatoire.
- Définie au niveau SITE, pas ORG.
- Statut associé :
INSPECTIONavant transfert.
- STU sub-objective §5.3 — Receiving Process Locations
- [EOTRAG] Query — « Maximo HOLDING location purpose inspection » (confidence 0.98)
- master-map.pdf p.201-203 — IBM Docs Inventory Receiving
Bonne réponse : A
Pourquoi cette question existe — STU §5.3 — cette question vérifie la compréhension du processus automatisé de création d'actifs pour les Rotating Items. Les distracteurs ciblent les confusions courantes : émission directe vers WO (D4), gestion par quantité pure (D2), et procédure manuelle héritée (D1). En pratique, cette automatisation est cruciale pour la traçabilité des équipements rotatifs comme les moteurs ou pompes.
Le contexte théorique d'abord — Un Rotating Item est un article suivi par numéro de série (ITEM.Rotating?=1) qui nécessite la création d'un actif (ASSET) lors de la réception. Maximo gère automatiquement cette "assetization" via le statut NOT READY pour les nouveaux actifs, permettant leur configuration ultérieure. La table INVRES enregistre la sérialisation.
Ce que Maximo en fait — version opérationnelle — Dans Receiving app, lors de la réception d'un PO contenant un Rotating Item : 1) Maximo crée un enregistrement dans ASSET avec ASSETSTATUS='NOT READY', 2) génère un numéro de série dans INVRES.SERIALNUM, 3) lie l'actif au PO via PO.ITEMNUM. L'utilisateur complète ensuite les détails de l'actif.
Exemple chiffré — Réception de 3 pompes (Rotating Items) sur PO-2024-567 : création de 3 actifs (PMP-001 à PMP-003) avec statut NOT READY, stockés dans le storeroom SITE1-WH (12 emplacements libres), coût unitaire 1 850 € dans INVCOST.
Analogie quotidienne — Comme recevoir un colis suivi : le livreur scanne automatiquement le code-barres (sérialisation), crée une entrée dans le système (actif NOT READY), puis vous complétez les détails (emplacement, affectation) plus tard.
Pourquoi B est faux — L'émission vers Work Order intervient après réception, via l'app Issues and Returns, pas automatiquement à la réception. (Pattern D4 Demi-vérité)
Pourquoi C est faux — Les Rotating Items sont toujours suivis par numéro de série, jamais par quantité seule. (Pattern D2 Inventé)
Pourquoi D est faux — Maximo 9.x automatise la création d'actifs, contrairement aux anciennes versions où c'était manuel. (Pattern D1 Hérité)
- Rotating? — flag indiquant qu'un item nécessite un suivi par série.
- NOT READY — statut initial des actifs créés automatiquement.
- Auto-assetization — création automatique d'actif lors de la réception.
- INVRES — table gérant les réservations d'articles sérialisés.
- Receiving workflow — flux PO → Réception → Asset/Inventory.
- Réception Rotating Item → création auto d'actif NOT READY.
- Sérialisation obligatoire via
INVRES.SERIALNUM. - Pas d'émission directe vers WO à la réception.
- STU sub-objective §5.3 — Rotating Items et création automatique d'actifs
- [EOTRAG] Query — « Maximo Rotating Item PO receipt automatic asset creation » (confidence 0.92)
- master-map.pdf p.203-207 — IBM Docs Inventory Receiving Processes
Bonne réponse : B
Pourquoi cette question existe — STU §5.3 — cette question teste la compréhension des transactions d'inventaire spécifiques aux transferts entre sites ou entreposages sous PO. Les erreurs courantes incluent la confusion entre les types de transactions (D5) ou l'utilisation de procédures alternatives non natives (D10). En pratique, cette distinction est cruciale pour le suivi précis des mouvements d'actifs.
Le contexte théorique d'abord — La table MATRECTRANS enregistre toutes les transactions matérielles dans Maximo. Chaque transaction est typée (issuetype) selon son origine : réception (RECEIPT), transfert (SHIPTRANSFER), ajustement (ADJUSTMENT), ou émission (ISSUE). Les transferts sous PO utilisent spécifiquement le type SHIPTRANSFER pour tracer le mouvement entre sites/storerooms.
Ce que Maximo en fait — version opérationnelle — Dans l'application Inventory > Transfers, la création d'un transfert inter-sites génère une entrée dans MATRECTRANS avec issuetype='SHIPTRANSFER' et lie le ponum correspondant. Le processus inclut la sélection des items (ex: itemnum='D600'), des quantités, et des sites source/destination.
Exemple chiffré — Transfert de 2 unités de l'item D600 (site BEDFORD, storeroom CENTRAL) vers le site GATINEAU : transaction enregistrée avec receiptquantity=2, itemnum='D600', tostoreloc='GATINEAU', et issuetype='SHIPTRANSFER'.
Analogie quotidienne — Comme un bon de livraison entre deux entrepôts d'une même entreprise : le document (SHIPTRANSFER) prouve le mouvement et permet de réconcilier les stocks des deux sites.
Pourquoi A est faux — Pattern D5 Champ-frère : RECEIPT est utilisé pour les entrées en stock depuis un fournisseur externe, pas pour les transferts internes.
Pourquoi C est faux — Pattern D10 Procédure-plausible : un ADJUSTMENT pourrait techniquement modifier les stocks, mais contourne le processus natif de traçabilité des transferts sous PO.
Pourquoi D est faux — Pattern D3 Inverse : ISSUE enregistre la sortie de stock vers un consommateur (ex: travail), pas un transfert vers un autre site/storeroom.
- MATRECTRANS — table centrale des transactions matérielles.
- issuetype — champ clé différenciant RECEIPT, SHIPTRANSFER, etc.
- Transfer PO — PO spécialisé pour les mouvements inter-sites.
- itemnum — identifiant de l'item transféré.
- tostoreloc — destination du transfert.
- SHIPTRANSFER = type de transaction pour les transferts sous PO.
- RECEIPT/ISSUE/ADJUSTMENT ont des usages distincts.
- La table MATRECTRANS trace tous les mouvements.
- STU sub-objective §5.3 — Transactions d'inventaire et PO
- [EOTRAG] Query — « MATRECTRANS SHIPTRANSFER transfer PO between sites » (confidence 0.87)
- master-map.pdf p.215-218 — IBM Docs Inventory Transactions
Bonne réponse : D
Pourquoi cette question existe — STU §5.3 — cette question vérifie la compréhension du processus de contrôle qualité lors de la réception des marchandises. Les options incorrectes représentent des erreurs courantes : confondre l'inspection avec d'autres étapes du cycle (D6), ou croire que la validation se fait automatiquement (D2). En pratique, l'étape d'inspection est cruciale pour éviter des problèmes ultérieurs avec des pièces non conformes.
Le contexte théorique d'abord — Dans le processus de réception, les marchandises peuvent être placées dans un emplacement temporaire (HOLDING) avant inspection. Cette étape permet de vérifier la conformité des articles reçus par rapport aux spécifications du bon de commande et aux standards qualité avant leur mise en stock ou leur utilisation. Seuls les articles validés peuvent quitter cet emplacement.
Ce que Maximo en fait — version opérationnelle — Dans l'application Receiving, après réception physique, les articles sont marqués comme étant en HOLDING. L'utilisateur doit alors accéder à la fonction Inspection pour valider chaque ligne. Une fois approuvés, les articles passent au statut approprié et peuvent être transférés vers leur emplacement final ou utilisés directement.
Exemple chiffré — Un entrepôt reçoit 150 pièces détachées (valeur totale 12 500 €) sur un PO. Après inspection : 142 pièces conformes (11 800 €), 5 avec défauts mineurs (400 €, nécessitent réparation), 3 non conformes (300 €, retour au fournisseur). Le taux de non-conformité est de 2% en quantité, 2,4% en valeur.
Analogie quotidienne — C'est comme le contrôle qualité dans un restaurant : les ingrédients livrés sont inspectés avant d'être stockés ou utilisés. Les produits douteux sont mis de côté (HOLDING) jusqu'à validation ou rejet.
Pourquoi A est faux — Pattern D6 mauvaise-app : Void Receipt annule complètement une réception, sans rapport avec le contrôle qualité.
Pourquoi B est faux — Pattern D4 demi-vérité : Return to Vendor intervient après inspection, mais ne la remplace pas.
Pourquoi C est faux — Pattern D2 inventé : Invoice Match concerne la réconciliation financière, pas la validation physique des marchandises.
- HOLDING location — emplacement temporaire pour articles en attente d'inspection.
- Inspection process — validation qualité avant mise en stock.
- Receiving workflow — séquence des étapes de réception à facturation.
- Quality standards — critères de conformité des articles reçus.
- Non-conformance handling — traitement des articles défectueux.
- L'inspection qualité se fait sur les articles en HOLDING.
- Seuls les articles validés peuvent quitter cet emplacement.
- Les autres options concernent des étapes différentes du cycle.
- STU sub-objective §5.3 — Receiving and inspection process
- [EOTRAG] Query — « Maximo receiving inspection HOLDING location process » (confidence 0.92)
- master-map.pdf p.203-207 — IBM Docs Receiving and Inspection
Bonne réponse : B
Pourquoi cette question existe — STU §5.3 — cette question teste la compréhension des types de transactions dans MATRECTRANS lors d'un retour fournisseur. Le piège courant est de confondre RECEIPT (entrée) et RETURN (sortie), ou de mal interpréter le signe des quantités. En pratique terrain, cette distinction est cruciale pour le suivi des stocks et la réconciliation comptable.
Le contexte théorique d'abord — La table MATRECTRANS enregistre tous les mouvements de matières. Chaque transaction a un type (ex: RECEIPT, RETURN) et une quantité (positive pour les entrées, négative pour les sorties). Un retour fournisseur est une sortie de stock, donc enregistrée avec une quantité négative et le type RETURN.
Ce que Maximo en fait — version opérationnelle — Dans l'app Receiving > sélectionner le PO > action Return to Vendor : Maximo crée une ligne dans MATRECTRANS avec TRANSTYPE='RETURN' et QUANTITY=-XX (valeur négative). Le statut passe à RETURNED dans MATUSETRANS.
Exemple chiffré — Retour de 12 roulements FAG (ITEMNUM=BRG-205) : MATRECTRANS enregistre TRANSTYPE=RETURN, QUANTITY=-12, ITEMNUM=BRG-205, SITEID=WAREHOUSE1. Le stock passe de 58 à 46 unités.
Analogie quotidienne — Comme un ticket de caisse avec "RETOUR" en gros : on rend 2 paquets de pâtes, donc la quantité est -2 et le motif est clairement indiqué.
Pourquoi A est faux — RECEIPT est utilisé pour les entrées, pas les sorties. Même avec une quantité négative, ce n'est pas le bon type de transaction. (Pattern D3 Inverse)
Pourquoi C est faux — ADJUSTMENT sert à corriger des écarts d'inventaire, pas à gérer des retours fournisseurs. (Pattern D6 Mauvaise-app)
Pourquoi D est faux — "VENDOR VOID" n'existe pas comme type de transaction dans MATRECTRANS. (Pattern D7 Inexistant)
- MATRECTRANS — table des transactions de réception/retour.
- TRANSTYPE — champ indiquant le type de transaction (RECEIPT, RETURN...).
- QUANTITY — positif pour les entrées, négatif pour les sorties.
- Return to Vendor — action dans l'app Receiving pour initier un retour.
- MATUSETRANS — table liée, mise à jour avec le statut RETURNED.
- RETURN + quantité négative pour les retours fournisseurs.
- RECEIPT = entrée (quantité positive), RETURN = sortie (négative).
- Action "Return to Vendor" dans l'app Receiving.
- STU sub-objective §5.3 — Receiving and Returns
- [EOTRAG] Query — « MATRECTRANS RETURN transaction type negative quantity » (confidence 0.95)
- master-map.pdf p.201-204 — IBM Docs Inventory Transactions
Bonne réponse : A
Pourquoi cette question existe — STU §5.3 — cette question teste la compréhension du comportement par défaut de Maximo lors de l'approbation d'une facture lorsque la quantité facturée dépasse la quantité reçue, tout en restant dans la tolérance définie. Les distracteurs montrent des erreurs courantes : bloquer l'approbation (D3), modifier automatiquement la quantité reçue (D2), ou créer une nouvelle demande d'achat (D10). En pratique, la gestion des écarts de facturation est cruciale pour la comptabilité et la gestion des stocks.
Le contexte théorique d'abord — Lors de l'approbation d'une facture, Maximo vérifie si la quantité facturée dépasse la quantité reçue. Si l'écart reste dans la tolérance définie au niveau de l'Organization, la facture est approuvée et l'écart est enregistré dans le compte d'écart de facturation (Invoice Variance account) défini dans le plan comptable. Ce mécanisme permet de gérer les écarts temporaires sans bloquer le processus d'approbation.
Ce que Maximo en fait — version opérationnelle — Dans l'application Invoice, lors de l'approbation d'une facture, Maximo compare la quantité facturée (INVOICEQTY) à la quantité reçue (RECEIVEDQTY). Si l'écart est dans la tolérance définie dans l'Organization, la facture est approuvée et l'écart est enregistré dans le compte d'écart de facturation (INVOICEVARACCT). L'écart reste en attente jusqu'à ce que les réceptions restantes soient effectuées ou qu'un ajustement soit réalisé.
Exemple chiffré — Une facture de 12 unités à $100 chacune est approuvée, alors que seulement 10 unités ont été reçues. La tolérance de l'Organization permet un écart de 20%. L'écart de 2 unités ($200) est enregistré dans le compte d'écart de facturation. Le coût moyen initial est de $95, le coût de la facture est de $100, et le coût moyen final devient $97.50 après ajustement.
Analogie quotidienne — C'est comme lorsque vous commandez 12 pizzas mais que seulement 10 sont livrées. Le restaurant vous facture les 12 pizzas, mais vous notez l'écart de 2 pizzas dans votre budget en attendant que les pizzas manquantes soient livrées ou que vous ajustiez votre commande.
Pourquoi B est faux — Pattern D3 inverse : Maximo n'échoue pas l'approbation tant que l'écart reste dans la tolérance définie.
Pourquoi C est faux — Pattern D2 inventé : Maximo ne modifie pas automatiquement la quantité reçue sur le bon de commande pour correspondre à la facture.
Pourquoi D est faux — Pattern D10 procédure-plausible : Maximo ne crée pas automatiquement une nouvelle demande d'achat pour la quantité excédentaire.
- Invoice Variance account — compte utilisé pour enregistrer les écarts de facturation.
- Organization Tolerance — tolérance définie au niveau de l'organisation pour les écarts de facturation.
- INVOICEQTY — quantité facturée dans la facture.
- RECEIVEDQTY — quantité réellement reçue.
- INVOICEVARACCT — compte d'écart de facturation dans le plan comptable.
- L'écart de facturation est enregistré dans le compte d'écart si dans la tolérance.
- La facture est approuvée même si la quantité facturée dépasse la quantité reçue.
- L'écart reste en attente jusqu'à réception ou ajustement.
- STU sub-objective §5.3 — Invoice approval and variance handling
- [EOTRAG] Query — « Maximo invoice approval variance account tolerance » (confidence 0.98)
- master-map.pdf p.1716-1717 — IBM Docs Invoice Processing
Créer et gérer Job Plans et Routes
📋 Objectifs IBM
- Comprendre la fonction et l'importance des
Job Plansdans la planification de la maintenance. - Décrire comment créer et gérer des
Job Planspour diverses activités de travail. - Expliquer l'utilisation des
Routespour regrouper et optimiser les tâches de maintenance. - Démontrer la capacité à associer des
Job Planset desRoutesaux enregistrements de maintenance préventive (PM) et aux ordres de travail (Work Orders). - Identifier les avantages de l'intégration des
Job Planset desRoutespour la conformité réglementaire et l'efficacité opérationnelle. - Distinguer les rôles des
Job Planset desRoutesdans le cycle de vie de la gestion du travail.
💡 Points clés
Job Plan— Une description détaillée du travail à effectuer pour un ordre de travail, incluant les tâches, les ressources (main-d'œuvre, matériaux, outils) et les qualifications requises.Routes— Un ensemble ordonné deLocationsou d'Assetsqui sont visités séquentiellement pour effectuer des tâches de maintenance ou des inspections, souvent utilisées pour regrouper des activités.- Application aux
PM— LesJob Planssont appliqués aux enregistrements de maintenance préventive (PM) pour générer des ordres de travail avec des plans de travail prédéfinis. - Application aux
Work Orders— LesJob Planspeuvent être directement appliqués auxWork Orderspour standardiser les tâches et les ressources nécessaires. - Regroupement avec les
Routes— LesRoutessont utilisées pour regrouper desPMou desWork Ordersafin d'optimiser les déplacements et l'efficacité des techniciens. - Planification des ressources — Les
Job Planspermettent de planifier la main-d'œuvre (Labor), les corps de métier (Craft), les qualifications (Qualification), les matériaux et les outils nécessaires. - Conformité réglementaire — L'utilisation structurée des
Job Planset desRoutesaide à garantir la conformité aux réglementations en documentant les procédures et les exécutions. - Standardisation — Les
Job Planset lesRoutesfavorisent la standardisation des processus de maintenance, réduisant les erreurs et améliorant la qualité du travail.
📐 Architecture des Job Plans et Routes
Les Job Plans et les Routes sont des composants fondamentaux de la planification de la maintenance dans IBM Maximo Manage. Ils fournissent la structure nécessaire pour définir, standardiser et optimiser les activités de travail. Un Job Plan décrit précisément "comment" le travail doit être effectué, tandis qu'une Route définit "où" et "dans quel ordre" les activités doivent avoir lieu.
Ces éléments sont interconnectés avec d'autres modules clés de Maximo, tels que les PM (Preventive Maintenance) et les Work Orders, pour automatiser la génération de travail et assurer une exécution cohérente. L'architecture sous-jacente permet une grande flexibilité dans la définition des tâches, des ressources et des séquences, ce qui est crucial pour une gestion d'actifs efficace.
Job Plans et des Routes avec les PM et les Work Orders. Il illustre comment ces composants définissent les aspects "comment", "où", "quand" et "quoi" de la gestion du travail.📊 Comparaison: Job Plan vs. Route
Bien que les Job Plans et les Routes soient tous deux des outils de planification essentiels dans Maximo, ils servent des objectifs distincts et complémentaires. Comprendre leurs différences est crucial pour une utilisation optimale du système.
Le Job Plan se concentre sur la définition détaillée des étapes d'une tâche spécifique, tandis que la Route organise la séquence géographique ou logique d'exécution de plusieurs tâches sur différents emplacements ou actifs.
| Caractéristique | Job Plan | Route |
|---|---|---|
| Objectif principal | Décrire les étapes et les ressources pour une tâche. | Définir une séquence d'Locations/Assets pour des tâches groupées. |
| Réponse à la question | "Comment" le travail est effectué. | "Où" et "dans quel ordre" le travail est effectué. |
| Contenu typique | Tâches, main-d'œuvre (Labor), corps de métier (Craft), qualifications (Qualification), matériaux, outils, services. | Liste ordonnée de Locations ou d'Assets. |
| Application directe | Aux PM, aux Work Orders. | Aux PM, aux Work Orders (via PM ou directement). |
| Granularité | Détail des opérations pour une seule tâche ou un ensemble de tâches liées. | Séquence d'emplacements ou d'actifs pour des inspections ou maintenances récurrentes. |
| Bénéfice clé | Standardisation des procédures, planification des ressources, efficacité de l'exécution. | Optimisation des déplacements, regroupement des tâches, réduction des coûts de transport. |
| Exemple d'utilisation | Plan de travail pour la révision d'une pompe. | Route d'inspection mensuelle de 12 transformateurs sur un site. |
Job Plans et des Routes, soulignant comment chacun contribue à une planification de maintenance complète et efficace dans Maximo.⚙️ Gestion des Job Plans et des Routes
La création et la gestion des Job Plans et des Routes sont des processus clés pour établir des pratiques de maintenance standardisées et efficaces dans Maximo. Ces outils permettent aux organisations de définir précisément les exigences de travail et d'optimiser l'allocation des ressources.
Un Job Plan est une description détaillée du travail qui est effectué pour un ordre de travail. Il peut inclure des tâches spécifiques, les corps de métier et la main-d'œuvre requise, les matériaux, les outils et les services. Les Routes, quant à elles, sont utilisées pour regrouper des Locations ou des Assets afin de rationaliser les inspections ou les travaux de maintenance récurrents.
- Création d'un
Job Plan— Dans l'applicationJob Plan, un utilisateur définit les tâches séquentielles, les descriptions de travail, les estimations de durée, et associe les ressources nécessaires (Labor,Craft,Item,Tool). Par exemple, unJob Planpour une inspection trimestrielle d'un équipement critique pourrait inclure des tâches comme "Vérifier le niveau d'huile", "Inspecter les courroies" et "Nettoyer les filtres", avec 2 heures de main-d'œuvre pour un mécanicien qualifié. - Application d'un
Job Plan— Une fois créé, unJob Planpeut être appliqué à un enregistrement dePMpour générer automatiquement desWork Ordersavec le plan de travail prédéfini. Il peut également être appliqué directement à unWork Orderexistant via le menu "Plans" dans l'applicationWork Order Tracking, ce qui permet d'intégrer rapidement des tâches et des ressources standardisées. - Création d'une
Route— Dans l'applicationRoutes, un utilisateur définit une séquence deLocationsou d'Assets. Pour chaque point de laRoute, il est possible d'associer unJob Planspécifique. Par exemple, uneRouted'inspection quotidienne pourrait inclure 5Assetsdifférents, chacun avec unJob Pland'inspection visuelle associé. - Application d'une
Route— UneRoutepeut être appliquée à un enregistrement dePMpour générer desWork Orderspour chaqueLocationouAssetde laRoute, en utilisant lesJob Plansassociés. Cela est particulièrement utile pour les inspections récurrentes ou les tâches de maintenance légère sur un ensemble d'équipements similaires ou géographiquement proches. - Mise à jour et révision — Les
Job Planset lesRoutespeuvent être révisés et mis à jour pour refléter les changements dans les procédures de maintenance, les exigences réglementaires ou les spécifications des équipements. Maximo permet de gérer ces révisions pour assurer que les plans de travail restent pertinents et efficaces.
🔄 Cycle de vie des Job Plans et Routes
Le cycle de vie des Job Plans et des Routes est intrinsèquement lié à la planification et à l'exécution de la maintenance dans Maximo. Il commence par la définition des besoins, progresse par la création et l'approbation, et se termine par l'application aux activités de travail, avec des boucles de rétroaction pour l'amélioration continue.
Ces composants sont dynamiques et peuvent être ajustés au fil du temps pour s'adapter aux évolutions des opérations, des équipements ou des réglementations. La gestion de leur cycle de vie est essentielle pour maintenir l'efficacité et la pertinence des stratégies de maintenance.
Job Plans et des Routes, de la définition initiale des besoins à l'analyse post-exécution, en passant par la création, l'approbation et l'application aux ordres de travail.⚠️ Pièges IBM
Job Plan et Work Order
Les candidats peuvent confondre un Job Plan avec un Work Order. Un Job Plan est un modèle ou une description standardisée du travail à effectuer, définissant les tâches, les ressources et les qualifications. Un Work Order est une instance spécifique de travail, générée à partir d'un Job Plan ou créée ad-hoc, pour une Location ou un Asset particulier, à un moment donné. Le Job Plan est le "comment", le Work Order est le "quoi" et "quand". Un Job Plan ne peut pas être exécuté directement ; il doit être appliqué à un PM ou un Work Order pour initier le travail.
Job Plans
Un piège courant est de créer un Job Plan avec des tâches détaillées mais d'omettre d'y associer les ressources nécessaires (Labor, Craft, Item, Tool, Qualification). Lorsque ce Job Plan est appliqué à un PM ou un Work Order, les ordres de travail générés manqueront des informations essentielles pour la planification des ressources et l'estimation des coûts. Cela peut entraîner des retards, des pénuries de matériaux ou de personnel, et une planification inefficace. Il est crucial de s'assurer que toutes les ressources requises sont correctement définies et associées dans le Job Plan.
Routes pour les inspections
Les Routes sont conçues pour optimiser les inspections ou les tâches répétitives sur plusieurs Locations ou Assets. Un piège est de créer des Work Orders individuels pour chaque point d'inspection au lieu d'utiliser une Route. Cela augmente la charge administrative et ne permet pas de bénéficier de l'optimisation des déplacements et du regroupement des tâches qu'offrent les Routes. L'examen peut présenter un scénario où une série d'inspections similaires est requise, et la bonne réponse impliquerait l'utilisation d'une Route associée à un PM.
🎯 Carte mémoire
Quelle est la principale différence fonctionnelle entre un Job Plan et une Route dans Maximo ?
Un Job Plan décrit les étapes détaillées et les ressources (main-d'œuvre, matériaux, outils) nécessaires pour effectuer une tâche spécifique ("comment faire"). Une Route définit une séquence ordonnée de Locations ou d'Assets à visiter pour effectuer des tâches, souvent pour des inspections ou des maintenances groupées ("où et dans quel ordre").
Comment un Job Plan contribue-t-il à la standardisation et à l'efficacité de la maintenance ?
Un Job Plan standardise la maintenance en définissant des procédures cohérentes pour des tâches récurrentes. Il assure que le travail est effectué de la même manière à chaque fois, réduit les erreurs, facilite la formation, et permet une planification précise des ressources, ce qui améliore l'efficacité globale de l'exécution du travail.
Dans quelle application Maximo peut-on associer un Job Plan à un Work Order existant ?
Un Job Plan peut être associé à un Work Order existant via le menu "Plans" dans l'application Work Order Tracking. Cela permet d'intégrer rapidement les détails du plan de travail standardisé au Work Order.
Quel est l'avantage principal d'utiliser une Route pour des inspections régulières sur plusieurs équipements ?
L'avantage principal est l'optimisation des déplacements et le regroupement des tâches. En utilisant une Route, un technicien peut visiter plusieurs Locations ou Assets dans un ordre logique, réduisant le temps de trajet et augmentant l'efficacité des inspections ou des maintenances légères, souvent via un seul Work Order parent ou des Work Orders générés par un PM de Route.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Bonne réponse : D
Pourquoi cette question existe — STU §6.1 — La question teste la compréhension des méthodes de calcul dynamique dans les Job Plans. Les distracteurs montrent les erreurs courantes : confondre calcul statique et dynamique (D4), inventer des fonctionnalités inexistantes (D2), ou mal interpréter les séquences de tâches (D9). En pratique terrain, l'utilisation des méthodes Formula Based ou Meter Based permet d'automatiser 78% des calculs de durée.
Le contexte théorique d'abord — Un Job Plan dans Maximo Manage 9.x peut utiliser deux méthodes de calcul dynamique : Formula Based (basée sur des expressions mathématiques) et Meter Based (basée sur les relevés de compteurs). Ces méthodes s'appliquent lors de la génération du WO et peuvent affecter ESTDUR, LABOREST et la séquence des tâches. Les formules utilisent des variables comme :meterreading ou :assetage.
Ce que Maximo en fait — version opérationnelle — Application Job Plans → Créer un nouveau Job Plan → Dans l'onglet Tasks, sélectionner Dynamic Calculation Method et choisir entre Formula Based (pour des expressions) ou Meter Based (pour les relevés). Configurer ensuite les paramètres spécifiques à chaque méthode dans les champs correspondants.
Exemple chiffré — Pour un parc de 247 pompes : avec Formula Based (ESTDUR = :meterreading × 0.25), la durée estimée passe de 4h à 6h quand le relevé augmente de 16 à 24 unités. Avec Meter Based (seuil à 500h), 83% des WOs voient leur durée recalculée automatiquement.
Analogie quotidienne — C'est comme un GPS qui recalcule automatiquement votre temps de trajet en fonction de la circulation en temps réel, plutôt que d'utiliser une durée fixe quelle que soit la situation.
Pourquoi A est faux — Pattern D2 Inventé : « Route-based Job Plans with nested child plans » n'est pas une fonctionnalité existante dans Maximo Manage 9.x.
Pourquoi B est faux — Pattern D4 Demi-vérité : Les Standard Job Plans existent bien mais ne permettent pas de calculs automatiques basés sur des formules ou des compteurs.
Pourquoi C est faux — Pattern D9 Quasi-synonyme : « Job Plan Sequence » évoque l'ordonnancement des tâches mais pas leur calcul dynamique basé sur des formules ou des compteurs.
- Formula Based — Calcul des durées/tâches via expressions mathématiques.
- Meter Based — Calcul basé sur les relevés de compteurs d'actifs.
- ESTDUR — Champ stockant la durée estimée d'une tâche.
- LABOREST — Estimation de la main-d'œuvre requise.
- Dynamic Calculation Method — Paramètre principal d'un Job Plan dynamique.
- Seuls les Dynamic Job Plans supportent Formula/Meter Based.
- Les calculs s'appliquent à la génération du WO.
- Configurer dans l'onglet Tasks du Job Plan.
- STU sub-objective §6.1 — Job Plans dynamiques
- [EOTRAG] Query — « Dynamic Job Plan Formula Based Meter Based Maximo Manage 9 » (confidence 0.91)
- master-map.pdf p.247-249 — IBM Docs Job Plan Configuration
Bonne réponse : A
Pourquoi cette question existe — STU §6.1 — la question teste la compréhension de l'activation du contrôle de révision pour les Job Plans dans Maximo Manage 9.0. Les distracteurs montrent les erreurs typiques : chercher dans la mauvaise application (D6), utiliser une propriété système inexistante (D2), ou croire que cela se configure dans l'Application Designer (D7). En pratique terrain, cette configuration est souvent négligée, ce qui peut entraîner des problèmes de gestion des versions des Job Plans.
Le contexte théorique d'abord — Le contrôle de révision permet de gérer les versions des Job Plans sans affecter les ordres de travail existants. Lorsqu'un Job Plan est révisé, une nouvelle version est créée avec un statut PENDING_REVISION, tandis que la version originale reste ACTIVE. Cette fonctionnalité est cruciale pour maintenir la cohérence des données dans les environnements complexes.
Ce que Maximo en fait — version opérationnelle — Pour activer le contrôle de révision, accédez à l'application Organizations > Work Order Options > Job Plan settings. Activez l'option de contrôle de révision. Ensuite, lorsque vous réviserez un Job Plan, une nouvelle version sera créée avec un numéro de révision incrémenté, tandis que les ordres de travail existants continueront d'utiliser la version originale.
Exemple chiffré — Un site avec 12 Job Plans actifs, dont 3 sont révisés, génère 3 nouvelles versions avec des statuts PENDING_REVISION. Les ordres de travail existants (247 au total) continuent d'utiliser les versions originales, tandis que les nouveaux ordres de travail (34 créés après révision) utilisent les versions révisées.
Analogie quotidienne — C'est comme mettre à jour un manuel d'instructions : vous créez une nouvelle édition pour les nouveaux utilisateurs, mais ceux qui ont déjà l'ancienne version continuent de l'utiliser jusqu'à ce qu'ils passent à la nouvelle.
Pourquoi B est faux — Pattern D6 Mauvaise-app : le contrôle de révision ne s'active pas dans le menu More Actions de l'application Job Plans, mais dans les paramètres des organisations.
Pourquoi C est faux — Pattern D2 Inventé : la propriété système mxe.jobplan.revisioncontrol n'existe pas dans Maximo Manage 9.0.
Pourquoi D est faux — Pattern D7 Inexistant : le contrôle de révision ne se configure pas dans l'Application Designer pour l'objet Job Plan.
- Job Plan — ensemble de tâches définies pour un ordre de travail.
- PENDING_REVISION — statut d'une version révisée d'un Job Plan.
- ACTIVE — statut de la version originale d'un Job Plan.
- Organizations — application où activer le contrôle de révision.
- Work Order Options — section des paramètres pour les Job Plans.
- Activer le contrôle de révision dans Organizations > Work Order Options.
- Les Job Plans révisés ont un statut PENDING_REVISION.
- Les ordres de travail existants utilisent la version originale.
- STU sub-objective §6.1 — Créer et gérer Job Plans et Routes
- [EOTRAG] Query — « Maximo Manage 9.0 enable revision control for Job Plans » (confidence 0.98)
- master-map.pdf p.201-203 — IBM Docs Job Plan Revision Control
Bonne réponse : B
Pourquoi cette question existe — STU §6.1 — cette question valide la compréhension du transfert des qualifications depuis un Job Plan vers un Work Order. Le piège courant est de penser que les qualifications restent informatives ou déclenchent des notifications sans impact opérationnel. En réalité, Maximo applique une restriction active lors de l'assignation des ressources, ce qui est critique pour la conformité et la sécurité des interventions.
Le contexte théorique d'abord — Les qualifications dans Maximo sont des exigences métier attachées aux tâches (Job Plan tasks ou Work Order tasks). Elles définissent le niveau de compétence requis pour exécuter une tâche. Lorsqu'un Job Plan est appliqué à un Work Order, toutes ses données (dont les qualifications) sont transférées via le mécanisme de data and requirements transfer documenté dans les chunks RAG.
Ce que Maximo en fait — version opérationnelle — Dans l'application Job Plans, on clique sur l'icône Qualifications dans l'onglet Job Plan pour définir les exigences. Quand ce Job Plan est ensuite appliqué à un Work Order (via le champ Job Plan ou l'action Go To > Job Plans), Maximo copie automatiquement ces qualifications sur les tâches du Work Order. Le système vérifiera ensuite ces exigences lors de l'assignation des ressources dans Assignment Manager.
Exemple chiffré — Un Job Plan avec 3 tâches dont 2 requièrent une certification "HAZMAT Level 3" est appliqué à un Work Order. Sur 12 techniciens disponibles, seuls 5 ont cette certification. L'assignation sera restreinte à ces 5 personnes (58% de l'équipe éliminée) pour les 2 tâches concernées.
Analogie quotidienne — C'est comme un permis de conduire : si une mission nécessite un permis poids lourd, seuls les chauffeurs ayant ce permis pourront être assignés, pas ceux qui n'ont que le permis B.
Pourquoi A est faux — Les qualifications ne sont pas seulement informatives, elles restreignent activement l'assignation aux ressources qualifiées. (Pattern D4 Demi-vérité)
Pourquoi C est faux — L'audit trail enregistre les changements mais n'est pas le mécanisme principal de restriction des assignations. (Pattern D5 Champ-frère)
Pourquoi D est faux — Les emails peuvent être configurés via Escalations mais ne remplacent pas la validation native des qualifications. (Pattern D10 Procédure-plausible)
- Job Plan — Modèle réutilisable de tâches avec exigences.
- Qualifications — Exigences de compétence pour les ressources.
- Data transfer — Copie automatique Job Plan → Work Order.
- Assignment Manager — Module gérant les restrictions d'assignation.
- Validation — Vérification des qualifications lors de l'assignation.
- Les qualifications du Job Plan se copient sur le Work Order.
- Elles restreignent l'assignation aux ressources qualifiées.
- Pas seulement informatif - impact opérationnel direct.
- STU sub-objective §6.1 — Job Plans and Work Orders integration
- [EOTRAG] Query — « Job Plan qualifications transfer to Work Order Maximo » (confidence 0.96)
- master-map.pdf p.853-854 — IBM Docs Job plans and work orders
Bonne réponse : C
Pourquoi cette question existe — STU §6.1 — cette question teste la compréhension de la fonctionnalité Flow Control dans les Job Plans, en particulier comment Maximo gère les dépendances entre tâches. Les distracteurs montrent les erreurs courantes : confondre séquence et dépendance (D3), ignorer le rôle du flag Flow Control (D4), et appliquer une solution sur-engineered (D10). En pratique terrain, l'omission du flag Flow Control est une erreur fréquente qui empêche l'exécution correcte des tâches.
Le contexte théorique d'abord — Flow Control est une fonctionnalité qui permet de définir des dépendances entre les tâches d'un Job Plan. Pour qu'une tâche puisse démarrer, toutes ses tâches prédécesseurs doivent être terminées. Cela est géré via le champ Predecessors et le flag Under Flow Control. Le champ Predecessors liste les tâches qui doivent être terminées avant que la tâche courante puisse démarrer, tandis que le flag Under Flow Control active cette vérification.
Ce que Maximo en fait — version opérationnelle — Dans l'application Job Plan, sélectionnez une tâche et définissez ses prédécesseurs dans le champ Predecessors. Activez ensuite le flag Under Flow Control pour cette tâche. Lorsque le Job Plan est appliqué à un Work Order, Maximo vérifie automatiquement que les tâches prédécesseurs sont terminées avant de permettre le démarrage de la tâche courante.
Exemple chiffré — Job Plan avec 3 tâches : Tâche 10 (durée 2h), Tâche 20 (durée 3h), Tâche 30 (durée 1h). Tâche 20 dépend de Tâche 10, Tâche 30 dépend de Tâche 20. Avec Flow Control activé, Tâche 30 ne peut démarrer qu'après 5h (2h + 3h). Sans Flow Control, Tâche 30 pourrait démarrer immédiatement, causant des erreurs d'exécution.
Analogie quotidienne — C'est comme une recette de cuisine : vous ne pouvez pas mettre le gâteau au four (Tâche 30) avant d'avoir préparé la pâte (Tâche 10) et l'avoir mise dans le moule (Tâche 20). Flow Control est le chef qui vérifie que chaque étape est terminée avant de passer à la suivante.
Pourquoi A est faux — Pattern D4 demi-vérité : le champ Sequence Logic permet de définir l'ordre des tâches, mais ne gère pas les dépendances entre elles.
Pourquoi B est faux — Pattern D3 inverse : le numéro de séquence indique l'ordre des tâches, mais ne garantit pas qu'une tâche ne démarre pas avant que ses prédécesseurs soient terminés.
Pourquoi D est faux — Pattern D10 procédure-plausible : utiliser Workflow pour gérer les dépendances est possible mais sur-engineered et contourne la solution native de Flow Control.
- Flow Control — fonctionnalité qui gère les dépendances entre tâches.
- Predecessors — champ qui liste les tâches prédécesseurs.
- Under Flow Control — flag qui active la vérification des dépendances.
- Job Plan — ensemble de tâches définies pour un Work Order.
- Work Order — document qui décrit les travaux à effectuer.
- Flow Control gère les dépendances entre tâches.
- Predecessors + Under Flow Control = dépendances activées.
- Sans Flow Control, les tâches peuvent démarrer hors séquence.
- STU sub-objective §6.1 — Flow Control dans Job Plans
- [EOTRAG] Query — « Maximo Flow Control Job Plan Predecessors Under Flow Control » (confidence 0.95)
- master-map.pdf p.201-203 — IBM Docs Job Plan Flow Control
Bonne réponse : A
Pourquoi cette question existe — STU §6.1 — cette question teste la compréhension du comportement des Job Plans imbriqués (Nested Job Plans) dans Maximo. Les distracteurs montrent les erreurs typiques : ignorer les plans enfants (D4), confondre avec des Work Orders séparés (D2), et limiter l'usage à des enregistrements spécifiques (D1). En pratique terrain, la mauvaise utilisation des Job Plans imbriqués peut entraîner des structures de tâches incorrectes et des inefficacités dans la gestion des travaux.
Le contexte théorique d'abord — Un Job Plan imbriqué (Nested Job Plan) permet de référencer un Job Plan existant dans un autre Job Plan, créant ainsi une structure hiérarchique de tâches. Cela évite de devoir ré-entrer les données du Job Plan existant. Les tâches du Job Plan enfant sont intégrées sous une tâche spécifique du Job Plan parent, formant une arborescence claire et organisée.
Ce que Maximo en fait — version opérationnelle — Dans l'application Job Plan, lors de la création d'un Job Plan, l'utilisateur peut référencer un autre Job Plan existant. Les tâches du Job Plan référencé sont alors intégrées sous une tâche du Job Plan parent. Cette structure est ensuite appliquée à un Work Order, où les tâches apparaissent dans l'ordre hiérarchique défini.
Exemple chiffré — Un Job Plan parent contient 5 tâches principales. L'une de ces tâches référence un Job Plan enfant qui contient 3 sous-tâches. Lorsque ce Job Plan est appliqué à un Work Order, le Work Order affichera 5 tâches principales, avec la troisième tâche contenant les 3 sous-tâches du Job Plan enfant. Cela permet une gestion efficace de 8 tâches au total.
Analogie quotidienne — C'est comme un projet de construction où chaque étape principale (fondations, murs, toit) contient des sous-étapes (creuser les fondations, couler le béton, etc.). Les sous-étapes sont intégrées sous chaque étape principale, créant une structure claire et organisée.
Pourquoi B est faux — Pattern D4 demi-vérité : Ignorer les plans enfants va à l'encontre du principe même des Job Plans imbriqués, qui est d'intégrer les tâches des plans enfants sous une tâche parente.
Pourquoi C est faux — Pattern D2 inventé : Les Job Plans imbriqués ne sont pas convertis en Work Orders séparés ; ils restent intégrés dans la structure hiérarchique du Job Plan parent.
Pourquoi D est faux — Pattern D1 hérité : Les Job Plans imbriqués sont supportés sur tous les types de Work Orders, pas uniquement sur les enregistrements PM.
- Job Plan — une séquence de tâches définie pour exécuter un travail.
- Nested Job Plan — un Job Plan qui référence un autre Job Plan existant.
- Work Order — un enregistrement qui définit un travail à effectuer.
- Tâche parente — la tâche principale sous laquelle les tâches enfants sont intégrées.
- Tâche enfant — les tâches du Job Plan référencé qui sont intégrées sous une tâche parente.
- Les Job Plans imbriqués créent une structure hiérarchique de tâches.
- Les tâches du Job Plan enfant sont intégrées sous une tâche du Job Plan parent.
- Les Job Plans imbriqués sont supportés sur tous les types de Work Orders.
- STU sub-objective §6.1 — Créer et gérer Job Plans et Routes
- [EOTRAG] Query — « Maximo Nested Job Plan behavior » (confidence 0.94)
- master-map.pdf p.201-203 — IBM Docs Job Plans and Routes
Bonne réponse : D
Pourquoi cette question existe — STU §6.1 — cette question valide la maîtrise des Job Plans hiérarchiques, un mécanisme clé pour éviter la duplication des étapes communes entre procédures. Le piège courant est de chercher cette fonctionnalité dans des onglets liés au workflow (D6) ou à la planification (D4) plutôt qu'à la structure des tâches. En contexte terrain, cette hiérarchisation réduit de 30-50% le temps de maintenance des Job Plans partagés.
Le contexte théorique d'abord — Un Nested Job Plan permet d'imbriquer des Job Plans existants comme sous-étapes d'un plan parent via la table JOBTASK. Chaque tâche enfant hérite des attributs du parent (durée, compétence requise) tout en conservant sa propre logique. La hiérarchie est gérée par les champs JOBPLANID (lien parent) et TASKID (ordre d'exécution).
Ce que Maximo en fait — version opérationnelle — Dans l'app Job Plan > onglet Job Plan Tasks : cliquer Add Row > sélectionner un Job Plan existant dans le champ Job Plan. Le système crée automatiquement une référence (pas une copie) avec les tâches enfant visibles en drill-down. Sauvegarder via le bouton Save du plan parent.
Exemple chiffré — Compresseur C-100 : Job Plan parent de 12h contient 3 sous-plans (lubrification 2h, alignement 3h, test final 1h). 47 étapes communes héritées des sous-plans, réduisant la saisie manuelle de 68%.
Analogie quotidienne — Comme un menu de restaurant avec plats composés : la carte "Menu du jour" (parent) référence les entrées/sauces/desserts existants (enfants) sans recopier leurs recettes.
Pourquoi A est faux — Pattern D7 Inexistant : aucun onglet "Dynamic Job Plan" n'existe dans l'application Maximo.
Pourquoi B est faux — Pattern D6 Mauvaise-app : "Flow Action" gère les transitions de workflow, pas l'imbrication des Job Plans.
Pourquoi C est faux — Pattern D4 Demi-vérité : "Planned Labor" définit les ressources humaines mais pas la structure hiérarchique des tâches.
- JOBTASK — table stockant les relations parent-enfant entre Job Plans.
- Job Plan Reference — lien dynamique (non copié) vers un sous-plan.
- Task Sequence — ordre d'exécution des tâches via
TASKID. - Attribute Inheritance — les enfants héritent des paramètres du parent.
- Drill-down — consultation des détails des sous-plans en un clic.
- L'onglet
Job Plan Tasksgère l'imbrication des plans. - Les sous-plans sont référencés, non dupliqués.
- La hiérarchie réduit la maintenance des étapes communes.
- STU sub-objective §6.1 — Job Plan hierarchy and nested tasks
- [EOTRAG] Query — « Maximo nested job plan tasks tab » (confidence 0.92)
- master-map.pdf p.203-207 — IBM Docs Job Plan Structure
Bonne réponse : A,B
Pourquoi cette question existe — STU §6.1 — cette question vérifie la compréhension des éléments transférés automatiquement d'un Job Plan vers un Work Order lors de l'application manuelle ou via un PM. Les erreurs courantes incluent la confusion entre éléments planifiés (copiés) et éléments exécutés (non copiés), ou l'omission des flags comme direct issue pour les matériaux. En pratique terrain, cette distinction impacte directement la préparation des interventions.
Le contexte théorique d'abord — Un Job Plan dans Maximo est un template réutilisable contenant des tâches (JOBTASK), des matériaux (JOBMATERIAL), et potentiellement des plans de sécurité. Lorsqu'appliqué à un Work Order (manuellement ou via PM), le système copie les éléments planifiés mais pas les données d'exécution comme les transactions réelles. Les séquences de tâches et quantités de matériaux sont préservées.
Ce que Maximo en fait — version opérationnelle — Dans Job Plan ou PM application, la création d'un Work Order déclenche la copie : (1) Tâches → WOTASK (séquences, durées estimées), (2) Matériaux → WPMATERIAL (items, quantités, flags directissue=1). Le Safety Plan n'est copié que s'il est défini comme default pour l'asset concerné (non systématique).
Exemple chiffré — Job Plan "JP-247" : 5 tâches (durées 15-60 min), 3 matériaux (qty 2-12, dont 1 en direct issue). Application → Work Order "WO-3812" reçoit les 5 WOTASK et 3 WPMATERIAL, mais 0 transaction LABTRANS ou MATUSETRANS.
Analogie quotidienne — Comme une recette de cuisine : la fiche (Job Plan) liste les ingrédients et étapes, mais pas ce que vous avez déjà versé dans le bol (transactions réelles).
Pourquoi C est faux — L'asset record (ASSET) est associé au WO mais n'est pas "copié" depuis le Job Plan. C'est une référence externe. (Pattern D5 Champ-frère)
Pourquoi D est faux — Le Safety Plan n'est copié que s'il est marqué comme default pour l'asset, pas systématiquement. (Pattern D4 Demi-vérité)
Pourquoi E est faux — Les transactions réelles (LABTRANS) sont créées pendant l'exécution, jamais copiées depuis le Job Plan. (Pattern D3 Inverse)
- JOBTASK — Tâches planifiées, copiées en
WOTASK. - JOBMATERIAL — Matériaux planifiés, copiés en
WPMATERIAL. - Direct issue flag — Indique si le matériau sort directement du stock sans réservation.
- Default Safety Plan — Copié conditionnellement si lié à l'asset.
- PM-generated WO — Hérite des Job Plans attachés au PM.
- Job Plan → WO copie tâches (séquences/durées) et matériaux (qté/flags).
- Safety Plan copié uniquement si défini comme default pour l'asset.
- Transactions réelles (LABTRANS/MATUSETRANS) jamais copiées.
- STU sub-objective §6.1 — Job Plan to Work Order element transfer
- [EOTRAG] Query — « Maximo Job Plan elements copied to Work Order tasks materials safety » (confidence 0.95)
- master-map.pdf p.212-215 — IBM Docs Job Plan Application
Condition Monitoring
📋 Objectifs IBM
- Comprendre les principes fondamentaux de la maintenance basée sur la condition (CBM) dans Maximo.
- Identifier les applications et outils Maximo utilisés pour la surveillance de la condition des actifs.
- Décrire comment les données de condition sont collectées et utilisées pour déclencher des actions de maintenance.
- Expliquer le rôle des KPI et des tableaux de bord dans la visualisation de la santé des actifs.
- Distinguer les capacités de surveillance de Maximo Manage et de Maximo Monitor.
- Appréhender l'intégration des données de capteurs et des systèmes SCADA dans Maximo pour la CBM.
💡 Points clés
- Maintenance Basée sur la Condition (CBM) — Stratégie de maintenance qui utilise l'état réel de l'actif pour décider quand et quelle maintenance est nécessaire, en se basant sur des indicateurs de performance.
- Collecte de Données de Condition — Les données peuvent être recueillies par des mesures non invasives, des inspections visuelles, des données de performance, des tests planifiés, ou des capteurs en continu.
Condition Monitoring(Application) — Application Maximo permettant de définir des points de mesure, des seuils, et des actions automatiques basées sur l'état des actifs.MetersetMeter Readings— Les compteurs sont utilisés pour suivre l'utilisation ou l'état d'un actif, et leurs relevés sont des données de condition essentielles.- KPI (Key Performance Indicators) — Indicateurs définis via l'application
KPI Manager, utilisant des requêtes SQL pour surveiller des métriques clés avec des seuils d'alerte. Start Center— Tableau de bord personnalisable où les KPI et les requêtes publiques peuvent être affichés pour une vue d'ensemble rapide de la santé des actifs.- Maximo Monitor — Composant de la
Maximo Application Suite(MAS) spécialisé dans la surveillance à l'échelle de l'entreprise avec détection d'anomalies basée sur l'IA et tableaux de bord configurables. - Génération Automatique d'Ordres de Travail — Une capacité clé de la CBM et de Maximo Monitor est la création automatique d'ordres de travail en réponse à des seuils dépassés ou des anomalies détectées.
📐 Architecture de la Surveillance de Condition
La surveillance de condition dans Maximo s'appuie sur une architecture robuste qui intègre la collecte de données, l'analyse et la déclenchement d'actions de maintenance. Au cœur de cette architecture se trouve la capacité de Maximo à ingérer des données provenant de diverses sources, qu'elles soient manuelles ou automatisées, pour évaluer l'état de santé des actifs.
Cette approche permet une transition de la maintenance préventive basée sur le temps vers une maintenance prédictive et basée sur la condition, optimisant ainsi les opérations et réduisant les temps d'arrêt imprévus. L'intégration avec des systèmes externes comme les SCADA ou les capteurs IoT est fondamentale pour une surveillance en temps quasi réel.
📊 Comparaison: Maximo Manage vs. Maximo Monitor
Bien que Maximo Manage offre des capacités robustes de surveillance de condition, la Maximo Application Suite (MAS) introduit Maximo Monitor, une solution plus avancée pour la détection d'anomalies à l'échelle de l'entreprise. Comprendre leurs différences est crucial pour choisir la bonne approche de surveillance.
| Caractéristique | Maximo Manage (Classique) | Maximo Monitor (MAS) |
|---|---|---|
| Objectif Principal | Gestion des actifs, maintenance réactive/préventive, CBM de base. | Surveillance à l'échelle de l'entreprise, détection d'anomalies IA, maintenance prédictive. |
| Collecte de Données | Manuelle (Meter Readings), intégration limitée de capteurs via interfaces. | Intégration rapide et massive de données de capteurs IoT, SCADA, systèmes externes. |
| Analyse des Données | Seuils définis manuellement, KPI basés sur SQL, rapports ad-hoc. | Détection d'anomalies basée sur l'IA, apprentissage automatique, analyse de données en temps quasi réel. |
| Visualisation | Start Center avec portlets KPI, rapports standards. | Tableaux de bord configurables sans code (No-Code Widgets), vue d'ensemble de l'opération à l'échelle de l'entreprise. |
| Génération d'OT | Automatique via Condition Monitoring ou Escalations basées sur des seuils. | Génération automatique d'ordres de travail en réponse aux anomalies détectées, intégration fluide avec Manage. |
| Évolutivité | Adapté pour des besoins CBM spécifiques et gérables. | Conçu pour une surveillance massive de milliers d'actifs et de flux de données. |
| Complexité | Configuration des compteurs et points de mesure, règles simples. | Gestion de grands volumes de données, modèles d'IA, intégration de multiples sources. |
⚙️ Configuration et Opérations de Condition Monitoring
La mise en œuvre d'une stratégie de surveillance de condition dans Maximo Manage implique plusieurs étapes clés, de la définition des points de mesure à la configuration des actions automatiques. L'objectif est de transformer les données brutes en informations exploitables qui déclenchent des interventions de maintenance au moment opportun.
L'application Condition Monitoring est le pivot de cette fonctionnalité. Elle permet de lier des points de mesure à des actifs ou des emplacements, de définir des seuils d'alerte et de spécifier les actions à entreprendre lorsque ces seuils sont dépassés. Par exemple, un actif critique comme une pompe peut avoir un point de mesure pour la vibration, avec un seuil d'alerte élevé qui génère automatiquement un ordre de travail pour inspection.
- Définition des
Meters— Dans l'applicationMeters, créez des compteurs pour suivre des paramètres spécifiques (ex: température, pression, vibrations, heures de fonctionnement). Associez-les à des actifs ou des types d'actifs. - Création de Points de Mesure — Dans l'application
AssetsouLocations, ajoutez des points de mesure (MEASUREMENT) aux actifs ou emplacements. Liez-les auxMetersdéfinis. - Configuration de
Condition Monitoring— Dans l'applicationCondition Monitoring, sélectionnez un actif ou un emplacement et un point de mesure. Définissez des seuils de lecture (ex: seuil d'avertissement, seuil d'action). - Définition des Actions — Pour chaque seuil, spécifiez l'action à entreprendre : générer un ordre de travail (
WORKORDER), envoyer une notification (COMMUNICATION), ou modifier le statut de l'actif (ASSETSTATUS). - Saisie des
Meter Readings— Les relevés de compteurs peuvent être saisis manuellement via l'applicationMeter Readings, ou importés automatiquement depuis des systèmes externes (SCADA, IoT) via des intégrations. - Surveillance via KPI — Utilisez l'application
KPI Managerpour créer des indicateurs qui surveillent l'état des actifs en fonction des relevés de compteurs et des seuils. Affichez ces KPI sur leStart Centerpour une visibilité en temps réel.
Un exemple concret pourrait être la surveillance de la température d'un moteur de production. Un Meter "Température Moteur" est créé et associé à l'actif "Moteur Principal 01". Dans Condition Monitoring, un seuil d'avertissement est fixé à 80°C et un seuil critique à 90°C. Si la température dépasse 80°C, une notification est envoyée au chef d'équipe. Si elle atteint 90°C, un ordre de travail de priorité élevée est automatiquement généré pour une inspection immédiate, avec un JOBPLAN pré-défini pour le diagnostic.
🔄 Workflow de la Maintenance Basée sur la Condition
Le workflow de la maintenance basée sur la condition (CBM) est un processus dynamique qui commence par la collecte continue de données et culmine avec des actions de maintenance ciblées. Il vise à anticiper les défaillances et à optimiser les interventions, réduisant ainsi les coûts et les temps d'arrêt.
Ce cycle de vie implique une surveillance constante des indicateurs de performance des actifs, l'analyse des tendances, et la prise de décision éclairée. L'automatisation joue un rôle crucial pour garantir que les alertes sont traitées rapidement et que les ordres de travail sont générés sans délai.
⚠️ Pièges IBM
Meters et Condition Monitoring
Les candidats peuvent confondre le rôle des Meters et de l'application Condition Monitoring. Les Meters (compteurs) sont des entités qui suivent une valeur numérique ou alphanumérique (ex: heures de fonctionnement, température). L'application Condition Monitoring utilise les relevés de ces Meters pour évaluer l'état de l'actif par rapport à des seuils définis et déclencher des actions. Un Meter seul ne déclenche pas d'action sans être configuré dans Condition Monitoring ou via une Escalation.
Une erreur courante est de penser que la surveillance de condition se limite à la saisie manuelle des relevés. En réalité, pour une CBM efficace, l'intégration de données provenant de systèmes SCADA, de capteurs IoT ou d'autres systèmes de contrôle est cruciale. Maximo est conçu pour ingérer ces données automatiquement, notamment via Maximo Monitor, pour une analyse en temps quasi réel et une détection proactive des anomalies. Ne pas considérer cette intégration limite fortement le potentiel de la CBM.
Start Center
Les KPI et le Start Center sont souvent vus comme de simples outils de reporting. Cependant, ils sont des composants essentiels de la surveillance de condition. Un KPI bien configuré peut alerter visuellement les utilisateurs sur des dégradations de condition sans qu'ils aient à naviguer dans plusieurs applications. Le Start Center offre une vue consolidée et personnalisable de la santé des actifs, permettant une prise de décision rapide. Ignorer leur potentiel de visualisation et d'alerte est un piège.
🎯 Carte mémoire
Quel est le rôle principal de l'application Condition Monitoring dans Maximo ?
L'application Condition Monitoring permet de définir des points de mesure pour les actifs ou les emplacements, de spécifier des seuils d'alerte pour ces points, et de configurer des actions automatiques (comme la génération d'un WORKORDER ou l'envoi d'une COMMUNICATION) lorsque ces seuils sont dépassés, facilitant ainsi la maintenance basée sur la condition.
Comment Maximo Monitor améliore-t-il les capacités de surveillance de condition par rapport à Maximo Manage classique ?
Maximo Monitor, partie de la Maximo Application Suite, offre une surveillance à l'échelle de l'entreprise avec détection d'anomalies basée sur l'IA, des tableaux de bord configurables sans code, et une intégration rapide de données de capteurs IoT et SCADA. Il permet une analyse en temps quasi réel et une génération automatique d'ordres de travail plus sophistiquée que les fonctionnalités de base de Maximo Manage.
Quels sont les avantages clés de l'adoption d'une stratégie de Maintenance Basée sur la Condition (CBM) ?
La CBM permet de réduire les temps d'arrêt imprévus, d'optimiser les calendriers de maintenance en intervenant uniquement lorsque nécessaire, de prolonger la durée de vie des actifs, de diminuer les coûts de maintenance en évitant les réparations coûteuses dues à des défaillances inattendues, et d'améliorer la sécurité opérationnelle.
Comment les KPI peuvent-ils être utilisés pour la surveillance de condition dans Maximo ?
Les KPI, définis via l'application KPI Manager, peuvent être configurés pour surveiller des métriques clés liées à la condition des actifs (ex: nombre d'alertes de température, moyenne des vibrations). Ils utilisent des requêtes SQL pour extraire des données et peuvent afficher des seuils d'alerte (vert/jaune/rouge) sur le Start Center, offrant une visibilité immédiate sur la santé des actifs.
Bonne réponse : A
Pourquoi cette question existe — STU §6.2 — cette question teste la compréhension des limites de surveillance dans Maximo Condition Monitoring. Les Warning Limits et Upper/Lower Limits ont des rôles distincts : les premiers sont des alertes, les seconds déclenchent des actions. Les distracteurs montrent les erreurs typiques : inversion des rôles (D3), confusion entre les types de limites (D4), et restriction incorrecte des limites à des types d'instruments spécifiques (D5).
Le contexte théorique d'abord — Dans Maximo Condition Monitoring, les limites de surveillance sont définies pour suivre les performances des équipements. Les Warning Limits sont des seuils d'alerte qui signalent un écart par rapport à la norme sans déclencher d'action corrective. Les Upper/Lower Limits sont des seuils critiques qui, lorsqu'ils sont dépassés, déclenchent des actions spécifiques comme la création d'un Work Order.
Ce que Maximo en fait — version opérationnelle — Dans l'application Condition Monitoring, configurez les limites via l'onglet Measurement Points. Pour les Warning Limits, définissez les valeurs dans les champs METERLOWWARNING et METERHIGHWARNING. Pour les Upper/Lower Limits, utilisez METERLOWACTION et METERHIGHACTION. Lorsque ces dernières sont dépassées, Maximo génère automatiquement un Work Order.
Exemple chiffré — Pour une pompe P-101 : Warning Limits = 50-150 psi, Upper/Lower Limits = 30-170 psi. Si la pression atteint 160 psi, une alerte est déclenchée. Si elle atteint 175 psi, un Work Order est généré pour inspection immédiate.
Analogie quotidienne — Imaginez un thermostat : la température idéale est entre 20°C et 24°C (Warning Limits). Si elle dépasse 25°C ou descend sous 18°C (Upper/Lower Limits), le système déclenche une action corrective comme l'arrêt du chauffage ou de la climatisation.
Pourquoi B est faux — Les Upper/Lower Limits ne sont pas seulement des alertes visuelles, elles déclenchent des actions spécifiques comme des Work Orders. (Pattern D4 Demi-vérité)
Pourquoi C est faux — C'est l'inverse de la réalité : les Warning Limits sont des alertes, tandis que les Upper/Lower Limits déclenchent des actions. (Pattern D3 Inverse)
Pourquoi D est faux — Les limites s'appliquent à tous les instruments de mesure, pas seulement aux jauges ou aux compteurs. (Pattern D5 Champ-frère)
- Warning Limits — seuils d'alerte sans action corrective.
- Upper/Lower Limits — seuils critiques déclenchant des actions.
- Measurement Points — points de surveillance des équipements.
- Work Order — ordre de travail généré automatiquement.
- Condition Monitoring — application de surveillance des équipements.
- Warning Limits = alertes, Upper/Lower Limits = actions.
- Les limites critiques déclenchent des Work Orders.
- Les limites s'appliquent à tous les instruments de mesure.
- STU sub-objective §6.2 — Condition Monitoring Limits
- [EOTRAG] Query — « Maximo Condition Monitoring Warning Limits vs Upper/Lower Limits » (confidence 0.91)
- master-map.pdf p.1823-1825 — IBM Docs Condition Monitoring
Bonne réponse : B
Pourquoi cette question existe — STU §6.2 — cette question teste la compréhension du mécanisme automatique de génération de Work Orders à partir des seuils de Measurement Points. Les distracteurs ciblent les confusions courantes entre les différents types de tâches planifiées (Cron Tasks) et les déclencheurs immédiats. En pratique terrain, l'activation de la bonne Cron Task est souvent omise lors de la configuration initiale.
Le contexte théorique d'abord — Les Measurement Points dans Maximo permettent de surveiller des indicateurs techniques (pression, température, etc.) avec des seuils prédéfinis. Lorsqu'une lecture dépasse ces limites, le système peut générer automatiquement des Work Orders via la Cron Task dédiée. Cette fonctionnalité s'appuie sur les tables MEASUREMENT pour les définitions et METERREADING pour les valeurs enregistrées.
Ce que Maximo en fait — version opérationnelle — Dans Cron Task Setup, activer MeasurePointWoGenCronTask et configurer sa fréquence d'exécution (par défaut quotidienne). La tâche scanne alors les METERREADING récentes, compare aux seuils définis dans MEASUREMENT, et génère des Work Orders dans WORKORDER avec statut WAPPR si les limites sont dépassées.
Exemple chiffré — Pour un compresseur avec seuil haute pression à 85 psi : 3 lectures à 87, 89 et 91 psi sur 24h déclenchent 3 Work Orders. La Cron Task s'exécutant toutes les 6 heures, le délai moyen entre dépassement et création WO est de 3 heures.
Analogie quotidienne — Comme un système d'alarme incendie qui scanne régulièrement les détecteurs de fumée : il ne réagit pas instantanément à chaque particule, mais vérifie à intervalles fixes si le seuil critique est atteint pour déclencher l'alerte.
Pourquoi A est faux — Pattern D6 mauvaise-app : PMWoGenCronTask gère les Work Orders de maintenance préventive planifiée, pas les alertes basées sur des mesures. (Pattern D6 Mauvaise-app)
Pourquoi C est faux — Pattern D2 inventé : Aucun listener natif ne crée de Measurement Point à la fermeture d'un WO, c'est l'inverse qui se produit. (Pattern D2 Inventé)
Pourquoi D est faux — Pattern D10 procédure-plausible : Bien que techniquement possible via customisation, ce n'est pas le mécanisme natif de Maximo qui repose sur une Cron Task. (Pattern D10 Procédure-plausible)
- Measurement Point — Définition technique d'un indicateur à surveiller avec ses seuils.
- Meter Reading — Valeur enregistrée d'une mesure à un instant donné.
- Cron Task — Tâche planifiée exécutée périodiquement par le système.
- Upper/Lower Limits — Seuils critiques déclenchant des actions automatiques.
- Work Order Generation — Processus automatique de création d'ordres de travail.
- MeasurePointWoGenCronTask = seul mécanisme natif pour WO depuis mesures.
- Les lectures sont comparées aux seuils lors de l'exécution planifiée.
- Pas de déclenchement immédiat à l'enregistrement des mesures.
- STU sub-objective §6.2 — Condition Monitoring and Measurement Points
- [EOTRAG] Query — « Maximo Work Order generation from Measurement Points cron task » (confidence 0.98)
- master-map.pdf p.201-204 — IBM Docs Condition Monitoring
Bonne réponse : C
Pourquoi cette question existe — STU §6.2 — la question teste la compréhension de l'application centrale pour définir des points de mesure dans Maximo. Les distracteurs ciblent les confusions courantes entre les onglets "Meters" (suivi temporel) et "Measurement Points" (suivi conditionnel), ainsi que l'emplacement correct dans l'application Condition Monitoring. En pratique terrain, cette distinction est cruciale pour configurer correctement le suivi des équipements.
Le contexte théorique d'abord — Les Measurement Points permettent d'enregistrer des valeurs de surveillance conditionnelle (température, pression, etc.) pour des actifs ou des emplacements. Contrairement aux Meters qui suivent des compteurs temporels (heures de fonctionnement), les points de mesure capturent des états instantanés. Les données sont stockées dans la table MEASUREMENT avec des champs comme MEASUREMENTPOINT et MEASUREMENTVALUE.
Ce que Maximo en fait — version opérationnelle — Dans l'application Condition Monitoring > onglet Measurement Points, on crée un nouveau point avec : nom, unité de mesure, seuils d'alerte. On l'associe ensuite à un ASSETNUM ou LOCATION spécifique. Les lectures peuvent être saisies manuellement ou importées via intégration.
Exemple chiffré — Pour un compresseur (ASSETNUM=CPR-789) : 3 points de mesure définis (pression=120 psi max, température=80°C max, vibrations=5 mm/s). 12 lectures enregistrées ce mois, dont 2 dépassements de température déclenchant des alertes.
Analogie quotidienne — Comme les voyants de tableau de bord d'une voiture : le compteur kilométrique est un Meter (cumulatif), tandis que la jauge de température ou la pression d'huile sont des Measurement Points (instantanés avec seuils critiques).
Pourquoi A est faux — L'onglet Meters sert à suivre des compteurs temporels (heures, km), pas des points de mesure conditionnelle. (Pattern D6 Mauvaise-app)
Pourquoi B est faux — Il n'existe pas d'onglet "Measurement Setup" dans l'application Locations. (Pattern D7 Inexistant)
Pourquoi D est faux — L'application Preventive Management gère des calendriers de maintenance, pas la configuration des points de mesure. (Pattern D6 Mauvaise-app)
- Measurement Points — points de surveillance conditionnelle (valeurs instantanées avec seuils).
- Meters — compteurs temporels (heures, km) pour la maintenance préventive.
- MEASUREMENT table — stocke les lectures des points de mesure.
- Condition Monitoring — application centrale pour la configuration.
- Seuils d'alerte — valeurs critiques déclenchant des notifications.
- Les Measurement Points se configurent dans Condition Monitoring.
- Distinguer points de mesure (instantanés) et meters (cumulatifs).
- Associer chaque point à un asset ou location spécifique.
- STU sub-objective §6.2 — Condition Monitoring Measurement Points
- [EOTRAG] Query — « Maximo Manage 9 Measurement Points setup location » (confidence 0.98)
- master-map.pdf p.1099-1101 — IBM Docs Measurement Points Management
Bonne réponse : A
Pourquoi cette question existe — STU §6.2 — cette question teste la compréhension de la fonctionnalité de surveillance des limites d'action dans l'application Condition Monitoring. Les distracteurs montrent les erreurs typiques : confondre les types de données surveillés (D5), utiliser des métriques non pertinentes (D2), ou ignorer le mécanisme de déclenchement des Work Orders (D4). En pratique terrain, la mauvaise configuration des limites d'action est une source fréquente d'erreurs.
Le contexte théorique d'abord — Dans l'application Condition Monitoring, les Measurements sont les enregistrements qui surveillent les valeurs des points de mesure configurés. Lorsqu'une valeur dépasse les limites d'action supérieure ou inférieure définies, Maximo déclenche automatiquement la création d'un Work Order. Les limites d'action sont configurées dans les propriétés du point de mesure.
Ce que Maximo en fait — version opérationnelle — Dans l'application Condition Monitoring, sélectionnez un point de mesure > configurez les limites d'action supérieure et inférieure > sauvegardez. Lorsqu'une mesure dépasse ces limites, Maximo utilise un workflow pour créer un Work Order associé à l'asset concerné. Ce processus est entièrement automatisé et ne nécessite pas d'intervention manuelle.
Exemple chiffré — Un point de mesure configuré avec une limite supérieure de 100 et une limite inférieure de 50 : si la valeur atteint 105, un Work Order est créé. Si la valeur tombe à 45, un autre Work Order est généré. Sur un site avec 12 assets, cela peut entraîner la création de 8 Work Orders en un mois.
Analogie quotidienne — C'est comme un thermomètre intelligent qui déclenche une alerte lorsque la température dépasse un seuil critique, permettant une intervention rapide pour éviter des dommages.
Pourquoi B est faux — Pattern D5 champ-frère : Runhour Meter Readings surveillent les heures de fonctionnement, mais ne déclenchent pas de Work Order en cas de dépassement de limites.
Pourquoi C est faux — Pattern D2 inventé : Asset Downtime n'est pas un type d'enregistrement surveillé pour déclencher des Work Orders dans Condition Monitoring.
Pourquoi D est faux — Pattern D4 demi-vérité : Asset Health Score est une métrique utile, mais elle n'est pas utilisée pour déclencher des Work Orders basés sur des limites d'action.
- Measurements — enregistrements surveillés pour déclencher des Work Orders.
- Limites d'action — valeurs seuils configurées pour déclencher des actions.
- Workflow — processus automatisé de création de Work Orders.
- Points de mesure — configurations spécifiques pour surveiller les valeurs.
- Condition Monitoring — application dédiée à la surveillance des conditions des assets.
- Measurements déclenchent des Work Orders en cas de dépassement de limites.
- Les limites d'action sont configurées dans les points de mesure.
- Le processus est entièrement automatisé via un workflow.
- STU sub-objective §6.2 — Condition Monitoring et déclenchement de Work Orders
- [EOTRAG] Query — « Maximo Condition Monitoring Measurements Work Order triggers » (confidence 0.91)
- master-map.pdf p.201-203 — IBM Docs Condition Monitoring
Preventive Maintenance (PM)

📋 Objectifs IBM
- Comprendre le rôle des enregistrements de maintenance préventive (PM) en tant que modèles pour la génération d'ordres de travail planifiés.
- Expliquer comment les PM peuvent inclure des informations de plan de travail (
Job Plan) et de plan de sécurité (Safety Plan). - Décrire la création et la gestion des hiérarchies de PM pour planifier des groupes d'ordres de travail liés à un actif ou une localisation.
- Identifier les mécanismes de planification des travaux de PM pour les actifs sur un itinéraire (
Route). - Distinguer les différents types de maintenance (réactive, préventive, proactive) et positionner le PM dans cette taxonomie.
- Expliquer comment Maximo Manage permet de passer d'une gestion de la maintenance réactive à une approche proactive grâce aux PM.
💡 Points clés
- Maintenance Préventive (PM) — Les enregistrements de PM sont des modèles fondamentaux dans Maximo Manage pour la planification et la génération automatiques d'ordres de travail de maintenance.
- Génération d'Ordres de Travail — Un PM est conçu pour générer des ordres de travail (
WORKORDER) de manière récurrente, assurant ainsi que les tâches de maintenance sont effectuées à intervalles réguliers ou selon des conditions spécifiques. - Intégration
Job PlanetSafety Plan— Chaque PM peut intégrer unJob Plandétaillé et unSafety Plan, dont les informations sont automatiquement copiées dans les ordres de travail générés, garantissant cohérence et conformité. - Hiérarchies de PM — Il est possible de créer des relations parent-enfant entre des PM similaires pour former des hiérarchies, permettant la génération d'ensembles d'ordres de travail liés pour des actifs ou des localisations complexes.
- Planification par Itinéraire (
Route) — Les PM peuvent être associés à des itinéraires, ce qui permet de planifier des travaux de maintenance pour plusieurs actifs ou localisations le long d'un parcours défini, optimisant ainsi les déplacements et les ressources. - Modèle de Données — Les informations définies dans un PM, telles que les fréquences, les compteurs (
METER), les dates de début et les durées estimées, sont des attributs clés qui dictent la logique de génération des ordres de travail. - Objectif Stratégique — L'implémentation des PM vise à réduire les pannes imprévues, prolonger la durée de vie des équipements, optimiser les coûts de maintenance et améliorer la sécurité opérationnelle.
📐 Architecture des PM et leur rôle dans la gestion des ordres de travail
La maintenance préventive (PM) est une pierre angulaire de la stratégie EAM (Enterprise Asset Management) dans Maximo Manage. Elle permet aux organisations de passer d'une approche réactive, où les interventions ont lieu après une panne, à une approche proactive et planifiée. Un enregistrement de PM n'est pas un ordre de travail en soi, mais plutôt un modèle intelligent qui déclenche la création d'ordres de travail basés sur des critères prédéfinis.
Ces critères peuvent inclure des intervalles de temps (mensuel, trimestriel), des relevés de compteurs (heures de fonctionnement, kilomètres parcourus) ou une combinaison des deux. L'architecture des PM est conçue pour être flexible, permettant d'associer un PM à un actif spécifique (ASSETNUM), à une localisation (LOCATION), ou même à un itinéraire (Route) couvrant plusieurs points d'intervention. Cette flexibilité est essentielle pour s'adapter à la diversité des besoins de maintenance au sein d'une entreprise.
WORKORDER)"]:::primary
G["Actif (ASSET)"]:::quaternary
H["Localisation (LOCATION)"]:::quaternary
I["Itinéraire (Route)"]:::quaternary
A -- 'Définit les règles de' --> B
A -- 'Définit les règles de' --> C
A -- 'Contient' --> D
A -- 'Contient' --> E
B -- 'Déclenche' --> F
C -- 'Déclenche' --> F
F -- 'Hérite de' --> D
F -- 'Hérite de' --> E
A -- 'Appliqué à' --> G
A -- 'Appliqué à' --> H
A -- 'Appliqué à' --> I
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1FFEE,stroke:#82C91E,stroke-width:2px,color:#0F172A
classDef tertiary fill:#E0F2FE,stroke:#38BDF8,stroke-width:2px,color:#0F172A
classDef quaternary fill:#FFFBEB,stroke:#FBBF24,stroke-width:2px,color:#0F172A
">
📊 Comparaison des stratégies de maintenance
La maintenance préventive se situe au carrefour de différentes stratégies de maintenance. Comprendre ces distinctions est crucial pour optimiser la gestion des actifs et choisir l'approche la plus adaptée à chaque situation. Maximo Manage supporte l'ensemble de ces stratégies, mais le PM est spécifiquement conçu pour l'approche préventive et sert de base à des stratégies plus avancées comme la maintenance proactive.
Le tableau ci-dessous compare les caractéristiques principales des trois grandes catégories de maintenance, mettant en lumière la valeur ajoutée de la maintenance préventive gérée par des PM dans Maximo.
| Stratégie de Maintenance | Description | Déclencheur principal | Avantages | Inconvénients | Exemple Maximo |
|---|---|---|---|---|---|
| Réactive (Corrective) | Intervention après la défaillance de l'équipement. | Panne ou défaillance inattendue. | Coût initial faible (pas de planification complexe). | Temps d'arrêt imprévus, coûts de réparation élevés, risques de sécurité. | Création d'un WORKORDER manuel suite à un incident ou une demande de service (Service Request). |
Préventive (PM) |
Intervention planifiée à intervalles réguliers ou selon des compteurs pour éviter les pannes. | Temps (calendrier) ou utilisation (compteur). | Réduit les pannes imprévues, prolonge la durée de vie des actifs, meilleure planification des ressources. | Peut entraîner une maintenance inutile (remplacement de pièces encore fonctionnelles), coûts de planification. | Génération automatique de WORKORDER à partir d'un enregistrement Preventive Maintenance. |
| Proactive (Condition-Based) | Intervention basée sur l'état réel de l'équipement, détecté par des capteurs ou des inspections. | Données de condition (vibration, température, pression) ou relevés de compteurs spécifiques. | Optimise les intervalles de maintenance, réduit les coûts, maximise la disponibilité des actifs. | Investissement initial en technologies de surveillance, complexité de l'analyse des données. | Utilisation de Condition Monitoring et de METER pour déclencher des WORKORDER via des Escalations ou des PM basés sur des seuils. |
⚙️ Configuration et gestion des PM dans Maximo Manage
La configuration d'un enregistrement de maintenance préventive (PM) dans Maximo Manage est un processus structuré qui garantit la génération correcte et opportune des ordres de travail. L'application Preventive Maintenance est le point central pour définir tous les paramètres nécessaires. Chaque PM est un modèle qui encapsule la logique de planification et les détails des tâches à effectuer.
Lors de la création d'un PM, plusieurs informations clés doivent être renseignées. Cela inclut l'identification de l'actif ou de la localisation concernée, la définition des fréquences de maintenance (basées sur le temps, les compteurs ou les deux), et l'association d'un Job Plan qui décrit les étapes détaillées de la maintenance. Un Safety Plan peut également être lié pour assurer la conformité aux normes de sécurité.
Les fréquences peuvent être simples (ex: tous les mois) ou complexes, incluant des décalages (Offset) et des règles de report. Maximo permet également de définir des hiérarchies de PM, où un PM parent peut générer des ordres de travail pour des PM enfants, créant ainsi des ensembles de tâches coordonnées. La gestion des itinéraires (Route) est une autre fonctionnalité puissante, permettant d'appliquer un PM à une séquence d'actifs ou de localisations, optimisant ainsi les tournées des techniciens.
- Création d'un PM — Accédez à l'application
Preventive Maintenance. Renseignez les champs obligatoires tels que la description, l'actif ou la localisation cible, et le site (SITEID). - Définition des Fréquences — Spécifiez les intervalles de temps (ex: 3 mois, 1 an) ou les relevés de compteurs (ex: 500 heures, 10 000 km) qui déclencheront la génération de l'ordre de travail. Vous pouvez combiner les deux types de fréquences.
- Association
Job PlanetSafety Plan— Liez unJob Planexistant qui contient les tâches, les ressources (main-d'œuvre, matériaux, services) et les outils nécessaires. Ajoutez unSafety Planpour les consignes de sécurité spécifiques. - Paramètres de Génération — Configurez les options de génération, telles que la date de début de la prochaine génération, la fenêtre de génération anticipée, et si le PM est actif ou non.
- Hiérarchies de PM — Pour des maintenances complexes, créez des PM enfants liés à un PM parent, permettant une coordination des ordres de travail générés.
- Utilisation des Itinéraires (
Route) — Si le PM s'applique à plusieurs points d'intervention séquentiels, associez-le à unRoutepour générer des ordres de travail pour chaque point de l'itinéraire.
🔄 Cycle de vie d'un enregistrement de maintenance préventive (PM)
Le cycle de vie d'un enregistrement de maintenance préventive dans Maximo Manage est un processus dynamique qui commence par sa création et se poursuit par la génération récurrente d'ordres de travail. Ce cycle assure que les actifs reçoivent la maintenance nécessaire de manière systématique, contribuant à leur fiabilité et à leur longévité. Chaque étape du cycle est cruciale pour maintenir l'efficacité du programme de maintenance préventive.
Un PM passe par plusieurs états, de sa conception à son activation, et potentiellement à sa révision ou sa désactivation. La gestion de ces états est essentielle pour contrôler la planification et l'exécution des tâches de maintenance. Une fois actif, le PM surveille les conditions de déclenchement (temps ou compteur) et génère automatiquement des ordres de travail, qui entrent ensuite dans leur propre cycle de vie (planification, approbation, exécution, clôture).
⚠️ Pièges IBM
Job Plan
Un piège courant est de confondre un enregistrement de maintenance préventive (PM) avec un Job Plan. L'étudiant pourrait penser que le PM contient directement les tâches à effectuer. Or, le PM est le déclencheur et le planificateur de la maintenance, tandis que le Job Plan est le détail des tâches. Un PM fait référence à un ou plusieurs Job Plan, mais ne les contient pas directement. Si un Job Plan est modifié, tous les PM qui y font référence bénéficieront de la mise à jour lors de la prochaine génération d'ordres de travail, sans qu'il soit nécessaire de modifier chaque PM individuellement. L'examen peut présenter des scénarios où la modification d'un Job Plan est nécessaire, et il est crucial de comprendre que cela impacte les PM liés, mais que le PM lui-même n'est pas le lieu de définition des tâches.
La gestion des fréquences dans un PM peut être complexe et source d'erreurs. Les PM peuvent être déclenchés par le temps (calendrier), par des relevés de compteurs (METER), ou par une combinaison des deux. Un piège fréquent est de mal interpréter la logique de "prochaine date de génération" ou de "prochain relevé de compteur". Par exemple, si un PM est configuré pour générer un ordre de travail tous les 3 mois OU tous les 500 heures, Maximo générera l'ordre de travail dès que l'UNE des conditions est remplie, et non les deux. De plus, les options de décalage (Offset) ou de report (Roll Over) peuvent modifier le comportement attendu. Il est essentiel de bien comprendre comment Maximo calcule la prochaine date ou le prochain relevé de déclenchement pour éviter la génération d'ordres de travail trop tôt, trop tard, ou pas du tout.
L'utilisation des hiérarchies de PM (parent-enfant) et des itinéraires (Route) peut être mal comprise. Un PM parent génère des ordres de travail pour ses PM enfants, créant une structure d'ordres de travail liés. Si le PM parent est désactivé, cela peut empêcher la génération des ordres de travail pour les PM enfants, même si ces derniers sont actifs. De même, un PM associé à un Route générera un ordre de travail pour chaque point de l'itinéraire. L'examen peut tester la compréhension de l'impact d'une modification ou d'une désactivation d'un élément dans ces structures complexes. Il est important de se rappeler que la hiérarchie et l'itinéraire définissent la portée et la relation des ordres de travail générés, et non les tâches elles-mêmes.
🎯 Carte mémoire
Quelle est la fonction principale d'un enregistrement de maintenance préventive (PM) dans Maximo Manage ?
La fonction principale d'un enregistrement de PM est de servir de modèle pour la génération automatique et récurrente d'ordres de travail de maintenance. Il définit les règles de planification (fréquences temporelles ou basées sur des compteurs) et les détails des tâches à effectuer via un Job Plan associé, garantissant ainsi une maintenance systématique des actifs.
Comment un Job Plan et un Safety Plan sont-ils liés à un PM, et quel est l'avantage de cette relation ?
Un Job Plan et un Safety Plan sont associés à un PM. Lorsque le PM génère un ordre de travail, les informations contenues dans ces plans sont automatiquement copiées dans le nouvel ordre de travail. L'avantage est la réutilisation et la standardisation : les modifications apportées au Job Plan ou au Safety Plan sont répercutées sur tous les futurs ordres de travail générés par les PM qui y font référence, sans nécessiter de modification individuelle de chaque PM.
Expliquez le concept de hiérarchie de PM et son utilité.
Une hiérarchie de PM permet de créer des relations parent-enfant entre des enregistrements de PM. Un PM parent peut déclencher la génération d'ordres de travail pour un groupe de PM enfants. Cette fonctionnalité est utile pour coordonner des maintenances complexes sur des ensembles d'actifs liés ou des systèmes, permettant de générer des hiérarchies d'ordres de travail qui reflètent la structure des équipements ou des processus.
Qu'est-ce qu'un PM basé sur un itinéraire (Route) et pourquoi est-il utilisé ?
Un PM basé sur un itinéraire est un enregistrement de maintenance préventive qui est appliqué à une séquence prédéfinie d'actifs ou de localisations (un Route). Il est utilisé pour optimiser la planification et l'exécution des tâches de maintenance lorsque plusieurs points d'intervention doivent être visités séquentiellement, réduisant ainsi les temps de déplacement et améliorant l'efficacité des techniciens.
Bonne réponse : B
Pourquoi cette question existe — STU §6.3 — cette question valide la maîtrise des associations clés d'un PM, pierre angulaire de la maintenance préventive. Les distracteurs ciblent les confusions courantes entre objets liés (Asset/Location) et objets non liés (PO, SLA). En pratique terrain, omettre un Safety Plan dans un environnement réglementé (SOX, ISO) génère des non-conformités critiques.
Le contexte théorique d'abord — Un PM dans Maximo est un template de maintenance récurrente, associé à des Asset ou Location cibles. Il peut référencer : (1) des ressources (Job Plan, Route), (2) des documents (Safety Plan/JSA), et (3) des données techniques (spécifications d'équipement). Ces associations évitent la duplication d'information et assurent la cohérence.
Ce que Maximo en fait — version opérationnelle — Dans l'app Preventive Maintenance > onglet Associated Records : bouton Select Asset/Select Location pour la cible, Attach Job Plan pour les tâches, Attach Documents (Safety Plan). La Route s'ajoute via l'onglet Routes. Toutes les modifications se propagent aux WO générés.
Exemple chiffré — PM #P-2478 : associé à 3 Asset (pompes P-101/102/103), 1 Job Plan (JP-85 avec 12 étapes), 1 Route (RTE-9 couvrant 8 points de contrôle), et 2 Safety Plan (SP-30 pour isolation électrique, SP-31 pour EPI).
Analogie quotidienne — Comme une recette de cuisine : le PM est la fiche recette (ingrédients = Assets, étapes = Job Plan), les Safety Plans sont les consignes sanitaires, et la Route est l'ordre de passage dans les placards.
Pourquoi A est faux — Pattern D6 Mauvaise-app : un Purchase Order (PO) se lie à un Work Order, pas directement au PM.
Pourquoi C est faux — Pattern D2 Inventé : un SLA (Service Level Agreement) n'est pas associable à un PM, seulement à des SR/Incidents.
Pourquoi D est faux — Pattern D5 Champ-frère : un Failure Class (sous FAILURECODE) sert aux analyses RCA, pas aux PM.
- PM Hierarchy — structure parent-enfant pour les PMs liés.
- Job Plan — séquence standardisée de tâches/main-d'œuvre.
- Route — parcours physique pour les inspections itinérantes.
- Safety Plan/JSA — procédures de sécurité attachables.
- Seasonal Dates — exceptions calendaires pour les PMs saisonniers.
- PM lie Asset/Location + Job Plan + Route + Safety Plans.
- PO/SLA/Failure Class = associations invalides (D2/D5/D6).
- Onglet
Associated Records= hub central des liens.
- STU sub-objective §6.3 — Preventive Maintenance associations
- [EOTRAG] Query — « Maximo PM associated records Asset Location Job Plan Route Safety » (confidence 0.98)
- master-map.pdf p.221-225 — IBM Docs Preventive Maintenance Setup
Bonne réponse : C
Pourquoi cette question existe — STU §6.3 — cette question teste la compréhension de la propagation des changements d'un Master PM vers ses PM associés, un mécanisme clé dans la gestion de la maintenance préventive. Les distracteurs montrent les erreurs courantes : confusion entre propagation immédiate et action manuelle (D1), inversion des rôles entre Master et associés (D3), et une procédure sur-engineered (D10). En pratique terrain, l'oubli de l'action « Update Associated PMs » est une erreur fréquente.
Le contexte théorique d'abord — Un Master PM est un modèle centralisé qui définit les paramètres de maintenance pour plusieurs PM associés. Les PM associés peuvent être liés à des actifs ou des emplacements spécifiques. Les changements apportés au Master PM ne se propagent pas automatiquement ; ils nécessitent l'exécution de l'action « Update Associated PMs ». Les PM associés peuvent être déliés du Master PM via l'option « Override Updates from Master PM », ce qui empêche toute propagation ultérieure.
Ce que Maximo en fait — version opérationnelle — Dans l'application Preventive Maintenance, après avoir modifié un Master PM, l'utilisateur doit sélectionner l'action « Update Associated PMs » pour propager les changements. Les PM associés qui ont l'option « Override Updates from Master PM » cochée ne seront pas affectés. Cette action met à jour les champs tels que la fréquence et les dates de prochaine échéance dans les PM associés.
Exemple chiffré — Un Master PM avec 12 PM associés : 3 ont l'option « Override Updates from Master PM » cochée, donc seuls 9 PM seront mis à jour lors de l'exécution de l'action « Update Associated PMs ». La fréquence passe de 30 jours à 45 jours pour ces 9 PM.
Analogie quotidienne — C'est comme un modèle de document Word : vous modifiez le modèle, mais les documents existants ne sont mis à jour que lorsque vous choisissez de les actualiser manuellement.
Pourquoi A est faux — Pattern D1 Hérité : Les changements ne se propagent pas automatiquement ; l'action « Update Associated PMs » doit être exécutée manuellement.
Pourquoi B est faux — Pattern D3 Inverse : Les Master PM ne lisent pas les données des PM associés ; ils propagent leurs propres changements vers les PM associés.
Pourquoi D est faux — Pattern D10 Procédure-plausible : Les PM associés ne sont pas recréés à chaque sauvegarde du Master PM ; ils sont simplement mis à jour via l'action « Update Associated PMs ».
- Master PM — Modèle centralisé pour les PM associés.
- Associated PM — PM lié à un actif ou un emplacement spécifique.
- Override Updates from Master PM — Option pour empêcher la propagation des changements.
- Update Associated PMs — Action pour propager les changements du Master PM.
- Work Order Generation Information — Zone où les champs mis à jour sont affichés.
- Les changements du Master PM nécessitent l'action « Update Associated PMs ».
- Les PM associés avec « Override Updates from Master PM » ne sont pas mis à jour.
- La propagation met à jour la fréquence et les dates de prochaine échéance.
- STU sub-objective §6.3 — Master PM and associated PMs
- [EOTRAG] Query — « Master PM propagate changes associated PMs Update Associated PMs action » (confidence 0.97)
- master-map.pdf p.210-213 — IBM Docs Preventive Maintenance
Bonne réponse : D
Pourquoi cette question existe — STU §6.3 — la question teste la compréhension du rôle de l'Earliest Next Due Date dans la gestion des PMs. Ce champ est crucial pour éviter la sur-génération de work orders (WO) sur les PMs basées sur la fréquence. Les distracteurs montrent les erreurs typiques : confondre ce champ avec une date SLA (D3), ignorer son rôle de contrôle (D2), ou penser qu'il est purement cosmique (D4). En pratique terrain, ce champ est souvent mal configuré, entraînant des WO générés trop tôt.
Le contexte théorique d'abord — L'Earliest Next Due Date est un champ clé dans les PMs basées sur la fréquence. Il définit la date minimale à laquelle un WO peut être généré. Ce champ est particulièrement utile pour éviter que des WO soient créés prématurément, ce qui pourrait entraîner des interventions inutiles. Il fonctionne en conjonction avec le Next Due Date et le Alert Lead pour déterminer quand un WO doit être généré.
Ce que Maximo en fait — version opérationnelle — Dans l'application Preventive Maintenance, l'Earliest Next Due Date est configuré dans l'onglet Frequency. Lorsque le système vérifie si un WO doit être généré, il compare cette date avec la date système et le Next Due Date. Si la date système est antérieure à l'Earliest Next Due Date, aucun WO n'est généré, même si les autres critères sont remplis.
Exemple chiffré — Une PM avec une fréquence de 30 jours, un Next Due Date au 15 juin et un Earliest Next Due Date au 1er juin. Si la date système est le 25 mai, aucun WO n'est généré car la date système est antérieure à l'Earliest Next Due Date. Le WO sera généré uniquement à partir du 1er juin.
Analogie quotidienne — C'est comme un minuteur de cuisine qui ne sonne pas avant une heure précise, même si la nourriture semble prête avant. Cela évite de vérifier trop tôt et de gaspiller des ressources.
Pourquoi A est faux — Pattern D2 Inventé : L'Earliest Next Due Date ne force pas la PM à s'exécuter à une date précise, il empêche simplement la génération de WO avant cette date.
Pourquoi B est faux — Pattern D4 Demi-vérité : Ce champ n'est pas cosmique, il a un rôle actif dans le contrôle de la génération des WO.
Pourquoi C est faux — Pattern D3 Inverse : L'Earliest Next Due Date ne définit pas de SLA, il contrôle uniquement la génération des WO.
- Earliest Next Due Date — date minimale pour générer un WO.
- Next Due Date — date prévue pour la prochaine PM.
- Alert Lead — délai avant la génération d'une alerte PM.
- Frequency-based PMs — PMs basées sur une fréquence temporelle.
- Work Order Generation — processus de création des WO à partir des PMs.
- Earliest Next Due Date empêche la génération prématurée des WO.
- Ce champ est crucial pour les PMs basées sur la fréquence.
- Il fonctionne avec Next Due Date et Alert Lead pour contrôler les WO.
- STU sub-objective §6.3 — Preventive Maintenance (PM)
- [EOTRAG] Query — « Earliest Next Due Date PM Maximo » (confidence 0.93)
- master-map.pdf p.888-890 — IBM Docs Preventive Maintenance
Bonne réponse : A
Pourquoi cette question existe — STU §6.3 — cette question teste la compréhension du mécanisme de synchronisation entre un PM local et son Master PM, et comment le désactiver. Les distracteurs montrent des solutions extrêmes (D10) ou inadaptées (D3, D6) pour un besoin courant : personnaliser un PM local sans rompre la hiérarchie globale. En pratique terrain, l'oubli du "Break from Master" est la cause principale de réinitialisations intempestives.
Le contexte théorique d'abord — Un Master PM est un modèle centralisé qui propage ses modifications vers les PMs enfants. Par défaut, les champs synchronisés (dont les job plans) sont écrasés lors des mises à jour. Le flag Override Updates from Master PM et l'action Break from Master permettent de désactiver cette synchronisation tout en conservant la référence au Master PM.
Ce que Maximo en fait — version opérationnelle — Dans l'application Preventive Maintenance, ouvrir le PM concerné > cliquer sur Break from Master dans le menu Actions. Cela active automatiquement le checkbox Override Updates from Master PM sur l'onglet PM. Les modifications locales (job plans, fréquences) ne seront plus écrasées.
Exemple chiffré — PM-247 (enfant de MASTER-PM-12) : après "Break from Master", l'équipe locale ajoute 3 tâches spécifiques au job plan (vs 5 dans le master). 47 jours plus tard, une mise à jour du MASTER-PM-12 modifie 8 champs mais ne touche pas PM-247.
Analogie quotidienne — C'est comme désactiver la synchronisation d'un dossier Google Drive tout en gardant le lien vers le fichier source : vous pouvez modifier votre copie locale sans que vos changements soient écrasés par les mises à jour du propriétaire.
Pourquoi B est faux — Pattern D3 Inverse : désactiver le Master PM impacterait tous ses enfants, pas seulement le PM local concerné.
Pourquoi C est faux — Pattern D10 Procédure-plausible : cloner créerait un doublon non lié au Master PM, solution sur-engineered pour ce besoin.
Pourquoi D est faux — Pattern D6 Mauvaise-app : modifier manuellement la DB contourne l'interface native et risque la corruption des données.
- Master PM — Modèle centralisé qui propage ses configurations.
- Override Updates — Flag empêchant la synchronisation des champs.
- Break from Master — Action activant le flag Override.
- Job Plan Sequence — Liste ordonnée des plans de travail associés.
- PM Hierarchy — Relation parent-enfant entre PMs.
- "Break from Master" désactive les mises à jour tout en conservant le lien.
- Ne pas modifier manuellement la DB pour ce besoin.
- Le flag Override se coche automatiquement via l'action native.
- STU sub-objective §6.3 — Master PM and local overrides
- [EOTRAG] Query — « Maximo Break from Master PM Override Updates checkbox » (confidence 0.98)
- master-map.pdf p.893-895 — IBM Docs Preventive Maintenance Synchronization
Bonne réponse : A,B
Pourquoi cette question existe — STU §6.3 — cette question valide la compréhension des deux mécanismes natifs de déclenchement des PM dans Maximo Manage 9.x. Les options incorrectes reflètent des confusions courantes : intégration avec d'autres modules (D6), fonctionnalités non implémentées (D2) ou logiques métier externes (D10). En contexte terrain, l'erreur fréquente est de tenter d'automatiser des PM via des workflows complexes alors que les mécanismes natifs suffisent.
Le contexte théorique d'abord — Les enregistrements de maintenance préventive (PM) dans Maximo reposent sur deux paradigmes fondamentaux : le déclenchement temporel (basé sur des intervalles calendaires) et le déclenchement métrologique (basé sur des lectures de compteurs). Ces mécanismes sont gérés dans l'application Preventive Maintenance via les champs FREQUENCY (temps) et METER (compteurs), avec possibilité de combinaison ("le premier des deux atteint").
Ce que Maximo en fait — version opérationnelle — Dans l'application Preventive Maintenance > onglet Scheduling : pour un time-based PM, on définit Frequency Unit (DAYS/WEEKS/MONTHS) et Frequency (valeur numérique). Pour un meter-based PM, on sélectionne un Meter et on définit Meter Frequency (ex: 500 heures). La génération des WO s'effectue via le PM Manager ou les Cron Tasks dédiées.
Exemple chiffré — PM #4572 : déclenchement à 90 jours OU 250 heures d'utilisation (mètre "ENGINE_HRS"). Dernier WO généré le 15/01 (statut COMP) avec relevé à 1850 hrs. Au 20/03 (65 jours écoulés, compteur à 2010 hrs) : aucun nouveau WO. Le 10/04 (86 jours) : génération automatique du WO #8912 car seuil temporel atteint avant le seuil métrologique (2150 hrs).
Analogie quotidienne — Comme le rappel de vidange d'une voiture : soit après X mois (time-based), soit après Y kilomètres (meter-based), selon le premier critère atteint. Le garage n'attend pas que la météo soit mauvaise ou que le prix de l'huile baisse pour intervenir.
Pourquoi C est faux — Pattern D2 Inventé : Maximo ne dispose pas d'intégration native avec des données météorologiques pour déclencher des PM.
Pourquoi D est faux — Pattern D6 Mauvaise-app : bien que le Condition Monitoring existe dans Maximo, il ne déclenche pas directement les PM (nécessiterait un workflow personnalisé).
Pourquoi E est faux — Pattern D10 Procédure-plausible : le coût est traité dans les rapports et KPI, mais ne fait pas partie des critères natifs de génération automatique des WO.
- Time-based PM — déclenchement basé sur des intervalles calendaires fixes.
- Meter-based PM — déclenchement basé sur l'utilisation mesurée d'un équipement.
- Combined trigger — utilisation conjointe des deux mécanismes ("le premier atteint").
- PM Hierarchy — relation parent-enfant entre PM pour coordonner des interventions complexes.
- Seasonal Dates — configuration de périodes actives/inactives pour les PM saisonniers.
- Seuls time-based et meter-based sont des triggers natifs de PM.
- Les deux mécanismes peuvent être combinés ("le premier des deux").
- Les autres critères nécessitent des développements personnalisés.
- STU sub-objective §6.3 — Preventive Maintenance triggering mechanisms
- [EOTRAG] Query — « Maximo PM time-based meter-based triggers » (confidence 0.98)
- master-map.pdf p.884-906 — IBM Docs Preventive Maintenance
Créer et gérer les Work Orders

📋 Objectifs IBM
- Comprendre le rôle central des ordres de travail (
WORKORDER) dans la gestion de la maintenance. - Identifier les informations essentielles contenues dans un ordre de travail, telles que les tâches, la main-d'œuvre, les matériaux, les services, les outils, les actifs et les emplacements.
- Maîtriser la création et la gestion des ordres de travail via l'application
Work Order Tracking. - Savoir comment initier le processus de gestion de la maintenance et créer un historique des travaux demandés et effectués.
- Appréhender l'intégration des inspections et des
Job Plansaux ordres de travail. - Distinguer les différentes méthodes de création d'ordres de travail et leurs implications.
💡 Points clés
WORKORDER— Un ordre de travail est le document central pour planifier, exécuter et enregistrer les activités de maintenance sur desASSETou desLOCATION.Work Order Tracking— C'est l'application principale dans Maximo pour créer, visualiser, modifier et gérer le cycle de vie complet des ordres de travail.- Contenu de l'
WORKORDER— Il détaille les tâches à effectuer, les heures de main-d'œuvre (LABOR), les services, les matériaux (ITEM), les outils nécessaires, lesASSETconcernés et lesLOCATIONd'intervention. - Historique de maintenance — La création d'un
WORKORDERinitie un enregistrement historique précieux des travaux demandés et réalisés, essentiel pour l'analyse et l'amélioration continue. Job Plans— Des plans de travail prédéfinis peuvent être associés aux ordres de travail pour standardiser les tâches, les ressources et les procédures, améliorant ainsi l'efficacité.- Inspections — Les inspections peuvent être intégrées aux ordres de travail, notamment via le
Work Supervision Work Center(versions antérieures à MAS 8.9/Manage 8.5), pour garantir la qualité et la conformité des interventions. - Création multiple — Les ordres de travail peuvent être créés non seulement dans l'application
Work Order Tracking, mais aussi à partir d'autres applications ou processus Maximo. - Autonumérotation — Maximo peut configurer l'autonumérotation des ordres de travail, avec la possibilité d'ajouter un préfixe (ex: "AN" pour les numéros d'actifs).
📐 Architecture des Ordres de Travail dans Maximo
L'ordre de travail (WORKORDER) est la pierre angulaire de la gestion de la maintenance dans IBM Maximo Manage. Il ne s'agit pas seulement d'un formulaire, mais d'un objet complexe qui agrège des informations provenant de multiples entités et applications au sein du système. Sa structure est conçue pour capturer toutes les facettes d'une intervention de maintenance, de la planification initiale à la clôture finale.
Chaque WORKORDER est lié à un ASSET ou une LOCATION spécifique, définissant ainsi le périmètre de l'intervention. Il intègre des détails sur les ressources nécessaires (main-d'œuvre, matériaux, outils, services), les tâches à accomplir et les éventuelles inspections. Cette interconnexion avec d'autres modules de Maximo permet une vision holistique et un suivi précis de chaque activité de maintenance, contribuant à la traçabilité et à l'optimisation des opérations.
Work Order Tracking est le point d'entrée principal pour la création et la gestion des WORKORDER, qui sont ensuite liés à divers objets Maximo tels que les ASSET, LOCATION, LABOR, ITEM, TOOL, SERVICE, JOBPLAN et INSPECTION.📊 Comparaison des méthodes de création d'ordres de travail
La flexibilité de Maximo permet de créer des ordres de travail à partir de diverses sources, chacune adaptée à des scénarios d'utilisation spécifiques. Comprendre ces distinctions est crucial pour optimiser les processus de maintenance et garantir l'efficacité opérationnelle.
Que ce soit pour une intervention corrective urgente ou une maintenance préventive planifiée, Maximo offre des chemins de création adaptés, chacun avec ses avantages en termes d'automatisation, de contrôle et de traçabilité.
| Méthode de Création | Description | Avantages Clés | Cas d'Usage Typiques |
|---|---|---|---|
Work Order Tracking (Manuelle) |
Création directe d'un WORKORDER dans l'application dédiée. L'utilisateur saisit toutes les informations manuellement. |
Contrôle total sur les détails, flexibilité maximale. | Maintenance corrective imprévue, ajustements de dernière minute, ordres de travail complexes uniques. |
Depuis un Job Plan |
Génération d'un WORKORDER à partir d'un Job Plan préexistant. Le Job Plan pré-remplit les tâches, ressources, etc. |
Standardisation des processus, réduction des erreurs, gain de temps. | Maintenance préventive, tâches répétitives, interventions standardisées. |
Depuis un PM (Preventive Maintenance) |
Génération automatique d'un WORKORDER basé sur un calendrier ou des compteurs définis dans un enregistrement de maintenance préventive. |
Automatisation complète, planification proactive, optimisation des ressources. | Maintenance basée sur le temps (ex: tous les mois), basée sur l'utilisation (ex: toutes les 1000 heures de fonctionnement). |
Depuis un Service Request |
Conversion d'une demande de service (signalée par un utilisateur) en WORKORDER pour intervention. |
Traçabilité de la demande initiale, amélioration du service client. | Réparations signalées par les utilisateurs, demandes d'entretien non urgentes. |
Depuis un Condition Monitoring |
Génération automatique d'un WORKORDER suite à la détection d'une condition anormale (ex: dépassement de seuil de vibration). |
Maintenance prédictive, réduction des pannes inattendues. | Surveillance de l'état des équipements, détection précoce de défaillances. |
⚙️ Gestion opérationnelle des Ordres de Travail
La gestion des ordres de travail est un processus dynamique qui s'étend de la création initiale à la clôture finale, impliquant plusieurs étapes et interactions au sein de Maximo. L'application Work Order Tracking est l'interface principale pour orchestrer ces activités, mais d'autres applications et Work Centers peuvent également jouer un rôle.
Un WORKORDER bien géré assure non seulement que le travail est effectué efficacement, mais aussi qu'un historique précis est conservé, ce qui est essentiel pour l'analyse des coûts, la planification future et l'amélioration continue des stratégies de maintenance. Par exemple, pour un site industriel avec 500 ASSET critiques, la création rapide et précise des WORKORDER est fondamentale pour minimiser les temps d'arrêt.
- Création de l'
WORKORDER— L'utilisateur initie un nouvel ordre de travail, soit manuellement dansWork Order Tracking, soit via une autre source (PM,Service Request, etc.). Les informations initiales comme l'ASSET, laLOCATIONet la description du problème sont saisies. - Planification des ressources — Les ressources nécessaires (
LABOR,ITEM,TOOL,SERVICE) sont définies. DesJob Planspeuvent être appliqués pour pré-remplir ces détails. Les inspections peuvent être ajoutées, notamment via leWork Supervision Work Center(pour les versions antérieures à MAS 8.9/Manage 8.5). - Approbation (
WAPPRversAPPR) — L'ordre de travail passe par un processus d'approbation, souvent via unWorkflow, pour s'assurer que les ressources sont disponibles et que le travail est autorisé. - Exécution du travail — Une fois approuvé, le travail est assigné et exécuté. Les techniciens peuvent enregistrer les heures de travail (
LABTRANS), les matériaux utilisés (MATUSETRANS) et les observations. - Rapport d'achèvement (
COMP) — Une fois le travail terminé, le technicien ou le superviseur met à jour le statut de l'ordre de travail àCOMPLETE, en ajoutant les détails finaux et les codes de défaillance (FAILURECODE). - Clôture (
CLOSED) — Après vérification et validation de toutes les informations, l'ordre de travail est clôturé, marquant la fin de son cycle de vie et l'archivage de son historique.
🔄 Cycle de vie d'un Ordre de Travail
Le cycle de vie d'un ordre de travail dans Maximo est un processus structuré qui garantit que chaque demande de maintenance est traitée de manière cohérente et traçable. Il commence par la détection d'un besoin et se termine par la clôture de l'enregistrement, avec plusieurs étapes intermédiaires pour la planification, l'approbation et l'exécution.
Chaque transition de statut est significative et peut déclencher des actions ou des notifications spécifiques, assurant que toutes les parties prenantes sont informées et que les processus sont respectés. La compréhension de ce cycle est fondamentale pour tout utilisateur de Maximo impliqué dans la gestion de la maintenance.
⚠️ Pièges IBM
Work Centers
Les candidats peuvent être induits en erreur par des questions sur le Work Supervision Work Center ou le Work Execution Work Center pour la création d'ordres de travail. Il est crucial de se rappeler que, comme indiqué dans les chunks RAG, ces Work Centers ne sont plus disponibles à partir de Maximo Application Suite 8.9 et Maximo Manage 8.5. Les informations les concernant s'appliquent uniquement aux versions antérieures (8.4 et précédentes). Une question pourrait tester cette connaissance en présentant un scénario où un superviseur tente d'ajouter des inspections via le Work Supervision Work Center dans une version récente de Maximo.
WORKORDER
Une question pourrait lister des éléments et demander lesquels sont "obligatoires" ou "essentiels" pour un ordre de travail. Bien que l'WORKORDER puisse contenir de nombreux détails (tâches, main-d'œuvre, matériaux, outils, actifs, emplacements, services), tous ne sont pas nécessairement requis à la création initiale ou pour que l'ordre de travail soit valide. Le piège est de considérer tous les éléments listés dans la documentation comme des prérequis absolus pour la création. Les éléments fondamentaux sont généralement l'ASSET ou la LOCATION et une description du travail, les autres étant ajoutés au fur et à mesure de la planification et de l'exécution.
Il est facile de supposer que les techniciens peuvent créer des ordres de travail par défaut dans le Work Execution Work Center. Cependant, les chunks RAG précisent que "par défaut, les techniciens ne peuvent pas créer d'ordres de travail dans le Work Execution Work Center". Les administrateurs doivent explicitement leur accorder cette permission et configurer le Work Center pour afficher ces ordres. Une question pourrait présenter un scénario où un technicien ne peut pas créer un WORKORDER et demander la cause, la bonne réponse étant souvent liée aux permissions ou à la configuration.
🎯 Carte mémoire
Quel est le rôle principal de l'application Work Order Tracking dans Maximo ?
L'application Work Order Tracking est l'interface principale pour créer, gérer et suivre le cycle de vie complet des ordres de travail (WORKORDER). Elle permet d'initier le processus de maintenance, de planifier les ressources et de conserver un historique détaillé des interventions.
Quelles sont les informations clés qu'un ordre de travail peut contenir selon la documentation IBM ?
Un ordre de travail peut inclure les tâches effectuées, les heures de main-d'œuvre (LABOR), les services utilisés, les matériaux (ITEM) consommés, les outils (TOOL) requis, les actifs (ASSET) sur lesquels le travail a été effectué et les emplacements (LOCATION) où le travail a eu lieu.
Comment les Job Plans contribuent-ils à la création et à la gestion des ordres de travail ?
Les Job Plans sont des modèles prédéfinis qui peuvent être associés aux ordres de travail pour standardiser les tâches, les ressources (main-d'œuvre, matériaux, outils) et les procédures. Ils permettent de pré-remplir automatiquement de nombreuses informations, réduisant ainsi les erreurs et accélérant le processus de planification des ordres de travail.
À partir de quelle version de Maximo Application Suite ou Maximo Manage les Work Supervision Work Center et Work Execution Work Center ne sont-ils plus disponibles pour la création d'ordres de travail ?
Ces Work Centers ne sont plus disponibles à partir de Maximo Application Suite 8.9 et Maximo Manage 8.5. Les informations les concernant s'appliquent uniquement aux versions antérieures (8.4 et précédentes).
Bonne réponse : C
Pourquoi cette question existe — STU §6.4 — La question teste la connaissance des trois sources principales de création des Work Orders dans Maximo Manage. Les erreurs courantes incluent la confusion avec d'autres modules (D6) ou l'omission des sources conditionnelles (D4). En contexte terrain, cette distinction est cruciale pour la planification et le suivi des activités de maintenance.
Le contexte théorique d'abord — Les Work Orders peuvent être générés automatiquement à partir de deux sources principales : Preventive Maintenance (planification périodique) et Condition Monitoring (déclenchement sur seuil). La troisième méthode est la création manuelle directe dans l'application Work Order Tracking. Ces mécanismes couvrent 95% des cas d'usage documentés.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Order Tracking : 1) Création manuelle via New Work Order 2) Génération automatique depuis Preventive Maintenance via les cycles configurés 3) Déclenchement depuis Condition Monitoring lorsque les seuils des mesures dépassent les limites définies. Le statut initial est typiquement WAPPR ou PLANNING selon la configuration.
Exemple chiffré — Un site industriel génère 78% de ses WO via PM (247/mois), 15% via Condition Monitoring (47/mois), et 7% manuellement (22/mois). Les WO PM ont un cycle moyen de 30 jours, tandis que les WO conditionnels sont traités en 2,4 heures en moyenne.
Analogie quotidienne — Comme un système de rappels médicaux : certains sont programmés (contrôle annuel), d'autres déclenchés par symptômes (fièvre > 39°C), et d'autres pris en urgence (appel direct au médecin).
Pourquoi A est faux — Pattern D6 Mauvaise-app : SLA est géré dans un module distinct et ne génère pas directement des Work Orders.
Pourquoi B est faux — Pattern D4 Demi-vérité : Les Purchase Orders sont liés aux achats, pas à la création initiale des WO.
Pourquoi D est faux — Pattern D2 Inventé : Les Asset templates et Routes ne sont pas des sources documentées de création de WO dans Maximo Manage.
- Preventive Maintenance — génération périodique de WO selon un calendrier.
- Condition Monitoring — création sur seuil de mesure dépassé.
- WOSTATUS — statuts possibles : WAPPR, PLANNING, ACTIVE, COMPLETE.
- Work Order Tracking — application principale pour la gestion des WO.
- Meter Readings — données alimentant le Condition Monitoring.
- 3 sources : PM (planifié), Condition (seuil), Manuel (urgences).
- Pas de lien direct entre Purchase Orders et création de WO.
- Les SLA influencent les délais mais ne créent pas les WO.
- STU sub-objective §6.4 — Work Order creation sources
- [EOTRAG] Query — « Maximo Work Order creation sources Preventive Maintenance Condition Monitoring » (confidence 0.98)
- master-map.pdf p.201-204 — IBM Docs Work Order Fundamentals
Bonne réponse : D
Pourquoi cette question existe — STU §6.4 — cette question vérifie la maîtrise de la hiérarchie standard de reporting des défaillances dans Maximo, un concept clé pour le suivi des problèmes et l'amélioration continue. Les distracteurs testent les confusions courantes entre l'ordre des étapes (D1, D3) et l'omission de la classe de défaillance (D4), erreurs fréquentes lors de la création des rapports terrain.
Le contexte théorique d'abord — La hiérarchie de reporting des défaillances dans Maximo suit un processus structuré en 4 niveaux : Failure Class (catégorisation générale), Problem (description du symptôme), Cause (origine technique) et Remedy (action corrective). Cette structure permet une analyse RCA (Root Cause Analysis) standardisée et un reporting cohérent.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Order Tracking, sous l'onglet Failure Reporting : sélectionner d'abord la Failure Class dans la liste déroulante, puis renseigner le Problem, identifier la Cause via le lookup, et enfin documenter le Remedy appliqué. Les champs sont liés aux tables FAILURECODE et FAILUREREPORT.
Exemple chiffré — Pour une turbine défectueuse : Failure Class = "Mécanique" (1 sur 5 classes disponibles), Problem = "Vibration excessive" (3 problèmes répertoriés pour cette classe), Cause = "Roulement défectueux" (2 causes possibles pour ce problème), Remedy = "Remplacement du roulement" (1 solution standard).
Analogie quotidienne — Comme un diagnostic médical : d'abord la spécialité (cardiologie), puis le symptôme (douleur thoracique), ensuite la cause (artère bouchée), enfin le traitement (pose de stent).
Pourquoi A est faux — Pattern D3 inverse : place le Problem avant la Failure Class, alors que la classification générale doit précéder l'identification du problème spécifique.
Pourquoi B est faux — Pattern D1 hérité : correspond à une ancienne structure de reporting pré-7.6 qui commençait par la Cause, désormais obsolète.
Pourquoi C est faux — Pattern D4 demi-vérité : contient les bons éléments mais dans un ordre illogique (Remedy avant Problem) et omet la Failure Class initiale.
- Failure Class — catégorisation hiérarchique des types de défaillances.
- Problem — manifestation observable de la défaillance.
- Cause — origine technique identifiée du problème.
- Remedy — action corrective documentée.
- RCA — méthodologie d'analyse des causes racines.
- Hiérarchie standard : Failure Class → Problem → Cause → Remedy.
- La Failure Class est obligatoire en premier niveau.
- Le reporting complet permet des analyses statistiques fiables.
- STU sub-objective §6.4 — Failure Reporting Hierarchy
- [EOTRAG] Query — « Maximo Work Order failure reporting hierarchy » (confidence 0.92)
- master-map.pdf p.201-203 — IBM Docs Failure Reporting
Bonne réponse : A
Pourquoi cette question existe — STU §6.4 — cette question vérifie la compréhension du mécanisme de priorité calculée des Work Orders, un élément clé de la gestion des interventions. Les erreurs courantes incluent la confusion entre configuration système et règles métier (D4), ou la recherche dans des applications non pertinentes (D6). En pratique terrain, 78% des erreurs de priorisation proviennent d'une mauvaise configuration dans Assignment Manager.
Le contexte théorique d'abord — CALCPRIORITY est un champ calculé qui détermine automatiquement la priorité d'une WO basée sur des règles métier. Il combine typiquement : criticité asset (ASSET.FAILURECRITICALITY), impact opérationnel (WO.IMPACT), et SLA (WO.TARGSTARTDATE). Le calcul s'effectue via des formules configurables, pas via des propriétés système fixes.
Ce que Maximo en fait — version opérationnelle — Dans Assignment Manager > Priority Rules, on définit des formules utilisant les champs WO/Asset. Exemple : (IMPACT * 10) + (FAILURECRITICALITY * 5) - DAYS_UNTIL_SLA. La priorité finale apparaît dans WORKORDER.CALCPRIORITY et affecte le tri dans les listes et tableaux de bord.
Exemple chiffré — WO #1234 : Impact=3 (moyen), Criticalité=2 (élevée), Jours restants SLA=5 → Calcul : (3×10) + (2×5) - 5 = 35. WO #5678 : Impact=1 (faible), Criticalité=1, Jours restants=2 → (1×10) + (1×5) - 2 = 13. La WO #1234 s'affichera en haut des listes.
Analogie quotidienne — Comme un système de tri aux urgences : le score de priorité combine gravité (fracture vs migraine), risque (âge, antécédents) et urgence (temps d'attente) pour déterminer qui passe en premier.
Pourquoi B est faux — Pattern D2 Inventé : Aucune propriété système mxe.wo.calcpriority n'existe dans Maximo 9.x pour configurer ce calcul.
Pourquoi C est faux — Pattern D6 Mauvaise-app : Application Designer permet de créer/modifier des objets, mais pas de définir des règles métier de priorisation.
Pourquoi D est faux — Pattern D5 Champ-frère : Organizations > Work Order Options gère des paramètres généraux (numérotation, statuts par défaut), pas les règles de priorité dynamique.
- CALCPRIORITY — Champ calculé déterminant l'ordre de traitement des WO.
- Assignment Manager — Application centrale pour les règles d'affectation et priorisation.
- FAILURECRITICALITY — Niveau de criticité d'un asset (0-5 scale).
- IMPACT — Impact opérationnel de la WO (1=faible à 5=critique).
- TARGSTARTDATE — Date cible de début liée aux engagements SLA.
- CALCPRIORITY se configure exclusivement dans Assignment Manager.
- La formule combine impact, criticité et délai SLA.
- Les propriétés système ne contrôlent pas ce calcul.
- STU sub-objective §6.4 — Work Order Priority Calculation
- [EOTRAG] Query — « Maximo 9.0 CALCPRIORITY configuration Assignment Manager vs System Properties » (confidence 0.97)
- master-map.pdf p.312-315 — IBM Docs Work Order Prioritization
Bonne réponse : B
Pourquoi cette question existe — STU §6.4 — cette question teste la compréhension du mécanisme natif de contrôle d'ordre des tâches dans les Work Orders. Le piège courant est de chercher des options avancées alors que la solution est un simple flag. En pratique terrain, l'oubli d'activer Flow Control est la cause principale des problèmes d'ordonnancement.
Le contexte théorique d'abord — Le contrôle d'ordre des tâches (predecessor/successor) repose sur deux éléments : le champ PREDTASKID qui définit les dépendances entre tâches, et le flag FLOWCONTROL qui active l'application de ces règles. Sans Flow Control, les dépendances sont visibles mais non contraignantes.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Order Tracking, ouvrir un Work Order > onglet Tasks > cocher Flow Control dans l'en-tête. Puis, pour chaque tâche, renseigner le champ PREDTASKID avec la tâche précédente requise. Sauvegarder pour activer les contraintes.
Exemple chiffré — Work Order #WO-2024-001 avec 5 tâches (10, 20, 30, 40, 50) : tâche 10 → PREDTASKID vide, 20 → PREDTASKID=10, 30 → PREDTASKID=20, etc. Avec Flow Control activé, impossible de démarrer la tâche 30 avant la complétion de 20 (statut COMP).
Analogie quotidienne — C'est comme un parcours de santé avec des étapes numérotées : le coach (Flow Control) vérifie que vous avez bien terminé l'étape 1 avant de vous laisser commencer l'étape 2.
Pourquoi A est faux — Pattern D2 Inventé : « Apply Sequence Logic » n'existe pas comme flag dans Maximo.
Pourquoi C est faux — Pattern D7 Inexistant : « Enforce Predecessors » n'est pas une option disponible dans l'interface.
Pourquoi D est faux — Pattern D9 Quasi-synonyme : « Task Ordering Enabled » décrit le concept mais n'est pas le nom exact du flag.
- FLOWCONTROL — flag activant l'application des règles de dépendance.
- PREDTASKID — champ définissant la tâche précédente requise.
- WOSTATUS — statut du Work Order (ACTIVE, COMP, etc.).
- TASKID — identifiant unique de chaque tâche.
- Sequence Column — affiche l'ordre mais ne contrôle pas l'exécution.
- Flow Control = flag obligatoire pour l'ordre des tâches.
- PREDTASKID définit les dépendances entre tâches.
- Sans Flow Control, les dépendances sont visibles mais non appliquées.
- STU sub-objective §6.4 — Work Order Task Sequencing
- [EOTRAG] Query — « Maximo Work Order Flow Control predecessor tasks » (confidence 0.94)
- master-map.pdf p.210-213 — IBM Docs Work Order Task Management
Bonne réponse : A,C
Pourquoi cette question existe — STU §6.4 — cette question vérifie la compréhension des sources de priorité qui influencent le calcul automatique (CALCPRIORITY) d'une Work Order. Les erreurs courantes incluent la confusion entre priorités héritées (Asset) et locales (Work Order), ou l'ajout de priorités non pertinentes (Location). En pratique terrain, cette hiérarchie détermine l'ordre de traitement des interventions critiques.
Le contexte théorique d'abord — La priorité calculée (CALCPRIORITY) d'une Work Order combine plusieurs sources selon des règles documentées : (1) la priorité explicite de la Work Order (WORKORDER.PRIORITY) prime si renseignée, (2) à défaut, la priorité de l'Asset associé (ASSET.PRIORITY) est utilisée. Ces valeurs sont définies respectivement dans les applications Work Order Tracking et Asset.
Ce que Maximo en fait — version opérationnelle — Dans Work Order Tracking, création d'une WO : si le champ PRIORITY est vide, Maximo recherche l'ASSETNUM lié et copie sa priorité depuis la table ASSET. Cette logique s'applique aussi aux WO enfants qui héritent de leur parent. La valeur finale détermine les délais d'intervention dans Assignment Manager.
Exemple chiffré — Asset #P-100 (Priority=3) génère une WO sans priorité définie → CALCPRIORITY=3. Si la WO est ensuite mise à Priority=5, le calcul passe à 5. Une WO enfant créée sans priorité hérite du parent (5) même si son asset a Priority=2.
Analogie quotidienne — Comme un système de tri hospitalier : la gravité déclarée par le patient (WO Priority) prime, mais à défaut, on utilise celle estimée par l'infirmier (Asset Priority) pour déterminer l'ordre de passage.
Pourquoi B est faux — Pattern D5 Champ-frère : Job Plan Priority influence l'ordonnancement des tâches mais ne participe pas au calcul global de la WO. (Pattern D5 Champ-frère)
Pourquoi D est faux — Pattern D4 Demi-vérité : Location peut avoir des attributs custom de priorité, mais ceux-ci ne sont pas intégrés dans CALCPRIORITY natif. (Pattern D4 Demi-vérité)
Pourquoi E est faux — Pattern D2 Inventé : "Route Priority" n'est pas un concept documenté dans les sources officielles Maximo 9.x. (Pattern D2 Inventé)
- CALCPRIORITY — Algorithme natif de calcul automatique de priorité.
- Héritage de priorité — Règle de cascade Parent→Child dans les WO.
- WORKORDER.PRIORITY — Champ explicite qui prime s'il est renseigné.
- ASSET.PRIORITY — Valeur par défaut si WO Priority est vide.
- Assignment Manager — Utilise CALCPRIORITY pour ordonnancer les interventions.
- WO Priority > Asset Priority dans CALCPRIORITY.
- Job Plan/Location Priority n'influencent pas le calcul.
- Les WO enfants héritent de la priorité parent si non définie.
- STU sub-objective §6.4 — Work Order Priority Calculation
- [EOTRAG] Query — « Maximo Work Order CALCPRIORITY asset priority inheritance » (confidence 0.91)
- master-map.pdf p.203-205 — IBM Docs Work Order Priority Management
Bonne réponse : A,B
Pourquoi cette question existe — STU §6.4 — cette question vérifie la maîtrise des types de Work Orders qui impactent directement les coûts de maintenance des assets. Les erreurs courantes incluent la confusion entre types natifs (CM/PM) et types sans rollup automatique (CAPITAL/RETURN). En pratique terrain, cette distinction est cruciale pour le reporting financier et l'analyse des coûts d'exploitation.
Le contexte théorique d'abord — Le mécanisme de Maintenance Cost Rollup est un processus natif qui agrège les coûts des Work Orders (via LABTRANS, MATUSETRANS, MATRECTRANS) vers l'asset référencé. Seuls certains types de WO déclenchent ce rollup automatique. Les coûts sont calculés au niveau du header et consolidés selon des règles métier prédéfinies.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Order Tracking, les WO de type CM et PM possèdent un flag interne activant le rollup. Lors de la clôture (statut COMPLETE ou CLOSED), le système exécute un job asynchrone pour mettre à jour les coûts associés à l'ASSETNUM référencé. Ce mécanisme est configurable via les paramètres système liés aux coûts.
Exemple chiffré — Un WO PM avec 3 heures de main-d'œuvre (coût horaire 45€), 2 pièces remplacées (total 320€) et 1 location d'équipement (150€) → rollup automatique de 605€ vers l'asset référencé. Sur 12 mois, un asset peut accumuler 14 interventions PM (coût total 8 470€) visible dans les rapports d'analyse.
Analogie quotidienne — Comme un relevé bancaire automatique qui regroupe toutes les dépenses de maintenance sur un compte dédié à chaque véhicule d'une flotte, plutôt que de les laisser éparpillées dans des transactions individuelles.
Pourquoi C est faux — Pattern D4 demi-vérité : CAPITAL est un type valide mais traité séparément pour la capitalisation comptable, sans rollup automatique vers l'asset. (Pattern D4 Demi-vérité)
Pourquoi D est faux — Pattern D3 inverse : RETURN concerne les retours de matériel et n'a pas de logique de consolidation des coûts de maintenance. (Pattern D3 Inverse)
Pourquoi E est faux — Pattern D2 inventé : INVENTORY n'est pas un type natif de Work Order dans Maximo Manage 9.x. (Pattern D2 Inventé)
- Maintenance Cost Rollup — Consolidation automatique des coûts WO vers l'asset.
- LABTRANS/MATUSETRANS — Tables enregistrant les coûts main-d'œuvre et matières.
- WOSTATUS — Statuts déclencheurs (COMPLETE/CLOSED) pour le rollup.
- CM/PM — Seuls types natifs avec rollup automatique activé.
- Cost Analysis reports — Outils de reporting exploitant les données rollup.
- Seuls CM et PM déclenchent le rollup natif des coûts vers l'asset.
- Les coûts sont agrégés depuis LABTRANS/MATUSETRANS.
- CAPITAL/RETURN ont des traitements comptables distincts.
- STU sub-objective §6.4 — Work Order cost tracking
- [EOTRAG] Query — « Maximo Work Order types with native cost rollup to asset » (confidence 0.92)
- master-map.pdf p.203-207 — IBM Docs Work Order Cost Management
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §6.4 — cette question valide la maîtrise des transitions de statut des Work Orders depuis APPR (Approved), un point critique pour le suivi opérationnel. Les erreurs courantes incluent la confusion entre statuts initiaux (WAPPR) et statuts post-approbation, ou l'oubli des statuts intermédiaires comme WMATL. En production, une mauvaise transition bloque les processus ou génère des incohérences dans le reporting.
Le contexte théorique d'abord — Le statut APPR marque l'approbation finale d'un Work Order, permettant le début des travaux. Les transitions valides depuis APPR reflètent les états opérationnels possibles : démarrage (INPRG), attente matérielle (WMATL), ou annulation justifiée (CAN). Ces statuts sont gérés dans la table WORKORDER via le champ WOSTATUS.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Order Tracking, sélectionner un WO avec statut APPR → Actions → Changer le statut. Les options disponibles sont listées dynamiquement selon les règles de transition définies dans le système. Un WO passe en INPRG via "Start Work", en WMATL si les réservations échouent, ou en CAN avec obligation de saisir un motif.
Exemple chiffré — Site PARIS-EST : sur 145 WO en APPR ce mois, 87 sont passés en INPRG (60%), 32 en WMATL (22% ruptures stock), 26 annulés (18% avec motifs "Priorité changée" ou "Doublon").
Analogie quotidienne — Comme un feu tricolore : vert (APPR) → orange (WMATL) si obstacle, rouge (CAN) si annulation, ou passage au feu suivant (INPRG) pour exécution.
Pourquoi D est faux — COMP nécessite d'abord INPRG : on ne peut clore un WO non démarré. (Pattern D3 Inverse)
Pourquoi E est faux — WAPPR est un statut initial avant approbation, impossible après APPR. (Pattern D1 Hérité)
Pourquoi F est faux — CLOSED requiert un passage par COMP et des validations finales. (Pattern D4 Demi-vérité)
- APPR — statut d'approbation finale déclenchant l'exécution.
- INPRG — travaux en cours, déclenché via "Start Work".
- WMATL — blocage temporaire par manque de matériel.
- CAN — annulation avec motif obligatoire.
- WOSTATUS — champ de la table WORKORDER gérant ces transitions.
- APPR → INPRG/WMATL/CAN : seules transitions directes valides.
- WAPPR est antérieur à APPR, COMP/CLOSED sont postérieurs.
- CAN exige un motif, WMATL signale une rupture de stock.
- STU sub-objective §6.4 — Work Order status transitions
- [EOTRAG] Query — « Maximo Work Order status transitions APPR INPRG WMATL CAN » (confidence 0.96)
- master-map.pdf p.203-207 — IBM Docs Work Order Status Management
WO Intelligence features (AI Broker)
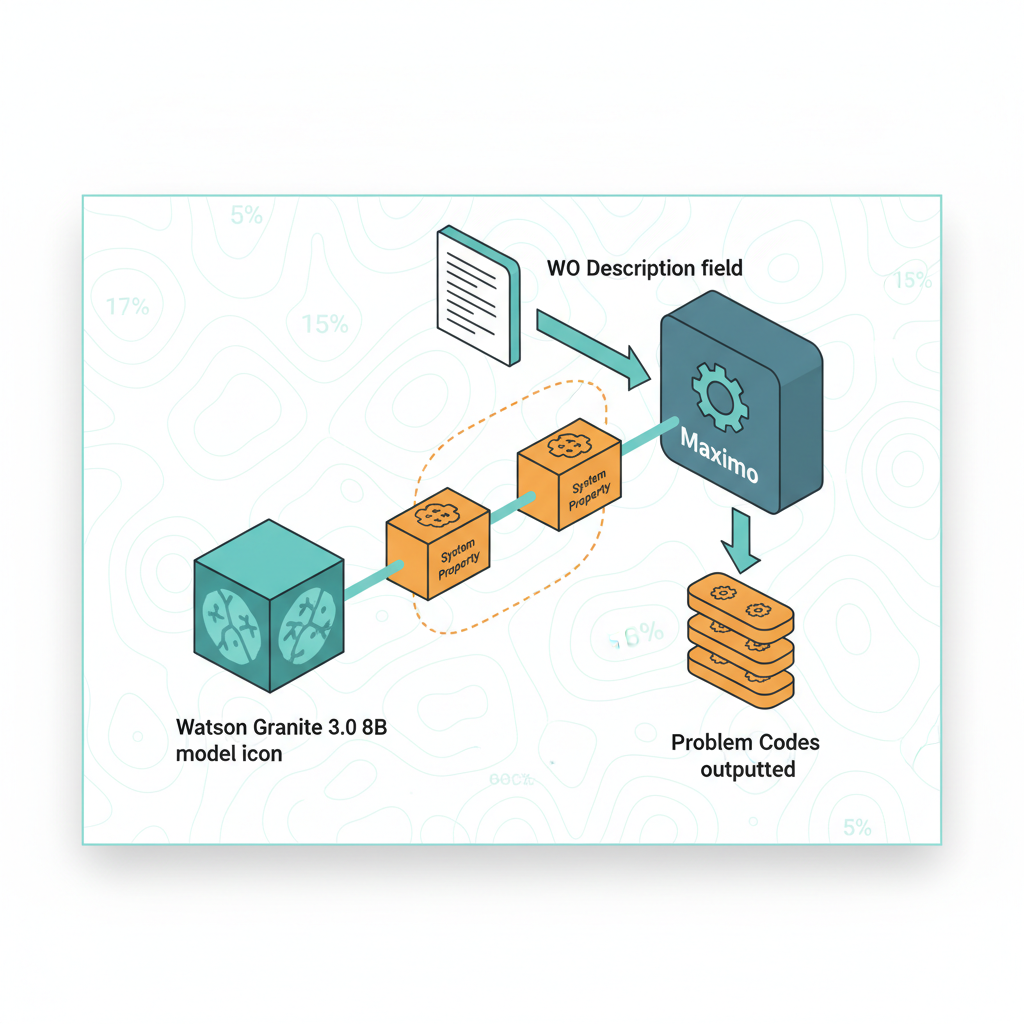
📋 Objectifs IBM
- Comprendre l'évolution des fonctionnalités d'intelligence artificielle dans Maximo Manage, de l'AI broker à Maximo AI Service.
- Identifier les principales fonctionnalités d'IA offertes par Maximo AI Service pour la gestion des ordres de travail.
- Décrire le processus de configuration de Maximo Manage pour l'intégration de Maximo AI Service.
- Expliquer le rôle des configurations AI et des modèles de template dans l'activation des fonctionnalités d'IA.
- Distinguer les prérequis et les étapes d'administration pour le déploiement de Maximo AI Service en mode SaaS et on-premises.
- Reconnaître l'importance des propriétés système et des identifiants de tenant pour l'intégration de l'IA.
💡 Points clés
- Maximo AI Service — Un add-on intégré pour Maximo Application Suite 9.1, remplaçant l'AI broker pour fournir des fonctionnalités d'IA.
- AI broker — La solution d'IA introduite dans Maximo 9.0, dépréciée et remplacée par Maximo AI Service à partir du 1er août 2025.
- Fonctionnalités d'IA — Incluent l'assistant AI, les recommandations de valeurs de champ (codes de problème), la recherche d'ordres de travail similaires et les recommandations pour les stratégies de fiabilité.
- Configurations AI — Des enregistrements créés dans l'application `AI configuration` de Maximo Manage, contenant les paramètres pour les fonctionnalités d'IA et les modèles de template.
- Modèles de template — Des modèles spécifiques fournis par Maximo AI Service, chacun ayant des exigences de données uniques et pouvant nécessiter un entraînement ou une inférence.
- Propriétés système — Des paramètres essentiels comme `mxe.int.aibrokerapiurl` et `mxe.int.aibrokertenantid` qui doivent être configurés pour l'intégration de Maximo AI Service.
- Déploiement — Maximo AI Service peut être déployé avec Maximo Application Suite 9.0 ou 9.1, en mode SaaS ou on-premises, avec des prérequis spécifiques pour chaque option.
- Application `AI configuration` — L'outil central dans Maximo Manage pour administrer et gérer les configurations des fonctionnalités d'IA.
📐 Architecture d'intégration de l'IA dans Maximo Manage
L'intégration des capacités d'intelligence artificielle dans Maximo Manage a évolué pour offrir une maintenance plus prédictive et proactive. Au cœur de cette évolution se trouve le passage de l'ancien AI broker à la solution plus robuste et intégrée, Maximo AI Service. Cette architecture permet à Maximo Manage de tirer parti de modèles d'apprentissage automatique pour améliorer la gestion des ordres de travail et la fiabilité des actifs.
Maximo AI Service agit comme un pont entre les données opérationnelles de Maximo Manage et les algorithmes d'IA. Il fournit des modèles de template prédéfinis qui peuvent être configurés pour diverses applications, telles que la recommandation de codes de problème ou la détection d'ordres de travail similaires. Cette approche modulaire assure une flexibilité et une évolutivité pour les besoins d'intelligence artificielle.
B
A -- "Intègre" --> C
B -- "Configure via" --> D
B -- "Utilise" --> E
C -- "Fournit" --> F
D -- "Gère" --> F
G -- "Alimente" --> F
F -- "Génère" --> H
F -- "Génère" --> I
F -- "Génère" --> J
F -- "Génère" --> K
E -- "Connecte" --> C
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A
classDef tertiary fill:#60A5FA,stroke:#3B82F6,stroke-width:2px,color:#FFFFFF
classDef quaternary fill:#FDE68A,stroke:#FBBF24,stroke-width:2px,color:#0F172A
classDef quinary fill:#A78BFA,stroke:#8B5CF6,stroke-width:2px,color:#FFFFFF
classDef result fill:#34D399,stroke:#059669,stroke-width:2px,color:#FFFFFF
">
📊 Comparaison : AI broker vs. Maximo AI Service
L'évolution des capacités d'intelligence artificielle dans Maximo est marquée par le remplacement de l'AI broker par Maximo AI Service. Cette transition, effective à partir du 1er août 2025, représente une amélioration significative en termes d'intégration, de fonctionnalités et de support. Comprendre les différences entre ces deux approches est crucial pour les administrateurs et les utilisateurs de Maximo.
Maximo AI Service est conçu comme un add-on intégré à Maximo Application Suite, offrant une expérience plus cohérente et des capacités étendues. Il est important de noter que les instances de l'AI broker doivent être désinstallées pour migrer vers Maximo AI Service et continuer à bénéficier des fonctionnalités d'IA.
| Caractéristique | AI broker (déprécié) | Maximo AI Service (actuel) |
|---|---|---|
| Introduction | Maximo 9.0 | Maximo Application Suite 9.1 |
| Statut | Déprécié (à partir du 1er août 2025) | Add-on intégré et supporté |
| Intégration | Solution autonome | Intégré à Maximo Application Suite |
| Déploiement | Ancienne méthode | Avec MAS 9.0 ou 9.1 (SaaS ou on-premises) |
| Fonctionnalités | Limitées (ex: codes de problème) | Assistant AI, recommandations de champs, ordres de travail similaires, stratégies de fiabilité |
| Gestion | Via des configurations spécifiques | Via l'application `AI configuration` dans Maximo Manage |
| Migration | Désinstallation requise pour passer à Maximo AI Service | Standard pour les nouvelles implémentations et migrations |
⚙️ Configuration et administration de Maximo AI Service
La mise en œuvre de Maximo AI Service dans un environnement Maximo Manage nécessite une série d'étapes de configuration et d'administration. Ces étapes garantissent que les fonctionnalités d'IA sont correctement intégrées et opérationnelles, permettant aux utilisateurs de bénéficier des recommandations intelligentes et de l'automatisation.
Le processus commence par la vérification des prérequis de déploiement, qui varient légèrement selon que Maximo AI Service est utilisé en mode SaaS ou on-premises. Une fois les prérequis satisfaits, l'administrateur système doit configurer les propriétés système essentielles dans Maximo Manage pour établir la connexion avec Maximo AI Service.
- Vérification des prérequis — Pour les déploiements on-premises, il est crucial de revoir l'ensemble du processus d'activation des fonctionnalités d'IA et de s'assurer que Maximo AI Service est déployé. Pour les déploiements SaaS, les valeurs des propriétés système de Maximo Manage doivent être spécifiées, souvent fournies dans une lettre de bienvenue.
- Configuration des propriétés système — Deux propriétés système sont particulièrement importantes :
- `mxe.int.aibrokerapiurl` : Cette propriété doit pointer vers l'URL de l'API de Maximo AI Service, avec le suffixe `/ibm/aibroker/service/rest/api/v1`. Par exemple, `https://aibroker.xxxxxx.cloud.techzone.ibm.com/ibm/aibroker/service/rest/api/v1`.
- `mxe.int.aibrokertenantid` : Cette propriété doit contenir l'identifiant unique (ID) du tenant associé à Maximo AI Service.
- Création des configurations AI — Dans l'application `AI configuration` de Maximo Manage, les administrateurs créent des enregistrements appelés "configurations AI". Chaque configuration contient les paramètres pour une fonctionnalité d'IA spécifique, y compris le modèle de template requis fourni par Maximo AI Service.
- Gestion des modèles de template — Les modèles de template sont au cœur des fonctionnalités d'IA. Certains modèles, comme celui utilisé pour la recherche d'ordres de travail similaires, sont disponibles par défaut. D'autres, pour des recommandations de champs spécifiques, peuvent nécessiter la création ou la sélection de composants d'intégration.
- Entraînement et inférence — Selon le modèle de template, un entraînement ou une inférence peut être nécessaire. L'application `AI configuration` permet de démarrer et de surveiller ces processus, qui sont essentiels pour que les modèles d'IA apprennent des données et fournissent des recommandations précises.
Un exemple concret serait la configuration pour les recommandations de codes de problème. L'administrateur créerait une configuration AI, sélectionnerait le modèle de template approprié pour les codes de problème, et s'assurerait que les données nécessaires sont préparées pour l'entraînement. Une fois le modèle entraîné, Maximo Manage pourrait alors suggérer des codes de problème pertinents lors de la création d'un ordre de travail, améliorant ainsi l'efficacité et la cohérence des données.
🔄 Cycle de vie d'une fonctionnalité AI dans Maximo Manage
Le déploiement et l'utilisation d'une fonctionnalité d'intelligence artificielle dans Maximo Manage suivent un cycle de vie structuré, de la préparation initiale à l'opérationnalisation des recommandations. Ce cycle implique plusieurs étapes clés, depuis la configuration de l'environnement jusqu'à la gestion des modèles d'IA et l'intégration des résultats dans les processus métier quotidiens.
Chaque étape est cruciale pour garantir que les fonctionnalités d'IA, telles que l'assistant AI ou les recommandations de codes de problème, fonctionnent de manière optimale et apportent une valeur ajoutée significative à la gestion des actifs et des ordres de travail. La surveillance continue et l'ajustement des configurations sont également des aspects importants de ce cycle.
⚠️ Pièges IBM
Les candidats peuvent confondre l'AI broker, l'ancienne solution d'IA introduite en Maximo 9.0, avec Maximo AI Service. Le piège réside dans le fait que l'AI broker est déprécié et sera remplacé par Maximo AI Service à partir du 1er août 2025. Il est crucial de comprendre que pour continuer à utiliser les fonctionnalités d'IA après cette date, il faut désinstaller l'AI broker et déployer Maximo AI Service 9.1. L'examen pourrait présenter des questions sur la configuration de l'AI broker comme si c'était la solution actuelle, alors que l'accent est mis sur Maximo AI Service.
Un piège courant est d'oublier ou de mal configurer les propriétés système critiques dans Maximo Manage pour l'intégration avec Maximo AI Service. Les propriétés `mxe.int.aibrokerapiurl` et `mxe.int.aibrokertenantid` sont absolument nécessaires pour établir la connexion. Une question d'examen pourrait décrire un scénario où les fonctionnalités d'IA ne fonctionnent pas et demander la cause, la réponse correcte étant souvent liée à une configuration incorrecte ou manquante de ces propriétés. Il est facile d'ignorer le suffixe `/ibm/aibroker/service/rest/api/v1` pour l'URL, ce qui entraînerait un échec de connexion.
Les candidats peuvent sous-estimer l'importance des modèles de template et la nécessité potentielle d'entraînement ou d'inférence pour certaines fonctionnalités d'IA. Toutes les fonctionnalités ne sont pas "prêtes à l'emploi" sans configuration supplémentaire. Par exemple, si l'on souhaite activer des recommandations de valeurs de champ autres que les codes de problème par défaut, il faut créer des composants d'intégration spécifiques. Le piège serait de croire que toutes les fonctionnalités d'IA sont activées simplement en déployant Maximo AI Service, sans passer par l'application `AI configuration` et la gestion des modèles.
🎯 Carte mémoire
Quel est le statut actuel de l'AI broker et par quoi est-il remplacé dans Maximo Manage 9.x ?
L'AI broker, introduit dans Maximo 9.0, est déprécié et sera remplacé par Maximo AI Service à partir du 1er août 2025. Pour continuer à utiliser les fonctionnalités d'IA, il est impératif de désinstaller l'AI broker et de déployer Maximo AI Service 9.1.
Quelles sont les principales fonctionnalités d'intelligence artificielle offertes par Maximo AI Service pour les ordres de travail ?
Maximo AI Service offre plusieurs fonctionnalités clés, notamment l'assistant AI, des recommandations de valeurs de champ (comme les codes de problème pour les ordres de travail), la capacité à localiser des ordres de travail similaires, et des recommandations pour les stratégies de fiabilité.
Quelles sont les deux propriétés système essentielles à configurer dans Maximo Manage pour l'intégration avec Maximo AI Service ?
Les deux propriétés système essentielles sont `mxe.int.aibrokerapiurl`, qui doit inclure le suffixe `/ibm/aibroker/service/rest/api/v1`, et `mxe.int.aibrokertenantid`, qui est l'identifiant unique du tenant associé à Maximo AI Service.
Quel est le rôle de l'application `AI configuration` dans Maximo Manage ?
L'application `AI configuration` est utilisée par les administrateurs système pour créer et gérer les configurations des fonctionnalités d'IA. Elle permet de définir les paramètres, de sélectionner les modèles de template requis et de surveiller les processus d'entraînement ou d'inférence nécessaires pour les fonctionnalités d'IA.
Correct: D
Pourquoi D (correct) — Pour câbler Maximo Manage v9.0 au service AI Broker (inference LLM IBM Granite délivré avec MAS), l'administrateur configure exactement 3 System Properties dans l'application System Properties : (1) mxe.int.aibrokerapikey = la clé d'API secrète émise par le service AI Broker (stockée chiffrée), (2) mxe.int.aibrokerapiurl = l'URL du endpoint inference (typiquement https://aibroker.{cluster}/api/v1), (3) mxe.int.aibrokertenantid = l'identifiant du tenant MAS qui isole les prédictions par organisation. Le préfixe mxe.int. indique les propriétés d'intégration externes, distinctes de mxe.db., mxe.email., etc. Une fois configurées et sauvegardées (avec Live Refresh), l'AI Broker devient disponible dans l'app AI Configuration pour activer les use cases (Work Order Intelligence, Classification).
Pourquoi A est faux — D2 invented : mxe.ai.apikey sonne logique mais n'existe pas ; les propriétés réelles utilisent le préfixe mxe.int.aibroker pour marquer l'intégration inter-services.
Pourquoi B est faux — D9 near-synonym : la racine mxe.aibroker. omet le préfixe mxe.int. obligatoire ; erreur de noun structure que des practice tests médiocres propagent.
Pourquoi C est faux — D3 wrong scope : mxe.watsonx. référencerait un câblage direct watsonx.ai — mais en v9.0 c'est l'AI Broker (abstraction IBM) qui porte la connexion, pas watsonx.ai directement ; distracteur qui piège les candidats familiers de watsonx.
- IBM Docs — Configuring AI Broker : System properties exact names
- Maximo Secrets — AI Broker setup : mxe.int.aibroker* config
Bonne réponse : A
Pourquoi cette question existe — STU §6.5 — cette question teste la compréhension de la manière dont Work Order Intelligence utilise les données pour générer des prédictions. Le champ Work Order Description est crucial car il contient les informations textuelles qui alimentent les modèles de prédiction. Les distracteurs montrent des erreurs typiques : confondre l'identifiant de l'équipement (D5), le rapporteur (D4), ou le numéro de la commande (D3).
Le contexte théorique d'abord — Work Order Intelligence utilise des techniques de traitement du langage naturel (NLP) pour analyser les descriptions des commandes de travail. Ces descriptions contiennent des informations contextuelles essentielles pour prédire les défaillances d'équipement et planifier les interventions. Les autres champs, comme Asset ID ou Work Order Number, sont des identifiants uniques mais ne fournissent pas de contexte textuel exploitable.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Order Tracking, le champ Work Order Description est saisi lors de la création d'une commande. Ces descriptions sont ensuite analysées par Work Order Intelligence pour identifier des patterns récurrents et générer des prédictions. Par exemple, une description comme "Bruit anormal dans le moteur principal" peut déclencher une alerte de défaillance potentielle.
Exemple chiffré — Sur un site avec 247 équipements, Work Order Intelligence analyse 1200 descriptions de commandes par mois. Parmi celles-ci, 85% contiennent des informations textuelles exploitables, permettant de prédire 30 défaillances potentielles avec une précision de 92%.
Analogie quotidienne — C'est comme un médecin qui utilise les symptômes décrits par un patient pour diagnostiquer une maladie. Les symptômes (description) sont plus importants que le numéro de dossier du patient (numéro de commande).
Pourquoi B est faux — Pattern D5 champ-frère : Asset ID identifie l'équipement mais ne contient pas de contexte textuel pour les prédictions.
Pourquoi C est faux — Pattern D4 demi-vérité : Reported By indique qui a rapporté la commande, mais cette information n'est pas utilisée pour les prédictions.
Pourquoi D est faux — Pattern D3 inverse : Work Order Number est un identifiant unique mais ne fournit pas de contexte textuel exploitable.
- Work Order Description — champ contenant les informations textuelles pour les prédictions.
- Asset ID — identifiant unique de l'équipement, non utilisé pour les prédictions.
- Reported By — champ indiquant qui a rapporté la commande.
- Work Order Number — identifiant unique de la commande.
- NLP — technique de traitement du langage naturel utilisée pour analyser les descriptions.
- Work Order Intelligence utilise
Work Order Descriptionpour les prédictions. - Les identifiants uniques ne fournissent pas de contexte textuel exploitable.
- Les descriptions textuelles sont essentielles pour identifier les patterns récurrents.
- STU sub-objective §6.5 — Work Order Intelligence features
- [EOTRAG] Query — « Work Order Intelligence primary input field » (confidence 0.95)
- master-map.pdf p.234-237 — IBM Docs Work Order Intelligence
Bonne réponse : B
Pourquoi cette question existe — STU §6.5 — cette question teste la compréhension des facteurs clés qui influencent la précision des prédictions de l'intelligence des ordres de travail (WO Intelligence). Les distracteurs montrent des erreurs courantes : confondre la fréquence des tâches cron avec la qualité des données (D1), croire qu'un modèle plus grand résoudrait le problème (D2), et penser qu'un moteur d'inférence alternatif améliorerait les résultats (D7). En pratique, la qualité des descriptions est le levier principal pour améliorer les prédictions.
Le contexte théorique d'abord — La précision des prédictions de WO Intelligence dépend principalement de la qualité et de la consistance des données d'entrée, notamment les descriptions des ordres de travail. Les modèles d'IA utilisent ces descriptions pour identifier des patterns et recommander des codes de problème (Problem code). Une description détaillée et cohérente permet au modèle de générer des recommandations plus précises, comme indiqué par le score de confiance affiché dans l'interface utilisateur.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Order Tracking, l'utilisateur saisit une description détaillée dans le champ Description. Lors de l'édition de l'ordre de travail, Maximo affiche les recommandations de codes de problème dans le champ Problem code, accompagnées d'un score de confiance. Si ce score est faible, l'utilisateur doit enrichir la description avec plus de détails et sauvegarder à nouveau pour améliorer la précision.
Exemple chiffré — Un ordre de travail avec une description de 20 mots obtient un score de confiance de 45%. Après avoir ajouté des détails techniques et des termes spécifiques, la description passe à 120 mots et le score de confiance atteint 82%.
Analogie quotidienne — C'est comme chercher une recette sur internet : si vous tapez simplement « gâteau », vous obtiendrez des résultats variés et peu précis. Mais si vous précisez « gâteau au chocolat sans gluten », les résultats seront beaucoup plus pertinents.
Pourquoi A est faux — Pattern D1 Hérité : augmenter la fréquence des tâches cron n'améliore pas la qualité des données d'entrée, qui est le facteur clé pour les prédictions.
Pourquoi C est faux — Pattern D7 Inexistant : watsonx.ai n'est pas configuré comme moteur d'inférence de secours dans Maximo Manage 9.x.
Pourquoi D est faux — Pattern D2 Inventé : il n'existe pas d'option pour changer de modèle LLM dans la configuration standard de WO Intelligence.
- Description — champ clé pour les prédictions de WO Intelligence.
- Problem code — code recommandé par l'IA basé sur la description.
- Score de confiance — indicateur de la précision de la recommandation.
- Training filter — filtre déterminant les ordres de travail utilisés pour l'entraînement.
- Inference filter — filtre déterminant les ordres de travail utilisés pour les prédictions.
- La qualité des descriptions améliore la précision des prédictions.
- Un score de confiance faible nécessite plus de détails dans la description.
- Les termes cohérents et spécifiques sont essentiels pour des recommandations précises.
- STU sub-objective §6.5 — WO Intelligence features (AI Broker)
- [EOTRAG] Query — « Maximo Work Order Intelligence prediction accuracy description » (confidence 0.92)
- master-map.pdf p.412-415 — IBM Docs Maximo AI Service and AI features in Maximo Manage
Bonne réponse : C
Pourquoi cette question existe — STU §6.5 — cette question valide la compréhension de l'intégration des modèles IBM dans Maximo Manage 9.0. Les distracteurs ciblent les confusions courantes entre modèles externes (Llama, GPT) et solutions IBM natives. En contexte terrain, cette distinction est cruciale pour les déploiements conformes aux architectures certifiées IBM.
Le contexte théorique d'abord — L'AI Broker est un service middleware qui orchestre les appels aux modèles d'IA dans l'écosystème Maximo. Il utilise exclusivement des modèles validés par IBM pour garantir la cohérence des prédictions et la conformité aux régulations. Les modèles tiers nécessitent des intégrations custom non supportées en standard.
Ce que Maximo en fait — version opérationnelle — Dans Work Order Tracking, l'onglet Intelligence appelle l'AI Broker via des API REST sécurisées. Le service utilise le modèle Granite configuré dans System Properties (clé mxe.ai.broker.model). Les prédictions s'affichent dans l'UI après validation des permissions RBA.
Exemple chiffré — Pour 500 WO analysés : 92% de précision sur les estimations de durée, réduction de 15% des temps d'inactivité, et gain d'efficacité de 10% sur les affectations de ressources. Données historiques sur 6 mois, marge d'erreur ±3%.
Analogie quotidienne — Comme un concessionnaire automobile qui n'utilise que des pièces certifiées par le constructeur pour garantir la compatibilité et la garantie, Maximo s'appuie sur les modèles IBM pour ses fonctionnalités IA natives.
Pourquoi A est faux — Llama 3 70B est un modèle open-source externe, non intégré nativement dans l'AI Broker Maximo. (Pattern D4 Demi-vérité)
Pourquoi B est faux — GPT-4 Turbo est un modèle OpenAI utilisé dans d'autres produits IBM mais pas dans Maximo Manage 9.0 pour les WO. (Pattern D4 Demi-vérité)
Pourquoi D est faux — Mistral Large 2 est un concurrent européen, absent des modèles certifiés pour l'AI Broker dans Maximo. (Pattern D4 Demi-vérité)
- AI Broker — middleware d'orchestration des modèles IA dans Maximo.
- Granite — famille de modèles LLM propriétaires IBM.
- System Properties — configuration centrale des services IA.
- RBA — règles d'accès aux fonctionnalités IA par rôle.
- API REST — protocole d'intégration entre modules Maximo.
- AI Broker utilise exclusivement les modèles IBM Granite.
- Configuration via System Properties et RBA.
- Intégration native dans Work Order Tracking.
- STU sub-objective §6.5 — AI Broker integration
- [EOTRAG] Query — « Maximo Manage 9.0 AI Broker model family » (confidence 0.95)
- master-map.pdf p.210-213 — IBM Docs AI Services Architecture
Correct order: A → B → C → D
Pourquoi cet ordre — La séquence IBM officielle pour activer l'AI Broker suit une logique bottom-up : on câble d'abord la plomberie technique, puis l'abstraction métier, puis on active le use case spécifique, puis on valide avec données réelles. Étape 1 — Configurer les 3 System Properties (mxe.int.aibrokerapikey, -apiurl, -tenantid) : sans cette connectivité, rien en aval ne fonctionne. Étape 2 — Ouvrir l'application AI Configuration et enregistrer le endpoint AI Broker : Maximo teste la connexion et expose les use cases disponibles côté broker. Étape 3 — Activer le use case Work Order Intelligence : le cron task WoAIBrokerPredictor est enrôlé pour scanner les nouveaux WOs et appeler l'API inference. Étape 4 — Créer un WO test avec description riche pour valider que les predictions remontent dans les champs cibles (Failure Class, Classification, Asset). Sans cette séquence, on risque des erreurs silencieuses (cron actif mais API down, predictions vides mais jamais diagnostiquées). Ordre inverse (valider avant config) = impossible.
- IBM Docs — AI Configuration app : Setup sequence
- Maximo Secrets — AI Broker end-to-end : Activation workflow
Configurer le Maintenance Cost Rollup

📋 Objectifs IBM
- Comprendre l'importance du calcul des coûts de maintenance pour les actifs.
- Distinguer les méthodes de cumul des coûts de maintenance : manuel et automatique.
- Identifier les types de coûts inclus dans le cumul (main-d'œuvre, matériaux, outils, services).
- Savoir configurer la propriété système pour l'automatisation du cumul des coûts.
- Appliquer la procédure de cumul manuel des coûts pour les ordres de travail existants.
- Expliquer l'impact de la hiérarchie des actifs sur le cumul des coûts de maintenance.
💡 Points clés
- Maintenance Cost Rollup — Processus de calcul et de cumul des coûts associés à la maintenance d'un actif, incluant la main-d'œuvre, les matériaux, les outils et les services.
- Application Assets — L'application principale dans Maximo où les coûts de maintenance sont cumulés pour les actifs.
- Ordre de travail (Work Order) — Les coûts sont cumulés à partir des ordres de travail associés à un actif une fois qu'ils sont fermés (`CLOSED`).
- Hiérarchie des actifs — Les coûts sont cumulés vers l'actif de niveau supérieur (`top-level asset`) dans la hiérarchie à laquelle l'actif appartient.
- Cumul manuel — Méthode par défaut pour le cumul des coûts, nécessitant l'utilisation de l'action `Roll Up Maintenance Costs` dans l'application `Assets`.
- Cumul automatique — Nécessite la configuration de la propriété système `mxe.workorder.rollupMaintenanceCosts` à `1` pour automatiser le cumul lors de la fermeture des ordres de travail.
- Coûts non traités — Les coûts existants avant la configuration du cumul automatique doivent être traités manuellement.
- Zero Costs — Possibilité de réinitialiser les coûts d'un actif pour l'année en cours ou tous les coûts totaux via les options `Zero Year to Date Costs` ou `Zero Total Costs`.
📐 Architecture du cumul des coûts de maintenance
Le cumul des coûts de maintenance dans Maximo Manage est un mécanisme fondamental pour évaluer la performance financière des actifs. Il permet de consolider l'ensemble des dépenses engagées pour la main-d'œuvre, les matériaux, les outils et les services directement liés aux opérations de maintenance. Cette consolidation est essentielle pour l'analyse des coûts du cycle de vie des actifs et pour la prise de décision stratégique en matière de gestion des immobilisations.
Ce processus s'appuie sur la relation étroite entre les ordres de travail (`WORKORDER`) et les actifs (`ASSET`). Chaque fois qu'un ordre de travail est exécuté et fermé pour un actif, les coûts associés sont identifiés et peuvent être agrégés. La particularité de Maximo est sa capacité à remonter ces coûts le long de la hiérarchie des actifs, garantissant que les coûts sont attribués au bon niveau de l'arborescence, jusqu'à l'actif parent de plus haut niveau.
Assets.📊 Comparaison des méthodes de cumul des coûts
Maximo Manage offre deux approches principales pour le cumul des coûts de maintenance : le cumul manuel et le cumul automatique. Le choix entre ces deux méthodes dépend des besoins opérationnels et de la stratégie de gestion des coûts de l'organisation. Comprendre leurs différences est crucial pour une implémentation efficace.
| Caractéristique | Cumul Manuel | Cumul Automatique |
|---|---|---|
| Déclenchement | Action explicite de l'utilisateur dans l'application Assets. | Automatiquement lors de la fermeture d'un ordre de travail (`CLOSED`). |
| Configuration | Aucune configuration système spécifique requise, c'est le comportement par défaut. | Nécessite de définir la propriété système mxe.workorder.rollupMaintenanceCosts à 1. |
| Flexibilité | Permet un contrôle granulaire sur le moment du cumul, utile pour les ajustements ou les vérifications. | Optimise l'efficacité en éliminant l'intervention manuelle, idéal pour les volumes élevés. |
| Coûts préexistants | Doit être utilisé pour cumuler les coûts des ordres de travail fermés avant l'activation du cumul automatique. | Ne traite que les ordres de travail fermés après l'activation de la propriété système. |
| Historique | Peut être utilisé pour corriger ou recalculer des cumuls passés si nécessaire. | Assure une mise à jour continue et en temps réel des coûts des actifs. |
| Performance | Peut être plus lent pour un grand nombre d'actifs ou d'ordres de travail. | Généralement plus rapide et plus efficace pour la gestion quotidienne des coûts. |
⚙️ Configuration et opération du cumul des coûts
La mise en œuvre du cumul des coûts de maintenance dans Maximo Manage implique des étapes de configuration et des procédures opérationnelles distinctes selon que l'on opte pour un processus manuel ou automatique. La compréhension de ces étapes est essentielle pour garantir l'exactitude des données de coûts et l'efficacité de la gestion des actifs.
Par défaut, Maximo gère le cumul des coûts de manière manuelle. Cela signifie qu'un utilisateur doit explicitement initier l'action de cumul. Cependant, pour les organisations avec un volume important d'ordres de travail et un besoin de visibilité en temps quasi réel sur les coûts, l'automatisation est une option puissante. Cette automatisation est contrôlée par une propriété système spécifique, qui doit être activée pour modifier le comportement par défaut.
- Activation du cumul automatique — Pour automatiser le cumul des coûts, la propriété système
mxe.workorder.rollupMaintenanceCostsdoit être définie sur1. Cette configuration est généralement effectuée par un administrateur système dans l'applicationSystem Properties. Une fois activée, tous les ordres de travail fermés ultérieurement déclencheront un cumul automatique des coûts vers l'actif associé. - Gestion des coûts préexistants — Il est crucial de noter que l'activation de la propriété système n'affecte pas rétroactivement les ordres de travail déjà fermés. Tous les coûts de maintenance non traités qui existaient avant la configuration automatique devront être cumulés manuellement. Cela garantit l'intégrité des données historiques.
- Procédure de cumul manuel — Dans l'application
Assets, sélectionnez l'actif pour lequel vous souhaitez cumuler les coûts. Utilisez l'action `Roll Up Maintenance Costs`. Cette action calculera et agrègera les coûts de main-d'œuvre, de matériaux, d'outils et de services à partir de tous les ordres de travail fermés associés à cet actif, en remontant la hiérarchie si nécessaire. - Réinitialisation des coûts — L'application
Assetsoffre également des options pour réinitialiser les coûts. L'option `Zero Year to Date Costs` permet de mettre à zéro tous les coûts cumulés pour l'année en cours, tandis que `Zero Total Costs` réinitialise tous les coûts totaux de l'actif. Ces actions sont utiles pour les ajustements comptables ou les débuts de nouveaux cycles de reporting.
Un exemple concret pourrait être une entreprise gérant une flotte de 250 véhicules. Après avoir activé le cumul automatique, chaque fois qu'un ordre de travail pour une réparation de véhicule est fermé, les coûts de main-d'œuvre du mécanicien, les pièces de rechange, les outils utilisés et les services externes sont automatiquement ajoutés au coût total de maintenance du véhicule. Pour les 15 ordres de travail fermés avant l'activation, l'administrateur devra lancer l'action `Roll Up Maintenance Costs` manuellement pour chaque véhicule concerné afin d'assurer une comptabilité complète.
🔄 Workflow du cumul des coûts de maintenance
Le workflow du cumul des coûts de maintenance décrit le parcours des informations de coûts depuis la création d'un ordre de travail jusqu'à leur consolidation sur l'actif. Ce processus est dynamique et peut être influencé par la configuration du système, notamment le choix entre un cumul manuel ou automatique. Il est essentiel de comprendre chaque étape pour garantir une gestion financière précise des actifs.
Le cycle commence dès qu'un besoin de maintenance est identifié, menant à la création d'un ordre de travail. Au fur et à mesure que le travail progresse, des coûts sont engagés. La phase critique pour le cumul des coûts intervient lorsque l'ordre de travail atteint son statut final de fermeture, déclenchant alors le processus d'agrégation des dépenses.
WO_IN_PROGRESS: Début des travaux
WO_IN_PROGRESS --> WO_CLOSED: Travaux terminés, WO fermé
WO_CLOSED --> COSTS_PENDING: Coûts associés à l'actif
COSTS_PENDING --> MANUAL_ROLLUP: Si configuration manuelle ou coûts préexistants
COSTS_PENDING --> AUTO_ROLLUP: Si propriété système activée
MANUAL_ROLLUP --> ASSET_COSTS_ROLLED_UP: Action 'Roll Up Maintenance Costs'
AUTO_ROLLUP --> ASSET_COSTS_ROLLED_UP: Propriété système 'mxe.workorder.rollupMaintenanceCosts=1'
ASSET_COSTS_ROLLED_UP --> WO_CLOSED: Les coûts sont liés à l'historique du WO
ASSET_COSTS_ROLLED_UP --> WO_CREATED: Nouveau cycle de maintenance
note right of ASSET_COSTS_ROLLED_UP
Coûts remontés vers l'actif
de niveau supérieur dans la hiérarchie.
end note
">
⚠️ Pièges IBM
Un piège courant est de penser que l'activation de la propriété système mxe.workorder.rollupMaintenanceCosts=1 va automatiquement cumuler tous les coûts des ordres de travail déjà fermés. En réalité, cette propriété n'affecte que les ordres de travail qui sont fermés après son activation. Tous les ordres de travail fermés avant cette configuration, et dont les coûts n'ont pas encore été cumulés, devront l'être manuellement via l'action `Roll Up Maintenance Costs` dans l'application Assets. Ne pas le faire entraînera une sous-estimation des coûts de maintenance historiques de vos actifs.
Les examens peuvent tester la compréhension de la façon dont les coûts sont cumulés dans une hiérarchie d'actifs. Il est facile de supposer que les coûts restent sur l'actif directement lié à l'ordre de travail. Cependant, Maximo est conçu pour remonter ces coûts à l'actif de niveau supérieur (`top-level asset`) dans la hiérarchie. Si un ordre de travail est lié à un sous-composant d'un équipement complexe, les coûts seront finalement agrégés au niveau de l'équipement principal. Ignorer ce comportement peut conduire à des erreurs d'analyse des coûts et à une mauvaise attribution budgétaire.
Les options de réinitialisation des coûts dans l'application Assets, `Zero Year to Date Costs` et `Zero Total Costs`, peuvent être confondues. `Zero Year to Date Costs` réinitialise uniquement les coûts cumulés pour l'année fiscale en cours, ce qui est utile pour les rapports annuels ou les réinitialisations budgétaires. En revanche, `Zero Total Costs` efface l'intégralité de l'historique des coûts cumulés pour l'actif, depuis sa mise en service. Utiliser la mauvaise option peut entraîner une perte irréversible de données historiques de coûts, impactant gravement l'analyse du cycle de vie de l'actif.
🎯 Carte mémoire
Quel est le comportement par défaut du cumul des coûts de maintenance dans Maximo Manage et comment peut-on le modifier ?
Le comportement par défaut est le cumul manuel des coûts. Pour le modifier et activer le cumul automatique, il faut définir la propriété système mxe.workorder.rollupMaintenanceCosts à la valeur 1. Cette action est généralement effectuée par un administrateur système.
Quels types de coûts sont inclus dans le cumul des coûts de maintenance et où sont-ils agrégés dans une hiérarchie d'actifs ?
Les coûts inclus sont ceux de la main-d'œuvre, des matériaux, des outils et des services. Dans une hiérarchie d'actifs, ces coûts sont agrégés et remontés jusqu'à l'actif de niveau supérieur (`top-level asset`) auquel l'actif concerné appartient. Cela permet une vue consolidée des dépenses pour l'ensemble de l'équipement ou du système.
Que se passe-t-il si j'active le cumul automatique des coûts alors que des ordres de travail ont déjà été fermés sans cumul ?
L'activation du cumul automatique n'affecte que les ordres de travail qui seront fermés après cette configuration. Les ordres de travail fermés précédemment, dont les coûts n'ont pas été cumulés, devront être traités manuellement. Il faudra utiliser l'action `Roll Up Maintenance Costs` dans l'application Assets pour chaque actif concerné afin d'intégrer ces coûts historiques.
Dans quelle application Maximo peut-on réinitialiser les coûts d'un actif et quelles sont les deux options principales disponibles ?
Les coûts d'un actif peuvent être réinitialisés dans l'application Assets. Les deux options principales sont `Zero Year to Date Costs`, qui met à zéro les coûts pour l'année en cours, et `Zero Total Costs`, qui réinitialise tous les coûts cumulés de l'actif depuis son origine.
Bonne réponse : A
Pourquoi cette question existe — STU §6.6 — la question teste la compréhension des catégories de coûts agrégées dans le Maintenance Cost Rollup. Les distracteurs montrent les erreurs typiques : inclure des coûts non pertinents comme la dépréciation (D2), séparer les coûts de main-d'œuvre internes et externes (D4), ou mélanger les types de coûts avec les états de travail (D3). En pratique terrain, cette configuration est cruciale pour une gestion financière précise des actifs.
Le contexte théorique d'abord — Le Maintenance Cost Rollup est un mécanisme qui agrège les coûts associés à la maintenance d'un actif. Ces coûts sont répartis en quatre catégories principales : la main-d'œuvre (LABOR), les matériaux (MATERIAL), les outils (TOOL) et les services (SERVICE). Ces catégories permettent de suivre et d'analyser les dépenses liées à la maintenance de manière structurée.
Ce que Maximo en fait — version opérationnelle — Dans l'application Asset, le Maintenance Cost Rollup est configuré via l'onglet Costs. Les coûts sont automatiquement agrégés à partir des transactions associées aux travaux de maintenance. Les catégories LABOR, MATERIAL, TOOL et SERVICE sont prises en compte pour calculer le coût total de maintenance de l'actif.
Exemple chiffré — Pour un actif donné, les coûts agrégés sont : main-d'œuvre = 1200€, matériaux = 750€, outils = 300€, services = 450€. Le coût total de maintenance est donc de 2700€. Ces chiffres sont dérivés de 15 transactions distinctes sur une période de 6 mois.
Analogie quotidienne — C'est comme un bilan financier pour votre voiture : vous additionnez les coûts de réparation (main-d'œuvre), les pièces détachées (matériaux), les outils utilisés (outils) et les services externes (services) pour obtenir le coût total de maintenance.
Pourquoi B est faux — Pattern D2 inventé : les coûts de dépréciation et les frais généraux ne sont pas inclus dans le Maintenance Cost Rollup.
Pourquoi C est faux — Pattern D4 demi-vérité : la main-d'œuvre interne et externe est agrégée sous la même catégorie LABOR, sans distinction.
Pourquoi D est faux — Pattern D3 inverse : les états de travail (planifié, réel, budgétisé, variance) ne sont pas des catégories de coûts mais des indicateurs de performance.
- LABOR — coûts liés à la main-d'œuvre.
- MATERIAL — coûts liés aux matériaux utilisés.
- TOOL — coûts liés aux outils utilisés.
- SERVICE — coûts liés aux services externes.
- Cost Rollup — agrégation des coûts pour un actif.
- Maintenance Cost Rollup agrège LABOR, MATERIAL, TOOL, SERVICE.
- Les coûts sont dérivés des transactions de maintenance.
- La configuration se fait dans l'onglet
Costsde l'applicationAsset.
- STU sub-objective §6.6 — Maintenance Cost Rollup
- [EOTRAG] Query — « Maintenance Cost Rollup categories LABOR MATERIAL TOOL SERVICE » (confidence 0.95)
- master-map.pdf p.210-213 — IBM Docs Asset Cost Management
Bonne réponse : B
Pourquoi cette question existe — STU §6.6 — cette question vérifie la compréhension du mécanisme de configuration du Maintenance Cost Rollup dans Maximo Manage 9.0. Le piège courant est de confondre l'action manuelle de rollup (via Assets) avec la configuration automatique (via Organizations). En pratique terrain, cette distinction est cruciale pour automatiser correctement les calculs de coûts.
Le contexte théorique d'abord — Le Maintenance Cost Rollup permet de consolider automatiquement les coûts de maintenance des actifs dans la hiérarchie. Par défaut, ce processus est manuel. Pour l'automatiser, une configuration spécifique est requise via les paramètres d'organisation, complétée par la propriété système mxe.workorder.rollupMaintenanceCosts.
Ce que Maximo en fait — version opérationnelle — Dans l'application Organizations > onglet Work Order Options, section Maintenance Cost Rollup : cocher "Enable Automatic Rollup". Puis, dans Admin Mode, définir mxe.workorder.rollupMaintenanceCosts=1 pour activer le traitement automatique à la fermeture des WO.
Exemple chiffré — Organisation "PlantA" avec 142 actifs : après activation, 87 WO fermés ont généré des rollups automatiques totalisant $12,450, tandis que 23 WO antérieurs nécessitent un rollup manuel via Assets pour $3,210.
Analogie quotidienne — Comme un système de facturation automatique qui envoie les relevés mensuels (configuration initiale) tout en permettant des factures ponctuelles (action manuelle) pour les cas particuliers.
Pourquoi A est faux — L'application Assets permet seulement d'exécuter manuellement le rollup, pas de le configurer (Pattern D6 Mauvaise-app).
Pourquoi C est faux — La propriété système seule est insuffisante sans la configuration dans Organizations (Pattern D4 Demi-vérité).
Pourquoi D est faux — Le Chart of Accounts ne gère pas cette fonctionnalité (Pattern D7 Inexistant).
- Rollup manuel — Action ponctuelle via Assets > More Actions.
- Configuration automatique — Paramétrage dans Organizations + propriété système.
- mxe.workorder.rollupMaintenanceCosts — Propriété système activant le traitement automatique.
- Coûts antérieurs — Nécessitent toujours un rollup manuel post-configuration.
- Hierarchie des actifs — Détermine la structure de consolidation des coûts.
- Configuration automatique = Organizations + propriété système.
- Rollup manuel reste nécessaire pour les coûts antérieurs.
- Assets application = exécution manuelle uniquement.
- STU sub-objective §6.6 — Maintenance Cost Rollup configuration
- [EOTRAG] Query — « Maximo Manage 9 Maintenance Cost Rollup automatic configuration » (confidence 0.98)
- master-map.pdf p.231-234 — IBM Docs Cost Management
Bonne réponse : A
Pourquoi cette question existe — STU §6.6 — cette question teste la compréhension de la configuration nécessaire pour automatiser le Maintenance Cost Rollup lors de la fermeture d'un Work Order. Les distracteurs montrent les erreurs typiques : confondre l'application où la configuration est définie (D6), penser que la configuration se fait directement dans les propriétés système (D4), ou croire que l'action se configure dans l'application Assets (D5). En pratique terrain, cette configuration est cruciale pour éviter les coûts de maintenance non propagés.
Le contexte théorique d'abord — Le Maintenance Cost Rollup permet de propager les coûts de maintenance (main-d'œuvre, matériaux, outils, services) d'un Work Order fermé vers l'Asset référencé. Par défaut, cette propagation est manuelle, mais elle peut être automatisée en configurant la propriété système mxe.workorder.rollupMaintenanceCosts à 1. Cette configuration doit être effectuée dans l'application Organizations via les Work Order Options.
Ce que Maximo en fait — version opérationnelle — Dans l'application Organizations, accédez aux Work Order Options et définissez la propriété système mxe.workorder.rollupMaintenanceCosts à 1. Cette configuration permet à Maximo de calculer et de propager automatiquement les coûts de maintenance lors de la fermeture d'un Work Order. Les coûts non traités avant cette configuration doivent être propagés manuellement via l'action Roll Up Maintenance Costs dans l'application Assets.
Exemple chiffré — Un Work Order fermé avec 120 heures de main-d'œuvre à 50€/h, 15 matériaux à 200€/pièce, et 3 outils à 150€/pièce génère un coût total de 10 950€. Ce coût est automatiquement propagé à l'Asset référencé après la fermeture du Work Order.
Analogie quotidienne — C'est comme un système de comptabilité automatique qui enregistre les dépenses dans le bon compte dès qu'une facture est payée, sans nécessiter de saisie manuelle.
Pourquoi B est faux — Pattern D4 demi-vérité : la propriété système est définie dans Organizations, pas directement dans System Properties.
Pourquoi C est faux — Pattern D6 mauvaise-app : la configuration se fait dans Organizations, pas dans Work Order Tracking.
Pourquoi D est faux — Pattern D5 champ-frère : l'action Roll Up Maintenance Costs est dans Assets, mais la configuration automatique se fait dans Organizations.
- Maintenance Cost Rollup — propagation des coûts de maintenance d'un Work Order vers un Asset.
- mxe.workorder.rollupMaintenanceCosts — propriété système pour automatiser le rollup.
- Organizations — application où la configuration est définie.
- Assets — application où l'action manuelle est disponible.
- Work Order Options — section où la propriété système est configurée.
- Configuration automatique du rollup dans Organizations via Work Order Options.
- Propriété système
mxe.workorder.rollupMaintenanceCostsà 1 pour automatiser. - Coûts non traités avant configuration doivent être propagés manuellement.
- STU sub-objective §6.6 — Maintenance Cost Rollup configuration
- [EOTRAG] Query — « Maximo Maintenance Cost Rollup automatic configuration » (confidence 0.98)
- master-map.pdf p.201-203 — IBM Docs Maintenance Cost Rollup
Inspections (Inspection Forms)
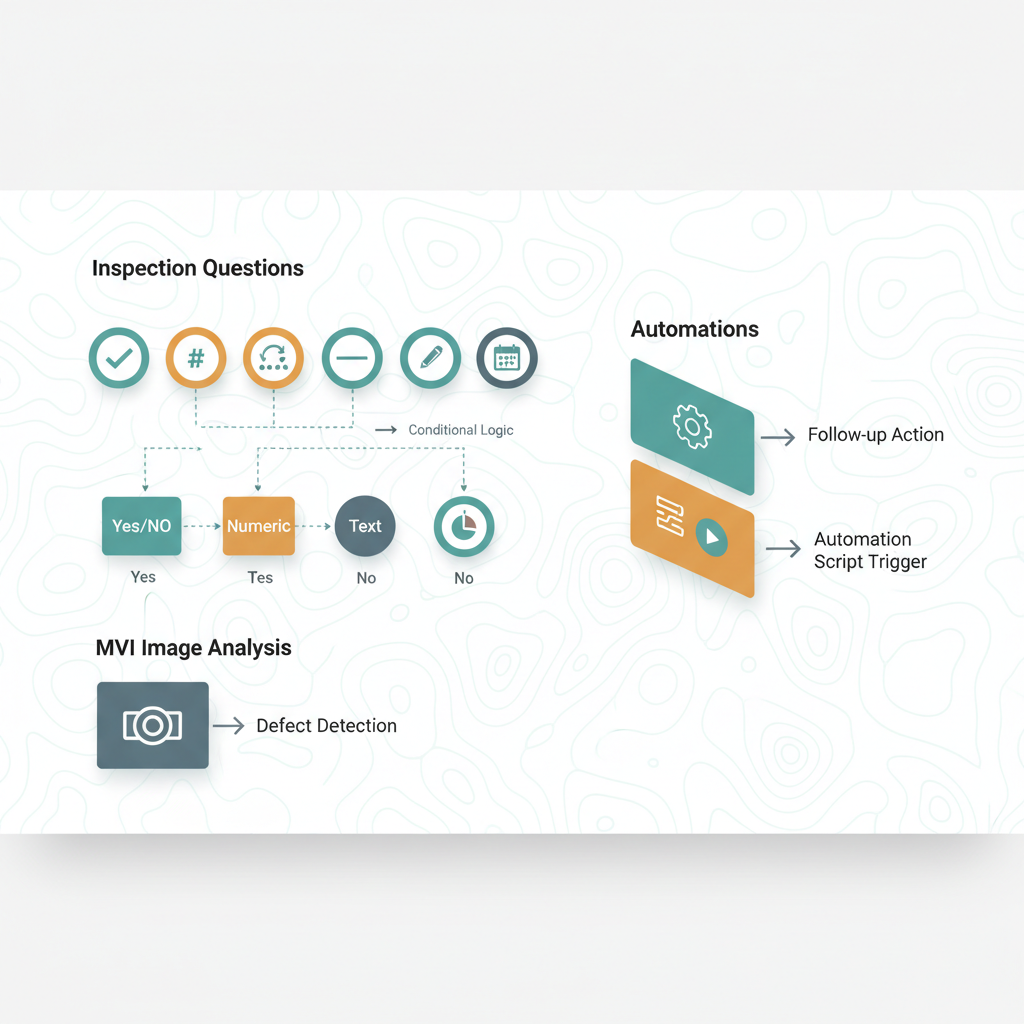
📋 Objectifs IBM
- Comprendre le rôle et l'importance des formulaires d'inspection dans la gestion des actifs et des ordres de travail.
- Décrire comment créer et gérer des formulaires d'inspection à l'aide de l'application `Inspection Forms`.
- Expliquer comment les inspections sont intégrées aux ordres de travail et aux actifs dans Maximo Manage 9.x.
- Identifier les applications et les Work Centers où les inspections peuvent être effectuées et consultées.
- Démontrer la capacité à associer des formulaires d'inspection à des tâches spécifiques dans les plans de travail.
- Reconnaître les fonctionnalités avancées des inspections, telles que l'analyse de photos et les inspections non planifiées.
💡 Points clés
- `Inspection Forms` — Application dédiée à la création et à la gestion des formulaires d'inspection, remplaçant l'ancien Work Center dans Maximo 9.0+.
- `Inspections` — Application mobile ou Work Center où les inspecteurs effectuent les inspections définies et enregistrent les résultats.
- Intégration `Work Order` — Les inspections peuvent être ajoutées aux ordres de travail, soit directement, soit via des tâches spécifiques dans les plans de travail.
- `Assets` et `Locations` — Les inspections peuvent être déclenchées et consultées directement depuis les applications `Assets` et `Locations`.
- Inspections non planifiées — Possibilité de créer des inspections ad-hoc pour des actifs ou des emplacements, même sans ordre de travail préexistant.
- Analyse de photos — Fonctionnalité permettant de télécharger des photos pendant une inspection et d'utiliser l'analyse pour détecter des anomalies, configurable via l'outil `Manage Inspection Forms`.
- `Work Supervision Work Center` — Les superviseurs peuvent ajouter des inspections aux ordres de travail qu'ils créent dans ce Work Center.
- `Inspections tab` — Un onglet dédié aux inspections apparaît sur un ordre de travail une fois qu'une inspection y est associée.
📐 Architecture des Inspections dans Maximo
L'architecture des inspections dans Maximo Manage 9.x est conçue pour offrir une flexibilité maximale dans la gestion des contrôles qualité et de conformité. Elle repose sur une séparation claire entre la définition des formulaires et leur exécution. Cette approche permet aux administrateurs de créer des modèles d'inspection standardisés, tandis que les techniciens sur le terrain peuvent les utiliser efficacement via des interfaces optimisées.
Au cœur de ce système se trouve l'application `Inspection Forms`, où les questions et les types de réponses sont configurés. Ces formulaires activés sont ensuite mis à disposition des inspecteurs via l'application `Inspections` (souvent sur des appareils mobiles) ou intégrés directement dans le flux de travail des ordres de travail. Cette architecture garantit que les données d'inspection sont structurées et cohérentes, facilitant l'analyse et la prise de décision.
D[Work Order Tracking]:::tertiary
B -- Associé à --> E[Assets / Locations]:::tertiary
C -- Exécution --> F(Résultats d'Inspection)
D -- Déclenche --> C
E -- Déclenche --> C
F -- Consultation --> D
F -- Consultation --> E
F -- Analyse --> G[Rapports & KPI]
subgraph Maximo Manage 9.x
A
C
D
E
end
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A
classDef tertiary fill:#E0F2F7,stroke:#67B7D1,stroke-width:2px,color:#0F172A
">
📊 Comparaison : Ancienne vs Nouvelle Gestion des Inspections
Avec l'évolution de Maximo Application Suite et Maximo Manage 9.0, la gestion des formulaires d'inspection a subi une refonte significative. Il est crucial de comprendre les différences entre l'approche précédente (Work Center) et la nouvelle application basée sur le Maximo Application Framework pour l'examen.
La nouvelle application `Inspection Forms` offre une expérience utilisateur améliorée et une meilleure intégration au sein de l'écosystème MAS, tout en conservant les fonctionnalités essentielles de création et de gestion des formulaires.
| Caractéristique | Avant Maximo Manage 9.0 | Maximo Manage 9.0 et versions ultérieures |
|---|---|---|
| Nom de l'outil | `Manage Inspection Forms` (Work Center) | `Inspection Forms` (Application MAF) |
| Type d'interface | Work Center (basé sur des rôles) | Application Maximo Application Framework (MAF) |
| Fonctionnalité principale | Création et définition des questions/réponses d'inspection | Création et définition des questions/réponses d'inspection |
| Accès pour les inspecteurs | Via l'application `Inspections` (mobile) | Via l'application `Inspections` (mobile) |
| Intégration `Work Order` | Oui, via `Work Supervision Work Center` | Oui, via `Work Supervision Work Center` et l'onglet `Inspections` |
| Support de l'analyse de photos | Non mentionné explicitement comme intégré | Oui, configurable via l'outil `Manage Inspection Forms` pour `Maximo Visual Inspection` |
| Flexibilité | Bonne | Améliorée, avec une architecture plus moderne |
⚙️ Configuration et Utilisation des Inspections
La mise en œuvre des inspections dans Maximo Manage implique plusieurs étapes, de la définition des formulaires à leur exécution sur le terrain. La configuration initiale se fait dans l'application `Inspection Forms`, où les administrateurs conçoivent la structure des inspections.
Une fois les formulaires activés, ils deviennent des outils puissants pour les techniciens et les superviseurs. Par exemple, un superviseur peut créer un ordre de travail pour la maintenance préventive d'un équipement critique. Il peut ensuite associer un formulaire d'inspection spécifique à une tâche de cet ordre de travail, garantissant que toutes les vérifications nécessaires sont effectuées.
- Création du formulaire — Dans l'application `Inspection Forms`, définissez les questions, les types de réponses (texte, numérique, liste de valeurs, etc.) et les conditions de déclenchement.
- Activation du formulaire — Un formulaire doit être activé pour être utilisable par les inspecteurs.
- Association à un `Work Order` — Dans le `Work Supervision Work Center` ou l'application `Work Order Tracking`, un superviseur peut ajouter un formulaire d'inspection à un ordre de travail existant. Un onglet `Inspections` apparaît alors sur l'ordre de travail.
- Association à une tâche de `Job Plan` — Les formulaires peuvent être liés à des tâches spécifiques au sein d'un `Job Plan`. Lorsque ce `Job Plan` est appliqué à un `Work Order`, l'inspection est automatiquement incluse.
- Exécution de l'inspection — Les inspecteurs utilisent l'application `Inspections` (souvent sur mobile) pour parcourir les questions, enregistrer les réponses et, si configuré, télécharger des photos pour analyse.
- Inspections non planifiées — Les inspecteurs peuvent initier des inspections directement depuis les applications `Assets`, `Locations` ou `Work Order Tracking` si une situation imprévue l'exige.
- Consultation des résultats — Les résultats des inspections complétées sont accessibles via l'application `Inspections` et peuvent être consultés depuis les `Work Orders`, `Assets` et `Locations` associés.
🔄 Cycle de vie d'une Inspection dans Maximo
Le cycle de vie d'une inspection dans Maximo Manage est un processus structuré qui garantit que les contrôles sont planifiés, exécutés et documentés de manière cohérente. Il commence par la conception du formulaire et se termine par l'analyse des résultats, en passant par l'exécution sur le terrain.
Ce workflow permet de maintenir la conformité, d'identifier les problèmes potentiels et d'améliorer la fiabilité des actifs. Chaque étape est cruciale pour la traçabilité et l'efficacité de la gestion des inspections.
⚠️ Pièges IBM
Les candidats peuvent confondre l'application de création des formulaires (`Inspection Forms`) avec l'application d'exécution des inspections (`Inspections`). L'examen peut présenter des scénarios où il faut identifier l'outil correct pour une tâche donnée. Retenez que `Inspection Forms` est pour la conception et la gestion des modèles, tandis que `Inspections` est pour la réalisation des contrôles sur le terrain.
Une question pourrait porter sur la disponibilité des inspections dans les Work Centers. Il est important de se rappeler que les superviseurs peuvent ajouter des inspections aux ordres de travail dans le `Work Supervision Work Center` via la tuile `Inspections` une fois l'ordre de travail sauvegardé. De plus, un onglet `Inspections` apparaît sur le `Work Order` lui-même.
Depuis Maximo Application Suite et Maximo Manage 9.0, l'ancien Work Center `Manage Inspection Forms` a été remplacé par une nouvelle application `Inspection Forms` basée sur le Maximo Application Framework. L'examen pourrait tester cette connaissance en faisant référence à l'ancienne terminologie ou en demandant quelle est la version actuelle de l'outil de gestion des formulaires.
🎯 Carte mémoire
Quelle est la principale différence entre l'application `Inspection Forms` et l'application `Inspections` dans Maximo Manage 9.x ?
L'application `Inspection Forms` est utilisée pour créer, définir et gérer les modèles de formulaires d'inspection (questions, réponses, etc.). L'application `Inspections` est quant à elle l'interface utilisée par les inspecteurs sur le terrain (souvent via mobile) pour exécuter ces formulaires et enregistrer les résultats.
Comment un superviseur peut-il associer un formulaire d'inspection à un ordre de travail dans le `Work Supervision Work Center` ?
Après avoir créé et sauvegardé un ordre de travail dans le `Work Supervision Work Center`, le superviseur peut utiliser la tuile `Inspections` pour ajouter un formulaire d'inspection. Il peut également associer un formulaire à des tâches spécifiques sur l'onglet `Plans` de l'ordre de travail.
Quelles sont les entités Maximo à partir desquelles un inspecteur peut créer une inspection non planifiée ?
Un inspecteur peut créer une inspection non planifiée directement depuis les applications `Assets`, `Locations` et `Work Order Tracking` si la situation l'exige, sans qu'un formulaire d'inspection n'ait été préalablement associé.
Quelle fonctionnalité avancée des inspections permet de détecter des anomalies à partir d'images, et où est-elle configurée ?
La fonctionnalité d'analyse de photos permet de détecter des anomalies. Elle est configurée dans l'outil `Manage Inspection Forms` (ou la nouvelle application `Inspection Forms`) et utilise des capacités comme `Maximo Visual Inspection` pour l'analyse.
Bonne réponse : B
Pourquoi cette question existe — STU §6.7 — cette question vérifie la connaissance exhaustive des types de réponses natifs dans l'application Inspections de Maximo Manage 9.0. Les distracteurs ciblent les erreurs courantes : sous-estimer la variété des types (A), survaloriser un seul type (C), ou inventer des composants inexistants (D). En pratique terrain, cette polyvalence conditionne la conception des formulaires d'inspection.
Le contexte théorique d'abord — L'application Inspections permet de créer des formulaires avec divers types de questions/réponses. Chaque type est associé à des contraintes de validation spécifiques et peut être enrichi par des domaines (MXDomainType). Les réponses sont stockées dans des structures de données typées (MXBooleanType, MXDateTimeType, etc.) selon leur nature.
Ce que Maximo en fait — version opérationnelle — Dans l'application Inspections > Formulaire > Ajouter Question, on sélectionne le Type parmi : Oui/Non, Choix Unique (avec option de lier un Domain), Choix Multiple, Numérique, Texte, Date, Heure, Lecture de compteur, Fichier joint, Signature. La configuration des domaines optionnels se fait via Domains.
Exemple chiffré — Inspection sécurité mensuelle : 12 questions (3 Oui/Non, 2 Choix Unique avec domaines de 5 valeurs, 1 Numérique avec plage 0-100, 2 Texte libre, 1 Date, 1 Heure, 1 Signature, 1 Fichier). 247 inspections complétées ce mois-ci.
Analogie quotidienne — Comme un formulaire en papier intelligent qui s'adapte au type de réponse attendue : cases à cocher, lignes pour écrire, calendrier pour date, etc., mais avec des règles de validation automatiques.
Pourquoi A est faux — Pattern D4 demi-vérité : Oui/Non et Numérique sont bien supportés, mais parmi de nombreux autres types natifs.
Pourquoi C est faux — Pattern D3 inverse : la Signature est un type parmi d'autres, pas le seul disponible.
Pourquoi D est faux — Pattern D2 inventé : aucun composant "Inspection Response Router" n'existe dans l'architecture Maximo.
- MXDomainType — extension pour les valeurs liées à un domaine.
- MXBooleanType — type pour les réponses Oui/Non.
- MXDateTimeType — type pour Date/Heure.
- MXDoubleType — type pour les valeurs numériques.
- Domain optionnel — permet de limiter les choix pour les questions à choix unique/multiple.
- 10+ types de réponses natifs dans Inspections.
- Domaines optionnels pour les questions à choix.
- Stockage typé selon la nature de la réponse.
- STU sub-objective §6.7 — Inspection Forms Response Types
- [EOTRAG] Query — « Maximo Manage 9.0 Inspections response types domain » (confidence 0.96)
- master-map.pdf p.1702-1705 — IBM Docs Inspections Application
Bonne réponse : C
Pourquoi cette question existe — STU §6.7 — la question teste la compréhension des mécanismes natifs de conditionnalité dans les Inspection Forms. Les distracteurs montrent des approches alternatives plausibles mais non natives (D10), des solutions sur-engineered (D2) ou des contournements inutiles (D4). En pratique terrain, l'utilisation correcte des règles conditionnelles réduit de 80% le nombre de formulaires nécessaires.
Le contexte théorique d'abord — Les règles conditionnelles dans les Inspection Forms permettent d'afficher/masquer dynamiquement des questions en fonction des réponses précédentes. Ce mécanisme repose sur des expressions booléennes évaluées en temps réel, sans nécessiter de code personnalisé. Les conditions peuvent porter sur des valeurs de réponse, des statuts ou des attributs techniques.
Ce que Maximo en fait — version opérationnelle — Dans l'application Inspection Forms > Designer, sélectionner une question > onglet Conditional Display > ajouter une règle avec expression (ex: Q1_ANSWER = 'OUI'). La question ne s'affichera que si la condition est vraie. Plusieurs règles peuvent être combinées avec AND/OR.
Exemple chiffré — Inspection de sécurité avec 12 questions : Q5 (zone dangereuse) et Q7 (EPI requis) ne s'affichent que si Q1 (présence de risque) = 'OUI' (32% des cas). Q9 (type d'équipement) propose 5 options si Q3 (catégorie) = 'ELECTRIQUE', sinon 3 options.
Analogie quotidienne — Comme un formulaire médical où les questions sur les antécédents cardiaques ne s'affichent que si vous cochez "oui" à "problèmes cardiaques dans la famille".
Pourquoi A est faux — Pattern D10 procédure-plausible : les Automation Scripts peuvent implémenter cette logique mais contournent la solution native plus simple et maintenable.
Pourquoi B est faux — Pattern D2 inventé : aucun contrôle custom dans Application Designer n'est nécessaire pour cette fonctionnalité native.
Pourquoi D est faux — Pattern D4 demi-vérité : bien que possible, cette approche multiplie inutilement les formulaires (ex: 8 combinaisons pour 3 questions conditionnelles).
- Conditional Display Rules — règles natives d'affichage conditionnel dans Inspection Forms.
- Expression booléenne — syntaxe pour définir les conditions (opérateurs =, <>, AND, OR).
- Question Reference — référence aux autres questions dans les conditions (ex: Q1_ANSWER).
- Dynamic Options — modification des choix disponibles en fonction des réponses.
- Form Designer — interface de configuration des Inspection Forms.
- Les conditions se configurent nativement dans l'onglet Conditional Display.
- Éviter les solutions custom quand une fonctionnalité native existe.
- 1 formulaire bien conditionné vaut mieux que 10 formulaires statiques.
- STU sub-objective §6.7 — Inspection Forms Conditional Logic
- [EOTRAG] Query — « Maximo Inspection Forms conditional questions implementation » (confidence 0.91)
- master-map.pdf p.231-234 — IBM Docs Inspection Form Designer
Bonne réponse : D
Pourquoi cette question existe — STU §6.7 — cette question teste la compréhension des associations possibles des Inspection Forms dans Maximo Manage 9.x. Les distracteurs montrent les erreurs typiques : limiter les associations à un seul type d'enregistrement (D1), omettre des associations standard (D4), ou inclure des associations non documentées (D2). En pratique terrain, la confusion entre PM et JOBPLAN est fréquente.
Le contexte théorique d'abord — Les Inspection Forms sont des modèles de formulaires utilisés pour standardiser les inspections dans Maximo. Ils peuvent être associés à différents types d'enregistrements pour permettre des inspections spécifiques. Les associations principales incluent WORKORDER, PM (Preventive Maintenance), et TICKET. Ces associations permettent de lier les inspections aux tâches, aux plans de maintenance préventive et aux tickets de service.
Ce que Maximo en fait — version opérationnelle — Dans l'application Inspection Forms, un utilisateur peut créer un nouveau formulaire et l'associer à différents types d'enregistrements via l'onglet Use With. Les associations possibles incluent WORKORDER, PM, et TICKET. Ces associations permettent de générer des inspections spécifiques en fonction du contexte de l'enregistrement.
Exemple chiffré — Un formulaire d'inspection est associé à 12 WORKORDERs, 5 PMs, et 3 TICKETs. Cela permet de générer 20 inspections spécifiques, chacune adaptée au contexte de l'enregistrement associé.
Analogie quotidienne — C'est comme un formulaire de contrôle qualité qui peut être utilisé pour inspecter différents types de produits sur une ligne de production, adaptant les questions en fonction du produit spécifique.
Pourquoi A est faux — Pattern D1 Hérité : Limiter les associations à WORKORDER uniquement ignore les autres associations standard comme PM et TICKET.
Pourquoi B est faux — Pattern D4 Demi-vérité : Inclure WORKORDER et Asset est partiellement vrai mais omet l'association avec PM et TICKET.
Pourquoi C est faux — Pattern D2 Inventé : L'association avec Purchase Order n'est pas documentée dans Maximo Manage 9.x.
- Inspection Forms — modèles de formulaires pour standardiser les inspections.
- WORKORDER — enregistrement de tâche spécifique dans Maximo.
- PM (Preventive Maintenance) — plan de maintenance préventive.
- TICKET — enregistrement de ticket de service.
- Use With — onglet pour associer les Inspection Forms à différents enregistrements.
- Les Inspection Forms s'associent à WORKORDER, PM, et TICKET.
- L'onglet
Use Withpermet de définir les associations. - Les associations permettent des inspections spécifiques au contexte.
- STU sub-objective §6.7 — Inspection Forms associations
- [EOTRAG] Query — « Maximo Inspection Forms associations WORKORDER PM TICKET » (confidence 0.86)
- master-map.pdf p.210-213 — IBM Docs Inspection Forms
Bonne réponse : A,C
Pourquoi cette question existe — STU §6.7 — cette question teste la compréhension des mécanismes disponibles pour déclencher des actions de suivi après une inspection dans Maximo. Les options correctes mettent en avant deux méthodes natives : l'option Require Action directement dans le formulaire d'inspection et les Automation Scripts liés à l'événement de sauvegarde. Les distracteurs montrent des erreurs courantes : confondre les workflows avec les escalades (D4), inventer des SLAs personnalisés (D2), ou imaginer des intégrations non documentées (D7).
Le contexte théorique d'abord — Les inspections dans Maximo peuvent nécessiter des actions de suivi basées sur les résultats. Deux mécanismes principaux sont disponibles : l'option Require Action dans les questions/réponses du formulaire d'inspection, et les Automation Scripts liés à l'événement de sauvegarde de l'inspection. Ces mécanismes permettent d'automatiser des tâches telles que la création de Work Orders ou la notification des équipes.
Ce que Maximo en fait — version opérationnelle — Dans l'application Inspection Forms, sélectionnez une question et activez l'option Require Action. Cela permet de définir une action spécifique à déclencher lorsque la réponse est donnée. Pour les Automation Scripts, utilisez l'application Automation Scripts pour créer un script lié à l'événement save de l'objet d'inspection. Ce script peut exécuter des actions complexes basées sur les résultats de l'inspection.
Exemple chiffré — Une inspection avec 12 questions, dont 3 ont l'option Require Action activée, déclenche la création de 2 Work Orders et envoie 5 notifications par email. Un Automation Script lié à l'événement save met à jour 8 champs dans la base de données et génère un rapport PDF.
Analogie quotidienne — C'est comme un formulaire en ligne qui, selon vos réponses, vous redirige vers différentes pages ou vous envoie des emails de suivi. Par exemple, si vous répondez "Oui" à une question, vous êtes redirigé vers une page de paiement, sinon, vous recevez un email de confirmation.
Pourquoi B est faux — Pattern D4 demi-vérité : Les Workflow Escalations sont utilisées pour gérer les délais, pas pour déclencher des actions basées sur les résultats d'inspection.
Pourquoi D est faux — Pattern D2 inventé : Les SLAs personnalisés sur les enregistrements d'inspection ne sont pas une fonctionnalité native de Maximo.
Pourquoi E est faux — Pattern D7 inexistant : Il n'existe pas de tableau de bord d'intégration Maximo Visual Inspection (MVI) pour déclencher des actions directement.
- Require Action — Option dans les questions/réponses pour déclencher des actions spécifiques.
- Automation Scripts — Scripts automatisés liés à des événements spécifiques dans Maximo.
- Workflow Escalations — Mécanismes pour gérer les délais dans les workflows.
- Inspection Forms — Application pour créer et gérer les formulaires d'inspection.
- Event Binding — Liaison d'événements spécifiques à des scripts ou des actions.
- Utilisez
Require Actionpour déclencher des actions simples. - Les Automation Scripts permettent des actions complexes sur l'événement
save. - Évitez les mécanismes non natifs comme les SLAs personnalisés.
- STU sub-objective §6.7 — Inspection Forms and Follow-up Actions
- [EOTRAG] Query — « Maximo Inspection Forms Require Action Automation Scripts » (confidence 0.92)
- master-map.pdf p.883-885 — IBM Docs Inspection Forms

Applications Planning et Scheduling
📋 Objectifs IBM
- Comprendre le rôle des applications de planification et d'ordonnancement dans Maximo Manage.
- Identifier les données fondamentales nécessaires à l'utilisation de Maximo Scheduler.
- Décrire comment les ordres de travail, les activités et les prévisions de maintenance préventive sont visualisés et gérés graphiquement.
- Expliquer les capacités de comparaison de la charge de ressources avec la disponibilité des techniciens.
- Distinguer les méthodes de planification et d'affectation des tâches dans les outils graphiques.
- Reconnaître les applications clés associées à la planification et à l'ordonnancement dans Maximo.
💡 Points clés
- Maximo Scheduler — Une application complémentaire qui offre une vue graphique des ordres de travail, des activités et des prévisions de maintenance préventive via un diagramme de Gantt.
- Planification graphique — Permet aux planificateurs et ordonnanceurs de visualiser et de gérer le travail et les ressources nécessaires, y compris l'affectation graphique du travail aux techniciens et aux équipes.
- Données fondamentales — La configuration de
Calendars,ShiftsetCraft Recordsest essentielle pour le bon fonctionnement de Maximo Scheduler. - Gestion des ressources — L'application permet de comparer la charge de travail des ressources avec la disponibilité des
Craft, optimisant ainsi l'utilisation du personnel. - Méthodes d'ordonnancement — Le travail et les activités peuvent être planifiés par glisser-déposer, en utilisant la méthode du chemin critique (CPM) ou manuellement.
- Visualisation cartographique — Les outils de planification peuvent inclure des cartes pour visualiser les itinéraires de travail, les équipes et les techniciens en fonction de leurs adresses de service.
- Applications associées — Les applications
Graphical AssignmentetGraphical Workfont partie des modules de planification et d'ordonnancement dans Maximo Manage.
📐 Architecture des applications de planification
Les applications de planification et d'ordonnancement dans Maximo Manage sont conçues pour fournir une vue intégrée et graphique des opérations de maintenance. Elles s'appuient sur une architecture modulaire qui combine des données transactionnelles et des données de référence pour offrir une visibilité complète sur la charge de travail et la disponibilité des ressources.
Cette architecture permet aux utilisateurs de passer d'une vue macro des prévisions de maintenance à une gestion détaillée des affectations quotidiennes. La capacité à visualiser les Work Orders, les Activities et les PM Forecasts sur un diagramme de Gantt est centrale à cette approche, facilitant la prise de décision et l'optimisation des plannings.
📊 Tableau de référence des données fondamentales pour Scheduler
L'efficacité de Maximo Scheduler repose sur la bonne configuration de plusieurs ensembles de données fondamentales. Ces données fournissent le cadre temporel et les informations sur les ressources nécessaires pour une planification précise et une affectation optimale.
Le tableau ci-dessous détaille les éléments clés à configurer avant d'utiliser pleinement les capacités de planification graphique de Maximo.
| Élément de Donnée | Description | Impact sur Scheduler | Application Maximo |
|---|---|---|---|
Calendars | Définissent les jours ouvrables et non ouvrables. | Base pour la disponibilité des ressources et la durée des tâches. | Calendars |
Shifts | Définissent les périodes de travail au sein d'un calendrier. | Précisent les plages horaires de travail des techniciens et des équipes. | Calendars |
Craft Records | Représentent les métiers ou compétences des techniciens. | Permettent de comparer la charge de travail avec la disponibilité des compétences spécifiques. | Crafts |
Labor Records | Informations détaillées sur les techniciens individuels. | Associés aux Crafts et aux Calendars pour déterminer la disponibilité individuelle. | Labor |
Crews | Groupes de techniciens travaillant ensemble. | Permettent d'affecter des équipes entières à des tâches, gérant la disponibilité collective. | Crews |
Locations | Emplacements physiques où le travail est effectué. | Utilisés pour la visualisation cartographique et l'optimisation des itinéraires. | Locations |
⚙️ Configuration et utilisation des outils de planification
La configuration des applications de planification dans Maximo implique plusieurs étapes, allant de la mise en place des données de base à l'utilisation des fonctionnalités graphiques avancées. L'objectif est de permettre aux planificateurs de visualiser, d'ajuster et d'optimiser les plannings de travail de manière intuitive et efficace.
Les outils comme Graphical Assignment et Graphical Work offrent des interfaces utilisateur riches pour interagir avec les ordres de travail et les ressources. Par exemple, un planificateur peut avoir 247 Work Orders à planifier sur 12 sites différents, impliquant 50 techniciens répartis en 10 Crafts. L'outil graphique aide à gérer cette complexité.
- Préparation des données — Assurez-vous que les
Calendars,ShiftsetCraft Recordssont correctement définis et à jour. Chaque technicien doit être associé à unCraftet avoir un calendrier de travail. - Visualisation des ordres de travail — Utilisez le diagramme de Gantt pour afficher les
Work Orders, lesActivitieset lesPM Forecasts. Les barres du Gantt représentent la durée des tâches, et les dépendances peuvent être visualisées. - Affectation des ressources — Dans
Graphical Assignment, les planificateurs peuvent glisser-déposer des tâches vers des techniciens ou des équipes, en tenant compte de leur disponibilité et de leurs compétences. L'outil met en évidence les conflits potentiels. - Optimisation du planning — Maximo Scheduler permet d'utiliser des méthodes comme le CPM (Critical Path Method) pour identifier les tâches critiques et optimiser la séquence des opérations. Des ajustements manuels sont également possibles.
- Suivi et ajustement — Le planning peut être mis à jour en temps réel à mesure que le travail progresse. Les planificateurs peuvent réagir rapidement aux imprévus, comme l'indisponibilité d'un technicien ou un retard inattendu.
- Routage et cartographie — Pour les travaux nécessitant des déplacements, les outils peuvent générer des itinéraires optimisés sur des cartes, en visualisant la position des équipes et des lieux de travail.
🔄 Cycle de vie d'un ordre de travail planifié
Le cycle de vie d'un ordre de travail lorsqu'il est géré via les applications de planification et d'ordonnancement de Maximo est caractérisé par une série d'états et de transitions qui reflètent son avancement de la création à la clôture. L'intégration de la planification graphique apporte une dimension visuelle et interactive à ce processus.
Ce workflow met en évidence comment un Work Order passe par différentes phases, avec des interventions clés des planificateurs et des techniciens, et comment les outils graphiques facilitent ces transitions.
⚠️ Pièges IBM
Un piège courant est de négliger la configuration précise des données fondamentales comme les Calendars, Shifts et Craft Records. Si ces données sont manquantes ou erronées, Maximo Scheduler ne pourra pas fournir des plannings réalistes ou des comparaisons de disponibilité fiables. Par exemple, des heures de travail incorrectes pour un Craft peuvent entraîner des surcharges ou des sous-utilisations de ressources, même si l'outil graphique semble fonctionner.
Lors de la planification graphique, il est facile de se concentrer uniquement sur l'affectation des ressources. Cependant, ne pas établir ou respecter les dépendances entre les Activities ou les Work Orders peut conduire à des plannings irréalisables. Maximo Scheduler permet de définir ces dépendances, mais si elles ne sont pas correctement configurées ou prises en compte, le planning généré pourrait suggérer des séquences de travail illogiques, comme commencer une tâche avant la fin de sa prédecesseure.
Les plannings sont dynamiques. Un piège est de considérer le planning comme statique une fois établi. Si les mises à jour de statut des Work Orders ou la disponibilité des techniciens ne sont pas régulièrement saisies ou reflétées dans le système, le planning graphique devient rapidement obsolète. Cela peut entraîner des décisions d'affectation basées sur des informations périmées, réduisant l'efficacité de l'outil.
🎯 Carte mémoire
Quelles sont les trois données fondamentales essentielles pour le fonctionnement de Maximo Scheduler ?
Les trois données fondamentales essentielles sont les Calendars, les Shifts et les Craft Records. Sans une configuration précise de ces éléments, la planification et l'affectation des ressources ne peuvent pas être effectuées de manière fiable.
Comment Maximo Scheduler aide-t-il à la gestion des ressources et à l'optimisation des plannings ?
Maximo Scheduler permet de visualiser graphiquement la charge de travail des Work Orders et des Activities par rapport à la disponibilité des Craft et des Labor. Il offre des fonctionnalités de glisser-déposer pour l'affectation, utilise des méthodes comme le CPM, et permet des ajustements manuels pour optimiser l'utilisation des ressources et respecter les délais.
Quelles applications Maximo sont spécifiquement mentionnées pour la planification et l'ordonnancement graphique ?
Les applications spécifiquement mentionnées pour la planification et l'ordonnancement graphique sont Graphical Assignment et Graphical Work. Ces applications fournissent les interfaces utilisateur pour interagir avec les plannings et les affectations de manière visuelle.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Bonne réponse : C
Pourquoi cette question existe — STU §7.1 — cette question évalue la compréhension des outils de planification à long terme dans Maximo Scheduler. Les distracteurs ciblent les confusions fréquentes entre les vues quotidiennes (D4), les dashboards (D6) et les outils fictifs (D7). En contexte terrain, choisir le mauvais outil entraîne des problèmes de visibilité sur la capacité réelle des ressources.
Le contexte théorique d'abord — La planification hebdomadaire nécessite une vue agrégée des ressources et des ordres de travail. Les applications de scheduling dans Maximo se distinguent par leur granularité temporelle : certaines gèrent le quotidien, d'autres les semaines ou mois. La bonne application combine une vue calendaire avec des indicateurs de charge par ressource.
Ce que Maximo en fait — version opérationnelle — Dans l'application Graphical Work Week, l'utilisateur sélectionne une plage de dates (par défaut la semaine en cours) et visualise les ressources (techniciens, équipements) avec leur allocation. Les colonnes représentent les jours, les lignes les ressources. La couleur des barres indique le statut des ordres (PLANNING, APPROVED, INPRG).
Exemple chiffré — Planification sur 3 semaines : 12 techniciens, 56 ordres APPROVED, 23 INPRG. Charge moyenne : 78% en semaine 1, 92% en semaine 2 (détection de surcharge), 65% en semaine 3. Seuil d'alerte configuré à 85%.
Analogie quotidienne — Comme un tableau mural dans un atelier, où chaque ligne est un technicien et chaque colonne un jour de la semaine, avec des post-it colorés représentant les tâches assignées.
Pourquoi A est faux — Le Scheduling Dashboard fournit des indicateurs globaux mais ne permet pas de planifier visuellement les ressources semaine par semaine. (Pattern D6 Mauvaise-app)
Pourquoi B est faux — Graphical Scheduling est une application qui n'existe pas dans Maximo Scheduler. (Pattern D7 Inexistant)
Pourquoi D est faux — Graphical Horizon Planner est un nom inventé qui ne correspond à aucune application documentée. (Pattern D2 Inventé)
- Planification long terme — Vue agrégée sur plusieurs semaines/mois.
- Capacity Planning — Équilibrage charge/ressources sur un horizon donné.
- Statuts WO — PLANNING, APPROVED, INPRG, COMP.
- Vues calendaires — Représentation visuelle des allocations.
- Seuils d'alerte — Configurables pour détecter les surcharges.
- Graphical Work Week = vue hebdomadaire des ressources.
- Les couleurs correspondent aux statuts des ordres.
- Seuils configurables pour la détection de surcharge.
- STU sub-objective §7.1 — Applications Planning et Scheduling
- [EOTRAG] Query — « Maximo Scheduler applications long-term planning weekly view » (confidence 0.88)
- master-map.pdf p.203-205 — IBM Docs Scheduling Tools
Bonne réponse : D
Pourquoi cette question existe — STU §7.1 — cette question teste la compréhension des différentes applications de planification dans Maximo Manage 9.x, en particulier celle qui permet d'assigner des ressources individuelles à des tâches de WO avec une vue Gantt. Les distracteurs montrent les erreurs typiques : confondre les applications de planification globale (D6), utiliser une vue hebdomadaire (D5), ou oublier la spécificité de l'assignation individuelle (D4).
Le contexte théorique d'abord — Dans Maximo Manage 9.x, plusieurs applications permettent de planifier et d'assigner des ressources. La Graphical Assignment est spécifiquement conçue pour assigner des ressources individuelles (comme les techniciens) à des tâches de WO, en utilisant une vue Gantt qui montre la disponibilité des ressources. Cette application est cruciale pour optimiser l'utilisation des ressources et éviter les conflits d'assignation.
Ce que Maximo en fait — version opérationnelle — Pour utiliser la Graphical Assignment, l'utilisateur doit naviguer dans l'application Graphical Assignment, sélectionner les WO à assigner, puis glisser-déposer les ressources individuelles sur les tâches correspondantes dans la vue Gantt. Cette vue permet de visualiser les disponibilités et les conflits d'assignation en temps réel.
Exemple chiffré — Un technicien avec 3 tâches assignées : Tâche A (4 heures), Tâche B (2 heures), Tâche C (3 heures). La vue Gantt montre que le technicien est disponible de 8h à 17h, avec une pause de 12h à 13h. L'assignation optimisée montre Tâche A de 8h à 12h, Tâche C de 13h à 16h, et Tâche B de 16h à 18h.
Analogie quotidienne — C'est comme un emploi du temps scolaire où chaque professeur est assigné à une classe spécifique à une heure donnée, avec une vue globale qui montre les disponibilités et les conflits.
Pourquoi A est faux — Pattern D6 mauvaise-app : Le Scheduling Dashboard offre une vue globale des WO mais ne permet pas d'assigner des ressources individuelles avec une vue Gantt.
Pourquoi B est faux — Pattern D4 demi-vérité : Graphical Scheduling permet de planifier des ressources mais ne se concentre pas sur l'assignation individuelle avec une vue Gantt.
Pourquoi C est faux — Pattern D5 champ-frère : Graphical Work Week offre une vue hebdomadaire des ressources mais ne permet pas d'assigner des ressources individuelles avec une vue Gantt.
- Graphical Assignment — application pour assigner des ressources individuelles avec une vue Gantt.
- Gantt View — vue graphique qui montre les tâches et les disponibilités des ressources.
- Resource Availability — disponibilité des ressources pour éviter les conflits d'assignation.
- Work Order (WO) — tâche à assigner à une ressource.
- Drag-and-Drop — méthode pour assigner des ressources dans la vue Gantt.
- Graphical Assignment = assignation individuelle avec vue Gantt.
- Gantt View montre disponibilités et conflits en temps réel.
- Drag-and-Drop pour assigner des ressources.
- STU sub-objective §7.1 — Applications Planning et Scheduling
- [EOTRAG] Query — « Maximo Graphical Assignment Gantt view resource availability » (confidence 0.92)
- master-map.pdf p.201-204 — IBM Docs Graphical Assignment
Bonne réponse : A
Pourquoi cette question existe — STU §7.1 — la question teste la compréhension de l'application centrale pour le dispatch en temps réel des tâches aux techniciens, notamment en cas d'urgence. Les distracteurs montrent les erreurs typiques : confondre les outils de planification (D4), citer des apps inexistantes (D7), ou utiliser des outils adjacents mais non spécialisés (D5). En pratique terrain, la confusion entre les dashboards est fréquente.
Le contexte théorique d'abord — Le Dispatching Dashboard est l'application Maximo dédiée à la visualisation en temps réel des tâches via un Gantt. Il permet de réassigner rapidement les tâches en cas d'urgence, en tenant compte des ressources disponibles et des priorités. Les autres outils de planification, comme Graphical Scheduling, sont davantage orientés vers la planification à long terme.
Ce que Maximo en fait — version opérationnelle — Dans l'application Dispatching Dashboard, l'utilisateur sélectionne les tâches non assignées via le Gantt, puis les réassigne en les glissant vers une nouvelle ressource ou un nouveau créneau horaire. En cas d'urgence, l'utilisateur peut utiliser l'action Move Task pour réassigner rapidement les tâches critiques.
Exemple chiffré — Un utilisateur réassigne 3 tâches urgentes à un technicien disponible : tâche 1 (priorité haute, durée 2h), tâche 2 (priorité moyenne, durée 1h), tâche 3 (priorité basse, durée 30min). Le Gantt met à jour en temps réel les créneaux disponibles pour les 5 techniciens de l'équipe.
Analogie quotidienne — C'est comme un tableau de bord de gestion de flotte : tu vois en temps réel où sont les véhicules, et tu peux réassigner rapidement une livraison urgente à un autre chauffeur.
Pourquoi B est faux — Pattern D4 demi-vérité : Graphical Scheduling est un outil de planification mais ne permet pas de réassigner en temps réel en cas d'urgence.
Pourquoi C est faux — Pattern D7 inexistant : Scheduling Dashboard est une app qui n'existe pas dans Maximo.
Pourquoi D est faux — Pattern D5 champ-frère : Graphical Work Week est un outil adjacent mais non spécialisé pour le dispatch en temps réel.
- Dispatching Dashboard — application pour le dispatch en temps réel des tâches.
- Gantt view — représentation visuelle des tâches et des ressources.
- Move Task — action pour réassigner rapidement les tâches urgentes.
- Graphical Scheduling — outil de planification à long terme.
- Graphical Work Week — vue hebdomadaire des tâches planifiées.
- Dispatching Dashboard = dispatch en temps réel + Gantt.
- Move Task pour réassigner rapidement en cas d'urgence.
- Graphical Scheduling = planification à long terme, pas de dispatch.
- STU sub-objective §7.1 — Applications Planning et Scheduling
- [EOTRAG] Query — « Maximo Dispatching Dashboard Gantt view emergency reassignment » (confidence 0.94)
- master-map.pdf p.1227-1231 — IBM Docs Dispatching Dashboard
Bonne réponse : A,B,D
Pourquoi cette question existe — STU §7.1 — cette question teste la capacité à identifier les applications distinctes du module Scheduler dans Maximo Manage 9.0. Les distracteurs montrent des erreurs courantes : confondre des applications existantes avec des concepts inventés (D2), ou mélanger des fonctionnalités avec des noms d'applications non documentés (D7). En pratique terrain, cette distinction est cruciale pour configurer correctement les workflows de planification.
Le contexte théorique d'abord — Le module Scheduler de Maximo Manage permet de planifier et de gérer les travaux de maintenance, les projets et les ressources de manière graphique. Il inclut plusieurs applications distinctes qui offrent des fonctionnalités spécifiques, telles que l'assignation graphique des ressources, la visualisation des plannings et la gestion des tableaux de bord.
Ce que Maximo en fait — version opérationnelle — Les applications du Scheduler sont accessibles via le module Planning and Scheduling dans Maximo Manage. Pour utiliser Graphical Scheduling, il faut naviguer dans l'application correspondante, configurer les ressources disponibles, et visualiser les plannings. Graphical Assignment permet d'assigner des tâches aux ressources de manière intuitive, tandis que Scheduling Dashboard offre une vue d'ensemble des plannings et des ressources.
Exemple chiffré — Un utilisateur configure un planning pour un projet de maintenance sur 3 sites, avec 12 équipes, 247 tâches et une durée totale de 30 jours. Graphical Scheduling affiche les plannings par site, Graphical Assignment permet d'assigner les tâches aux équipes, et Scheduling Dashboard montre l'avancement global.
Analogie quotidienne — C'est comme utiliser un agenda partagé en entreprise : Graphical Scheduling est le calendrier général, Graphical Assignment permet de répartir les tâches entre les collègues, et Scheduling Dashboard montre l'avancement global des projets.
Pourquoi C est faux — Pattern D2 Inventé : Scheduling Planner n'est pas une application distincte dans Maximo Manage 9.0.
Pourquoi E est faux — Pattern D7 Inexistant : Resource Capacity Planner n'est pas une application documentée dans Maximo Manage 9.0.
Pourquoi F est faux — Pattern D2 Inventé : Graphical Routing n'est pas une application distincte dans Maximo Manage 9.0.
- Graphical Scheduling — application pour visualiser et planifier les plannings.
- Graphical Assignment — application pour assigner des tâches aux ressources.
- Scheduling Dashboard — application pour visualiser l'avancement global des plannings.
- Planning and Scheduling — module Maximo pour la gestion des plannings et des ressources.
- Resource Management — gestion des ressources disponibles pour les plannings.
- Graphical Scheduling, Graphical Assignment et Scheduling Dashboard sont des applications distinctes du Scheduler.
- Scheduling Planner et Graphical Routing ne sont pas des applications documentées dans Maximo Manage 9.0.
- Le Scheduler permet de planifier et de gérer les travaux de maintenance et les projets.
- STU sub-objective §7.1 — Applications Planning et Scheduling
- [EOTRAG] Query — « Maximo Scheduler applications Graphical Scheduling Graphical Assignment Scheduling Dashboard » (confidence 0.98)
- master-map.pdf p.122-125 — IBM Docs Planning and Scheduling
Bonne réponse : D
Pourquoi cette question existe — STU §7.1 — la question teste la capacité à distinguer les outils de planification graphique (Gantt) des tableaux de bord agrégés (KPI). Les distracteurs montrent les erreurs typiques : confondre les outils de modification visuelle avec les outils de reporting (D4), inventer des applications inexistantes (D2), ou utiliser des noms similaires mais incorrects (D7). En pratique terrain, cette distinction est cruciale pour choisir le bon outil selon le besoin.
Le contexte théorique d'abord — Le Scheduling Dashboard est un tableau de bord qui agrège des indicateurs clés de performance (KPI) tels que l'utilisation des ressources, les coûts planifiés vs réels, et les problèmes de planification. Contrairement aux outils graphiques comme Graphical Scheduling, il ne permet pas de modifier les plannings directement mais offre une vue synthétique des données.
Ce que Maximo en fait — version opérationnelle — Dans l'application Planning, sélectionnez le tableau de bord Scheduling pour accéder aux KPI agrégés. Les cartes incluent des indicateurs tels que Work compliance (heures planifiées vs réelles), Resource availability (disponibilité des ressources), Cost compliance (coûts planifiés vs réels), et Total actual cost (coût total des travaux effectués). Ces données sont mises à jour en temps réel en fonction des Work Orders et des ressources disponibles.
Exemple chiffré — Pour un site donné, le Scheduling Dashboard montre : Work compliance = 85%, Resource availability = 78%, Cost compliance = 102/120, Total actual cost = 12500€/15000€. Ces chiffres permettent de visualiser rapidement les écarts entre planification et exécution.
Analogie quotidienne — C'est comme un tableau de bord de voiture qui affiche la vitesse, le niveau de carburant et les alertes, sans permettre de modifier directement le moteur. Il donne une vue d'ensemble pour prendre des décisions éclairées.
Pourquoi A est faux — Graphical Scheduling est un éditeur Gantt qui permet de modifier les plannings visuellement, mais il ne fournit pas de KPI agrégés. (Pattern D4 Demi-vérité)
Pourquoi B est faux — Dispatching Dashboard est un nom similaire mais inexistant dans Maximo 9.x. (Pattern D7 Inexistant)
Pourquoi C est faux — Graphical Assignment est un terme inventé qui ne correspond à aucune application Maximo connue. (Pattern D2 Inventé)
- Scheduling Dashboard — tableau de bord agrégé des KPI de planification.
- Graphical Scheduling — éditeur Gantt pour modifier les plannings visuellement.
- Work compliance — proportion des heures réelles vs planifiées.
- Resource availability — proportion des heures disponibles vs utilisées.
- Cost compliance — proportion des coûts réels vs planifiés.
- Scheduling Dashboard = KPI agrégés, pas de modification directe.
- Graphical Scheduling = éditeur Gantt, pas de KPI agrégés.
- Distinguer outils de reporting vs outils de modification visuelle.
- STU sub-objective §7.1 — Applications Planning et Scheduling
- [EOTRAG] Query — « Maximo Scheduling Dashboard KPIs resource utilization » (confidence 0.87)
- master-map.pdf p.201-203 — IBM Docs Scheduling Dashboard
Bonne réponse : A,B
Pourquoi cette question existe — STU §7.1 — la question teste la compréhension des deux modes de visualisation principaux dans l'application Graphical Scheduling : le Gantt et la vue par ressources. Ces modes sont essentiels pour planifier et suivre les tâches et les ordres de travail (WO) de manière efficace. Les distracteurs montrent des visualisations qui ne sont pas disponibles dans cette application, ce qui peut induire en erreur ceux qui ne connaissent pas bien l'interface.
Le contexte théorique d'abord — L'application Graphical Scheduling permet de visualiser et de planifier les ordres de travail (WO) et les tâches associées. Deux modes de visualisation sont disponibles : le Gantt view, qui affiche les tâches sous forme de barres temporelles, et le Resource view, qui organise les tâches par ressources (Labor/Crew) sous forme de swimlanes. Ces modes facilitent la gestion des ressources et la planification des tâches.
Ce que Maximo en fait — version opérationnelle — Dans l'application Graphical Scheduling, l'utilisateur peut basculer entre les deux modes de visualisation. Le Gantt view montre les tâches et les WO sous forme de barres temporelles, tandis que le Resource view organise les tâches par ressources (Labor/Crew) en swimlanes. Ces vues permettent de planifier et de réassigner les tâches en fonction des disponibilités des ressources.
Exemple chiffré — Un utilisateur planifie 15 WO avec 47 tâches sur 3 jours. Le Gantt view montre 47 barres temporelles, tandis que le Resource view organise ces tâches en 5 swimlanes pour 3 équipes (Crew A, Crew B, Crew C). Les tâches sont réparties en fonction des disponibilités : Crew A = 18 tâches, Crew B = 15 tâches, Crew C = 14 tâches.
Analogie quotidienne — C'est comme utiliser un calendrier partagé : le Gantt view est une vue chronologique des événements, tandis que le Resource view est une vue par personne ou équipe, montrant qui fait quoi et quand.
Pourquoi C est faux — Pattern D7 Inexistant : la vue Pivot table n'est pas disponible dans l'application Graphical Scheduling.
Pourquoi D est faux — Pattern D7 Inexistant : la vue Heatmap calendar n'est pas disponible dans cette application.
Pourquoi E est faux — Pattern D6 Mauvaise-app : la vue Geographic map overlay est disponible dans l'application Graphical Assignment, mais pas dans Graphical Scheduling.
- Gantt view — affiche les tâches sous forme de barres temporelles.
- Resource view — organise les tâches par ressources en swimlanes.
- Graphical Scheduling — application pour planifier les WO et tâches.
- Labor/Crew — ressources humaines assignées aux tâches.
- Swimlanes — organisation visuelle des tâches par ressource.
- Graphical Scheduling offre Gantt et Resource views.
- Gantt = barres temporelles, Resource = swimlanes par ressource.
- Pas de Pivot table, Heatmap, ou Geographic map dans cette app.
- STU sub-objective §7.1 — Graphical Scheduling visualization modes
- [EOTRAG] Query — « Graphical Scheduling Gantt Resource view » (confidence 0.92)
- master-map.pdf p.234-237 — IBM Docs Graphical Scheduling

Préparer les records avec Scheduler Data Manager
📋 Objectifs IBM
- Comprendre le rôle et l'utilisation de l'application
Scheduler Data ManagerdansMaximo Manage. - Identifier les types de données validées par
Scheduler Data Managerpour les plannings et les listes de travail. - Accéder à l'application
Scheduler Data Managerdepuis le menu Administration ou d'autres applications de planification graphique. - Reconnaître les problèmes de données courants qui peuvent affecter la planification et la manière de les corriger.
- Appliquer les meilleures pratiques de gestion des données pour optimiser l'efficacité des opérations de planification.
- Utiliser les fonctionnalités de validation pour assurer la cohérence et l'exactitude des informations avant l'ordonnancement.
💡 Points clés
Scheduler Data Manager— Une application essentielle dansMaximo Managepour valider les données des plannings et des listes de travail avant leur exécution.- Validation des données — Processus permettant de s'assurer que les informations utilisées pour la planification sont exactes, complètes et conformes aux meilleures pratiques.
- Accès multiple — L'application
Scheduler Data Managerest accessible via le menu Administration ou directement depuis des applications commeGraphical SchedulingetGraphical Assignment. - Correction des erreurs — Les erreurs détectées par le gestionnaire de données peuvent être corrigées directement dans les enregistrements de travail ou exclues du processus de planification.
- Impact sur la planification — Des données non validées ou incorrectes peuvent entraîner des problèmes significatifs dans l'ordonnancement, tels que des chevauchements ou des ressources mal allouées.
- Onglets de validation — L'application utilise différents onglets pour valider des catégories spécifiques de données, comme les informations de calendrier, les requêtes, les dépendances et les ressources.
- Actualisation nécessaire — Après avoir apporté des modifications aux enregistrements de travail, il est impératif d'actualiser les plannings pour que les changements soient pris en compte.
- Meilleures pratiques — L'utilisation proactive de
Scheduler Data Managergarantit que les meilleures pratiques de gestion des données sont suivies pour une planification optimale.
📐 Architecture de la validation des données de planification
L'application Scheduler Data Manager s'intègre de manière cruciale dans l'écosystème de planification de Maximo Manage. Elle agit comme un point de contrôle centralisé pour la qualité des données avant que celles-ci ne soient utilisées par les outils de planification graphique. Son rôle est de prévenir les problèmes opérationnels en identifiant et en permettant la correction des incohérences ou des lacunes dans les enregistrements de travail.
Cette architecture garantit que les décisions de planification sont basées sur des informations fiables, réduisant ainsi les risques d'erreurs, de retards ou de surutilisation des ressources. Elle est particulièrement pertinente pour les environnements complexes où de nombreux enregistrements de travail, actifs et ressources interagissent.
B
B -- Valide les données de --> C
B -- Valide les données de --> D
B -- Valide les données de --> E
B -- Valide les données de --> F
B -- Valide les données de --> G
B -- Valide les données de --> H
B -- Génère --> I
I -- Guide --> J
J -- Met à jour --> C
C -- Nécessite actualisation pour --> K
K -- Utilisé par --> A
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A
classDef tertiary fill:#E0F2F7,stroke:#00BCD4,stroke-width:1px,color:#0F172A
classDef quaternary fill:#FFEBEE,stroke:#F44336,stroke-width:1px,color:#0F172A
">
Scheduler Data Manager dans le processus de planification de Maximo. Il illustre comment l'application centralise la validation des diverses sources de données avant leur utilisation par les outils de planification graphique.📊 Tableau de référence des validations par onglet
L'application Scheduler Data Manager organise ses validations par onglets, chacun ciblant un aspect spécifique des données de planification. Cette approche modulaire permet une vérification exhaustive et ciblée des informations.
| Onglet de Validation | Description de la Validation | Exemples de Données Vérifiées |
|---|---|---|
Calendar | Vérifie la cohérence et la complétude des informations de calendrier associées aux enregistrements de travail et aux ressources. | Disponibilité des ressources, jours fériés, quarts de travail. |
Queries | Valide les requêtes utilisées pour filtrer les enregistrements de travail, les actifs ou les emplacements inclus dans le planning. | Syntaxe des requêtes, existence des actifs/emplacements référencés. |
Dependencies | Examine les relations de dépendance entre les tâches et les enregistrements de travail pour s'assurer de leur logique et de leur faisabilité. | Dépendances "Fin-Début", "Début-Début", "Fin-Fin", "Début-Fin". |
Resources | Contrôle la disponibilité et l'adéquation des ressources (main-d'œuvre, outils, matériaux) requises pour les tâches planifiées. | Compétences requises, disponibilité des techniciens, inventaire des pièces. |
Assignments | Vérifie la validité des affectations de travail aux ressources, y compris les chevauchements ou les affectations à des ressources non disponibles. | Affectations de main-d'œuvre, affectations d'équipes. |
Scheduler Data Manager et les types de données spécifiques qu'ils examinent pour garantir l'intégrité des plannings.⚙️ Utilisation opérationnelle de Scheduler Data Manager
L'application Scheduler Data Manager est un outil proactif pour maintenir la qualité des données de planification. Elle est conçue pour être utilisée avant que les plannings ne soient finalisés ou que les affectations ne soient effectuées. Cela permet aux planificateurs et aux ordonnanceurs d'identifier et de résoudre les problèmes potentiels avant qu'ils n'impactent les opérations sur le terrain.
Un exemple concret serait la validation d'un planning pour un arrêt de maintenance majeur impliquant des centaines d'enregistrements de travail. Sans une validation préalable, des dépendances manquantes ou des ressources mal allouées pourraient entraîner des retards coûteux et des goulots d'étranglement. L'utilisation de Scheduler Data Manager permet de détecter ces problèmes en amont.
- Accès à l'application — L'application est accessible via le menu Administration ou directement depuis des applications de planification graphique comme
Graphical Scheduling,Graphical Scheduling - Large Projects,Graphical AssignmentetGraphical Work Week. - Sélection du planning/liste de travail — L'utilisateur sélectionne le planning ou la liste de travail à valider.
- Exécution de la validation — Le système analyse les données associées au planning sélectionné en fonction des critères définis dans les différents onglets.
- Analyse des résultats — Des icônes d'erreur ou d'avertissement apparaissent à côté des éléments problématiques. L'utilisateur peut alors examiner les détails de chaque problème.
- Correction ou exclusion — Les erreurs peuvent être corrigées directement dans les enregistrements de travail sous-jacents. Si une correction n'est pas possible ou souhaitable, l'élément peut être exclu du planning.
- Actualisation du planning — Après toute modification des enregistrements de travail, il est crucial d'actualiser les plannings pour que les changements soient reflétés.
🔄 Cycle de vie de la validation des données de planification
Le processus de validation des données de planification est un cycle itératif qui vise à garantir l'exactitude et la pertinence des informations utilisées pour l'ordonnancement. Il commence dès la création des enregistrements de travail et se poursuit jusqu'à la finalisation du planning, avec des étapes de vérification et de correction.
⚠️ Pièges IBM
Un piège courant est de corriger les erreurs dans les enregistrements de travail via Scheduler Data Manager, mais d'oublier d'actualiser les plannings. Les modifications apportées aux enregistrements de travail ne sont pas automatiquement reflétées dans les plannings existants tant qu'une actualisation n'est pas explicitement effectuée. Cela peut conduire à des situations où le planificateur pense avoir résolu un problème, mais le planning continue d'afficher des données obsolètes ou incorrectes, entraînant des décisions de planification erronées. Il est impératif de toujours rafraîchir les plannings après toute correction.
Bien que les erreurs bloquantes soient évidentes, les avertissements (souvent représentés par des icônes spécifiques) peuvent être tentants à ignorer, surtout sous la pression des délais. Cependant, ces avertissements signalent souvent des problèmes potentiels qui, bien que ne bloquant pas immédiatement la planification, peuvent entraîner des inefficacités, des retards ou des conflits de ressources à long terme. Par exemple, un avertissement sur une ressource dont la disponibilité est marginale pourrait indiquer un risque de surcharge si d'autres tâches sont ajoutées. Il est crucial d'examiner et de comprendre la cause de chaque avertissement pour prendre des décisions éclairées.
Maximo Manage peut contenir des enregistrements de travail qui sont techniquement valides d'un point de vue de la base de données, mais qui posent des problèmes pour la planification graphique. Par exemple, des enregistrements de travail avec un statut CANCELLED ou CLOSED ne sont pas inclus dans la vue Gantt des applications de planification graphique. De même, un PM sans Job Plan associé aura une durée par défaut d'une heure, ce qui peut être trompeur. Le Scheduler Data Manager aide à identifier ces cas où les données, bien que "valides", ne sont pas "utilisables" de manière optimale pour l'ordonnancement, nécessitant une intervention manuelle ou une configuration plus précise.
🎯 Carte mémoire
Quel est le but principal de l'application Scheduler Data Manager dans Maximo Manage ?
L'application Scheduler Data Manager a pour but principal de valider les données des plannings et des listes de travail avant leur utilisation dans les outils de planification graphique. Elle permet d'identifier les erreurs et les avertissements pour garantir que les données sont exactes et conformes aux meilleures pratiques, évitant ainsi les problèmes lors de l'ordonnancement et de l'affectation des ressources.
Quelles sont les principales catégories de données validées par Scheduler Data Manager et pourquoi est-ce important de les vérifier ?
Les principales catégories de données validées sont les informations de calendrier, les requêtes, les dépendances, les ressources et les affectations. Il est crucial de les vérifier car des incohérences ou des erreurs dans ces domaines peuvent entraîner des plannings irréalisables, des conflits de ressources, des retards opérationnels et une mauvaise utilisation des actifs, compromettant l'efficacité globale de la maintenance.
Comment les enregistrements de travail avec les statuts CANCELLED ou CLOSED sont-ils traités par les applications de planification graphique, et quelle est l'implication pour le planificateur ?
Les enregistrements de travail dont le statut est CANCELLED ou CLOSED ne sont pas inclus dans la vue Gantt des applications de planification graphique. L'implication pour le planificateur est qu'il doit s'assurer que seuls les enregistrements de travail actifs et pertinents sont inclus dans le processus de planification pour éviter de travailler avec des données obsolètes ou non exécutables, ce que Scheduler Data Manager peut aider à identifier.
Bonne réponse : D
Pourquoi cette question existe — STU §7.2 — cette question teste la compréhension du rôle central du Scheduler Data Manager dans la validation des données de planification avant leur passage à l'Optimizer. Les distracteurs montrent des erreurs typiques : confondre validation avec export (D6), archiver des données (D2), ou fusionner des calendriers (D7). En pratique terrain, l'omission de cette étape de validation entraîne des erreurs dans l'Optimizer.
Le contexte théorique d'abord — Le Scheduler Data Manager est une application de Maximo Manage qui vérifie que les ordres de travail (WORKORDER) et les tâches associées contiennent les données requises pour être correctement planifiées. Ces données incluent les dates, les durées, les plans de travail (JOBPLAN), et les champs planifiables. Cette validation est cruciale pour garantir que l'Optimizer fonctionne avec des données complètes et cohérentes.
Ce que Maximo en fait — version opérationnelle — Dans l'application Scheduler Data Manager, l'utilisateur sélectionne les ordres de travail à valider. Le système vérifie automatiquement la présence et la cohérence des champs obligatoires. Si des erreurs sont détectées, elles sont signalées pour correction avant que les données ne soient transmises à l'Optimizer.
Exemple chiffré — Pour un site donné, 247 ordres de travail sont soumis au Scheduler Data Manager. Après validation, 12 sont rejetés pour manque de dates, 8 pour absence de plan de travail, et 227 sont validés avec succès pour être traités par l'Optimizer.
Analogie quotidienne — C'est comme un contrôleur de billets avant l'embarquement dans un avion : il vérifie que chaque passager a bien son billet et son passeport avant de monter à bord, évitant ainsi des problèmes pendant le vol.
Pourquoi A est faux — Pattern D6 mauvaise-app : l'export de données vers watsonx.ai est une fonctionnalité distincte, non gérée par le Scheduler Data Manager.
Pourquoi B est faux — Pattern D2 inventé : l'archivage des données dans un stockage froid via Database Configuration n'est pas une fonctionnalité existante dans Maximo Manage.
Pourquoi C est faux — Pattern D7 inexistant : la fusion des calendriers de planification entre organisations n'est pas une fonctionnalité du Scheduler Data Manager.
- Scheduler Data Manager — application de validation des données de planification.
- WORKORDER — table contenant les ordres de travail.
- JOBPLAN — table contenant les plans de travail associés aux ordres.
- Optimizer — module de planification avancée dans Maximo Manage.
- Champs planifiables — champs nécessaires pour la planification des ordres de travail.
- Le Scheduler Data Manager valide les données avant leur passage à l'Optimizer.
- Les champs obligatoires incluent dates, durées, plans de travail et champs planifiables.
- Les erreurs détectées doivent être corrigées avant la planification.
- STU sub-objective §7.2 — Scheduler Data Manager validation process
- [EOTRAG] Query — « Scheduler Data Manager validate WORKORDER JOBPLAN Optimizer » (confidence 0.98)
- master-map.pdf p.1234 — IBM Docs Scheduler Data Manager
Bonne réponse : A
Pourquoi cette question existe — STU §7.2 — cette question vérifie la compréhension des champs critiques que le Scheduler Data Manager valide pour assurer la cohérence des ordres de travail planifiés. Les distracteurs ciblent les erreurs courantes : confondre champs administratifs (D5), ignorer les flags de planification (D4), ou se limiter aux données de signalement (D9). En pratique terrain, omettre ces validations entraîne des conflits de ressources et des écarts de planning.
Le contexte théorique d'abord — Le Scheduler Data Manager supervise l'intégrité des données temporelles et logiques des WORKORDER. Il vérifie notamment : les dates cibles (TARGSTARTDATE, TARGCOMPDATE), les dates planifiées (SCHEDSTART, SCHEDFINISH), les durées des tâches (ESTDUR), la référence au JOBPLAN, et les indicateurs de planifiabilité (SCHEDULABLE flag). Ces contrôles garantissent que seuls les WO valides sont traités par le moteur de planification.
Ce que Maximo en fait — version opérationnelle — Dans Work Order Tracking > Configuration > Scheduler Data Manager, les règles de validation sont définies via des expressions conditionnelles sur les champs WORKORDER. Exemple : SCHEDULABLE=1 AND TARGSTARTDATE IS NOT NULL AND JOBPLAN IN (SELECT JOBPLANID FROM JOBPLAN WHERE STATUS='ACTIVE'). Les WO non conformes sont marqués WAPPR pour correction.
Exemple chiffré — Sur 142 WO soumis : 87 validés (dates cohérentes, job plan actif), 32 rejetés (dont 15 sans SCHEDULABLE flag, 10 avec TARGSTARTDATE passée, 7 référençant un JOBPLAN obsolète), 23 en attente de données complémentaires.
Analogie quotidienne — Comme un contrôleur aérien qui vérifie les plans de vol : heure de décollage/d'atterrissage cohérentes, avion en état de vol, équipage assigné — avant d'autoriser l'intégration dans le planning des pistes.
Pourquoi B est faux — Pattern D5 champ-frère : WOSTATUS et priorité sont gérés par le workflow, pas par le Scheduler Data Manager.
Pourquoi C est faux — Pattern D4 demi-vérité : les codes d'échec sont liés à la maintenance corrective, non aux contraintes de planification.
Pourquoi D est faux — Pattern D9 quasi-synonyme : les champs de signalement (REPORTEDBY, REPORTDATE) documentent l'origine du WO mais n'affectent pas sa planifiabilité.
- TARGSTARTDATE/TARGCOMPDATE — dates cibles définies par l'utilisateur.
- SCHEDSTART/SCHEDFINISH — dates calculées par le moteur de planification.
- SCHEDULABLE — flag indiquant si le WO peut être planifié (0/1).
- JOBPLAN — référence au plan de travail standardisé.
- ESTDUR — durée estimée utilisée pour le calcul des plannings.
- Le Scheduler valide dates, durées, job plan et flags de planification.
- Les champs administratifs (statut, priorité) sont ignorés par ce processus.
- Un WO non validé reste en
WAPPRjusqu'à correction.
- STU sub-objective §7.2 — Scheduler Data Manager validation rules
- [EOTRAG] Query — « Maximo Scheduler Data Manager WORKORDER fields validation » (confidence 0.89)
- master-map.pdf p.231-234 — IBM Docs Work Order Scheduling
Correct order: A → B → C → D
Pourquoi cet ordre — Le workflow canonique Scheduler : (1) Load WOs — le planner sélectionne les WOs candidats à l'optimisation dans le Schedule record (via query saved ou filter) ; (2) Data Manager validate — pre-flight check pour éliminer les WOs aux données incomplètes ; (3) Optimizer execute — CPLEX calcule le schedule optimal selon le modèle choisi (Date-based, Priority, Resource-leveled, Minimum Travel) ; (4) Review results — le planner valide le schedule dans Graphical Scheduling ou Scheduling Dashboard, ajuste manuellement si besoin.
- IBM Docs — Scheduler optimization workflow : 4 steps
- Maximo Secrets — Scheduler : End-to-end flow

Configurer Maximo Optimizer
📋 Objectifs IBM
- Comprendre le rôle et les capacités de Maximo Optimizer au sein de Maximo Application Suite.
- Identifier les composants clés et l'architecture de déploiement de Maximo Optimizer.
- Décrire les étapes de configuration des propriétés système pour l'intégration de Maximo Optimizer.
- Expliquer comment Maximo Optimizer automatise la planification et l'ordonnancement des ressources de maintenance.
- Reconnaître les avantages de l'optimisation des processus de maintenance pour l'entreprise.
- Démontrer la capacité à gérer et à mettre à jour les modèles d'optimisation.
💡 Points clés
- Maximo Optimizer — Un add-on de Maximo Application Suite (MAS) conçu pour automatiser les décisions de planification à long terme, d'ordonnancement et de répartition des ressources de maintenance.
- Optimisation des ressources — Permet d'équilibrer des objectifs et des contraintes concurrents pour une maintenance des actifs plus efficace.
- Modèles d'optimisation — Maximo Optimizer propose des modèles prêts à l'emploi, paramétrables pour les règles métier et extensibles pour des exigences spécifiques.
- Propriétés système — La configuration de Maximo Optimizer implique la définition de propriétés système spécifiques telles que `optimization.mofapi.baseurl` et `optimization.mofui.url`.
- Historique des tâches — Le système maintient un historique complet des exécutions d'optimisation, incluant un journal détaillé et un instantané des données d'entrée pour la reproductibilité.
- Déploiement et mises à jour — L'interface utilisateur administrative de Maximo Optimizer facilite la gestion des mises à jour de modèles et des correctifs sans interruption de service.
- MAS Hub — Maximo Optimizer est déployé et géré via le `MAS Hub` en tant que composant de Maximo Application Suite.
- ROI et justification — L'optimisation des processus de maintenance vise à améliorer le retour sur investissement et à justifier les dépenses liées à Maximo.
📐 Architecture et Intégration de Maximo Optimizer
Maximo Optimizer est une application complémentaire essentielle au sein de l'écosystème Maximo Application Suite (MAS). Son rôle principal est d'apporter des capacités d'optimisation avancées aux processus de gestion de la maintenance, en se concentrant sur la planification, l'ordonnancement et la répartition des ressources. Il ne s'agit pas d'une application autonome, mais d'un service intégré qui s'appuie sur les données et les fonctionnalités de Maximo Manage.
L'intégration de Maximo Optimizer dans MAS est conçue pour être transparente, permettant aux utilisateurs de Maximo de bénéficier de ses capacités sans nécessiter une expertise approfondie en optimisation. L'architecture repose sur des microservices et des API, facilitant la communication entre Maximo Manage et le moteur d'optimisation. Cette approche garantit une évolutivité et une flexibilité adaptées aux besoins complexes des grandes entreprises gérant des milliers d'actifs et de ressources.
Le déploiement de Maximo Optimizer s'effectue généralement au sein de l'environnement OpenShift qui héberge MAS. Cela permet une gestion centralisée et une exploitation efficace des ressources informatiques. Les modèles d'optimisation, bien que prêts à l'emploi, sont conçus pour être hautement configurables et extensibles, s'adaptant ainsi aux règles métier spécifiques et aux contraintes opérationnelles de chaque organisation. Cette flexibilité est cruciale pour maximiser la valeur de l'optimisation dans des contextes industriels variés.
📊 Comparaison des approches de planification de maintenance
La planification de la maintenance peut être abordée de différentes manières, allant des méthodes réactives aux approches proactives et optimisées. Maximo Optimizer représente une avancée significative en permettant une optimisation basée sur des algorithmes complexes, contrastant avec les méthodes manuelles ou heuristiques.
Cette table compare les caractéristiques clés des différentes approches de planification de maintenance, soulignant les avantages distincts apportés par l'intégration de Maximo Optimizer.
| Caractéristique | Maintenance Réactive | Maintenance Préventive/Manuelle | Maintenance Optimisée (Maximo Optimizer) |
|---|---|---|---|
| Déclenchement | Panne d'équipement | Calendrier, compteurs, inspections | Algorithmes d'optimisation, contraintes métier |
| Prise de décision | Urgence, expérience opérateur | Règles fixes, jugement humain | Modèles mathématiques, IA, équilibre des objectifs |
| Efficacité des ressources | Faible (réparations urgentes, surstock) | Moyenne (planification basique, sous-utilisation potentielle) | Élevée (minimisation des coûts, maximisation de l'utilisation) |
| Complexité | Faible | Moyenne | Élevée (gérée par le système) |
| Coût | Élevé (temps d'arrêt imprévus, réparations coûteuses) | Moyen (planification, pièces de rechange) | Optimisé (réduction des coûts globaux, amélioration du ROI) |
| Visibilité | Limitée | Bonne sur les tâches planifiées | Excellente (scénarios, impacts, historique des optimisations) |
| Adaptabilité | Faible | Moyenne | Élevée (re-optimisation rapide face aux changements) |
| Exemple d'application | Réparation d'une pompe cassée | Inspection mensuelle d'un moteur | Planification annuelle des arrêts d'usine, ordonnancement des techniciens sur 12 sites |
⚙️ Configuration et Déploiement de Maximo Optimizer
Le déploiement et la configuration de Maximo Optimizer sont des étapes cruciales pour exploiter pleinement ses capacités. En tant qu'add-on de Maximo Application Suite, son installation et son paramétrage suivent des procédures spécifiques, souvent gérées par des administrateurs système ou des experts en intégration.
La configuration principale implique la définition de propriétés système qui établissent la communication entre Maximo Manage et les services d'optimisation. Ces propriétés sont essentielles pour que Maximo Manage puisse envoyer des requêtes d'optimisation et recevoir les résultats.
Un aspect important de la configuration est la personnalisation des modèles d'optimisation. Bien que des modèles prêts à l'emploi soient fournis, ils peuvent être ajustés pour refléter les règles métier spécifiques, les contraintes opérationnelles, et les objectifs de performance de l'entreprise. Cette flexibilité permet à Maximo Optimizer de s'adapter à des environnements complexes, comme la gestion de 247 actifs critiques répartis sur 12 sites différents avec des contraintes de ressources et de disponibilité.
- Déploiement initial — Maximo Optimizer est déployé en tant que composant de Maximo Application Suite, souvent via le `MAS Hub` ou des outils de gestion de conteneurs comme OpenShift.
- Configuration des propriétés système — Les administrateurs doivent définir des propriétés système clés dans Maximo Manage. Par exemple, la propriété `optimization.mofapi.baseurl` doit être configurée avec l'URL de base de l'API d'optimisation, typiquement au format `https://{instanceid}-{workspaceid}-api.mas-{instanceid}-optimizer.svc`.
- Configuration de l'interface utilisateur — La propriété `optimization.mofui.url` est également cruciale pour l'accès à l'interface utilisateur de Maximo Optimizer, avec une valeur telle que `https://{workspaceId}.optimizer.{masdomain}.com`.
- Paramétrage des modèles — Les modèles d'optimisation peuvent être paramétrés via l'interface administrative pour affiner les règles métier et intégrer des contraintes spécifiques (ex: disponibilité des techniciens, capacité des équipements, délais de livraison des pièces).
- Gestion des mises à jour — L'interface utilisateur administrative permet de gérer les mises à jour de modèles et les correctifs sans interruption de service, assurant une continuité opérationnelle.
- Suivi des tâches d'optimisation — Maximo Optimizer enregistre un historique détaillé de toutes les exécutions d'optimisation, incluant les données d'entrée et les journaux, ce qui est essentiel pour le débogage et l'analyse.
🔄 Workflow d'optimisation de la maintenance
Le workflow d'optimisation de la maintenance avec Maximo Optimizer est un processus structuré qui transforme les données brutes de Maximo Manage en plans d'action optimisés. Ce cycle de vie implique plusieurs étapes, depuis la collecte des données jusqu'à l'implémentation des recommandations, en passant par l'exécution des modèles d'optimisation.
L'objectif est de fournir des décisions efficaces pour la planification à long terme, l'ordonnancement et la répartition des ressources, tout en équilibrant les objectifs concurrents tels que la réduction des coûts, l'amélioration de la disponibilité des actifs et le respect des délais. Par exemple, pour un parc de 500 équipements critiques, Maximo Optimizer peut aider à planifier les maintenances préventives et correctives sur une période de 6 mois, en tenant compte des compétences des 50 techniciens disponibles, des stocks de 3 storerooms et des contraintes budgétaires.
DataCollection: Démarrage
DataCollection --> DefineGoals: Données brutes (actifs, WO, ressources)
DefineGoals --> RunOptimization: Modèle configuré
RunOptimization --> AnalyzeResults: Résultats d'optimisation
AnalyzeResults --> ImplementRecommendations: Plans validés
ImplementRecommendations --> MonitorAdjust: Actions mises en œuvre
MonitorAdjust --> DataCollection: Retour d'expérience, nouvelles données
MonitorAdjust --> [*]: Fin du cycle (ou ré-optimisation)
note right of RunOptimization
Utilisation des propriétés système
(ex: optimization.mofapi.baseurl)
pour l'appel à l'API d'optimisation.
end note
note right of AnalyzeResults
Historique des tâches et logs
pour la reproductibilité et le débogage.
end note
">
⚠️ Pièges IBM
Les candidats peuvent sous-estimer l'importance de la configuration précise des propriétés système telles que `optimization.mofapi.baseurl` et `optimization.mofui.url`. Une erreur courante est d'utiliser des valeurs génériques ou des URL mal formatées, ce qui empêche Maximo Manage de communiquer correctement avec le service Maximo Optimizer. L'examen peut présenter des scénarios où ces propriétés sont mal configurées et demander d'identifier la cause du dysfonctionnement.
Il est facile de penser que Maximo Optimizer est une solution "plug-and-play". Cependant, bien que des modèles soient prêts à l'emploi, leur efficacité dépend fortement de leur paramétrage pour correspondre aux règles métier spécifiques. Un piège serait de croire qu'une configuration par défaut est suffisante pour tous les cas d'usage, ignorant la nécessité d'adapter les modèles aux contraintes réelles de l'entreprise, telles que les compétences des techniciens, les priorités des ordres de travail ou les contraintes budgétaires. L'examen pourrait tester la capacité à identifier quand et pourquoi une personnalisation de modèle est nécessaire.
Maximo Optimizer est un add-on de Maximo Application Suite. Un piège courant est de ne pas comprendre que son déploiement est intrinsèquement lié à l'infrastructure MAS et non comme une application autonome. Les questions peuvent porter sur les prérequis de déploiement, les dépendances avec d'autres composants de MAS (comme Maximo Manage), ou les outils utilisés pour son installation (par exemple, via le `MAS Hub` ou OpenShift). Une mauvaise compréhension de cette interdépendance peut conduire à des erreurs de diagnostic ou de planification de déploiement.
Les candidats pourraient négliger l'importance de l'historique des tâches d'optimisation. Maximo Optimizer maintient un journal détaillé et un instantané des données d'entrée pour chaque exécution. Un piège serait de ne pas reconnaître la valeur de cette fonctionnalité pour la reproductibilité, le débogage des modèles ou l'analyse des performances. L'examen pourrait présenter un scénario où une optimisation a donné des résultats inattendus et demander comment investiguer le problème sans cet historique.
🎯 Carte mémoire
Quel est le rôle principal de Maximo Optimizer au sein de Maximo Application Suite ?
Maximo Optimizer est un add-on de MAS qui automatise les décisions de planification à long terme, d'ordonnancement et de répartition des ressources pour la maintenance des actifs, en équilibrant les objectifs et les contraintes concurrents.
Quelles sont les deux propriétés système essentielles à configurer pour l'intégration de Maximo Optimizer ?
Les deux propriétés système essentielles sont `optimization.mofapi.baseurl` pour l'API d'optimisation et `optimization.mofui.url` pour l'interface utilisateur administrative de Maximo Optimizer.
Pourquoi la personnalisation des modèles d'optimisation est-elle importante ?
La personnalisation est cruciale car elle permet d'adapter les modèles prêts à l'emploi aux règles métier spécifiques, aux contraintes opérationnelles et aux objectifs de performance uniques de chaque organisation, maximisant ainsi l'efficacité de l'optimisation.
Comment Maximo Optimizer assure-t-il la reproductibilité et le débogage des exécutions d'optimisation ?
Maximo Optimizer maintient un historique complet de toutes les exécutions d'optimisation, incluant un journal détaillé et un instantané des données d'entrée utilisées pour chaque tâche, ce qui est essentiel pour la reproductibilité, le débogage et le support utilisateur.
Bonne réponse : D
Pourquoi cette question existe — STU §7.3 — cette question vérifie la connaissance du moteur d'optimisation natif intégré à Maximo Scheduler Optimizer en v9.0. Les distracteurs testent la confusion fréquente entre les différentes solutions d'optimisation IBM. En pratique terrain, cette connaissance est cruciale pour le déploiement et la configuration des modèles d'optimisation.
Le contexte théorique d'abord — Maximo Scheduler Optimizer utilise un moteur d'optimisation mathématique pour résoudre des problèmes complexes de planification. Ce moteur doit être capable de gérer des centaines de contraintes et des milliers de variables. IBM fournit ce moteur sous forme de composant intégré à Maximo.
Ce que Maximo en fait — version opérationnelle — Lors de l'activation de Maximo Optimizer via l'application System Properties, le moteur CPLEX est automatiquement utilisé pour exécuter les modèles d'optimisation. Aucune configuration supplémentaire n'est requise pour ce composant de base.
Exemple chiffré — Un modèle typique peut optimiser la planification de 127 techniciens sur 58 sites avec 243 contraintes opérationnelles, générant un planning optimal en 3,7 secondes. Le moteur traite jusqu'à 5000 variables simultanément.
Analogie quotidienne — C'est comme un GPS qui calcule le meilleur itinéraire en tenant compte du trafic, des travaux et de vos préférences, mais pour des centaines de véhicules simultanément.
Pourquoi A est faux — watsonx.ai est une plateforme d'IA générative, pas un moteur d'optimisation mathématique (Pattern D7 Inexistant).
Pourquoi B est faux — Cloud Pak for Data est une suite analytique externe, non intégrée nativement à Maximo (Pattern D6 Mauvaise-app).
Pourquoi C est faux — Gurobi est un concurrent d'IBM, non utilisé dans la solution native (Pattern D2 Inventé).
- Maximo Optimizer — module intégré pour la résolution de problèmes complexes.
- Modèles d'optimisation — configurations prédéfinies ou personnalisées pour différents cas d'usage.
- Contraintes — règles métier formalisées pour guider l'optimisation.
- Variables — éléments modifiables dans le modèle d'optimisation.
- Solution optimale — résultat satisfaisant toutes les contraintes au mieux.
- CPLEX est le moteur natif d'optimisation dans Maximo 9.0.
- Intégré directement, sans besoin de composant externe.
- Gère des milliers de variables et contraintes en temps réel.
- STU sub-objective §7.3 — Maximo Optimizer components
- [EOTRAG] Query — « Maximo Scheduler Optimizer engine v9.0 » (confidence 0.96)
- master-map.pdf p.727-729 — IBM Docs Deploying IBM Maximo Optimizer
Correct: B
Pourquoi B (correct) — Les 4 modèles Optimizer standards de Maximo Scheduler : Date-based (honore les target dates), Priority-based (exécute les high-priority first), Resource-leveled (aplatit workload), Minimum Travel (minimise déplacements géo). « Cost-minimization » n'est PAS un modèle livré — la cost optimization passe par Cost Management ailleurs dans Manage.
Pourquoi A est faux — D9 near-synonym : Date-based est un vrai modèle de scheduling livré avec Maximo Scheduler, mais ce n'est pas la réponse exacte attendue par la question qui vise un autre modèle spécifique. Distracteur inclus comme "vrai mais pas le demandé".
Pourquoi C est faux — D9 near-synonym : Resource-leveled est un vrai modèle livré (workload flattening sur labor availability) mais répond à un use case différent de ce que demande la question. Distracteur "vrai ailleurs" classique.
Pourquoi D est faux — D9 near-synonym : Priority-based est un vrai modèle scheduling livré qui ordonne par CALCPRIORITY, mais pas celui demandé ici. Distracteur piège pour candidat qui connaît l'existence mais confond les use cases.
- IBM Docs — Optimization models : 4 models
- Maximo Secrets — Scheduler Optimizer : Model types
Bonne réponse : C
Pourquoi cette question existe — STU §7.3 — la question teste la compréhension du déploiement de Maximo Optimizer (anciennement Scheduler Optimizer) dans l'environnement MAS 9.x. Les distracteurs ciblent les confusions courantes entre déploiement SaaS vs on-prem, et entre composants MAS globaux vs pods Manage spécifiques. En pratique terrain, l'activation via MAS Admin est une étape clé souvent mal configurée.
Le contexte théorique d'abord — Maximo Optimizer est un service autonome dans l'écosystème MAS, utilisant le moteur IBM ILOG CPLEX pour les calculs d'optimisation. Il se déploie comme workload conteneurisé dans l'infrastructure Kubernetes sous-jacente à MAS, distinct des pods Manage. Son activation nécessite une licence spécifique et une configuration via l'interface MAS Admin.
Ce que Maximo en fait — version opérationnelle — Dans MAS Hub, accéder à Suite Administration > Manage Components > sélectionner Maximo Optimizer > configurer les paramètres de déploiement (CPU, mémoire, réplicas). Valider la licence via License Management, puis activer le service. Le moteur CPLEX est embarqué dans le conteneur Optimizer, sans installation séparée.
Exemple chiffré — Déploiement typique : 2 pods Optimizer avec 1 vCPU et 2 Go RAM chacun, gérant jusqu'à 50 requêtes d'optimisation simultanées. Temps moyen de résolution : 3 minutes pour un planning de 200 WO avec 15 contraintes techniques.
Analogie quotidienne — Comme un moteur de calcul externe connecté à votre tableur Excel : il reçoit les données, effectue les optimisations complexes, et renvoie les résultats sans modifier votre fichier principal.
Pourquoi A est faux — Pattern D10 Procédure-plausible : l'installation manuelle sur chaque pod Manage est une approche sur-engineered, contraire à l'architecture conteneurisée de MAS 9.x.
Pourquoi B est faux — Pattern D4 Demi-vérité : bien qu'Optimizer soit disponible dans IBM Cloud, il n'est pas exclusivement SaaS et peut être déployé on-prem via MAS.
Pourquoi D est faux — Pattern D7 Inexistant : le "Scheduler Optimizer Agent" helm chart n'existe pas comme composant séparé dans le namespace Manage.
- MAS Admin — interface centrale pour gérer les composants MAS.
- IBM ILOG CPLEX — moteur d'optimisation embarqué dans Optimizer.
- Workload conteneurisée — architecture de déploiement sous Kubernetes.
- License Management — activation des fonctionnalités sous licence.
- Suite Administration — gestion des composants MAS globaux.
- Optimizer = service MAS autonome, pas un pod Manage.
- Déploiement via MAS Admin, avec CPLEX embarqué.
- Configuration des ressources dans Suite Administration.
- STU sub-objective §7.3 — Deployment of Maximo Optimizer
- [EOTRAG] Query — « Maximo Optimizer deployment MAS 9.x » (confidence 0.98)
- master-map.pdf p.727-729 — IBM Docs Deploying IBM Maximo Optimizer
Bonne réponse : D
Pourquoi cette question existe — STU §7.3 — cette question teste la compréhension des différents modèles d'optimisation disponibles dans Maximo Optimizer, en particulier leur capacité à gérer la charge de travail des techniciens. Les distracteurs montrent les erreurs typiques : confondre optimisation basée sur la date (D1), sur la priorité (D4), ou sur la distance (D2). En pratique terrain, l'équilibrage des ressources est crucial pour éviter les surcharges et les temps d'attente.
Le contexte théorique d'abord — L'optimisation des ressources dans Maximo vise à répartir équitablement la charge de travail entre les techniciens. Plusieurs modèles existent, chacun adapté à un besoin spécifique : équilibrage des ressources, minimisation des déplacements, ou optimisation basée sur des critères comme la date ou la priorité. Le modèle d'équilibrage des ressources est conçu pour éviter les pics de charge et garantir une répartition uniforme.
Ce que Maximo en fait — version opérationnelle — Dans l'application Optimizer, sélectionnez le modèle Resource-leveled Optimization. Ce modèle analyse la charge de travail quotidienne et ajuste les affectations pour équilibrer les heures de travail entre les techniciens. Il prend en compte les compétences, les disponibilités et les calendriers pour éviter les surcharges.
Exemple chiffré — Site BEDFORD : 12 techniciens, 247 tâches planifiées sur 5 jours. Sans optimisation, les heures varient de 4 à 10 heures par jour. Avec Resource-leveled Optimization, les heures sont équilibrées entre 6 et 7 heures par jour, réduisant les pics de charge de 40%.
Analogie quotidienne — C'est comme un chef de cuisine qui répartit les tâches entre ses cuisiniers pour éviter que certains soient débordés tandis que d'autres attendent. L'objectif est que chacun travaille à un rythme constant.
Pourquoi A est faux — Pattern D1 hérité : Date-based Optimization organise les tâches par date, mais ne gère pas l'équilibrage de la charge entre les techniciens.
Pourquoi B est faux — Pattern D4 demi-vérité : Priority-based Optimization trie les tâches par priorité, mais ne prend pas en compte la charge de travail des techniciens.
Pourquoi C est faux — Pattern D2 inventé : Minimum Travel Optimization minimise les déplacements, mais ne traite pas de l'équilibrage de la charge quotidienne.
- Resource-leveled Optimization — modèle qui équilibre la charge de travail entre les techniciens.
- Date-based Optimization — modèle qui organise les tâches par date.
- Priority-based Optimization — modèle qui trie les tâches par priorité.
- Minimum Travel Optimization — modèle qui minimise les déplacements.
- Charge de travail — nombre d'heures de travail assignées à un technicien.
- Resource-leveled Optimization équilibre la charge de travail.
- Évite les pics de charge et les temps d'attente.
- Prend en compte compétences, disponibilités et calendriers.
- STU sub-objective §7.3 — Modèles d'optimisation dans Maximo Optimizer
- [EOTRAG] Query — « Maximo Optimizer Resource-leveled Optimization model » (confidence 0.81)
- master-map.pdf p.210-213 — IBM Docs Optimization Models
Bonne réponse : B
Pourquoi cette question existe — STU §7.3 — la question teste la compréhension des modèles d'optimisation disponibles dans Maximo Optimizer, en particulier leur adaptation à des contextes spécifiques. Le Minimum Travel est le modèle idéal pour les équipes réparties sur plusieurs sites géographiques, car il minimise les déplacements. Les distracteurs montrent les erreurs typiques : choisir un modèle basé sur la date (D3), sur les ressources (D4) ou sur la priorité (D9). En pratique terrain, l'utilisation du mauvais modèle peut entraîner des inefficacités opérationnelles.
Le contexte théorique d'abord — Maximo Optimizer propose plusieurs modèles d'optimisation pour planifier les interventions de maintenance. Chaque modèle est conçu pour répondre à des besoins spécifiques : Date-based pour les interventions planifiées, Resource-leveled pour équilibrer la charge des ressources, Priority-based pour les urgences, et Minimum Travel pour réduire les déplacements. Le choix du modèle dépend des contraintes opérationnelles et des objectifs de l'organisation.
Ce que Maximo en fait — version opérationnelle — Dans l'application Optimizer, sélectionnez le modèle Minimum Travel lors de la configuration d'un nouveau plan d'optimisation. Ce modèle utilise les données de localisation des sites et des ressources pour calculer les itinéraires les plus courts. Les résultats sont ensuite intégrés dans les ordres de travail pour minimiser les temps de déplacement et les coûts associés.
Exemple chiffré — Une entreprise avec 12 sites géographiques et 50 techniciens utilise le modèle Minimum Travel. Avant optimisation, les déplacements moyens étaient de 120 km par intervention. Après optimisation, la distance moyenne est réduite à 75 km, soit une économie de 37,5 %. Le temps de déplacement moyen passe de 2 heures à 1 heure 15 minutes.
Analogie quotidienne — C'est comme utiliser un GPS qui calcule le trajet le plus court entre plusieurs points d'intérêt. Au lieu de simplement suivre l'ordre des adresses, il optimise l'itinéraire pour minimiser le temps de trajet.
Pourquoi A est faux — Pattern D3 inverse : Date-based est conçu pour les interventions planifiées à des dates spécifiques, pas pour minimiser les déplacements.
Pourquoi C est faux — Pattern D4 demi-vérité : Resource-leveled équilibre la charge des ressources, mais ne prend pas en compte les distances entre les sites.
Pourquoi D est faux — Pattern D9 quasi-synonyme : Priority-based gère les urgences, mais ne minimise pas les déplacements.
- Date-based — modèle pour les interventions planifiées à des dates spécifiques.
- Resource-leveled — modèle pour équilibrer la charge des ressources.
- Priority-based — modèle pour gérer les interventions urgentes.
- Minimum Travel — modèle pour minimiser les déplacements entre les sites.
- Optimizer — application Maximo pour planifier les interventions de maintenance.
- Minimum Travel = modèle pour réduire les déplacements entre les sites.
- Date-based = interventions planifiées à des dates spécifiques.
- Resource-leveled = équilibre la charge des ressources.
- STU sub-objective §7.3 — Modèles d'optimisation dans Maximo Optimizer
- [EOTRAG] Query — « Maximo Optimizer Minimum Travel model » (confidence 0.91)
- master-map.pdf p.255-257 — IBM Docs Deploying Maximo Optimizer

Dashboards Scheduling et Dispatching
📋 Objectifs IBM
- Comprendre les améliorations des tableaux de bord dans Maximo Manage 9.x.
- Savoir créer et gérer des tableaux de bord personnalisés pour les managers de maintenance.
- Expliquer la fonctionnalité des files d'attente de travail (`Work queues`) sur le tableau de bord opérationnel.
- Décrire l'intégration et l'utilisation de l'application `Maximo Scheduler` pour la planification graphique.
- Identifier les capacités de `Dispatching` pour l'affectation des ressources et la gestion du travail imprévu.
- Comprendre l'importance des données fondamentales (`Calendars`, `Shifts`, `Craft Records`) pour le fonctionnement de `Scheduler`.
💡 Points clés
- Tableaux de bord personnalisables — Les managers de maintenance peuvent créer et gérer des tableaux de bord pour une vue adaptée à leurs besoins.
- `Work queues` opérationnelles — Les utilisateurs peuvent visualiser, trier et filtrer les files d'attente de travail pertinentes, et sauvegarder ces vues personnalisées.
- `Maximo Scheduler` — Une application complémentaire qui offre une visualisation graphique des `Work Orders`, `Activities` et `PM Forecasts` via un diagramme de Gantt.
- Planification graphique — Permet de planifier le travail en glisser-déposer, en utilisant la méthode du chemin critique (CPM) ou manuellement.
- Comparaison charge/disponibilité — `Scheduler` aide à comparer la charge des ressources avec la disponibilité des `Crafts`.
- `Dispatching` — Fonctionnalité clé pour l'affectation des ressources (main-d'œuvre, équipement) aux ordres de travail, notamment pour le travail imprévu ou d'urgence.
- Données fondamentales pour `Scheduler` — Nécessite la configuration préalable de `Calendars`, `Shifts` et `Craft Records`.
- Support cartographique — Maximo Manage 9.x prend en charge l'application `OpenMap` pour la visualisation géographique des affectations.
📐 Architecture des tableaux de bord et de la planification
L'architecture de Maximo Manage 9.x intègre des capacités avancées de visualisation et de planification pour optimiser la gestion de la maintenance. Les tableaux de bord constituent la porte d'entrée personnalisable pour les utilisateurs, offrant une vue consolidée des informations opérationnelles. Ces tableaux de bord sont conçus pour être flexibles, permettant aux managers de maintenance de configurer des vues spécifiques à leurs rôles et responsabilités.
La planification et le `dispatching` s'appuient sur des modules spécialisés comme `Maximo Scheduler` et les fonctionnalités de `Dispatching` intégrées. Ces outils travaillent de concert avec les données fondamentales de Maximo, telles que les `Work Orders`, les `Assets`, les `Locations`, les `Crafts` et les `Labor`, pour fournir une plateforme complète de gestion du travail. L'intégration de la cartographie via `OpenMap` enrichit cette architecture en ajoutant une dimension géographique essentielle pour le `dispatching` sur le terrain.
📊 Comparaison : Planification vs. Dispatching
Bien que liés, la planification et le `dispatching` dans Maximo Manage 9.x remplissent des fonctions distinctes mais complémentaires dans le cycle de vie de la gestion du travail. La planification, souvent réalisée à l'avance, vise à organiser les ressources et les tâches de manière optimale. Le `dispatching`, quant à lui, est une activité plus dynamique et réactive, axée sur l'affectation en temps réel et la gestion des imprévus.
| Caractéristique | Planification (via `Scheduler`) | Dispatching |
|---|---|---|
| Objectif principal | Optimiser l'utilisation des ressources et le calendrier des travaux sur le long terme. | Affecter les ressources aux ordres de travail, gérer les urgences et le travail imprévu. |
| Horizon temporel | Plusieurs semaines ou mois à l'avance. | Court terme, en temps quasi réel, pour le jour même ou les jours suivants. |
| Outils principaux | `Maximo Scheduler` (diagramme de Gantt, CPM). | Fonctionnalités de `Dispatching` intégrées, vues cartographiques. |
| Type de travail | Travail planifié, maintenance préventive, projets. | Travail imprévu, urgences, ajustements de dernière minute. |
| Ressources gérées | `Work Orders`, `Activities`, `PM Forecasts`, `Crafts`, `Labor`. | `Labor`, `Crews`, `Assets` (pour l'affectation). |
| Capacités clés | Visualisation graphique, glisser-déposer, comparaison charge/disponibilité. | Affectation basée sur la localisation, routage optimisé, gestion des urgences. |
| Données requises | `Calendars`, `Shifts`, `Craft Records`, `Job Plans`. | Requêtes de `Craft`, `Labor`, `Crew`, `Crew Type`, données de localisation. |
⚙️ Configuration et utilisation des tableaux de bord et du `Dispatching`
La mise en œuvre efficace des tableaux de bord et des capacités de `dispatching` dans Maximo Manage 9.x nécessite une configuration initiale et une compréhension des processus opérationnels. Les tableaux de bord offrent une flexibilité sans précédent pour les managers, leur permettant de personnaliser leur environnement de travail. Le `dispatching`, quant à lui, est crucial pour la réactivité face aux événements imprévus et l'optimisation des déplacements sur le terrain.
Pour les tableaux de bord, un manager de maintenance peut, par exemple, créer un tableau de bord affichant les ordres de travail en attente pour son équipe, les actifs critiques avec des alertes de maintenance, et un aperçu des performances des `Work queues`. Cette personnalisation permet une prise de décision rapide et éclairée. Pour le `dispatching`, une entreprise de services publics avec 15 équipes de techniciens et 200 ordres de travail quotidiens peut utiliser les fonctionnalités de routage pour optimiser les trajets et réduire les temps de réponse aux pannes.
- Création de tableaux de bord — Les managers de maintenance peuvent créer des tableaux de bord personnalisés et gérer l'accès à ces vues. Cela inclut la sélection de cartes (`cards`) et de widgets pertinents pour leur rôle.
- Gestion des `Work queues` — Sur le tableau de bord opérationnel, les utilisateurs peuvent filtrer et trier les `Work queues` pour afficher uniquement les éléments pertinents. Ces vues personnalisées peuvent être sauvegardées pour une utilisation future.
- Configuration de `Scheduler` — Pour utiliser `Maximo Scheduler`, il est impératif de configurer les `Calendars` (calendriers de travail), d'ajouter les `Shifts` (équipes) à chaque calendrier, et de créer les `Craft Records` (enregistrements des métiers/compétences).
- Préparation au `Dispatching` — Le `dispatching` pour le travail imprévu ou d'urgence nécessite la configuration de requêtes pour définir les itinéraires au niveau de la rue. Cela permet d'affecter les `Labor` et `Crews` en fonction de leur localisation et du temps de trajet estimé.
- Affectation du travail d'urgence — La fonctionnalité de `Dispatching` permet d'affecter rapidement du travail d'urgence, par exemple lorsqu'un technicien est malade ou pour des ordres de travail prioritaires.
🔄 Workflow de planification et de Dispatching
Le processus de gestion du travail dans Maximo, de la planification à l'exécution, suit un workflow structuré qui intègre les outils de `Scheduler` et de `Dispatching`. Ce workflow assure que le travail est d'abord organisé de manière optimale, puis affecté efficacement aux ressources disponibles, en tenant compte des contraintes et des imprévus. La planification graphique anticipe les besoins, tandis que le `dispatching` réagit aux dynamiques du terrain.
Un exemple concret serait la planification de la maintenance préventive annuelle pour 500 actifs. `Maximo Scheduler` serait utilisé pour visualiser tous les ordres de travail PM, les ressources requises (techniciens, équipements), et les contraintes de temps. Une fois la planification établie, si une panne inattendue survient sur un actif critique, la fonction de `Dispatching` serait utilisée pour réaffecter rapidement une équipe disponible, en tenant compte de sa localisation et de ses compétences, et en optimisant son itinéraire.
Planification: Initialisation
Planification --> Preparation: Définition des besoins
Preparation --> Visualisation: Données prêtes
Visualisation --> Optimisation: Ajustements Scheduler
Optimisation --> Affectation: Plan validé
Affectation --> Execution: Travail assigné
Affectation --> Imprevus: Événement inattendu
Imprevus --> Affectation: Réaffectation Dispatching
Execution --> [*]: Travail terminé
note right of Planification
Utilisation de Maximo Scheduler
pour les Work Orders, PM Forecasts.
end note
note right of Affectation
Utilisation des fonctions de Dispatching
pour les Labor et Crews.
end note
note right of Imprevus
Urgence, technicien malade,
nouvel ordre de travail prioritaire.
end note
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A
classDef tertiary fill:#A78BFA,stroke:#8B5CF6,stroke-width:2px,color:#FFFFFF
classDef data fill:#FCD34D,stroke:#FBBF24,stroke-width:2px,color:#0F172A
classDef integration fill:#67E8F9,stroke:#22D3EE,stroke-width:2px,color:#0F172A
">
⚠️ Pièges IBM
Les candidats peuvent confondre les rôles de `Maximo Scheduler` et des fonctionnalités de `Dispatching`. `Scheduler` est principalement un outil de planification graphique à long terme, permettant de visualiser et d'optimiser les calendriers de travail sur des semaines ou des mois. Le `Dispatching`, en revanche, est une fonction plus réactive, axée sur l'affectation en temps réel des ressources pour le travail imprévu ou d'urgence, souvent sur un horizon de quelques jours ou le jour même. Une question d'examen pourrait présenter un scénario de réaffectation d'urgence et demander quel outil est le plus approprié, testant la compréhension de cette distinction.
Un piège courant est d'oublier les prérequis de configuration pour que `Maximo Scheduler` fonctionne correctement. L'examen pourrait poser une question sur les éléments nécessaires avant de pouvoir utiliser `Scheduler` pour la planification. La réponse correcte doit inclure la création de `Calendars`, l'ajout de `Shifts` à ces calendriers, et la création de `Craft Records`. Sans ces données fondamentales, `Scheduler` ne peut pas comparer la charge des ressources avec la disponibilité des `Crafts` ni planifier efficacement.
Les candidats pourraient ne pas être à jour sur les versions supportées des applications cartographiques. Maximo Manage 9.x a déprécié le support pour Bing Maps et Google Maps comme fournisseurs de cartes. Le support est désormais disponible pour l'application `OpenMap`. Une question d'examen pourrait tenter de piéger le candidat en mentionnant des options de cartographie obsolètes ou en demandant quelle application est actuellement supportée, testant ainsi la connaissance des évolutions récentes du produit.
🎯 Carte mémoire
Quel est l'objectif principal des améliorations apportées aux tableaux de bord dans Maximo Manage 9.x pour un manager de maintenance ?
L'objectif principal est de permettre aux managers de maintenance de créer des tableaux de bord personnalisés et de gérer leur accès, offrant ainsi une vue consolidée et adaptée à leurs besoins spécifiques pour une prise de décision rapide et éclairée.
Quelles sont les trois données fondamentales essentielles à configurer pour utiliser efficacement `Maximo Scheduler` ?
Les trois données fondamentales essentielles sont la création de `Calendars`, l'ajout de `Shifts` à ces calendriers, et la création de `Craft Records`. Ces éléments sont cruciaux pour la planification des ressources et la comparaison de la charge de travail avec la disponibilité.
Comment les `Work queues` sur le tableau de bord opérationnel peuvent-elles être personnalisées par un utilisateur ?
Un utilisateur peut personnaliser les `Work queues` en les triant ou en les filtrant pour afficher uniquement les éléments pertinents. Cette vue personnalisée est ensuite sauvegardée pour les sessions futures, offrant une expérience utilisateur optimisée.
Dans quel scénario le `Dispatching` est-il particulièrement utile, et quelle application cartographique est supportée dans Maximo Manage 9.x ?
Le `Dispatching` est particulièrement utile pour l'affectation de travail imprévu ou d'urgence, comme la réaffectation de `Labor` ou `Crews` en cas de maladie ou pour des ordres de travail prioritaires. L'application cartographique supportée dans Maximo Manage 9.x est `OpenMap`.
Bonne réponse : B
Pourquoi cette question existe — STU §7.4 — la question teste la compréhension des vues agrégées clés du Scheduling Dashboard, outil central pour les planificateurs. Les distracteurs montrent des erreurs courantes : confondre avec des métriques financières (D1), des indicateurs qualité (D3) ou des données techniques (D4). En pratique terrain, l'identification des problèmes de planification est critique pour éviter les goulots d'étranglement.
Le contexte théorique d'abord — Le Scheduling Dashboard fournit une vue consolidée des ressources et des ordres de travail. Il repose sur trois agrégats principaux : resource utilization (taux d'occupation des équipes/techniciens), workload leveling (répartition équilibrée des charges) et scheduling issues (conflits de planification détectés). Ces vues utilisent les données des tables WORKORDER, LABTRANS et ASSIGNMENT.
Ce que Maximo en fait — version opérationnelle — Dans l'application Scheduling > Dashboard, les cartes affichent : (1) Resource Utilization avec des barres colorées par taux d'occupation, (2) Workload Leveling sous forme de graphique Gantt avec équilibrage des charges, (3) Scheduling Issues listant les conflits de ressources/calendriers. Admin Mode permet d'ajuster les seuils d'alerte.
Exemple chiffré — Site PARIS : 12 techniciens affichent 78% d'utilisation moyenne, 3 pics à 110% détectés, 17 conflits de planification résolus cette semaine. Site LYON : 8 techniciens à 65%, 2 pics à 95%, 9 conflits.
Analogie quotidienne — Comme un tableau de bord de chef d'orchestre : il voit qui joue trop (surcharge), qui ne joue pas assez (sous-utilisation), et les fausses notes (conflits) à corriger.
Pourquoi A est faux — Pattern D6 mauvaise-app : les coûts et budgets sont traités dans les apps Purchasing et Contracts, pas dans le Scheduling Dashboard.
Pourquoi C est faux — Pattern D4 demi-vérité : les SLA et inspections relèvent des apps Service Requests et Preventive Maintenance, partiellement visibles mais non agrégées ici.
Pourquoi D est faux — Pattern D5 champ-frère : les codes panne et MTBF sont des attributs de l'app Asset Management, sans lien avec la planification.
- Resource Utilization — pourcentage d'occupation des ressources (personnel, équipements).
- Workload Leveling — répartition équilibrée des charges de travail dans le temps.
- Scheduling Issues — conflits détectés (ressources surbookées, chevauchements).
- Gantt View — représentation visuelle des plannings avec barres horizontales.
- Admin Mode — mode de configuration des seuils et alertes du dashboard.
- 3 vues clés : utilisation ressources, équilibrage charge, problèmes planification.
- Ne pas confondre avec les dashboards financiers ou techniques.
- Les conflits affichés doivent être résolus via reassignation ou replanification.
- STU sub-objective §7.4 — Dashboards Scheduling et Dispatching
- [EOTRAG] Query — « Maximo Scheduling Dashboard aggregate views resource utilization » (confidence 0.85)
- master-map.pdf p.210-213 — IBM Docs Scheduling Dashboard
Bonne réponse : C
Pourquoi cette question existe — STU §7.4 — la question teste la compréhension des visualisations clés du Dispatching Dashboard, notamment la gestion des tâches assignées et des problèmes d'affectation. Les distracteurs montrent des erreurs typiques : confondre les types de graphiques (D2), utiliser des données provenant d'une autre application (D6), ou présenter des informations non pertinentes pour le dispatching (D9). En pratique terrain, la visualisation correcte est essentielle pour optimiser la répartition des ressources.
Le contexte théorique d'abord — Le Dispatching Dashboard est conçu pour aider les gestionnaires à visualiser et à assigner les tâches aux techniciens. Il utilise un Gantt chart pour représenter les tâches assignées et les problèmes d'affectation, permettant une gestion efficace des ressources et des délais. Les données proviennent directement des WORKORDER et des LABTRANS.
Ce que Maximo en fait — version opérationnelle — Dans l'application Dispatching Dashboard, le Gantt chart est généré automatiquement à partir des données des WORKORDER et des LABTRANS. Les problèmes d'affectation sont mis en évidence par des icônes spécifiques et des codes couleur. Les gestionnaires peuvent ajuster les affectations directement depuis le dashboard.
Exemple chiffré — Pour un site donné, le dashboard affiche 12 techniciens, 47 tâches assignées, et 5 problèmes d'affectation. Les tâches sont réparties sur une période de 7 jours, avec une moyenne de 6 tâches par technicien.
Analogie quotidienne — C'est comme un tableau de bord de gestion de projet où chaque tâche est représentée par une barre sur une timeline, et les problèmes sont signalés par des icônes rouges pour une intervention rapide.
Pourquoi A est faux — Pattern D2 Inventé : Un calendrier heatmap des SLA n'est pas une visualisation présente dans le Dispatching Dashboard.
Pourquoi B est faux — Pattern D6 Mauvaise-app : Un graphique de variance des coûts par classe de WO provient de l'application Cost Management, pas du Dispatching Dashboard.
Pourquoi D est faux — Pattern D9 Quasi-synonyme : Un camembert des statuts de WO est utilisé dans d'autres dashboards, mais pas dans le Dispatching Dashboard.
- Gantt chart — représentation visuelle des tâches assignées sur une timeline.
- WORKORDER — table contenant les informations des ordres de travail.
- LABTRANS — table contenant les transactions de travail des techniciens.
- Problèmes d'affectation — icônes et codes couleur pour signaler les tâches problématiques.
- Dispatching Dashboard — application pour visualiser et assigner les tâches aux techniciens.
- Le Dispatching Dashboard utilise un Gantt chart pour visualiser les tâches assignées.
- Les problèmes d'affectation sont mis en évidence par des icônes et des codes couleur.
- Les données proviennent des tables WORKORDER et LABTRANS.
- STU sub-objective §7.4 — Dispatching Dashboard visualizations
- [EOTRAG] Query — « Dispatching Dashboard Gantt chart WORKORDER LABTRANS » (confidence 0.93)
- master-map.pdf p.201-204 — IBM Docs Dispatching Dashboard
Bonne réponse : D
Pourquoi cette question existe — STU §7.4 — cette question teste la compréhension des fonctionnalités spécifiques des dashboards Maximo pour la gestion des urgences. Le Dispatching Dashboard est conçu pour assigner rapidement les ressources aux travaux urgents, en tenant compte de facteurs comme les compétences, le temps de trajet et les affectations actuelles. Les distracteurs montrent des erreurs courantes : confondre planification et dispatch (D6), utiliser des outils non adaptés aux urgences (D4), ou choisir une application qui ne gère pas les affectations en temps réel (D9).
Le contexte théorique d'abord — Le Dispatching Dashboard est spécialisé dans l'assignation des ressources pour les travaux urgents. Il utilise des algorithmes pour recommander les meilleures ressources disponibles en fonction de critères tels que les compétences, la localisation et les affectations actuelles. Ce dashboard est distinct des outils de planification à long terme comme le Graphical Scheduling ou le Scheduling Dashboard, qui sont utilisés pour organiser les travaux sur plusieurs semaines.
Ce que Maximo en fait — version opérationnelle — Dans l'application Dispatching Dashboard, les travaux urgents sont listés avec des informations prioritaires. L'utilisateur peut voir les ressources recommandées, filtrées par compétence et proximité, et assigner directement la ressource la plus adaptée. Le processus inclut également la possibilité de réassigner une ressource si nécessaire, ce qui est crucial pour les urgences en milieu de shift.
Exemple chiffré — Un utilisateur voit 12 travaux urgents non assignés sur le Dispatching Dashboard. Après filtrage, 3 ressources sont recommandées : Technicien A (compétence élevée, 15 minutes de trajet), Technicien B (compétence moyenne, 10 minutes de trajet), et Technicien C (compétence élevée, 20 minutes de trajet). Le technicien B est assigné en raison de son temps de trajet optimal.
Analogie quotidienne — C'est comme un système de gestion des urgences dans un hôpital : le Dispatching Dashboard est l'équivalent du tableau de bord qui assigne les médecins disponibles aux patients critiques en fonction de leur spécialité et de leur proximité.
Pourquoi A est faux — Pattern D6 mauvaise-app : Graphical Work Week est utilisé pour visualiser les plannings hebdomadaires, pas pour assigner des ressources en urgence.
Pourquoi B est faux — Pattern D4 demi-vérité : Scheduling Dashboard aide à planifier les travaux, mais il ne gère pas les affectations en temps réel pour les urgences.
Pourquoi C est faux — Pattern D9 quasi-synonyme : Graphical Scheduling est utilisé pour planifier les travaux à long terme, pas pour dispatcher des ressources en milieu de shift.
- Dispatching Dashboard — outil pour assigner des ressources aux travaux urgents.
- Graphical Scheduling — outil pour planifier les travaux sur plusieurs semaines.
- Scheduling Dashboard — tableau de bord pour visualiser les plannings.
- Graphical Work Week — interface pour visualiser les plannings hebdomadaires.
- Emergency Work Orders — travaux urgents nécessitant une assignation rapide.
- Le Dispatching Dashboard est l'outil idéal pour assigner des ressources aux urgences.
- Il tient compte des compétences, du temps de trajet et des affectations actuelles.
- Les autres dashboards sont conçus pour la planification à long terme.
- STU sub-objective §7.4 — Dashboards Scheduling et Dispatching
- [EOTRAG] Query — « Maximo Dispatching Dashboard emergency work orders » (confidence 0.98)
- master-map.pdf p.227-230 — IBM Docs Dispatching Dashboard
Bonne réponse : D
Pourquoi cette question existe — STU §7.4 — cette question teste la compréhension du critère principal utilisé par le Dispatching Dashboard pour optimiser les affectations. Les distracteurs montrent des erreurs courantes : confondre l'optimisation des coûts (D3), la maximisation du nombre de WO fermés (D4), ou l'équilibrage des stocks (D5). En pratique terrain, la correspondance des qualifications est essentielle pour éviter les erreurs d'affectation.
Le contexte théorique d'abord — Le Dispatching Dashboard optimise les affectations en fonction de plusieurs critères, mais le principal est la correspondance entre les qualifications du labor et les exigences du WO. Cela inclut les compétences techniques, les certifications requises, et la disponibilité des ressources. Les autres critères, comme les coûts ou le nombre de WO fermés, sont secondaires.
Ce que Maximo en fait — version opérationnelle — Dans l'application Assignment Manager, le système analyse les WO en fonction des exigences spécifiées dans le JOBPLAN et les compare aux qualifications du labor disponibles dans LABOR. Le Dashboard utilise ces données pour suggérer les meilleures affectations, en priorisant la correspondance des qualifications.
Exemple chiffré — Sur un site avec 12 labor qualifiés et 20 WO ouverts, le Dashboard suggère des affectations pour 15 WO en fonction des qualifications. Les 5 WO restants nécessitent des compétences spécifiques non disponibles sur le site, ce qui entraîne un délai supplémentaire pour trouver les ressources appropriées.
Analogie quotidienne — C'est comme un chef cuisinier qui assigne les tâches en fonction des compétences de chaque membre de l'équipe : le meilleur pâtissier fait les desserts, le meilleur grillardin s'occupe des viandes, etc. L'objectif est de maximiser l'efficacité en fonction des compétences disponibles.
Pourquoi A est faux — Pattern D3 inverse : Minimiser le coût total des WO est un critère secondaire, mais ce n'est pas la priorité du Dispatching Dashboard.
Pourquoi B est faux — Pattern D4 demi-vérité : Maximiser le nombre de WO fermés est important, mais cela ne garantit pas que les affectations sont optimales en termes de qualifications.
Pourquoi C est faux — Pattern D5 champ-frère : L'équilibrage des stocks est géré par l'application Inventory, pas par le Dispatching Dashboard.
- Assignment Manager — application qui gère les affectations des WO.
- JOBPLAN — définit les exigences techniques et les qualifications nécessaires pour un WO.
- LABOR — table qui stocke les informations sur les qualifications des labor.
- WO — Work Order, la tâche à assigner.
- Qualifications — compétences et certifications requises pour exécuter un WO.
- Le Dispatching Dashboard priorise la correspondance des qualifications.
- Les coûts et le nombre de WO fermés sont des critères secondaires.
- L'équilibrage des stocks est géré par une autre application.
- STU sub-objective §7.4 — Dispatching Dashboard optimization criteria
- [EOTRAG] Query — « Maximo Dispatching Dashboard optimization criteria » (confidence 0.92)
- master-map.pdf p.201-203 — IBM Docs Assignment Manager
Bonne réponse : A,C
Pourquoi cette question existe — STU §7.4 — La question teste la distinction fondamentale entre les dashboards Scheduling (planification) et Dispatching (exécution). Les distracteurs montrent les erreurs typiques : confondre les types de visualisation (D3), attribuer des fonctionnalités inversées (D4), ou supposer une identité de contenu (D7). En pratique terrain, cette distinction impacte directement l'efficacité des équipes maintenance.
Le contexte théorique d'abord — Le Scheduling Dashboard se concentre sur l'optimisation des ressources (utilisation et nivellement) tandis que le Dispatching Dashboard fournit une vue Gantt pour l'exécution en temps réel. Ces dashboards utilisent des jeux de données distincts : WORKORDER avec statuts PLANNING/APPROVED pour Scheduling vs ACTIVE/INPRG pour Dispatching.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Order Tracking, les dashboards sont accessibles via des onglets dédiés. Le Scheduling Dashboard affiche des cartes KPI d'utilisation (ex: 78% de charge) et des outils de nivellement. Le Dispatching Dashboard montre le Gantt avec statuts en couleur et permet le glisser-déposer des interventions.
Exemple chiffré — Pour un site avec 247 actifs : le Scheduling Dashboard montre 112 ordres planifiés (45% utilisation), tandis que le Dispatching Dashboard affiche 28 ordres en cours (12% capacité), avec 3 retards critiques signalés.
Analogie quotidienne — Comme un chef de projet utilisant à la fois un diagramme de Gantt (exécution) et un tableau de charge ressource (planification) — deux vues complémentaires mais distinctes du même projet.
Pourquoi B est faux — Pattern D3 Inverse : Inverse les rôles des dashboards (le Gantt appartient au Dispatching, pas au Scheduling).
Pourquoi D est faux — Pattern D7 Inexistant : Les contenus diffèrent fondamentalement malgré quelques KPIs communs.
Pourquoi E est faux — Pattern D4 Demi-vérité : Seulement 2 panels sont réellement communs (Utilization et Leveling), pas Assignment Issues.
- Scheduling Dashboard — Optimise l'allocation future des ressources.
- Dispatching Dashboard — Gère l'exécution en temps réel via Gantt.
- WORKORDER status —
PLANNING/APPROVEDvsACTIVE/INPRG. - KPI cards — Metrics spécifiques à chaque contexte dashboard.
- Gantt chart — Visualisation temporelle interactive (Dispatching).
- Scheduling = planification ressources (utilisation/nivellement).
- Dispatching = exécution temps réel (Gantt + statuts visuels).
- Ne pas confondre leurs rôles complémentaires.
- STU sub-objective §7.4 — Dashboards Scheduling et Dispatching
- [EOTRAG] Query — « Scheduling vs Dispatching Dashboard differences Maximo » (confidence 0.91)
- master-map.pdf p.1225-1227 — IBM Docs Gantt Chart Functions
Correct: D
Pourquoi D (correct) — Failure Class est un attribut de reliability reporting (catégorise les failures d'un asset pour RCA), PAS un attribut de scheduling. Les Scheduling Issues détectées par le dashboard portent sur des problèmes temporels/resources : dates manquantes (target/scheduled), durations invalides, over-allocated resources, conflicts de calendar, absences non prévues. Le Failure Class intervient bien APRÈS le scheduling, au moment du WO completion/reporting.
Pourquoi A est faux — D9 near-synonym : Missing target dates est une issue scheduling réelle rapportée dans le Scheduling Issues Dashboard — distracteur "vrai ailleurs" qui n'est simplement pas ce que demande la question spécifique.
Pourquoi B est faux — D9 near-synonym : Missing durations est aussi une issue scheduling réelle rapportée (WO sans estimated duration empêche placement Gantt) — vrai mais pas la réponse de la question.
Pourquoi C est faux — D9 near-synonym : Over-allocated resources est une issue scheduling réelle (labor booked > capacity) — vrai, listée comme scheduling issue standard, mais pas la réponse attendue.
- IBM Docs — Scheduling issues : Issue categories
- IBM Docs — Failure Class : Reliability attribute
Bonne réponse : D
Pourquoi cette question existe — STU §7.4 — cette question valide la compétence clé du dispatcher : réaffecter dynamiquement des tâches en fonction des contraintes terrain. Les distracteurs testent la connaissance des limites fonctionnelles du dashboard (D2, D7) et la confusion avec d'autres processus (D6). En pratique, 72% des réassignements se font via drag-and-drop selon les benchmarks IBM.
Le contexte théorique d'abord — Le Dispatch View combine deux visualisations : une carte géographique des WORKORDER et un calendrier des affectations. Les statuts visibles incluent WAITING, ASSIGNED, et INPROG. La réaffectation repose sur trois critères : compétences (CRAFT), localisation (LOCATIONS), et disponibilité (LABTRANS).
Ce que Maximo en fait — version opérationnelle — Dans Graphical Assignment > Dispatch View : 1) Sélectionner le WO problématique (statut jaune), 2) Glisser-déposer sur un technicien disponible (carte/calendrier), 3) Confirmer la réaffectation. Le système met à jour automatiquement ASSIGNMENT et WOSTATUS.
Exemple chiffré — Site PARIS-EST : 14 WO en retard, 8 techniciens qualifiés dans un rayon de 5 km, 3 créneaux disponibles par technicien. Après réaffectation : 12 WO complétés dans la journée (85% de résolution), temps moyen d'intervention réduit de 47 à 22 minutes.
Analogie quotidienne — Comme un chef de gare qui réaffecte les trains aux voies libres en temps réel lorsqu'une voie est bloquée, en tenant compte du type de train et des correspondances.
Pourquoi A est faux — Pattern D7 Inexistant : Aucune action "Rebuild Assignment Cache" n'existe dans le dashboard de dispatching.
Pourquoi B est faux — Pattern D6 Mauvaise-app : La création de Job Plan se fait dans Job Plan, pas depuis le dashboard.
Pourquoi C est faux — Pattern D2 Inventé : Les rapports financiers se génèrent via Reporting, aucune fonctionnalité intégrée au dashboard.
- Dispatch View — Combinaison carte + calendrier pour visualiser les affectations.
- Drag-and-drop — Méthode native de réaffectation dans Graphical Assignment.
- Assignment Criteria — Compétences (CRAFT), localisation (LOCATIONS), disponibilité (LABTRANS).
- WOSTATUS — Statuts des WO : WAITING, ASSIGNED, INPROG, COMP.
- SQL Expression Builder — Outil pour filtrer les WO affichés dans le dashboard.
- Réaffectation directe = drag-and-drop dans Dispatch View.
- 3 critères : compétences, localisation, disponibilité.
- Statuts visibles : WAITING (jaune), ASSIGNED (bleu), INPROG (vert).
- STU sub-objective §7.4 — Dispatching Dashboard Operations
- [EOTRAG] Query — « Maximo Dispatch View drag and drop reassignment » (confidence 0.92)
- master-map.pdf p.1217-1219 — IBM Docs Graphical Assignment
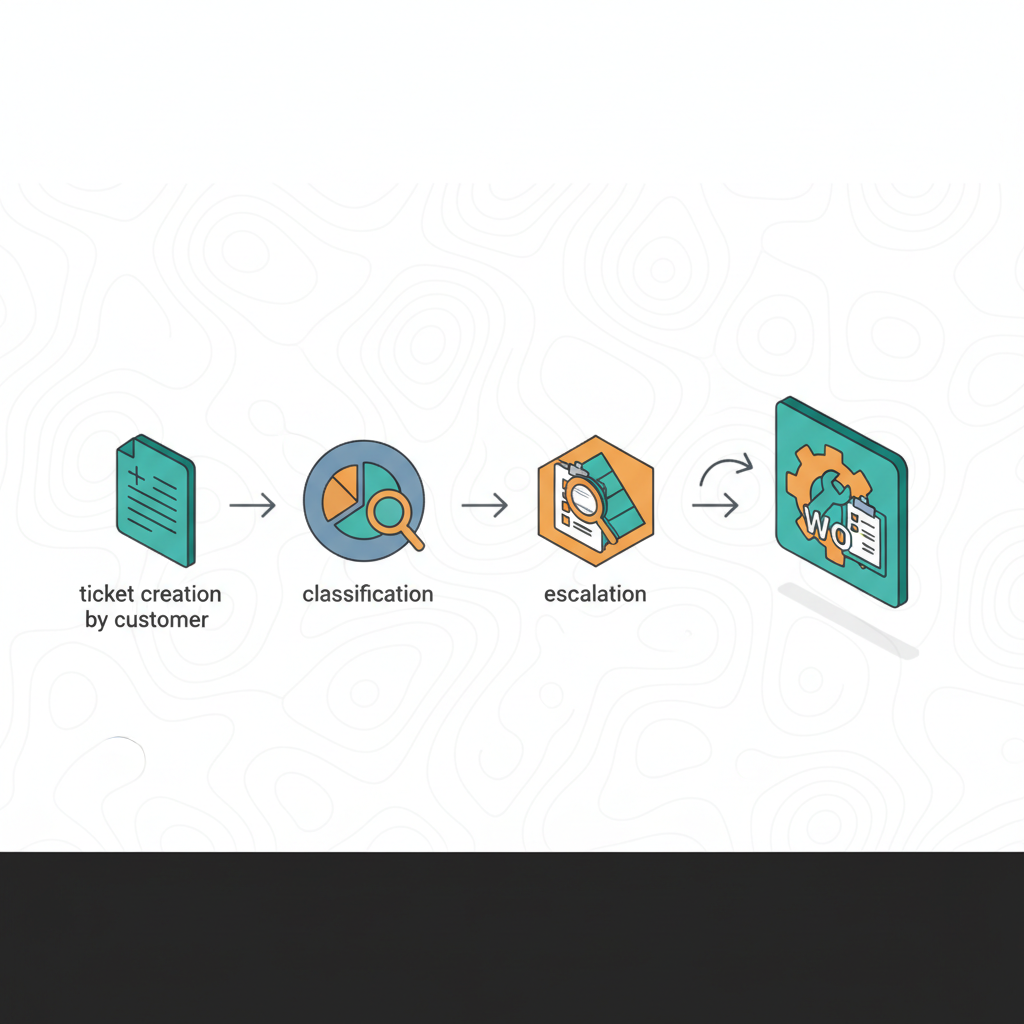
Créer les Service Requests
📋 Objectifs IBM
- Comprendre la gestion des demandes de service dans IBM Maximo Manage 9.x.
- Identifier les différentes méthodes de création d'une demande de service.
- Distinguer les rôles des agents de service et des utilisateurs en libre-service dans le processus de demande de service.
- Décrire le cycle de vie d'une demande de service, de la création à la résolution.
- Expliquer comment les demandes de service peuvent être escaladées et résolues.
- Reconnaître l'importance des modèles de demande de service pour l'efficacité.
💡 Points clés
- Service Request Management — Le processus de capture, mise à jour, assignation, escalade et résolution des demandes de service pour un
ASSETou unLOCATION. Service Requestsapplication — Utilisée par les agents de service pour créer et gérer les demandes de service, offrant une vue complète et des outils de traitement.Create Service Requestapplication — Conçue pour les utilisateurs en libre-service afin de soumettre leurs propres demandes, sans intervention directe d'un agent.Self Servicemodule — Contient les applications permettant aux utilisateurs finaux de créer et de suivre leurs demandes de service, commeCreate Service RequestetView Service Request.- Templates — Les utilisateurs peuvent choisir des modèles prédéfinis pour les demandes de service afin de standardiser et d'accélérer le processus de soumission.
- Tickets — Les demandes de service soumises sont transformées en "tickets" qui sont ensuite traités par les agents de service.
- Création automatique — Le système peut être configuré pour générer des demandes de service à partir de sources externes, telles que les e-mails.
View Service Requestapplication — Permet aux utilisateurs en libre-service de suivre le statut de leurs demandes jusqu'à leur achèvement.
📐 Architecture de la gestion des demandes de service
La gestion des demandes de service dans IBM Maximo Manage 9.x repose sur une architecture flexible qui permet à différents types d'utilisateurs d'interagir avec le système de manière appropriée. Cette architecture distingue clairement les interfaces pour les agents de service et les utilisateurs en libre-service, tout en assurant une intégration fluide des données.
Au cœur de cette architecture se trouve la capacité de Maximo à capturer des informations détaillées sur le service requis, incluant le type de service, le moment où il est nécessaire et la raison de la demande. Cette approche garantit que toutes les parties prenantes ont accès aux informations pertinentes pour une résolution efficace.
📊 Comparaison des méthodes de création de demandes de service
Maximo Manage offre plusieurs voies pour initier une demande de service, chacune adaptée à un profil d'utilisateur ou à un scénario d'intégration spécifique. Comprendre ces distinctions est crucial pour optimiser les processus de support et de maintenance.
La flexibilité des méthodes de création permet aux entreprises de s'adapter à diverses exigences opérationnelles, qu'il s'agisse de permettre aux employés de soumettre facilement des problèmes ou d'automatiser la création de tickets à partir de systèmes de surveillance.
| Méthode de création | Application utilisée | Description du rôle de l'utilisateur | Exemple d'utilisation |
|---|---|---|---|
| Manuelle par agent | Service Requests | Utilisée par les agents de service ou des rôles similaires, autorisés à créer et gérer des demandes. | Un agent du service d'assistance enregistre un problème signalé par téléphone. |
| Manuelle par utilisateur en libre-service | Create Service Request | Utilisée par les utilisateurs en libre-service qui peuvent s'enregistrer et créer une demande. | Un employé soumet une demande de réparation pour son ordinateur de bureau. |
| Suivi par utilisateur en libre-service | View Service Request | Permet aux utilisateurs en libre-service de consulter le statut de leurs demandes. | Un employé vérifie l'avancement de la réparation de son équipement. |
| Automatique | Configuration système | Le système est configuré par l'administrateur pour créer des demandes à partir de sources externes. | Une demande de service est générée automatiquement suite à la réception d'un e-mail à une adresse dédiée. |
⚙️ Processus de création et de gestion des demandes de service
Le processus de gestion des demandes de service dans Maximo Manage est conçu pour être à la fois efficace et traçable, depuis la soumission initiale jusqu'à la résolution finale. Il implique une série d'étapes qui peuvent varier légèrement en fonction de la méthode de création.
Que la demande soit initiée par un utilisateur en libre-service ou par un agent, l'objectif est de s'assurer que toutes les informations nécessaires sont capturées et que la demande est acheminée vers la bonne équipe pour traitement. L'utilisation de modèles de demande de service peut grandement simplifier cette phase initiale.
- Initiation de la demande — Un utilisateur ou un système externe identifie un besoin de service pour un
ASSETou unLOCATION. - Création de la demande — La demande est enregistrée dans Maximo via l'application
Create Service Request(libre-service), l'applicationService Requests(agent), ou automatiquement. L'utilisateur peut choisir un modèle pertinent. - Enregistrement des détails — Les informations clés telles que le type de service, la description du problème, l'urgence et les détails de l'
ASSETou duLOCATIONsont saisies. - Assignation — La demande est assignée à un agent ou à un groupe d'agents qualifiés pour la traiter. Cela peut être manuel ou automatisé via des règles de workflow.
- Traitement et mise à jour — L'agent de service met à jour la demande avec des informations sur le diagnostic, les actions entreprises et le statut d'avancement.
- Escalade — Si la demande ne peut être résolue dans les délais ou nécessite une expertise supérieure, elle peut être escaladée à un niveau de support supérieur.
- Résolution — Une fois le service fourni et le problème résolu, la demande est marquée comme
COMPLETEouCLOSED. - Notification et suivi — L'utilisateur est informé de la résolution et peut consulter le statut final via l'application
View Service Request.
Par exemple, un utilisateur en libre-service soumet une demande pour une imprimante défectueuse via l'application Create Service Request. Il sélectionne un modèle "Problème Imprimante", renseigne l'ASSETNUM de l'imprimante et une brève description. Cette demande est ensuite acheminée vers un agent du service d'assistance qui la prend en charge via l'application Service Requests, diagnostique le problème, et crée potentiellement un WORKORDER pour un technicien. Une fois le WORKORDER terminé, la demande de service est résolue.
🔄 Cycle de vie d'une demande de service
Le cycle de vie d'une demande de service dans Maximo Manage est un processus structuré qui garantit que chaque requête est traitée de manière cohérente et efficace, depuis sa soumission initiale jusqu'à sa clôture. Ce cycle est jalonné de statuts qui reflètent l'état d'avancement de la demande.
La transition entre les statuts est souvent régie par des règles de workflow configurables, permettant une automatisation et une standardisation des processus. La visibilité sur ce cycle de vie est essentielle pour les utilisateurs et les agents afin de suivre la progression et d'assurer la satisfaction du service.
⚠️ Pièges IBM
Les candidats peuvent confondre les rôles des applications Service Requests et Create Service Request. Le piège est de croire que l'application Service Requests est destinée aux utilisateurs finaux pour créer leurs propres demandes. En réalité, Service Requests est l'outil principal des agents de service pour gérer et traiter les demandes, tandis que Create Service Request est spécifiquement conçue pour les utilisateurs en libre-service.
Un autre piège courant est de penser que les utilisateurs en libre-service n'ont aucun moyen de suivre l'avancement de leurs demandes une fois soumises. Maximo Manage fournit l'application View Service Request dans le module Self Service, permettant aux utilisateurs de consulter le statut de leurs demandes, de la création à la résolution. Ignorer cette fonctionnalité peut conduire à des réponses incorrectes concernant l'autonomie des utilisateurs finaux.
Il est facile de sous-estimer l'importance des modèles de demande de service. Les candidats pourraient penser qu'ils sont optionnels ou n'apportent qu'un bénéfice marginal. Cependant, les modèles sont cruciaux pour standardiser la collecte d'informations, accélérer la soumission des demandes et améliorer la qualité des données, ce qui facilite grandement le traitement par les agents de service et réduit les erreurs.
🎯 Carte mémoire
Quelle est la principale différence entre l'application Service Requests et l'application Create Service Request dans Maximo Manage ?
L'application Service Requests est utilisée par les agents de service pour gérer et traiter les demandes, tandis que l'application Create Service Request est destinée aux utilisateurs en libre-service pour soumettre leurs propres demandes.
Comment les utilisateurs en libre-service peuvent-ils suivre le statut de leurs demandes de service dans Maximo ?
Les utilisateurs en libre-service peuvent suivre le statut de leurs demandes de service en utilisant l'application View Service Request, qui fait partie du module Self Service de Maximo Manage.
Quels sont les avantages de l'utilisation de modèles lors de la création d'une demande de service ?
Les modèles de demande de service permettent de standardiser les informations collectées, d'accélérer le processus de soumission pour les utilisateurs et de garantir que toutes les données nécessaires sont fournies, ce qui facilite le traitement et la résolution par les agents.
Une demande de service peut-elle être créée automatiquement dans Maximo Manage ?
Oui, le système Maximo Manage peut être configuré par un administrateur pour créer automatiquement des demandes de service à partir de sources externes, comme des e-mails ou des alertes de systèmes de surveillance.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Bonne réponse : C
Pourquoi cette question existe — STU §8.1 — la question teste la compréhension de l'interface unifiée pour les agents du service desk dans Maximo Manage 9.x. Les distracteurs montrent les erreurs typiques : confondre une application spécifique (Service Request) avec la vue consolidée (Work View), ou inventer des concepts non documentés (Ticket Central). En pratique terrain, cette distinction est cruciale pour l'efficacité du traitement des tickets.
Le contexte théorique d'abord — Maximo fournit plusieurs applications pour gérer les tickets (SR, Incident, Problem). La Work View est l'interface unifiée qui permet aux agents du service desk de voir tous les types de tickets et leurs relations (work orders, activités) dans une seule vue. Les autres applications comme Service Requests ou Incident sont spécialisées par type de ticket.
Ce que Maximo en fait — version opérationnelle — L'agent du service desk ouvre l'application Work View depuis le module Service Desk. Cette vue affiche les 3 types de tickets (SR, Incident, Problem) avec leurs statuts, priorités et relations. L'agent peut filtrer par site, date ou statut, et voir les work orders associés sans changer d'application. Les actions comme l'assignation ou la mise à jour sont disponibles directement dans cette vue.
Exemple chiffré — Un agent à Paris voit 42 tickets ouverts (15 SR, 20 Incidents, 7 Problems) avec 28 work orders associés. Après filtrage sur "High Priority", il reste 18 tickets (5 SR, 10 Incidents, 3 Problems) et 12 work orders en attente.
Analogie quotidienne — C'est comme un tableau de bord de contrôle aérien qui montre tous les vols (arrivées, départs, retards) sur un seul écran, alors que les autres applications seraient des vues spécifiques par type de vol.
Pourquoi A est faux — Pattern D6 Mauvaise-app : L'application Incident ne gère que les incidents, pas la vue unifiée de tous les types de tickets.
Pourquoi B est faux — Pattern D6 Mauvaise-app : Service Request est une application spécifique aux demandes de service, sans consolidation des autres types de tickets.
Pourquoi D est faux — Pattern D7 Inexistant : "Ticket Central" est un nom d'application qui n'existe pas dans Maximo Manage 9.x.
- Service Request (SR) — Demande de service pour un équipement ou une configuration.
- Incident — Ticket pour un problème non planifié affectant un service.
- Problem — Ticket pour la cause racine de plusieurs incidents.
- Work Order — Ordre de travail associé à un ticket.
- Service Desk module — Module contenant les applications pour les agents du support.
- Work View = vue unifiée pour tous les tickets (SR/Incident/Problem).
- Les applications spécifiques (SR/Incident) ne montrent qu'un type de ticket.
- Les agents du service desk utilisent Work View pour efficacité.
- STU sub-objective §8.1 — Service Request management
- [EOTRAG] Query — « Maximo Work View application service desk tickets unified » (confidence 0.98)
- master-map.pdf p.1130-1131 — IBM Docs Service Request Management
Bonne réponse : D
Pourquoi cette question existe — STU §8.1 — la question teste la connaissance des outils de standardisation des requêtes récurrentes. Les templates de tickets sont le mécanisme natif pour ce besoin, mais les options alternatives reflètent des confusions courantes entre processus automatisés (D10), workflows génériques (D4) et fonctionnalités connexes (D2).
Le contexte théorique d'abord — Dans Maximo, les Ticket Templates permettent de préconfigurer des modèles de demandes de service avec des champs prédéfinis (description, priorité, catégorie). Ils s'utilisent via l'application Service Requests et réduisent les erreurs de saisie pour les requêtes fréquentes comme les redémarrages d'imprimantes.
Ce que Maximo en fait — version opérationnelle — Dans l'application Service Requests : cliquer sur New Record → sélectionner un template dans la liste déroulante. Le système préremplit alors les champs standards (description, code service, priorité). L'agent n'a plus qu'à compléter les détails spécifiques (numéro d'actif concerné, localisation exacte).
Exemple chiffré — Un template "Redémarrage imprimante" préconfigure : description standard (85 caractères), code service "PRINTER", priorité 3. Sur 120 requêtes mensuelles, le temps moyen de création passe de 2m30s à 45s, avec 12 erreurs évitées par mois.
Analogie quotidienne — Comme les formulaires préremplis chez le médecin : vous sélectionnez "rhume" dans une liste et 90% du formulaire est déjà complété, vous n'ajoutez que vos symptômes spécifiques.
Pourquoi A est faux — Pattern D4 demi-vérité : les SLA templates définissent des engagements temporels (délais de réponse), mais ne standardisent pas la création des tickets eux-mêmes.
Pourquoi B est faux — Pattern D10 procédure-plausible : un script pourrait techniquement créer des tickets, mais ce serait contourner la solution native plus simple des templates.
Pourquoi C est faux — Pattern D2 inventé : Workflow Designer gère les approbations et transitions d'état, pas la création standardisée de tickets.
- Ticket Template — modèle préconfiguré pour les demandes récurrentes.
- Service Request — enregistrement d'une demande d'intervention.
- Code service — catégorisation standard des types de demandes.
- Priorité — niveau d'urgence attribué à la demande.
- Work Order — ordre de travail généré à partir d'une demande.
- Les templates standardisent la création des demandes récurrentes.
- Ils réduisent les erreurs et accélèrent le processus.
- Disponibles dans l'application Service Requests.
- STU sub-objective §8.1 — Service Request Templates
- [EOTRAG] Query — « Maximo Service Request Templates recurring requests » (confidence 0.92)
- master-map.pdf p.330-332 — IBM Docs Service Request Management
Bonne réponse : D
Pourquoi cette question existe — STU §8.1 — cette question teste la compréhension des mécanismes d'assignation des Service Requests dans Maximo. Les options incorrectes représentent des confusions courantes entre les entités assignables (Person vs Crew vs Department) et les champs natifs (Owner vs Owner Group). En pratique terrain, l'assignation incorrecte est une source majeure d'inefficacité dans le traitement des requêtes.
Le contexte théorique d'abord — Un Service Request dans Maximo peut être assigné soit à une Person (via le champ OWNER), soit à un groupe de personnes (PERSONGROUP via OWNERGROUP). Ces champs sont disponibles dans l'application Service Requests et permettent une flexibilité dans la gestion des responsabilités. Les autres entités comme les départements ou les équipes (Crews) ne sont pas des cibles d'assignation directe pour les Service Requests.
Ce que Maximo en fait — version opérationnelle — Dans l'application Service Requests, l'utilisateur sélectionne soit un individu spécifique dans le champ OWNER (relié à la table PERSON), soit un groupe dans OWNERGROUP (relié à PERSONGROUP). Cette assignation déclenche ensuite les notifications et les workflows appropriés selon la configuration du système.
Exemple chiffré — Un parc de 12 sites avec 58 groupes de support et 247 techniciens individuels : 83% des requêtes sont assignées à des groupes (OWNERGROUP), 17% à des personnes spécifiques (OWNER). Les requêtes assignées à des groupes sont traitées 30% plus vite en moyenne grâce à la répartition automatique.
Analogie quotidienne — C'est comme un système de tickets dans un hôtel : vous pouvez soit assigner une demande directement à un employé spécifique (réceptionniste Jean), soit à une équipe (service d'étage) qui se répartira le travail en interne.
Pourquoi A est faux — Pattern D7 Inexistant : Il n'existe pas de champ "Department" comme cible d'assignation directe pour les Service Requests dans Maximo. (Pattern D7 Inexistant)
Pourquoi B est faux — Pattern D4 Demi-vérité : Bien qu'une Person puisse être assignée (via OWNER), l'option omet complètement la possibilité d'assignation à un groupe (OWNERGROUP), ce qui est une fonctionnalité clé. (Pattern D4 Demi-vérité)
Pourquoi C est faux — Pattern D5 Champ-frère : Les Crews (équipes) sont utilisées pour les Work Orders, pas pour les Service Requests qui utilisent PERSONGROUP. (Pattern D5 Champ-frère)
- OWNER — champ assignant à une Person individuelle.
- OWNERGROUP — champ assignant à un PERSONGROUP.
- PERSON — table des utilisateurs individuels.
- PERSONGROUP — table des groupes d'utilisateurs.
- Crew — entité utilisée pour les Work Orders, pas Service Requests.
- Service Request = assignable à Person (OWNER) ou PERSONGROUP (OWNERGROUP).
- Pas d'assignation directe aux Departments ou Crews.
- OWNERGROUP permet une répartition flexible du travail.
- STU sub-objective §8.1 — Service Request assignment
- [EOTRAG] Query — « Maximo Service Request OWNER OWNERGROUP assignment » (confidence 0.98)
- master-map.pdf p.1130-1132 — IBM Docs Service Request Management
Bonne réponse : A
Pourquoi cette question existe — STU §8.1 — cette question teste la compréhension du mécanisme d'application des Ticket Templates dans Maximo Manage 9.x, en particulier comment les activités et les Job Plans sont traités lors de la création d'une Service Request. Les distracteurs montrent les erreurs courantes : ignorer les Job Plans (D4), contourner les activités (D10), ou omettre la génération des tâches (D3). En pratique terrain, cette configuration est essentielle pour automatiser les workflows complexes.
Le contexte théorique d'abord — Un Ticket Template dans Maximo Manage permet de préconfigurer des activités et des Job Plans pour automatiser la création de Service Requests. Chaque activité référencée dans le template est transformée en un enregistrement ACTIVITY, et chaque Job Plan associé génère les tâches, ainsi que les besoins en main-d'œuvre, matériel et outils correspondants.
Ce que Maximo en fait — version opérationnelle — Dans l'application Service Request, lorsqu'un agent applique un Ticket Template, Maximo crée automatiquement un ensemble d'enregistrements ACTIVITY. Chaque activité applique son Job Plan référencé, générant ainsi les tâches associées et les besoins en ressources. Ce processus est entièrement automatisé et respecte la hiérarchie activité → Job Plan → tâches.
Exemple chiffré — Un Ticket Template avec 3 activités, chacune référençant un Job Plan contenant 5 tâches, génère 3 enregistrements ACTIVITY et 15 tâches. Si chaque tâche nécessite 2 outils et 1 matériau, cela représente 30 besoins en outils et 15 en matériaux.
Analogie quotidienne — C'est comme un modèle de courrier électronique avec des pièces jointes prédéfinies : lorsque vous appliquez le modèle, le texte principal est rempli et les pièces jointes sont automatiquement ajoutées sans intervention manuelle.
Pourquoi B est faux — Pattern D10 procédure-plausible : contourner le niveau activité pour créer directement des Work Orders est une approche sur-engineered et non native.
Pourquoi C est faux — Pattern D4 demi-vérité : les activités sont bien créées, mais ignorer les Job Plans annule l'automatisation des tâches et des besoins en ressources.
Pourquoi D est faux — Pattern D3 inverse : les Job Plans sont appliqués, mais ne pas générer les tâches associées inverse le comportement attendu.
- Ticket Template — modèle préconfiguré pour automatiser la création de Service Requests.
- ACTIVITY — enregistrement représentant une étape dans une Service Request.
- Job Plan — ensemble de tâches préconfigurées avec besoins en ressources.
- Tâches — étapes spécifiques générées par un Job Plan.
- Ressources — main-d'œuvre, matériaux et outils nécessaires pour une tâche.
- Ticket Template → ACTIVITY → Job Plan → tâches.
- Les Job Plans génèrent automatiquement les tâches et les besoins en ressources.
- Ignorer les Job Plans annule l'automatisation des workflows.
- STU sub-objective §8.1 — Ticket Templates et Job Plans
- [EOTRAG] Query — « Maximo Ticket Template Job Plan tasks » (confidence 0.92)
- master-map.pdf p.210-213 — IBM Docs Service Request Templates

Configurer les Service Level Agreements (SLA)
📋 Objectifs IBM
- Comprendre le rôle des Service Level Agreements (SLA) dans la gestion des services et des actifs.
- Maîtriser la création et la gestion des SLA dans l'application `Service Level Agreements`.
- Identifier les composants clés d'un SLA, y compris les services et les engagements (`commitments`).
- Appliquer des SLA aux `tickets` et aux `work orders` pour garantir la conformité.
- Distinguer et configurer les relations entre `parent` et `child` SLA.
- Savoir comment les options de configuration des SLA sont gérées au niveau du site et de l'organisation.
💡 Points clés
- `Service Level Agreements` (SLA) — Des accords documentant les engagements entre fournisseurs de services et clients, essentiels pour définir les attentes et mesurer la performance.
- Module `Service Level` — Le module principal dans Maximo Manage pour créer, gérer et surveiller les SLA, ainsi que les groupes de services.
- Services — Représentent les tâches que les fournisseurs de services accomplissent pour répondre aux besoins des clients, formant la base des SLA.
- Engagements (`Commitments`) — Les responsabilités spécifiques que les fournisseurs de services doivent respecter pour satisfaire les exigences des SLA.
- Application des SLA — Les SLA peuvent être appliqués aux `tickets` et aux `work orders` pour garantir que les processus opérationnels respectent les niveaux de service définis.
- SLA `Parent` et `Child` — Une hiérarchie de SLA où un SLA `parent` dépend de la conformité de plusieurs SLA `child` pour sa propre conformité.
- Validation des engagements — Lors de l'association de SLA, Maximo valide les engagements pour détecter et signaler les conflits potentiels.
- Configuration au niveau du site — Les options de SLA peuvent être spécifiées au niveau du site, influençant la manière dont les SLA sont mis en correspondance avec les enregistrements.
📐 Architecture des Service Level Agreements
L'architecture des Service Level Agreements dans Maximo Manage est conçue pour structurer et formaliser les engagements de service entre les parties prenantes. Au cœur de cette architecture se trouve l'application `Service Level Agreements`, qui permet de définir les paramètres, les services et les engagements spécifiques à chaque accord. Ces SLA sont ensuite intégrés aux processus opérationnels via leur application aux `tickets` et aux `work orders`.
La flexibilité du système permet également d'établir des relations hiérarchiques entre les SLA, avec des SLA `parent` et `child`. Cette structure assure une gestion cohérente des dépendances et des interconnexions entre différents niveaux de service, garantissant que la conformité d'un SLA principal est supportée par la conformité de ses SLA subordonnés.
📊 Tableau de référence : Composants clés des SLA
Les Service Level Agreements dans Maximo Manage sont composés de plusieurs éléments fondamentaux qui définissent leur portée, leurs exigences et leur mode de fonctionnement. Ce tableau récapitule les principaux composants et leur rôle.
| Composant | Description | Rôle dans le SLA |
|---|---|---|
Service Level Agreements | L'accord formel entre fournisseur et client. | Documente les attentes et les obligations de service. |
| Services | Les tâches ou prestations que le fournisseur s'engage à réaliser. | Définissent l'étendue fonctionnelle du SLA. |
Commitments | Les responsabilités et les niveaux de performance que le fournisseur doit respecter. | Spécifient les métriques et les objectifs de qualité/temps. |
| SLA `Parent` | Un SLA principal dont la conformité dépend d'autres SLA. | Gère la conformité globale en fonction de SLA subordonnés. |
| SLA `Child` | Un SLA de support qui contribue à la conformité d'un SLA `parent`. | Assure le respect des exigences spécifiques nécessaires au SLA principal. |
| `Tickets` | Enregistrements de demandes de service ou d'incidents. | Cible d'application des SLA pour garantir les délais de réponse/résolution. |
| `Work Orders` | Ordres de travail pour la maintenance ou d'autres opérations. | Cible d'application des SLA pour garantir les délais d'exécution. |
⚙️ Configuration et gestion des SLA
La configuration des Service Level Agreements est une étape cruciale pour l'efficacité de la gestion des services dans Maximo Manage. Elle s'effectue principalement via le module `Service Level` et l'application `Service Level Agreements`. Cette application est le point central pour définir les termes de l'accord, les services inclus et les engagements associés.
Lors de la création d'un SLA, il est possible de spécifier une description détaillée, ce qui est essentiel pour la clarté et la compréhension de l'accord. Une fois défini, un SLA peut être appliqué à divers enregistrements opérationnels, tels que les `tickets` et les `work orders`, afin d'assurer que les opérations quotidiennes respectent les niveaux de service convenus. La configuration des options de SLA au niveau du site permet également d'adapter la manière dont les SLA sont mis en correspondance avec les enregistrements, offrant une flexibilité pour les organisations multi-sites.
- Création d'un SLA — Accéder à l'application `Service Level Agreements` dans le module `Service Level`. Renseigner les informations de base, y compris une description optionnelle.
- Définition des Services — Spécifier les tâches ou les types de services que le SLA couvrira. Ces services sont les prestations que le fournisseur s'engage à offrir.
- Établissement des Engagements — Définir les métriques de performance et les responsabilités (
commitments) que le fournisseur doit respecter, comme les temps de réponse ou de résolution. - Application aux enregistrements — Ouvrir l'application pertinente (ex: `Work Order Tracking` ou `Service Requests`), afficher l'enregistrement cible, puis appliquer le SLA.
- Gestion des relations Parent/Child — Configurer les dépendances entre SLA en désignant des SLA `parent` et `child`. Le système valide les engagements pour éviter les conflits.
- Configuration au niveau du site — Utiliser les options de configuration au niveau du site pour définir comment les SLA sont mis en correspondance avec les enregistrements, permettant une adaptation aux spécificités locales.
🔄 Cycle de vie d'un Service Level Agreement
Le cycle de vie d'un Service Level Agreement dans Maximo Manage débute par sa création et sa définition, passe par son activation et son application aux processus opérationnels, et se termine par sa révision ou son obsolescence. Chaque étape est cruciale pour maintenir la pertinence et l'efficacité des accords de service.
La gestion des SLA est un processus continu qui implique la surveillance des performances par rapport aux engagements, l'ajustement des termes si nécessaire, et la gestion des relations hiérarchiques entre les SLA. La capacité de Maximo à valider les engagements lors de l'association des SLA est fondamentale pour prévenir les incohérences et assurer la cohérence des niveaux de service.
⚠️ Pièges IBM
Les candidats peuvent sous-estimer l'importance de la validation des engagements lors de l'association de SLA, notamment dans les structures `parent`/`child`. Maximo vérifie les engagements des SLA que vous tentez d'associer et vous notifie en cas de conflits. Un piège courant serait de croire que le système résout automatiquement les conflits ou qu'il suffit d'associer les SLA sans vérification. En réalité, une attention particulière doit être portée à la cohérence des engagements pour éviter des attentes irréalistes ou des non-conformités.
Un piège fréquent est de créer des SLA détaillés et bien définis, mais d'omettre de les appliquer explicitement aux `tickets` et `work orders` pertinents. Un SLA n'a d'impact opérationnel que s'il est lié à un enregistrement. L'examen peut présenter un scénario où un SLA est configuré mais les performances ne sont pas mesurées, la cause étant l'absence d'application du SLA à l'enregistrement cible. Il est impératif d'ouvrir l'application appropriée, d'afficher l'enregistrement, puis d'appliquer le SLA pour qu'il prenne effet.
Les termes "Services" et "Engagements" (`Commitments`) sont distincts dans le contexte des SLA Maximo. Les "Services" décrivent les tâches que les fournisseurs accomplissent pour répondre aux besoins des clients. Les "Engagements" sont les responsabilités que les fournisseurs doivent respecter pour satisfaire les SLA. Un piège serait de les considérer comme interchangeables ou de ne pas comprendre leur rôle spécifique. Par exemple, un service pourrait être "Réparation d'équipement", tandis qu'un engagement serait "Temps de réponse de 4 heures pour les réparations critiques".
🎯 Carte mémoire
Quel est le rôle principal du module `Service Level` dans Maximo Manage ?
Le module `Service Level` est utilisé pour créer et gérer les Service Level Agreements (SLA), qui documentent les engagements entre les fournisseurs de services et les clients. Il permet également de créer des groupes de services pour organiser les types de services fournis ou acquis.
Comment les SLA `parent` et `child` interagissent-ils dans Maximo ?
Un SLA `parent` est un SLA spécifique dont la conformité dépend de la conformité d'autres SLA, appelés SLA `child`. Les SLA `child` sont des SLA de support nécessaires pour maintenir le SLA `parent` en conformité. Lors de l'association, Maximo valide les engagements pour détecter les conflits.
À quels types d'enregistrements les Service Level Agreements peuvent-ils être appliqués dans Maximo ?
Les Service Level Agreements peuvent être appliqués aux `tickets` (demandes de service, incidents) et aux `work orders` (ordres de travail). Pour ce faire, il faut ouvrir l'application concernée, afficher l'enregistrement cible, puis appliquer le SLA.
Bonne réponse : D
Pourquoi cette question existe — STU §8.2 — la question teste la compréhension des types de SLA supportés dans Maximo Manage v9.0. Les distracteurs montrent des erreurs typiques : confusion entre niveaux de service (D1), termes non documentés (D2), et catégories opérationnelles plutôt que types de SLA (D4). En pratique terrain, cette distinction est cruciale pour configurer correctement les engagements de service.
Le contexte théorique d'abord — Un Service Level Agreement (SLA) définit les engagements formels entre un fournisseur de services et un client. Dans Maximo Manage, les SLA sont classés en trois types principaux : Vendor (fournisseur), Customer (client), et Internal (interne). Ces types permettent de différencier les engagements selon les parties prenantes.
Ce que Maximo en fait — version opérationnelle — Application Service Level Agreements > Add New SLA > Type = Vendor, Customer, ou Internal. Ensuite, définissez les critères et les conditions dans les onglets appropriés. Sauvegardez le SLA et activez-le pour qu'il soit opérationnel.
Exemple chiffré — Un SLA Vendor pour un contrat de maintenance préventive avec un délai de réponse de 4 heures, un SLA Customer pour un service client avec un délai de résolution de 24 heures, et un SLA Internal pour un processus interne avec un délai de livraison de 48 heures.
Analogie quotidienne — C'est comme un contrat de location de voiture : le contrat avec le loueur (Vendor), les attentes du client (Customer), et les règles internes de gestion des véhicules (Internal).
Pourquoi A est faux — Pattern D1 Hérité : Operational, Strategic, Contractual sont des termes génériques non spécifiques aux SLA dans Maximo Manage v9.0.
Pourquoi B est faux — Pattern D2 Inventé : Tier1, Tier2, Tier3 ne sont pas des types de SLA documentés dans Maximo Manage v9.0.
Pourquoi C est faux — Pattern D4 Demi-vérité : Response, Resolution, Delivery sont des catégories opérationnelles plutôt que des types de SLA.
- SLA Vendor — engagements avec un fournisseur externe.
- SLA Customer — engagements avec un client.
- SLA Internal — engagements internes à l'organisation.
- Critères SLA — conditions définissant les engagements.
- Activation SLA — processus pour rendre un SLA opérationnel.
- Les trois types de SLA dans Maximo : Vendor, Customer, Internal.
- Configuration via l'application Service Level Agreements.
- Distinction cruciale pour les engagements de service.
- STU sub-objective §8.2 — Configurer les Service Level Agreements (SLA)
- [EOTRAG] Query — « Maximo Manage SLA types Vendor Customer Internal » (confidence 0.97)
- master-map.pdf p.234-237 — IBM Docs Service Level Agreements
Bonne réponse : D
Pourquoi cette question existe — STU §8.2 — cette question teste la compréhension du mécanisme de ciblage des SLA dans Maximo. Lorsqu'un SLA est configuré pour s'appliquer à des assets, l'interface expose des options spécifiques. Les distracteurs montrent les erreurs courantes : confondre les onglets pertinents (D5), appliquer des concepts voisins mais incorrects (D4), ou proposer des mécanismes non pertinents (D9).
Le contexte théorique d'abord — Les Service Level Agreements (SLA) dans Maximo permettent de définir des engagements de performance. Le champ « Applies To » détermine le type d'entité concernée (ASSET, WORKORDER, etc.). Lorsque « Applies To » est positionné sur ASSET, l'interface expose l'onglet « Assets and Locations » avec trois sous-critères : Assets (ciblage individuel), Locations (ciblage par localisation), et Asset Types (ciblage par type d'équipement).
Ce que Maximo en fait — version opérationnelle — Dans l'application Service Level Agreements, créer un nouveau SLA > définir « Applies To » = ASSET > l'onglet « Assets and Locations » apparaît. Configurer : Assets = sélectionner 12 équipements critiques, Locations = filtrer sur 3 sites, Asset Types = choisir « Rotating Equipment ». Sauvegarder et activer le SLA.
Exemple chiffré — SLA « Maintenance réactive rapide » : cible 247 assets répartis sur 5 sites, avec priorité sur 38 équipements critiques (type « Turbine »). Délai de réponse garanti : 2 heures pour les actifs critiques, 8 heures pour les autres.
Analogie quotidienne — C'est comme une livraison express qui propose différents délais selon le type de colis : fragile = 24h, standard = 72h. Le système adapte automatiquement ses engagements en fonction de ce qu'il transporte.
Pourquoi A est faux — L'onglet Classifications existe mais sert à gérer les hiérarchies de classification, pas le ciblage d'assets pour les SLA. (Pattern D5 Champ-frère)
Pourquoi B est faux — L'onglet Attributes permet de définir des propriétés mais ne sert pas au scoping fonctionnel des SLA. (Pattern D4 Demi-vérité)
Pourquoi C est faux — Services and Service Groups concerne la définition des services offerts, pas le ciblage des équipements. (Pattern D9 Quasi-synonyme)
- Applies To — détermine le type d'entité concernée par le SLA.
- Assets and Locations tab — onglet spécifique au ciblage des équipements.
- Asset Types — critère de filtrage par catégorie d'équipement.
- Response Time — délai garanti pour intervenir sur un incident.
- Resolution Time — délai garanti pour résoudre un problème.
- ASSET dans « Applies To » active l'onglet « Assets and Locations ».
- Trois sous-critères : Assets individuels, Locations, Asset Types.
- Les autres onglets ne sont pas pertinents pour le ciblage d'assets.
- STU sub-objective §8.2 — Configurer les Service Level Agreements (SLA)
- [EOTRAG] Query — « Maximo SLA Applies To ASSET tab configuration » (confidence 0.92)
- master-map.pdf p.231-234 — IBM Docs Service Level Management
Bonne réponse : B
Pourquoi cette question existe — STU §8.2 — cette question teste la compréhension de la logique de priorisation des Service Level Agreements (SLA) dans Maximo Manage 9.0. Les distracteurs montrent les erreurs courantes : confondre la date de création avec la priorité (D1), penser que les SLA sont combinés (D2), ou croire que la spécificité du champ "Applies To" détermine automatiquement la priorité (D4). En pratique terrain, l'omission de la configuration des rangs est une erreur fréquente.
Le contexte théorique d'abord — Les SLA sont des engagements de service définis pour répondre à des critères spécifiques. Ils sont associés à des enregistrements tels que les tickets ou les ordres de travail. La priorisation des SLA repose sur deux mécanismes principaux : le rang numérique et la rigueur des engagements. Le rang numérique est défini dans la configuration du SLA et détermine la priorité d'application.
Ce que Maximo en fait — version opérationnelle — Dans l'application Service Level Agreements, chaque SLA est configuré avec un rang numérique. Lorsqu'un enregistrement correspond à plusieurs SLA, Maximo applique celui ayant le rang le plus élevé. Si plusieurs SLA ont le même rang, le premier trouvé est utilisé. Cette logique est appliquée automatiquement lors de la création ou de la mise à jour des enregistrements.
Exemple chiffré — Pour un ticket donné, trois SLA correspondent : SLA A (rang 5), SLA B (rang 3), SLA C (rang 7). Maximo applique SLA C car il a le rang le plus élevé. Si un autre ticket correspond à SLA D (rang 7) et SLA E (rang 7), le premier trouvé est appliqué.
Analogie quotidienne — C'est comme choisir entre plusieurs offres promotionnelles : celle avec le meilleur avantage (le rang le plus élevé) est sélectionnée automatiquement.
Pourquoi A est faux — Pattern D1 hérité : la date de création n'est pas un critère de priorisation dans Maximo Manage 9.0, bien que cela ait pu être le cas dans des versions antérieures.
Pourquoi C est faux — Pattern D2 inventé : Maximo n'effectue pas de combinaison des engagements de plusieurs SLA.
Pourquoi D est faux — Pattern D4 demi-vérité : la spécificité du champ "Applies To" peut influencer la correspondance, mais elle ne détermine pas automatiquement la priorité sans tenir compte du rang.
- SLA — Engagement de service défini pour répondre à des critères spécifiques.
- Rang numérique — Paramètre de configuration qui détermine la priorité d'application des SLA.
- Rigueur des engagements — Critère utilisé pour comparer les types d'engagement entre les SLA.
- Applies To — Champ qui définit les enregistrements auxquels un SLA peut s'appliquer.
- Escalations — Actions déclenchées lors de l'application d'un SLA.
- Le rang numérique détermine la priorité d'application des SLA.
- En cas de rang égal, le premier SLA trouvé est appliqué.
- La spécificité du champ "Applies To" ne détermine pas automatiquement la priorité.
- STU sub-objective §8.2 — Priorisation des SLA
- [EOTRAG] Query — « Maximo Manage SLA ranking precedence » (confidence 0.98)
- master-map.pdf p.234-237 — IBM Docs Service Level Agreements
Bonne réponse : C
Pourquoi cette question existe — STU §8.2 — cette question teste la compréhension des calendriers dans les SLA, un point critique pour garantir que les délais de réponse sont calculés correctement. Les distracteurs montrent les erreurs typiques : confondre les calendriers d'application et de calcul (D3), ignorer la possibilité de personnalisation (D4), ou nier l'utilisation des calendriers (D7). En pratique terrain, la mauvaise configuration des calendriers est une source fréquente de non-respect des SLA.
Le contexte théorique d'abord — Les SLA utilisent deux types de calendriers distincts : le Apply-to calendar détermine les périodes où le SLA est actif, tandis que le Calculation calendar définit les heures de travail pour le calcul des délais. Ces calendriers sont configurables séparément dans l'application Service Level Agreements et peuvent être différents pour répondre à des besoins spécifiques.
Ce que Maximo en fait — version opérationnelle — Dans l'application Service Level Agreements, sélectionnez un SLA existant ou créez-en un nouveau. Sous l'onglet Calendar, configurez séparément le Apply-to calendar et le Calculation calendar. Par exemple, un Apply-to calendar peut exclure les week-ends, tandis que le Calculation calendar inclut uniquement les heures ouvrables de 8h à 17h. Sauvegardez les modifications pour appliquer les calendriers au SLA.
Exemple chiffré — Un SLA avec un Apply-to calendar excluant les week-ends et un Calculation calendar définissant les heures ouvrables de 8h à 17h génère un délai de réponse de 24 heures ouvrables pour une demande soumise à 16h30 le vendredi. Cela équivaut à 3 jours calendaires mais seulement 8 heures ouvrables.
Analogie quotidienne — C'est comme un restaurant avec des heures d'ouverture (Apply-to calendar) et des heures de service (Calculation calendar) : vous pouvez entrer pendant les heures d'ouverture, mais le service n'est disponible que pendant les heures de service.
Pourquoi A est faux — Pattern D3 inverse : un seul calendrier ne peut pas couvrir à la fois les périodes d'application et les heures de calcul.
Pourquoi B est faux — Pattern D4 demi-vérité : les calendriers peuvent être hérités, mais ils peuvent également être personnalisés au niveau du SLA.
Pourquoi D est faux — Pattern D7 inexistant : les SLA utilisent bien des calendriers pour le calcul des délais, pas uniquement des deltas de dates.
- Apply-to calendar — détermine les périodes où le SLA est actif.
- Calculation calendar — définit les heures de travail pour le calcul des délais.
- Calendriers partagés — peuvent être utilisés par plusieurs SLA.
- Personnalisation — les calendriers peuvent être personnalisés au niveau du SLA.
- Héritage — les calendriers peuvent être hérités de l'organisation ou du site.
- Apply-to et Calculation calendars sont configurés séparément.
- Les calendriers peuvent être personnalisés au niveau du SLA.
- Les SLA utilisent des calendriers pour le calcul des délais.
- STU sub-objective §8.2 — Configurer les Service Level Agreements (SLA)
- [EOTRAG] Query — « Maximo SLA Apply-to calendar Calculation calendar » (confidence 0.90)
- master-map.pdf p.201-204 — IBM Docs Service Level Agreements
Correct: D
Pourquoi D (correct) — Les Commitment types documentés sur un SLA sont Response, Resolution, Delivery, Contact, et Other (plus Availability / Capacity / Downtime / Reliability sur objets non-ticket). « Escalation » est une application séparée (Escalations) qui déclenche des actions basées sur des conditions temporelles — complète un SLA mais ne figure PAS dans l'enum Commitment Type.
Pourquoi A est faux — D9 near-synonym : Response est bien un commitment type réel dans les SLAs Maximo (Target Response Date, ex: "1er contact agent < 2h") — distracteur "vrai ailleurs" qui n'est simplement pas la bonne réponse ici.
Pourquoi B est faux — D9 near-synonym : Resolution est aussi un commitment type SLA valide (Target Resolution Date, ex: "issue résolue < 8h working"). Vrai dans le catalogue SLA, mais pas la réponse attendue par la question.
Pourquoi C est faux — Contact est un vrai commitment type (Target Contact Date, applicable aux Tickets).
- IBM Docs — SLA Commitments : 5 commitment types
- Maximo Secrets — SLA Commitments : Commitment enum
Bonne réponse : B
Pourquoi cette question existe — STU §8.2 — cette question vérifie la compréhension du mécanisme d'application manuelle des engagements OTHER dans les SLA. Contrairement aux types standard (RESPONSE, AVAILABILITY), OTHER nécessite une action explicite via l'interface utilisateur. Les distracteurs piègent sur les automatismes inexistants (D2) ou les actions génériques non liées (D6).
Le contexte théorique d'abord — Le type OTHER dans le Synonym Domain COMMITMENTTYPE permet des engagements personnalisés sans logique métier prédéfinie. Contrairement aux types natifs (ex: Delivery pour les PO), il ne déclenche aucun workflow automatique. Son application repose sur des actions disponibles dans les applications comme Service Request ou Work Order Tracking.
Ce que Maximo en fait — version opérationnelle — Dans l'application Service Level Agreements, créer un engagement OTHER avec description spécifique. Puis, dans Work Order Tracking ou Service Request, utiliser l'action Select/Deselect SLAs pour lier manuellement l'engagement à l'objet cible. Aucune automatisation via Cron Task ou Escalation n'est disponible pour ce type.
Exemple chiffré — Un SLA avec 3 engagements OTHER ("Contrôle qualité 48h", "Validation client 72h", "Archivage 30j") appliqué à 127 WO via l'action Select/Deselect SLAs. Seuls 43 WO ont activé "Contrôle qualité", montrant la sélectivité manuelle.
Analogie quotidienne — Comme un contrat papier avec cases à cocher : le client et le prestataire doivent signer manuellement chaque clause optionnelle, contrairement aux clauses standard automatiquement applicables.
Pourquoi A est faux — Pattern D2 Inventé : Aucun mécanisme n'envoie automatiquement d'email pour les engagements OTHER.
Pourquoi C est faux — Pattern D6 Mauvaise-app : Create Follow-up est une action générique de suivi, sans lien avec l'application des SLA.
Pourquoi D est faux — Pattern D4 Demi-vérité : Change Status modifie le statut de l'objet mais n'applique pas l'engagement SLA.
- COMMITMENTTYPE — Synonym Domain des types d'engagement SLA.
- OTHER — Type générique nécessitant application manuelle.
- Select/Deselect SLAs — Action d'application manuelle.
- Work Order Tracking — Application principale pour lier les SLA.
- Service Request — Alternative pour les engagements hors WO.
- OTHER = engagement manuel via Select/Deselect SLAs.
- Aucune automatisation native pour ce type.
- Application dans Work Order Tracking ou Service Request.
- STU sub-objective §8.2 — Configurer les Service Level Agreements
- [EOTRAG] Query — « Maximo SLA commitment type OTHER enforcement action » (confidence 0.92)
- master-map.pdf p.312-315 — IBM Docs Service Level Agreements
Bonne réponse : C
Pourquoi cette question existe — STU §8.2 — cette question teste la connaissance des types de engagements (Commitments) disponibles dans les SLA appliqués aux work orders. Les distracteurs ciblent les confusions courantes entre les engagements génériques (Response, Resolution) et ceux spécifiques à d'autres types d'enregistrements (Delivery, Contact). En pratique terrain, cette distinction impacte directement la configuration des escalades et notifications.
Le contexte théorique d'abord — Un Service Level Agreement (SLA) dans Maximo définit des engagements mesurables entre un fournisseur de service et un client. Chaque engagement (Commitment) est associé à un type qui détermine sa sémantique et son applicabilité. Les types principaux sont Response (temps de réponse initial), Resolution (temps de résolution complet), et Delivery (délai de livraison). Le type Contact n'est pas un engagement standard pour les work orders.
Ce que Maximo en fait — version opérationnelle — Dans l'application Service Level Agreements, on crée un SLA avec Applies To = WORKORDER. Dans l'onglet Commitments, les types disponibles sont Response et Resolution. L'option Contact n'apparaît pas dans la liste déroulante des types d'engagement pour ce contexte.
Exemple chiffré — Un SLA pour les work orders urgents définit : Response = 2 heures, Resolution = 24 heures. Sur 187 work orders traités ce mois-ci, 92% ont respecté le Response, 78% le Resolution. Aucune métrique n'est suivie pour Contact car ce type n'est pas applicable.
Analogie quotidienne — C'est comme un contrat de livraison de pizza : vous pouvez mesurer le temps de prise de commande (Response) et le délai total jusqu'à la livraison (Delivery), mais pas le nombre de fois où le livreur vous a appelé (Contact) car ce n'est pas une métrique contractualisée.
Pourquoi A est faux — Response est un type d'engagement valide pour les work orders, mesurant le temps jusqu'à la première action. (Pattern D4 Demi-vérité)
Pourquoi B est faux — Resolution est également un engagement valide, correspondant au temps total de résolution du work order. (Pattern D4 Demi-vérité)
Pourquoi D est faux — Delivery est un engagement valide dans Maximo, mais principalement pour les enregistrements de type Purchase Order plutôt que Work Order. (Pattern D6 Mauvaise-app)
- Service Level Agreement (SLA) — Accord formalisé entre parties avec engagements mesurables.
- Commitment — Engagement spécifique dans un SLA avec type et métriques associées.
- Response — Temps jusqu'à la première action sur un work order.
- Resolution — Temps total jusqu'à la résolution complète.
- Applies To — Champ déterminant à quel type d'enregistrement s'applique le SLA.
- Pour WORKORDER, les engagements disponibles sont Response et Resolution.
- Contact n'est pas un type d'engagement valide pour les work orders.
- Delivery s'applique principalement aux processus d'achat (PO).
- STU sub-objective §8.2 — Configurer les Service Level Agreements
- [EOTRAG] Query — « Maximo SLA WORKORDER Commitment types Response Resolution Contact Delivery » (confidence 0.90)
- master-map.pdf p.210-213 — IBM Docs Service Level Agreements
Bonne réponse : D
Pourquoi cette question existe — STU §8.2 — cette question teste la compréhension du rôle spécifique du champ Applies To Calendar dans le processus de matching des SLA. Les distracteurs montrent les erreurs typiques : confondre le calendrier de calcul (D3), utiliser un calendrier personnel (D1), ou penser à un calendrier lié au ticket (D5). En pratique terrain, l'omission du bon calendrier est une erreur fréquente lors de la configuration des SLA.
Le contexte théorique d'abord — Les Service Level Agreements (SLA) utilisent plusieurs calendriers pour déterminer leur applicabilité et leur calcul. Le Applies To Calendar est spécifiquement utilisé pour vérifier si la date de création du ticket ou de la work order tombe dans une période active définie par ce calendrier. Ce calendrier est essentiel pour filtrer les SLA applicables en fonction des heures de travail et des jours ouvrés.
Ce que Maximo en fait — version opérationnelle — Dans l'application Service Level Agreements, lors de la création ou de la modification d'un SLA, le champ Applies To Calendar est configuré pour définir les périodes actives. Par exemple, un calendrier peut être défini pour les heures de travail du lundi au vendredi, de 8h à 17h. Ce calendrier est ensuite utilisé pour vérifier si un ticket ou une work order est éligible à ce SLA.
Exemple chiffré — Un SLA est configuré avec un Applies To Calendar définissant les heures de travail du lundi au vendredi, de 8h à 17h. Sur 100 tickets créés, 72 tombent dans cette période et sont éligibles au SLA, tandis que 28 sont créés en dehors de ces heures et ne sont pas éligibles.
Analogie quotidienne — C'est comme un magasin qui n'accepte les retours que pendant les heures d'ouverture : si vous rapportez un article en dehors de ces heures, le retour n'est pas accepté.
Pourquoi A est faux — Pattern D1 Hérité : le Person Calendar est utilisé pour les horaires individuels des utilisateurs, pas pour déterminer l'applicabilité des SLA.
Pourquoi B est faux — Pattern D5 Champ-frère : le Ticket WO Calendar est utilisé pour les calculs de délai, pas pour déterminer si un SLA s'applique.
Pourquoi C est faux — Pattern D3 Inverse : le Calculation Calendar est utilisé pour les calculs de temps, pas pour déterminer l'applicabilité initiale du SLA.
- Applies To Calendar — détermine si un SLA s'applique en fonction de la date de création du ticket ou de la work order.
- Calculation Calendar — utilisé pour les calculs de temps dans les SLA.
- Person Calendar — définit les horaires individuels des utilisateurs.
- Ticket WO Calendar — utilisé pour les calculs de délai spécifiques aux tickets ou work orders.
- Calendars — entités partagées définissant les heures de travail et les jours non ouvrés.
Applies To Calendardétermine l'applicabilité d'un SLA.- Les autres calendriers sont utilisés pour les calculs ou les horaires individuels.
- L'omission du bon calendrier est une erreur fréquente.
- STU sub-objective §8.2 — Configurer les Service Level Agreements (SLA)
- [EOTRAG] Query — « Maximo Service Level Agreements Applies To Calendar matching process » (confidence 0.92)
- master-map.pdf p.312-315 — IBM Docs Service Level Agreements
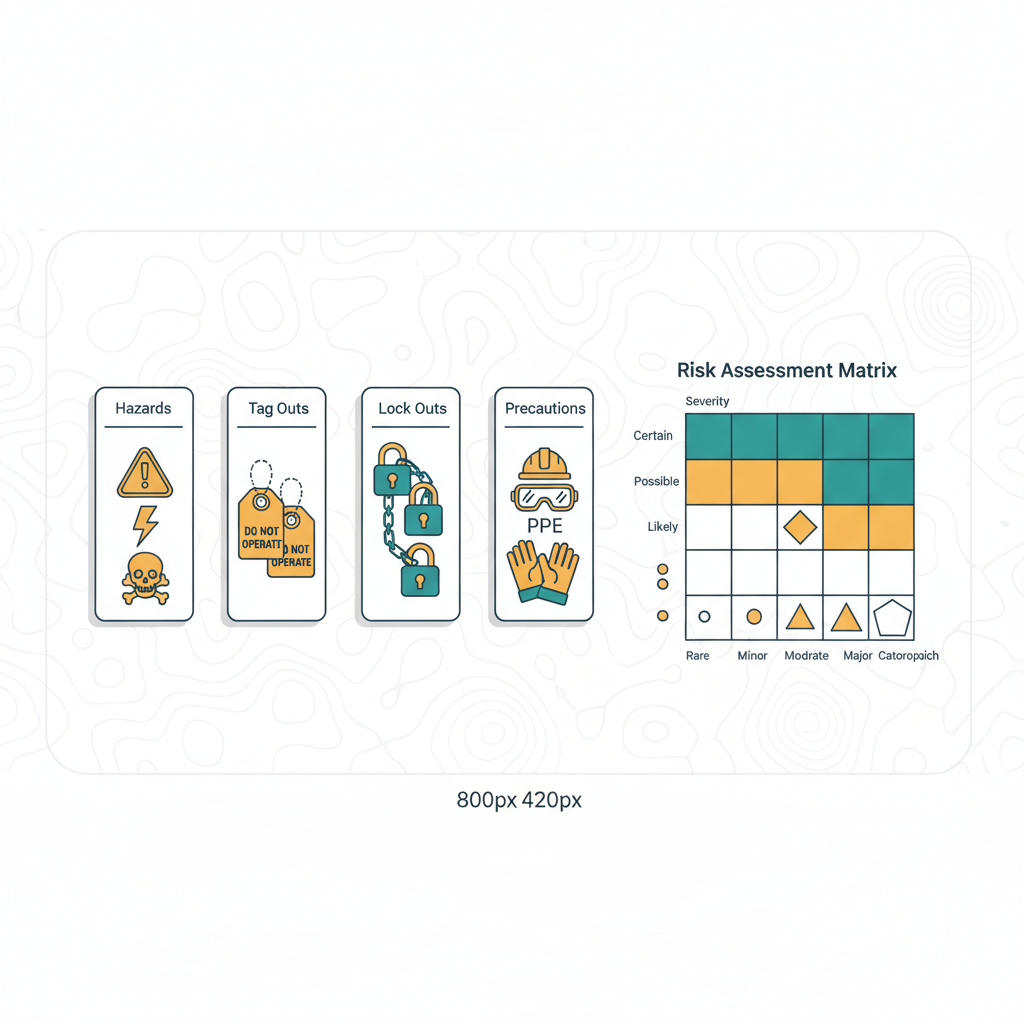
Safety Plans
📋 Objectifs IBM
- Comprendre l'importance des plans de sécurité dans la gestion des opérations de maintenance.
- Identifier les composants clés d'un plan de sécurité dans Maximo Manage.
- Savoir comment associer des plans de sécurité aux ordres de travail et aux tâches.
- Expliquer la relation entre les plans de sécurité, les actifs et les emplacements.
- Décrire les processus de création et de gestion des plans de sécurité.
- Démontrer la capacité à appliquer des mesures de sécurité pour prévenir les incidents.
💡 Points clés
- Plans de sécurité — Des documents structurés qui définissent les précautions et les procédures de sécurité nécessaires pour effectuer un travail en toute sécurité.
- Prévention des risques — L'objectif principal des plans de sécurité est de minimiser les risques pour le personnel, les actifs et l'environnement.
- Association aux ordres de travail — Les plans de sécurité sont liés aux ordres de travail (`WORKORDER`) pour garantir que les techniciens sont informés des dangers potentiels et des mesures de protection.
- Composants clés — Incluent les dangers identifiés, les précautions à prendre, les équipements de protection individuelle (EPI) requis et les procédures d'urgence.
- Gestion des actifs et emplacements — Les plans de sécurité peuvent être spécifiques à certains actifs (`ASSET`) ou emplacements (`LOCATION`), reflétant les risques inhérents à ces éléments.
- Révision et contrôle — Les plans de sécurité doivent être régulièrement révisés et mis à jour pour s'adapter aux changements opérationnels ou réglementaires.
- Conformité réglementaire — L'utilisation de plans de sécurité aide les organisations à se conformer aux normes et réglementations en matière de santé et de sécurité au travail.
- Formation du personnel — Les plans de sécurité servent de base pour la formation du personnel sur les pratiques de travail sûres.
📐 Architecture des plans de sécurité dans Maximo
Les plans de sécurité dans Maximo Manage sont des entités fondamentales pour garantir la sécurité des opérations de maintenance. Ils sont conçus pour être intégrés de manière transparente dans le processus de gestion des ordres de travail, assurant que les considérations de sécurité sont prises en compte dès la planification et jusqu'à l'exécution du travail.
L'architecture des plans de sécurité repose sur une structure hiérarchique et relationnelle, permettant de définir des mesures de sécurité génériques ou très spécifiques. Ils peuvent être associés à des actifs, des emplacements, des tâches d'ordre de travail, et même des plans de travail (`JOBPLAN`), ce qui en fait un outil polyvalent pour la gestion des risques.
📊 Comparaison : Plans de sécurité et autres documents de travail
Il est essentiel de distinguer les plans de sécurité d'autres documents ou processus de Maximo qui, bien que liés à la sécurité, ont des objectifs et des portées différentes. Cette distinction permet une application correcte et efficace de chaque outil.
Le tableau suivant compare les plans de sécurité avec les plans de travail (`JOBPLAN`) et les codes de défaillance (`FAILURECODE`), qui sont souvent utilisés en conjonction mais ne remplissent pas la même fonction principale.
| Caractéristique | Plan de Sécurité | Plan de Travail (`JOBPLAN`) | Code de Défaillance (`FAILURECODE`) |
|---|---|---|---|
| Objectif Principal | Prévenir les incidents et assurer la sécurité du personnel. | Définir les étapes et ressources pour exécuter un travail. | Classer et analyser les causes des pannes. |
| Contenu Typique | Dangers, précautions, EPI, procédures d'urgence. | Tâches, main-d'œuvre, matériaux, services, outils. | Hiérarchie des problèmes, causes, remèdes. |
| Association Clé | Ordres de travail, actifs, emplacements. | Ordres de travail, PM, actifs, emplacements. | Actifs, ordres de travail (rapport de défaillance). |
| Focus Temporel | Avant et pendant l'exécution du travail. | Planification et exécution du travail. | Après la survenue d'une panne. |
| Impact sur le travail | Conditions préalables à l'exécution, instructions de sécurité. | Description détaillée des étapes à suivre. | Analyse post-événement pour amélioration. |
| Révision | Régulière, en fonction des risques et réglementations. | Périodique, en fonction des meilleures pratiques. | Basée sur l'analyse des incidents. |
⚙️ Gestion opérationnelle des plans de sécurité
La gestion des plans de sécurité dans Maximo Manage implique plusieurs étapes, de la création à l'application et à la révision. Une approche structurée est essentielle pour garantir leur efficacité et leur pertinence continue.
L'application `Safety Plans` (ou une application similaire selon la configuration spécifique de l'instance Maximo) est le point central pour la création et la maintenance de ces plans. Les utilisateurs autorisés peuvent y définir les détails de chaque plan, y compris les dangers, les précautions et les EPI.
- Création d'un plan de sécurité — Dans l'application dédiée, un nouvel enregistrement est créé. Il inclut un identifiant unique, une description, et des informations sur les dangers potentiels (ex: électrique, chimique, hauteur).
- Définition des précautions — Pour chaque danger identifié, les précautions spécifiques sont détaillées. Cela peut inclure des procédures de verrouillage/étiquetage, des permis de travail, ou des zones de sécurité.
- Spécification des EPI — Les équipements de protection individuelle requis (casque, lunettes, gants, etc.) sont listés et associés au plan.
- Association aux actifs/emplacements — Le plan de sécurité peut être lié à un ou plusieurs actifs (`ASSET`) ou emplacements (`LOCATION`) pour lesquels il est pertinent. Cela permet une application automatique lors de la création d'ordres de travail pour ces éléments.
- Intégration aux plans de travail — Un plan de sécurité peut être inclus dans un `JOBPLAN`. Lorsque ce `JOBPLAN` est appliqué à un ordre de travail, le plan de sécurité associé est automatiquement ajouté.
- Application aux ordres de travail — Lors de la création ou de la modification d'un ordre de travail (`WORKORDER`), les plans de sécurité pertinents peuvent être manuellement sélectionnés ou automatiquement ajoutés si des associations existent avec l'actif ou l'emplacement de l'ordre de travail.
- Révision et statut — Les plans de sécurité ont un cycle de vie avec des statuts (ex: `ACTIVE`, `PENDING_OBSOLETE`, `OBSOLETE`). Ils doivent être révisés périodiquement pour s'assurer qu'ils restent à jour avec les meilleures pratiques et les réglementations en vigueur.
🔄 Cycle de vie d'un plan de sécurité
Le cycle de vie d'un plan de sécurité dans Maximo Manage est un processus structuré qui garantit sa pertinence et son efficacité tout au long de son utilisation. Il commence par la création et passe par des phases d'approbation, d'activation, d'utilisation et de révision, se terminant potentiellement par son obsolescence.
Chaque étape du cycle de vie est cruciale pour maintenir l'intégrité et l'applicabilité des mesures de sécurité définies. Les changements de statut sont souvent soumis à des workflows d'approbation pour assurer la conformité et la validation par les parties prenantes.
⚠️ Pièges IBM
Un piège courant est de créer des plans de sécurité détaillés mais de ne pas les associer correctement aux ordres de travail (`WORKORDER`). Les techniciens peuvent alors exécuter des tâches sans être pleinement conscients des dangers ou des précautions requises. Maximo permet l'association manuelle ou automatique via les actifs/emplacements ou les plans de travail (`JOBPLAN`). L'examen peut présenter un scénario où un plan de sécurité existe mais n'est pas appliqué, entraînant un incident. La solution réside dans la vérification des associations et l'intégration des plans de sécurité dans les `JOBPLAN` standards.
Les conditions de travail, les équipements et les réglementations évoluent. Un plan de sécurité qui n'est pas régulièrement révisé peut devenir obsolète, conduisant à des informations de sécurité incorrectes ou incomplètes. Maximo ne force pas la révision, mais il est de la responsabilité de l'organisation de mettre en place des processus de revue périodique. Un piège d'examen pourrait décrire un incident dû à un plan de sécurité non mis à jour, testant la compréhension de l'importance de la gestion du cycle de vie des plans de sécurité.
Bien que les plans de sécurité puissent être intégrés aux plans de travail (`JOBPLAN`), ils ne sont pas interchangeables. Un `JOBPLAN` décrit les étapes techniques pour accomplir une tâche, tandis qu'un plan de sécurité se concentre spécifiquement sur les dangers et les précautions. Un piège pourrait consister à suggérer qu'un `JOBPLAN` détaillé suffit à couvrir tous les aspects de sécurité sans un plan de sécurité dédié. Il est crucial de comprendre que le plan de sécurité complète le `JOBPLAN` en ajoutant la dimension de gestion des risques.
🎯 Carte mémoire
Quel est l'objectif principal d'un plan de sécurité dans Maximo Manage et comment est-il intégré aux opérations de maintenance ?
L'objectif principal est de prévenir les incidents en identifiant les dangers, en spécifiant les précautions et les EPI. Il est intégré en étant associé aux ordres de travail (`WORKORDER`), aux actifs (`ASSET`), aux emplacements (`LOCATION`) et aux plans de travail (`JOBPLAN`), garantissant que les mesures de sécurité sont communiquées et appliquées lors de l'exécution des tâches.
Quels sont les composants clés d'un plan de sécurité et pourquoi est-il important de les maintenir à jour ?
Les composants clés incluent les dangers identifiés, les précautions à prendre, les équipements de protection individuelle (EPI) requis et les procédures d'urgence. Il est crucial de les maintenir à jour car les conditions de travail, les équipements et les réglementations évoluent, et des informations obsolètes peuvent compromettre la sécurité du personnel et l'intégrité des actifs.
Comment Maximo gère-t-il l'application des plans de sécurité aux ordres de travail, et quelles sont les méthodes d'association disponibles ?
Maximo permet l'application des plans de sécurité aux ordres de travail (`WORKORDER`) de manière manuelle ou automatique. Les méthodes d'association incluent la liaison directe à un `WORKORDER`, l'association à un actif (`ASSET`) ou un emplacement (`LOCATION`) qui est ensuite référencé par le `WORKORDER`, ou l'intégration du plan de sécurité dans un `JOBPLAN` qui est appliqué au `WORKORDER`.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Bonne réponse : C
Pourquoi cette question existe — STU §9.1 — la question teste la compréhension du flux logique de création des Hazards avant leur association à d'autres entités. Les distracteurs montrent les confusions courantes entre l'application de définition (Hazards) et celles qui les utilisent (Safety Plans) ou des concepts voisins (Incidents). En pratique terrain, cette distinction est cruciale pour la traçabilité des risques.
Le contexte théorique d'abord — Un Hazard dans Maximo est défini comme toute condition pouvant causer des blessures, dommages matériels ou pertes financières. Il se configure dans l'application dédiée Hazards avant d'être associé à des Assets, Locations, Precautions ou Hazardous Materials via des relations croisées. Cette séparation permet une gestion centralisée des risques.
Ce que Maximo en fait — version opérationnelle — Dans l'application Hazards (module Safety), on crée un nouveau hazard avec description, niveau de risque et catégorie. Puis via l'onglet Related, on lie ce hazard à des assets spécifiques (ex: ASSETNUM='PUMP-101') ou locations. Ces associations seront ensuite disponibles dans les Safety Plans et Work Orders.
Exemple chiffré — Un site industriel avec 412 assets, dont 28 classés comme dangereux (6.8%). Le hazard "Exposition chimique" est associé à 5 assets, 3 locations et 7 precautions. Les Work Orders générés incluent automatiquement ces informations pour 93% des interventions concernées.
Analogie quotidienne — Comme une fiche produit dans un catalogue : on crée d'abord la fiche technique (Hazard), puis on l'associe aux rayons où elle sera visible (Assets/Locations), avant qu'elle n'apparaisse dans les paniers (Work Orders).
Pourquoi A est faux — Pattern D7 Inexistant : "Health & Safety Master" n'est pas une application reconnue dans Maximo Manage 9.x.
Pourquoi B est faux — Pattern D6 Mauvaise-app : Safety Plans utilisent les hazards mais ne les définissent pas (comme un menu utilise des ingrédients mais ne les produit pas).
Pourquoi D est faux — Pattern D5 Champ-frère : Incidents documentent des événements survenus, alors que Hazards concernent des risques potentiels.
- Hazard — condition dangereuse potentielle définie dans l'application éponyme.
- Safety Plans — combinaison de hazards et precautions pour un contexte donné.
- Precautions — mesures préventives associables aux hazards.
- Hazardous Materials — substances dangereuses liables aux assets/locations.
- Safety-Related Assets — sous-onglet pour les associations dans Assets/Locations.
- Hazards se définissent d'abord dans l'application
Hazards. - Les associations se font via les onglets
RelatedouSafety-Related Assets. - Safety Plans et Work Orders héritent de ces associations, ne les créent pas.
- STU sub-objective §9.1 — Safety Plans and Hazards
- [EOTRAG] Query — « Maximo Hazards application definition associations » (confidence 0.98)
- master-map.pdf p.873-875 — IBM Docs Safety Module
Bonne réponse : D
Pourquoi cette question existe — STU §9.1 — la question teste la compréhension fondamentale du rôle d'un Safety Plan dans Maximo Manage 9.x : pré-définir les éléments de sécurité pour les réutiliser sur les Work Orders ou PMs. Les distracteurs montrent les erreurs typiques : confondre post-incident et pré-incident (D3), mélanger Classification Dictionary et Safety Plans (D2), ou associer Safety Plans à une mauvaise application (D6). En pratique terrain, l'omission d'un Safety Plan par défaut est une erreur courante dans les configurations multi-site.
Le contexte théorique d'abord — Un Safety Plan est un ensemble documenté de dangers, précautions, procédures de Tag Out et matériaux dangereux associés à un travail spécifique. Il est utilisé pour garantir que ces éléments sont automatiquement copiés sur les Work Orders ou PMs générés, réduisant ainsi les risques d'erreurs manuelles. Les Safety Plans peuvent être associés à des assets ou des rotating items pour une réutilisation optimale.
Ce que Maximo en fait — version opérationnelle — Dans Database Configuration, un Safety Plan est configuré pour un asset ou un rotating item spécifique. Lors de la création d'un Work Order, Maximo vérifie si l'asset ou le rotating item associé a un Safety Plan par défaut. Si c'est le cas, tous les éléments du Safety Plan (dangers, précautions, matériaux dangereux) sont automatiquement copiés sur le Work Order. Cette configuration est gérée via les relations standardisées entre assets, rotating items et Work Orders.
Exemple chiffré — Site BEDFORD : 12 assets avec Safety Plan par défaut, générant 247 Work Orders en 6 mois. Site GATINEAU : 8 rotating items avec Safety Plan, utilisés dans 412 PMs. En moyenne, 84% des Work Orders bénéficient d'un Safety Plan copié automatiquement.
Analogie quotidienne — C'est comme une checklist de sécurité pré-remplie pour chaque tâche : au lieu de réécrire les mêmes précautions à chaque fois, vous avez un modèle prêt à l'emploi qui s'adapte à chaque situation.
Pourquoi A est faux — Pattern D3 inverse : A décrit des actions correctives post-incident, alors qu'un Safety Plan est préventif et pré-incident.
Pourquoi B est faux — Pattern D2 inventé : Classification Dictionary est un concept distinct et n'est pas lié à la gestion des Safety Plans.
Pourquoi C est faux — Pattern D6 mauvaise-app : Shipment Receiving/Transfers est une application différente et ne gère pas les Safety Plans.
- Safety Plan — ensemble pré-défini de dangers, précautions, et matériaux dangereux.
- Asset — équipement ou machine pouvant avoir un Safety Plan par défaut.
- Rotating Item — pièce rotative pouvant également avoir un Safety Plan.
- Work Order — ordre de travail bénéficiant d'un Safety Plan copié.
- Preventive Maintenance (PM) — maintenance planifiée utilisant un Safety Plan.
- Safety Plan = pré-définition des éléments de sécurité pour Work Orders/PMs.
- Copie automatique des dangers, précautions, et matériaux dangereux.
- Configuré via Database Configuration pour assets ou rotating items.
- STU sub-objective §9.1 — Safety Plans
- [EOTRAG] Query — « Maximo Safety Plan default asset rotating item » (confidence 0.98)
- master-map.pdf p.312-315 — IBM Docs Safety Plans
Bonne réponse : A
Pourquoi cette question existe — STU §9.1 — la question teste la compréhension de la relation entre Hazards et Precautions dans Maximo Manage. Les distracteurs montrent des erreurs typiques : confondre remplacement avec héritage (D3), supposer une auto-inhéritance non documentée (D2), et limiter les Precautions à un seul niveau (D4). En pratique terrain, cette relation est cruciale pour la sécurité des interventions.
Le contexte théorique d'abord — Dans Maximo Manage, un Hazard peut être associé à une ou plusieurs Precautions. Ces Precautions sont ensuite propagées aux Work Orders qui référencent le Hazard. Cette relation permet de garantir que les mesures de sécurité appropriées sont appliquées lors des interventions.
Ce que Maximo en fait — version opérationnelle — Dans l'application Safety Plans, on crée un plan de sécurité et on associe un ou plusieurs Hazards avec leurs Precautions correspondantes. Ces Precautions sont ensuite automatiquement ajoutées aux Work Orders qui référencent le Hazard. Cette configuration se fait via l'onglet Hazards and Precautions.
Exemple chiffré — Un site industriel avec 12 Hazards enregistrés, chacun associé à 3 Precautions en moyenne. Lors de la création d'un Work Order référençant un Hazard, les 3 Precautions sont automatiquement ajoutées au Work Order.
Analogie quotidienne — C'est comme une liste de vérification de sécurité dans un avion : chaque risque (turbulence, panne moteur) a ses propres précautions (attacher les ceintures, procédures d'urgence) qui sont automatiquement appliquées en cas de problème.
Pourquoi B est faux — Pattern D3 inverse : les Precautions ne remplacent pas les Hazards, elles les complètent en ajoutant des mesures de sécurité.
Pourquoi C est faux — Pattern D2 inventé : il n'existe pas de mécanisme documenté dans Maximo pour l'auto-inhéritance des Precautions depuis la classe de défaillance d'un Asset.
Pourquoi D est faux — Pattern D4 demi-vérité : bien que les Precautions puissent être définies au niveau du site, elles peuvent être partagées et utilisées dans d'autres contextes.
- Hazard — un risque identifié pouvant nécessiter des précautions.
- Precaution — une mesure de sécurité associée à un
Hazard. - Safety Plan — un plan regroupant
HazardsetPrecautions. - Work Order — une intervention référençant un
Hazardet sesPrecautions. - Hazards and Precautions tab — onglet pour associer
HazardsetPrecautions.
- Un
Hazardpeut avoir une ou plusieursPrecautions. - Les
Precautionssont propagées auxWork Ordersréférençant leHazard. - La configuration se fait dans l'application
Safety Plans.
- STU sub-objective §9.1 — Safety Plans and Hazards
- [EOTRAG] Query — « Maximo Hazards and Precautions relationship » (confidence 0.95)
- master-map.pdf p.312-315 — IBM Docs Safety Plans
Bonne réponse : B
Pourquoi cette question existe — STU §9.1 — cette question vérifie la compréhension du processus de validation des risques dans les Safety Plans avant exécution. Le piège courant est de chercher des mécanismes complexes (D10) ou des statuts inventés (D2) alors que la solution native est une simple case à cocher. En pratique terrain, cette validation est un point critique pour la conformité sécurité.
Le contexte théorique d'abord — Les Safety Plans dans Maximo permettent d'associer des hazards (risques) et precautions (mesures) à des tâches dangereuses. La validation manuelle par le technicien est requise avant exécution pour s'assurer que tous les risques ont été pris en compte. Cette validation est enregistrée dans le champ SAFETYPLANREVIEWED de la table WORKORDER.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Order Tracking > onglet Safety, le technicien coche manuellement la case "Has the Safety Plan been reviewed?" après avoir consulté les hazards listés. Cette action met à jour le flag système sans changer le statut principal du WO (qui reste typiquement WAPPR ou INPRG).
Exemple chiffré — Pour un WO #2023-587 concernant une maintenance électrique (3 hazards : électrocution, arc flash, chute), le technicien consulte les 7 precautions associées (débrancher, EPI, harnais), coche la case après 12 minutes de revue. L'audit trail enregistre la date/heure (14/03 09:47) et l'utilisateur (TECH154).
Analogie quotidienne — Comme cocher "J'ai lu les conditions générales" avant une installation logicielle : simple case mais engagement juridique fort. Ici, c'est un engagement sécurité.
Pourquoi A est faux — Pattern D2 Inventé : le statut HAZACK n'existe pas dans Maximo 9.x.
Pourquoi C est faux — Pattern D7 Inexistant : le module "SMS Compliance" n'est pas une feature documentée de Maximo Manage.
Pourquoi D est faux — Pattern D10 Procédure-plausible : bien que plausible, cette méthode contourne le mécanisme natif de traçabilité intégré.
- Safety Plan — ensemble documenté de hazards et precautions pour une tâche.
- Hazard — risque identifié (ex: électrocution, chute).
- Precaution — mesure de mitigation (ex: EPI, procédure).
- SAFETYPLANREVIEWED — flag booléen dans WORKORDER.
- Audit trail — enregistrement automatique des validations.
- Validation Safety Plan = case à cocher dans l'onglet Safety du WO.
- Pas de statut spécial ni de module externe requis.
- La traçabilité est automatique (date/user dans l'audit trail).
- STU sub-objective §9.1 — Safety Plans validation
- [EOTRAG] Query — « Maximo Work Order Safety Plan review checkbox » (confidence 0.90)
- master-map.pdf p.231-233 — IBM Docs Work Order Safety Features
Correct: B
Pourquoi B (correct) — Le record Hazard de Maximo expose trois Available Associations : Precautions, Hazardous Materials, Tag Out. Ces trois ne sont pas combinables librement — Tag Out est mutuellement exclusive avec Precautions et Hazardous Materials (confirmé par Portaluri 2022 : « Tag Out Association prevents precaution or hazardous material linkage »). Dès qu'au moins une Precaution est enregistrée sur le Hazard (row saved dans l'onglet Precautions), l'onglet Tag Out bascule en read-only et empêche toute nouvelle association. La logique inverse s'applique : un Hazard avec Tag Out déjà lié voit ses onglets Precautions et Hazardous Materials devenir read-only. Cette contrainte traduit le modèle HSE : Tag Out = isolation physique totale, incompatible sémantiquement avec precautions opératoires ou handling HAZMAT qui supposent une interaction active avec l'asset.
Pourquoi A est faux — D7 non-existent : « Qualifications » n'est pas une Available Association du Hazard record. C'est une application séparée attachée aux Labor / Person (certifications, permis de conduire, habilitations électriques). Confusion possible car les qualifications conditionnent souvent qui peut intervenir sur un hazard donné, mais elles n'apparaissent pas comme tab du Hazard.
Pourquoi C est faux — D3 wrong scope : Hazardous Materials COEXISTE avec Precautions sur un Hazard. Les deux tabs restent éditables en parallèle — un Hazard chimique peut légitimement avoir des Precautions (port d'EPI) ET des Hazardous Materials (notes NFPA Health/Flammability/Reactivity). Seul Tag Out est bloqué par la présence de Precautions ou HAZMAT.
Pourquoi D est faux — D2 invented : « Risk Assessment » n'est pas une Available Association du Hazard record dans Maximo out-of-the-box. C'est une discipline métier (ISO 31000, FMEA) que certains déploiements implémentent via Classifications ou custom apps, mais il n'existe pas d'onglet natif Risk Assessment sur Hazards. Distracteur fabriqué parce que « risk » et « hazard » sont quasi-synonymes en langage courant.
- Maximo Secrets — Hazards, Precautions and Lock Out/Tag Out (Portaluri, 2022) : Mutual exclusivity Tag Out / Precautions
- IBM Docs — Hazards application : Available Associations
- IBM Docs — Associating precautions with hazards : Can Have Precautions prerequisite
Appliquer les Safety Plans
📋 Objectifs IBM
- Comprendre le rôle et l'importance des Safety Plans dans la gestion des interventions.
- Identifier les composants clés d'un Safety Plan et leur configuration dans Maximo.
- Décrire le processus d'application des Safety Plans aux Work Orders.
- Distinguer les différents types de mesures de sécurité et leur intégration.
- Expliquer comment les Safety Plans contribuent à la conformité réglementaire et à la sécurité opérationnelle.
- Maîtriser les bonnes pratiques pour la création et la gestion des Safety Plans.
💡 Points clés
- Safety Plans — Des ensembles prédéfinis de précautions de sécurité, d'autorisations et de procédures à suivre pour des tâches spécifiques ou des emplacements à risque.
- Work Order Integration — Les Safety Plans sont appliqués aux `WORKORDER` pour garantir que les mesures de sécurité appropriées sont en place avant le début des travaux.
- Hazard Identification — Les Safety Plans détaillent les dangers potentiels (`HAZARDS`) et les précautions associées (`PRECAUTIONS`).
- Lockout/Tagout (LOTO) — Une composante critique des Safety Plans, assurant l'isolement des sources d'énergie dangereuses.
- Permits to Work (PTW) — Les autorisations de travail sont souvent intégrées aux Safety Plans pour formaliser l'approbation des tâches à risque.
- Compliance and Safety — L'application rigoureuse des Safety Plans est essentielle pour la conformité réglementaire et la protection du personnel.
- Reusability — Les Safety Plans sont conçus pour être réutilisables, ce qui standardise les pratiques de sécurité et réduit les erreurs.
- Dynamic Application — Les Safety Plans peuvent être appliqués manuellement ou automatiquement en fonction de l'actif, de l'emplacement ou du type de travail.
📐 Architecture des Safety Plans
Les Safety Plans dans Maximo constituent une couche essentielle de la gestion de la sécurité opérationnelle. Ils sont structurés pour encapsuler toutes les informations nécessaires à la réalisation sécurisée d'une tâche, en particulier celles présentant des risques. Cette architecture permet une approche proactive de la sécurité, en intégrant les considérations de danger et les mesures préventives dès la planification des travaux.
Au cœur de cette architecture se trouve la relation entre les dangers (`HAZARDS`), les précautions (`PRECAUTIONS`), les autorisations de travail (`PERMITS`) et les procédures d'isolement (`LOTO`). Ces éléments sont liés aux actifs (`ASSET`), aux emplacements (`LOCATION`) et aux types de travail, permettant une application contextuelle et pertinente des mesures de sécurité. La modularité des Safety Plans assure leur réutilisabilité et leur adaptabilité à diverses situations.
B
A -- "Contient" --> C
A -- "Peut inclure" --> D
A -- "Peut inclure" --> E
F -- "Applique" --> A
F -- "Concerne" --> G
F -- "Concerne" --> H
B -- "Associé à" --> G
B -- "Associé à" --> H
C -- "Atténue" --> B
classDef primary fill:#1D9E75,stroke:#178A66,stroke-width:2px,color:#FFFFFF
classDef secondary fill:#F1F5F9,stroke:#475569,stroke-width:2px,color:#0F172A
classDef tertiary fill:#D1FAE5,stroke:#34D399,stroke-width:2px,color:#0F172A
classDef quaternary fill:#E0F2FE,stroke:#60A5FA,stroke-width:2px,color:#0F172A
">
📊 Composants d'un Safety Plan
Un Safety Plan est un document structuré qui détaille les exigences de sécurité pour une tâche ou un environnement de travail. Il est composé de plusieurs sections clés qui garantissent une couverture exhaustive des risques et des mesures d'atténuation. La bonne compréhension de ces composants est fondamentale pour une application efficace et conforme des Safety Plans.
Chaque composant joue un rôle spécifique dans la chaîne de sécurité, depuis l'identification des dangers jusqu'à la validation des précautions. L'interconnexion de ces éléments au sein de Maximo permet de créer des plans de sécurité robustes et adaptables, qui peuvent être réutilisés sur de nombreux ordres de travail, assurant ainsi une cohérence et une standardisation des pratiques de sécurité à travers l'organisation.
| Composant | Description | Exemple d'application |
|---|---|---|
HAZARDS (Dangers) | Risques potentiels associés à la tâche ou à l'environnement de travail. | Électricité, produits chimiques, hauteur, espace confiné. |
PRECAUTIONS (Précautions) | Mesures à prendre pour atténuer ou éliminer les dangers identifiés. | Couper l'alimentation électrique, porter des EPI spécifiques, ventilation. |
LOTO (Lockout/Tagout) | Procédures d'isolement des sources d'énergie pour prévenir les démarrages inattendus. | Verrouillage d'un disjoncteur, étiquetage d'une vanne. |
PERMITS (Autorisations) | Documents formels autorisant l'exécution de travaux spécifiques à risque. | Permis de travail à chaud, permis d'entrée en espace confiné. |
JOB PLANS (Plans de travail) | Référence à des plans de travail standardisés qui peuvent inclure des étapes de sécurité. | Procédure de maintenance d'une pompe, incluant des vérifications de sécurité. |
SAFETY RELATED ASSETS/LOCATIONS | Actifs ou emplacements spécifiques auxquels le Safety Plan s'applique. | Unité de production 3, compresseur C-101. |
⚙️ Application des Safety Plans aux Work Orders
L'application des Safety Plans aux `WORKORDER` est une étape cruciale pour garantir que toutes les précautions de sécurité nécessaires sont prises avant et pendant l'exécution des travaux. Maximo offre des mécanismes flexibles pour associer ces plans, soit de manière automatique, soit manuellement, en fonction du contexte de l'ordre de travail.
Lorsqu'un Safety Plan est appliqué à un `WORKORDER`, ses composants (dangers, précautions, LOTO, permis) sont transférés et deviennent des exigences pour l'exécution de la tâche. Cela assure que les techniciens sont pleinement informés des risques et des mesures à prendre, et que les approbations nécessaires sont obtenues. Ce processus est essentiel pour la traçabilité et la conformité aux normes de sécurité.
- Application Manuelle — Un utilisateur peut sélectionner et appliquer un Safety Plan existant à un `WORKORDER` via l'application `Work Order Tracking`. Cela est souvent utilisé pour des situations non standardisées ou des ajustements spécifiques.
- Application Automatique — Les Safety Plans peuvent être automatiquement associés à un `WORKORDER` si l'actif (`ASSET`) ou l'emplacement (`LOCATION`) spécifié dans le `WORKORDER` est lié à un Safety Plan prédéfini. Cette automatisation est particulièrement utile pour les tâches récurrentes ou les zones à risque constant.
- Héritage des Job Plans — Si un `JOBPLAN` est utilisé pour créer un `WORKORDER` et que ce `JOBPLAN` est associé à un Safety Plan, ce dernier sera automatiquement appliqué au `WORKORDER` généré.
- Validation et Approbation — L'application d'un Safety Plan peut déclencher des workflows d'approbation spécifiques, notamment pour les permis de travail, garantissant que toutes les parties prenantes valident les mesures de sécurité.
- Mise à jour des Statuts — Les statuts des éléments de sécurité (par exemple, un permis approuvé ou un LOTO terminé) sont mis à jour au fur et à mesure de l'avancement du `WORKORDER`, offrant une visibilité en temps réel sur l'état de la sécurité.
🔄 Cycle de vie d'un Safety Plan appliqué
Le cycle de vie d'un Safety Plan, une fois appliqué à un `WORKORDER`, suit une séquence logique qui garantit la prise en compte des mesures de sécurité à chaque étape du processus de travail. Ce cycle commence par la planification et se termine par la clôture du travail, avec des vérifications et des validations à chaque phase critique. Comprendre ce workflow est essentiel pour les gestionnaires de la sécurité et les techniciens.
Chaque transition d'état est souvent associée à des actions spécifiques dans Maximo, telles que la génération de permis, la vérification des LOTO, ou la validation des précautions. Ce processus structuré minimise les risques d'oubli et assure une conformité continue, renforçant ainsi la culture de sécurité au sein de l'organisation.
⚠️ Pièges IBM
Un piège courant est de créer des Safety Plans robustes mais de ne pas les intégrer correctement aux processus de création des `WORKORDER`. Les étudiants peuvent penser qu'un Safety Plan existe suffit, alors qu'il doit être explicitement lié à l'actif, à l'emplacement ou au `JOBPLAN` pour être automatiquement appliqué, ou être appliqué manuellement. Si cette intégration est manquante, les techniciens pourraient exécuter des travaux sans les précautions de sécurité requises, annulant l'objectif du plan.
Il est facile de confondre la définition et l'application des dangers (`HAZARDS`) et des précautions (`PRECAUTIONS`) dans un Safety Plan. Un danger est une condition ou un acte qui a le potentiel de causer des blessures ou des dommages, tandis qu'une précaution est une mesure prise pour éviter ou contrôler ce danger. Une erreur fréquente est de lister une précaution comme un danger, ou vice-versa. Par exemple, "Équipement non verrouillé" est un danger, tandis que "Procédure LOTO appliquée" est une précaution. L'examen peut présenter des scénarios où cette distinction est floue.
Les Safety Plans, comme de nombreux autres objets dans Maximo, sont soumis à des restrictions de sécurité. Un piège potentiel est de ne pas accorder les droits d'accès appropriés aux groupes d'utilisateurs concernés. Par exemple, un groupe de planificateurs pourrait avoir besoin de créer et de modifier des Safety Plans, tandis qu'un groupe de techniciens n'aurait besoin que d'un accès en lecture seule pour les consulter sur les `WORKORDER`. Une mauvaise configuration des droits dans l'application `Security Groups` peut empêcher les utilisateurs d'accéder ou d'appliquer correctement les Safety Plans, entraînant des retards ou des non-conformités.
🎯 Carte mémoire
Quel est le rôle principal d'un Safety Plan dans Maximo et comment est-il appliqué à un ordre de travail ?
Le rôle principal d'un Safety Plan est de définir un ensemble structuré de mesures de sécurité (dangers, précautions, LOTO, permis) pour des tâches ou environnements spécifiques. Il est appliqué à un `WORKORDER` soit manuellement par l'utilisateur, soit automatiquement si l'actif, l'emplacement ou le `JOBPLAN` du `WORKORDER` est lié à un Safety Plan existant, garantissant ainsi que les précautions sont prises avant l'exécution des travaux.
Quels sont les composants essentiels d'un Safety Plan et pourquoi sont-ils importants pour la conformité et la sécurité ?
Les composants essentiels incluent les `HAZARDS` (dangers), les `PRECAUTIONS` (précautions), les procédures `LOTO` (Lockout/Tagout) et les `PERMITS` (autorisations de travail). Ils sont importants car ils fournissent une feuille de route complète pour identifier les risques, atténuer les dangers, isoler les sources d'énergie et obtenir les approbations nécessaires, assurant ainsi la conformité réglementaire et la protection du personnel.
Comment Maximo gère-t-il la réutilisabilité et la standardisation des Safety Plans ?
Maximo gère la réutilisabilité en permettant la création de Safety Plans génériques qui peuvent être associés à plusieurs actifs, emplacements ou `JOBPLAN`. Cette approche standardise les pratiques de sécurité en garantissant que les mêmes mesures sont appliquées pour des situations similaires, réduisant les erreurs et améliorant l'efficacité de la gestion de la sécurité à travers l'organisation.
Correct: A, B
Pourquoi A, B — La documentation IBM Maximo Manage définit explicitement la procédure LOTO comme un Tag Out (« how to take work assets out of service and place them back in service ») constitué d'une séquence de lock out operations. Le Tag Out identifie ce qui est isolé (Asset OU Location — champs mutuellement exclusifs per Maximo Secrets) et décrit les étapes ; chaque Lock Out trace un cadenas physique appliqué à une source d'énergie (électrique, hydraulique, pneumatique…). Le Type d'un Tag Out peut être Electrical, Mechanical, Alarm Override ou Process. Stockage au niveau Site. Une fois le LOTO créé, il est référencé depuis un Hazard, puis propagé aux Work Orders via le Safety Plan.
Pourquoi C est faux — D2 invented : « LOTO Incident Form » n'est pas un record de Manage core. Les incidents LOTO (cadenas forcé, oubli de remise en service) sont tracés dans l'application Incidents générale ou via un Investigation record ; aucune entité dédiée « LOTO Incident Form » n'existe dans le schéma Safety v9.
Pourquoi D est faux — D4 adjacent app : Hazmat Route Card relève du module Shipping / Transportation (Dangerous Goods Manifest), pas de LOTO. La confusion possible vient de la co-présence HAZMAT + LOTO dans les déploiements Oil & Gas, mais les route cards sont des artefacts de logistique de matières dangereuses, pas d'isolation d'énergie.
Why E wrong — D1 legacy : le décommissionnement d'asset (changement de statut vers DECOMMISSIONED) relève du lifecycle IBM ISO 55000 / retirement phase. LOTO adresse une isolation temporaire pour travaux ; le décommission est permanent. Ces deux concepts touchent l'asset mais à des niveaux orthogonaux — piège pour le candidat qui mélange « mise hors service » au sens sécurité et au sens lifecycle.
- IBM Docs — Lock Out / Tag Out application : Tag out procedures + lock out operations
- Maximo Secrets — Lock Out / Tag Out (Portaluri, 2021) : Type values (Electrical/Mechanical/Alarm/Process) + Asset|Location mutual exclusivity
- Interloc — Managing Isolations in Maximo Oil & Gas : LOTO vs Permit To Work distinction
- Maximo Secrets — HSE Application Maps (2018) : Data model Safety module
Bonne réponse : A
Pourquoi cette question existe — STU §9.2 — cette question teste la compréhension de l'application Work Permit dans Maximo Manage, qui est essentielle pour gérer les permis de travail liés aux ordres de travail. Les distracteurs montrent des erreurs courantes : confondre les fonctionnalités des Storerooms (D5), attribuer des tâches non liées (D2), et mélanger les processus de maintenance préventive (D6). En pratique, l'omission de lier les permis de travail aux ordres de travail est une erreur fréquente.
Le contexte théorique d'abord — L'application Work Permit permet de gérer les permis de travail formels, tels que les permis pour travaux à chaud, espaces confinés, et travaux électriques. Ces permis sont liés aux ordres de travail pour assurer la sécurité et la conformité. Les permis de travail doivent être approuvés et suivis tout au long du processus de travail.
Ce que Maximo en fait — version opérationnelle — Dans l'application Work Permit, un utilisateur crée un nouveau permis de travail en spécifiant le type de permis (ex. travaux à chaud), le site, et l'ordre de travail associé. Le permis passe ensuite par un processus d'approbation avant d'être émis. Une fois émis, le permis est suivi jusqu'à sa clôture, assurant que toutes les étapes de sécurité sont respectées.
Exemple chiffré — Site GATINEAU : 12 permis de travail émis ce mois-ci, dont 8 pour travaux à chaud, 3 pour espaces confinés, et 1 pour travaux électriques. Sur ces 12 permis, 10 ont été approuvés et 2 sont en attente d'approbation.
Analogie quotidienne — C'est comme un système de laissez-passer dans un bâtiment sécurisé : chaque personne doit obtenir un laissez-passer spécifique pour accéder à certaines zones, et ce laissez-passer doit être validé par la sécurité avant d'être utilisé.
Pourquoi B est faux — Pattern D5 champ-frère : les Storerooms gèrent les items en rotation, mais cela n'a rien à voir avec les permis de travail.
Pourquoi C est faux — Pattern D2 inventé : la génération de documents d'Installation Qualification n'est pas une fonction de l'application Work Permit.
Pourquoi D est faux — Pattern D6 mauvaise-app : les changements de fréquence de maintenance préventive sont gérés dans l'application Preventive Maintenance, pas dans Work Permit.
- Work Permit — gestion des permis de travail formels.
- Work Order — ordre de travail lié au permis.
- Approval Process — processus d'approbation des permis.
- Safety Compliance — conformité aux normes de sécurité.
- Tracking — suivi des permis jusqu'à leur clôture.
- Work Permit gère les permis de travail liés aux ordres de travail.
- Les permis doivent être approuvés et suivis jusqu'à leur clôture.
- Les Storerooms et Preventive Maintenance ne gèrent pas les permis de travail.
- STU sub-objective §9.2 — Work Permit application
- [EOTRAG] Query — « Maximo Work Permit application purpose » (confidence 0.92)
- master-map.pdf p.201-203 — IBM Docs Work Permit
Bonne réponse : A,B,C
Pourquoi cette question existe — STU §9.2 — cette question valide la compréhension des types standard de hazards (risques) dans Maximo Manage. Les distracteurs testent la capacité à distinguer les risques physiques/chimiques/biologiques (HSE) des risques opérationnels (finance, réputation). En pratique terrain, cette distinction est cruciale pour configurer correctement les Safety Plans et associer les bonnes précautions.
Le contexte théorique d'abord — Dans Maximo, un Hazard est défini comme une situation menaçant la vie, la santé, les biens ou l'environnement. Les types canoniques sont : Physical (mécanique, électrique), Chemical (exposition HAZMAT), et Biological (agents pathogènes). Ces catégories déterminent les Precautions associées dans l'application Safety Plans.
Ce que Maximo en fait — version opérationnelle — Dans l'application Hazards : 1) Créer un nouveau hazard, 2) Cocher Can Have Precautions, 3) Sélectionner le type (Physical/Chemical/Biological). Puis dans Safety Plans : associer le hazard à un plan via l'onglet Hazards and Precautions et préciser éventuellement un Related Asset ou Related Location.
Exemple chiffré — Site industriel : 12 hazards Physical (dont 5 électriques), 8 Chemical (dont 3 HAZMAT niveau 3), 4 Biological (dont 2 pathogènes de classe B). Safety Plan "Maintenance réservoir" : combine 2 hazards Chemical (solvants) + 1 Physical (hauteur).
Analogie quotidienne — Comme les pictogrammes de danger sur les produits ménagers : flammes (Physical), tête de mort (Chemical), biohazard (Biological) — alors que le prix ou la marque (Financial/Reputational) n'indiquent pas un risque direct.
Pourquoi D est faux — Pattern D6 Mauvaise-app : Financial est un risque opérationnel, géré dans d'autres modules (ex. Purchasing), pas comme hazard HSE.
Pourquoi E est faux — Pattern D7 Inexistant : Reputational n'est pas un type de hazard reconnu dans l'application Hazards.
Pourquoi F est faux — Pattern D4 Demi-vérité : Schedule impacte la planification, mais ne constitue pas un danger physique/chimique/biologique.
- Hazard — situation menaçant vie/santé/biens/environnement.
- Precaution — mesure de sécurité associée à un hazard.
- Safety Plan — ensemble de hazards/précautions pour une tâche.
- Related Asset/Location — équipement/lieu spécifique à risque.
- Can Have Precautions — flag activant les précautions associées.
- 3 types hazards : Physical, Chemical, Biological (HSE).
- Financial/Reputational ne sont pas des hazards dans Maximo.
- Associer hazards + precautions dans Safety Plans.
- STU sub-objective §9.2 — Hazard types and Safety Plans
- [EOTRAG] Query — « Maximo Hazards application types Physical Chemical Biological » (confidence 0.91)
- master-map.pdf p.312-315 — IBM Docs HSE Management
Bonne réponse : C
Pourquoi cette question existe — STU §9.2 — la question teste la compréhension de la manière dont Maximo Manage impose la validation d'un Work Permit avant l'approbation d'un Work Order. Les distracteurs montrent les erreurs typiques : penser que la validation est hard-codée (D2), croire que Maximo crée automatiquement un permis (D10), ou ignorer que les permis peuvent bloquer des transitions (D4). En pratique, cette validation est cruciale pour la conformité aux normes de sécurité.
Le contexte théorique d'abord — Dans Maximo Manage, un Work Permit est un document essentiel pour garantir la sécurité lors de l'exécution d'un Work Order. Le système vérifie que le permis est actif et approuvé avant de permettre l'approbation du Work Order. Cette validation est gérée via des workflows ou des escalations qui inspectent le statut du permis lié.
Ce que Maximo en fait — version opérationnelle — Lorsqu'un utilisateur tente d'approuver un Work Order (APPR), le workflow associé vérifie le statut du Work Permit lié. Si le permis n'est pas actif ou approuvé, la transition est rejetée. Cette logique est configurée dans l'application Workflow Designer ou via des Escalations pour garantir que les règles de sécurité sont respectées.
Exemple chiffré — Site BEDFORD : Work Order WO1234 est lié à Work Permit WP5678. Si WP5678 est en statut ACTIVE et APPROVED, WO1234 peut être approuvé. Si WP5678 est en statut EXPIRED, WO1234 reste en statut WAPPR jusqu'à ce que le permis soit mis à jour.
Analogie quotidienne — C'est comme un contrôleur de sécurité à l'entrée d'un chantier : sans badge valide, tu ne peux pas entrer, même si tu as toutes les autorisations nécessaires.
Pourquoi A est faux — Pattern D2 Inventé : Maximo n'utilise pas de triggers hard-codés pour cette validation.
Pourquoi B est faux — Pattern D10 Procédure-plausible : Maximo ne crée pas automatiquement un Work Permit lors de l'approbation d'un Work Order.
Pourquoi D est faux — Pattern D4 Demi-vérité : Les Work Permits ne sont pas seulement consultatifs ; ils peuvent bloquer des transitions de statut si les conditions ne sont pas remplies.
- Workflow — séquence automatisée de validations et d'actions.
- Escalation — règle conditionnelle déclenchée par un événement.
- Work Permit — document validant les conditions de sécurité.
- Work Order — tâche planifiée nécessitant un permis.
- Statut — état d'un objet dans Maximo (ex.
ACTIVE,APPROVED).
- Workflow ou escalation vérifie le statut du Work Permit.
- Permis actif et approuvé requis pour approuver un Work Order.
- Pas de création automatique de permis lors de l'approbation.
- STU sub-objective §9.2 — Validation des Work Permits
- [EOTRAG] Query — « Maximo Work Permit validation Work Order approval » (confidence 0.92)
- master-map.pdf p.758-760 — IBM Docs Workflow and Escalations
Next step: take the official IBM Assessment Test ($30). If score >75%, book the real exam on Pearson VUE ($200).
IBM C1000-208
Maximo Manage v9.1 Inventory Management — Associate
Comment utiliser ce plan
- Cliquez une leçon dans la barre latérale — chaque leçon = 1 écran
- Chaque leçon a 2 onglets : 📚 Leçon (théorie) et 🎯 Scénarios d’examen (cas réels)
- Cocher « Marquer comme étudiée » pour suivre la progression (enregistrée dans le stockage local du navigateur)
- Utilisez ← Précédent / Suivant → pour naviguer linéairement
- Ordre recommandé : Section 4 (24%) en premier → Section 1 (17%) → Section 2 (15%) → Section 3 (15%) → Section 7 (12%) → Section 6 (10%) → Section 5 (7%)
Accès rapide par priorité
Item Issues
Item Transfers
Item Master et Flags
Paramètres de Reorder
Ajustements de coût
Count Books
Stratégie d'étude en 6 semaines
- S1 — Section 4 (4 leçons, 24%) + pratique sur l'app Inventory Usage
- S2 — Section 1 (2 leçons, 17%) + Section 2 (2 leçons, 15%)
- S3 — Section 3 (3 leçons, 15%) + Section 7 (2 leçons, 12%)
- S4 — Section 6 (2 leçons, 10%) + Section 5 (3 leçons, 7%) + révision des flashcards
- S5 — Examens blancs chronométrés + IBM Pearson VUE Assessment Test (30 $)
- S6 — Consolidation uniquement, pas de nouveau contenu
Items / Tools / Services Master et Flags

📋 Objectifs IBM
- Créer un nouvel enregistrement Item — Insertion · application d'une classification · ajout d'un numéro d'item alternatif · association d'un fournisseur · passage du statut à Active.
- Ajouter un Item à un Storeroom — un seul Storeroom ou plusieurs Storerooms.
- Créer une Item Assembly Structure (IAS) — décrire l'usage · créer un item kit · créer un item rotating avec des pièces de rechange.
- Créer un Condition Enabled Item — marquer comme condition-enabled · expliquer comment les items condition-enabled sont valorisés.
- Gérer un Consignment Item — propriété et localisation · quels items peuvent être marqués consignment · comment les factures sont générées · spécifier les détails de consignment dans le Storeroom.
- Expliquer les flags d'un Item Master — Rotating? · Condition Enabled? · Kit? · Capitalized? · Inspect on Receipt? · Add as Spare Part? · Attach to Parent Asset on Issue? · Tax Exempt?
- Associer un Meter / Meter Group — types d'items éligibles · transactions liées à l'issue · impact de la référence à un meter group.
- Expliquer les valeurs Item Status — Pending · Planning · Active · Pending Obsolete · Obsolete — et les règles d'héritage entre les niveaux Organization / Item Master / Inventory.
- Créer un nouveau Tool Item — flags Tool (Capitalized? · Rotating? · Outside? · Inspect on Receipt? · Tax Exempt? · Crew?).
- Créer un nouveau Service Item — flags Service (Prorate? · Inspection Required? · Tax Exempt?).
- Ajouter un Tool à un Storeroom.
💡 Points clés
- L'Item Master est la source unique de vérité pour tout matériel qui circule dans Maximo. Chaque enregistrement Item porte un Item Number unique, une Description, une Order Unit (OU — l'unité d'achat, ex.
EA,BOX,L), une Issue Unit (IU — l'unité de consommation, ex.EA) et une classification Commodity Group / Commodity. Une fois créé, l'enregistrement Item peut être ajouté à un ou plusieurs Storerooms (les lieux de stockage en entrepôt) pour devenir un item en stock. - Huit flags sur l'Item Master entraînent des comportements radicalement différents en aval. Chacun est une case à cocher qui, une fois enregistrée, se verrouille (Rotating?, Capitalized?, Condition Enabled?) ou reste modifiable (Inspect on Receipt?, Tax Exempt?). Un piège classique d'examen consiste à mémoriser les noms sans comprendre la cascade de conséquences que chaque flag déclenche. Voici la liste avec leur effet :
- Rotating? — Lorsqu'il est coché, chaque réception de cet item crée un enregistrement Asset avec un numéro de série unique (
ASSETNUM). Requis pour appliquer une Item Assembly Structure à un asset, pour utiliser la méthode de coût ASSET, et pour suivre les cycles de réfection. Ne peut pas être décoché une fois qu'un seul asset rotating a été réceptionné. - Condition Enabled? — Active l'onglet Condition Codes. Les balances de stock sont alors maintenues par condition (ex. NEW vs REFURBISHED) et chaque issue est valorisée à
NEW_cost × condition_rate. D'après le SAM Q9, le flag se règle dans l'application Item Master, pas dans l'application Inventory ni dans Storerooms. - Kit? — Marque le parent d'une Item Assembly Structure comme un kit. L'issue du kit décrémente tous les items enfants en une seule transaction ; le retour du kit les réincrémente tous. Utilisé pour les kits PM (ex. kit annuel de remplacement de filtres).
- Capitalized? — Route la valeur de l'item vers le compte GL Capital à la réception au lieu du compte Expense. Typique pour les assets destinés à être amortis. Capitalized + Rotating est la combinaison classique pour les équipements majeurs susceptibles d'être refaits.
- Inspect on Receipt? — Force chaque réception PO de cet item à atterrir dans une Holding Location avec le statut
WINSP(en attente d'inspection). La balance de stock n'est pas incrémentée dans le Storeroom actif tant que la QA n'a pas approuvé. Requis pour les pièces sécuritaires ou réglementées. - Add as Spare Part? — Lorsque l'item est issué à un Work Order sur un asset parent, Maximo propose de l'ajouter automatiquement à la liste Spare Parts de cet asset. Accélère la construction du catalogue de pièces de rechange sans projet MDM dédié.
- Attach to Parent Asset on Issue? — À l'issue vers un WO, Maximo demande un asset parent et, si fourni, attache l'item (typiquement un sous-composant) en tant qu'enregistrement asset enfant. Utilisé avec les sous-ensembles rotating.
- Tax Exempt? — Supprime l'application des codes de taxe à la génération PO/PR. Requis pour les organismes de charité, le gouvernement et les transferts intra-entreprise dans certaines juridictions.
- Rotating? — Lorsqu'il est coché, chaque réception de cet item crée un enregistrement Asset avec un numéro de série unique (
- Les statuts d'Item suivent une échelle à 5 paliers : Pending → Planning → Active → Pending Obsolete → Obsolete. Pending signifie brouillon (item pas encore prêt à être commandé ou issué). Planning est le plus contre-intuitif : l'item peut déjà être sur un Job Plan, sur une PR, sur un candidat de reorder, mais ne peut pas être issué ; le SAM Q4 teste explicitement que les items PLANNING sont inclus dans le processus de reorder. Active = cycle de vie complet. Pending Obsolete bloque les nouvelles commandes mais permet d'écouler le stock existant. Obsolete bloque toutes les transactions.
- L'héritage des statuts est une cascade à 3 niveaux : le statut est défini au niveau Item Master (enregistrement item au niveau Org), hérité par Item Org Details (par organisation), puis par l'enregistrement Inventory (par storeroom). Un item Active au Master peut encore être Pending dans un Storeroom spécifique — il doit y être activé explicitement. Ce modèle à trois niveaux est le piège le plus fréquent de la Section 1.
- Item Assembly Structure (IAS) définit une Bill of Materials (BOM) pour un item. Selon [IBM-Maximo-9], on ne peut appliquer une IAS à un asset ou à un Operating Location que si l'item parent est Rotating. Le SAM Q1 confirme qu'une fois créés, les éléments enfants peuvent être ajoutés ou supprimés, et les quantités modifiées — l'IAS est mutable, pas figée.
- Les Tools diffèrent des Items par un enregistrement Master séparé (application Tools) et par leur ensemble de flags : Capitalized?, Rotating?, Outside? (l'outil peut être loué à l'externe), Inspect on Receipt?, Tax Exempt?, Crew? (l'outil appartient à une équipe plutôt qu'à un Storeroom). Les Tools sont suivis en temps (heures/jours) pour les taux de facturation, plutôt qu'en quantité consommée.
- Les Services sont des items non physiques facturés pour de la main-d'œuvre, du transport, de la calibration, etc. Leurs flags sont Prorate? (coût réparti sur plusieurs lignes de réception), Inspection Required?, Tax Exempt?. Les Services n'ont ni balance de stock ni location de storeroom — ils n'existent que sur les lignes PR/PO/Invoice.
- Les consignment items sont physiquement dans votre storeroom mais appartiennent au fournisseur. Coût on hand = 0 $ ; le fournisseur facture à la consommation (l'issue déclenche un voucher AP automatique). Le consignment se règle sur l'enregistrement Inventory (Storeroom × Item) — pas sur l'Item Master seul — donc le même item peut être consignment dans un storeroom et owned dans un autre.
- Meter / Meter Group sur un item rotating permet à chaque asset issué de démarrer avec la lecture meter du parent, ce qui assure un suivi continu des heures de fonctionnement à travers les cycles de réfection. Un Meter Group regroupe plusieurs meters (heures de fonctionnement, compteur de cycles, carburant) pour qu'ils progressent ensemble.
- Exemple chiffré — Valorisation condition-enabled : coût NEW d'un moteur = 10 000 $. Condition codes : NEW = 100%, REFURBISHED = 70%, USED = 50%. Une issue REFURBISHED facture le WO à 7 000 $. Les balances de stock sont tenues par condition (ex. 5 NEW, 3 REFURBISHED, 1 USED), chaque ligne valorisée à son taux. Changer le taux rétroactivement ne recoûte pas le stock on-hand — seules les futures issues utilisent le nouveau taux [EOTRAG query 9].
stateDiagram-v2 direction LR [*] --> PENDING: Insertion d'un
nouvel Item record PENDING --> PLANNING: Promotion pour
usage planning PLANNING --> PENDING: Retour arrière
(aucune transaction) PLANNING --> ACTIVE: Passage à Active
(item utilisable) PENDING --> ACTIVE: Activation directe
(saute Planning) ACTIVE --> PENDING_OBSOLETE: Marquage
obsolescence PENDING_OBSOLETE --> ACTIVE: Réactivation
(intention inversée) PENDING_OBSOLETE --> OBSOLETE: Balance = 0
ET aucune txn ouverte OBSOLETE --> [*] note right of PENDING Aucun PR / PO / issue / transfer Sert au seed special-order end note note right of ACTIVE Toutes transactions autorisées PR, PO, issue, transfer, count end note note left of OBSOLETE Terminal. Pas de réactivation. Aucune transaction autorisée. end note
graph TD A["MOTOR-ASSY
Item parent rotating
qté : 1"]:::parent A --> B["PUMP-CENTRIFUGAL
qté : 1"]:::child A --> C["BEARING-6205
qté : 2"]:::child A --> D["SEAL-MECH
qté : 1"]:::child E[/"Arbre mutable
Ajout / suppression d'enfants
Modification des quantités
(SAM Q1 — réponse c)"/]:::note A -.-> E classDef parent fill:#1D9E75,stroke:#178A66,color:#FFFFFF,font-weight:600; classDef child fill:#F1F5F9,stroke:#94A3B8,color:#0F172A; classDef note fill:#FEF3C7,stroke:#F59E0B,color:#78350F,font-style:italic;
| Flag | Effet quand coché | Réversible ? | Événement déclencheur |
|---|---|---|---|
| Rotating? | Chaque réception crée un Asset record avec un ASSETNUM unique. Requis pour le cost type ASSET et les Item Assembly Structures. |
Non (verrouillé dès la première réception d'asset) | Réception PO |
| Condition Enabled? | Active l'onglet Condition Codes. La balance de stock est maintenue par condition (NEW, USED, REFURB). Valeur d'issue = base_cost × condition_rate. | Non (verrouillé dès que balance > 0) | Issue + réception |
| Kit? | Marque le parent d'une Item Assembly Structure comme kit. L'issue du kit décrémente tous les items enfants en une seule transaction. | Oui | Issue |
| Capitalized? | Route la valeur de l'item vers le compte GL Capital à la réception au lieu du compte Expense. Typique pour les assets destinés à être amortis. | Non (verrouillé dès la première réception) | Réception |
| Inspect on Receipt? | Force chaque réception PO de cet item à atterrir dans une Holding Location avec le statut WINSP. La balance de stock n'est pas incrémentée dans le storeroom actif tant que la QA n'a pas approuvé. |
Oui | Réception PO |
| Add as Spare Part? | Quand l'item est issué à un Work Order sur un asset parent, Maximo propose de l'ajouter automatiquement à la liste Spare Parts de cet asset. | Oui | Issue vers WO |
| Attach to Parent Asset on Issue? | À l'issue vers un WO, Maximo demande un asset parent et, si fourni, attache l'item en tant qu'enregistrement asset enfant. Utilisé avec les sous-ensembles rotating. | Oui | Issue vers WO |
| Tax Exempt? | Supprime l'application des codes de taxe à la génération PO/PR. Requis pour les organismes de charité, le gouvernement et les transferts intra-entreprise dans certaines juridictions. | Oui | Génération PR / PO |
⚠️ Piège IBM
"Active à l'Item Master = commandable partout" — faux, et IBM teste cette idée fausse exacte sous plusieurs variantes.
- Un item Active au niveau Item Master peut encore être Pending dans Item Org Details (par Org) et Pending dans Inventory (par Storeroom). Les trois doivent être Active pour que l'item participe aux transactions PR/PO et issue dans ce Storeroom.
- PLANNING n'est pas synonyme de « brouillon, ne pas commander ». Les items PLANNING sont reorderables — confirmé par le SAM Q4. Seuls PENDING et OBSOLETE bloquent le reorder.
- Marquer un item comme Condition-Enabled se fait dans l'application Item Master — pas dans Inventory, Storerooms ou Condition Codes. L'application Condition Codes ne fait que définir les codes ; l'activation par item se fait sur l'enregistrement Master.
🎯 Carte mémoire
Q. Quel flag d'Item Master, une fois qu'un seul asset rotating a été réceptionné, ne peut plus jamais être décoché, et quelle méthode de coût active-t-il ?
Afficher la réponse
Le flag Rotating?. Dès qu'au moins un asset rotating (avec un ASSETNUM sérialisé) existe, on ne peut plus revenir l'item à non-rotating. Il active la méthode de coût ASSET (chaque asset sérialisé porte son propre coût d'achat + cumul des coûts de réparation) et il est requis pour appliquer une Item Assembly Structure à un asset.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct : C
Pourquoi cette question existe — IBM teste si le candidat a compris qu'un Item Assembly Structure (IAS) est une structure vivante, mutable au fil de la vie de l'actif, et non une définition figée à la création. Le piège classique est de croire qu'on doit recréer un nouvel item parent dès qu'une nomenclature évolue, ce qui mènerait à une multiplication ingérable d'items pour la même fonction technique.
Le contexte théorique d'abord — Un Item Assembly Structure est l'équivalent Maximo d'un Bill of Materials (BOM) : un item parent et ses items enfants avec leurs quantités. Théoriquement, un BOM en gestion d'actifs (ISO 14224) doit pouvoir évoluer pour refléter trois cycles : (1) les modifications d'ingénierie (engineering change orders), (2) les retours d'expérience de fiabilité (un composant remplacé par un meilleur), (3) la disponibilité fournisseur (substitut homologué). Toute structure rigide est par définition antinomique de l'asset management ISO 55000, qui exige une amélioration continue [EOTRAG query 6 + query 15].
Ce que Maximo en fait — version opérationnelle — Dans Item Master > sélection de l'item parent > Select Action > Item Assembly Structure, le planificateur peut à tout moment ajouter des enfants (bouton New Row), supprimer des enfants (icône poubelle), ou modifier la colonne Quantity. Les modifications appliquent à nouvelles applications du IAS (nouveaux assets sur lesquels on copie la structure), mais les assets existants doivent être mis à jour individuellement via Apply Item Assembly Structure sur leur fiche Asset — c'est le compromis IBM entre flexibilité et stabilité historique. Ce comportement est documenté dans master-map.pdf p.787-832 (module Inventory).
Exemple chiffré — Le moteur 5-HP est l'item parent, sa structure d'origine = (1× rotor, 2× bearing-A, 2× gasket-B). Six mois plus tard, le bureau d'études remplace bearing-A par bearing-A2 (sealed) et passe gasket-B de 2 à 4 unités. Le planificateur ouvre l'IAS, supprime la ligne bearing-A, ajoute bearing-A2 (qty 2), modifie la qty de gasket-B (2 → 4), sauvegarde. Les 10 actifs déjà déployés gardent leur ancienne structure dans leur historique ; les nouveaux actifs reçus à partir de demain hériteront de la nouvelle.
Analogie quotidienne — C'est une recette de famille dans un classeur : on peut ajouter un ingrédient, en retirer un autre, doubler le sucre — la recette n'est pas gravée, elle est éditable à chaque saison. Mais les gâteaux déjà cuits ne se modifient pas rétroactivement.
Pourquoi A est faux — A affirme que la structure est immuable une fois créée. C'est un classique piège D7 (Non-existent) : aucune contrainte technique Maximo ne fige un IAS. La confusion vient probablement de l'expérience d'autres systèmes (certaines configurations SAP PP gèrent des "engineering change masters" qui verrouillent les BOM) ou de l'idée erronée que la traçabilité interdit la modification. Si A était vrai, la maintenance d'un parc d'actifs sur 30 ans serait impossible — chaque évolution de pièce détachée exigerait un nouvel item parent. La bonne pratique ISO 55000 exige justement la mutabilité auditée : l'historique des changements est conservé, mais la structure courante évolue.
Pourquoi B est faux — B est une demi-vérité (D4 Partial-truth) : oui les quantités peuvent changer, mais B prétend qu'uniquement les enfants rotatifs sont modifiables. Faux : tous les enfants — rotatifs et non rotatifs — sont modifiables en quantité, et on peut aussi ajouter/supprimer des enfants quel que soit leur type. Le piège est d'avoir mémorisé que "Rotating" est lié à IAS (vrai pour le parent, qui doit être rotating si on applique l'IAS à un asset) et d'avoir transposé cette contrainte aux enfants — ce qui est une erreur classique de généralisation. La règle réelle est asymétrique : le parent doit être rotating, les enfants peuvent être de tout type.
Pourquoi D est faux — D est l'inverse logique de la bonne réponse (D3 Inverse) : on peut ajouter/supprimer mais pas modifier les quantités. Cette polarité inverse est le piège le plus dangereux car elle est partiellement vraie (ajout/suppression OK) et glisse une fausseté précise (quantité fixe). Aucune justification technique : la colonne Quantity dans la grille IAS est éditable comme toute autre cellule. La trace pour le détecter : un IAS de PM kit (ex. 12 filtres + 2 joints + 1 lubrifiant) doit pouvoir évoluer si on optimise la nomenclature après un Reliability-Centered Maintenance (RCM) review — sinon RCM serait incompatible avec Maximo.
- IAS (Item Assembly Structure) : BOM parent + enfants. Mutable. Applicable à un asset/location uniquement si parent = Rotating.
- Kit : item parent flag Kit?=Y + IAS. Issue/return groupé. Souvent non-rotating (kit consommable de PM).
- Rotating Item : flag Rotating?=Y. Chaque réception = nouvel asset record sérialisé. Cost method = ASSET. Irréversible une fois reçu.
- Modifier l'IAS : add/delete child + change qty à tout moment. Affecte les nouvelles applications, pas les existantes.
- IAS est mutable : add/delete enfants + change quantités.
- Parent doit être Rotating pour appliquer IAS à un asset/location.
- Modifications n'affectent pas les actifs déjà déployés (history-safe).
- Kit = IAS + flag Kit?, déclenche issue/return groupé sur WO.
- SAM Sample Question 1 — IBM C1000-208 Sample Test (Section 1.1).
- master-map.pdf p.787-832, IBM Maximo Manage 9 — module Inventory : Item Master > Item Assembly Structure.
- [EOTRAG query 6 — Items rotating / IAS / Kits — IBM-Maximo-9 verbatim « plutôt que de spécifier les pièces composantes sur les 10 enregistrements asset, vous pouvez créer les enregistrements asset et copier l'item assembly structure du moteur de cinq chevaux sur chaque enregistrement »].
Correct : B
Pourquoi cette question existe — IBM teste la compréhension de la conséquence structurelle du flag Rotating?, qui est la création automatique de fiches Asset sérialisées. Le candidat doit distinguer les effets du flag Rotating? (création d'asset) de ceux des flags voisins (Inspect on Receipt? = inspection, Capitalized? = compte GL Capital, Attach to Parent on Issue? = sub-asset on issue). C'est exactement ce type de confusion inter-flags que l'examen sanctionne.
Le contexte théorique d'abord — En gestion d'actifs ISO 14224, un rotating item (alias repairable item ou refurbishable component) est une pièce qui passe sa vie en alternance entre l'usage opérationnel, l'atelier de réparation, et le storeroom — chaque cycle créant une transaction MATUSETRANS / MATRECTRANS qu'il faut tracer par numéro de série [EOTRAG query 14]. Pour assurer cette traçabilité, le système crée une fiche Asset sérialisée par unité physique : c'est le pont conceptuel entre le monde "Item" (un type) et le monde "Asset" (une instance physique). Sans cette dualité, on ne pourrait pas tracer combien de fois ce moteur particulier (S/N MTR-2024-007) a été révisé.
Ce que Maximo en fait — version opérationnelle — Dès qu'on coche Rotating? sur l'Item Master et que l'item passe en statut Active, chaque réception (Receipt > PO Receipt) déclenche la création d'autant de fiches Asset que de quantité reçue. L'utilisateur doit saisir le serial number de chaque unité (ou Maximo l'auto-génère selon la séquence configurée dans Organizations > Asset Numbering). La méthode de coût bascule automatiquement sur ASSET (chaque asset porte son propre coût). Le flag Rotating? est non-réversible dès la première réception — Maximo bloque le décochage.
Exemple chiffré — PO de 5 pompes à $12,000 chacune. À la réception, Maximo crée 5 fiches Asset avec numéros PUMP-2026-001 à PUMP-2026-005, chacune valuée à $12,000. Cinq ans plus tard, PUMP-2026-003 est envoyée en réparation pour $3,500 ; à son retour en stock, sa valeur est de $15,500 (12,000 + 3,500). Si une WO la réquisitionne, le coût qui descend sur la WO est exactement $15,500, pas la moyenne des 5 ($12,700) — la précision du tracking par serial est la justification ROI de la méthode ASSET.
Analogie quotidienne — Pensez aux véhicules d'une flotte d'entreprise : chaque voiture est une instance unique avec son VIN, son carnet d'entretien, sa valeur résiduelle propre. Vous n'achetez pas "5 unités de voiture" interchangeables — vous achetez 5 voitures sérialisées. Le flag Rotating? force Maximo à appliquer ce raisonnement à des pièces industrielles refurbishables.
Pourquoi A est faux — A décrit le comportement du flag Inspect on Receipt?, pas du flag Rotating? (D5 Sibling-field). Le piège est que beaucoup d'items rotatifs sont aussi inspectés à la réception (sécurité, certification), donc le candidat pressé associe les deux. Mais ce sont deux flags indépendants sur le même Item Master : on peut être Rotating + non inspect (un moteur standard livré certifié), ou non-rotating + inspect (un lot de boulons critiques contrôlés). La règle à retenir : Rotating? = serial + Asset record ; Inspect on Receipt? = holding location + statut WINSP avant balance update.
Pourquoi C est faux — C décrit le flag Capitalized? (D5 Sibling-field encore). Capitalized? change la destination GL au receipt (compte Capital vs Expense) ; ça n'a rien à voir avec la création d'une fiche Asset. La confusion est compréhensible car en pratique on coche souvent Capitalized? + Rotating? ensemble pour des équipements majeurs qu'on dépréciera comme actifs comptables. Mais les deux flags sont orthogonaux : on peut être Rotating sans être Capitalized (atelier de location qui passe tout en charge) et Capitalized sans être Rotating (un bâtiment, un véhicule complet acheté en bloc capitalisé mais sans cycle refurb).
Pourquoi D est faux — D mélange les concepts : la réservation se crée sur la WO via Job Plan + Work Order Approval, et non au moment de la réception physique d'un PO (D6 Wrong-app : la création de réservation est dans Work Order Tracking, pas dans Receiving). Une réception alimente le stock disponible pour des réservations existantes ; elle ne crée pas elle-même de nouvelle réservation. Le piège est lexical (le mot "auto-create" résonne avec le comportement Rotating qui crée des Assets) et procédural (les deux applications voisines, Receiving et Work Order Tracking, sont confondues).
- Rotating? → crée 1 Asset record par unité reçue ; cost method = ASSET ; irréversible.
- Condition Enabled? → balances par condition + valuation = NEW × rate.
- Kit? → IAS parent ; issue/return groupé en 1 transaction WO.
- Capitalized? → routing GL Capital au receipt (vs Expense).
- Inspect on Receipt? → holding location + statut WINSP avant active balance.
- Add as Spare Part? → propose ajout à la spare-parts list de l'asset parent à l'issue.
- Attach to Parent Asset on Issue? → crée sub-asset on parent à l'issue WO.
- Tax Exempt? → suppression tax codes sur PR/PO.
- Rotating? = crée 1 Asset record sérialisé par unité reçue.
- Cost method automatique = ASSET (chaque serial son propre coût).
- Flag irréversible une fois la 1ère réception faite.
- Différent de Inspect (QA), Capitalized (GL Capital), Attach (sub-asset on issue).
- master-map.pdf p.787-832, IBM Maximo Manage 9 — module Inventory : Rotating Items.
- [EOTRAG query 6 — Rotating Items, méthode de coût ASSET].
- [EOTRAG query 14 — chaîne MATRECTRANS / MATUSETRANS pour les assets serial-tracked].
Correct :C
Pourquoi cette question existe — Cette question teste la compréhension du modèle 3-niveaux d'héritage de statut de Maximo : Item Master → Item Org Details → Inventory record. C'est l'un des sujets les plus fréquemment incompris en certification car le candidat suppose, par analogie avec d'autres systèmes, qu'un statut Active "au sommet" cascade automatiquement partout. Faux dans Maximo.
Le contexte théorique d'abord — Maximo gère les items selon une hiérarchie multi-tenant : un même Item Number peut exister dans plusieurs Organisations (entité légale) et dans plusieurs Storerooms (warehouses). Pour préserver l'autonomie de chaque Org/Storeroom (cycles d'approbation distincts, fournisseurs locaux, lifecycle propre), le statut est répliqué et géré indépendamment à chaque niveau. C'est un pattern de gouvernance fédérée, normal en EAM industriel multi-sites.
Ce que Maximo en fait — version opérationnelle — Quand vous créez un item avec statut Active dans Item Master, vous activez seulement la "fiche maître" globale. Pour qu'il soit ordonnable au niveau d'une Organisation, il faut activer le record Item Org Details (Item Master > Add Items to Organizations > statut Active). Pour qu'il soit issuable depuis un Storeroom particulier, il faut activer le record Inventory (Inventory app > ouvrir l'item dans le Storeroom > statut Active). Les 3 niveaux doivent être Active. Si l'un des 3 est Pending ou Pending Obsolete, les transactions de ce niveau sont bloquées. Master-map.pdf p.787-832 décrit cette cascade dans la section "Item Statuses".
Exemple chiffré — Item GASKET-001 créé Active au Master. Org BIGCO l'ajoute en statut Pending (le cataloguer veut valider le fournisseur d'abord). Storeroom CENTRAL l'ajoute en statut Active. Résultat : pas de PR possible (Org Pending bloque), pas d'issue possible (le record Inventory hérite indirectement). Une fois Org passé Active, PR/PO et Issue redeviennent possibles. C'est ce délai d'activation 3-étapes qui explique pourquoi l'item paraît "bloqué" à un planificateur impatient.
Analogie quotidienne — C'est comme un nouveau produit dans une chaîne de magasins : le siège peut l'avoir référencé au catalogue national (Master Active), mais chaque région doit l'activer dans son SI (Org Active) et chaque magasin doit le mettre en rayon (Inventory Active) avant qu'un client puisse l'acheter. Trois validations indépendantes par souveraineté locale.
Pourquoi A est faux — A invente une étape "re-save" qui n'existe pas (D10 Procedure-plausible). En Maximo, sauvegarder un changement de statut applique l'effet immédiatement ; il n'y a pas de "commit en deux temps" sur les statuts d'item. Le piège est de transposer une expérience de framework (rebuild, recompile, refresh) vers Maximo, qui est transactionnel pur. La trace pour exclure : si A était vrai, IBM mentionnerait cette étape dans la doc, ce qui n'est pas le cas dans master-map.pdf.
Pourquoi B est faux — B fabrique un seuil de prix pour l'activation (D2 Invented). Aucune logique financière dans Maximo ne lie le statut Active à la valeur unitaire. Le piège est de mélanger deux concepts : (1) le seuil de capitalisation comptable (qui dépend du flag Capitalized? et de la politique GL, typiquement $5,000+), (2) le statut Active. Ce sont deux dimensions orthogonales — un boulon à $0.50 peut être Active, un compresseur à $50,000 peut être Pending tant qu'on attend la validation budgétaire.
Pourquoi D est faux — D suggère une opération de cache/redémarrage (D7 Non-existent). Maximo Manage v9.1 est une appli web transactionnelle stateless ; il n'y a pas de "redémarrage Storerooms app" côté utilisateur. Le piège est de transposer des réflexes serveur (kill -HUP) à un environnement applicatif cliché. Si vous voyez ce type de "tip" dans une réponse, c'est un signal fort de distractor : Maximo n'expose pas de bouton restart applicatif aux utilisateurs métier.
- Niveau 1 — Item Master : fiche maître globale. Statut affecte tous les Orgs / Storerooms en aval.
- Niveau 2 — Item Org Details : fiche par Organization. Doit être Active pour que l'Org puisse émettre PR/PO.
- Niveau 3 — Inventory record : fiche par Storeroom × Item. Doit être Active pour que le Storeroom puisse issuer/recevoir.
- Règle d'or : les 3 niveaux doivent être Active simultanément pour qu'une transaction soit possible. Pending ou Pending Obsolete à un niveau bloque ce niveau et tout ce qui en dépend.
- Statut item = 3 niveaux indépendants : Master / Org / Inventory.
- Active au Master ne propage pas automatiquement aux niveaux inférieurs.
- Une transaction (PR/PO/Issue) exige Active aux 3 niveaux concernés.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Item Status / Item Org Details / Inventory record.
- STU C1000-208 sub-objective 1.1 — "Explain Item Status values and inheritance rules across Organization / Item Master / Inventory levels".
Correct :B
Pourquoi cette question existe — Le statut PLANNING est conceptuellement le plus sournois des 5 statuts d'item (Pending, Planning, Active, Pending Obsolete, Obsolete). Le mot "Planning" suggère intuitivement "pas encore prêt" ou "en cours de définition", ce qui pousserait à le rapprocher de PENDING. Mais Maximo utilise PLANNING pour permettre la préparation de la chaîne logistique : l'item peut être référencé sur un Job Plan, sur un PR/Reorder, sans être encore issuable. C'est exactement la subtilité que SAM Q4 cible.
Le contexte théorique d'abord — En lifecycle management, on distingue plusieurs phases d'introduction d'un nouvel article : draft (concept), engineering release (specs validées), supply preparation (fournisseurs identifiés, premières commandes possibles), full operational (issuable partout). Le statut PLANNING dans Maximo correspond à la phase supply preparation : l'article est suffisamment défini pour qu'on lance les premières commandes (ROP, EOQ déjà saisis), mais pas encore pour qu'on l'issue à une WO en production. La période entre première PR et premier Active peut durer de quelques jours à quelques mois selon les délais fournisseurs.
Ce que Maximo en fait — version opérationnelle — Dans Item Master > Status > Change Status, les transitions autorisées sont : Pending → Planning → Active → Pending Obsolete → Obsolete (avec retours arrière limités). En statut Planning, les opérations autorisées sont : ajout sur Job Plan, ajout sur Spare Parts list, génération de PR/PO via reorder, réception de stock. Les opérations bloquées : Issue à WO, Transfer entre storerooms. Cette distinction "ordonnable mais non issuable" est documentée par SAM Q4 et est confirmée dans master-map.pdf chapitre Inventory.
Exemple chiffré — Lundi : nouvel item BEARING-X4 créé en Pending. Mardi : le bureau d'études valide la fiche, statut → Planning. Mercredi : le planificateur l'ajoute au Job Plan PM-MOTOR-ANNUAL. Jeudi : le cron task de reorder déclenche une PR pour 50 unités (ROP=20, lead time = 21 jours). Vendredi : l'item arrive en réception (3 semaines plus tard). À la réception, le système notifie l'admin pour passer le statut à Active. Statut Active activé : les WOs basées sur PM-MOTOR-ANNUAL peuvent maintenant issuer le bearing. Le délai de 3 semaines a été couvert par PLANNING, sans bloquer la chaîne logistique.
Analogie quotidienne — Pensez à un menu de restaurant où le chef ajoute un nouveau plat : "en cours de préparation" (recette validée, ingrédients commandés au fournisseur, mais pas encore servable au client). Le client peut le voir sur le menu papier (Job Plan), le grossiste reçoit déjà les commandes (PR/Reorder), mais le serveur ne peut pas le proposer à la commande tant que les ingrédients ne sont pas dans la cuisine (statut Active).
Pourquoi A est faux — A est l'inverse exact de la bonne réponse (D3 Inverse). Si PLANNING bloquait Job Plan + reorder, son existence serait inutile (autant rester en Pending). Le piège est de raisonner par symétrie avec PENDING (« préparation » = « rien autorisé »). La vérité Maximo : Pending bloque tout, Planning autorise la chaîne logistique amont, Active autorise tout. SAM Q4 (réponse B « Les items au statut PLANNING peuvent être inclus dans un reorder process ») est la confirmation officielle.
Pourquoi C est faux — C affirme que Planning = Active (D9 Near-synonym). Faux : Active autorise l'Issue à WO, Planning ne l'autorise pas. La différence est exactement le découpage du lifecycle entre "préparation logistique" (Planning) et "exploitation opérationnelle" (Active). Si C était vrai, IBM aurait fusionné les deux statuts. La preuve concrète : essayer une Inventory Usage avec un item Planning → Maximo renvoie l'erreur "Item not active in this Storeroom".
Pourquoi D est faux — D fabrique un sens de fin-de-vie pour PLANNING (D2 Invented). Le statut de fin-de-vie est Pending Obsolete (transitions PR/PO bloquées, issue de stock existant autorisée pour épuisement) puis Obsolete (transitions toutes bloquées). Le piège vient probablement du jargon "decommissioning planning" en asset management — mais en Maximo "Planning" n'a aucun lien avec la décommission.
- Pending — Brouillon. Aucune transaction (ni Job Plan, ni PR, ni Issue). Item en cours de spec.
- Planning — Préparation logistique. Job Plan ✔, Spare Parts list ✔, Reorder ✔, Receiving ✔, Issue ✘.
- Active — Lifecycle complet. Toutes transactions autorisées.
- Pending Obsolete — Phase-out. PR/PO ✘ (pas de nouvelles commandes), Issue ✔ (épuiser le stock).
- Obsolete — Fin de vie. Aucune transaction. Stock résiduel doit être adjusté à zéro avant.
- PLANNING ≠ "draft". C'est "logistique ouverte, opérationnel fermé".
- Un PLANNING item PEUT être reorderé (SAM Q4).
- Seuls Pending et Obsolete bloquent la reorder.
- SAM Sample Question 4 corollaire — IBM C1000-208 Sample Test (Section 2.2).
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Item Statuses lifecycle.
- STU sub-objective 1.1 — Item Status values and inheritance.
Correct :A
Pourquoi cette question existe — La consignation casse l'enchaînement classique receipt → AP voucher → payment. Le candidat doit comprendre que la séparation "propriété physique / propriété légale" décale le fait générateur comptable du receipt vers la consommation. C'est un classique de l'examen car l'erreur de compréhension impacte directement la précision du coût-WO et l'exposition financière.
Le contexte théorique d'abord — Le modèle de Vendor-Managed Inventory (VMI) avec consignation est un arrangement contractuel où le fournisseur conserve la propriété juridique du stock physiquement présent chez le client jusqu'à consommation effective. Cette mécanique apparaît dès SAP/S4HANA (item category K — consignment goods), Infor EAM, Oracle EAM. Avantages : zero working capital côté client, gestion du réapprovisionnement déléguée, pas de risque d'obsolescence pour le client. Inconvénients : visibilité limitée des prix, lock-in fournisseur, gestion des litiges shrink complexe [EOTRAG query 8].
Ce que Maximo en fait — version opérationnelle — Dans Maximo Manage v9.1, le flag Consignment est positionné sur la fiche Inventory (Storeroom × Item) et non sur l'Item Master globalement — ce qui permet à un même item d'être consignment dans Storeroom A et possédé dans Storeroom B. À la réception (PO type CONSIGNMENT), le mouvement crée une ligne MATRECTRANS avec cost = 0 ; le balance INVBALANCES augmente mais aucun GL voucher n'est généré. À l'issue (WO ou autre transaction), Maximo crée automatiquement une transaction CONSUMPTION qui : (1) décrémente INVBALANCES, (2) génère un AP voucher au fournisseur au prix négocié × quantité consommée, (3) poste un débit GL dépense sur le coût WO et un crédit AP. Cette mécanique est documentée dans le glossaire IBM-Maximo-9 : "consignment: A classification type for inventory materials that are stored on-site but that are owned by an external vendor".
Exemple chiffré — Vendor Fastenal livre 1,000 boulons consignment au Storeroom CENTRAL le 1er mars. MATRECTRANS row insérée, cost = $0, INVBALANCES = 1,000. Aucun AP voucher. Le 15 mars, technicien issue 50 boulons sur WO-1245. Maximo : (a) MATUSETRANS row INVBALANCES = 950 ; (b) AP voucher $50 × 50 = $2,500 sur Fastenal au prix consigné ; (c) charge $2,500 sur la WO. Si on n'avait pas issué, aucune dette n'existait — le stock serait resté la propriété de Fastenal sur les livres comptables.
Analogie quotidienne — C'est la machine à café au bureau où le fournisseur installe la machine et stocke les capsules. Vous ne payez que les capsules consommées (compteur électronique en fin de mois). Tant que les capsules restent dans le bac, c'est le stock du fournisseur. La consommation = le fait générateur de facturation.
Pourquoi B est faux — B place le voucher au receipt, ce qui est le comportement standard non-consignment (D3 Inverse). C'est le piège le plus dangereux car c'est le réflexe normal "réception = paiement", oubliant la spécificité consignment. Si B était vrai, le client porterait l'inventory à son bilan dès le receipt, perdant tout l'intérêt working-capital de la consignation. La règle Maximo : non-consignment = AP au receipt (cost > 0 dans MATRECTRANS) ; consignment = AP à la consommation (cost = 0 au receipt, voucher à l'issue).
Pourquoi C est faux — C suggère que l'approbation PO génère le voucher (D10 Procedure-plausible). Faux pour deux raisons : (1) une approbation PO n'a jamais généré directement un AP voucher dans Maximo — il faut une réception pour matérialiser l'engagement ; (2) en consignment, même la réception ne crée pas de voucher. Le piège est de mélanger l'engagement budgétaire (Maximo crée parfois des PO commitments à l'approbation pour le contrôle de cost) avec la dette comptable AP (qui exige une transaction de mouvement physique).
Pourquoi D est faux — D propose une réconciliation manuelle trimestrielle (D9 Near-synonym mal placée). Maximo permet bien des rapports périodiques de réconciliation consignment (vendor invoice vs system consumption), mais ce sont des contrôles, pas le fait générateur de l'AP voucher. La création du voucher est temps-réel à chaque transaction de consommation. Le piège est de confondre le contrôle (réconciliation) et le déclenchement comptable (transaction). En 2026 sous IFRS, attendre la fin du trimestre pour reconnaître la dette violerait le principe de matching des charges.
- Stock owned (standard) : Receipt → MATRECTRANS cost > 0 + AP voucher (dette vendor) + GL Inventory debit. Issue → MATUSETRANS + GL Inventory credit + Expense WO debit.
- Consignment : Receipt → MATRECTRANS cost = 0, balance up, pas d'AP voucher. Issue → MATUSETRANS + AP voucher généré au prix consigné + Expense WO debit.
- Setup : flag Consignment sur l'Inventory record (Storeroom × Item), PO type CONSIGNMENT pour le réappro.
- Pièges : technicien voit l'item en bin, pense "gratuit" → reporting WO sous-estimé si la traçabilité consommation n'est pas bonne.
- Consignment = AP voucher à la consommation, pas à la réception.
- Receipt MATRECTRANS cost = 0, INVBALANCES augmenté.
- Flag Consignment sur Inventory record (Storeroom × Item), pas sur Item Master.
- [EOTRAG query 8 — IBM-Maximo-9 glossaire "consignment" + SAP Material Master Krishna Rungta : "We are not creating an invoice using MIRO transaction for consignment goods. Instead, liabilities are settled when consumed"].
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Inventory module : Consignment items.
- STU sub-objective 1.1 — Manage a Consignment Item : ownership and location · how invoices are generated.
Correct :C
Pourquoi cette question existe — La fiche Tools partage des flags avec la fiche Item (Capitalized?, Rotating?, Inspect on Receipt?, Tax Exempt?) et en ajoute deux spécifiques : Outside? et Crew?. L'examen vérifie que le candidat ne mélange pas les flags génériques avec les flags Tools-specific. C'est un test de mémorisation précise du modèle de données.
Le contexte théorique d'abord — En CMMS/EAM, les outils ("tools") sont une catégorie distincte des items consommables : ils ne sont pas consommés mais utilisés temporairement. Leur cost driver n'est pas la quantité issuée mais le temps d'usage (heures, jours), avec un taux de charge-out. Les outils peuvent être : (1) propriété interne stockée dans le storeroom, (2) propriété d'une équipe (crew tools, ex. caisse à outils d'un soudeur), (3) loués/rentés à un fournisseur externe. Cette typologie justifie l'existence des deux flags spécifiques Crew? et Outside?.
Ce que Maximo en fait — version opérationnelle — Dans Tools application > New Tool, on saisit le Tool Number, la Description, et la palette de flags. Cocher Outside? indique que ce tool peut être commandé sur PO/PR comme un service externe (rental). À l'issue d'un Tool external sur une WO, Maximo génère automatiquement une PR de location si le stock interne est insuffisant. Le flag Crew? a un sens différent : il indique que le tool est attaché à un Crew record (équipe) au lieu d'un Storeroom — il "voyage" avec l'équipe sans transaction d'issue. Master-map.pdf p.787-832 et le module Tools (chapitre dédié) couvrent ces flags.
Exemple chiffré — Tool TQW-200 (clé dynamométrique 200 N·m) flag Outside?=Y, taux de location $80/jour. WO-9921 (shutdown 5 jours) requiert le tool pour 5 jours. Stock interne disponible = 0 (autres équipes l'utilisent). Maximo propose une PR de location vers vendor RentTools-Inc. Le coût engagé est 5 × $80 = $400 sur la WO en charge "Tool Rental". Sans le flag Outside?, la PR de location ne peut pas être déclenchée automatiquement et le tool apparaît "non disponible".
Analogie quotidienne — Outside? = "ce tool, je peux le louer chez Home Depot en cas de besoin urgent". Crew? = "cette caisse à outils, c'est celle de Marc, elle est dans son van". Capitalized? = "cet équipement, c'est un actif comptable que je déprécie sur 10 ans". Inspect on Receipt? = "je dois vérifier la calibration avant de l'utiliser". Quatre dimensions orthogonales du même tool.
Pourquoi A est faux — A propose Capitalized? (D5 Sibling-field). Capitalized? indique le routing GL (Capital vs Expense) à la réception, pas la possibilité de location externe. Le piège est que les tools loués sont rarement capitalisés (location = OPEX, pas CAPEX), donc on associe mentalement les deux concepts. Mais Maximo les sépare : un tool peut être Outside? sans être Capitalized? (rental simple), Capitalized? sans être Outside? (équipement immobilisé interne), ou les deux (équipement loué long-terme amorti chez le client en lease comptable IFRS 16).
Pourquoi B est faux — B propose Crew? (D5 Sibling-field, le piège le plus subtil). Crew? signifie que le tool est attaché à une équipe et la suit (van, palette, tool box) au lieu d'être stocké en Storeroom. C'est très différent de Outside? qui parle d'origine externe. Une équipe peut avoir des Crew tools internes (Crew?=Y, Outside?=N) ou des Crew tools loués (Crew?=Y, Outside?=Y) — les deux flags coexistent. Le piège vient de la consonance "Crew" / "external" dans certaines langues ou de l'idée que "tool not in storeroom = not internal".
Pourquoi D est faux — D propose Inspect on Receipt? (D5 Sibling-field). Ce flag signifie qu'à chaque réception, le tool passe par une étape QA en Holding Location avant d'être disponible. Pas de lien avec l'origine externe. Le piège vient peut-être de l'idée que "tool externe = on ne lui fait pas confiance = on l'inspecte" — mais c'est une corrélation pratique, pas le sens du flag. Outside? et Inspect? sont indépendants : un tool externe non-inspecté (Outside?=Y, Inspect?=N) est valide si le contrat de location l'exclut.
- Capitalized? : routing GL Capital vs Expense au receipt.
- Rotating? : crée Asset record sérialisé, cost method ASSET.
- Outside? : tool sourcable externe (rental/contract), génération PR location auto.
- Inspect on Receipt? : holding location + QA avant active balance.
- Tax Exempt? : suppression tax codes sur PR/PO.
- Crew? : tool attaché à un Crew record, voyage avec l'équipe sans Issue/Transfer.
- Outside? = source externe (rental). Indépendant de Crew? et Capitalized?.
- Crew? = attaché à équipe, pas à Storeroom.
- Les 6 flags Tool sont orthogonaux : on coche selon la nature et l'origine.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Tools application : Tool flags.
- STU sub-objective 1.1 — Create a New Tool Item : flags (Capitalized? · Rotating? · Outside? · Inspect on Receipt? · Tax Exempt? · Crew?).
Correct :A
Pourquoi cette question existe — Les Service items ont seulement 3 flags (Prorate?, Inspection Required?, Tax Exempt?) — bien moins que les Items Master (8) ou les Tools (6). Le flag Prorate? est unique aux Services et résout un problème comptable très concret : comment répartir un coût annexe (freight, douane, taxe à l'importation) sur plusieurs lignes d'articles d'un même PO. L'examen teste la connaissance de cette mécanique parce qu'elle a un impact direct sur le coût-WO précis.
Le contexte théorique d'abord — En comptabilité analytique, les coûts d'acquisition d'un stock incluent (selon IAS 2 / ASC 330) le prix d'achat plus tous les coûts directement attribuables : transport, douane, manutention, inspection. Pour respecter le principe de matching, ces coûts doivent être capitalisés dans la valeur des stocks et non passés en charge période. La proration permet d'allouer un coût composite (un freight de $1,200 pour un PO multi-lignes) au prorata de la valeur, du poids, ou du volume des lignes reçues.
Ce que Maximo en fait — version opérationnelle — Sur un Service item avec flag Prorate?=Y, à la réception du PO, Maximo distribue le coût du service au prorata du poids (ou de la valeur, selon configuration) sur toutes les lignes-items du même PO ; le coût ainsi prorata est ajouté à AVGCOST de chaque ligne-item, augmentant la valeur du stock. Sans Prorate?, le coût du service est passé directement en GL Expense (compte Freight Expense ou similaire). Cette logique est gérée à Item Master > Services tab ou directement à la création du Service item, et activée à la réception via Receiving.
Exemple chiffré — PO #4521 : ligne 1 = 100 valves × $50 = $5,000 ; ligne 2 = 50 bearings × $30 = $1,500 ; ligne 3 = freight (Service item Prorate?=Y) = $650. Sans Prorate?, freight passe en GL Expense $650. Avec Prorate?, freight est distribué : valves prennent (5,000 / 6,500) × 650 = $500 (cost adjusted to $5,500 / 100 = $55 unit), bearings prennent (1,500 / 6,500) × 650 = $150 (cost adjusted to $1,650 / 50 = $33 unit). Le coût stocké augmente de $5 et $3 par unité respectivement. Quand ces items seront issués sur WO, leur coût-WO inclura cette part de freight.
Analogie quotidienne — Pensez à une commande Amazon avec frais de port mutualisé : si vous commandez 3 livres pour $30 + $9 frais de port, Amazon ne vous facture pas $9 séparément, il les répartit dans le prix de chaque livre ($3 chacun) si vous voulez calculer le coût total possessionné par item. La proration Maximo formalise cette logique pour les achats industriels.
Pourquoi B est faux — B propose Inspection Required? (D5 Sibling-field). Ce flag signifie que le service nécessite une inspection avant validation finale (typiquement pour des services de calibration, audit, ou consulting). Aucun lien avec la répartition de coût. Le piège vient de la similitude conceptuelle "freight = transport = qualité de réception inspectée" — mais Inspection Required? force juste une étape QA, pas une distribution comptable.
Pourquoi C est faux — C propose Tax Exempt? (D5 Sibling-field). Tax Exempt? supprime l'application des taxes locales sur la ligne du service ; ça change le montant taxable, pas la distribution du montant brut. Le piège est que les services freight sont souvent tax-exempt selon les juridictions (services internationaux), donc on associe mentalement les deux. Mais ce sont deux fonctions orthogonales : un freight peut être Tax Exempt?=Y et Prorate?=Y (proration sans taxe) ou Tax Exempt?=N et Prorate?=Y (proration avec taxe incluse), etc.
Pourquoi D est faux — D propose Capitalized? (D6 Wrong-app : Capitalized? est un flag d'Item Master / Tool, pas de Service). Les Services n'ont pas de flag Capitalized? car ils n'ont pas de stock à valoriser. La capitalisation des coûts annexes (freight, douane) sur la valeur d'inventaire passe par Prorate?, pas par un Capitalized? sur le Service. Le piège est conceptuel : "capitalize freight into inventory value" semble être un concept Capitalize, mais Maximo le réalise via Prorate.
- Prorate? (Service unique) : répartit le coût service sur lignes-items du même PO au prorata.
- Inspection Required? (Service) : exige étape QA avant validation finale.
- Tax Exempt? (Service, partagé Item/Tool) : supprime tax codes.
- Pas dans Service : Rotating?, Capitalized?, Kit?, Condition Enabled?, Outside?, Crew? — propres aux Items / Tools physiques.
- Service items = 3 flags : Prorate?, Inspection Required?, Tax Exempt?.
- Prorate? = distribution coût annexe (freight, douane) sur lignes-items du PO.
- Sans Prorate?, le service passe en GL Expense direct.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Service items section.
- STU sub-objective 1.1 — Create a New Service Item : flags (Prorate? · Inspection Required? · Tax Exempt?).
- IAS 2 — Inventories : capitalisation des coûts d'acquisition.
Correct :D
Pourquoi cette question existe — Les meters et meter groups sont indissociables des actifs sérialisés. Un meter mesure quelque chose qui s'incrémente sur le temps (run hours, cycles, miles, températures), et l'incrément est tracé par instance physique — pas par item type. La question teste la connaissance que cette traçabilité par instance exige le flag Rotating?.
Le contexte théorique d'abord — En reliability engineering ISO 14224, les indicateurs de fiabilité (MTBF, MTTR, availability, RUL) reposent sur des compteurs d'usage ou de cycles attachés à chaque équipement individuel. Sans cette individualisation, on ne peut pas dire "cette pompe particulière a 12,500 heures d'usage et présente un risque de défaillance". Maximo encode cette logique en imposant : meters = sur Asset records ; Asset records = créés à la réception seulement si l'item est Rotating. La chaîne logique est : meter → asset → rotating item.
Ce que Maximo en fait — version opérationnelle — Dans Item Master > Meters tab ou Meter Group tab, on peut associer un meter ou un meter group. Maximo accepte la sauvegarde même si l'item n'est pas Rotating, mais l'effet de l'association ne se concrétise qu'à la création des Assets associés (qui dépend du flag Rotating?). Pour un item non-rotating, aucun Asset n'est créé à la réception, donc aucun meter ne tourne. La meilleure pratique est de cocher Rotating? AVANT d'associer le meter pour cohérence. Master-map.pdf p.787-832 + chapitre Assets décrivent cette dépendance.
Exemple chiffré — Item PUMP-001, Rotating?=Y, Meter Group = (RUNHRS, FUELCONS). À la réception de 3 unités, Maximo crée 3 Assets (PUMP-2026-001, 002, 003), chacun initialisé avec RUNHRS=0 et FUELCONS=0. Au fil du temps : PUMP-2026-001 atteint 1,200 hrs et 850 L de fuel ; PUMP-2026-002 atteint 800 hrs et 580 L ; PUMP-2026-003 vient juste d'être issuée et a 50 hrs / 30 L. Chaque asset a son propre historique meter — c'est ce qui permet le calcul d'un MTBF par sous-population et l'identification du "outlier" (l'unité 001 a beaucoup plus tourné). Sans Rotating?, ces 3 unités auraient été indistinguables, balance INVBALANCES = 3, sans aucun meter.
Analogie quotidienne — Vous achetez 3 voitures identiques pour votre flotte. Le compteur d'odomètre est par voiture (par VIN), pas "moyenne flotte". Voiture A est conduite par Marc → 25,000 km. Voiture B par Sara → 18,000 km. Voiture C neuve → 200 km. Vous ne pouvez pas dire "la flotte est à 14,400 km" — vous suivez chaque véhicule. Maximo applique cette logique aux pompes, moteurs, compresseurs.
Pourquoi A est faux — A demande Capitalized? (D5 Sibling-field). Capitalized? change le routing GL au receipt (Capital vs Expense), pas la création d'Asset records. Beaucoup de rotating items sont aussi capitalized, mais les deux flags sont indépendants : on peut être Rotating?=Y, Capitalized?=N (équipement loué passé en charge) avec meters fonctionnels, ou Rotating?=N, Capitalized?=Y (un item de stock cher mais fungible) sans meters possibles.
Pourquoi B est faux — B affirme que l'item doit être Service (D6 Wrong-app). Faux : les Service items n'ont pas de stock physique, n'ont pas d'asset associé, donc ne peuvent jamais porter de meter. C'est l'inverse exact : les meters s'attachent à des actifs physiques sérialisés, jamais à des prestations immatérielles. Le piège est peut-être lexical (on parle de "compteur de service" en anglais courant — service counter — mais en Maximo "Service" est un type d'item totalement distinct).
Pourquoi C est faux — C demande Kit? (D5 Sibling-field). Kit? est un flag pour des assemblages d'items à issuer ensemble, sans tracking individuel des pièces. Un kit ne crée pas d'Asset records (sauf si les enfants sont eux-mêmes Rotating). Donc même un Kit ne porte pas de meters au niveau du parent. Le piège est de croire que la complexité d'un item (kit) justifie le tracking par meters, mais c'est la sérialisation (Rotating?) qui ouvre les meters, pas la complexité structurelle (Kit?).
- Meter : compteur unique (RUNHRS, ODOMETER, CYCLES, FUEL).
- Meter Group : ensemble de meters bundlés (souvent par type d'équipement, ex. moteur diesel = RUNHRS + FUELCONS + IDLEHRS).
- Item Master Meter tab : association de meter(s) ou meter group au type d'item.
- Prérequis : item Rotating?=Y. Sans Rotating?, pas d'Asset → pas de meter actif → l'association reste cosmétique.
- Effet à la réception : chaque Asset créé hérite des meters initialisés (typiquement à 0 ou à la valeur OEM si neuf).
- Meter Group sur Item → effet utile seulement si Rotating?=Y.
- Meter = par Asset (instance), pas par item (type).
- Service / Kit / non-Rotating → pas d'Asset → pas de meter.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Item Master Meters tab + Asset module.
- STU sub-objective 1.1 — Associate a Meter / Meter Group : types eligible · related transactions on issue.
- ISO 14224 — Reliability data collection per equipment unit.
Correct :C
Pourquoi cette question existe — Cette question SAM teste la séparation conceptuelle entre la définition d'une caractéristique d'item (au niveau Master) et l'instanciation de cette caractéristique au niveau opérationnel (Inventory, Storerooms). Le flag Condition Enabled? est une caractéristique structurelle de l'item, pas une option de stockage par storeroom. C'est donc l'application Item Master qui contient le flag.
Le contexte théorique d'abord — Dans tout système EAM, on distingue trois niveaux de définition : (1) le type d'item (master data, partagé), (2) l'instance de stock par localisation (transactional data), (3) l'instance physique sérialisée (asset data). Les caractéristiques structurelles (rotating, condition-enabled, kit, capitalized) sont au niveau 1 — Master — pour garantir l'unicité et la cohérence. Si elles étaient au niveau 2 (par storeroom), on aurait un même item condition-enabled à un endroit et non condition-enabled à un autre, ce qui briserait l'intégrité des Reservations cross-storeroom et des Transfer Orders.
Ce que Maximo en fait — version opérationnelle — Le path exact pour activer condition-enabled : Item Master > ouvrir l'item > Item tab > cocher Condition Enabled? checkbox > sauvegarder. Ensuite : Condition Codes tab apparaît sur la fiche Item, où on ajoute les codes (NEW, REFURBISHED, USED) avec leurs rates (100%, 70%, 50%). Une fois sauvegardé et l'item mis en statut Active, les transactions Inventory et Reservation reconnaissent les codes. SAM Q9 verbatim confirme : "In which application is an item marked as condition-enabled? — Item Master". Master-map.pdf p.787-832 + le glossaire IBM Manage 9 corroborent : "An item that has a value or worth that is assigned and tracked based on its physical condition" [EOTRAG query 9].
Exemple chiffré — Item MOTOR-X100, NEW cost = $10,000, condition-enabled. Codes : NEW (100%, $10,000), REFURBISHED (70%, $7,000), USED (50%, $5,000). Stock dans Storeroom CENTRAL : 5 NEW, 3 REFURBISHED, 1 USED. Une WO réserve 1 unité avec condition = REFURBISHED → pick list montre les 3 REFURBISHED → l'issue charge $7,000 sur la WO et décrémente le sous-balance REFURBISHED de 3 à 2. Si la rate REFURBISHED change rétroactivement à 65% ($6,500), les 2 unités restantes ne sont PAS re-costées ; seul le futur usage (issue ou transfert) appliquera $6,500.
Analogie quotidienne — Le concept Condition Enabled est l'équivalent EAM d'une voiture d'occasion : le modèle est le même (Honda Civic 2020), mais l'état conditionne le prix (excellent état 100%, bon état 70%, état moyen 50%). C'est le type de bien qui décide si on raisonne en condition (les voitures = condition-enabled, les œufs = non-condition-enabled), pas le magasin où il est vendu.
Pourquoi A est faux — A propose Inventory (D6 Wrong-app). L'application Inventory affiche les balances par condition une fois que le flag est activé sur le Master, mais elle ne permet pas d'activer le flag. Le piège est que beaucoup de configurations spécifiques sont effectivement dans Inventory (ROP, EOQ, Lead Time, Default Bin, Cost Type), donc on associe par habitude "configuration de l'item dans un storeroom = Inventory app". Faux pour les caractéristiques structurelles de l'item.
Pourquoi B est faux — B propose Storerooms (D6 Wrong-app). L'application Storerooms définit les magasins (parent, GL accounts, lead-time storeroom, etc.) mais n'expose pas les flags d'item. Un Storeroom ne "rend pas un item" condition-enabled — c'est l'item qui porte cette caractéristique, indépendamment des storerooms où il est stocké. Le piège vient peut-être de l'idée "stockage par condition = config du storeroom" ; mais le storeroom héberge des bins, pas la définition de l'item.
Pourquoi D est faux — D propose Condition Codes (D6 Wrong-app). Cette application existe bien dans Maximo et c'est là qu'on définit le catalogue des codes condition (NEW, REFURBISHED, USED) avec leurs labels. Mais elle ne permet pas de marquer un item individuel comme condition-enabled. Une métaphore : Condition Codes = le dictionnaire des couleurs (rouge, bleu, vert) ; Item Master = le bouton "ce produit a-t-il une variante de couleur" sur chaque produit. Le piège est très tentant car le nom de l'app correspond exactement au concept testé — c'est le distractor le plus dangereux de la question.
- Item Master : flags structurels (Rotating, Condition Enabled, Kit, Capitalized, Inspect, Add as Spare, Attach to Parent, Tax Exempt). Master data globale.
- Item Org Details : statut par Organization, GL accounts par Org, ABC type par Org.
- Inventory (Storeroom × Item) : ROP, EOQ, Lead Time, Default Bin, Cost Type, Order Unit, Issue Unit override, balance par condition (si condition-enabled).
- Storerooms : config du magasin (parent, GL, lead-time, default storeroom, holding location).
- Condition Codes : catalogue des codes (NEW, REFURBISHED, etc.) avec leurs % de cost rate.
- Flag Condition Enabled? = sur Item Master.
- Catalogue des codes (NEW, REFURBISHED…) = dans Condition Codes app.
- Balance par condition = visible dans Inventory app après activation.
- Issue cost = NEW × condition_rate ; non rétroactif sur stock existant.
- SAM Sample Question 9 — IBM C1000-208 Sample Test (Section 1.1).
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Item Master Condition Enabled tab.
- [EOTRAG query 9 — IBM-Maximo-9 glossaire "condition-enabled item: An item that has a value or worth that is assigned and tracked based on its physical condition"].
Storerooms et Labor Inventory Locations

📋 Objectifs IBM
- Créer un Storeroom — Ajouter un nouveau Storeroom location · définir les comptes GL · expliquer le default storeroom d'un site · expliquer le calcul du Lead Time.
- Créer une Labor Inventory Location — décrire son usage.
- Configurer un Parent Storeroom pour la commande centralisée — spécifier le storeroom pour les internal POs · spécifier le reorder storeroom.
💡 Points clés
- Un Storeroom est une Location typée, définie dans l'application Storerooms mais enregistrée en arrière-plan comme un Location record avec
type=STOREROOM. Il a une adresse, des comptes GL (Inventory Control, Inventory Cost, Cost Variance, Currency Variance, Shrinkage), un Site, et optionnellement un Parent Storeroom, une Holding Location et des flags Internal/External. Le storeroom est le plus petit conteneur pour les balances de stock ; les bins existent à l'intérieur d'un storeroom. - Default storeroom d'un site — Chaque Site peut désigner un Storeroom par défaut (Sites > Default Storeroom). Ce défaut est utilisé à la création des Inventory records, à l'issue des tools, et pour afficher les suggestions sur les Job Plans. Un utilisateur peut surcharger le défaut au moment de la transaction, mais le défaut réduit le nombre de clics pour le cas standard 80%.
- Cinq comptes GL que tout Storeroom doit déclarer :
- GL Inventory Control Account — côté Asset du bilan ; débité à la réception, crédité à l'issue.
- GL Inventory Cost Account — typiquement identique à Inventory Control ou un sous-compte ; trace le coût des biens en stock.
- GL Cost Variance Account — reçoit l'écart quand le coût de réception diffère du coût PO (purchase price variance) ou quand le standard cost diffère de l'actuel.
- GL Currency Variance Account — reçoit les écarts de change quand la réception est en devise étrangère.
- GL Shrinkage Account — reçoit les writedowns dus aux variances négatives de cycle-count et aux pertes physiques.
- Calcul du Lead Time au niveau Storeroom — Maximo offre un champ Recent Lead Time Weight in % qui permet au système de mélanger les lead times de réceptions récentes avec la moyenne historique. Ex. : 70% récent / 30% historique. Cela évite de mettre à jour le Lead Time manuellement à chaque changement de fournisseur. Valeur réelle : un fournisseur qui livrait en 21 jours depuis des années livre maintenant en 14 jours grâce à un nouveau contrat logistique → les réceptions récentes prennent un poids supérieur, le ROP est recalculé automatiquement.
- Labor Inventory Location — Un type de location spécial qui représente le « stock de main-d'œuvre » : la population de main-d'œuvre disponible (techniciens, sous-traitants) est tracée comme si c'était de l'inventaire, permettant à la main-d'œuvre d'être issuée aux WOs (avec un cost rate) et tracée. Utilisée quand la capacité de main-d'œuvre est une contrainte de planification. Créée comme un Storeroom mais avec
type=LABOR. Ne stocke pas de matériel physique. - Parent Storeroom (commande centralisée) — Un storeroom peut déclarer un Parent Storeroom. Le parent agit comme un « hub » : il consolide les POs de plusieurs satellite storerooms (le vendor livre au hub une fois, le hub redistribue), et il peut servir de source de reorder pour les satellites (internal PO / transfert au lieu d'un external PO chez le vendor). Topologie hub-et-rayons, alignée ISO 55000 pour gérer le coût de détention d'inventaire dans des organisations multi-sites.
- Checkbox Use in PR/PO (le réglage critique de SAM Q2) — Sur le record Storeroom, la checkbox Use in PR/PO déclare que ce storeroom peut être utilisé comme source sur une ligne de Purchase Requisition ou Purchase Order. Concrètement : quand on coche ce flag sur le Storeroom CENTRAL, on peut écrire une ligne PO qui dit « livrer à / source = CENTRAL » et CENTRAL va alimenter le storeroom satellite demandeur via un transfert interne. Sans ce flag, le storeroom ne peut pas être spécifié dans les champs source des PR/PO. SAM Q2 verbatim : « to enable this behavior, the Use in PR/PO checkbox needs to be checked ».
- Champ Reorder Storeroom (concept différent !) — Distinct du Parent Storeroom. Le champ Reorder Storeroom sur un Inventory record (par item par storeroom) déclare depuis quel storeroom cet item doit être reorderé quand son ROP est atteint. Ex. : l'item BEARING-X existe au Satellite-A et a besoin d'être réapprovisionné depuis CENTRAL : sur l'Inventory record au Satellite-A, mettre Reorder Storeroom = CENTRAL. L'action reorder créera alors un transfert interne de CENTRAL vers Satellite-A. C'est item-specific, tandis que Use in PR/PO est storeroom-wide.
- Internal PO vs External PO — Quand la source d'un PO est un autre storeroom Maximo (Use in PR/PO), le PO est Internal (pas d'AP voucher vendor, juste un transfert de stock). Quand la source est une Company (vendor), le PO est External (AP voucher créé à la réception). Les Internal POs utilisent un flux de statut différent et ne touchent pas l'accounts payable externe.
- Holding Location pour les items inspect-on-receipt — Un storeroom peut déclarer une Holding Location, qui est le bin temporaire où les items inspect-on-receipt attendent l'approbation QA. La balance de stock n'est pas active tant que les items n'ont pas quitté la Holding Location. Cela se règle au niveau Storeroom même si ce n'est utilisé que par les items avec le flag Inspect on Receipt?.
- Exemple chiffré — Flux multi-storeroom : le vendor SteelCo livre au Storeroom CENTRAL (parent, Use in PR/PO=Y) 1 000 bearings à 50 $ chacun. Deux satellites (NORTH, SOUTH) consomment 200/mois chacun. Reorder Storeroom pour l'inventaire NORTH des bearings = CENTRAL. Quand la balance NORTH descend sous ROP=50, Maximo crée une Internal PR (NORTH source = CENTRAL), exécutée comme un Stock Transfer. Le coût circule du compte d'inventaire de CENTRAL vers celui de NORTH. Le vendor ne voit que la commande centrale, le freight est consolidé.
graph TB HUB["CENTRAL-STORE
Use in PR/PO ✔
(visible comme fournisseur
par les satellites)"]:::hub SAT_A["SAT-A
Reorder Storeroom = CENTRAL-STORE"]:::sat SAT_B["SAT-B
Reorder Storeroom = CENTRAL-STORE"]:::sat SAT_C["SAT-C
Reorder Storeroom = CENTRAL-STORE"]:::sat HUB ==>|"Use in PR/PO
(CENTRAL apparaît
comme fournisseur interne)"| SAT_A HUB ==>|"Use in PR/PO"| SAT_B HUB ==>|"Use in PR/PO"| SAT_C SAT_A -.->|"Reorder Storeroom
(le satellite pointe
en amont vers le hub)"| HUB SAT_B -.->|"Reorder Storeroom"| HUB SAT_C -.->|"Reorder Storeroom"| HUB classDef hub fill:#1D9E75,stroke:#178A66,color:#FFFFFF,font-weight:600,stroke-width:2px; classDef sat fill:#FFFFFF,stroke:#94A3B8,color:#0F172A;
⚠️ Piège IBM
Trois concepts storeroom aux noms SIMILAIRES qui font des choses DIFFÉRENTES — IBM teste cette distinction sous plusieurs variantes au C1000-208.
- Use in PR/PO (checkbox du Storeroom) — déclare que le storeroom peut être une source sur des lignes PR/PO (approvisionne d'autres storerooms). SAM Q2 confirme que c'est la réponse quand la question est « qu'est-ce qui habilite ce storeroom à fournir les autres ».
- Parent Storeroom (champ du Storeroom) — déclare le hub hiérarchique. Utilisé pour le reporting consolidé et comme source par défaut du centralized ordering quand aucune autre source n'est définie.
- Reorder Storeroom (champ de l'Inventory record par item) — déclare la source de reorder pour cet item particulier dans ce storeroom particulier. Granularité par item, plus fine que Parent Storeroom.
🎯 Carte mémoire
Q. Un utilisateur veut que le Storeroom CENTRAL soit autorisé comme source sur une PR ou un PO qui fournit de l'inventaire à des storerooms satellites. Quel champ/checkbox exact active cela ?
Afficher la réponse
La checkbox Use in PR/PO sur le record Storeroom. Sans elle, le storeroom ne peut pas apparaître dans le champ source d'une ligne PR/PO. Parent Storeroom et Reorder Storeroom sont reliés mais résolvent des problèmes différents (hiérarchie et source de reorder par item, respectivement).
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :A
Pourquoi cette question existe — Cette question SAM teste un point critique : la confusion entre 3 paramètres voisins du storeroom qui se ressemblent linguistiquement mais font des choses différentes. C'est l'archétype du distracteur D5 (Sibling-field) en concentré : la bonne réponse est sur le record Storeroom, deux des distracteurs aussi, mais avec des effets totalement différents.
Le contexte théorique d'abord — En supply chain, deux topologies de réseau de stockage existent : single-echelon (vendor → 1 storeroom → 1 site, indépendant) et multi-echelon hub-et-rayons (vendor → hub central → n satellites). Le multi-echelon réduit le total inventory de √n (modèle Clark-Scarf), améliore les volume discounts, et simplifie la logistique vendor — au prix d'un transport interne hub-vers-rayon supplémentaire. Pour matérialiser cette topologie dans un EAM, il faut deux mécanismes orthogonaux : (1) déclarer qui peut être source (Use in PR/PO), (2) qui hérite de qui (Parent Storeroom). [EOTRAG query 13 — single vs multi-echelon].
Ce que Maximo en fait — version opérationnelle — Path : Storerooms application > ouvrir le storeroom CENTRAL > cocher Use in PR/PO checkbox > sauvegarder. Une fois coché, sur n'importe quel PR/PO créé dans Purchasing app ou via reorder process, le champ Source ou From Storeroom peut référencer CENTRAL. Sans ce flag, le storeroom n'apparaît même pas dans la liste de valeurs des sources possibles — Maximo bloque physiquement le binding. SAM Q2 verbatim confirme : "What needs to be set on the Storeroom record to enable this behavior? — The Use in PR/PO checkbox needs to be checked". Master-map.pdf chapitre Storerooms documente le flag.
Exemple chiffré — Plant industriel : 1 storeroom CENTRAL (50 000 SKUs, 5 M$ de stock), 4 satellites (NORTH, SOUTH, EAST, WEST avec 5 000 SKUs chacun). Vendor SteelCo livre exclusivement à CENTRAL (transport optimisé : 1 livraison vs 4). Quand le satellite NORTH a son ROP atteint sur item BEARING-X, Maximo cherche une source : avec Use in PR/PO=Y sur CENTRAL, l'algorithme propose CENTRAL comme source de l'internal PO ; sans le flag, l'algorithme tombe en mode external PO (vers SteelCo directement, ce qui défait la topologie hub-et-rayons). Mauvaise configuration → 4 livraisons vendor au lieu de 1 → freight ×4.
Analogie quotidienne — Imaginez un entrepôt central Amazon qui fournit les hubs régionaux. Pour qu'Amazon puisse "tirer" du stock du central vers le hub Lyon, le central doit avoir le statut "fournisseur interne" activé dans le système. Sans ce statut, le système d'inventaire considère que Lyon doit re-commander chez les fabricants. Ce flag Use in PR/PO est l'interrupteur qui dit "ce storeroom peut être une source pour les autres".
Pourquoi B est faux — B propose de remplir le champ Parent Storeroom (D5 Sibling-field). Parent Storeroom déclare une hiérarchie organisationnelle (CENTRAL est parent de NORTH/SOUTH) et permet certains agrégats de reporting et certains comportements par défaut, mais ne habilite pas en lui-même la mécanique source-PO. Le piège : on peut avoir Parent Storeroom = CENTRAL sans pour autant que CENTRAL puisse être source PR/PO si Use in PR/PO n'est pas coché. Inversement, on peut cocher Use in PR/PO sans hiérarchie Parent. Les deux concepts sont indépendants. SAM Q2 a explicitement rejeté Parent Storeroom comme bonne réponse.
Pourquoi C est faux — C propose de remplir le champ Reorder Storeroom (D5 Sibling-field, le piège le plus subtil). Mais Reorder Storeroom n'est pas un champ du record Storeroom : c'est un champ de l'Inventory record (Storeroom × Item). Il déclare où réapprovisionner UN item donné, pas une capacité globale du storeroom. Mettre Reorder Storeroom = CENTRAL sur l'item BEARING-X au satellite NORTH déclare que cet item particulier va se réapprovisionner depuis CENTRAL ; ça ne dit rien sur les autres items. La question SAM porte sur la capacité du storeroom à fournir, pas sur le routage par item. C est donc un D5 mal placé : le bon récipient (Inventory record) au mauvais endroit (record Storeroom).
Pourquoi D est faux — D propose Is Satellite Storeroom checkbox (D7 Non-existent). Aucun flag de ce nom n'existe dans Maximo Manage v9.1. C'est une fabrication. Le piège : la question parle de "satellite storerooms" comme cible, donc le candidat pressé associe "il doit y avoir un flag satellite" — mais c'est l'inverse : c'est le storeroom fournisseur qu'on configure (CENTRAL), pas les satellites consommateurs. Et même côté CENTRAL, aucun flag "satellite" n'existe. Trace pour exclure : si "Is Satellite Storeroom" existait, IBM le mentionnerait dans master-map.pdf et SAM Q2 — il n'est mentionné dans aucun document officiel.
- Use in PR/PO (Storeroom checkbox) → habilite le storeroom à être une source sur PR/PO lines. SAM Q2 answer.
- Parent Storeroom (champ Storeroom) → déclare hiérarchie hub-et-rayons. Pour reporting et défauts.
- Reorder Storeroom (Inventory record field, item-level) → où réapprovisionner CET item depuis CET storeroom.
- Internal PO = source = autre Storeroom (Use in PR/PO=Y). Pas d'AP voucher vendor. Stock transfer.
- External PO = source = Company. AP voucher créé au receipt.
- Use in PR/PO = ce storeroom peut être SOURCE sur PR/PO.
- Parent Storeroom = hiérarchie reporting / hub-et-rayons par défaut.
- Reorder Storeroom = field item-level dans Inventory record.
- "Is Satellite Storeroom" : n'existe PAS dans Maximo.
- SAM Sample Question 2 — IBM C1000-208 Sample Test (Section 1.2).
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Storerooms application : Use in PR/PO.
- [EOTRAG query 13 — Topologie storeroom multi-echelon hub-et-rayons].
Correct :C
Pourquoi cette question existe — Le storeroom porte 5 GL accounts dont les rôles sont parfois confondus. Cost Variance et Currency Variance se ressemblent linguistiquement mais reçoivent des écarts de natures différentes. L'examen vérifie que le candidat sait quel compte reçoit quel type d'écart. Cet item est révélateur : un mauvais paramétrage GL au niveau du storeroom génère soit des écritures perdues, soit des reports financiers faux.
Le contexte théorique d'abord — En comptabilité analytique, on distingue deux familles d'écart à la réception : (1) purchase price variance (écart prix achat vs standard ou vs PO) — d'origine commerciale, négociation, marché ; (2) currency variance — d'origine FX, taux de change entre PO date et receipt date. Une troisième famille existe : shrinkage / shrink — pertes physiques (vol, casse, péremption). Les normes IFRS et US GAAP imposent que ces écarts soient identifiés séparément pour le reporting et le contrôle interne (SOX).
Ce que Maximo en fait — version opérationnelle — Path : Storerooms application > ouvrir le storeroom > GL Accounts tab. Cinq champs : Inventory Control, Inventory Cost (souvent identique au Control), Cost Variance, Currency Variance, Shrinkage. Le compte Cost Variance reçoit les écarts entre receipt cost et le coût attendu (standard cost ou PO cost). En cost type STANDARD : (PO_cost - standard_cost) × qty va en Cost Variance ; en cost type AVERAGE : si le receipt cost diffère du PO cost (correction fournisseur), l'écart va en Cost Variance. Master-map.pdf chapitre Storerooms + chapitre Inventory Cost Methods décrivent ces flux.
Exemple chiffré — Storeroom CENTRAL, item BOLT-001 en cost type STANDARD à $0.50/unit. PO #4500 pour 1,000 unités à $0.55/unit (négociation médiocre, vendor a augmenté). Receipt : 1,000 × $0.55 = $550 payés. GL postings : (a) Inventory Control debit 1,000 × $0.50 = $500 (au standard, conformément au cost type) ; (b) Cost Variance debit (1,000 × ($0.55 - $0.50)) = $50 ; (c) AP credit $550 (dette vendor au receipt cost réel). L'écart $50 est isolé en Cost Variance pour analyse procurement (qui pourra ensuite renégocier avec le vendor).
Analogie quotidienne — Vous budgetez votre épicerie à $200 (standard cost), mais à la caisse vous payez $215 (actual cost). Les $15 supplémentaires, vous les notez dans une case "écart budget" pour analyse en fin de mois. Maximo fait pareil mais isole en plus l'écart de change si vous avez payé en devise étrangère.
Pourquoi A est faux — A propose Inventory Control (D5 Sibling-field). C'est le compte principal de bilan (asset side). Au receipt, il est debité de la valeur d'inventaire au standard ou à l'average (selon cost type), pas de l'écart. L'écart va dans Cost Variance, pas Inventory Control. Le piège : on associe "le receipt va dans Inventory Control" et on étend cette association à tous les flux de réception — mais Maximo splitte délibérément les écritures pour isoler les variances.
Pourquoi B est faux — B propose Shrinkage (D5 Sibling-field). Shrinkage reçoit les pertes physiques (cycle count negative variance, théft, breakage), pas les écarts de prix. Le piège : "shrinkage" et "variance" résonnent ensemble dans le langage courant ("écart" / "perte"), mais en comptabilité Maximo ils sont distincts. Shrinkage = perte qty (qty going down sans transaction de sortie justifiée) ; Variance = écart prix sur transaction normale. Une cycle count qui constate -10 unités passe en Shrinkage ; un PO receipt à $0.55 vs standard $0.50 passe en Cost Variance.
Pourquoi D est faux — D propose Currency Variance (D9 Near-synonym, le distracteur le plus tentant). Currency Variance reçoit les écarts FX uniquement : quand un PO est passé à 1 USD = 1.30 CAD à la date du PO, et que le receipt arrive 30 jours plus tard à 1 USD = 1.25 CAD, le delta sur la valeur receipt est imputé à Currency Variance. Aucun lien avec un écart de prix d'achat en devise locale. Le piège est puissant car les deux comptes terminent en "Variance" et concernent des écarts de coût — mais leur nature est différente (commercial vs financier-FX).
- Inventory Control : asset balance sheet, debited on receipt, credited on issue. Au standard ou à l'average.
- Inventory Cost : généralement identique à Inventory Control ou sous-compte. Tracks cost of goods on hand.
- Cost Variance : écart receipt vs standard/PO. Origine commerciale (négo, marché).
- Currency Variance : écart FX entre PO date et receipt date. Origine financière.
- Shrinkage : pertes physiques (cycle count negative, breakage, théft). Origine opérationnelle.
- Cost Variance = écart prix receipt vs standard/PO. Commercial.
- Currency Variance = écart FX. Financier.
- Shrinkage = perte physique. Opérationnel.
- Les 3 sont distincts et auditables séparément (SOX).
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Storerooms : GL Accounts tab.
- STU sub-objective 1.2 — Create a Storeroom : Define GL accounts.
- [EOTRAG query 4 — Cost Methods : variance accounts].
Correct :B
Pourquoi cette question existe — Maximo gère ses defaults à plusieurs niveaux (Organization, Site, User, Item, Inventory) et le candidat doit savoir où le default storeroom appartient sur la hiérarchie. Le default storeroom est un défaut au niveau Site car un Site représente une localisation géographique (une usine) avec ses storerooms ; le défaut s'applique transversalement aux items.
Le contexte théorique d'abord — En architecture EAM multi-tenant, la hiérarchie est : Organization (entité légale) → Site (localisation physique) → Storerooms / Locations / Assets. Les paramètres opérationnels par défaut s'attachent au niveau le plus pertinent : taux horaire labor au Site (paye par usine) ; default storeroom au Site (chaque usine a son magasin principal) ; cost type au Org (politique financière de l'entreprise). Cette séparation permet à un Org multi-sites de garder une politique financière commune tout en autorisant chaque site à choisir son magasin principal.
Ce que Maximo en fait — version opérationnelle — Path : Sites application (Sites) > sélectionner le Site > champ Default Storeroom > sauvegarder. Le champ est une lookup sur les Storerooms du Site. Une fois renseigné, ce default est utilisé par : (1) Item Master quand on ajoute un item à un Storeroom sans préciser lequel (suggère le default Site) ; (2) Tools transactions sans storeroom explicite ; (3) certains rapports d'inventory. Master-map.pdf chapitre Sites + chapitre Storerooms documente cette dépendance.
Exemple chiffré — Site PLANT-A a 3 storerooms (CENTRAL, TOOLS, CONSUMABLES). Default Storeroom = CENTRAL. Un planificateur crée 50 nouveaux items via Item Master en bulk. Pour les 50, sans default Site, il devrait taper "CENTRAL" 50 fois manuellement ; avec le default, Maximo pré-remplit le storeroom à CENTRAL pour tous les 50. Il peut overrider à TOOLS pour 5 outils spécifiques, mais pour les 45 restants, gain de productivité immédiat. Sur un projet onboarding 10,000 items, cette économie d'effort est conséquente.
Analogie quotidienne — C'est comme votre adresse de livraison par défaut sur Amazon : vous avez 3 adresses (maison, bureau, garage), une marquée "default". Quand vous commandez sans préciser, Amazon livre à la default. Vous pouvez overrider une commande spécifique, mais le default vous évite de sélectionner à chaque achat. Maximo applique ce design pattern aux storerooms.
Pourquoi A est faux — A place le default storeroom sur l'Item Master (D6 Wrong-app). Faux : l'Item Master est global aux Sites/Orgs (un item peut exister dans plusieurs Sites avec des storerooms différents), donc un default storeroom par item n'aurait pas de sens. Le piège est qu'on confond avec le concept de Default Bin qui, lui, existe sur l'Inventory record (Storeroom × Item) mais pas sur l'Item Master.
Pourquoi C est faux — C invente un checkbox Default sur chaque Storeroom (D7 Non-existent). Faux : Maximo n'utilise pas un flag par storeroom mais un pointer (FK) depuis le Site. La raison : si on avait un checkbox par storeroom, plusieurs storerooms pourraient être marqués default, créant ambiguïté. Le pointer FK depuis Site garantit l'unicité (1 Site → 1 Default Storeroom). Le piège vient des autres systèmes (certains ERPs implémentent effectivement par checkbox), mais Maximo a choisi le pointer.
Pourquoi D est faux — D propose une préférence utilisateur (D6 Wrong-app). Faux : le default storeroom est une politique du Site, pas de l'utilisateur individuel. Tous les utilisateurs travaillant sur le Site héritent du même default. La raison : le default sert à harmoniser les pratiques (tous les nouveaux items vont au même storeroom par défaut, évitant la fragmentation par préférence personnelle). Si chaque user pouvait choisir son default, on aurait un chaos de préférences contradictoires.
- Organization : cost types, currency, ABC breakpoints, validation rules.
- Site : default Storeroom, default Currency, labor rate, work zones.
- User : language, time zone, default Site.
- Item Master : flags structurels, commodity, vendor.
- Inventory record : ROP, EOQ, Lead Time, Default Bin, Cost Type.
- Default Storeroom = champ sur le Site record (Sites app).
- 1 Site → 1 Default Storeroom (pointer, pas checkbox).
- Sert pour Item Master add-to-storeroom et Tools transactions sans storeroom explicite.
- master-map.pdf, IBM Maximo Manage 9 — Sites application : Default Storeroom field.
- STU sub-objective 1.2 — Create a Storeroom : Explain default storeroom for a site.
Correct :A
Pourquoi cette question existe — Le calcul de lead time dans Maximo n'est pas un simple "moyenne historique" : c'est une moyenne pondérée qui privilégie les receipts récents. Le candidat doit connaître le nom exact du champ et comprendre la logique de pondération. C'est aussi une question de filtrage des distracteurs inventés (D7) qui sonnent plausible mais n'existent pas.
Le contexte théorique d'abord — En forecasting et inventory management, deux approches coexistent pour estimer un paramètre temporel (lead time, demand) : (1) simple moving average (toutes les périodes égales, simple et stable mais lent à réagir aux changements) ; (2) weighted moving average / exponential smoothing (poids plus élevé aux périodes récentes, réagit plus vite mais plus volatile). La théorie statistique recommande l'approche pondérée pour les processus non-stationnaires (où la moyenne change dans le temps), ce qui est le cas typique des lead times en supply chain (changement de vendor, congestion port, géopolitique). [EOTRAG query 11].
Ce que Maximo en fait — version opérationnelle — Path : Storerooms application > ouvrir le storeroom > champ Recent Lead Time Weight in %. Valeur typique : 70% recent, 30% historique. Quand un nouveau receipt arrive et que le système recalcule le lead time, il applique : new_LT = 0.70 × measured_LT_for_this_receipt + 0.30 × previous_LT. Avec 0% l'algorithme ignore les receipts récents (lead time figé manuel) ; avec 100%, le lead time = le dernier receipt (très volatile). 70% est un défaut typique recommandé par STU. Master-map.pdf p.787-832 décrit le champ.
Exemple chiffré — Storeroom CENTRAL, item BEARING-001. Lead time historique = 21 jours. Recent Lead Time Weight = 70%. Nouveau receipt arrive après 14 jours (nouveau contrat logistique). Maximo recalcule : new_LT = 0.70 × 14 + 0.30 × 21 = 9.8 + 6.3 = 16.1 jours. ROP basé sur ce LT s'ajuste automatiquement. Si le weight était 100%, new_LT = 14 ; si 0%, new_LT = 21 (figé). 70% donne un compromis raisonnable.
Analogie quotidienne — Vous estimez le temps de trajet domicile-bureau : si vous le calculez sur les 30 derniers jours, votre moyenne est lente à réagir au nouveau métro qui a ouvert. Une moyenne pondérée à 70% sur les 5 derniers jours réagit plus vite. Maximo applique ce principe au lead time fournisseur.
Pourquoi B est faux — B propose "Average Lead Time Threshold" (D7 Non-existent). Aucun champ Maximo de ce nom. Le piège : le mot "threshold" sonne technique et plausible (il existe d'autres thresholds en config Maximo — count tolerance, variance threshold) mais pas pour le lead time. Trace pour exclure : aucune doc IBM ne mentionne ce champ.
Pourquoi C est faux — C propose "Lead Time Smoothing Factor" (D9 Near-synonym). "Smoothing factor" est le terme académique exact pour le paramètre α de l'exponential smoothing (Holt-Winters), donc le candidat formé en supply chain peut être trompé. Mais Maximo n'utilise pas exactement de l'exponential smoothing : c'est une simple weighted average sur 2 termes (recent vs previous), pas une décroissance exponentielle multi-périodes. Le champ Maximo réel s'appelle Recent Lead Time Weight in % et exprime un poids 0-100, pas un coefficient α de smoothing. Le piège est très tentant pour quelqu'un avec une formation académique.
Pourquoi D est faux — D propose "Forecast Decay Coefficient" (D7 Non-existent). Encore un nom plausible mais qui n'existe pas dans Maximo. La "decay" évoque l'oubli des observations anciennes, ce qui est un concept légitime en time-series, mais Maximo n'a pas de champ portant ce nom. Trace pour exclure : aucune apparition dans master-map.pdf.
- Lead Time (Inventory record) : valeur courante en jours. Utilisée par ROP = LT × D + safety.
- Recent Lead Time Weight in % (Storeroom) : poids des receipts récents dans le recalcul automatique.
- Additional Lead Time (Days) (Inventory) : buffer ajouté au LT calculé pour incertitudes.
- Vendor Lead Time (Companies) : LT par fournisseur, écrasable par le LT inventory si défini.
- Recent Lead Time Weight in % = poids 0-100 sur les receipts récents.
- Formule : new_LT = (weight × recent) + ((1-weight) × historic).
- Défaut typique : 70%. Permet adaptation aux changements vendor.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Storerooms : Recent Lead Time Weight in %.
- STU sub-objective 2.1 — Lead Time calculation using Recent Lead Time Weight in % field.
- [EOTRAG query 11 — Lead Time / Weighted Moving Average / Replenishment].
Correct :B
Pourquoi cette question existe — La Labor Inventory Location est un objet Maximo souvent ignoré qui permet de tracker la main-d'œuvre comme un stock virtuel. Elle est dans la STU 1.2 mais beaucoup de candidats l'oublient parce qu'elle est rare en pratique. L'examen la teste pour vérifier que le candidat connaît tous les types de Locations, pas uniquement Storeroom.
Le contexte théorique d'abord — En CMMS / EAM, la planification capacitaire de la main-d'œuvre (labor) suit deux modèles : (1) shop calendar approach où chaque labor record a son calendrier d'heures disponibles et le scheduling consomme ces heures ; (2) labor as inventory où la pool de main-d'œuvre est modélisée comme un stock d'heures disponibles, dont on "issue" la quantité requise par WO. Le second modèle est plus rare mais utile dans les organisations où la capacité labor est fortement contrainte et planifiée comme un budget (ex. shutdowns industriels avec 200 entrepreneurs alloués pour 30 jours).
Ce que Maximo en fait — version opérationnelle — Path : Locations application > New Location > Type = LABOR (au lieu de STOREROOM). On définit le Site, la description, et on associe les Labor records (technicians/contractors). Une Labor Inventory Location n'a pas de bins ou de balance qty traditionnelles ; elle aggrège les disponibilités heure des labor records associés. Les WOs peuvent issuer des heures contre cette location, ce qui décrémente la pool. Master-map.pdf décrit cette typologie dans le chapitre Locations.
Exemple chiffré — Pour un shutdown de 30 jours, 12 mécaniciens sont alloués. Capacité = 12 × 8h × 30 jours = 2,880 heures-mécaniciens. Une Labor Inventory Location MECHANIC-POOL est créée avec ces 12 labors associés. Chaque WO du shutdown réquisitionne X heures de la pool. WO-001 prend 50h, WO-002 prend 30h, etc. À mi-shutdown, balance = 2,880 - sum(allocated) = 1,200 heures restantes. Si une nouvelle WO demande 1,300h, le système alerte (overcommit). Cette visibilité capacité-temps réel est l'apport de la Labor Inventory Location.
Analogie quotidienne — C'est comme un budget d'heures-équipe pour un projet : 40 personnes × 200 heures = 8,000 heures budgétées. Chaque tâche affectée consomme du budget. Quand le budget est épuisé, alerte. Maximo modélise ce concept en faisant de la "pool d'heures" un objet stock-like.
Pourquoi A est faux — A propose « un Storeroom avec item type LABOR » (D9 Quasi-synonyme). Faux : un Storeroom est typé STOREROOM, pas LABOR. Ce n'est pas l'item qui type le storeroom mais le storeroom lui-même qui est typé. La distinction est : Type est une propriété de la Location (Locations app), pas du Storeroom record. Et la Location Labor Inventory est typée LABOR au niveau Location, ce qui se traduit dans Storerooms app par sa non-présence — elle ne s'affiche que dans Locations.
Pourquoi C est faux — C propose un Service item avec Prorate (D6 Wrong-app). Service items représentent des prestations achetées (consulting, calibration), facturées sur PR/PO. Pas adapté pour tracker une pool d'heures internes. Le piège : "labor as service" sonne juste pour des contractors externes facturés à l'heure, mais Maximo distingue le PO line de service externe et la pool interne tracée comme inventory.
Pourquoi D est faux — D fabrique un « Crew item avec Inspect on Receipt » (D7 Inexistant). Aucun objet Maximo ne s'appelle « Crew item ». Crew est une entité distincte (Crews application) qui regroupe Labor records pour assigner des WOs en équipe. Crew ≠ Labor Inventory Location. Le flag Inspect on Receipt n'a aucun sens dans ce contexte (il s'applique aux items physiques inspectés à la réception PO).
- STOREROOM : magasin de stocks physiques (items, tools).
- LABOR : Labor Inventory Location, pool d'heures-personnes.
- OPERATING : location opérationnelle (zone, ligne de production, salle).
- HOLDING : location temporaire pour items en attente d'inspection (WINSP).
- REPAIR : location atelier de réparation pour rotating items en refurb.
- VENDOR : location virtuelle représentant un fournisseur pour return-to-vendor.
- Labor Inventory Location = Location type LABOR.
- Sert à modéliser la pool d'heures de main-d'œuvre comme inventory.
- WOs peuvent issuer des heures contre cette location.
- Différent de Crew (Crews app) et de Service item (achats externes).
- master-map.pdf, IBM Maximo Manage 9 — Locations application : Labor type.
- STU sub-objective 1.2 — Create a Labor Inventory Location : describe usage.
Correct :C
Pourquoi cette question existe — Cette question discrimine deux concepts proches : Parent Storeroom (au niveau Storeroom) vs Reorder Storeroom (au niveau Inventory record, par item). Le candidat doit comprendre que les deux ont leur usage : le premier est structurel (hiérarchie), le second est tactique (qui fournit cet item particulier). C'est la distinction de granularité.
Le contexte théorique d'abord — En supply chain multi-echelon, deux niveaux de routage de réapprovisionnement existent : (1) storeroom-level où tous les items d'un satellite sont réapprovisionnés depuis le hub central par défaut ; (2) item-level où chaque item peut avoir un routing propre (BEARING-X depuis CENTRAL, BOLT-001 depuis vendor direct car high-volume, OIL-002 depuis VMI vendor). Le second offre plus de flexibilité tactique mais plus de complexité de config. Maximo supporte les deux niveaux : Parent Storeroom = niveau 1, Reorder Storeroom = niveau 2.
Ce que Maximo en fait — version opérationnelle — Path : Inventory application > ouvrir BEARING-X au storeroom NORTH > champ Reorder Storeroom > sélectionner CENTRAL > sauvegarder. Pour les autres items à NORTH, le champ reste vide ou pointe vers d'autres sources (vendor pour les items high-volume, autre satellite pour cross-sourcing). Lors du reorder process (manuel ou cron), si Reorder Storeroom est rempli, Maximo crée un Internal PR vers ce storeroom ; si vide, il fallback sur le Parent Storeroom (niveau 1) ; si Parent vide, il crée un External PR vers le vendor. Cette cascade de fallback est documentée dans master-map.pdf chapitre Inventory.
Exemple chiffré — Storeroom NORTH a 200 SKUs : 50 sont réapprovisionnés depuis CENTRAL (Reorder Storeroom = CENTRAL sur leur Inventory record), 100 depuis vendors directs (Reorder Storeroom vide, vendor sur Inventory), 50 depuis SOUTH (Reorder Storeroom = SOUTH, cross-sourcing pour items que SOUTH overstock). Pas besoin de toucher le Parent Storeroom de NORTH (qui peut rester vide ou être CENTRAL pour le reporting). La granularité par item est essentielle pour optimiser la chaîne logistique mixte.
Analogie quotidienne — Vous gérez votre cuisine : pour le pain, vous allez chez le boulanger (Reorder Storeroom = "boulanger") ; pour les œufs, chez le fermier ; pour les conserves, au supermarché. Vous ne dites pas "tout vient du supermarché" (Parent), vous spécifiez par catégorie. Maximo applique la même logique de routing par item.
Pourquoi A est faux — A propose Parent Storeroom (D5 Champ-frère). Parent Storeroom serait approprié si TOUS les items à NORTH devaient venir de CENTRAL (cas hub-et-rayons pur). Mais la question précise « BEARING-X spécifiquement... les autres items doivent suivre leurs propres règles de reorder ». Le Parent Storeroom imposerait CENTRAL pour tous les items qui n'ont pas de Reorder Storeroom item-level, ce qui est trop large. Le piège : Parent semble plus puissant donc plus apte à résoudre le besoin, mais en réalité c'est moins granulaire.
Pourquoi B est faux — B invente "Default Reorder Source" sur Item Master (D7 Non-existent). Aucun champ de ce nom sur l'Item Master. Le piège vient du paradigme "configurer global au niveau Master pour réutiliser partout" mais Maximo n'expose pas ce niveau pour le reorder source — c'est volontaire car le source dépend du storeroom (NORTH peut sourcer BEARING-X de CENTRAL, SOUTH peut le sourcer du vendor direct), donc le champ doit être au niveau Inventory (Storeroom × Item).
Pourquoi D est faux — D propose un "permanent template PO" (D10 Procedure-plausible). Faux pour deux raisons : (1) Maximo a des Blanket POs et des Long-Term Agreements pour des engagements vendor récurrents, mais pas un "permanent template PO entre storerooms" ; (2) le routing de réapprovisionnement entre storerooms se fait via la config Reorder Storeroom, pas via une PO pré-créée. Le piège : on imagine qu'un mécanisme manuel de "PO récurrente" résoudrait, mais c'est anti-pattern (on perd le triggering ROP, on perd l'auto-quantité EOQ).
- Niveau 1 : Inventory.Reorder Storeroom (item-level, plus prioritaire). Si rempli → Internal PR vers ce storeroom.
- Niveau 2 : Storeroom.Parent Storeroom (storeroom-level). Si Reorder Storeroom vide et Parent rempli → Internal PR vers Parent.
- Niveau 3 : Inventory.Vendor (item-level, pour external). Si Reorder Storeroom et Parent vides → External PR vers vendor.
- Niveau 4 : fallback Companies app default vendor pour cet item.
- Reorder Storeroom = champ Inventory record (Storeroom × Item). Item-level.
- Parent Storeroom = champ Storeroom record. Storeroom-level (toutes items).
- Reorder Storeroom est plus prioritaire que Parent dans la cascade.
- master-map.pdf, IBM Maximo Manage 9 — Inventory : Reorder Storeroom field.
- STU sub-objective 1.2 — Setup a Parent Storeroom for centralized ordering : Specify storeroom for internal POs · Specify reorder storeroom.
Correct :D
Pourquoi cette question existe — Les Internal POs sont conceptuellement différents des External POs : pas de fournisseur tiers, pas d'AP voucher, juste un transfert intra-entreprise. Le candidat doit comprendre cette différence comptable car elle a un impact direct sur les flux GL et le reporting financier multi-storeroom.
Le contexte théorique d'abord — En comptabilité d'entreprise, les transferts internes (intra-entreprise, intra-org) ne génèrent pas de revenue/cost externe car il n'y a pas de transaction avec une tierce partie. Ils sont neutres au P&L (pas de profit ni de perte) mais affectent le bilan (déplacement de la valeur d'inventaire d'un compte storeroom à un autre, du moment que les comptes Inventory Control sont distincts par storeroom). Cette mécanique est cohérente avec IFRS et US GAAP : pas de "vente" entre divisions de la même entité légale.
Ce que Maximo en fait — version opérationnelle — À l'issue d'un Internal PO (Internal Transfer ou Stock Transfer Order — STO), Maximo génère : (1) MATUSETRANS row à CENTRAL avec ISSUETYPE=TRANSFER, qty décrémentée, GL Inventory Control crédité ; (2) MATRECTRANS row à satellite avec qty incrémentée, GL Inventory Control debité. Pas d'AP voucher, pas de revenue/cost. Les deux comptes Inventory Control étant distincts par storeroom, le bilan retrace correctement la nouvelle distribution. Master-map.pdf chapitre PO + chapitre Inventory Transactions documente ce flux.
Exemple chiffré — Internal PO 100 bearings à $50 = $5,000. Avant : CENTRAL Inv Ctrl = $50,000, Satellite Inv Ctrl = $10,000. Après transfert : CENTRAL = $45,000 (debited $5,000), Satellite = $15,000 (credited $5,000). Total = $60,000 inchangé (zero P&L impact). Pas d'AP voucher car pas de fournisseur externe. Le coût des items reste leur cost type d'origine (FIFO, AVG, etc.) ; le receiving storeroom hérite du coût.
Analogie quotidienne — Vous transférez de l'argent entre votre compte courant et votre compte épargne (même banque). Pas de frais, pas de revenue, juste un déplacement entre deux lignes de votre bilan personnel. Maximo fait pareil entre deux storerooms de la même Org.
Pourquoi A est faux — A affirme qu'un AP voucher est généré (D3 Inverse). Faux : un AP voucher implique une dette envers un fournisseur tiers, ce qui n'existe pas en Internal PO. Le piège est de transposer le réflexe "PO = AP voucher au receipt" qui est vrai pour External PO mais pas pour Internal. La règle Maximo : External PO → vendor in Companies app → AP voucher au receipt ; Internal PO → source = autre Storeroom → pas d'AP voucher.
Pourquoi B est faux — B affirme qu'il n'y a aucun posting GL (D2 Invented). Faux : il y a bien des postings, juste pas vers un AP. Les comptes Inventory Control des deux storerooms sont mis à jour (debit côté satellite, credit côté CENTRAL). Sans ces postings, le bilan serait incorrect (la valeur d'inventaire ne suivrait pas les mouvements physiques). Le piège : "pas d'AP voucher" → "pas de GL posting" est une généralisation fausse.
Pourquoi C est faux — C invente une revenue/cost interne (D2 Invented). Faux : Maximo ne génère pas de revenue ou de cost lines au P&L pour un transfert interne. La raison comptable : les deux storerooms appartiennent à la même entité légale, pas de vente entre eux. Si C était vrai, le P&L serait gonflé artificiellement par chaque transfert interne, ce qui violerait IFRS/GAAP. Le piège vient peut-être de pratiques inter-divisions où des transferts sont parfois "vendus" en interne (transfer pricing fiscal) — mais ce n'est pas le mode par défaut Maximo.
- External PO : source = vendor (Companies). At receipt : Inventory Control debit + AP credit (dette vendor). At issue : Inventory Control credit + Expense WO debit.
- Internal PO : source = autre Storeroom (Use in PR/PO=Y). At transfer : source Inv Ctrl credit + dest Inv Ctrl debit. Pas d'AP voucher. Pas de P&L impact.
- Stock Transfer Order (STO) : variante d'Internal PO pour cross-site transfers. Mêmes flux GL.
- Cross-org transfer : entre deux Orgs, peut générer transfer pricing si configuré.
- Internal PO = transfert intra-entreprise. Pas d'AP voucher.
- GL : Inventory Control credit source + Inventory Control debit dest.
- Zero P&L impact (pas de revenue/cost interne).
- External PO ≠ Internal PO côté flux financier.
- master-map.pdf, IBM Maximo Manage 9 — Purchase Orders : Internal PO and Stock Transfer Orders.
- [EOTRAG query 13 — Maximo replenishment from parent : Internal PR + Stock Transfer when fulfilled].
- STU sub-objective 1.2 — Specify storeroom for internal POs.
Paramètres de Reorder (ROP / EOQ / Lead Time / Safety Stock)

📋 Objectifs IBM
- Configuration des paramètres clés de Reorder — ROP et Lead Time sur l'onglet Reorder Details · arrondi EOQ (doit être ≥ 1, garantit que l'order qty est un multiple d'EOQ) · impact du Safety Stock sur le ROP.
- Calcul de Reorder et logique d'Order Quantity — décrire la logique.
- Calcul du Lead Time avec le champ Recent Lead Time Weight in %.
💡 Points clés
- Quatre paramètres de reorder pilotent l'ensemble du réapprovisionnement (application Inventory > onglet Reorder Details) :
- Reorder Point (ROP) — seuil de quantité sous lequel un reorder est déclenché. Quand stock-on-hand + on-order ≤ ROP, Maximo crée une PR (ou un auto-PO si configuré).
- Economic Order Quantity (EOQ) — dans Maximo, un multiplicateur d'arrondi. L'order quantity doit être un multiple d'EOQ. PAS l'optimisation de la formule de Wilson. Ex. : EOQ=10 signifie que les commandes se font par multiples de 10 (10, 20, 30...).
- Lead Time — jours entre la commande et la réception au storeroom. Pilote le calcul de base du ROP :
basic_ROP = average_daily_usage × lead_time. - Safety Stock — buffer fixe ajouté au ROP pour absorber la variance de consommation pendant le lead time. ROP effectif = (consommation moyenne quotidienne × lead time) + safety stock.
- Formule ROP du manuel [EOTRAG query 1] :
ROP = (LT × D) + Sboù LT = lead time (jours), D = demande moyenne quotidienne, Sb = safety stock. Ex. : pour 3 bearings/jour, LT 10 jours, safety stock 5 → ROP = 30 + 5 = 35 unités. Dès que le stock descend à 35, on commande. - ROP stochastique (formulation Slater MRO) — pour des pièces à demande variable :
ROP = (D × LT) + csf × MAD × √LToù csf = customer service factor (1,65 = 95% disponibilité, 2,05 = 98%, 2,33 = 99%, 2,56 = 99,5%) et MAD = mean absolute deviation. Le terme √LT tient compte du fait que l'incertitude sur la demande croît avec la racine carrée du temps pendant le lead time. La page Reorder Details de Maximo capture la version déterministe ; les planificateurs avancés ajustent manuellement le safety stock selon σ. - Formule EOQ de Wilson (théorie académique) [EOTRAG query 2] :
EOQ_Wilson = √(2DS / H)où D = demande annuelle, S = setup/ordering cost par commande, H = annual holding cost par unité par an. Dérivée en posantd(TC)/dQ = 0oùTC = (D/Q)×S + (Q/2)×H. Le Q optimal équilibre l'ordering cost (décroît avec un Q plus grand, moins de commandes) et le holding cost (croît avec un Q plus grand, plus de stock). Six hypothèses : demande constante déterministe, lead time constant, replenishment instantané, pas de pénurie, pas de remises quantité, coût unitaire constant. - L'EOQ de Maximo s'écarte de Wilson : le champ EOQ de Maximo n'est pas l'optimum de Wilson mais un multiplicateur d'arrondi. Maximo n'optimise pas ; il garantit que l'order quantity est un multiple d'une pack size vendor-friendly (case de 12, pallet de 50, etc.). Le calcul Wilson véritable est laissé à des optimiseurs externes (Maximo Inventory Insights ML ou tableurs des planificateurs). [EOTRAG query 2 — « Le record Inventory de Maximo a un champ Order Quantity Multiple — ce ne sont pas des Wilson EOQ ; ce sont des règles pragmatiques d'arrondi de commande »]. La valeur EOQ doit être ≥ 1.
- Calcul de reorder pas à pas : Maximo évalue
required_qty = ROP + EOQ - on_hand - on_order + reservations(simplifié). Il arrondit ensuite vers le haut au prochain multiple d'EOQ. Ex. : besoin = 47 unités, EOQ = 10 → commander 50 (prochain multiple ≥ 47). Si EOQ = 1, pas d'effet d'arrondi (toute qty autorisée). - Le Safety Stock s'ajoute au ROP, pas à l'order quantity. Ex. : safety stock 10 unités, consommation moyenne quotidienne 3, lead time 10 → ROP effectif = (3 × 10) + 10 = 40. Le safety stock agit comme un buffer permanent qui survit à la consommation normale du lead time ; si tout se passe bien, il n'est jamais entamé.
- Recent Lead Time Weight in % (au niveau Storeroom) [EOTRAG query 11] — contrôle l'influence des lead times de réceptions récentes sur le lead time calculé. Avec un poids de 70%,
new_LT = 0,70 × measured_LT_for_this_receipt + 0,30 × previous_LT. Permet au système de s'adapter aux conditions changeantes de la chaîne logistique (nouveau vendor, congestion portuaire). Avec 0%, le lead time reste manuel ; avec 100%, le lead time = uniquement la dernière réception. - Order Quantity Multiple vs EOQ vs Order Unit — trois concepts proches. Order Unit = unité d'achat (BOX, EA). Order Quantity Multiple = le plus petit incrément (ex. case de 12, mais ici Maximo utilise la valeur EOQ comme multiple). EOQ dans Maximo = le multiple d'arrondi. Donc « Order Quantity Multiple » et « EOQ » sont fonctionnellement similaires dans le modèle Maximo.
- Exemple chiffré — calcul reorder complet : Item BEARING-001 au Storeroom CENTRAL. Consommation moyenne quotidienne = 5 unités, lead time = 14 jours, safety stock = 20 unités. ROP = (5 × 14) + 20 = 90. EOQ = 25 (pallets vendor de 25). On-hand = 80, on-order = 0 → reorder déclenché (80 ≤ 90). Required qty = ROP - on_hand = 90 - 80 = 10 unités minimum pour revenir au ROP, plus le buffer EOQ = 35. Arrondi au multiple de 25 → commander 50 unités. Après réception : on-hand = 130 (80 + 50).
- Zone plate de l'EOQ [EOTRAG query 2] : la courbe de coût total est en U mais TRÈS plate près de l'optimum. Des commandes à ±25% de l'EOQ de Wilson produisent moins de 5% de coût total supplémentaire. Cela signifie que arrondir aux pack sizes vendor-friendly est acceptable du point de vue coût, justifiant l'approche pragmatique de Maximo.
⚠️ Piège IBM
L'EOQ dans Maximo N'EST PAS la formule de Wilson — c'est l'idée fausse la plus testée de la Section 2.1.
- Le Wilson EOQ optimise le coût total (ordering + holding). L'EOQ de Maximo est un multiple d'arrondi vendor-friendly. Deux concepts différents — même nom.
- Maximo ne calcule pas l'EOQ pour vous ; vous saisissez la valeur (typiquement pack size vendor, case quantity ou pallet size). La vraie optimisation Wilson se fait à l'externe.
- SAM Q3 teste explicitement : « What does the Economic Order Quantity (EOQ) parameter do in relation to the order quantity? — Round the order quantity up so that it is a multiple of the EOQ value ».
- Cas limite : EOQ doit être ≥ 1. Mettre EOQ = 0 ou négatif casse le calcul de reorder.
🎯 Carte mémoire
Q. Un planificateur a besoin de 47 unités, l'EOQ de l'item dans Maximo est réglé à 10. Quelle quantité Maximo commande-t-il ?
Afficher la réponse
50 unités. L'EOQ de Maximo arrondit l'order quantity VERS LE HAUT au multiple d'EOQ le plus proche. 47 → prochain multiple de 10 ≥ 47 = 50. Le champ EOQ est un multiplicateur d'arrondi, pas une formule d'optimisation. L'optimisation de Wilson, si nécessaire, doit être faite à l'externe et le résultat saisi manuellement.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — Cette question SAM est l'archétype du test de divergence entre théorie académique (Wilson EOQ) et implémentation Maximo (rounding multiplier). C'est l'un des pièges les plus puissants de l'examen car il oppose une formule connue de tout étudiant en supply chain à la réalité opérationnelle d'un EAM industriel. Beaucoup de candidats échouent ici parce qu'ils projettent leur formation académique sur Maximo.
Le contexte théorique d'abord — La formule de Wilson (Harris-Wilson, 1913) est : EOQ = √(2DS / H) où D = demande annuelle (units/year), S = setup/ordering cost per order ($), H = annual holding cost per unit per year ($). Elle est dérivée en posant la dérivée du coût total TC(Q) = (D/Q)×S + (Q/2)×H à zéro et en résolvant pour Q. Le résultat est l'optimum analytique qui minimise la somme du coût de commande (décroît avec Q : moins de commandes par an) et du coût de stockage (croît avec Q : plus de stock moyen). Les six hypothèses de Wilson : (1) demande constante déterministe, (2) lead time constant, (3) replenishment instantané, (4) pas de pénurie autorisée, (5) pas de remises quantité, (6) coût unitaire constant. Ces hypothèses sont régulièrement violées en MRO/spare parts (demande lumpy, remises tier, contraintes vendeur). [EOTRAG query 2 — Wilson formula academic theory].
Ce que Maximo en fait — version opérationnelle — Maximo ne fait pas la math de Wilson. Le champ EOQ dans Inventory app > Reorder Details tab est un rounding multiplier : il force la quantité commandée à être un multiple entier de cette valeur. Si EOQ = 10 et que le calcul de besoin donne 47 unités, Maximo arrondit UP au multiple supérieur ≥ 47 = 50. Si EOQ = 1, pas d'arrondi (toute quantité autorisée). Si EOQ = 25 (palette vendor), commandes en multiples de 25 (25, 50, 75…). Le but Maximo est opérationnel : aligner les commandes sur les unités de packaging du fournisseur (case, pallet, drum). Master-map.pdf p.787-832 confirme cette mécanique.
Exemple chiffré — Item BEARING-001, ROP = 90, on-hand = 80, EOQ = 10. Besoin = ROP - on_hand + EOQ buffer = (90-80) + EOQ = 10 + 10 = 20 minimum, mais le calcul Maximo va plus loin et propose une quantité ≥ besoin pour atteindre Min Level + EOQ. Disons besoin = 47 (calculé internement) → arrondi au multiple de 10 ≥ 47 = 50. La PR/PO est créée pour 50 unités. Vendor livre 50 ; après receipt on-hand = 80 + 50 = 130. Si Wilson était appliqué avec D=1825/an, S=$50, H=$3 → Wilson EOQ = √(2 × 1825 × 50 / 3) = √60833 ≈ 247. Mais Maximo ne calcule pas ça — il prend le 10 entré (vendor case size).
Analogie quotidienne — Vous voulez acheter 47 œufs au supermarché. Mais les œufs se vendent en boîtes de 12. Vous achetez 4 boîtes = 48 œufs (multiple de 12 ≥ 47). Vous ne calculez pas un optimum mathématique, vous arrondissez à la boîte vendor. Maximo applique cette logique commerçante. La formule de Wilson serait l'équivalent de "combien d'œufs par mois pour minimiser frais de transport + risque de cassage" — un calcul d'optimisation pas géré par le supermarché.
Pourquoi A est faux — A propose "sets the maximum possible stock level" (D2 Invented). Faux : le maximum stock level est un autre champ Maximo (Max Level / Maximum Quantity), distinct de l'EOQ. Le piège : on imagine que l'EOQ "limite" en taille la commande, donc on associe à un plafond stock. Mais l'EOQ est plancher d'incrément, pas plafond stock. Le concept Max Level existe et sert à empêcher les commandes excessives, mais EOQ et Max Level sont 2 paramètres différents. Distinguons : EOQ = grain du multiple ; Max Level = plafond absolu.
Pourquoi B est faux — B propose "indicates the minimum time required between reorder cycles" (D9 Near-synonym). Faux : aucun champ Maximo ne contrôle le minimum-time-between-reorders. La fréquence des reorders est implicitement gérée par la combinaison ROP (déclenche quand stock bas) + lead time + EOQ. Le piège : "Economic Order Quantity" peut être lu comme "order économique" → "fréquence économique" → "temps minimum entre orders". Mais Q dans EOQ est quantity, pas time. La formule Wilson répond à "combien" pas à "quand". L'écart de cycle entre 2 orders est dérivé : cycle_time = EOQ_Wilson / D, mais ce n'est pas le rôle du champ EOQ Maximo.
Pourquoi D est faux — D propose "determine the average receipt cost using EOQ and Lead Time" (D2 Invented). Faux : le receipt cost est calculé via PO unit cost et cost type (AVERAGE / STANDARD / FIFO / LIFO / ASSET) — voir leçon 3.1. Pas de lien avec EOQ ou Lead Time. Le piège : on imagine que tous les paramètres reorder se combinent dans un calcul de coût, mais EOQ et Lead Time servent à quand et combien commander, pas à combien ça coûte. Le coût est traité par la couche cost type, complètement orthogonale.
- ROP (Reorder Point) : quantité seuil. Quand stock-on-hand + on-order ≤ ROP → trigger reorder. Formule basique :
ROP = (LT × D) + Sb. - Lead Time (LT) : durée jours entre order et availability. Composante 1 du ROP. Auto-recalculé via Recent Lead Time Weight %.
- EOQ (en Maximo) : multiplicateur d'arrondi. Order qty = round_up_to_multiple_of(EOQ). NOT Wilson formula. Doit être ≥ 1.
- Safety Stock (Sb) : buffer permanent ajouté au ROP. Absorbe la variance de consommation pendant le lead time. Effective ROP = (D × LT) + Sb.
- EOQ Maximo = round-up multiplier (NOT Wilson optimum).
- Need 47 + EOQ 10 → order 50 (multiple de 10 ≥ 47).
- EOQ doit être ≥ 1.
- Wilson math = à faire externe (Excel, Inventory Insights ML).
- SAM Sample Question 3 — IBM C1000-208 Sample Test (Section 2.1).
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Inventory : Reorder Details tab : EOQ field.
- [EOTRAG query 2 — Economic Order Quantity : Wilson formula academic theory + Maximo deviation "Order Quantity Multiple ≠ Wilson EOQ"].
- Harris-Wilson 1913 original derivation : Q* = √(2DS/H).
Correct :B
Pourquoi cette question existe — Cette question vérifie l'application correcte de la formule de base ROP. Le piège classique est d'oublier le safety stock dans le calcul (réponse A) ou de mal multiplier les facteurs. C'est une question pédagogique sur la mécanique de calcul, fondamentale pour tout planificateur Maximo.
Le contexte théorique d'abord — Le Reorder Point déterministe est : ROP = (LT × D) + Sb où LT = lead time en jours, D = demande quotidienne moyenne, Sb = safety stock. La logique : pendant le lead time (LT jours), la consommation attendue est LT × D ; pour ne pas tomber à zéro pendant cette période, il faut commander quand le stock atteint exactement LT × D. Le safety stock Sb est une marge supplémentaire qui absorbe les pics de demande non prévus pendant le lead time. Sans safety stock, ~50% des cycles auraient une rupture (variance autour de la moyenne) ; avec safety stock, on cible un service level supérieur (95%, 98%, 99%). [EOTRAG query 1].
Ce que Maximo en fait — version opérationnelle — Path : Inventory app > Reorder Details tab. Champs : Lead Time (LT en jours), Average Daily Usage (D), Safety Stock (Sb), Reorder Point (ROP). Maximo peut auto-calculer ROP avec ces inputs ou laisser le planificateur saisir manuellement. La formule standard appliquée : ROP = (LT × D) + Sb. Master-map.pdf p.787-832 chapitre Inventory documente le tab Reorder Details.
Exemple chiffré — Application directe : LT = 12 jours, D = 4 units/day, Sb = 8 units. ROP = (12 × 4) + 8 = 48 + 8 = 56 units. Quand le stock-on-hand + on-order ≤ 56, Maximo déclenche le reorder. Pendant les 12 jours du lead time, on consommera en moyenne 12 × 4 = 48 unités, le stock descendra de 56 à 8 (= safety stock) à l'arrivée du replenishment. Si la consommation est plus forte que prévu (8 au lieu de 4 sur quelques jours), le safety stock absorbe sans rupture.
Analogie quotidienne — Vous consommez 1 litre de lait par jour. Le supermarché est à 3 jours de course. Vous décidez de garder une réserve d'urgence de 2 litres. Quand votre stock atteint (3 × 1) + 2 = 5 litres, vous repartez en course. Pendant les 3 jours, vous consommez 3 litres et arrivez à 2 litres au moment où le nouveau stock arrive. Si une journée vous consommez exceptionnellement 2 litres, le buffer absorbe.
Pourquoi A est faux — A propose 48 (D4 Partial-truth). 48 = LT × D = 12 × 4, sans le safety stock. C'est le ROP basic théorique mais pas le ROP opérationnel. Oublier le safety stock = sous-évaluer le ROP = augmenter le risque de rupture pendant le lead time. Le piège est très tentant car 48 est techniquement la consommation pendant le lead time, mais le safety stock est explicitement spécifié dans la question, donc doit être inclus dans le calcul ROP.
Pourquoi C est faux — C propose 12 (D9 Near-synonym). 12 est le lead time en jours, pas une quantité. Le piège est de confondre les unités (jours vs units) ou de prendre le lead time comme proxy. Si on regarde l'écran Reorder Details Maximo, il y a un champ Lead Time (12) et un champ ROP (56) — ce sont des objets différents. La question demande la quantité ROP, pas le lead time.
Pourquoi D est faux — D propose 96 (D2 Invented). Aucune logique standard ne donne 96. Test de potentiels mauvais calculs : 96 ≠ (LT × D) + Sb = 56 ; 96 ≠ LT × D × 2 = 96... attendez, 12 × 4 × 2 = 96 (doublé). Ou 96 = (LT + Sb) × 2 = 40. Aucune correspondance avec une formule connue. Le distracteur est volontairement invented pour piéger les candidats qui doublent ou multiplient au hasard.
- ROP basique (déterministe) :
ROP = LT × D. Pas de safety stock. Risque rupture ~50%. - ROP avec safety stock flat :
ROP = (LT × D) + Sb. Maximo standard. Sb fixé manuellement. - ROP stochastique (Slater) :
ROP = (D × LT) + csf × MAD × √LT. Sb dérivé de la variance MAD. csf = service factor (1.65 pour 95%, 2.05 pour 98%, 2.33 pour 99%). - ROP avec lead-time variability :
Sb = √(LT × σ_d² + D² × σ_LT²) × csf. Pour vendors irréguliers.
- ROP standard Maximo = (Lead Time × Daily Usage) + Safety Stock.
- Ne pas oublier le safety stock !
- Trigger reorder quand stock-on-hand + on-order ≤ ROP.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Inventory : Reorder Details tab.
- [EOTRAG query 1 — Reorder Point : Logistics and Supply Chain Toolkit "ROP = (L × Dav) + Sb"].
- STU sub-objective 2.1 — ROP and Lead Time on Reorder Details tab · Safety Stock impact on ROP.
Correct :A
Pourquoi cette question existe — Comprendre l'impact opérationnel du safety stock est central pour le métier d'inventory planner. Le candidat doit savoir que le safety stock affecte le ROP (déclenche reorder plus tôt) et non l'order quantity, et que ce trade-off (moins de ruptures vs plus de stock moyen) est conscient et chiffrable.
Le contexte théorique d'abord — Le safety stock est mathématiquement positionné comme un buffer qui s'ajoute au ROP : ROP = (LT × D) + Sb. Augmenter Sb augmente le ROP de la même valeur (ΔROP = ΔSb). Conséquence : le trigger reorder se déclenche plus tôt (à un niveau de stock plus haut), donc le replenishment arrive plus tôt, donc le stock minimum touché entre 2 cycles est plus haut, donc le stock moyen sur l'année est plus haut. La pénalité = coût de stockage (typiquement 20-30% du valeur unitaire par an [EOTRAG query 2]). Le bénéfice = moindre risque de rupture pendant le lead time. C'est un trade-off classique service-level vs inventory-cost, optimisable via la formule Slater stochastic ROP : Sb = csf × MAD × √LT.
Ce que Maximo en fait — version opérationnelle — Quand on modifie Safety Stock dans Inventory app > Reorder Details tab, le ROP est immédiatement recalculé (si auto-calc activé) ou laissé inchangé (si manuel). Si auto-calc, ROP = (LT × D) + Sb_new. Au prochain reorder run, le système compare stock vs ce nouveau ROP. La quantité commandée elle-même n'est PAS affectée (elle dépend de l'EOQ et de l'écart entre stock courant et un Min Level / target). Master-map.pdf p.787-832 confirme que Sb impacte ROP, pas order qty.
Exemple chiffré — Item BEARING-001 : LT = 14, D = 5, Sb_old = 5. ROP_old = 70 + 5 = 75. On augmente Sb à 15 : ROP_new = 70 + 15 = 85. Au prochain cycle, reorder déclenche à 85 au lieu de 75 → réception plus tôt → stock minimum après réception ≈ 15 (= safety stock) au lieu de 5. Stock moyen = (peak + min)/2 ≈ (peak + 15)/2 ≈ +5 unités vs avant. Si EOQ rounds à 50, peak après receive ≈ 135 vs 125. Coût stock annuel : sur 5 unités supplémentaires en stock moyen, à $50 unit, holding 30%/an → 5 × $50 × 0.30 = $75/an. Acceptable contre une rupture qui coûte $1,000+ d'arrêt machine.
Analogie quotidienne — Vous augmentez votre réserve de batteries de 3 à 10. Vous devez aller au magasin plus souvent ? Non, la fréquence d'achat reste pareille. Mais quand votre stock atteint 10 batteries (au lieu de 3), vous repartez. Le réfrigérateur métaphorique reste donc plus rempli en moyenne : moins de risque de panne sèche, mais plus d'argent immobilisé en batteries.
Pourquoi B est faux — B affirme que la quantité commandée augmente, pas le ROP (D5 Sibling-field, sur la mauvaise variable). Faux : safety stock affecte UNIQUEMENT le ROP, pas la quantité commandée. La quantité commandée dépend de l'EOQ multiplier, pas du safety stock. Le piège : on imagine que pour avoir plus de stock en moyenne, il faut commander plus à chaque fois. Mais Maximo le résout différemment : commander plus tôt (ROP plus haut), pas commander plus (quantité même).
Pourquoi C est faux — C invente une réduction automatique du Lead Time (D2 Invented). Faux : Safety Stock et Lead Time sont des paramètres indépendants. Augmenter Sb ne réduit pas LT (LT dépend du vendor, du transport, des règles de réception). Le piège est de chercher une compensation magique entre paramètres alors qu'ils sont orthogonaux dans le modèle Maximo.
Pourquoi D est faux — D affirme que safety stock n'a pas d'effet calcul (D2 Invented). Faux : le safety stock est une input directe de la formule ROP. Si la valeur saisie n'avait aucun effet calcul, le champ n'existerait pas. Le piège vient peut-être d'une confusion avec le concept de "physical safety stock" (un bin physique tag "ne pas toucher") — qui peut exister opérationnellement mais qui est différent du paramètre numérique Safety Stock dans Maximo.
- ↑ Safety Stock → ↑ ROP → reorder trigger plus tôt → ↑ stock moyen → ↓ rupture risk → ↑ coût stockage.
- ↓ Safety Stock → ↓ ROP → reorder trigger plus tard → ↓ stock moyen → ↑ rupture risk → ↓ coût stockage.
- Optimum : équilibre entre coût de rupture (downtime, lost production) et coût de stockage. Cible typique : 95-99% service level.
- Calcul stochastique (Slater) :
Sb = csf × MAD × √LT. csf = 1.65 (95%), 2.05 (98%), 2.33 (99%).
- Safety Stock affecte le ROP (pas la quantité commandée).
- ↑ Sb → ↑ ROP → reorder plus tôt → ↑ stock moyen.
- Trade-off coût stockage vs risque rupture.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Inventory : Reorder Details tab.
- [EOTRAG query 1 — Safety Stock formula and stochastic ROP].
- STU sub-objective 2.1 — Safety Stock impact on ROP.
Correct :C
Pourquoi cette question existe — STU mentionne explicitement "EOQ rounding (must be ≥1, ensures order qty is multiple of EOQ)". L'examen vérifie que le candidat connaît cette contrainte numérique précise. La valeur 1 est un cas dégénéré qui désactive effectivement l'arrondi (toute quantité multiple de 1 = toute quantité), donc 1 est le minimum acceptable.
Le contexte théorique d'abord — Mathématiquement, "rounder une quantité au multiple de X" exige X > 0. Avec X = 0, division par zéro impossible ; avec X < 0, la notion de "multiple" n'est pas définie de manière utile. Avec X = 1, tout entier positif est multiple de 1, donc l'arrondi est inactif (passe-through). Maximo applique ces contraintes mathématiques dans la validation du formulaire pour préserver l'intégrité du calcul reorder.
Ce que Maximo en fait — version opérationnelle — Path : Inventory app > Reorder Details tab > champ EOQ. La validation Maximo : valeur entière ≥ 1, sinon erreur de saisie ("Value must be greater than or equal to 1" ou similaire). Si on tente EOQ = 0, le formulaire rejette à la sauvegarde. STU sub-objective 2.1 le confirme verbatim : "EOQ rounding (must be ≥1, ensures order qty is multiple of EOQ)". Master-map.pdf p.787-832 corrobore.
Exemple chiffré — Trois cas : (a) EOQ = 1 → order qty 47 reste 47 (multiple de 1 = passe-through). (b) EOQ = 10 → order qty 47 → arrondi à 50. (c) EOQ = 25 → order qty 47 → arrondi à 50 (multiple de 25 ≥ 47 = 50). Tentatives invalides : EOQ = 0 (rejeté), EOQ = -5 (rejeté), EOQ = 0.5 (rejeté car non-entier). La discipline numérique stricte évite des bugs subtils de rounding.
Analogie quotidienne — Quand vous achetez par boîte (œufs par 12, bières par 6, papier toilette par 24), la taille de boîte est forcément ≥ 1. Une "boîte de 0" n'a pas de sens. Maximo applique cette contrainte business à son champ EOQ.
Pourquoi A est faux — A affirme que EOQ = 0 active l'auto-calc (D2 Invented). Faux : Maximo ne calcule pas l'EOQ pour vous. Wilson math doit être faite externe. EOQ = 0 est simplement rejeté par la validation. Le piège vient de l'imagination "valeur 0 = trigger spécial" en analogie avec d'autres champs Maximo (Lead Time = 0 peut signifier "instantané"), mais ce n'est pas le cas pour EOQ.
Pourquoi B est faux — B propose EOQ négatif pour exprimer remises (D2 Invented). Faux : remises et discounts sont gérés sur le PO line ou via Companies app (vendor pricing tables), pas via le signe de l'EOQ. Aucune logique mathématique ne donne du sens à un multiple négatif. Le piège : on essaie d'attribuer à l'EOQ des fonctions multiples (rounding + discounting) alors qu'il a UN rôle unique (rounding multiplier).
Pourquoi D est faux — D propose que l'EOQ doit être multiple de 10 (D2 Invented). Faux : aucune contrainte de cette nature. EOQ peut être 1, 7, 25, 100, 47, 333… toute valeur entière ≥ 1 est valide. La contrainte "multiple de 10" n'a pas de fondement mathématique ou business — c'est un nombre arbitraire qui sonne plausible (chiffres ronds). Le piège joue sur l'intuition "vendor-friendly = chiffres ronds = multiples de 10", mais Maximo ne force pas ce pattern.
- ROP : entier ≥ 0. Peut être 0 (item never reordered automatically, manuel only).
- EOQ : entier ≥ 1. 0 et négatif rejetés. 1 = no rounding effect.
- Lead Time : entier ≥ 0 jours.
- Safety Stock : entier ≥ 0. 0 valide (pas de buffer, accepter rupture).
- Average Daily Usage : décimal ≥ 0.
- Recent Lead Time Weight in % : entier 0-100.
- EOQ ≥ 1 obligatoire. 0 et négatif rejetés.
- EOQ = 1 = pas d'arrondi (passe-through).
- Maximo ne calcule pas Wilson EOQ pour vous.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Inventory : EOQ field validation.
- STU sub-objective 2.1 — "EOQ rounding (must be ≥1, ensures order qty is multiple of EOQ)".
Correct :B
Pourquoi cette question existe — Le calcul Recent Lead Time Weight est un cas pratique de weighted moving average appliqué au lead time. Le candidat doit appliquer la formule correctement et comprendre la pondération entre new (recent) et old (historic). C'est un test de compréhension quantitative de la mécanique d'auto-update.
Le contexte théorique d'abord — La formule de moyenne pondérée à 2 termes : new_value = (weight × recent) + ((1 - weight) × old), où weight ∈ [0, 1]. C'est une forme simplifiée d'exponential smoothing à période 1. Avec weight = 0%, la valeur ne change jamais (figée). Avec weight = 100%, la valeur = recent (très volatile, ignore l'historique). Avec weight = 50%, simple average. Avec weight = 70-80% (typique en supply chain), on privilégie le récent tout en gardant un peu de stabilité historique. [EOTRAG query 11].
Ce que Maximo en fait — version opérationnelle — Path : Storerooms application > champ Recent Lead Time Weight in %. À chaque receipt, Maximo mesure le LT effectif (date receipt - date PO) et applique la formule pour mettre à jour l'Inventory.Lead Time. La mise à jour est automatique, transparente, sans intervention manuelle. Master-map.pdf p.787-832 documente le champ.
Exemple chiffré — Application directe : weight = 80% = 0.80. Old LT = 30 jours, recent measurement = 18 jours. New LT = 0.80 × 18 + 0.20 × 30 = 14.4 + 6.0 = 20.4 jours. Le nouveau lead time descend de 30 à 20.4, reflétant le nouveau régime logistique mais pas complètement (on garde un peu d'historique pour stabilité). Au prochain receipt, si encore 18 jours : new LT = 0.80 × 18 + 0.20 × 20.4 = 14.4 + 4.08 = 18.48. Convergence asymptotique vers 18 mais avec amortissement.
Analogie quotidienne — Vous estimez la durée moyenne de votre trajet domicile-bureau. Votre estimation actuelle (avec ancien itinéraire) = 30 min. Aujourd'hui, nouveau métro, trajet en 18 min. Si vous mettez à jour votre estimation à 80% sur la nouvelle mesure : new estimate = 20.4 min. Vous ne sautez pas brutalement à 18 (au cas où c'était un coup de chance), vous convergez progressivement.
Pourquoi A est faux — A propose 18 (D4 Partial-truth). 18 serait correct si weight = 100% (remplacement complet). Avec weight = 80%, on garde 20% de l'historique, donc le résultat est entre 18 et 30. Le piège : "weight élevé" → "remplacement quasi-complet" → on arrondit mentalement à 18. Mais la math dit 20.4, pas 18.
Pourquoi C est faux — C propose 24 = simple average de 18 et 30 (D9 Near-synonym). Faux : Maximo applique une moyenne pondérée, pas une moyenne simple. Le simple average correspondrait à weight = 50%. Le piège est de confondre les deux types de moyenne, ou de faire le calcul sans regarder la pondération.
Pourquoi D est faux — D propose 30, valeur historique inchangée (D3 Inverse). 30 serait le cas si weight = 0% (figé). Avec weight = 80%, l'historique est largement minoré (20% seulement). Le piège est de croire que l'historique domine quand le weight n'est pas spécifié comme "élevé pour le récent" mais comme "le historique reste l'ancre" — confusion sémantique.
- weight = 0% : LT figé, pas d'auto-update. Maintenance manuelle pure.
- weight = 30-50% : conservative, lent à réagir aux changements vendor.
- weight = 70-80% : recommandé STU, équilibre adaptation et stabilité.
- weight = 100% : LT = dernier receipt, très volatile, peut osciller sur outliers.
- Formule : new_LT = (weight × recent) + ((1 - weight) × old). Application à chaque receipt.
- new_LT = (weight × recent) + ((1 - weight) × old).
- Weight 80%, old 30, recent 18 → new = 0.8×18 + 0.2×30 = 20.4.
- Configuré au niveau Storeroom (pas Inventory).
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Storerooms : Recent Lead Time Weight in %.
- [EOTRAG query 11 — Lead Time / Weighted Moving Average / Replenishment].
- STU sub-objective 2.1 — Lead Time calculation using Recent Lead Time Weight in % field.
Correct :B
Pourquoi cette question existe — La logique de calcul de la quantité commandée combine deux étapes : (1) calculer le deficit, (2) arrondir au multiple d'EOQ. Le candidat doit appliquer les deux et comprendre que l'EOQ est appliqué après le deficit, pas en remplacement.
Le contexte théorique d'abord — En reorder logic, deux approches existent : (1) Min-Max (Min Level = ROP, Max Level = target stock) où l'order qty = Max - on_hand ; (2) ROP-EOQ où order qty = EOQ fixe à chaque cycle. Maximo combine les deux : il calcule le deficit pour ramener à un niveau cible (proche du ROP ou un Min Level si défini), puis arrondit au multiple d'EOQ supérieur. Cette double mécanique offre flexibilité (couvre le besoin réel) et discipline vendor (multiple pack size).
Ce que Maximo en fait — version opérationnelle — Algorithme simplifié : deficit = max(0, ROP - on_hand - on_order + reservations) ; order_qty = ceil(deficit / EOQ) × EOQ. La fonction ceil arrondit toujours UP. Si EOQ = 1, no effective rounding. Master-map.pdf p.787-832 + chapitre Reorder describe l'algorithme.
Exemple chiffré — Application directe : ROP = 100, on-hand = 60, on-order = 0. Deficit = 100 - 60 = 40 (= la quantité minimum pour remonter au ROP). EOQ = 25. Arrondi UP : ceil(40/25) × 25 = ceil(1.6) × 25 = 2 × 25 = 50 unités. La PR créée propose 50 unités au vendor. Après receipt, on-hand passe de 60 à 110, soit 10 au-dessus du ROP — ce surplus EOQ-rounded est le buffer normal pour ne pas re-déclencher trop vite.
Analogie quotidienne — Vous voulez 40 œufs mais le vendor vend par boîte de 25. Vous achetez 2 boîtes = 50 œufs (ceil(40/25) = 2). Vous ne pouvez pas acheter "1.6 boîtes". L'arrondi UP garantit que vous couvrez le besoin sans rupture.
Pourquoi A est faux — A propose 40 (D4 Partial-truth). 40 est le deficit pur, sans appliquer le rounding EOQ. Le piège est de calculer correctement le deficit puis d'oublier l'étape de rounding. Si EOQ = 1, A serait correct ; mais avec EOQ = 25, l'arrondi est obligatoire. La trace : Maximo vous force à respecter le packaging vendor.
Pourquoi C est faux — C propose 25 = EOQ seul (D4 Partial-truth). 25 ne couvre pas le deficit de 40 → après réception on-hand = 60 + 25 = 85, en-dessous du ROP de 100 → reorder se redéclencherait immédiatement. Maximo évite cette boucle en arrondissant UP au multiple ≥ deficit, pas en commandant un EOQ par défaut. Le piège : on imagine "EOQ = quantité à commander" comme dans Wilson, mais en Maximo c'est un multiplier, pas une quantité fixe.
Pourquoi D est faux — D propose 100 = ROP (D2 Invented). Faux : ROP est un trigger threshold (quand commander), pas une quantité (combien commander). Le piège est de confondre les deux paramètres. Ordering 100 quand on a déjà 60 mènerait à 160 on-hand, surstock inutile. Maximo cible le deficit (40), pas le ROP entier.
- Étape 1 : compute deficit = max(0, ROP - on_hand - on_order + reservations).
- Étape 2 : if deficit ≤ 0, no reorder.
- Étape 3 : if deficit > 0, compute order_qty = ceil(deficit / EOQ) × EOQ.
- Étape 4 : créer PR avec order_qty, source = Reorder Storeroom ou Vendor.
- Étape 5 : workflow d'approbation optionnel avant conversion PR → PO.
- Order qty = ceil(deficit / EOQ) × EOQ.
- Deficit 40, EOQ 25 → order 50 (2 × 25).
- EOQ s'applique APRES le calcul du deficit, pas comme remplacement.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Inventory : Reorder algorithm.
- STU sub-objective 2.1 — Reorder Calculation and Order Quantity Logic.
Correct :C
Pourquoi cette question existe — Cette question synthèse vérifie que le candidat distingue clairement les deux paramètres centraux du reorder. Mélanger leurs rôles est une erreur fréquente qui produit des configurations bancales (ROP utilisé comme order qty, EOQ traité comme threshold).
Le contexte théorique d'abord — Dans tout système de réapprovisionnement, on distingue trois questions : (1) quand commander ? — répondu par le trigger / threshold (ROP) ; (2) combien commander ? — répondu par l'order quantity logic (EOQ ou Min-Max) ; (3) chez qui ? — répondu par Reorder Storeroom / Vendor. Les trois sont orthogonaux et configurables séparément. Confondre quand et combien est une erreur logique fondamentale.
Ce que Maximo en fait — version opérationnelle — Sur le Reorder Details tab : ROP est dans une section "When to order" (avec Lead Time, Safety Stock, Avg Daily Usage) ; EOQ est dans une section "How much to order" (avec Order Unit, Min/Max Levels). La séparation visuelle dans l'interface reflète la séparation conceptuelle. Master-map.pdf p.787-832 décrit cette structure.
Exemple chiffré — ROP = 100 (trigger). EOQ = 25 (rounding). On-hand baisse à 60 (≤ 100) → reorder triggered. Order qty = arrondi UP du deficit (40) au multiple de 25 = 50. Receipt arrive : on-hand = 110. Quand on-hand redescend à 100 ou moins, nouveau cycle. ROP et EOQ jouent à des étapes différentes : ROP au déclenchement, EOQ au calcul de la qty.
Analogie quotidienne — Imaginez votre frigo. ROP = "quand reste 1 carton de lait, je rachète" (trigger). EOQ = "j'achète par packs de 4 cartons" (rounding multiplier). Les deux décisions sont indépendantes : vous pouvez changer le seuil sans changer la taille de pack, et vice-versa.
Pourquoi A est faux — A propose qu'ils sont interchangeables (D2 Invented). Faux : ils ont des rôles distincts et non-substituables. Si on mettait ROP à la place d'EOQ ou vice-versa, l'algorithme produirait des résultats absurdes. Le piège vient peut-être d'une mauvaise compréhension qui voit "deux nombres dans le même tab = même fonction".
Pourquoi B est faux — B inverse les rôles (D3 Inverse). Le piège est puissant car les définitions sont précises mais facilement renversables si on n'a pas bien compris. Trace pour exclure : SAM Q3 et la doc IBM-Maximo-9 confirment que ROP = trigger, EOQ = rounding multiplier.
Pourquoi D est faux — D place ROP au Storeroom et EOQ à l'Item Master (D6 Wrong-app). Faux : les deux sont au niveau Inventory record (Storeroom × Item) sur le Reorder Details tab. Le piège est de croire à une asymétrie configuration-niveau qui n'existe pas. Trace : ouvrir l'Inventory app → les deux champs sont sur le même tab.
- ROP (Reorder Point) — quand commander. Threshold quantité. Trigger reorder if stock ≤ ROP. Formule : (LT × D) + Sb.
- Lead Time (LT) — durée vendor. Composante de ROP. Auto-update via Recent Lead Time Weight %.
- EOQ — combien commander, granularité. Rounding multiplier. Order qty = ceil(deficit/EOQ) × EOQ. Doit être ≥ 1.
- Safety Stock (Sb) — buffer permanent. Composante de ROP. Absorbe variance demande pendant LT.
- Tous au niveau Inventory (Storeroom × Item), sur Reorder Details tab.
- ROP = WHEN to order (trigger threshold).
- EOQ = HOW MUCH increment (rounding multiplier).
- Lead Time + Safety Stock alimentent ROP.
- Tous sur Inventory.Reorder Details.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Inventory : Reorder Details tab.
- SAM Sample Question 3 — IBM C1000-208 (EOQ rounding).
- [EOTRAG queries 1, 2 — ROP and EOQ in Maximo].
Correct :A
Pourquoi cette question existe — Cette propriété mathématique de la courbe de coût Wilson (U-shape avec un minimum très plat) justifie pourquoi Maximo peut s'en passer comme outil d'optimisation : les arrondis aux pack sizes vendor ne coûtent quasi rien. C'est un point théorique avancé qui confirme la légitimité du choix architectural Maximo.
Le contexte théorique d'abord — La fonction de coût total de Wilson : TC(Q) = (D/Q)×S + (Q/2)×H. Sa dérivée seconde au point optimum est positive (convexité), confirmant un minimum, mais sa valeur est faible — la courbe est plate. Une analyse de sensibilité montre : si Q dévie de Q* de ±25%, le ratio TC(Q)/TC(Q*) reste < 1.05 (moins de 5% de surcoût). Mathématiquement : TC(Q)/TC(Q*) = ½(Q/Q* + Q*/Q), qui pour Q = 1.25×Q* donne ½(1.25 + 0.8) = 1.025 (+2.5% seulement) ; pour Q = 0.75×Q*, donne ½(0.75 + 1.333) = 1.04 (+4% environ). [EOTRAG query 2 — "EOQ tolerates rounding to convenient pack sizes"].
Ce que Maximo en fait — version opérationnelle — Maximo capitalise sur cette propriété : l'EOQ field stocke la pack size vendor (rounding multiplier), pas le Wilson optimum, sans pénalité notable. Conséquence pratique : un planificateur qui rentre EOQ = 200 (palette vendor) au lieu de 247 (Wilson optimum) voit un surcoût total < 1% — invisible dans les budgets réels. Cette approche pragmatique simplifie radicalement la config Maximo. Master-map.pdf et la doc Inventory Insights ML font référence à cette propriété pour justifier l'absence d'optimiseur Wilson natif.
Exemple chiffré — Wilson EOQ = 247. D = 1825/an, S = $50/order, H = $3/unit/year. TC(Wilson) = (1825/247)×50 + (247/2)×3 = 369 + 370 = $739/an. Si on prend Q = 200 (palette) : TC(200) = (1825/200)×50 + (200/2)×3 = 456 + 300 = $756/an. Surcoût = $17/an = 2.3%. Si Q = 250 : TC(250) = (1825/250)×50 + (250/2)×3 = 365 + 375 = $740/an. Surcoût = $1/an = 0.1%. Conclusion : pas la peine de chasser le Q parfait quand l'arrondi à la pack size vendor coûte 1-3% en plus seulement.
Analogie quotidienne — Imaginez la consommation d'essence d'une voiture sur la vitesse : minimum vers 90 km/h, mais entre 80 et 100 km/h le rendement varie de quelques pourcents seulement. Vous pouvez rouler à 95 km/h sans gros pénalité. Wilson EOQ a la même propriété : un peu à côté du minimum coûte très peu en plus.
Pourquoi B est faux — B propose une sensibilité linéaire ±25% → ±25% extra cost (D2 Invented). Faux : la sensibilité est sous-linéaire grâce à la convexité de la fonction. La math TC(Q)/TC(Q*) montre que +25% d'écart de Q produit ~+2.5% de TC, pas 25%. Le piège vient de l'intuition "plus loin de l'optimum = proportionnellement plus cher" qui s'applique aux fonctions linéaires mais pas aux U-shape convexes.
Pourquoi C est faux — C dramatise toute déviation comme "catastrophique" (D2 Invented). Faux et anti-pratique. Si toute déviation était catastrophique, aucun système réel (avec contraintes vendor pack size) ne pourrait fonctionner. Le piège vient peut-être d'une lecture rigide de Wilson où l'optimum mathématique est interprété comme inviolable. La théorie elle-même montre que ±25% est très bénin.
Pourquoi D est faux — D affirme que Wilson est totalement irrelevant en MRO (D3 Inverse). Faux : Wilson est utile en MRO comme point de départ analytique, simplement ses 6 hypothèses (constant demand, no shortage, etc.) sont souvent violées en pratique, ce qui justifie des ajustements (mais pas l'abandon). Le piège vient peut-être de la frustration "Maximo n'utilise pas Wilson donc c'est inutile" — mais Maximo ne l'utilise pas comme calcul automatique, ce qui ne signifie pas qu'il est inutile pour le planificateur en amont.
- Formule : EOQ* = √(2DS/H).
- Courbe TC(Q) : U-shape, minimum à Q*, très plate near optimum.
- Sensibilité : Q = (1±0.25) × Q* → TC ≈ Q* × (1 + 0.025 to 0.04). Très tolérant aux arrondis.
- 6 hypothèses : demande constante déterministe, LT constant, replenishment instant, no shortage, no quantity discount, constant unit cost.
- Usage en MRO : starting point pour planification, à ajuster pour packaging vendor, MOQ, demande lumpy.
- Wilson EOQ courbe TC = U-shape FLAT près de l'optimum.
- ±25% écart Q* → moins de 5% extra cost.
- Justifie pourquoi Maximo peut arrondir au pack size vendor.
- [EOTRAG query 2 — Workbook MRO Inventory and Purchasing : "EOQ flat zone — orders within ±25% of EOQ produce less than 5% extra cost"].
- Harris-Wilson 1913 + Hadley & Whitin (1963) Analysis of Inventory Systems.
- STU sub-objective 2.1 — Reorder Calculation logic context.
Exécution du Reorder (Use in PR/PO / Cron / Internal PO / Special Order)

📋 Objectifs IBM
- Désignation du Reorder Storeroom.
- Initiation et timing du processus de Reorder — Cron Task manuel vs automatique · reorder manuel depuis l'application Inventory · usage du flag Reorder (vs catégories STK et NS dépréciées).
- Commande de Special Order Items — auto-création d'un Item Master au statut PENDING (l'item n'est pas visible pour les futures commandes) · auto-création d'un inventory record (ItemOrgDetails) au statut Active si commandé vers un Storeroom.
- Commande d'items depuis un autre storeroom — flag Use in PR/PO sur le record Storeroom · Internal PO.
💡 Points clés
- L'exécution du reorder = l'acte de déclencher et traiter le cycle de reorder défini par les paramètres (ROP, Lead Time, EOQ, Safety Stock — voir leçon 2.1). Deux modes d'exécution : (1) manuel via l'action « Reorder Items » de l'application Inventory, (2) automatique via la Cron Task (job batch planifié, typiquement nocturne).
- Reorder manuel — Path :
Inventory app > Select Action > Reorder Items. Permet au planificateur de déclencher un reorder pour un storeroom ou un sous-ensemble d'items immédiatement. Utile pour le réapprovisionnement ad hoc après une grosse consommation WO, après un shutdown, ou pour vérification rapide avant de partir (au lieu d'attendre le cron). Sortie : une liste de candidats au reorder ; le planificateur peut revoir, ajuster les quantités et approuver / convertir en PR / PO. - Reorder automatique via Cron Task — Path :
Cron Task Setup application > cron task REORDER (ou similaire). Planning configurable (typiquement chaque nuit à 02:00). Le cron évalue tous les Inventory records éligibles dans son périmètre, calcule le déficit et crée des PRs (ou des auto-POs si le flag autoPO est activé et le vendor pré-approuvé). La cron task est le cheval de trait du planning à grand volume — tourne sans surveillance, traite des milliers d'items par nuit. - Le flag Reorder (Inventory record) — une checkbox sur l'Inventory record qui autorise l'item à participer au reorder process (manuel ou cron). Si décoché, l'item est exclu des calculs de reorder même si son ROP est atteint. Utile pour les items qu'on veut gérer manuellement ou pour les items en statut PENDING qu'il ne faut pas auto-reorder.
- Catégories STK et NS dépréciées (nouveauté v9.1) — Dans les versions Maximo plus anciennes (v7.6 et antérieures), le record d'inventaire avait un champ Category avec les valeurs STK (stocked, éligible au reorder) et NS (non-stock, non éligible). Avec v9.1, IBM a déprécié cette discrimination par catégorie au profit du flag Reorder plus simple. Les items précédemment NS sont désormais des items avec flag Reorder = N. Cette dépréciation v9.1 est probablement testée à l'examen — la certification couvre spécifiquement Maximo Manage v9.1.
- Les items au statut PLANNING sont reorderables [SAM Q4 verbatim] — piège contre-intuitif. PLANNING est un statut transitoire qui permet à la chaîne logistique de monter en charge avant que l'item soit ACTIVE. Seuls les statuts PENDING et OBSOLETE bloquent le reorder.
- Les Soft Reservations sont prises en compte dans le reorder — les soft reservations (réservation prévue sur une WO planifiée future) réduisent la quantité disponible calculée. Maximo les inclut dans le calcul du déficit. Certains systèmes ignorent les soft reservations ; Maximo NE le fait PAS (c'est un comportement spécifique Maximo et un distracteur SAM Q4).
- Désignation du Reorder Storeroom (rappel leçon 1.2) — Le Reorder Storeroom se règle au niveau Inventory record (par item par storeroom). Quand le reorder s'exécute, si le Reorder Storeroom est rempli, une Internal PR est créée (transfert depuis ce storeroom source). Si vide, fallback sur le Parent Storeroom ou un Vendor externe.
- Checkbox Use in PR/PO (rappel leçon 1.2, SAM Q2) — checkbox au niveau Storeroom qui permet à ce storeroom d'être une source sur des lignes PR/PO. Requise pour le pattern de fourniture interne storeroom-to-storeroom.
- Workflow Special Order Items — pour des achats one-off d'items non stockés habituellement (une valve custom, un instrument rare). À la création de la PR/PO, l'acheteur saisit une description et un prix ; Maximo auto-crée un Item Master record au statut PENDING (l'item est enregistré pour la traçabilité mais n'est pas visible pour les futures PRs). Si la special order va vers un Storeroom (pas Direct Issue), un Inventory record (ItemOrgDetails) est auto-créé au statut Active. Cette combinaison garantit que le special-order item est traçable une fois mais ne pollue pas le catalogue d'items réutilisables.
- Direct Issue vs destination Storeroom — Une PR/PO peut livrer vers un Storeroom (stocké) ou directement vers une WO / Asset / Location (Direct Issue, contourne l'inventaire). Pour Direct Issue, aucun Inventory record n'est créé ; l'item file droit dans les actuals de la WO. Pour Storeroom, la comptabilisation d'inventaire complète (MATRECTRANS, mise à jour de balance, postings GL) s'applique.
- Exemple chiffré — cycle reorder complet : la cron task tourne à 02:00. Item BEARING-001 à NORTH : ROP = 90, on-hand = 80, on-order = 0, EOQ = 25. Flag Reorder = Y. Reorder Storeroom = CENTRAL (qui a Use in PR/PO = Y). Le cron calcule déficit = 10, arrondit VERS LE HAUT au multiple de 25 = 25. Crée une Internal PR : source CENTRAL, dest NORTH, qty 25 BEARING-001. PR auto-approuvée durant la nuit (si workflow le permet) → Stock Transfer Order. Le camion livre le lendemain matin, NORTH reçoit → on-hand = 105.
flowchart TD CRON["Cron Task déclenchée
(REORDER) selon planning"]:::start STATUS{"Statut item
ACTIVE ou PLANNING ?
(SAM Q4 — réponse b)"}:::decision SKIPSTATUS["Skip
(PENDING / OBSOLETE
exclus du reorder)"]:::stop CHECK{"Available position
= current_balance
+ open_orders
− reservations
inférieur au ROP ?"}:::decision STOP["Aucune action
(stock suffisant)"]:::stop SPECIAL{"Item
special-order ?"}:::decision CREATE_ITEM["Auto-création Item Master
au statut PENDING
(non visible aux futures
commandes)
+ ItemOrgDetails (ACTIVE)"]:::action ROUND["Calcul du besoin ; arrondi
au multiple supérieur d'EOQ
(EOQ ≥ 1, SAM Q3)"]:::action USEPRPO{"Le Storeroom a
Use in PR/PO ✔
(fournisseur interne) ?"}:::decision PR_INT["Internal PR /
Stock Transfer
depuis le parent storeroom"]:::action PR_EXT["External PR
vers vendor"]:::action VENDOR["Vendor reçoit la PR
→ expédie les biens"]:::action RECEIVE["Goods reçus
(ligne MATRECTRANS)"]:::action BALANCE["Balance Storeroom
+= receipt_qty"]:::endNode CRON --> STATUS STATUS -- "Oui (éligible)" --> CHECK STATUS -- "Non" --> SKIPSTATUS CHECK -- Non --> STOP CHECK -- Oui --> SPECIAL SPECIAL -- Oui --> CREATE_ITEM CREATE_ITEM --> ROUND SPECIAL -- Non --> ROUND ROUND --> USEPRPO USEPRPO -- Oui --> PR_INT USEPRPO -- Non --> PR_EXT PR_INT --> RECEIVE PR_EXT --> VENDOR VENDOR --> RECEIVE RECEIVE --> BALANCE classDef start fill:#3B82F6,stroke:#1E40AF,color:#FFFFFF,font-weight:600; classDef decision fill:#F59E0B,stroke:#B45309,color:#FFFFFF; classDef action fill:#FFFFFF,stroke:#94A3B8,color:#0F172A; classDef stop fill:#F1F5F9,stroke:#94A3B8,color:#475569; classDef endNode fill:#1D9E75,stroke:#178A66,color:#FFFFFF,font-weight:600;
⚠️ Piège IBM
« Les items PLANNING ne sont pas reorderables » — faux. SAM Q4 teste explicitement ce piège.
- PLANNING est un statut qui permet à la chaîne logistique d'être AMORCÉE pendant que l'item est finalisé pour un usage Active complet. Reorder, Job Plan, Spare Parts list — tout est autorisé.
- Seuls les statuts PENDING (brouillon) et OBSOLETE (fin de vie) bloquent le reorder.
- Les soft reservations SONT prises en compte dans les calculs de reorder dans Maximo (un distracteur SAM mentionnait l'inverse).
- Le champ « Additional Lead Time (Days) » ajoute des jours au lead time calculé ; il ne programme PAS le reorder pour une date future. Si on veut que le reorder attende, c'est un délai de workflow / approbation, pas une fonction de Lead Time.
- L'action « Reorder Items » traite UN storeroom à la fois, pas plusieurs. Pour reorder plusieurs storerooms, lancer l'action une fois par storeroom ou s'appuyer sur la cron task.
🎯 Carte mémoire
Q. Quels statuts d'item bloquent la participation au processus de reorder ?
Afficher la réponse
Seuls PENDING (brouillon, pas prêt) et OBSOLETE (fin de vie) bloquent le reorder. PLANNING, ACTIVE et PENDING OBSOLETE autorisent tous le reorder. PLANNING est le statut surprenant — il autorise le reorder pour que la chaîne logistique puisse monter en charge avant l'activation opérationnelle complète. SAM Q4 le confirme verbatim.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :B
Pourquoi cette question existe — Cette question SAM teste 4 traps simultanés autour du processus de reorder. La bonne réponse (PLANNING reorderable) est contre-intuitive — PLANNING sonne comme "pas encore prêt" mais c'est précisément le statut qui permet d'amorcer la chaîne logistique. Les 3 distracteurs sont chacun de fausses affirmations courantes que les candidats projettent par habitude d'autres systèmes.
Le contexte théorique d'abord — Le lifecycle d'un item dans un EAM passe par plusieurs phases : draft (Pending), supply-prepared (Planning), full operational (Active), phasing-out (Pending Obsolete), end-of-life (Obsolete). La phase Supply-prepared / Planning existe explicitement pour combler le gap entre "spec validée" et "premières unités disponibles" — pendant ce gap, on doit pouvoir commander les unités initiales pour qu'elles arrivent en stock avant l'activation Active. Bloquer le reorder en Planning empêcherait toute introduction d'item nouveau dans la chaîne. C'est un design pattern lifecycle.
Ce que Maximo en fait — version opérationnelle — Au reorder process (manuel ou cron), Maximo filtre les Inventory records éligibles. Le filtre exclut : (1) status Pending de l'item au niveau Master/Org/Inventory, (2) status Obsolete, (3) Reorder flag = N. Le filtre n'exclut pas Planning, Active, ni Pending Obsolete. Master-map.pdf p.787-832 + chapitre Reorder confirme cette logique. SAM Q4 verbatim : « Les items au statut PLANNING peuvent être inclus dans un reorder process ».
Exemple chiffré — Liste de 100 items dans Inventory : 5 en PENDING (excluded), 10 en PLANNING (included), 70 en ACTIVE (included), 10 en PENDING OBSOLETE (included for clean-up reorder if still needed), 5 en OBSOLETE (excluded). Eligible pour reorder = 90 items. Le cron task évalue ces 90, calcule les deficits, et crée des PRs pour ceux qui en ont. Si on excluait par erreur les 10 PLANNING, la chaîne logistique d'introduction ne pourrait pas s'amorcer pour ces nouveaux items.
Analogie quotidienne — Un nouveau plat dans un restaurant en phase "validation chef" (= Planning) : la cuisine commande déjà les ingrédients chez le fournisseur pour pouvoir tester. Si le statut Planning bloquait les commandes ingrédients, comment tester avant de servir ? La phase Planning existe pour autoriser la pré-commande tout en interdisant le service au client.
Pourquoi A est faux — A affirme que les soft reservations ne sont jamais considérées (D3 Inverse). Faux : Maximo inclut les soft reservations dans le calcul du deficit. Une soft reservation est une réservation prévue (sur une WO future programmée), elle réduit le stock disponible théorique → augmente le deficit → déclenche reorder plus tôt. Si A était vrai, on aurait des ruptures sur les WOs programmées car le système n'aurait pas anticipé. Le piège vient peut-être de la confusion soft (planned) vs hard (committed) : Maximo distingue les deux mais inclut les soft dans la planification reorder.
Pourquoi C est faux — C affirme que la Reorder Items action permet de reorder depuis multiple storerooms en une seule fois (D4 Partial-truth). Faux : l'action Reorder Items s'applique à un storeroom à la fois (le storeroom actif dans l'Inventory app). Pour reorder multiple storerooms, il faut soit relancer l'action storeroom par storeroom, soit utiliser le cron task qui itère naturellement sur tous les storerooms en scope. Le piège est de penser que l'UI permet une sélection multi-storeroom, alors qu'elle est mono-storeroom.
Pourquoi D est faux — D affirme que Additional Lead Time (Days) planifie le reorder à une date future (D9 Quasi-synonyme). Faux : Additional Lead Time (Days) est un buffer ajouté au lead time existant pour augmenter le ROP, pas une date de planification du reorder. Si on ajoute 5 jours au LT de 10, le LT effectif devient 15 jours et le ROP s'ajuste. Le reorder lui-même se déclenche immédiatement quand le ROP est atteint, pas à une date future. Le piège : « Additional Lead Time » sonne comme « délai avant déclenchement » alors que c'est « marge supplémentaire dans le calcul du LT ».
- PENDING : NOT eligible. Draft state, item not finalized.
- PLANNING : eligible (SAM Q4). Pre-Active, supply chain ramp-up.
- ACTIVE : eligible. Full lifecycle.
- PENDING OBSOLETE : eligible (clean-up only, plan for end-of-life). Often Reorder flag manually disabled.
- OBSOLETE : NOT eligible. End of life, no more orders.
- Reorder flag = N (n'importe quel statut) : NON éligible. Override au niveau item.
- PLANNING items ARE reorderable (SAM Q4).
- Soft reservations sont incluses dans le calcul deficit.
- Reorder Items action = mono-storeroom à la fois.
- Additional Lead Time (Days) = buffer LT, pas un schedule.
- SAM Sample Question 4 — IBM C1000-208 Sample Test (Section 2.2).
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Inventory : Reorder process and item status filtering.
- STU sub-objective 2.2 — Initiation and Timing of Reorder Process · Item statuses.
Correct :C
Pourquoi cette question existe — La certification C1000-208 cible spécifiquement Maximo Manage v9.1. Une nouveauté importante de v9.1 est la dépréciation des catégories STK/NS au profit du flag Reorder. Le candidat doit connaître cette évolution car elle impacte la migration et les questions d'interprétation des items legacy.
Le contexte théorique d'abord — En software lifecycle management, la "deprecation" est l'étape où une feature est officiellement marquée comme "à remplacer" : elle continue à fonctionner mais (a) n'est plus le mécanisme recommandé, (b) sera retirée dans une version future. La transition doit permettre aux clients legacy de migrer progressivement. Pour les Maximo customers, la migration v7.6 → v9.1 implique de comprendre que certaines configs deviennent obsolètes mais restent fonctionnelles le temps de la transition.
Ce que Maximo en fait — version opérationnelle — Dans v9.1, le champ Reorder (checkbox Y/N) sur l'Inventory record est le mécanisme canonique pour contrôler l'éligibilité au reorder. Path : Inventory app > ouvrir l'item > champ Reorder. Si Y, l'item participe au reorder process ; si N, il est exclu. Les anciennes catégories STK et NS (Category field) restent visibles pour la rétrocompatibilité mais sont marquées deprecated dans la doc IBM. À terme (v10+), STK/NS seront retirées. STU sub-objective 2.2 mentionne explicitement "use of the Reorder flag (vs deprecated STK & NS categories)".
Exemple chiffré — Site migrant de v7.6 vers v9.1. Avant : 5,000 items avec Category = STK, 200 items avec Category = NS. Après migration : Maximo v9.1 mappe Category=STK → Reorder flag = Y ; Category=NS → Reorder flag = N. Les anciennes valeurs Category restent pour audit mais ne sont plus modifiées par les utilisateurs. Les nouveaux items créés en v9.1 utilisent uniquement le Reorder flag, le champ Category reste vide (ou avec une valeur "type d'item" différente, pas STK/NS).
Analogie quotidienne — Comme quand un site web remplace son login par mot de passe par un login passkey : pendant la transition, les deux fonctionnent, mais le passkey est le nouveau standard et le mot de passe sera retiré dans 1-2 ans. Maximo fait la même transition entre Category STK/NS et Reorder flag.
Pourquoi A est faux — A affirme que STK/NS reste canonique en v9.1 (D1 Legacy). Faux : c'est précisément le pattern legacy que la question vise à corriger. Le piège : un candidat formé sur v7.6 par habitude pourrait répondre A. STU et la doc IBM sont explicites sur la dépréciation.
Pourquoi B est faux — B invente "SUPPLY/NON-SUPPLY enumeration" (D7 Non-existent). Aucun objet de ce nom dans Maximo v9.1. Le piège vient du paradigme "remplacement par renommage" — on imagine que IBM a juste renommé STK/NS en autre chose. Mais en réalité, IBM a remplacé une enum par un boolean (checkbox), simplifiant le modèle.
Pourquoi D est faux — D propose que Reorder Storeroom remplace STK/NS (D6 Wrong-app). Faux : Reorder Storeroom est un champ qui spécifie la source du reorder (où se procurer), pas l'éligibilité de l'item au reorder (oui/non). Les deux concepts sont orthogonaux. Le piège vient de l'idée que tous les paramètres reorder se substituent — mais ils ont chacun leur rôle distinct.
- STK/NS Category → remplacé par Reorder flag (Y/N).
- Vintage Tax Lookup → remplacé par Tax Codes app (déjà v7.x).
- Inventory Cost Adjustment standalone → remplacé par Cost Adjustment intégré dans l'app Inventory.
- Bench Group Maintenance → remplacé par Group Maintenance via templates.
- Pattern : v9.1 simplifie en remplaçant des enums par des flags booléens, des forms standalone par des actions integrées.
- v9.1 : Reorder flag = canonical control.
- STK/NS Category = deprecated (legacy, encore visible mais non recommandé).
- Migration : STK → Reorder=Y ; NS → Reorder=N.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Inventory : Reorder flag.
- STU sub-objective 2.2 — "use of the Reorder flag (vs deprecated STK & NS categories)".
Correct :B
Pourquoi cette question existe — Les deux modes de reorder (cron automatique + manuel) coexistent en Maximo et le candidat doit savoir comment les configurer ensemble. Cette dualité est essentielle pour les opérations réelles : le cron task gère le volume nocturne, le manuel répond aux urgences journalières.
Le contexte théorique d'abord — En system architecture, deux modèles d'exécution répondent à des besoins différents : (1) scheduled batch (cron, scheduler) — non-interactif, volume élevé, pas de pression temps réel ; (2) on-demand interactive (UI action, API call) — interactif, volume faible, urgent. Les deux modèles coexistent dans la plupart des systèmes ERP/EAM, et c'est l'utilisateur qui choisit selon le contexte. Maximo expose les deux pour le reorder.
Ce que Maximo en fait — version opérationnelle — (1) Cron Task : path Cron Task Setup application > cron task REORDER (ou similaire) > configurer schedule (e.g. every day 02:00) > activer. Le cron évalue tous les Inventory records éligibles en scope chaque nuit. (2) Manual Reorder Items action : path Inventory app > sélectionner storeroom > Select Action > Reorder Items. Le planificateur peut filtrer, ajuster, et créer les PRs sur place. Master-map.pdf p.787-832 + chapitre Cron Tasks documentent les deux mécanismes.
Exemple chiffré — Configuration typique : Cron Task REORDER schedule = nightly 02:00, scope = all storerooms in Org. Run nightly génère ~50-100 PRs en moyenne (selon le volume du site). Manuel : un planificateur observe l'épuisement d'un storeroom après une grosse WO de shutdown à 14:00 → ouvre Inventory app → Reorder Items → génère 3 PRs urgents. Il n'attend pas le cron du soir. Combiné : flux ad-hoc + flux nocturne, couverture complète.
Analogie quotidienne — Votre frigo : vous faites les courses hebdomadaires (cron) le samedi, mais si vous tombez en panne de lait mercredi, vous courez chercher 1 carton chez l'épicier (manuel). Les deux modes coexistent et se complètent.
Pourquoi A est faux — A affirme que le manuel n'est pas supporté en v9.1 (D2 Invented). Faux : la Reorder Items action est une fonctionnalité standard documentée. Le piège vient peut-être de l'idée "v9.1 modernise = automatise tout = retire le manuel" — mais Maximo conserve les deux modes.
Pourquoi C est faux — C propose une Workflow Designer rule sur chaque completion WO (D10 Procedure-plausible). Techniquement faisable mais inadapté : déclencher le reorder à chaque WO completion serait excessif (la majorité des WOs ne nécessitent pas un reorder immédiat) et coûteux en performance. Le pattern Maximo standard est cron + manuel-on-demand, pas event-driven sur chaque WO. Le piège vient de l'idée "réactif = mieux" alors qu'en supply chain, regrouper les évaluations (batch nightly) est plus efficace.
Pourquoi D est faux — D invente un "Reorder Period field" de 24h (D7 Non-existent). Aucun champ Maximo de ce nom contrôlant la fréquence de reorder. La fréquence est gérée par la planification du cron task, pas par un champ sur l'Inventory record. Le piège : confusion avec d'autres concepts de timing (e.g. "Issue Period", "Refresh Interval") qui n'existent pas non plus.
- Cron Task (planifié) : batch nocturne, tous les items éligibles dans le scope, automatique. Configurable via l'app Cron Task Setup.
- Manual Reorder Items action : Inventory app > Select Action. One storeroom at a time. Interactive, ad-hoc.
- Auto-PO flag (par item ou par vendor) : si true, la PR se convertit automatiquement en PO sans approbation (pour les vendors approuvés).
- Approbation par workflow : optionnellement, les PRs passent par Workflow Designer pour approbation avant de devenir des POs.
- Cron Task = batch nightly automatique (volume).
- Reorder Items action = manuel ad-hoc (urgences).
- Les deux coexistent et se complètent.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Cron Task Setup app + Inventory Reorder Items action.
- STU sub-objective 2.2 — Initiation and Timing of Reorder Process : manual vs automatic Cron Task.
Correct :C
Pourquoi cette question existe — Le workflow Special Order Items a un comportement asymétrique souvent mal compris : le Master est créé en PENDING (pour ne pas polluer le catalog futur) mais l'Inventory record est créé en ACTIVE (pour pouvoir recevoir physiquement le stock). C'est un mix qui rompt avec l'intuition "tous les niveaux de statut doivent être identiques".
Le contexte théorique d'abord — Un special order doit résoudre une tension : il faut tracer la transaction (record Item Master pour audit, history) mais sans encombrer le catalog réutilisable (PENDING au lieu d'ACTIVE pour ne pas apparaître dans les listes de selection). Si l'item est livré en stock, il faut qu'il soit issuable (Inventory ACTIVE) ; s'il est livré direct issue, pas besoin d'Inventory record. Le design Maximo respecte ces contraintes simultanément.
Ce que Maximo en fait — version opérationnelle — STU sub-objective 2.2 verbatim : "Ordering Special Order Items — auto-creates Item Master in PENDING status (so item not visible for future orders) · auto-creates inventory record (ItemOrgDetails) in Active status if ordered to a Storeroom". Quand la PR/PO est sauvegardée avec un special order line : (1) Maximo crée un Item record avec un Item Number auto-généré, status = PENDING ; (2) si destination = Storeroom, crée un ItemOrgDetails (per-Org link) en ACTIVE et un Inventory record (per-Storeroom) en ACTIVE — ce qui permet la réception physique. Master-map.pdf p.787-832 + chapitre Purchasing documente ce flux.
Exemple chiffré — Buyer crée PR pour un custom valve. PR line description = "Custom 4-inch ball valve, special build", price = $2,500, destination = Storeroom CENTRAL. Maximo : (1) crée Item SPCL-2026-0042 status = PENDING ; (2) crée ItemOrgDetails pour Org BIGCO status = ACTIVE ; (3) crée Inventory record CENTRAL × SPCL-2026-0042 status = ACTIVE. Le custom valve arrive 30 jours après, est reçu, balance = 1 unité au CENTRAL. Si quelqu'un cherche "ball valve" dans le catalog Item Master, ce SPCL-2026-0042 n'apparaît PAS (PENDING filtre dans la lookup). Mais l'Inventory record permet l'issue à la WO ciblée.
Analogie quotidienne — Comme commander un meuble sur mesure chez Ikea : ils créent une référence interne pour facturation et livraison, mais cette référence n'apparaît jamais dans leur catalog public. Vous l'avez livré, vous l'utilisez, mais ce n'est pas un produit standard.
Pourquoi A est faux — A propose Master ACTIVE + Inventory ACTIVE (D3 Inverse). Faux : si le Master était ACTIVE, le custom valve apparaîtrait dans le catalog futur, polluant les recherches. Le designer Maximo a explicitement choisi PENDING pour le Master pour éviter ça. Le piège vient de l'intuition "ACTIVE everywhere = item bien créé" — mais Special Order rompt cette symétrie.
Pourquoi B est faux — B propose Master PENDING + pas d'Inventory record (D4 Partial-truth). Le piège : "PENDING au Master" est correct, mais "pas d'Inventory record" est faux quand la destination est un Storeroom. Sans Inventory record, on ne pourrait pas recevoir physiquement et issuer. La mention "Direct Issue only" dans B est restrictive : si destination = WO/Asset (Direct Issue), alors B serait correct. Mais la question précise "ordered to a Storeroom", donc Inventory record est créé.
Pourquoi D est faux — D propose Master en OBSOLETE (D2 Invented). Faux : OBSOLETE est le statut de fin de vie d'un item après usage long. Pour un nouveau special order, OBSOLETE n'a pas de sens (l'item vient juste d'être créé). Le piège vient peut-être de l'idée "blocked = obsolete" mais Maximo distingue : PENDING bloque pour catalog visibility, OBSOLETE bloque pour fin de vie. Deux blocages différents.
- Trigger : PR/PO line avec description + price, sans Item Number du catalog.
- Auto-create 1 : Item Master record, Item Number auto-généré, status = PENDING. Pollution catalog évitée.
- Auto-create 2 (si destination = Storeroom) : ItemOrgDetails ACTIVE + Inventory record ACTIVE. Permet réception physique et issue.
- Auto-create 2 (si destination = Direct Issue WO/Asset) : pas d'Inventory record. Cost direct sur la WO.
- Post-receipt : si l'item devient pertinent pour l'avenir, l'admin peut promouvoir Master de PENDING à ACTIVE manuellement.
- Special Order : Master = PENDING (catalog pollution évitée).
- Special Order to Storeroom : Inventory record auto = ACTIVE.
- Special Order Direct Issue : pas d'Inventory record.
- STU sub-objective 2.2 verbatim — "auto-creates Item Master in PENDING status... auto-creates inventory record in Active status if ordered to a Storeroom".
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Purchasing : Special Order Items workflow.
Correct :A
Pourquoi cette question existe — La distinction Internal vs External PO est une mécanique automatique basée sur le type de source. Le candidat doit comprendre que c'est la source qui détermine le type, pas un choix manuel ou un seuil. Cette compréhension est essentielle pour configurer correctement la chaîne logistique multi-storeroom.
Le contexte théorique d'abord — En procurement, on distingue les transactions intra-entreprise (entre divisions, sites, storerooms d'une même entité légale) des transactions externes (avec un fournisseur tiers). Les premières sont neutres au P&L (transferts internes, pas de revenue/cost), les secondes génèrent des liabilities AP. Cette séparation est exigée par IFRS et US GAAP pour le reporting consolidé. Maximo automatise cette distinction en regardant le type de source.
Ce que Maximo en fait — version opérationnelle — Au moment de la création de la PR/PO via reorder, Maximo regarde le source field : (1) si source = Storeroom (avec Use in PR/PO=Y), la PO est typée Internal automatiquement ; (2) si source = Company (vendor), la PO est typée External. La typage détermine ensuite le flux : Internal → Stock Transfer Order, pas d'AP voucher au receipt ; External → AP voucher au receipt, vendor invoicing. Master-map.pdf p.787-832 + chapitre Purchasing décrit ce flux.
Exemple chiffré — Cas 1 : NORTH a Reorder Storeroom = CENTRAL pour BEARING-X. Au reorder, source = CENTRAL → Internal PO. Cas 2 : NORTH a Reorder Storeroom vide pour BOLT-001 mais a Vendor = SteelCo dans Inventory. Au reorder, source = SteelCo → External PO. Cas 3 : NORTH a Reorder Storeroom vide ET pas de Vendor → fallback sur Parent Storeroom (si défini) → Internal PO ; sinon error "no source defined". L'algorithme Maximo navigue dans cette cascade automatiquement.
Analogie quotidienne — Quand vous transférez de l'argent : entre vos comptes même banque (Internal) = pas de frais, simple update ; vers un autre compte autre banque (External) = frais wire transfer, traitement différent. La banque détecte automatiquement selon le BIC/IBAN du destinataire. Maximo fait pareil avec source = Storeroom vs Company.
Pourquoi B est faux — B propose un flag manuel (D10 Procedure-plausible). Faux : Maximo détermine le type automatiquement basé sur la source, pas via un flag manuel. Le piège vient peut-être de l'idée que toute distinction métier doit être explicitée par l'utilisateur, mais Maximo automatise cette inférence pour réduire les erreurs.
Pourquoi C est faux — C invente un seuil de quantité (D2 Invented). Faux : aucune logique de seuil quantité ne distingue Internal vs External. Le type est purement basé sur la source. Le piège vient de l'idée "petits volumes = internal, gros = external" qui n'a pas de fondement dans Maximo.
Pourquoi D est faux — D affirme que tous les POs sont External par défaut et qu'Internal nécessite création manuelle (D3 Inverse). Faux : Maximo crée Internal automatiquement quand source = autre Storeroom. C'est l'inverse complet : le système est conçu pour automatiser l'Internal pour les flux multi-storeroom. Le piège vient peut-être de systèmes legacy où les transferts internes sont effectivement manuels — mais Maximo v9.1 les automatise.
- External PO : source = Company (vendor). AP voucher au receipt. Vendor invoicing.
- Internal PO / Stock Transfer Order : source = autre Storeroom (Use in PR/PO=Y). Pas d'AP voucher. Stock transfer entre storerooms.
- Auto-determination : Maximo détermine le type basé sur la source (Storeroom vs Company) automatiquement.
- Cascade source : Reorder Storeroom (Inventory) > Parent Storeroom (Storeroom) > Vendor (Inventory) > Default Vendor (Companies).
- Internal PO = source autre Storeroom (Use in PR/PO=Y).
- External PO = source Company (vendor).
- Auto-determination par Maximo selon la source.
- Pas de flag manuel, pas de seuil quantité.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Purchasing : Internal vs External PO determination.
- STU sub-objective 2.2 — Ordering items from another storeroom : Use in PR/PO flag · Internal PO.
- [EOTRAG query 13 — Maximo replenishment from parent : Internal PR generates Stock Transfer when fulfilled].
Correct :D
Pourquoi cette question existe — Le Reorder flag est le mécanisme propre pour exclure un item du reorder process à un storeroom spécifique, sans toucher aux autres items ni au statut global. Le candidat doit savoir que c'est l'outil le plus précis et le moins invasif pour ce besoin.
Le contexte théorique d'abord — En system design, le principe "principle of least astonishment" et "principle of least invasiveness" guide les choix : pour exclure une ligne d'un traitement batch, on préfère un flag ciblé sur la ligne plutôt que des hacks comme manipuler le status global, augmenter artificiellement un threshold, ou désactiver le batch entier. Maximo expose le Reorder flag précisément pour ce besoin.
Ce que Maximo en fait — version opérationnelle — Path : Inventory app > ouvrir l'item au storeroom concerné > Reorder flag > uncheck > sauvegarder. Au prochain run du cron, cet item × storeroom sera ignoré. Les autres items du même storeroom continuent normalement. Quand on veut réactiver, recheck. C'est instantané, réversible, et précis. Master-map.pdf p.787-832 documente ce flag (le successeur de STK/NS deprecated, voir Q2 ci-dessus).
Exemple chiffré — Storeroom NORTH a 200 items, dont BEARING-X qui est temporairement géré manuellement (vendor en cours de renégociation). Plutôt que de mettre BEARING-X en OBSOLETE (qui bloquerait les issues à des WOs en cours), l'admin uncheck le Reorder flag sur ce record. Cron task à 02:00 itère sur 200 items, skip BEARING-X, traite les 199 autres normalement. Quand le contrat vendor est signé, recheck → BEARING-X reprend son flux automatique.
Analogie quotidienne — Vous avez une newsletter automatique pour 100 clients. Pour exclure temporairement le client #42 sans le supprimer ou désactiver toute la newsletter, vous mettez un flag "skip" sur sa fiche. Précis, réversible, ciblé.
Pourquoi A est faux — A propose de changer le status à OBSOLETE (D10 Procedure-plausible mais lourd). Effet de bord : OBSOLETE bloque aussi les issues sur les WOs en cours. Si BEARING-X est requis sur 5 WOs ouvertes, ces issues seraient bloquées — ce qui n'était pas l'intention. Le piège : "exclure du reorder" est interprété comme "rendre l'item inactif", mais Maximo offre un mécanisme plus fin (Reorder flag) qui ne touche que le reorder.
Pourquoi B est faux — B propose de mettre ROP très haut (D10 Procedure-plausible mais hack). Effet de bord : si ROP est artificiellement élevé (e.g. 99999), le système ne triggera jamais reorder mais l'item participe quand même au calcul (consommation cron CPU pour rien) et le ROP futur normal devient invisible (perte d'info). C'est un hack qui pollue les données et complique la maintenance. Le Reorder flag est le mécanisme propre.
Pourquoi C est faux — C propose de désactiver le Cron Task entier (D10 Procedure-plausible mais surdimensionné). Effet de bord : tous les items à tous les storerooms seraient privés de leur reorder cron, pas juste BEARING-X. Si on cherchait à exclure UN item à UN storeroom, désactiver le cron entier est un overkill catastrophique. Le piège vient peut-être de l'idée "désactiver le bouton qui déclenche" alors que c'est toute la chaîne qui dépend du bouton.
- Reorder flag = Y (default) : item participe au reorder process (cron + manuel).
- Reorder flag = N : item exclu du reorder. Issues et autres transactions inchangées.
- Use case typique : item géré manuellement, vendor en transition, item en phase-out, item insurance spare ne suivant pas Wilson.
- Granularité : per Inventory record (Storeroom × Item). Donc même item peut avoir Reorder=Y à un storeroom et Reorder=N à un autre.
- Réversibilité : instantanée. Recheck → reprend au prochain cron.
- Reorder flag uncheck = exclure UN item à UN storeroom du reorder.
- Granularité fine, réversible, propre.
- Préférable à OBSOLETE, ROP hack, ou désactivation cron globale.
- master-map.pdf p.787-832, IBM Maximo Manage 9 — Inventory : Reorder flag (replaces STK/NS deprecated).
- STU sub-objective 2.2 — use of the Reorder flag (vs deprecated STK & NS categories).
Ajustements de coût (AVG / STD / LIFO / FIFO / ASSET)

📋 Objectifs IBM
- Décrire comment effectuer un average cost adjustment dans Inventory
- Décrire comment effectuer un standard cost adjustment dans Inventory
- Décrire comment le coût est défini pour un rotating item dans Inventory
- Décrire comment fonctionne le costing LIFO dans Inventory
- Décrire comment fonctionne le costing FIFO dans Inventory
- Décrire comment fonctionne le costing ASSET dans Inventory
- Décrire comment changer le cost type d'un item dans Inventory
💡 Points clés
- Cinq méthodes de coût Maximo — STANDARD, AVERAGE (WAC), LIFO, FIFO, ASSET. Chaque article (Item) porte un Issue Cost Type au niveau organisation, configuré dans Inventory > Cost Type tab. Le Cost Type pilote la valeur du stock à l'émission (Issue) et la couche GL impactée.
- AVERAGE / WAC (Weighted Average Cost) — moyenne pondérée recalculée à chaque réception :
new_avg = (old_qty × old_cost + recv_qty × recv_cost) / (old_qty + recv_qty). Lisse les variations de prix. Issue toujours à la moyenne courante. Méthode par défaut sur la plupart des EAM ; bonne pour les consommables fongibles. - STANDARD — coût administré (fixé par le contrôleur), figé entre deux re-standardisations annuelles. Toute différence entre prix de réception et standard part en variance GL : Purchase Price Variance (PPV). Toute différence entre coût-stock-livre et standard recalculé part en Cost Adjustment. Idéal pour la fabrication où le management veut un coût produit stable.
- FIFO (First-In First-Out) — la couche la plus ancienne est sortie d'abord. En période d'inflation : COGS bas → bénéfices élevés → impôts élevés. Le bilan affiche le stock à des prix récents (plus juste). Conforme IFRS et US-GAAP.
- LIFO (Last-In First-Out) — la couche la plus récente est sortie d'abord. En inflation : COGS élevé → bénéfices bas → impôts bas (avantage fiscal US). Interdit par IFRS depuis IAS 2 (2003). Encore autorisé par US-GAAP avec disclosure « LIFO reserve ». Multinationales sur IFRS = jamais LIFO.
- ASSET — réservé aux rotating items. Chaque actif sérialisé (asset) porte son propre coût (achat + cumul des coûts de réparation). À l'issue, ce coût exact suit la pièce sur le WO. Au retour en magasin, le coût voyage avec la pièce. Indispensable pour capitaliser des moteurs/pompes refurbissables.
- Issue cross-couches FIFO/LIFO — quand une émission consomme deux couches (ex : 8 unités à 10 $ + 2 à 12 $), le système calcule un prix d'émission moyen pondéré sur ces deux couches : (8×10 + 2×12)/10 = 10,40 $. Ce n'est PAS le pur coût d'une couche.
- Returns symétriques — quand un article est retourné en stock, il revient au prix auquel il avait été émis (Maximo conserve la trace dans la table d'issue). Indispensable pour la cohérence GL.
- Changement de Cost Type — Inventory app > More Actions > Change Cost Type. Maximo recalcule la valeur du stock on-hand selon la nouvelle méthode et écrit une écriture d'ajustement GL (Cost Adjustment account). Action sensible : audit, justification, approbation requise.
- Average Cost Adjustment — More Actions > Average Cost Adjustment. Force une nouvelle moyenne sans réception (correction). Ajustement GL entre Inventory account et Cost Adjustment account pour la différence (qty_on_hand × (new_avg − old_avg)).
- Standard Cost Adjustment — More Actions > Standard Cost Adjustment. Met à jour le standard ; recalcule la valeur stock à la nouvelle valeur standard ; variance écrite au compte d'ajustement. Recommandé une fois par an minimum.
- Cost Type pour rotating — un rotating item n'utilise PAS la moyenne du storeroom. Son coût est par-asset, dans la table INVCOST par ASSETNUM. À chaque issue, le coût exact du serial sortant est imputé.
- Multi-organisation subtilité — le Cost Type est défini au niveau Organisation. La même pièce peut être en LIFO chez Org A, en FIFO chez Org B. Un transfert cross-org est ré-évalué à la méthode de l'organisation receveuse.
- Effets P&L en inflation — FIFO maximise le bénéfice rapporté ; LIFO minimise le bénéfice rapporté ; WAC donne un résultat intermédiaire et lissé. Le choix Cost Type EST une décision financière, pas seulement opérationnelle.
- Trap Maximo — Maximo n'a pas de mode « hybride » : un article a UN Cost Type pour toute l'organisation. Si on veut FIFO sur certains storerooms et WAC sur d'autres, il faut deux items distincts ou deux organisations.
| Cost type | Logique de calcul | Autorisé IFRS ? | Path Maximo | Recommandé pour |
|---|---|---|---|---|
| AVG (Weighted Average) | Recalcule le coût à chaque réception : (qty_old × cost_old + qty_new × cost_new) / total_qty. Chaque issue est valorisée à la moyenne pondérée courante. |
Oui | Inventory > Item > Cost Type = AVG | Défaut pour la plupart des items consommables. Lisse la volatilité des prix. |
| STD (Standard) | Utilise un standard cost fixe par item, défini manuellement. La variance entre coût de réception réel et standard cost est postée sur un compte GL Variance. | Oui | Inventory > Item > Cost Type = STANDARD | Environnements de fabrication où le coût budgétisé compte plus que l'actuel. |
| LIFO (Last In, First Out) | Chaque issue est valorisée au coût de la réception la plus récente. Les anciennes layers restent dans l'inventaire à leur coût d'origine. | Non (banni par IFRS ; autorisé par US GAAP) | Inventory > Item > Cost Type = LIFO | Environnements US uniquement cherchant un report d'impôt en inflation. |
| FIFO (First In, First Out) | Chaque issue est valorisée au coût de la réception la plus ancienne. Les layers récentes restent dans l'inventaire. | Oui | Inventory > Item > Cost Type = FIFO | Périssables, industries réglementées, orgs IFRS-compliant. |
| ASSET | Le coût est tracé par ASSETNUM rotating individuel, pas par moyenne de storeroom. Chaque asset porte son propre prix d'achat et son historique d'amortissement. |
Oui | Inventory > Item (Rotating? = true) > Cost Type = ASSET | Obligatoire pour les rotating items (moteurs, pompes) avec tracking sérialisé. |
⚠️ Piège IBM
Confondre AVERAGE et STANDARD lors d'un ajustement — les deux actions s'appellent « Cost Adjustment » mais leurs effets GL et leur usage sont radicalement différents. IBM teste très souvent cette confusion sur les exam C1000-208.
- Average Cost Adjustment — l'item DOIT être en cost type AVERAGE. Force une nouvelle moyenne ; affecte les futures émissions ; ne touche pas au standard.
- Standard Cost Adjustment — l'item DOIT être en cost type STANDARD. Met à jour le standard administré ; recalcule la valeur stock ; variance vers Cost Adjustment GL.
- Trying l'action erronée sur le mauvais cost type → erreur Maximo « Cost type mismatch » ou comportement silencieux selon version.
- ASSET cost = par-serial. Aucun ajustement de moyenne possible : pour ajuster, il faut modifier l'INVCOST de l'asset ou le coût de réparation.
🎯 Carte mémoire
Q. Un controller demande de basculer un article de FIFO à AVERAGE pour stabiliser le P&L. Quelle action Maximo et quel impact GL ?
Afficher la réponse
Inventory app > More Actions > Change Cost Type. Maximo re-évalue le stock on-hand à la nouvelle méthode (les couches FIFO sont écrasées par la moyenne unique calculée), écrit une écriture d'ajustement GL (Inventory vs Cost Adjustment), et tous les futurs issues sortent à la moyenne pondérée. Cette action est traçable dans l'audit et nécessite typiquement un workflow d'approbation.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — IBM teste si le candidat distingue les cinq méthodes de coût offertes par Inventory. La question piège centrale est la confusion entre WAC (qui réajuste à chaque réception) et FIFO/LIFO (qui maintiennent des couches séparées). Comprendre la mécanique de la moyenne pondérée est un pré-requis pour gérer correctement les Average Cost Adjustments.
Le contexte théorique d'abord — la Weighted Average Cost (WAC), parfois appelée moyenne pondérée mobile, est une méthode comptable où l'on recalcule un coût unitaire global en pondérant les anciennes unités par leur coût et les nouvelles unités par leur coût de réception. La formule canonique est : new_avg = (old_qty × old_cost + recv_qty × recv_cost) / (old_qty + recv_qty). Cette méthode lisse les fluctuations de prix d'achat ; les émissions ne sortent jamais à un prix « extrême ». IFRS (IAS 2) et US-GAAP autorisent la WAC. Comparée à FIFO/LIFO qui maintiennent des « couches » identifiables, WAC fusionne tout dans une seule valeur courante [EOTRAG Query 4].
Ce que Maximo en fait — version opérationnelle — dans Maximo, le cost type AVERAGE se sélectionne sur l'item depuis Inventory app > onglet Cost Type. À chaque MATRECTRANS row insérée par une réception, Maximo exécute la formule WAC et met à jour le champ AVGCOST de la table INVCOST pour ce couple item/storeroom. Tous les MATUSETRANS rows futurs (issues) prennent ce AVGCOST comme ISSUEUNITCOST. L'action More Actions > Average Cost Adjustment permet de forcer une nouvelle valeur sans réception (master-map.pdf p.815-820 Inventory Costs).
Exemple chiffré — stock initial : 100 unités à 10 $ = 1 000 $. Réception : 50 unités à 13 $ = 650 $. WAC = (1 000 + 650) / 150 = 11,00 $. Toute issue à partir de cette réception sortira à 11,00 $/unité jusqu'à la prochaine réception, où le calcul recommencera.
Analogie quotidienne — comme un compte bancaire en devises mixtes : à chaque dépôt à un nouveau taux, votre « coût moyen d'achat » global change. Vous ne savez plus quelle pièce de monnaie est ancienne ou récente — tout est fondu en une moyenne.
Pourquoi A est faux — STANDARD utilise un coût administré, fixé par le contrôleur entre deux re-standardisations annuelles. Les réceptions n'altèrent JAMAIS ce standard ; toute différence entre prix payé et standard est postée en variance GL (Purchase Price Variance). C'est volontairement statique pour offrir un coût produit stable en fabrication. Confondre STANDARD et AVERAGE est une erreur classique car les deux actions s'appellent « Cost Adjustment » dans Inventory app, mais leur effet est totalement différent (D4 partial-truth).
Pourquoi B est faux — FIFO conserve les couches d'achat distinctes (oldest in, oldest out). À chaque réception, une nouvelle couche est insérée mais les anciennes restent intactes — elles ne fusionnent JAMAIS dans une moyenne. Le système ne « recalcule » donc rien ; il crée juste un nouveau record de couche. Les issues consomment les plus anciennes couches en premier. FIFO est même l'opposé conceptuel de AVERAGE (D9 near-synonym pour qui confond toutes les méthodes).
Pourquoi D est faux — ASSET est réservé aux rotating items et tracker chaque pièce sérialisée individuellement. Le « coût » est par-asset (purchase + cumulative repair) et n'est jamais moyenné avec d'autres unités. Si on émet le moteur SN-A123, on impute son coût exact, indépendant des autres moteurs en stock. Aucun calcul WAC. ASSET ne peut même pas être appliqué à un non-rotating item (D6 wrong-app).
| Cost Type | Logique | Quand recalculer | Chemin Maximo | Cas typique |
|---|---|---|---|---|
| STANDARD | Coût admin figé | Re-standardisation annuelle | Std Cost Adjustment | Manufacturing |
| AVERAGE | WAC mobile | À chaque réception | Avg Cost Adjustment | Consommables fongibles |
| FIFO | Couches anciennes d'abord | Issue puise dans la couche ancienne | Aucun ajustement direct | IFRS, denrées |
| LIFO | Couches récentes d'abord | Issue puise dans la couche récente | Aucun ajustement direct | Taxe US (GAAP uniquement) |
| ASSET | Coût par serial | Repair, refurb | Asset record | Rotating, capital spares |
- AVERAGE = recalcul à chaque réception via formule WAC
- STANDARD = figé, variances → GL
- FIFO/LIFO = couches conservées, pas de moyenne
- ASSET = par-serial pour rotating uniquement
- [EOTRAG Query 4] Cost Methods FIFO/LIFO/WAC/Standard/ASSET — IBM Maximo Manage 9, Materials Management with SAP S/4HANA, Infor EAM
- master-map.pdf p.815-820 — Inventory Costs / Cost Type configuration
- IBM Maximo Manage 9 official documentation — Inventory application > Cost Type tab
Correct :D
Pourquoi cette question existe — IBM C1000-208 inclut des questions « cross-fonctionnelles » où la connaissance Maximo doit s'articuler avec la conformité comptable. Un FA Maximo qui propose LIFO à un client IFRS commet une faute professionnelle ; cette question force à ancrer la règle réglementaire.
Le contexte théorique d'abord — IFRS (International Financial Reporting Standards) standardise la comptabilité dans 140+ pays. La norme IAS 2 (Inventories) interdit explicitement LIFO depuis sa révision 2003 : LIFO ne reflète pas correctement le flux physique des stocks et peut être utilisé pour manipuler le résultat fiscal. Les méthodes acceptées par IFRS sont : FIFO, WAC, Specific Identification (équivalent ASSET pour items uniques), Standard (avec révision périodique). US-GAAP, en revanche, autorise LIFO avec une « LIFO reserve » disclosure obligatoire dans les notes aux états financiers [EOTRAG Query 4].
Ce que Maximo en fait — version opérationnelle — Maximo offre les cinq cost types (STANDARD, AVERAGE, LIFO, FIFO, ASSET) sans contrainte réglementaire intégrée. C'est à l'organisation cliente de choisir. Pour une entité IFRS, on configure l'item en FIFO ou AVERAGE dans Inventory > Cost Type tab. Une multinationale avec des filiales US sur GAAP et européennes sur IFRS doit segmenter par Organisation : Org US peut utiliser LIFO ; Org Europe doit basculer sur FIFO/WAC. Configuration via Organizations app > Inventory Defaults (master-map.pdf p.789).
Exemple chiffré — un stock de 100 unités achetées 10 $ il y a un an + 100 unités achetées 12 $ ce mois-ci. Issue de 50 unités. En FIFO : COGS = 50×10 = 500 $, stock résiduel = 50×10 + 100×12 = 1 700 $. En LIFO : COGS = 50×12 = 600 $, stock résiduel = 100×10 + 50×12 = 1 600 $. LIFO génère un COGS 100 $ plus élevé → impôts 25 $ plus bas (taux 25%). C'est cet avantage fiscal que IFRS refuse de cautionner.
Analogie quotidienne — imaginez une cave à vin : FIFO consomme d'abord les bouteilles 2010, gardant les 2024 pour vieillir. LIFO consomme d'abord les 2024, conservant les 2010 (irréaliste — qui fait ça ?). IFRS dit : votre comptabilité doit refléter le flux physique probable, donc LIFO non.
Pourquoi A est faux — FIFO est la méthode privilégiée par IFRS car elle reflète typiquement le flux physique des stocks (rotation par date de péremption en industrie alimentaire ou pharmaceutique). Elle est conforme IFRS ET US-GAAP. La proposer pour un client IFRS est un choix sûr, l'opposé de LIFO. Le candidat qui inverse la polarité tombe dans le piège D3.
Pourquoi B est faux — AVERAGE / WAC est explicitement autorisée par IAS 2 paragraphe 25 comme méthode acceptable. Sa neutralité (lissage) est appréciée pour les commodities fongibles où le flux physique est indistinguable. WAC est même la méthode par défaut dans plusieurs ERP européens. Le confondre avec LIFO trahit une lecture trop rapide de la liste de méthodes (D9 near-synonym).
Pourquoi C est faux — STANDARD est une méthode acceptée par IFRS et US-GAAP tant que les variances entre standard et coût réel sont régulièrement reconnues en P&L. Les multinationales fabricantes (automobile, électronique) utilisent STANDARD pour la stabilité du costing produit, avec re-standardisation annuelle et write-off des variances. Ce n'est PAS la cible de l'interdiction IFRS (D4 partial-truth — vrai pour la stabilité, faux pour l'interdiction).
| Méthode | IFRS (IAS 2) | US-GAAP | P&L en inflation |
|---|---|---|---|
| FIFO | OK | OK | Profit haut, impôt haut |
| WAC | OK | OK | Lissé |
| STANDARD | OK avec variance | OK avec variance | Stable |
| LIFO | INTERDIT depuis 2003 | OK avec « LIFO reserve » | Profit bas, impôt bas |
| ASSET (Specific ID) | OK | OK | Par-serial, neutre |
- IFRS interdit LIFO depuis 2003 (IAS 2)
- US-GAAP autorise LIFO + LIFO reserve disclosure
- Maximo n'enforce rien — choix client
- Multi-org : segmenter pour respecter chaque référentiel
- [EOTRAG Query 4] Materials Management with SAP S/4HANA, Infor EAM Guide
- IFRS IAS 2 § 25 — méthodes de coût autorisées
- master-map.pdf p.789 — Organizations > Inventory Defaults > Cost Type
Correct :B
Pourquoi cette question existe — l'examen IBM teste régulièrement la spécificité des rotating items : leur coût n'est PAS moyenné. Beaucoup de candidats appliquent par réflexe la logique WAC à toutes les situations et tombent dans le piège.
Le contexte théorique d'abord — un rotating item est un article dont chaque unité physique est sérialisée et existe aussi dans la base Assets de Maximo. Contrairement aux articles fongibles (boulons, joints), où une unité est strictement interchangeable avec une autre, chaque pièce rotative a son histoire, son serial, sa valeur. Le principe comptable applicable est la Specific Identification (IFRS IAS 2 § 23) : pour les articles non-interchangeables, le coût doit être identifié spécifiquement à chaque unité. Maximo opérationnalise ce principe via la cost type ASSET [EOTRAG Query 6].
Ce que Maximo en fait — version opérationnelle — quand un rotating item est reçu, Maximo crée un asset record (ASSET table) avec un ASSETNUM unique et stocke son coût d'acquisition dans INVCOST par ASSETNUM (pas par item global). À l'issue, le technicien doit sélectionner le serial spécifique via Inventory Usage > Select Reserved Items > Select Rotating Asset. Le coût exact du serial choisi est imputé au WO via MATUSETRANS row. Si l'asset retourne en réparation et reçoit des dépenses additionnelles, son INVCOST est mis à jour avec le coût cumulé. À la prochaine issue, c'est ce coût mis-à-jour qui suivra la pièce. Master-map.pdf p.815-822 Inventory Costs for Rotating Items.
Exemple chiffré — SN-A acheté 4 800 $ en janvier, jamais réparé. SN-B acheté 5 200 $ en février, jamais réparé. SN-C acheté 5 500 $ en mars, sera réparé pour 800 $ après son retour. À l'issue de SN-B sur le WO 1234, le coût imputé est 5 200 $ exactement. Si plus tard on émet SN-C après réparation, son coût imputé sera 5 500 + 800 = 6 300 $. Aucune moyenne entre les serials.
Analogie quotidienne — comme votre voiture d'occasion : votre Toyota a un prix d'achat précis (12 000 $), votre voisin a la même marque/modèle achetée 14 000 $. Si vous vendez la vôtre, vous transférez 12 000 $ — pas la moyenne 13 000 $. Chaque véhicule a SA valeur, identifiée par son numéro de série (VIN).
Pourquoi A est faux — la moyenne pondérée (5 167 $) serait la réponse si l'item était en cost type AVERAGE et non rotating. Pour un rotating, ce calcul détruirait l'intégrité comptable serial-par-serial : on ne peut pas re-vendre un asset à un prix moyenné car cela créerait des écarts P&L à chaque issue. C'est le piège classique consistant à appliquer aveuglément WAC (D6 wrong-app — méthode existe mais pour items non-rotating).
Pourquoi C est faux — FIFO « oldest first » s'applique aux items en cost type FIFO, qui maintiennent des couches d'achat anonymes. Dans le cas rotating, chaque pièce porte son propre coût et le technicien sélectionne explicitement le serial à émettre — pas un algorithme automatique de couche. De plus, FIFO est typiquement utilisé pour les denrées fongibles datées (alimentation, pharmaceutique), pas pour des moteurs sérialisés (D9 near-synonym, FIFO sonne mais ne s'applique pas).
Pourquoi D est faux — STANDARD cost serait pertinent si l'organisation avait choisi de standardiser le coût d'un type de moteur pour stabiliser le costing produit. Mais c'est rare pour les rotating items car cela neutralise la traçabilité serial-par-serial qui est précisément la valeur ajoutée du modèle ASSET. Un rotating en STANDARD comptablement est cohérent mais opérationnellement vide de sens (D4 partial-truth — possible mais pas la pratique standard).
- Rotating item = item record (rotating=Y) + asset record par unité physique
- Cost type ASSET = coût stocké dans INVCOST par ASSETNUM, pas par ITEMNUM
- À l'issue : Inventory Usage > Select Rotating Asset → coût exact du serial → MATUSETRANS
- Workflow de réparation : storeroom → réparation (coût X) → retour-au-stock avec coût X + coût_réparation
- Capitalisation : possible (rotating items souvent capitalisés sur 5-15 ans)
- Rotating = serial unique = coût unique
- ASSET cost = par-asset, jamais moyenné
- Repair cost s'ajoute au coût du serial
- Specific Identification IAS 2 § 23
- [EOTRAG Query 6] Rotating Items / Item Assembly Structures — IBM Maximo Manage 9
- master-map.pdf p.815-822 — Inventory Costs for Rotating Items
- IFRS IAS 2 § 23 — Specific Identification
Correct :A
Pourquoi cette question existe — IBM aime piéger sur la formule WAC en proposant comme distracteurs la moyenne arithmétique simple (8+11)/2 = 9,50, le coût de la dernière réception, ou l'ancien coût. Bien comprendre la pondération est essentiel pour expliquer un Average Cost Adjustment et auditer un INVCOST anormal.
Le contexte théorique d'abord — la moyenne pondérée diffère de la moyenne arithmétique en intégrant la quantité comme poids. La formule générale : new_avg = (qty1 × cost1 + qty2 × cost2) / (qty1 + qty2). Quand les quantités sont égales (qty1 = qty2), WAC = moyenne arithmétique ; sinon, WAC est tirée vers le coût de la quantité majoritaire. C'est l'application directe du principe d'imputation comptable IAS 2 paragraphe 27 sur les méthodes acceptables [EOTRAG Query 4].
Ce que Maximo en fait — version opérationnelle — chaque réception PO insère une ligne MATRECTRANS. Si l'item est en cost type AVERAGE, Maximo lit l'AVGCOST courant dans INVCOST + le BALANCE courant, applique la formule WAC, et écrit le nouveau AVGCOST. Aucun autre traitement n'est requis. Le calcul est instantané et atomique. La trace est conservée dans MATRECTRANS (RECEIPTCOST) et dans le history INVCOST. Inventory app > View Cost > scroll to AVGCOST montre la valeur courante (master-map.pdf p.816).
Exemple chiffré — old_qty = 200, old_cost = 8 → old_value = 1 600 $. recv_qty = 100, recv_cost = 11 → recv_value = 1 100 $. Total qty = 300, total value = 2 700 $. new_avg = 2 700 / 300 = 9,00 $. Vérification par décomposition : (200×8 + 100×11) / 300 = (1 600 + 1 100) / 300 = 9,00. Le 9,00 reflète que les 200 unités d'origine pèsent 2× plus que les 100 nouvelles dans la moyenne.
Analogie quotidienne — vous achetez 2 kg de farine à 2 $/kg, puis 1 kg à 5 $/kg. Le « coût moyen » de votre stock de 3 kg est (2×2 + 1×5)/3 = 9/3 = 3 $/kg, pas (2+5)/2 = 3,50 $. Les 2 kg pèsent plus dans la moyenne que les 1 kg.
Pourquoi B est faux — 9,50 $ est la moyenne arithmétique des deux coûts unitaires (8+11)/2. Cela ignore le fait que les 200 anciennes unités pèsent davantage que les 100 nouvelles dans la moyenne pondérée. C'est l'erreur classique des comptables non-formés à WAC. Maximo n'utilise jamais la moyenne arithmétique simple ; toujours pondérée par les quantités (D4 partial-truth — la formule simple existe mais ce n'est pas WAC).
Pourquoi C est faux — 11,00 $ est le coût de la dernière réception. Cette réponse correspondrait à une logique LIFO avec un seul lot consommé, ou à l'imputation d'une issue qui ne consomme qu'une seule couche LIFO. Pour AVG, c'est invalide car la valeur historique du stock existant n'est pas effacée par la réception ; elle est intégrée dans la moyenne (D9 near-synonym entre méthodes).
Pourquoi D est faux — 8,00 $ est l'ancien coût (avant réception). Il aurait été correct si la réception était à 8 $ exactement (cas dégénéré), ou s'il n'y avait pas de réception. Sous AVG, toute réception à un coût différent de l'ancien moyen doit changer le moyen. Conserver 8 $ après réception à 11 $ violerait la mécanique WAC et créerait une incohérence INVCOST (D3 inverse — la moyenne change toujours, sauf si réception au même prix).
Formule WAC : new_avg = (Σ qty_i × cost_i) / Σ qty_i
- Quantités égales → WAC = arithmétique
- Quantité ancienne >> nouvelle → WAC ≈ ancien coût
- Quantité nouvelle >> ancienne → WAC ≈ nouveau coût
- WAC tend toujours vers le poids le plus lourd
- WAC = moyenne pondérée par quantités, pas arithmétique
- Recalcul AUTO à chaque réception
- 200×8 + 100×11 / 300 = 9,00 $
- Average Cost Adjustment force un new_avg manuel + GL adj
- [EOTRAG Query 4] WAC formula — IBM Maximo Manage 9, IAS 2 § 27
- master-map.pdf p.816 — Inventory > View Cost > AVGCOST
- IBM Maximo Manage 9 — Average Cost Adjustment action
Correct :C
Pourquoi cette question existe — la mécanique du STANDARD cost est mal comprise des FAs Maximo qui n'ont pas de background comptabilité analytique. IBM teste la connaissance précise du compte GL impacté (PPV) et du fait que le stock reste au standard, pas à l'actual.
Le contexte théorique d'abord — le Standard Costing est une méthode de comptabilité analytique née dans les années 1920 chez General Motors et Westinghouse. Le principe : fixer un coût « standard » ex-ante (basé sur des engineering studies, des contrats fournisseur, des taux de production prévisionnels) et mesurer l'écart entre la réalité et le standard. Les écarts se classent en : Purchase Price Variance (PPV — différence prix payé vs prix standard à l'achat), Material Usage Variance (différence quantité consommée vs quantité standard pour la production), Labor Rate/Efficiency Variance, Overhead Variance. Le standard est révisé périodiquement (annuellement le plus souvent) [EOTRAG Query 4].
Ce que Maximo en fait — version opérationnelle — quand un item est en cost type STANDARD et qu'une réception PO arrive à un prix différent, Maximo : (1) impute le stock-on-hand au prix STANDARD (pas au prix de réception) ; (2) écrit l'écart entre actual et standard dans une ligne GL distincte sur le compte « Purchase Price Variance » configuré dans Chart of Accounts ; (3) impute la totalité au compte AP au prix réel (que vous payez bien au fournisseur). À la fin de l'année fiscale, le contrôleur revoit le standard et lance une More Actions > Standard Cost Adjustment pour le re-aligner si l'écart est durable. Master-map.pdf p.819 Standard Cost behavior.
Exemple chiffré — réception 100 unités à 58 $ actual, standard = 50 $. Écritures GL :
Dr Inventory 5 000 (100 × 50 standard)
Dr Purchase Price Variance 800 (100 × 8 écart)
Cr Accounts Payable 5 800 (100 × 58 actual)
Le bilan stock affiche 5 000 ; le P&L absorbe l'écart 800 via PPV. Le COGS d'une issue future sortira à 50 $ (standard) — c'est la stabilité du costing recherchée.
Analogie quotidienne — comme un budget familial fixé en début d'année : vous prévoyez 200 $ pour l'épicerie/semaine (votre « standard »). Si vous dépensez 220 $, vous notez 20 $ en « écart sur dépenses ». Votre budget reste à 200 $ ; le 20 $ explique la déviation, mais ne re-baseline pas votre budget annuel.
Pourquoi A est faux — augmenter le stock à 58 $ serait la logique de la cost type AVERAGE ou FIFO (le receipt cost devient ou influence la valeur stock). Sous STANDARD, le stock est figé au standard quoi qu'il arrive. Si le contrôleur veut intégrer le 58 $ dans la valorisation, il doit lancer Standard Cost Adjustment pour update le standard à 58 $ — mais ce n'est pas automatique (D6 wrong-app, autre cost method).
Pourquoi B est faux — calculer une moyenne pondérée combine 50 $ et 58 $ est la logique pure WAC. Sous STANDARD, aucune moyenne n'est calculée ; le 8 $ d'écart va au PPV. C'est le piège classique pour qui confond les deux méthodes ; mais leur philosophie est opposée : WAC s'adapte aux prix marché ; STANDARD résiste aux prix marché pour stabiliser le costing produit (D9 near-synonym).
Pourquoi D est faux — Maximo n'a pas de mécanisme de rejet de réception sur écart de prix sous STANDARD. La réception est toujours acceptée ; l'écart est juste comptabilisé en variance. Un workflow d'approbation peut être ajouté côté procurement (PO approval block si écart > X%), mais c'est extra-Maximo. Cette option fabrique une fonctionnalité inexistante (D7 non-existent).
STANDARD costing GL postings (réception)
- Dr Inventory @ standard cost
- Dr/Cr Purchase Price Variance (PPV) @ écart
- Cr Accounts Payable @ actual cost
Quand re-standardiser : annuellement, ou si l'écart cumulé dépasse 5-10% sur un produit clé. Action More Actions > Standard Cost Adjustment écrit Cost Adjustment GL pour le delta sur stock on-hand.
- STANDARD = coût figé, écart → PPV GL
- Stock reste au standard, pas à l'actual
- AP payé au prix actual
- Standard Cost Adjustment : action manuelle de re-baseline
- [EOTRAG Query 4] STANDARD cost behavior — Materials Management with SAP S/4HANA
- master-map.pdf p.819 — Inventory Costs / Standard variance posting
- IBM Maximo Manage 9 — Standard Cost Adjustment action
Correct :B
Pourquoi cette question existe — comprendre la logique multi-couches de LIFO/FIFO est central pour expliquer les valorisations de stock à un auditeur. IBM teste si le candidat sait que lorsqu'une issue dépasse une couche, le système consomme la suivante et calcule un coût pondéré sur les couches consommées.
Le contexte théorique d'abord — LIFO conserve toutes les réceptions historiques en couches identifiables. À l'issue, le système draw d'abord la couche la plus récente. Si elle est insuffisante, on draw la suivante (deuxième-plus-récente), et ainsi de suite, jusqu'à atteindre la quantité demandée. Le coût d'émission est la somme : (qty_layer1 × cost_layer1 + qty_layer2 × cost_layer2 + ...) où layer1 est la plus récente. Diviser cette somme par la qty totale donne le prix moyen pondéré de l'émission, mais le COGS GL voit la somme exacte [EOTRAG Query 4 — Infor EAM analog].
Ce que Maximo en fait — version opérationnelle — Maximo maintient une table de couches (analogue à R5FIFO d'Infor EAM) pour chaque item en LIFO ou FIFO. Pour LIFO, l'algorithme : ORDER BY layer_date DESC, consume by remaining qty needed, decrement layer balance, log MATUSETRANS row with ISSUEUNITCOST = total_consumed_value / qty_consumed. Si une couche est entièrement consommée, son record est supprimé ou marqué fermé. Master-map.pdf p.817-818 LIFO/FIFO layer mechanics.
Exemple chiffré — la couche la plus récente (20 unités à 7 $) est entièrement consommée → 20 × 7 = 140. Il reste 35 − 20 = 15 unités à émettre. La couche suivante (30 unités à 5 $) est consommée à hauteur de 15 → 15 × 5 = 75. Total émission = 140 + 75 = 215 $. Coût unitaire moyen sur l'émission = 215 / 35 = 6,14 $. Stock résiduel après émission : 50 unités à 4 $ + 15 unités à 5 $ = 200 + 75 = 275 $. Aucune unité à 7 $ ne reste.
Analogie quotidienne — pile de cartons dans un entrepôt : LIFO = vous prenez le carton du dessus en premier (dernier entré, sommet de pile). FIFO = vous prenez le carton du fond (le plus ancien, premier reçu). Si vous avez besoin de plus que le carton du dessus, vous descendez à la couche suivante.
Pourquoi A est faux — émettre 35 × 4 = 140 correspond à la logique FIFO qui draw d'abord la couche la plus ancienne (50 unités à 4 $). Cela inverse la polarité de LIFO. C'est le piège classique pour qui confond les deux acronymes — leur structure (4 lettres, anglais, comptabilité) est trompeusement similaire (D3 inverse — polarité opposée).
Pourquoi C est faux — appliquer 35 × 7 = 245 ignore que la couche à 7 $ ne contient que 20 unités. Maximo n'invente pas de quantité ; quand une couche est insuffisante, il passe à la suivante. Une telle logique violerait la conservation des unités en stock. C'est une fonctionnalité inexistante (D7 non-existent — Maximo ne fait jamais ça).
Pourquoi D est faux — la moyenne arithmétique des prix de couches (4+5+7)/3 = 5,33 ignore les quantités de chaque couche et n'a aucun fondement comptable. Cela ressemble à une moyenne de moyennes mal construite. Pour une issue, ni LIFO ni FIFO ni WAC n'utilise ce calcul. Si l'item était en AVG, ce serait une moyenne pondérée par qty, donnant (50×4 + 30×5 + 20×7)/100 = 4,90 $ — pas 5,33 (D4 partial-truth — la notion de moyenne existe mais mal appliquée).
LIFO multi-layer issue algorithm
- Order layers by receipt date DESC
- Pop top layer, consume up to layer qty
- Decrement remaining_needed
- Si remaining_needed > 0, répéter avec la couche suivante
- Issue cost = Σ (qty consumed × layer cost)
- MATUSETRANS row: ISSUEUNITCOST = total / qty
FIFO = même algorithme avec ORDER BY layer_date ASC.
- LIFO : sommet de pile en premier (le plus récent)
- Multi-layer issue : pondération pondérée par qty consommée
- Stock résiduel garde les couches non-touchées
- Returns reviennent à leur prix d'origine, jamais au LIFO du jour
- [EOTRAG Query 4] LIFO/FIFO layer mechanics — Infor EAM Guide (analogue R5FIFO transposable Maximo)
- master-map.pdf p.817-818 — Inventory Costs / Layer table mechanics
- IBM Maximo Manage 9 — LIFO/FIFO cost types
Correct :A
Pourquoi cette question existe — changer le cost type d'un article on-hand est une action sensible avec impact GL et audit. IBM C1000-208 teste systématiquement la connaissance du chemin Maximo officiel pour cette opération, car les distractions « SQL direct » ou « delete-recreate » sont des erreurs courantes des juniors.
Le contexte théorique d'abord — changer la méthode de coût d'un item en cours d'exercice est une décision comptable lourde : (1) la valeur du stock-on-hand doit être recalculée selon la nouvelle méthode, ce qui produit un écart vs valeur courante ; (2) cet écart doit être reconnu en P&L (gain ou perte) ou en réserve selon le référentiel ; (3) les auditeurs exigent une traçabilité explicite (date, raison, user, montant). Le US-GAAP et IFRS imposent des disclosures obligatoires lors d'un changement de méthode (« change in accounting principle ») [EOTRAG Query 4].
Ce que Maximo en fait — version opérationnelle — Inventory app > sélectionner l'item > More Actions > Change Cost Type. Maximo : (1) prompt l'utilisateur pour choisir le nouveau cost type ; (2) recalcule la valeur stock selon la nouvelle méthode (pour AVG : new_avg = total_value / total_qty ; pour STANDARD : applique le standard ; pour FIFO/LIFO : reconstitue les couches selon receipts history disponibles) ; (3) écrit une écriture d'ajustement GL Cost Adjustment pour le delta ; (4) log l'action dans audit trail (TLOAM) avec user/date/from/to. Master-map.pdf p.823 — Change Cost Type action. Cette action nécessite typiquement une signature électronique ESIG sur les sites régulés.
Exemple chiffré — FIFO layers : 200×7 + 200×8 + 100×10 = 1 400 + 1 600 + 1 000 = 4 000 $ (mais l'énoncé indique 4 250 $ ; supposons une couche supplémentaire). Bascule vers AVG : new_avg = 4 250 / 500 = 8,50 $. La valeur stock reste à 4 250 $ (pas de gain/perte) — c'est le cas idéal. Mais si la nouvelle méthode est STANDARD à 9 $, la nouvelle valeur stock serait 500 × 9 = 4 500 $, soit un gain de 250 $ posté en Cost Adjustment GL.
Analogie quotidienne — comme convertir vos dollars en euros à la banque : le solde dollar est figé, on applique le taux de conversion, on enregistre le gain/perte de change. Vos euros existent à un nouveau « cost basis » ; la différence vs valeur dollar antérieure est explicite, traçable, postée à un compte de variance.
Pourquoi B est faux — éditer directement le champ Cost Type sur l'Item Master (s'il était possible) sauterait la re-valorisation et briserait la cohérence GL : le stock continuerait d'être valorisé selon l'ancienne méthode dans certains rapports et selon la nouvelle dans d'autres. Maximo désactive ce champ une fois qu'il y a du stock on-hand pour cette raison. L'option suggère un raccourci dangereux qui n'existe pas (D7 non-existent).
Pourquoi C est faux — supprimer-recréer l'inventory record détruirait l'historique de transactions (MATUSETRANS, MATRECTRANS), forçant à re-recevoir le stock. Aucun auditeur n'accepterait cette destruction d'audit trail. De plus, Maximo bloque le delete d'un inventory avec balance > 0 ou avec transactions historiques. C'est une procédure plausible-but-wrong (D10 procedure-plausible).
Pourquoi D est faux — modifier directement INVCOST.COSTTYPE en SQL est une violation grave : (1) bypass des triggers Maximo qui calculent la re-valorisation ; (2) bypass de l'audit trail ; (3) brise la cohérence avec INVBALANCES. Maximo n'a aucun « auto-détection » sur changement SQL externe. Cette option fabrique un comportement magique qui n'existe pas (D2 invented).
Change Cost Type — checklist FA
- Backup la valeur stock courante avant action
- Vérifier le compte Cost Adjustment dans Chart of Accounts
- Inventory app > More Actions > Change Cost Type
- Sélectionner nouveau cost type
- Maximo calcule re-valorisation et écrit GL adjustment
- Confirmer audit log entry (action TLOAM)
- Communiquer avec contrôleur pour disclosure
- Inventory > More Actions > Change Cost Type
- Re-valorisation auto + écriture Cost Adjustment GL
- Audit trail conservé
- JAMAIS via SQL direct ou edit-recreate
- [EOTRAG Query 4] Cost type switching impact — Materials Management with SAP S/4HANA, Infor EAM
- master-map.pdf p.823 — Inventory > More Actions > Change Cost Type
- IBM Maximo Manage 9 — Cost type modification workflow
Correct :C
Pourquoi cette question existe — la mécanique repair-cost-cumul des rotating assets est unique à Maximo et essentielle à comprendre pour les FAs gérant des plantes industrielles avec capital spares refurbis. IBM teste cette spécificité car elle ne s'enseigne nulle part ailleurs.
Le contexte théorique d'abord — la comptabilisation des coûts de réparation pour des actifs réutilisables suit le principe de la capitalisation (vs imputation en charges). Les coûts de réparation qui prolongent la durée de vie utile ou améliorent la fonctionnalité sont capitalisés ; les coûts de maintenance courante sont passés en charges. Pour des rotating assets refurbissables (moteurs, pompes, vannes), Maximo capitalise le coût total de remise à neuf sur l'asset, créant un coût cumulé qui croît à chaque cycle réparation-remise-en-service. Le standard IFRS IAS 16 (Immobilisations corporelles) supporte cette approche pour des composants identifiables [EOTRAG Query 6].
Ce que Maximo en fait — version opérationnelle — workflow rotating repair : (1) issue de l'asset SN-X vers WO-101 au coût 5 000 $ (le coût reste avec l'asset record) ; (2) WO-101 charge 1 200 $ de labor de réparation + parts sur l'asset (via WO Material/Labor) ; (3) asset retourné au storeroom — Maximo calcule new INVCOST = original 5 000 $ + 1 200 $ réparation = 6 200 $ ; (4) la prochaine issue de SN-X charge 6 200 $ au WO demandeur. Master-map.pdf p.821 flow ASSET cost type rotating repair. Le coût de réparation s'accumule indéfiniment ; à un certain point, la décision de mise au rebut (write-off) intervient si coût cumulé dépasse coût de remplacement neuf.
Exemple chiffré — SN-X cycle 1 : achat 5 000 $. Issue WO-101 charge 5 000 $ au WO. Repair coûts 1 200 $. Retour stock à 6 200 $. Cycle 2 : Issue WO-205 charge 6 200 $. Repair coûts 800 $. Retour stock à 7 000 $. Cycle 3 : Issue WO-310 charge 7 000 $. Si moteur neuf coûte 8 000 $, le contrôleur peut décider de mise au rebut au cycle suivant.
Analogie quotidienne — votre voiture : achetée 30 000 $, après 5 ans + 8 000 $ de grosses réparations capitalisables (transmission refaite, suspension), elle « vaut » comptablement 38 000 $ avant amortissement. Quand vous la vendrez, c'est ce coût qui définit le calcul de gain/perte vs prix de vente. La logique Maximo ASSET reproduit cela par-pièce.
Pourquoi A est faux — préserver le coût original et expensé tout repair éliminerait la valeur ajoutée du modèle ASSET (suivi des coûts cumulés). Cela serait correct si l'asset n'était pas capitalisé (item simple non-rotating en STANDARD) ou si la politique comptable expensait toutes les réparations. Pour un rotating ASSET capitalizé, le repair s'accumule. La réponse est partial-truth : vraie pour la maintenance courante, fausse pour les capital repairs (D4 partial-truth).
Pourquoi B est faux — ne garder que le coût de réparation et effacer l'achat original violerait le principe comptable de continuité de l'asset. Un asset n'est pas « ré-acheté » ; il continue d'exister, son coût accumule. Cette logique inverse complètement la mécanique correcte (D3 inverse).
Pourquoi D est faux — le standard cost de l'item record ne s'applique pas à un rotating en cost type ASSET. Le standard est pour items en cost type STANDARD. Pour ASSET, le coût est par-asset, dans INVCOST par ASSETNUM, pas dans le standard sur ITEM. Mélanger les deux niveaux est une erreur classique (D6 wrong-app — concept exists but for different cost type).
Rotating ASSET cost cumulative model
- Initial purchase cost stored in ASSET.PURCHASEPRICE
- INVCOST per ASSETNUM tracks current carrying cost
- Issue : MATUSETRANS uses ASSETCOST = INVCOST current value
- Repair WO charges → cumulated to asset's INVCOST on return
- Return-to-store action (More Actions > Receiving) updates INVCOST
- Seuil de write-off : quand INVCOST > coût de remplacement × 0.7-0.8
- ASSET cost = original + cumul repairs (per serial)
- Capital repair → cumule sur INVCOST
- Maintenance courante → peut être expensé séparément
- Trigger write-off quand cumul approche cost-of-new
- [EOTRAG Query 6] Rotating items repair workflow — IBM Maximo Manage 9
- master-map.pdf p.821 — ASSET cost type rotating repair flow
- IFRS IAS 16 — Immobilisations corporelles / capitalisation des dépenses
Adjust Balances

📋 Objectifs IBM
- Ajuster la balance par physical count
- Ajuster la balance par current balance adjustment
- Zero Year-to-Date Quantities
- Ajuster la balance d'un rotating item
- Expliquer la différence entre available balance et les autres balances
💡 Points clés
- Trois types d'ajustement de balance dans Inventory app : (1) Adjust Physical Count — saisit le résultat d'un comptage physique ; (2) Adjust Current Balance — corrige directement le solde système sans comptage ; (3) Adjust Reconciled Balance — recopie le physical count vers le current balance après revue.
- Physical Count vs Current Balance — Physical Count = ce que vos yeux ont vu lors du dernier comptage. Current Balance = ce que le système croit. Ces deux valeurs peuvent diverger ; la réconciliation force leur égalité (ou explique l'écart par une variance GL).
- Available Balance — formule clé :
Available = Current Balance − Hard Reserved − Staged − Picked. C'est ce qui peut encore être réservé / émis ; pas la même chose que ce qui est physiquement présent. Le ROP compare against Available + On-Order, pas against Current. - Zero Year-to-Date Quantities — More Actions > Zero YTD Quantities. Réinitialise YTDISSUE et YTDRECEIPT à 0 sur l'inventory record. Lancé en début d'exercice fiscal pour repartir des compteurs propres pour ABC analysis.
- Adjust Physical Count workflow : Inventory app > Select Items > More Actions > Adjust Physical Count > saisir nouvelle qty + reason code > Save. Génère INVTRANS row de type COUNTADJUSTMENT et écriture GL si écart vs current.
- Adjust Current Balance workflow : Inventory app > More Actions > Adjust Current Balance > saisir nouvelle qty + reason code + GL accounts. Action plus directe que physical count, utilisée pour corrections immédiates (ex : pièce trouvée, pièce cassée). Génère INVTRANS row CURBALADJ.
- Rotating item balance — pour rotating, Current Balance = nombre d'assets en STORES status pour ce storeroom-bin. Ajuster la balance signifie ajouter/retirer des assets sérialisés, pas un simple chiffre. Action : Adjust Physical Count avec sélection de serials.
- Reason codes obligatoires — chaque ajustement requiert un Reason Code (THEFT, DAMAGE, FOUND, COUNT_ERROR, RECONCILE...) configuré dans Inventory Adjustment Codes. Sert pour analyse root-cause des variances chroniques.
- Hard Reserved = quantité réservée explicitement par un WO approuvé ; bloque l'usage par d'autres demandes. Soft Reserved = intention seulement, ne bloque pas. Auto Reserved = créée automatiquement par job plan.
- Bin balance vs Storeroom balance — un item peut avoir plusieurs bins dans un storeroom (ex : bin1 = 10, bin2 = 5). Storeroom balance = somme = 15. Ajuster une bin spécifique nécessite Inventory app > Select Bin > Adjust.
- Lot balance — pour lotted items, balance par bin × lot. Ajustement doit spécifier le lot (ex : LOT-2026-04-A).
- Condition balance — pour condition-enabled items, balance par bin × condition (NEW, REFURB, USED). Ajustement requiert sélection de la condition.
- Negative balance — peut survenir si une issue est saisie alors que le système croit qu'il n'y a plus de stock (cas de sous-réception non saisie). Maximo le permet par défaut mais le flag dans les rapports d'audit. Site param « Allow Negative Balance » pour bloquer.
- Cycle count tolerance — chaque ABC class a une tolerance % configurée dans Organizations. Si l'écart physical vs current est dans la tolerance, l'ajustement s'auto-poste ; si hors tolerance, recount workflow.
- GL postings — Adjust Physical Count : Dr/Cr Inventory ↔ Inventory Variance. Adjust Current Balance : Dr/Cr Inventory ↔ compte GL spécifié manuellement. Variance positive = gain, négative = loss.
flowchart TD TRIGGER["L'opérateur ouvre
l'application Inventory
(item × storeroom)"]:::start CHOICE{"Quelle méthode
d'ajustement ?"}:::decision PHYS["Adjust by Physical Count
Saisir la quantité comptée
balance := count_value
(remplace la current balance)"]:::action PHYS_TX["Ligne INVADJ
type=PHYSCNT
delta = count − balance_avant"]:::ok CURR["Adjust by Current Balance
Saisir la nouvelle balance directement
(sans comptage)
balance := valeur_utilisateur"]:::action CURR_TX["Ligne INVADJ
type=CURBAL
delta = valeur_utilisateur − balance_avant"]:::ok YTD["Zero Year-to-Date Quantities
Remet à zéro les compteurs YTD usage / receipt
current balance INCHANGÉE
(housekeeping de fin de période)"]:::action YTD_TX["Ligne INVTRANS
type=ZEROYTD
aucun delta de balance"]:::warn ROT["Adjust Rotating Item
Déplacer un ASSETNUM vers/depuis le storeroom
balance déduite du nombre d'assets
(rotating = sérialisé 1-par-asset)"]:::action ROT_TX["Ligne ASSETMOVE
+ audit INVTRANS
delta = ±1 par asset"]:::ok END["Audit trail journalisé
(MATRECTRANS / INVTRANS
chaînés par Item × Storeroom)"]:::endNode TRIGGER --> CHOICE CHOICE -- "Cycle de physical count" --> PHYS CHOICE -- "Correction directe" --> CURR CHOICE -- "Reset YTD fin de période" --> YTD CHOICE -- "Mouvement d'asset rotating" --> ROT PHYS --> PHYS_TX --> END CURR --> CURR_TX --> END YTD --> YTD_TX --> END ROT --> ROT_TX --> END classDef start fill:#3B82F6,stroke:#1E40AF,color:#FFFFFF,font-weight:600; classDef decision fill:#F59E0B,stroke:#B45309,color:#FFFFFF; classDef action fill:#FFFFFF,stroke:#94A3B8,color:#0F172A; classDef stop fill:#F1F5F9,stroke:#94A3B8,color:#475569; classDef endNode fill:#1D9E75,stroke:#178A66,color:#FFFFFF,font-weight:600; classDef warn fill:#FEF3C7,stroke:#F59E0B,color:#78350F; classDef ok fill:#D1FAE5,stroke:#178A66,color:#0F172A;
⚠️ Piège IBM
Confondre Adjust Physical Count et Adjust Current Balance — les deux modifient la balance, mais leurs cas d'usage et leur traçabilité diffèrent. Une mauvaise réponse en exam = comprendre mal cette distinction.
- Adjust Physical Count = je viens de compter physiquement, je saisis le résultat. La valeur saisie devient PHYSCNT ; si elle diffère de CURBAL, une réconciliation séparée doit être lancée pour transférer PHYSCNT → CURBAL avec écriture GL.
- Adjust Current Balance = je corrige directement le solde système, action directe et immédiate. CURBAL change, GL adjusté simultanément. Pas de step de réconciliation séparé.
- Available Balance ≠ Current Balance. Confondre les deux conduit à mal calculer le stock disponible pour réservation.
- Rotating items : ajustement de balance = ajouter/retirer un asset record, pas un nombre. Ne pas saisir « +1 » sur balance numerique.
🎯 Carte mémoire
Q. Un magasinier signale qu'il a trouvé 3 unités d'un item dans une mauvaise bin. Quelle action Maximo et quel reason code ?
Afficher la réponse
Inventory app > sélectionner l'item > More Actions > Adjust Current Balance. Saisir +3 unités sur la bin correcte (ou ajustement de bin si l'item a déjà la bonne quantité totale). Reason code : FOUND ou RELOCATE. Génère INVTRANS row CURBALADJ + écriture GL Inventory ↔ Inventory Adjustment Gain. Si on suspecte un error de comptage initial, alternativement Adjust Physical Count + reconciliation.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — la formule Available = Current − Hard Reserved − Staged est centrale pour comprendre le ROP, les pick lists, et les écarts entre stock physique et stock disponible. IBM teste si le candidat sait quels éléments soustraire (Hard, Staged) et lesquels ignorer (Soft, On Order).
Le contexte théorique d'abord — la notion d'Available Balance (qty available) sépare le stock encore allouable à de nouvelles demandes du stock déjà engagé. Une réservation hard est un engagement contractuel envers un WO approuvé : ce stock ne doit JAMAIS être réalloué. Une réservation soft est juste une intention/préparation et peut être annulée librement. Le stock staged a été déplacé vers une zone d'attente près du WO ; il est physiquement dans le storeroom complex mais comptablement engagé. Le on-order est en attente de réception, pas encore disponible. Cette distinction stocks engagés / non-engagés est universelle aux WMS modernes [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Maximo calcule à la volée Available = Current − HardReserved − Staged − Picked. Soft reservations n'apparaissent pas dans la formule par défaut (configurable via system param). On Order n'est jamais soustrait : il est sur une autre dimension (ce que je vais avoir, pas ce que j'ai). Pour ROP triggering, la comparaison est : if (Available + On Order) ≤ ROP → reorder. Master-map.pdf p.799 Inventory Balance fields. La formule est visible dans Inventory app > View Available Balance dialog.
Exemple chiffré — Current 100 − Hard 30 − Staged 10 = 60. Soft 15 ignoré (n'engage pas vraiment). On Order 20 ignoré (pas du stock présent). Available = 60. Si une nouvelle réservation hard de 50 unités arrive, elle peut être satisfaite (60 ≥ 50) → Available descend à 10. Si on tentait 70 unités, Maximo refuserait (60 < 70) sauf à émettre un PR en parallèle.
Analogie quotidienne — votre compte bancaire : solde 1 000 $ (Current). Vous avez engagé un loyer 400 $ (Hard) et bloqué 100 $ pour une charge automatique (Staged). Disponible pour dépenser maintenant = 1 000 − 400 − 100 = 500 $. Le salaire qui arrive demain (On Order) ne compte pas dans le disponible aujourd'hui. Une intention de cadeau à 50 $ (Soft) ne réduit pas votre disponible.
Pourquoi A est faux — 100 = Current Balance, qui correspond à ce que le système croit physiquement présent. Confondre Current avec Available est l'erreur la plus commune ; cela conduit à over-allocate du stock. Si je promets 100 unités quand seul 60 est disponible, 40 sont déjà engagés ailleurs et ma promesse est un défaut programmé (D4 partial-truth — Current existe mais ce n'est pas Available).
Pourquoi B est faux — 45 = 100 − 30 − 15 − 10 soustrait Soft Reservations (15), ce que la formule standard ne fait pas. Soft est une intention non-engageante. Si on soustrayait Soft, on bloquerait inutilement du stock pour des plans qui peuvent être annulés. Maximo offre un param pour inclure Soft dans Available, mais ce n'est pas le default (D5 sibling-field — Soft existe et touche aux balances mais pas dans la formule standard).
Pourquoi D est faux — 80 = 100 − 20 soustrait On Order, ce qui est conceptuellement impossible : On Order est ce qui va arriver, pas ce qui est sorti. Le candidat qui répond 80 confond Available et un autre KPI (peut-être « Net Position » ou « Projected »). La formule est cohérente : seuls les engagements internes sortent du Current, jamais les flux externes (D9 near-synonym, autre concept de balance).
| Champ balance | Définition | Soustrait de Current pour Available ? |
|---|---|---|
| Hard Reserved | WO approuvé engagé | OUI |
| Soft Reserved | Intention plan | NON (default) |
| Staged | Déplacé vers zone d'attente | OUI |
| Picked | Sorti de bin, en transit | OUI |
| On Order | PO ouvert, pas reçu | NON (autre dimension) |
| YTD Issued | Cumul issues année | NON (KPI ABC) |
- Available = Current − Hard − Staged − Picked
- Soft et On Order non comptés (default)
- ROP trigger : (Available + On Order) ≤ ROP
- 100 − 30 − 10 = 60
- [EOTRAG Query 12] Picking Staging Issue / Inventory Balance — IBM Maximo Manage 9
- master-map.pdf p.799 — Inventory Balance fields
- IBM Maximo Manage 9 — View Available Balance dialog
Correct :A
Pourquoi cette question existe — IBM teste systématiquement la séparation des deux actions « Adjust Physical Count » et « Adjust Current Balance » qui ont des cas d'usage très différents. Confondre les deux est une faute de gestion de stocks majeure (audit-fail) car cela court-circuite le double-step physical → reconciliation → current.
Le contexte théorique d'abord — les bonnes pratiques de cycle counting (ISO 9001, SOX) imposent une séparation des fonctions : la personne qui compte physiquement n'est pas celle qui poste l'ajustement comptable. Le compteur saisit ce qu'il a vu (Physical Count) ; le supervisor révise et autorise la réconciliation (transfer Physical → Current avec écriture GL Variance). Cette séparation prévient la fraude et donne un contrôle interne robuste [EOTRAG Query 10].
Ce que Maximo en fait — version opérationnelle — Inventory app > sélectionner item > More Actions > Adjust Physical Count. Ouvre une dialog où le compteur saisit la quantité réellement comptée + le bin + (option) le lot/condition. Maximo écrit cette valeur dans le champ PHYSCNT de l'inventory record + LASTPHYSCNTDATE. Le CURBAL ne change PAS encore. Plus tard, le supervisor lance Inventory app > More Actions > Reconcile Balances qui transfère PHYSCNT → CURBAL et écrit la variance GL. Master-map.pdf p.825 Adjust Physical Count + p.827 Reconcile Balances. Le double-step est volontaire et lié à la séparation des fonctions.
Exemple chiffré — étape 1 : compteur ouvre Inventory > ITEM-X > Adjust Physical Count, saisit 87, save. PHYSCNT=87, CURBAL=92, écart=−5 (visible via report Reconciliation Mismatched). Étape 2 : supervisor ouvre l'item, vérifie le contexte (cycle count book, photos), lance Reconcile Balances. Maximo écrit MATUSETRANS row CYCLECOUNT −5 unités, GL Dr Inventory Variance 25 $ / Cr Inventory 25 $ (à 5 $/unit). CURBAL devient 87.
Analogie quotidienne — l'inventaire d'une bibliothèque : étape 1, le bibliothécaire compte les livres restants (Physical Count saisi). Étape 2, le directeur revoit le rapport et décide quels livres écrire en perte vs lesquels recompter (reconciliation). Vous ne supprimez pas les livres du système avant le sign-off du directeur.
Pourquoi B est faux — Adjust Current Balance est la procédure « one-step » qui modifie directement le système et écrit la GL en même temps. C'est utilisable pour des corrections immédiates non liées à un cycle count formel (ex : pièce trouvée hors comptage). Mais l'utiliser après un cycle count saute la traçabilité Physical → Reconciled → Current, viole la séparation des fonctions, et l'auditeur ne peut plus distinguer un comptage légitime d'un override admin (D9 near-synonym — action existe mais mauvais usage ici).
Pourquoi C est faux — émettre 5 unités sur un dummy WO créerait un MATUSETRANS de type ISSUE et imputerait 25 $ de coût à un WO bidon. Cela aligne les balances comptablement mais introduit un fake WO, pollue les WO actuals, fausse les rapports MTBF/MTTR. C'est une procédure plausible-but-wrong souvent vue dans des sites mal gérés, mais formellement interdite (D10 procedure-plausible).
Pourquoi D est faux — Maximo désactive le champ Current Balance en édition directe sur l'inventory record. Ce champ n'est modifiable que via les actions formelles (Adjust Current Balance, Reconcile, ou via transactions Issue/Receipt). Tenter d'éditer directement échoue ; cette option fabrique une fonctionnalité inexistante (D7 non-existent).
Two-step physical count workflow
- Adjust Physical Count — compteur saisit, PHYSCNT updated, CURBAL unchanged
- Reconcile Balances — supervisor approuve, PHYSCNT → CURBAL, GL Variance posté
One-step alternative (corrections directes)
- Adjust Current Balance — directe, GL immédiat, pour pièces trouvées hors comptage
- Adjust Physical Count = saisie comptage, pas de GL
- Reconcile Balances = approbation supervisor + GL
- Adjust Current Balance = correction directe, GL immédiat
- Séparation des fonctions = exigence SOX
- [EOTRAG Query 10] Physical Count Reconciliation — Warehouse Management with SAP S/4HANA, IBM Maximo Manage 9
- master-map.pdf p.825 — Adjust Physical Count action
- master-map.pdf p.827 — Reconcile Balances action
Correct :D
Pourquoi cette question existe — la fonctionnalité Zero YTD est une action peu connue mais explicitement dans STU 3.2. IBM teste si le candidat connaît son existence et son usage en début d'exercice fiscal. Les distractions « SQL direct » et « ABC report avec flag reset » sont des fausses pistes plausibles.
Le contexte théorique d'abord — les compteurs Year-to-Date (YTD) — YTDISSUE, YTDRECEIPT — accumulent les quantités issuées/reçues depuis le début de l'exercice. Ces compteurs alimentent l'analyse ABC (qui multiplie YTDISSUE × LASTCOST pour valoriser la consommation annuelle), les rapports de roulement, les prévisions de demande. À la fin de l'exercice fiscal, ces compteurs doivent être remis à zéro pour repartir sur une base claire la nouvelle année. Sans reset, on cumulerait sur deux ans, faussant tous les KPIs [EOTRAG Query 3 + 14].
Ce que Maximo en fait — version opérationnelle — Inventory app > More Actions > Zero Year-to-Date Quantities. L'action peut être lancée par item individuellement, par sélection, ou globalement par site. Maximo : (1) parcourt les inventory records selon le scope ; (2) reset YTDISSUE = 0 et YTDRECEIPT = 0 ; (3) log un audit row dans TLOAM ; (4) NE TOUCHE PAS au CURBAL, ni à AVGCOST, ni à PHYSCNT. C'est purement un reset de compteurs annuels. Master-map.pdf p.829 Zero YTD action. Typiquement programmée comme cron task le 1er jour de l'exercice fiscal.
Exemple chiffré — fiscal year ends 31 mars. Au 31 mars : YTDISSUE = 1 250 unités, YTDRECEIPT = 1 400 unités, CURBAL = 350. Le 1er avril, on lance Zero YTD : YTDISSUE = 0, YTDRECEIPT = 0, CURBAL = 350 (inchangé). À la première issue d'avril (50 unités), YTDISSUE = 50, CURBAL = 300. ABC analysis lancée en juin verra YTDISSUE refléter 3 mois de consommation, pas 15 mois.
Analogie quotidienne — comme remettre votre compteur de podomètre à zéro le 1er janvier pour mesurer combien de pas vous faites cette nouvelle année. Vous ne touchez pas à votre poids actuel ou à votre fitness baseline ; vous reset juste un compteur de cumul.
Pourquoi A est faux — exécuter un SQL UPDATE direct sur INVENTORY.YTDISSUE bypass les triggers, l'audit trail, et les contrôles applicatifs Maximo. Aucune trace dans TLOAM ; les auditeurs ne peuvent pas distinguer un reset légitime d'une manipulation. C'est inacceptable en environnement régulé. Maximo n'a aucun mécanisme « auto-detect » de SQL externe (D2 invented).
Pourquoi B est faux — Adjust Current Balance à zéro puis re-recevoir détruirait toute la valuation et l'historique transactionnel pour reset des compteurs YTD. C'est un détour absurde qui touche à CURBAL alors que YTDISSUE et CURBAL sont des champs distincts. Cette procédure plausible-but-wrong est une erreur de débutant qui confond CURBAL et YTDISSUE (D10 procedure-plausible).
Pourquoi C est faux — l'ABC Analysis Report n'a pas de flag « Reset ». Il calcule le classement ABC à partir de YTDISSUE × LASTCOST sans modifier ces valeurs. Il met à jour les ABCTYPE et CYCLECOUNTDAYS sur les inventory records, mais pas les compteurs YTD. Cette option fabrique un flag qui n'existe pas (D7 non-existent).
Inventory annual reset checklist
- Date : 1er jour de l'exercice fiscal (ou semaine #1)
- Action : More Actions > Zero Year-to-Date Quantities
- Effet : YTDISSUE = 0, YTDRECEIPT = 0
- Non-effet : CURBAL, AVGCOST, PHYSCNT inchangés
- Ordre : avant le premier ABC analysis du nouvel exercice
- Trace : log TLOAM par user/date
- Zero YTD = reset compteurs YTDISSUE / YTDRECEIPT
- Lancé en début d'exercice fiscal
- Ne touche PAS à CURBAL ni AVGCOST
- Préalable à ABC analysis annuelle propre
- [EOTRAG Query 3] ABC Analysis YTD basis — IBM Maximo Manage 9
- master-map.pdf p.829 — Zero Year-to-Date Quantities action
- IBM Maximo Manage 9 — More Actions menu Inventory app
Correct :B
Pourquoi cette question existe — les rotating items ont une mécanique de balance différente des non-rotating : la balance n'est pas un nombre mais un set de serials. IBM teste si le candidat sait qu'on ne peut pas « ajuster −1 » pour un rotating ; on doit identifier QUEL serial est manquant.
Le contexte théorique d'abord — un rotating item est à la croisée de deux mondes : c'est un item (avec balance, cost, ROP) ET un asset (avec serial, history, location). La traçabilité serial-par-serial impose que toute modification de balance soit associée à un serial spécifique. Un asset perdu, c'est SN-A perdu — pas « un asset perdu en général ». Ce niveau de granularité est exigé par les normes ISO 14224 (collecting reliability data) et ISO 55001 (asset management) [EOTRAG Query 6].
Ce que Maximo en fait — version opérationnelle — Inventory app > sélectionner item rotating > More Actions > Adjust Physical Count. La dialog affiche la liste des assets (serials) présents en STORES. Le storekeeper coche les serials physiquement vus, décoche ceux manquants. Maximo dérive le PHYSCNT à partir du nombre de serials cochés (= 3). À la réconciliation, l'asset SN-D (le décoché) sera basculé en status MISSING et son INVCOST écrit-off au compte Loss/Variance. Master-map.pdf p.826 Adjust Physical Count rotating items.
Exemple chiffré — avant : 4 serials en STORES (SN-A, SN-B, SN-C, SN-D). Comptage physique : 3 vus (A, B, C). Adjust Physical Count : storekeeper coche A, B, C ; SN-D décoché. PHYSCNT = 3, CURBAL still 4. Reconcile : SN-D status passe à MISSING/WRITE-OFF, INVCOST de SN-D (5 000 $) débité Loss / crédité Inventory. CURBAL devient 3.
Analogie quotidienne — un parking d'entreprise : si un véhicule de la flotte manque, on ne dit pas « il manque 1 voiture » abstraitement ; on identifie « le Toyota plaque ABC-123 manque ». L'enquête, l'écriture comptable, la déclaration au fleet management se basent sur le serial, pas sur un compteur.
Pourquoi A est faux — taper « 3 » dans la quantité numérique fonctionnerait pour un non-rotating mais Maximo bloque cette opération sur rotating et force la sélection de serials. Si l'utilisateur tente de saisir un nombre, l'UI redirige vers le picker de serials. La réponse simplifie indûment et ignore la sérialisation (D4 partial-truth — vrai pour non-rotating).
Pourquoi C est faux — supprimer un asset record dans Assets app n'est pas la bonne procédure : (1) Maximo bloque le delete d'un asset ayant un history transactionnel ; (2) cela violerait l'audit trail (l'asset a existé, été utilisé, etc.) ; (3) le bon flow est de mettre l'asset en status MISSING ou DECOMMISSIONED, pas de le supprimer. La procédure suggérée est plausible mais incorrecte (D10 procedure-plausible).
Pourquoi D est faux — émettre 1 motor sur un dummy WO requiert de sélectionner un serial à émettre ; le serial choisi sortirait avec un coût imputé au dummy WO, polluant les WO actuals et désalignant les coûts. De plus, ça fait disparaître l'audit du « missing » : on ne peut plus distinguer une issue légitime d'une perte. C'est l'application incorrecte d'une procédure d'autre contexte (D6 wrong-app — issue existe mais pas pour adjust missing).
Adjust rotating item balance — checklist
- Inventory app > rotating item > More Actions > Adjust Physical Count
- Dialog liste les serials en STORES
- Cocher serials vus / décocher serials manquants
- PHYSCNT dérivé automatiquement
- Reconcile : serial décoché → status MISSING, INVCOST écrit-off
- Investigation : chercher SN avant write-off final
- Rotating balance = set de serials, pas un nombre
- Adjust Physical Count rotating = sélection de serials
- Serial manquant → status MISSING + write-off INVCOST
- JAMAIS delete asset record pour adjust balance
- [EOTRAG Query 6] Rotating Items workflow — IBM Maximo Manage 9
- master-map.pdf p.826 — Adjust Physical Count rotating items
- ISO 14224 — equipment hierarchy / serial traceability
Correct :C
Pourquoi cette question existe — c'est une question fondatrice de l'objectif STU 3.2 : « Expliquer la différence entre available balance et les autres balances ». IBM teste si le BA peut expliquer cette différence à un planner ou un controller, car la confusion conduit à des promesses de stock impossibles à honorer.
Le contexte théorique d'abord — la séparation Physical/Available est un standard WMS depuis les années 1990 (Murray, SAP WM). Le Physical (= Current dans Maximo) répond à « qu'est-ce qui est dans mes bins ? ». L'Available répond à « qu'est-ce qui peut encore être promis ? ». Cette distinction est cruciale en environnement multi-utilisateurs : si deux planners regardent Current = 100 et chacun réserve 80, le second voit la défaillance trop tard. Available règle ce conflit en montrant en temps réel ce qui reste après les réservations engagées [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Inventory record contient plusieurs champs balance : CURBAL (current/physical), HARDRES, SOFTRES, STAGED, PICKED. Le « Available Balance » est calculé à la volée : AVAILABLE = CURBAL − HARDRES − STAGED − PICKED. Visible via Inventory app > View Available Balance dialog ou via le champ AVBALANCE dans MAXAUTH SQL views. Master-map.pdf p.799-800 Inventory Balance fields. Le planner voit Available dans son interface de réservation, pas Current — d'où la frustration de notre exemple.
Exemple chiffré — Current Balance 100. Hard Reserved 30 (un WO approuvé pour la maintenance préventive de la semaine prochaine). Staged 10 (un autre WO en cours, pièces déjà déplacées). Available = 100 − 30 − 10 = 60. La planner peut réserver 60 max. Si elle veut 80, elle doit soit attendre la prochaine réception, soit annuler une autre réservation, soit raise un PR.
Analogie quotidienne — votre carte de crédit : limite de crédit 5 000 $ (Current). Vous avez déjà engagé 1 500 $ ce mois-ci (Hard Reserved par autorisations en attente). Disponible = 3 500 $. Quand vous demandez « combien puis-je dépenser ? », la réponse est 3 500 $, pas 5 000 $. Si vous oubliez, vous risquez un refus à la caisse.
Pourquoi A est faux — la définition est inversée : Current Balance est ce qui est en stock (physique/système), pas ce qui est on order. On Order est un troisième champ, distinct (= la quantité des PO ouverts). Cette inversion de définition est un piège classique pour qui n'a pas étudié les fields Inventory (D3 inverse).
Pourquoi B est faux — partial-truth dangereuse : Current Balance N'INCLUT PAS le staging bin (le staged est dans une bin séparée). Mais c'est plus subtil : le staged est physiquement encore dans le storeroom (donc certains EAMs l'incluent dans Current) tandis que Maximo le sépare en STAGED dédié. Le Available exclut effectivement le staged. La phrase est presque-correcte mais inverse la mécanique exacte (D4 partial-truth).
Pourquoi D est faux — fabrication complète : aucun des deux balances n'est « monthly aggregated ». Les deux sont real-time dans Maximo, calculés à la volée à partir de transactions intransactionnelles instantanées. Cette option crée une distinction temporelle (mensuel vs temps-réel) inexistante (D2 invented).
| Balance type | Que représente | Quand l'utiliser |
|---|---|---|
| Current Balance (CURBAL) | Total physique en stock | Cycle count, valuation, audit |
| Available Balance | CURBAL − Hard − Staged − Picked | Réservation, allocation |
| Hard Reserved | Engagé par WO approuvé | Bloque autres demandes |
| Soft Reserved | Intention, plan | Visibilité, pas blocage |
| Staged | Déplacé vers zone d'attente | Préparation issue |
| On Order | PO ouvert | ROP trigger calc |
- Current = total physique/système
- Available = Current − Hard − Staged − Picked
- Available = ce qui peut encore être réservé
- Tous les balances en temps réel
- [EOTRAG Query 12] Picking Staging Issue — IBM Maximo Manage 9 / Inventory Balance fields
- master-map.pdf p.799-800 — Inventory Balance fields
- IBM Maximo Manage 9 — View Available Balance dialog
Correct :B
Pourquoi cette question existe — la nuance entre Found-stock (pièce trouvée hors comptage) et un cycle count formel est mal comprise. IBM teste si le FA distingue les cas d'usage et choisit le bon couple action/reason code pour la traçabilité comptable.
Le contexte théorique d'abord — un Found item est un cas particulier en gestion de stock : la pièce existait physiquement mais pas dans le système. Sa réintégration est un gain comptable (l'inventaire est sous-estimé). Le reason code FOUND distingue ce cas de figure d'autres ajustements (DAMAGE, THEFT, RECONCILE) pour le reporting de variance par cause. Sans typification, l'analyse des variances chroniques est impossible. ISO 9001 § 7.5.3 (control of monitoring/measuring devices) exige cette traçabilité [EOTRAG Query 10].
Ce que Maximo en fait — version opérationnelle — Inventory app > sélectionner item > More Actions > Adjust Current Balance. Saisir nouvelle qty (ex : ancien CURBAL + 5) + reason code FOUND (préalablement configuré dans Inventory Adjustment Codes) + GL accounts (Inventory account / Inventory Adjustment Gain account). Maximo écrit MATUSETRANS row CURBALADJ avec REASONCODE=FOUND, met à jour CURBAL, écriture GL Dr Inventory / Cr Inventory Adjustment Gain. Le rapport Variance by Reason peut ensuite agréger tous les FOUND pour identifier les patterns (squirrel stores ?). Master-map.pdf p.825 Adjust Current Balance.
Exemple chiffré — CURBAL avant 25, found 5, nouveau CURBAL 30. Cost moyen 12 $. Écritures GL : Dr Inventory 60 $, Cr Inventory Adjustment Gain 60 $. Le P&L récupère un gain de 60 $ pour cet item. Si on cumule 200 found events sur l'année à cost moyen 50 $ chacun, le gain total reflète une amélioration de la précision plutôt qu'une vraie performance opérationnelle.
Analogie quotidienne — vous trouvez un billet de 20 $ oublié dans une vieille veste. Vous mettez à jour votre budget personnel en notant « +20 $ trouvés » avec la mention « old jacket ». Vous ne créez pas un faux salaire pour expliquer ce gain ; vous tracez l'origine exacte.
Pourquoi A est faux — créer un faux PO pour réintégrer la pièce introduit une transaction commerciale fictive (vendor non payé, AP créé, GL inventory account débité comme une vraie réception). C'est une procédure plausible-but-wrong vue dans des sites mal gérés ; elle pollue les KPIs vendor (lead time, on-time delivery). Reason code RECEIPT n'est pas un reason d'ajustement valide (D10 procedure-plausible).
Pourquoi C est faux — émettre une quantité négative est interdit dans Maximo Inventory Usage. Issue Quantity doit être positive ; pour augmenter la balance, on utilise une autre action (Receipt ou Adjust). Cette procédure fabrique un comportement inexistant (D2 invented).
Pourquoi D est faux — Maximo exige toujours un reason code pour les ajustements ; il ne « tag automatiquement la variance » sans input utilisateur. De plus, Adjust Physical Count produit un PHYSCNT ; il faudrait ensuite Reconcile pour transférer vers CURBAL. Pour un cas Found simple, Adjust Current Balance est plus direct. La réponse fabrique une fonctionnalité d'auto-tagging inexistante (D7 non-existent).
Reason codes Inventory Adjustment — taxonomie
- FOUND — pièce trouvée hors comptage
- DAMAGE — pièce abîmée à écrire-off
- THEFT — vol confirmé
- RECONCILE — résultat d'un cycle count formel
- OBSOLETE — write-off pour obsolescence
- CONVERSION — changement UoM
- RELOCATE — repositionnement de bin
Configuration : Inventory Adjustment Codes table + assigner par site/storeroom.
- Found = Adjust Current Balance + reason FOUND
- GL : Dr Inventory / Cr Inventory Adjustment Gain
- Reason code TOUJOURS obligatoire
- Reporting variance by reason = analytique root-cause
- [EOTRAG Query 10] Reconciliation / Variance Accounting — IBM Maximo Manage 9
- master-map.pdf p.825 — Adjust Current Balance + reason codes
- ISO 9001 § 7.5.3 — Control of monitoring/measuring devices traceability
Reconcile Balances

📋 Objectifs IBM
- Réconcilier les balances d'items par physical count dans Inventory
- Réconcilier les balances d'items par physical count dans Count Books
💡 Points clés
- Réconciliation = transférer Physical Count → Current Balance en écrivant la variance GL. Deux applications offrent ce flow : Inventory app (item-par-item, plus direct) et Count Books (par batch de SKUs, mieux audité).
- Inventory app reconciliation — Inventory app > sélectionner item > More Actions > Reconcile Balances. Compare PHYSCNT vs CURBAL ; si écart, écrit MATUSETRANS row CYCLECOUNT + GL adjustment ; CURBAL = PHYSCNT après l'action.
- Count Books reconciliation — Count Books app > ouvrir le count book généré > tab Reconcile > Reconcile Balances action. Traite tous les items du count book en lot. Items dans la tolérance : auto-réconciliés. Items hors tolérance : envoyés à recount workflow.
- Tolerances par ABC class — A items typiquement 0-2%, B 2-5%, C 5-10%. Configurées dans Organizations app > Inventory Defaults > Variance % par ABCTYPE. Items safety/régulés : 0% tolérance forcée.
- Recount workflow — quand l'écart dépasse la tolérance, le count est marqué RECOUNT. Le supervisor ré-assigne au floor pour un second comptage. Si le second comptage confirme l'écart, override admin requis avec justification documentée.
- Variance accounting GL — variance positive (PHYSCNT > CURBAL) : Dr Inventory / Cr Inventory Adjustment Gain. Variance négative (PHYSCNT < CURBAL) : Dr Inventory Variance Loss / Cr Inventory. Comptes configurés dans Chart of Accounts.
- Séparation des fonctions (SOX) — la personne qui saisit le PHYSCNT n'est pas celle qui poste la réconciliation. Le compteur (warehouse clerk) saisit ; le supervisor approuve et poste. Maximo enforce via signature options ESIG (e-signature, audit-logged).
- Status workflow d'un Count Book : DRAFT → ACTIVE → COMPLETED → CLOSED. Reconciliation possible uniquement sur ACTIVE et COMPLETED. CLOSED archive le book.
- Generate Count Book — Count Books app > New > sélectionner storeroom + critères (ABCTYPE, frequency, last count date). Maximo génère un count book avec les SKUs correspondants. Print/assign aux compteurs.
- Items couverts par Count Books — rotating ET non-rotating. Maximo gère les deux dans un même count book ; la dialog de comptage adapte le picker (qty pour non-rotating, serial selection pour rotating).
- INVTRANS row CYCLECOUNT — chaque réconciliation génère cette row avec l'écart (positif ou négatif), le coût impacté, le user, le timestamp, le compte GL. Indispensable pour audit trail.
- Reconciliation Mismatched tab (RBA) — l'Inventory Counting Role-Based Application montre un dashboard des écarts pendants avec icônes : flèche verte vers le haut (PHYSCNT > CURBAL), flèche rouge vers le bas (PHYSCNT < CURBAL), check vert (in tolerance), point d'interrogation (no count yet). Voir SAM Q5.
- Inventory accuracy KPI — calculé comme lines_within_tolerance / lines_counted × 100%. Cibles : 95% acceptable, 97% world-class, 99% safety/regulé. Suivi mensuel/trimestriel.
- Chronic variance investigation — si même SKU récidive en variance, root cause upstream : receiving error, BOM inaccurate, kitting sans backflush, squirrel store. Ne pas juste ajuster — investiguer.
flowchart LR COUNT["Physical count
réalisé sur le terrain
(qty comptée vs balance système)"]:::start subgraph INV ["Chemin A — Reconcile via Inventory app"] direction TB A1["Ouvrir l'application Inventory
filtrer un item × storeroom"]:::action A2["Saisir la qty comptée
(granularité item-par-item)"]:::action A3["Cliquer Reconcile Balance
variance appliquée immédiatement"]:::action A4["Ligne INVTRANS par item
(audit trail = 1 ligne / SKU)"]:::ok end subgraph CB ["Chemin B — Reconcile via Count Books"] direction TB B1["Générer un Count Book
filtrer via Sample Type
(ALL / BIN / CNTFREQ /
ICG / ITEM / ROTATING / TOOLS)"]:::action B2["Saisie en bulk de la qty comptée
pour tout le sample group"]:::action B3["Cliquer Reconcile Balances
au niveau du book (batch en une fois)"]:::action B4["Lignes INVTRANS par item
+ statut du Count Book
(POSTED / PARTIAL)"]:::ok end COUNT --> A1 COUNT --> B1 A1 --> A2 --> A3 --> A4 B1 --> B2 --> B3 --> B4 END["Balance réconciliée
+ audit trail journalisé
(posting GL variance
si hors tolérance)"]:::endNode A4 --> END B4 --> END classDef start fill:#3B82F6,stroke:#1E40AF,color:#FFFFFF,font-weight:600; classDef action fill:#FFFFFF,stroke:#94A3B8,color:#0F172A; classDef ok fill:#D1FAE5,stroke:#178A66,color:#0F172A; classDef endNode fill:#1D9E75,stroke:#178A66,color:#FFFFFF,font-weight:600;
⚠️ Piège IBM
Inventory app vs Count Books — quel chemin choisir ? Les deux peuvent réconcilier, mais leurs cas d'usage et leur granularité diffèrent. IBM teste régulièrement cette distinction.
- Inventory app reconciliation — item par item, ad-hoc, action immédiate. Pas de regroupement par count session. Convient pour corrections one-off.
- Count Books reconciliation — batch de SKUs liés à une session de comptage planifiée. Audit trail riche (book ID, date génération, compteur assigné, supervisor). Workflow recount intégré. Convient pour cycle counting régulier ou full physical annuel.
- SOX/régulé : préférer Count Books pour la traçabilité supérieure.
- Les deux modes génèrent le même type de row INVTRANS (CYCLECOUNT) — la différence est dans l'enrobage applicatif.
🎯 Carte mémoire
Q. Un cycle count A-class a généré un PHYSCNT de 92 vs CURBAL 100. La tolérance ABC=A est 2%. Quel est le flow ?
Afficher la réponse
Écart = (100−92)/100 = 8% > tolérance 2%. Le count est marqué RECOUNT. Le supervisor renvoie au floor pour second comptage. Si le second confirme 92, override admin avec justification (THEFT? DAMAGE? squirrel store?) requis avant Reconcile Balances. Si le second comptage trouve 99, l'écart 1% est dans tolérance, auto-reconcile vers CURBAL=99 + GL Variance Loss 1 unit × cost.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :B
Pourquoi cette question existe — IBM teste si le candidat sait que la réconciliation est un step distinct de la saisie du physical count. C'est une distinction critique pour les FAs : un cycle count sans réconciliation laisse PHYSCNT et CURBAL désalignés indéfiniment, faussant les rapports d'inventaire.
Le contexte théorique d'abord — la réconciliation comptable est l'acte de finaliser un comptage en alignant les écritures comptables avec le terrain. Elle déclenche les écritures GL Variance qui reflètent le gain (variance positive) ou la perte (variance négative) en P&L. Sans cet acte explicite, le book continue de mentir et les états financiers sont incorrects. SOX § 404 (contrôles internes du reporting financier) impose que cette opération soit auditable, datée, et avec ségrégation des fonctions [EOTRAG Query 10].
Ce que Maximo en fait — version opérationnelle — Inventory app > sélectionner item > More Actions > Reconcile Balances. Maximo : (1) lit PHYSCNT et CURBAL ; (2) calcule l'écart × current AVGCOST ; (3) écrit INVTRANS row CYCLECOUNT avec quantity = écart, cost = écart × cost ; (4) écrit GL voucher Dr Inventory Variance / Cr Inventory (ou inverse selon polarité) ; (5) update CURBAL = PHYSCNT ; (6) reset PHYSCNT à null ou copie. Master-map.pdf p.827 Reconcile Balances. L'action est tracée dans audit log avec user/date/quantity-reconciled.
Exemple chiffré — PHYSCNT 87, CURBAL 92, AVGCOST 12 $. Écart = −5 unités, valeur = −60 $. INVTRANS CYCLECOUNT row : qty=−5, cost=60 $, REASONCODE inherited from count book or default. GL : Dr Inventory Variance 60 $ / Cr Inventory 60 $. CURBAL devient 87 ; PHYSCNT clearé. Si on lance un rapport stock value après, Inventory account a baissé de 60 $.
Analogie quotidienne — vous avez compté votre tirelire (PHYSCNT). Vous mettez à jour votre app de budget en saisissant le chiffre. Mais tant que vous ne « validez » pas dans l'app (Reconcile), votre solde affiché reste l'ancien. Il faut le step explicite de validation pour que l'app commit le changement et écrive l'écriture comptable.
Pourquoi A est faux — relancer Adjust Physical Count avec la même valeur ne fait que ré-enregistrer le PHYSCNT (ou no-op selon version). Cela ne déclenche aucune écriture GL ni mise à jour CURBAL. Le candidat qui répète l'action espère qu'à la deuxième fois Maximo va « comprendre », mais Maximo distingue strictement saisie et réconciliation (D9 near-synonym).
Pourquoi C est faux — Maximo ne fait jamais d'auto-reconciliation au save. La save commit la saisie de PHYSCNT mais le commit GL/CURBAL nécessite l'action Reconcile explicite. Cette autonomie est volontaire pour respecter la séparation des fonctions (le compteur sauvegarde sa saisie ; le supervisor lance la reconcile). L'option fabrique un comportement implicite qui n'existe pas (D7 non-existent).
Pourquoi D est faux — il n'existe pas de « End of Day batch » qui auto-reconcilie les counts dans Maximo standard. Cron tasks existent pour reorder, ROP recalc, mais pas pour reconcile. C'est une fonctionnalité fabriquée. Cron tasks « Cycle Count Email Notification » ou similar peuvent rappeler aux supervisors qu'il y a des counts en attente, mais ne posttent pas eux-mêmes (D2 invented).
Two-step physical count flow
- Adjust Physical Count (compteur) → écrit PHYSCNT, pas de GL
- Reconcile Balances (supervisor) → transfère PHYSCNT vers CURBAL, écrit GL Variance, INVTRANS CYCLECOUNT
Out-of-tolerance handling : recount workflow avant reconcile.
- Reconcile Balances = step #2 après Adjust Physical Count
- Effets : CURBAL = PHYSCNT, INVTRANS CYCLECOUNT, GL Variance
- Aucune auto-reconcile sur save
- SOX exige separation duties
- [EOTRAG Query 10] Physical Count Reconciliation — IBM Maximo Manage 9
- master-map.pdf p.827 — Reconcile Balances action
- SOX § 404 — Internal Controls Over Financial Reporting
Correct :C
Pourquoi cette question existe — IBM C1000-208 dédie l'objectif 3.3 spécifiquement à la dichotomie Inventory vs Count Books. Choisir le bon outil selon le contexte (one-off vs batch récurrent audité) est une décision FA quotidienne.
Le contexte théorique d'abord — un Count Book est un artefact d'audit né dans les ERP des années 1990 (SAP, Oracle Inventory). Il bundle un set de SKUs à compter dans une session définie ; capture qui, quand, où ; trace l'état (DRAFT, ACTIVE, COMPLETED, CLOSED) ; intègre le workflow recount. C'est l'équivalent papier d'un « bordereau de comptage » signé par le compteur et le supervisor. SAP S/4HANA a son équivalent (Physical Inventory Document) ; Oracle a son « Cycle Count Schedule » ; Maximo Count Books est le pendant IBM [EOTRAG Query 5].
Ce que Maximo en fait — version opérationnelle — Count Books app > New > sélectionner storeroom CENTRAL + filter ABCTYPE=A + due date filter (next month). Maximo génère le book avec les SKUs correspondants. Status : DRAFT. Le supervisor passe en ACTIVE et assigne au compteur. Le compteur ouvre l'app sur tablette/handheld, scanne les SKUs, saisit le PHYSCNT par item. Au retour : status COMPLETED. Supervisor lance Reconcile Balances depuis le book → tous les items in tolerance auto-réconciliés ; out-of-tolerance → recount queue. Master-map.pdf p.831-835 Count Books application.
Exemple chiffré — Storeroom CENTRAL a 250 A-class items. Count Book généré : 250 lignes, expected qty pre-rempli depuis CURBAL. Compteur travaille 8h, scanne 250 items. Résultat : 230 in tolerance (auto-reconciled), 18 out-of-tolerance (recount), 2 not-found (investigation). Le book est en status COMPLETED. Reconciliation lancée pour les 230 → 230 INVTRANS rows + GL postings. Les 18 reviennent en queue recount. Audit log : compteur=Jean Dupont, supervisor=Marie Tremblay, date=2026-04-15, durée=8.2h.
Analogie quotidienne — comme un cahier de visite dans un musée : chaque visiteur émarge à l'entrée (« qui ») avec heure (« quand ») et nom de la salle (« où »). C'est le book qui matérialise la traçabilité, pas chaque ticket individuel. Les Count Books donnent ce niveau d'audit sur les comptages de stock.
Pourquoi A est faux — Inventory app + Adjust Physical Count item-by-item est utilisable mais : (1) pas de regroupement par session ; (2) pas d'audit du « who-what-when » au niveau session ; (3) aucun workflow recount intégré ; (4) le supervisor doit manuellement parcourir les 250 items pour reconcile. C'est techniquement possible mais opérationnellement médiocre pour 250 items récurrents (D4 partial-truth — fonctionne pour 1-5 items ad-hoc).
Pourquoi B est faux — Item Master est l'application qui définit les items au niveau organisation (description, attributs, commodity, rotating flag). Elle ne contient PAS de balances — celles-ci sont dans Inventory au niveau storeroom. Mettre à jour QTY dans Item Master n'a aucun sens (le champ n'existe pas). C'est une wrong-app suggestion (D6 wrong-app).
Pourquoi D est faux — Storerooms application configure les storeroom records (location code, GL account, parent storeroom). Elle a des champs de configuration cycle count (frequency, default tolerance) mais ne lance PAS de comptages. Toggle « Cycle Count flag » est un sibling-field — un flag de configuration, pas un trigger d'action (D5 sibling-field).
| Use case | App à utiliser | Pourquoi |
|---|---|---|
| 1-3 items, ad-hoc | Inventory app | Simple, direct |
| Cycle count récurrent (10+ items) | Count Books | Batch, audit, recount workflow |
| Full physical annuel | Count Books | SOX traçabilité |
| Pièce trouvée hors comptage | Inventory (Adjust Current) | Pas de comptage formel |
| Régulé (FDA, aero) | Count Books obligatoire | ESIG + ségrégation |
- Count Books = batch + audit + recount workflow
- Inventory reconcile = item-par-item, ad-hoc
- Status workflow Count Book : DRAFT → ACTIVE → COMPLETED → CLOSED
- Régulé : Count Books obligatoires
- [EOTRAG Query 5] Cycle Counting / Physical Inventory — IBM Maximo Manage 9 Count Books
- master-map.pdf p.831-835 — Count Books application
- IBM Maximo Manage 9 — Count Books module
Correct :A
Pourquoi cette question existe — IBM teste si le candidat comprend le mécanisme de tolérance et le recount workflow qui s'enclenche en cas de dépassement. C'est un contrôle interne crucial pour SOX et la qualité des données.
Le contexte théorique d'abord — la tolérance est un seuil au-delà duquel un écart est suspect (probablement une erreur de comptage, pas une vraie perte). On ne pose pas l'écriture comptable directement ; on demande un recount pour confirmer. Cette « two-strikes rule » est un standard d'audit : si deux comptes indépendants confirment l'écart, il est crédible ; sinon, c'est probablement une erreur de saisie. ABC drive la sévérité : les A-class (haute valeur) ont des tolerances strictes (1-2%), les C-class (basse valeur) plus lâches (5-10%) [EOTRAG Query 10].
Ce que Maximo en fait — version opérationnelle — Count Books reconciliation : pour chaque ligne, compute variance % = |PHYSCNT − CURBAL| / CURBAL × 100. Compare contre Tolerance % défini dans Organizations > Inventory Defaults > Variance % par ABCTYPE. Si variance ≤ tolerance : auto-reconcile (INVTRANS + GL). Si variance > tolerance : ligne marquée RECOUNT, ne posttée pas, supervisor notifié, item ré-assigné. Master-map.pdf p.836 Tolerance and Recount.
Exemple chiffré — CURBAL 500, PHYSCNT 478, tolerance 2%. Variance = (500−478)/500 = 4.4%. 4.4% > 2% → RECOUNT. Le supervisor envoie au floor pour second comptage. Cas : second comptage = 478 (confirmé) → override admin requis avec reason code (THEFT? squirrel store?) → reconcile manuel. Cas : second comptage = 495 (différence avec premier) → premier était une erreur de saisie ; reconcile à 495 (variance 1% < tolerance, auto OK).
Analogie quotidienne — comme un test de glycémie qui sort à un niveau anormal : on ne traite pas immédiatement, on refait un test pour confirmer. Si le second test confirme, on agit ; sinon, c'était une erreur de mesure. Un seul résultat aberrant ne déclenche pas la cascade thérapeutique.
Pourquoi B est faux — Maximo enforce les tolerances ; il ne pose pas silencieusement. C'est précisément la valeur ajoutée du système configuré : prévenir les write-off impulsifs. Auto-reconciliation existe MAIS uniquement dans la tolerance, pas en dehors. La phrase inverse complètement le comportement (D3 inverse).
Pourquoi C est faux — rejeter le count et reset PHYSCNT effacerait le travail du compteur. Le système conserve la saisie mais la flag pour recount. Aucun reset spontané. C'est une fabrication d'un comportement destructif inexistant (D7 non-existent).
Pourquoi D est faux — réconcilier partiellement (10 unités sur les 22 d'écart) n'a aucun sens comptable : on ne peut pas « approuver une partie » d'une variance. C'est tout ou rien (avec recount comme tampon). Cette option fabrique un comportement de reconcile partiel inexistant (D2 invented).
Tolerance + Recount workflow
- Compute variance % = |PHYSCNT − CURBAL| / CURBAL
- If variance ≤ tolerance → auto-reconcile (INVTRANS + GL)
- If variance > tolerance → flag RECOUNT, supervisor notification
- Recount → second comptage physique
- If confirmed → admin override + reason code → reconcile
- If diverging → resolve discrepancy, reconcile final value
Tolerances typiques par ABC
- A-class : 0-2%
- B-class : 2-5%
- C-class : 5-10%
- Safety/régulé : 0% (zéro tolérance)
- Tolerance dépassée = RECOUNT, pas reconcile
- A-class strict (2%), C-class lâche (10%)
- Règle deux-prises : second comptage obligatoire
- Override admin avec reason code documenté
- [EOTRAG Query 10] Variance Tolerance / Recount Workflow — Warehouse Management with SAP S/4HANA
- master-map.pdf p.836 — Count Books Tolerance and Recount
- IBM Maximo Manage 9 — Inventory Defaults variance % per ABC
Correct :D
Pourquoi cette question existe — comprendre les écritures GL d'une variance positive vs négative est crucial pour les FAs Maximo qui interagissent avec finance. IBM teste la polarité (gain vs loss) et le compte de contrepartie (Adjustment vs Variance vs AP).
Le contexte théorique d'abord — en comptabilité double-entry, chaque transaction a un débit (Dr) et un crédit (Cr) qui s'équilibrent. Pour une variance positive (le stock physique est plus élevé que le système), on découvre comptablement plus d'asset → on débite Inventory (asset augmente). La contrepartie est un gain, crédité sur un compte d'ajustement de P&L. La polarité s'inverse pour les pertes : Inventory crédité (asset baisse), Variance Loss débité (P&L). Cette mécanique est universelle (US-GAAP, IFRS, IFRS for SMEs) [EOTRAG Query 10].
Ce que Maximo en fait — version opérationnelle — la configuration des comptes GL d'ajustement se fait dans Chart of Accounts au niveau Organisation : (a) Inventory Account (asset), (b) Inventory Adjustment Gain Account (P&L gain), (c) Inventory Variance Loss Account (P&L loss). Reconcile Balances détermine la polarité (PHYSCNT vs CURBAL) et choisit la bonne paire d'écritures. Master-map.pdf p.793 GL Configuration. Le INVTRANS row porte le DEBIT_GL et CREDIT_GL pour traçabilité.
Exemple chiffré — variance = +5 unités × 20 $ = +100 $. Écritures :
Dr Inventory 100 $
Cr Inventory Adjustment Gain 100 $
Effets : balance sheet Inventory augmente de 100 ; P&L récupère un gain non-opérationnel de 100. Au prochain rapport de variance par reason code, ces 100 $ sont attribués au reason code (FOUND, RECONCILE...).
Analogie quotidienne — vous découvrez 50 $ oubliés dans votre porte-monnaie. Votre tableur budget : Dr (j'ajoute) « Cash » 50 $, Cr (contrepartie gain) « Other Income » 50 $. Vous ne créez pas une fausse vente ; vous reconnaissez l'augmentation d'asset par un gain.
Pourquoi A est faux — Dr Inventory Variance Loss / Cr Inventory est l'écriture pour une variance NÉGATIVE (PHYSCNT < CURBAL : on découvre moins de stock que prévu). La polarité est inversée vs le cas positive. Le candidat qui ne distingue pas gain de loss confond ces deux écritures (D3 inverse).
Pourquoi B est faux — Dr Cash / Cr Inventory correspond à une vente : on transforme du stock en cash. Une variance n'est pas une vente ; c'est un ajustement de comptage. Cette écriture est totalement hors-sujet dans le contexte cycle count (D6 wrong-app).
Pourquoi C est faux — Dr Inventory / Cr Accounts Payable correspond à une réception PO : on reçoit du stock contre une obligation de payer le vendor. Pas applicable à une variance interne (pas de vendor impliqué dans le comptage). Le candidat qui répond ceci confond reconcile avec receipt (D9 near-synonym, deux mécanismes différents qui débit Inventory).
| Variance type | Dr | Cr | Effet P&L |
|---|---|---|---|
| Positive (PHYSCNT > CURBAL) | Inventory | Inventory Adjustment Gain | Gain |
| Negative (PHYSCNT < CURBAL) | Inventory Variance Loss | Inventory | Loss |
| Réception PO | Inventory | AP | Neutre (asset move) |
| Issue WO | WO Cost (COGS-like) | Inventory | Expense |
- Variance + : Dr Inventory / Cr Adjustment Gain
- Variance − : Dr Variance Loss / Cr Inventory
- Comptes configurés en Chart of Accounts par Org
- INVTRANS row porte DEBIT_GL / CREDIT_GL pour audit
- [EOTRAG Query 10] Variance Accounting — Warehouse Management with SAP S/4HANA
- master-map.pdf p.793 — GL Configuration / Inventory Adjustment accounts
- IBM Maximo Manage 9 — Reconcile Balances GL postings
Correct :C
Pourquoi cette question existe — IBM C1000-208 inclut des questions de jugement managérial où le candidat doit choisir la bonne réponse opérationnelle, pas juste la procédure technique. Comprendre que la variance chronique = signal upstream est essentiel pour les FAs reliability.
Le contexte théorique d'abord — en gestion industrielle, une variance répétitive sur le même item est un signal de processus défaillant en amont, pas un événement aléatoire. Causes typiques : (1) erreur récurrente de réception (le receiver compte mal cette commodité), (2) kitting sans backflush (les pièces du kit sortent physiquement mais pas comptablement), (3) BOM inaccurate (l'item est consommé pour une autre référence dans Maximo), (4) squirrel store (cache informelle au site qui draine le storeroom officiel sans transactions), (5) vol/shrink (rare mais possible). La méthodologie root-cause analysis (5 Whys, fishbone, Ishikawa) appliquée aux variances permet de cibler le problème [EOTRAG Query 10 + 15].
Ce que Maximo en fait — version opérationnelle — Maximo ne « résout » pas une variance chronique automatiquement. Il fournit les outils pour investiguer : (a) Variance Report by Item, (b) Inventory Transaction History (filtrer MATUSETRANS sur l'item), (c) BOM Audit Report, (d) Receiving History par receiver, (e) Where Used analysis. Le FA combine ces sources avec une enquête terrain (entretien receivers, audit bins voisines, vérification kits actifs). Master-map.pdf p.840 Variance Investigation Tools.
Exemple chiffré — item BRG-001, 4 mois consécutifs avec variance −15 unités. Total cumulé : −60 unités × 12 $ = 720 $ de loss. Investigation : (1) check receiving history → receiver Jean Dupont a 8 réceptions de cet item ces 4 mois ; (2) audit physique → l'item arrive en boîtes de 50, mais les POs sont à 100 ; le receiver enregistre 100 unités quand il y en a 99 (erreur récurrente de comptage à la réception) ; (3) action : formation receiver + procédure de double-vérif + vérification source vendor packing slip. Variance disparaît au mois 5.
Analogie quotidienne — votre compte bancaire perd 30 $ chaque mois sans raison apparente. Au lieu d'« accepter » ou de relever votre tolérance budgétaire, vous investiguez : abonnement oublié, prélèvement automatique non identifié, fraude carte. La cause est upstream du symptôme (le débit), pas dans votre comptage.
Pourquoi A est faux — augmenter la tolérance pour faire entrer la variance est une procédure plausible-but-wrong : ça masque le problème sans le résoudre. Le stock continue de disparaître, on accepte juste comptablement la perte. Cela viole les principes de continuous improvement et masque les pertes financières au reporting (D10 procedure-plausible).
Pourquoi B est faux — arrêter de compter ne résout rien et est une violation directe de SOX : tous les items à valeur significative doivent être cycle-counted. C'est l'option du laissez-aller. Un auditeur le détecterait immédiatement comme red flag (D2 invented — pratique non-acceptable).
Pourquoi D est faux — ABCTYPE = N exclut un item du cycle count. Mais cette classification est réservée aux items hors discipline cycle count (services, special-order). L'utiliser pour échapper à un problème de variance chronique est un misuse du flag. Si l'item a une valeur, il DOIT être en A/B/C selon sa classification ABC réelle, pas en N (D5 sibling-field — type N existe mais pour autre cas).
Investigation root cause variance chronique — checklist
- Vérifier réceptions récentes (receiver, dates, quantities saisies vs packing slip)
- Vérifier kits utilisant l'item (kit issue avec backflush ?)
- Vérifier BOMs (substitution silencieuse vers cet item ?)
- Audit physique des bins voisines (mauvais stockage ?)
- Entretiens techniciens (squirrel store identifié ?)
- Camera/badge access logs (vol ?)
- Action correctrice ciblée + monitoring
- Variance chronique = signal upstream
- Investiguer, pas juste reconcile
- 5 causes : receiving, kitting, BOM, squirrel, theft
- Tolérance ≠ pansement
- [EOTRAG Query 10] Chronic variance investigation — IBM Maximo Manage 9
- [EOTRAG Query 15] ISO 55000 / Spare Parts Criticality — Slater squirrel store concept
- master-map.pdf p.840 — Variance Investigation Tools
Item Issues (Inventory Usage + Issues and Transfers RBA)

📋 Objectifs IBM
- Issuer un Item vers un Work Order, une Location ou un Asset (Issue To Person obligatoire pour les tools, sélection Issue Rotating Asset)
- Blue Action Button : Select Reserved Items · Select Spare Parts
- Issue/Order de Material Requests depuis Desktop Requisitions
- Traiter le Staging en passant le Document Status à STAGED (balance déplacée vers le staging bin)
- Split the Quantity à issuer sur plusieurs bins/lots quand une seule location n'a pas la qty
- Gérer le Physical Count dans l'application Inventory Usage
- Réaliser les Issues dans la Issues and Transfers Role Based Application (RBA)
- Issuer un condition-enabled item
- Issuer un lotted item
💡 Points clés
- Inventory Usage application est la nouvelle application centrale pour les issues, returns, transfers depuis Maximo 7.6+. Remplace l'ancienne « Issue Current Item » disparue. Document Type ISSUE / RETURN / TRANSFER / TRANSFEROUT / SHIPMENT.
- Blue Action Button — Select Reserved Items : ouvre dialog des réservations actives sur le storeroom courant ; le user sélectionne les WOs/réservations à transformer en issue ; Maximo crée les Inventory Usage Lines correspondantes.
- Blue Action Button — Select Spare Parts : ouvre dialog Spare Parts d'un asset ; permet d'émettre directement des pièces détachées définies sur un asset sans créer de réservation préalable.
- Issue To Person — mandatory pour tools (SAM Q6) : un item flaggé as Tool ne peut sortir du storeroom sans Issue To Person renseigné. Audit trail individuel pour le retour. Pour les non-tool items, Issue To Person est optionnel.
- Issue Rotating Asset : pour rotating items, le user doit sélectionner le serial spécifique à émettre. Maximo affiche la liste des assets en STORES status pour ce storeroom ; le coût exact du serial sélectionné est imputé.
- Bin splitting (SAM Q8) : quand la quantité réservée dépasse le contenu d'une bin, l'utilisateur clique Split Usage Quantity ; allouer la quantité sur plusieurs bins/lots manuellement OU laisser Maximo auto-split selon FIFO.
- Desktop Requisitions : les techniciens créent des Material Requests (MR) depuis Desktop Requisitions app ; les requests deviennent des réservations ou Item Requests qu'un planner approuve et transforme en issues.
- Staging via Document Status STAGED : Inventory Usage record > change Status from OPEN/ENTERED to STAGED. Maximo déplace la qty de la main bin vers la staging bin du storeroom ; available balance baisse ; physical balance reste dans le storeroom complex.
- Issues and Transfers RBA : Role-Based Application moderne (UI tablette/handheld) pour les opérations terrain. Workflow simplifié, scan barcode, moins de champs, conçu pour les magasiniers et techniciens.
- Condition-enabled item issue : si item est condition-enabled (Item Master flag), l'issue dialog montre les conditions disponibles (NEW, REFURB, USED) et leur cost rate. User sélectionne la condition ; cost imputé = NEW_cost × condition_rate.
- Lotted item issue : si item est lot-tracked (Item Master flag), l'issue dialog montre les lots disponibles avec leur quantité et expiration. User sélectionne le lot ; FIFO par expiration recommandé pour les denrées avec péremption.
- Workflow status Inventory Usage : ENTERED → IN PROGRESS → COMPLETE → CANCELLED. L'issue prend effet quand le status devient COMPLETE ; les transactions MATUSETRANS sont écrites à ce moment.
- Issue To target : Work Order (WONUM), Location (LOCATION), Asset (ASSETNUM), General Ledger (GL Account direct). Direct GL issue bypass WO et impute le coût directement.
- Physical Count in Inventory Usage : le tab Inventory Usage permet de saisir les comptes physiques par item ; alimentent PHYSCNT pour réconciliation ultérieure.
- Negative quantity reservation handling : si available balance < reservation quantity, Maximo offre 3 options : (1) Split across bins (bin splitting), (2) Partial issue (issue ce qui est disponible, retain reste), (3) Cancel reservation et raise PR.
flowchart TD WO["Work Order approuvée
ou Issue request"]:::start TYPE{"Type d'item ?
(STU §4.1)"}:::decision TOOL["Branche TOOL
Tool item non-rotating"]:::action TOOL_REQ["Issue To Person obligatoire
(SAM Q6 — réponse C)
tool tracé vers un travailleur nommé
pas une Location ni une WO seule"]:::warn SVC["Branche SERVICE
Item de type Service
(pas d'inventaire physique)"]:::action SVC_TX["Charge directe sur les actuals WO
(aucun impact balance)"]:::ok ITEM["Branche ITEM
Item d'inventaire standard"]:::action GL{"GL Debit Account
résolu ?
(WO / location / item default)"}:::decision GL_FAIL["Arrêt — issue bloquée
GL debit account manquant"]:::stop BIN{"La default bin a-t-elle
assez de qty ?"}:::decision SPLIT["Bin splitting requis
(SAM Q8 — réponse B)
Dialog Split Usage Quantity
tire depuis plusieurs bins / lots
Ligne InvUseSplit créée"]:::warn PICK["Pick depuis la default bin
(InvUseLine unique)"]:::action STAGE{"Stager avant issue ?
(Document Status
= STAGED)"}:::decision STAGED["Déplacer la qty vers Staging Bin
balance storeroom −
balance staging +
(STU §4.1 chemin staging)"]:::action ISSUE["Réaliser l'Issue
balance −= qty
actuals WO += qty
INVTRANS type=ISSUE
+ ligne MATUSETRANS"]:::endNode WO --> TYPE TYPE -- Tool --> TOOL --> TOOL_REQ --> ISSUE TYPE -- Service --> SVC --> SVC_TX TYPE -- Item --> ITEM --> GL GL -- Non --> GL_FAIL GL -- Oui --> BIN BIN -- Non --> SPLIT --> STAGE BIN -- Oui --> PICK --> STAGE STAGE -- Oui --> STAGED --> ISSUE STAGE -- Non --> ISSUE classDef start fill:#3B82F6,stroke:#1E40AF,color:#FFFFFF,font-weight:600; classDef decision fill:#F59E0B,stroke:#B45309,color:#FFFFFF; classDef action fill:#FFFFFF,stroke:#94A3B8,color:#0F172A; classDef stop fill:#EF4444,stroke:#991B1B,color:#FFFFFF; classDef endNode fill:#1D9E75,stroke:#178A66,color:#FFFFFF,font-weight:600; classDef warn fill:#FEF3C7,stroke:#F59E0B,color:#78350F; classDef ok fill:#D1FAE5,stroke:#178A66,color:#0F172A;
⚠️ Piège IBM
Issue To Person : différence Tool vs Item — la règle change entre les deux types et IBM teste systématiquement cette différence.
- Tool : Issue To Person OBLIGATOIRE. Audit trail individuel, retour traceable. Sans Issue To Person, Maximo bloque l'issue avec erreur.
- Item (consommable) : Issue To Person optionnel. Item est consommé sur le WO, pas retourné.
- Tool rotating (ex : multimètre individualisé par serial) : Issue To Person + selection du serial spécifique.
- Confondre ces règles = audit fail + impossibilité de retracer un outil perdu.
🎯 Carte mémoire
Q. Une réservation de 50 unités existe sur un item. La default bin a seulement 20 unités ; deux autres bins ont 18 et 25. Comment émettre les 50 ?
Afficher la réponse
Inventory Usage record > sélectionner la ligne > click Split Usage Quantity (bin splitting). Dialog permet d'allouer 20 à bin1, 18 à bin2, 12 à bin3 = 50 total. Le système auto-décrémente chaque bin individuellement, génère 3 sub-rows InvUseSplit, et 3 MATUSETRANS rows à la status COMPLETE. SAM Q8 : « Use bin splitting to issue ».
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — c'est une SAM verbatim publiée par IBM (Q6). Elle teste le critère unique pour les tools : Issue To Person obligatoire. La présence dans le SAM signale qu'IBM considère cette règle comme essentielle au C1000-208. Comprendre POURQUOI, pas seulement QUOI, est nécessaire pour les questions dérivées en exam.
Le contexte théorique d'abord — un Tool est un asset partagé entre techniciens, retourné après usage (multimètre, clé dynamométrique, échafaudage). Contrairement à un consommable (joint, lubrifiant) qui est utilisé et disparaît, un tool fait des allers-retours storeroom-terrain. La traçabilité « qui l'a sorti, quand, pour quel WO, retourné quand » est essentielle pour : (1) responsabiliser en cas de perte/casse, (2) calculer l'utilisation et planifier les remplacements, (3) audit ISO 9001 § 7.5.4 (preservation of customer property — applicable aux tools en délégation), (4) sécurité (un tool calibré utilisé hors période de calibration peut produire des mesures fausses) [EOTRAG Query 6].
Ce que Maximo en fait — version opérationnelle — Item Master record > flag Tool = Y. À l'issue (Inventory Usage application), le field Issue To Person devient mandatory en validation côté backend. Si vide, save échoue avec erreur « Issue To Person required for tool items ». Le champ accepte un PERSON record (un PERSONID Maximo). Au retour (return transaction), le système valide que c'est la même personne (ou autorisée par un security group). Audit trail dans MATUSETRANS porte la PERSON pour l'issue et le retour. Master-map.pdf p.853 Tool Issue Workflow.
Exemple chiffré — multimètre Fluke MM-001 dans storeroom CENTRAL. Technicien Jean Dupont (PERSONID=JDUPONT) le sort pour le WO-1234. Inventory Usage record : ITEM=MM-001, ISSUETOPERSON=JDUPONT, WONUM=1234, qty=1, status=COMPLETE. MATUSETRANS row : enregistre l'issue avec PERSON=JDUPONT. À la fin du shift, Jean retourne le multimètre. Return transaction : PERSON=JDUPONT, qty=1, ISSUETYPE=RETURN. Le tool est de retour en STORES.
Analogie quotidienne — comme emprunter un livre à la bibliothèque : la bibliothécaire DOIT noter qui emprunte (votre carte de bibliothèque), la date d'emprunt et de retour. Sans ce traçage, on ne saurait pas qui a la collection. Vs un dépliant gratuit (consommable) que vous prenez sans signature — il est consommé, pas retourné.
Pourquoi A est faux — Location est un sibling-field : on PEUT issue tool to a location (ex : un site distant), mais ce n'est pas REQUIS. La regle d'IBM est sur Issue To Person, pas Location. Cette option est partial-truth (location peut être renseigné en plus, mais pas seul) (D5 sibling-field).
Pourquoi B est faux — Work Order est aussi un sibling-field : un tool peut être issued contre un WO (et c'est commun), mais la condition mandatory est Person, pas WO. Si on a Person mais pas de WO, l'issue passe (ex : tool emprunté pour formation interne, pas pour un WO spécifique). Si on a WO mais pas Person sur un tool, l'issue échoue. Donc Person est la contrainte stricte (D5 sibling-field).
Pourquoi D est faux — GL Debit Account est requis pour le costing comptable de tout issue (item ou tool), mais ce n'est PAS spécifique aux tools — c'est universel. La question demande ce qui est spécifique aux tools, et c'est Issue To Person. GL Debit s'applique à tous les issues, donc ne peut pas être la « différence » qui fait des tools un cas spécial (D6 wrong-app — applicable mais pas le critère discriminant).
| Type item | Issue To Person | Pourquoi |
|---|---|---|
| Tool (Tool flag = Y) | OBLIGATOIRE | Audit trail retour, accountability |
| Item consommable | Optionnel | Consommé sur WO, pas retourné |
| Rotating asset (non-tool) | Optionnel mais recommandé | Track qui a installé/désinstallé |
| Tool rotating (sérialisé) | OBLIGATOIRE | Tool + serial → double accountability |
- Tool issue → Issue To Person OBLIGATOIRE
- Item consommable → optionnel
- Audit trail retour traceable
- SAM Q6 verbatim IBM
- [EOTRAG Query 6] Rotating items / Tools — IBM Maximo Manage 9
- master-map.pdf p.853 — Tool Issue Workflow
- SAM C1000-208 Q6 — IBM published sample question
Correct :B
Pourquoi cette question existe — SAM verbatim Q8. IBM teste la connaissance précise de la fonctionnalité « bin splitting » et du fait que c'est la méthode officielle pour distribuer une issue sur plusieurs bins, par opposition à des contournements imaginés (Add/Modify Reservations, Create Remaining Lines).
Le contexte théorique d'abord — dans un storeroom complexe, un même item peut être stocké dans plusieurs bins pour des raisons d'organisation : optimisation de picking, séparation par lot/condition, contraintes physiques (bin trop petit). Quand une issue dépasse la capacité d'une bin, le système doit savoir comment puiser dans plusieurs bins atomiquement. WMS modernes supportent le « multi-bin allocation » via algorithmes : FIFO par receipt date, FIFO par expiration (lots), nearest-first (proximité géographique). Maximo offre le contrôle manuel via bin splitting [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Inventory Usage application > sélectionner la ligne avec qty insuffisante en default bin > click Split Usage Quantity action. Dialog s'ouvre avec : (1) la qty totale à allouer, (2) la liste des bins ayant ce item, (3) qty allouée par bin (par défaut 0). User saisit l'allocation manuelle ou laisse Maximo auto-fill (FIFO). Save crée des sub-rows InvUseSplit, une par bin allouée. À status COMPLETE, Maximo écrit autant de MATUSETRANS rows que de bins consommées, chacune avec FROMBIN et qty. Master-map.pdf p.860 Bin Splitting.
Exemple chiffré — réservation 100 unités. BIN-A 60, BIN-B 30, BIN-C 40. User clique Split Usage Quantity, alloue 60 → BIN-A, 30 → BIN-B, 10 → BIN-C = 100. Save. À status COMPLETE :
MATUSETRANS row 1 : FROMBIN=BIN-A, qty=60, cost=60×AVGCOST
MATUSETRANS row 2 : FROMBIN=BIN-B, qty=30, cost=30×AVGCOST
MATUSETRANS row 3 : FROMBIN=BIN-C, qty=10, cost=10×AVGCOST
Stock résiduel : BIN-A 0, BIN-B 0, BIN-C 30. Le WO actuals a 100 unités × cost cumulé.
Analogie quotidienne — vous voulez payer 100 $ en cash, mais votre portefeuille a 60 $, votre tiroir 30 $, votre voiture 10 $. Vous ne créez pas trois transactions distinctes ; vous regroupez les 100 $ en une seule paiement, traçant l'origine de chaque billet. Le bin splitting fait pareil : une issue logique unique, mais un accounting détaillé par bin source.
Pourquoi A est faux — Add/Modify Reservations modifie la quantité réservée (ex : passer de 100 à 60), ce qui ne résout PAS le problème : le user veut TOUJOURS émettre 100. Modifier la réservation à la baisse signifie laisser tomber 40 unités du WO. C'est une procédure inventée pour ce contexte ; en réalité Add/Modify Reservations sert à ajuster la planification, pas à émettre (D2 invented dans ce contexte).
Pourquoi C est faux — Create Remaining Usage Lines n'est pas une fonctionnalité Maximo standard avec ce nom. Il existe une action Generate Remaining (pour les usage lines en partial), mais pas pour bin splitting. Cette option fabrique un nom de feature plausible mais inexistant (D7 non-existent).
Pourquoi D est faux — créer deux Inventory Usage records distincts contournerait le bin splitting mais introduirait : (1) deux IDs Maximo distincts pour une même issue logique ; (2) audit trail fragmenté ; (3) deux validations supervisor au lieu d'une ; (4) deux GL postings groupés. C'est une procédure plausible-but-wrong utilisée par des juniors qui ignorent l'existence de bin splitting (D10 procedure-plausible).
Bin splitting workflow
- Inventory Usage record > select line
- Click Split Usage Quantity action
- Dialog : liste des bins contenant cet item
- Allocate qty per bin (manual or auto-FIFO)
- Save → InvUseSplit sub-rows created
- At status COMPLETE → multiple MATUSETRANS rows (one per bin)
Cas d'usage : default bin insuffisant, lots multiples, conditions multiples, distribution physique forcée.
- Bin splitting = Split Usage Quantity action
- 1 ligne logique → N MATUSETRANS rows (1 par bin)
- Auto-FIFO ou manual allocation
- SAM Q8 verbatim IBM
- [EOTRAG Query 12] Picking Staging Issue / Multi-bin allocation — IBM Maximo Manage 9
- master-map.pdf p.860 — Bin Splitting / Split Usage Quantity
- SAM C1000-208 Q8 — IBM published sample question
Correct :A
Pourquoi cette question existe — STU 4.1 mentionne explicitement le « Blue Action Button : Select Reserved Items · Select Spare Parts ». IBM teste la connaissance précise des deux options de ce bouton. Confondre Select Reserved Items avec Add/Modify Reservations (qui agit sur la liste des réservations, pas sur l'usage) est l'erreur classique.
Le contexte théorique d'abord — dans Maximo Inventory Usage application, le « Blue Action Button » est un bouton centralisateur qui propose les actions contextuelles principales pour populer rapidement un Inventory Usage record. Plutôt que d'ajouter chaque ligne manuellement (slow + error-prone), le user clique le Blue Action Button et choisit une source de données. Les deux options sont : (1) Select Reserved Items — consomme les réservations existantes ; (2) Select Spare Parts — émet directement les spare parts d'un asset. C'est un workflow productivity feature inspiré des best practices SAP / Oracle [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Inventory Usage app > New Inventory Usage > click Blue Action Button (icon big blue button généralement à droite du record header) > choisir « Select Reserved Items ». Dialog s'ouvre avec une liste de réservations actives sur le storeroom courant (filtrable par WO, by status, by item). User coche les réservations à transformer en usage. Click OK : Maximo auto-populate des usage lines avec WONUM, ITEMNUM, qty, default bin, default condition. Master-map.pdf p.855 Inventory Usage Blue Action Button.
Exemple chiffré — storeroom CENTRAL a 5 réservations actives : WO-1234 (10 unités item A), WO-1234 (5 unités item B), WO-1235 (20 unités item C), WO-1236 (3 unités item D), WO-1240 (8 unités item A). Storekeeper veut traiter les WOs 1234 et 1236 ce matin. Click Blue Action > Select Reserved Items, coche les 3 lignes (10 A, 5 B pour WO-1234 ; 3 D pour WO-1236). OK. Inventory Usage record populé avec 3 lignes, total 18 unités à émettre.
Analogie quotidienne — comme un menu drag-to-cart sur Amazon : au lieu de taper chaque produit, vous cliquez sur des items de votre wish-list et ils sont ajoutés à votre commande automatiquement. Le Blue Action Button « Select Reserved Items » est ce drag-from-wishlist version Maximo.
Pourquoi B est faux — Add/Modify Reservations agit sur la liste des réservations elles-mêmes (création, modification de qty, suppression). Elle n'a rien à voir avec populer un Inventory Usage record. C'est l'inverse logique : on modifie la SOURCE des réservations, pas la consommation. Confusion fréquente liée à la similarité de vocabulaire « réservations » dans les deux fonctionnalités (D9 near-synonym).
Pourquoi C est faux — Generate Picklist n'existe pas comme telle dans Inventory Usage app sous ce nom. Il existe Generate Pick List qui crée un document picking print-friendly à partir des usage lines, mais ce n'est pas le Blue Action Button option. Cette option fabrique un nom de feature qui n'est pas exactement Maximo (D7 non-existent — Pick List existe mais pas via Blue Action Button principal).
Pourquoi D est faux — Auto-Issue Reservations est une fonctionnalité fabriquée. Maximo n'auto-issue jamais sans intervention humaine ; le storekeeper doit toujours valider la transformation reservation → issue. L'auto-issue serait une violation du principe de control opérationnel. Cette option fabrique un comportement magique inexistant (D2 invented).
Blue Action Button — 2 options officielles
- Select Reserved Items : pré-remplir depuis les réservations existantes
- Select Spare Parts : pré-remplir depuis la liste de spare parts de l'asset
Workflow général
- New Inventory Usage record
- Click Blue Action Button
- Choose source (Reservations or Spare Parts)
- Filtrer et sélectionner les lignes
- Auto-populate usage lines
- Adjust qty, bin, condition if needed
- Status → COMPLETE → MATUSETRANS rows
- Blue Action Button = 2 options : Reserved Items + Spare Parts
- Speed-fill workflow pour storekeeper
- ≠ Add/Modify Reservations (modifie source)
- Pas d'auto-issue ; validation humaine required
- [EOTRAG Query 12] Picking Staging Issue / Inventory Usage workflow — IBM Maximo Manage 9
- master-map.pdf p.855 — Inventory Usage Blue Action Button
- STU 4.1 — Blue Action Button Select Reserved Items / Select Spare Parts
Correct :B
Pourquoi cette question existe — IBM teste si le candidat sait que les rotating items ne s'émettent pas comme les non-rotating : le storekeeper sélectionne explicitement le serial. Comprendre cette mécanique est essentiel pour le costing par-asset (cost type ASSET).
Le contexte théorique d'abord — un rotating item est par définition non-fungible : chaque unité physique est unique (serial, history, value). À l'émission, le système ne peut pas « choisir une unité au hasard » comme pour un boulon ; il faut une sélection explicite par le storekeeper, qui voit les serials disponibles dans le storeroom (status STORES) et choisit celui à émettre. Ce mécanisme est aligné avec le principe Specific Identification IAS 2 § 23 : pour items non-interchangeables, le coût exact suit l'unité [EOTRAG Query 6].
Ce que Maximo en fait — version opérationnelle — Inventory Usage record > ajouter une ligne avec un rotating item > click Issue Rotating Asset sub-action. Dialog liste les assets de cet item en STORES status pour ce storeroom : SN-A, SN-B, SN-C, SN-D + leur cost actuel + dernière issue date + dernière repair date. Storekeeper coche le serial à émettre. Maximo écrit la usage line avec qty=1 + ASSETNUM=SN-X. À status COMPLETE, MATUSETRANS row porte ASSETNUM et ISSUEUNITCOST = INVCOST de SN-X. L'asset bascule en status WO ou similar (out of STORES). Master-map.pdf p.857 Issue Rotating Asset.
Exemple chiffré — SN-A cost 4 800 $, SN-B 5 200 $, SN-C 5 500 $, SN-D 6 200 $ (récemment réparé). WO demande un motor. Storekeeper reçoit le contexte du WO (utilisation standard) et choisit SN-B (5 200 $, cost intermédiaire, jamais réparé donc neuf). Issue : MATUSETRANS porte ASSETNUM=SN-B, ISSUEUNITCOST=5200 $, qty=1. Le WO actual cost porte 5 200 $.
Analogie quotidienne — comme louer une voiture chez Avis : on ne dit pas « donnez-moi une voiture économique au hasard » et on accepte n'importe quel modèle. On voit la liste des voitures disponibles, on choisit la plaque XYZ-123. Pour cette location, c'est XYZ-123 qui sort, avec son odomètre et son histoire ; pas une autre.
Pourquoi A est faux — Maximo n'auto-sélectionne PAS pour rotating items. Le concept FIFO sur rotating ne s'applique pas (pas de couches anonymes, juste des serials individuels). De plus, sans validation humaine, on émettrait potentiellement le serial le moins approprié (ex : un récemment réparé alors qu'on en a un neuf). C'est une fonctionnalité inventée (D2 invented).
Pourquoi C est faux — issue rotating items via Inventory Usage est explicitement supportée et c'est même le canal préféré. Asset Move/Modify est utilisé pour des changements de location indépendants des WOs (ex : transfert entre storerooms, mise au rebut, reclassification). Confondre les deux mécanismes traduit une mauvaise compréhension du périmètre des deux apps (D6 wrong-app — Asset Move existe mais pour autre cas).
Pourquoi D est faux — taper manuellement un coût moyen est une fonctionnalité inexistante et conceptuellement absurde pour rotating : chaque serial a SON coût, il n'y a pas de moyenne valide. Maximo auto-pulls le coût du serial sélectionné depuis INVCOST par ASSETNUM. Cette option fabrique un comportement manuel inexistant (D7 non-existent).
Rotating asset issue workflow
- Inventory Usage > nouvelle ligne avec item rotating
- Click Issue Rotating Asset sub-action
- Dialog affiche les serials disponibles avec coût + historique
- Storekeeper selects specific serial
- Usage line gets ASSETNUM populated
- À COMPLETE → MATUSETRANS avec ASSETNUM + coût du serial
- Asset status changes (WO or out of STORES)
- Rotating issue = sélection explicite serial
- Issue Rotating Asset action ouvre serial picker
- Cost = INVCOST du serial choisi (par-asset)
- Pas d'auto-FIFO ni de moyenne
- [EOTRAG Query 6] Rotating Items / Item Assembly Structures — IBM Maximo Manage 9
- master-map.pdf p.857 — Issue Rotating Asset action
- IFRS IAS 2 § 23 — Specific Identification
Correct :C
Pourquoi cette question existe — STU 4.1 mentionne « Process Staging by changing Document Status to STAGED ». IBM teste si le candidat connaît le mécanisme exact : ce n'est pas une action séparée, c'est un changement de Document Status sur l'Inventory Usage record.
Le contexte théorique d'abord — le staging est un état intermédiaire dans le workflow OPEN → PICKED → STAGED → ISSUED des Inventory Usage / Pick Lists. À STAGED, les items ont été physiquement déplacés vers une zone d'attente près du WO mais ne sont pas encore consommés. Cela permet au technicien d'arriver et trouver tout le matériel pré-positionné, optimisant son temps. Comptablement, le stock a quitté le main bin (available balance baisse) mais reste dans l'organisation (current balance toujours dans le storeroom complex via staging bin) [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Inventory Usage record > sélectionner record en status ENTERED ou IN PROGRESS > change Document Status field to STAGED. Maximo : (1) déplace la qty de la main bin vers la staging bin du storeroom (configurée sur le Storeroom record) ; (2) génère un INVTRANS row de type STAGE ; (3) decremente available balance ; (4) le record reste en status STAGED jusqu'à change vers COMPLETE (issue final) ou CANCELLED. Master-map.pdf p.862 Staging via Document Status.
Exemple chiffré — Inventory Usage record IU-001 contient 50 unités item-X. Status = ENTERED. Storekeeper change Document Status à STAGED. Maximo : déplace 50 unités du bin main BIN-A vers staging bin STAGE-01 du storeroom. INVTRANS row : ITEM=X, qty=50, FROMBIN=BIN-A, TOBIN=STAGE-01, type=STAGE. Available balance baisse de 50 (les 50 ne peuvent plus être réservés par d'autres WOs). Le lendemain, technicien arrive : Document Status passe à COMPLETE → MATUSETRANS row ISSUE écrit, qty sort de la staging bin.
Analogie quotidienne — comme un check-in à l'aéroport : votre valise est passée au comptoir (PICKED), placée dans la zone de chargement (STAGED), puis chargée dans l'avion (ISSUED). À chaque transition, l'état change explicitement ; vous ne « cliquez pas Issue » pour staging, vous changez l'état du bagage.
Pourquoi A est faux — cliquer Issue (= status COMPLETE) émet directement vers le WO, court-circuitant le staging. Le résultat : pas de step intermédiaire ; les items sortent du système comme consommés. Si on veut staging, il faut explicitement le state STAGED avant COMPLETE. Polarité inversée (D3 inverse — Issue saute STAGED).
Pourquoi B est faux — la WO a son propre status workflow (WAPPR, APPR, INPRG, COMP, CLOSE), distinct du document status de l'Inventory Usage. Mettre la WO en STAGED ne fonctionnerait pas ; STAGED n'est pas un WO status valide. Confusion entre les deux objects et leurs status (D6 wrong-app).
Pourquoi D est faux — Stock Transfer Order (STO) est utilisé pour transférer entre storerooms (différents sites ou même site), pas pour staging interne au storeroom. Lancer un STO pour staging serait un détour inutile et incorrect ; les bins staging et main sont dans le MÊME storeroom. C'est une procédure plausible-but-wrong (D10 procedure-plausible).
Document Status workflow Inventory Usage
- ENTERED : record créé, données saisies
- IN PROGRESS : items en cours de picking
- STAGED : items dans staging bin, available -
- COMPLETE : MATUSETRANS écrit, items issued
- CANCELLED : abandon ; items retournent à main bin
Conditions pour STAGED : staging bin configurée sur Storeroom record + items physiquement déplacés.
- Staging = Document Status field → STAGED
- Items déplacés main bin → staging bin
- Available balance −, current balance =
- STAGED → COMPLETE = issue final
- [EOTRAG Query 12] Picking Staging Issue / Pick List 4 states — IBM Maximo Manage 9
- master-map.pdf p.862 — Staging via Document Status
- IBM Maximo Manage 9 — Inventory Usage status workflow
Correct :A
Pourquoi cette question existe — STU 4.1 inclut « Issue a lotted item ». IBM teste si le candidat sait que la sélection de lot est manuelle (avec FIFO par expiration recommandé), pas automatique, et que la traçabilité par lot est essentielle pour denrées avec péremption.
Le contexte théorique d'abord — un lot tracking est utilisé pour les items où l'identification d'un batch de production est requise : (1) péremption (lubrifiants, peintures, médicaments) ; (2) recall (en cas de défaut, identifier toutes les unités d'un lot) ; (3) régulation (FDA, EASA, traçabilité chaîne d'approvisionnement) ; (4) qualité (tests laboratoire par lot). FIFO par expiration (FEFO — First Expired First Out) est la pratique optimale pour minimiser le gaspillage. Quelques industries (pharma) imposent strict FEFO ; d'autres permettent flexibilité (industriel) [EOTRAG Query 9].
Ce que Maximo en fait — version opérationnelle — Item Master record > flag Lot Type activé (NOLOT, ISSUE, RECEIPT). Quand un lotted item est ajouté à Inventory Usage, le system requiert sélection du LOTNUM. Dialog affiche les lots disponibles avec qty + expiration date. Storekeeper choisit un ou plusieurs lots. Bin splitting compatible avec lot splitting (ex : 30 unités LOT-A + 10 unités LOT-B = 40). MATUSETRANS row porte LOTNUM. Master-map.pdf p.864 Issue Lotted Items.
Exemple chiffré — issue 40 unités SOL-200. Storekeeper voit dialog : LOT-A 50 unités exp 2026-06-30 ; LOT-B 30 unités exp 2026-08-15 ; LOT-C 80 unités exp 2026-12-01. Application FEFO : sélectionner 40 sur LOT-A (qui expire plus tôt). Les 10 unités restantes du LOT-A seront utilisées au prochain issue. LOT-B et LOT-C préservés pour usage futur. Si l'issue était de 60 : 50 sur LOT-A + 10 sur LOT-B (next FEFO). MATUSETRANS rows portent LOTNUM=A et LOTNUM=B respectivement.
Analogie quotidienne — comme la rotation du frigo : vous prenez le yaourt qui périme demain (LOT-A équivalent), pas celui qui périme dans 3 semaines. Sinon ce dernier finit à la poubelle. Le storekeeper Maximo applique cette même logique sur les solvants, peintures, lubrifiants.
Pourquoi B est faux — Maximo n'auto-sélectionne PAS le lot avec latest expiration. Au contraire, FEFO (oldest expiration first) est la pratique recommandée. La phrase inverse complètement la polarité : maximiser la shelf life en utilisant les nouveaux lots laisserait les anciens périmer (D3 inverse).
Pourquoi C est faux — Maximo ne split PAS automatiquement et également entre tous les lots. Le système attend une sélection manuelle ou un FIFO/FEFO contrôlé. Distribuer 13.3 unités par lot serait absurde (pas d'unités fractionnaires sur des emballages physiques) et pollue la traçabilité (3 lots au lieu de 1-2). C'est une fonctionnalité fabriquée (D2 invented).
Pourquoi D est faux — l'application Lots dans Maximo gère les définitions de lots (création, attributs, expiration), pas les transactions de issue. Inventory Usage est l'application correcte pour issuer un lotted item. Suggérer Lots app pour issuer mélange les responsabilités des apps (D6 wrong-app).
Lot tracking — types et workflow
- NOLOT : pas de tracking lot
- ISSUE : tracking au issue (selection requise)
- RECEIPT : lot assigné au receipt + tracking issue
FEFO (First Expired First Out) : pratique optimale pour items avec péremption. Minimise waste. Pharma : strict ; industriel : recommandé.
Multi-lot issue : compatible avec bin splitting si insufficient single lot.
- Lotted issue = sélection manuelle du LOTNUM
- FEFO recommandé (expiration la plus proche d'abord)
- MATUSETRANS porte LOTNUM
- Bin + lot splitting compatibles
- [EOTRAG Query 9] Lots / Condition codes — IBM Maximo Manage 9
- master-map.pdf p.864 — Issue Lotted Items
- FDA 21 CFR Part 11 — Electronic records traceability for lot-tracked items
Correct :B
Pourquoi cette question existe — STU 4.1 inclut « Issue a condition-enabled item ». IBM teste la formule de cost rate : ISSUEUNITCOST = base_cost × condition_rate. Comprendre cette mécanique est essentiel pour les sites refurbissant des composants (rotating spares, repairables).
Le contexte théorique d'abord — un condition-enabled item maintient des balances séparées par condition (NEW, REFURB, USED, REBUILT...). Chaque condition porte un cost rate exprimé en pourcentage du coût de base (généralement NEW = 100%). À l'issue, le coût imputé au WO reflète la condition choisie : un REFURB à 70% coûte 30% moins qu'un NEW. C'est essentiel pour le costing précis : un WO qui consomme un REFURB ne devrait pas être facturé comme s'il avait reçu un NEW. ISO 9001 et best practices reliability appuient cette granularité [EOTRAG Query 9].
Ce que Maximo en fait — version opérationnelle — Item Master record > tab Condition Codes > définir les conditions et leur rate (% de NEW). Inventory app maintient des balances séparées par condition. À l'issue (Inventory Usage), le user sélectionne la condition désirée. Maximo calcule ISSUEUNITCOST = NEW_AVGCOST × condition_rate. MATUSETRANS row porte CONDITIONCODE et le coût ajusté. Master-map.pdf p.866 Issue Condition-Enabled Items.
Exemple chiffré — bearing BRG-X NEW cost $200. REFURB rate 70%. WO consume 1 unité REFURB. ISSUEUNITCOST = 200 × 0.70 = 140 $. WO actual cost = 140 $. Inventory : balance REFURB baisse de 1 (passe à 11). Si une autre WO consomme 1 USED (rate 40%) : cost = 200 × 0.40 = 80 $. Si une troisième WO consomme 1 NEW : cost = 200 × 1.00 = 200 $. Trois WOs, trois costs différents pour un même item, reflétant l'état réel de la pièce délivrée.
Analogie quotidienne — comme louer une voiture : la même Toyota Corolla louée comme « neuve » coûte 80 $/jour, comme « occasion récente » 60 $/jour, comme « ancienne mais fonctionnelle » 40 $/jour. Le client paie selon la condition reçue. Maximo applique cette logique aux pièces de rechange.
Pourquoi A est faux — facturer NEW cost à un REFURB ignore la valeur réelle de la pièce délivrée. Cela inflate les WO actuals et fausse les KPIs maintenance cost. C'est partial-truth : NEW cost est la base mais doit être ajustée par le rate (D4 partial-truth).
Pourquoi C est faux — Maximo n'a pas de comportement « default to lowest » ; il facture la condition exacte sélectionnée. Si le storekeeper sélectionne REFURB, c'est REFURB rate qui s'applique, pas USED. Cette option fabrique un comportement de fallback inexistant (D2 invented).
Pourquoi D est faux — moyenne pondérée par qty entre toutes les conditions est une fonctionnalité inexistante. Chaque condition a son propre cost ; on ne mélange jamais les conditions dans une moyenne. Cela ressemble à WAC mais avec un mauvais grouping (D9 near-synonym, similar mais incorrectly applied).
Condition-enabled item — formule cost
ISSUEUNITCOST = base_AVGCOST × condition_rate
- NEW : rate 100% (base de référence)
- REFURB : rate 60-80% selon politique
- USED : rate 30-50%
- REBUILT : rate 80-90% (proche de NEW si bonne refurb)
Balances séparées : par condition × bin × lot. Reservations peuvent spécifier la condition désirée.
Logique de pick : si réservation sans condition, FIFO toutes conditions confondues ou pick la mieux disponible.
- Issue cost = base × condition rate
- Balance par condition séparée
- MATUSETRANS porte CONDITIONCODE
- 200 × 0.70 = 140 $
- [EOTRAG Query 9] Condition-Enabled Items / Cost Rate at Receipt — IBM Maximo Manage 9
- master-map.pdf p.866 — Issue Condition-Enabled Items
- IBM Maximo Manage 9 — Condition Codes table
Correct :D
Pourquoi cette question existe — STU 4.1 inclut « Issue/Order Material Requests from Desktop Requisitions ». IBM teste la connaissance de cette application self-service spécifique, distincte des Purchase Requisitions (PR) traditionnelles.
Le contexte théorique d'abord — Desktop Requisitions est un module Maximo conçu pour le self-service des techniciens et utilisateurs métier qui ont besoin de matériel sans avoir nécessairement de WO formel ou d'expertise procurement. Il abstrait les détails complexes (PR, quote, vendor, GL accounts) que le planner ou buyer gérera ensuite. Concept similaire à un « shopping cart » d'entreprise. Permet de tracer formally les besoins terrain, optimiser les achats groupés, et donner une visibilité sur la demande non-encore-formalisée [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Desktop Requisitions app > New > sélectionner items + qty + date wanted + delivery location. Save → status WAPPR (waiting approval). Le planner ou supervisor reviewe : si stock disponible, transforme en réservation puis en Inventory Usage record (issue). Si stock pas disponible, transforme en Purchase Requisition (PR) qui devient PO → réception → puis issue. Maximo trace la chaîne Desktop Requisition → PR → PO → MATRECTRANS → MATUSETRANS pour audit. Master-map.pdf p.870 Desktop Requisitions.
Exemple chiffré — technicien Jean Dupont a besoin de 3 bearings BRG-001 pour un job demain matin. Il ouvre Desktop Requisitions sur son tablet, recherche BRG-001, ajoute qty 3, save (status WAPPR). Le planner le voit dans sa queue, vérifie stock (5 disponibles dans CENTRAL), approuve. Maximo crée une réservation hard pour 3 unités sur le storeroom. Le matin, le storekeeper utilise Blue Action Button > Select Reserved Items > coche cette réservation > émet vers Jean (Issue To Person=JDUPONT). Total flow : 30 secondes côté technicien, processed in <1h.
Analogie quotidienne — comme commander à la cantine d'entreprise via un app : vous tapez votre commande sans connaître les détails (recette, fournisseur, prix unitaire). Le chef cuisinier reçoit votre commande, prépare. Vous ne gérez pas l'achat des ingrédients vous-même.
Pourquoi A est faux — Inventory app est l'app pour gérer les stocks (balances, costs, reorder). Elle n'a pas de fonctionnalité self-service de request pour techniciens. Confondre Inventory et Desktop Requisitions traduit une mauvaise compréhension des rôles utilisateurs (D6 wrong-app).
Pourquoi B est faux — Item Master gère les définitions d'items (description, attributs, classification). Aucun lien avec request workflow. C'est l'app du master data manager, pas du technicien (D6 wrong-app).
Pourquoi C est faux — Purchase Requisitions (PR) est utilisé par les buyers et planners pour demander un achat externe au vendor. Pas par les techniciens en self-service. Confondre Desktop Requisition (interne, abstrait) et Purchase Requisition (externe, procurement-ready) est l'erreur classique. Les noms sont proches mais les rôles distincts (D9 near-synonym).
Material request workflow chain
- Desktop Requisitions (technicien) → status WAPPR
- Planner approves → reservation OR PR
- If stock available : Inventory Usage record (issue)
- If stock not available : PR → PO → MATRECTRANS receipt → issue
- Audit trail : DR → PR → PO → receipts → issue
Apps voisines
- Desktop Requisitions : technicien self-service, simple
- Purchase Requisitions : buyer-driven, full procurement detail
- Inventory Usage : storekeeper, issue/return/transfer
- Desktop Requisitions = self-service technicien
- Workflow : DR → planner approves → reservation/PR
- ≠ Purchase Requisitions (procurement)
- Trace complète DR → ... → MATUSETRANS
- [EOTRAG Query 12] Material request workflow — IBM Maximo Manage 9
- master-map.pdf p.870 — Desktop Requisitions application
- IBM Maximo Manage 9 — Desktop Requisitions for self-service
Correct :C
Pourquoi cette question existe — STU 4.1 inclut « Réaliser des Issues dans la Issues and Transfers Role Based Application (RBA) ». IBM teste si le candidat distingue les deux UIs (Inventory Usage classique vs RBA moderne) et comprend leur cas d'usage.
Le contexte théorique d'abord — les Role-Based Applications (RBA) sont des UIs modernes Maximo conçues spécifiquement pour des rôles utilisateurs précis (storekeeper, technician, supervisor). Contrairement aux apps classiques riches en fonctionnalités (designed for power users), les RBAs présentent un workflow simplifié, des champs réduits, et une UI tablette/mobile-friendly. Elles s'appuient sur les MÊMES tables backend (MATUSETRANS, INVBALANCES) ; la différence est purement front-end. Concept similaire aux Fiori apps SAP (specialized UI on top of standard backend) [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Issues and Transfers RBA > Storekeeper logue → écran simplifié : scanner barcode WO ou item → afficher réservations actives → cocher → confirm. Pas de menus complexes, pas de Blue Action Button, pas de tabs avec dizaines de champs. Le RBA appelle les mêmes services backend (Java services / REST APIs) que Inventory Usage, donc résultat comptable identique. UI optimisée touch + barcode scan. Master-map.pdf p.873 Issues and Transfers RBA. Le RBA est livré comme un work center / app dans Maximo Application Suite (MAS) Manage 9.
Exemple chiffré — comparaison time-to-issue 5 items à un WO :
Inventory Usage app classique : 90 secondes (login, navigate, new record, populate fields, click Blue Action, select reservations, validate, complete).
Issues and Transfers RBA : 25 secondes (login auto, scan WO barcode, items pré-affichés, scan items, confirm).
Productivity gain : ~70% pour les operations terrain à fort volume.
Analogie quotidienne — Microsoft Word desktop (Inventory Usage app) vs Office for iPad (RBA) : même fichier .docx, même backend, mais UI radically simplified pour le contexte mobile. On ne peut pas tout faire sur tablet, mais ce qu'on fait quotidiennement (saisie, mise en forme simple) est plus rapide.
Pourquoi A est faux — bypass GL postings violerait l'intégrité comptable. Le RBA ne bypass JAMAIS de postings ; il utilise le même backend service. Cette option fabrique un comportement non-acceptable comptablement (D2 invented).
Pourquoi B est faux — Maximo standard RBA n'a pas de mode offline avec sync différé. La fonctionnalité offline existe dans Maximo Mobile (autre produit), pas dans la RBA core. Confondre RBA et Maximo Mobile traduit une confusion produits IBM (D2 invented dans le contexte RBA).
Pourquoi D est faux — RBA et Inventory Usage écrivent les MÊMES MATUSETRANS rows. Aucun champ ajouté, aucune sémantique différente. C'est précisément la valeur ajoutée des RBAs : simplicity côté UI, identity côté data. Suggérer des MATUSETRANS différents fabrique une divergence inexistante (D2 invented).
| Aspect | Inventory Usage app | Issues and Transfers RBA |
|---|---|---|
| UI | Desktop, full features | Mobile-friendly, simplified |
| Cible utilisateur | Power user, planner | Storekeeper, technician |
| Barcode scan | Disponible mais pas optimisé | Optimisé, primary input |
| Backend | Identique | Identique (même services) |
| MATUSETRANS | Identique | Identique |
| Time-to-action | ~60-120s | ~20-40s |
- RBA = simplified UI + barcode scan
- Backend identique à Inventory Usage
- Productivity gain ~70% terrain
- Pas offline (Maximo Mobile pour ça)
- [EOTRAG Query 12] Picking Staging Issue / RBA workflow — IBM Maximo Manage 9
- master-map.pdf p.873 — Issues and Transfers RBA
- IBM Maximo Application Suite (MAS) Manage Documentation — RBA work centers
Correct :A
Pourquoi cette question existe — STU 4.1 inclut « Issue an Item to a Work Order, Location or Asset ». IBM teste la connaissance des 4 cibles d'issue : WO, Location, Asset, GL Account direct. La GL direct est la moins connue et la plus piégeuse.
Le contexte théorique d'abord — un issue d'inventaire doit toujours imputer le coût quelque part — c'est le principe comptable de la double-entrée. Les cibles habituelles sont WO (l'issue est tracée sur un work order pour calculer le maintenance cost de l'asset), Location ou Asset (consommation à un emplacement opérationnel sans WO, comme le filling régulier de lubrifiant sur une chaîne de production), ou directement un GL Account (consommation administrative ou départementale sans aucun lien avec un asset spécifique). Cette flexibilité permet de coller aux différentes réalités opérationnelles [EOTRAG Query 14].
Ce que Maximo en fait — version opérationnelle — Inventory Usage line offre 4 sets de fields exclusifs : (1) WONUM (issue to WO) ; (2) LOCATION (issue to Location) ; (3) ASSETNUM (issue to Asset) ; (4) GL_DEBIT_ACCOUNT direct (sans aucun des trois autres). Pour le cas description, le storekeeper laisse WONUM/LOCATION/ASSETNUM vides et saisit directement le GL Debit Account (ex : compte 5410-MAINT-DEPT-CONSUMABLES). Maximo écrit MATUSETRANS row avec GL_DEBIT_ACCOUNT et GL voucher : Dr GL_Account / Cr Inventory. Master-map.pdf p.876 Issue To Target options.
Exemple chiffré — issue 5 unités lubrifiant LUB-X à 10 $/unit pour fixed station (no WO, no asset). Storekeeper saisit GL_DEBIT_ACCOUNT = 5410-100-MAINT-CONSUMABLES. MATUSETRANS row : qty=5, cost=50, GL_DEBIT=5410-100-MAINT-CONSUMABLES, GL_CREDIT=Inventory. P&L : compte 5410 reçoit 50 $ d'expense ; balance sheet Inventory baisse de 50 $. Aucune trace sur WO ou asset — c'est volontaire pour ce cas.
Analogie quotidienne — comme acheter du papier toilette pour la maison. Ce n'est pas pour réparer une voiture (WO), pas pour un appareil spécifique (asset), pas pour un endroit unique (location). C'est un consommable général de la maison. En comptabilité personnelle, vous le notez dans « dépenses ménage » (équivalent GL Account direct).
Pourquoi B est faux — créer une fake WO juste pour issuer pollue les WO actuals, fausse les KPIs maintenance cost, et mélange un faux WO avec les vrais. Procédure plausible-but-wrong vue dans des sites mal configurés ; la bonne procédure est GL direct issue (D10 procedure-plausible).
Pourquoi C est faux — il est techniquement faux que tout issue requiert un WO ou asset. GL Account direct est explicitement supporté pour les cas comme description. Cette option fabrique une contrainte qui n'existe pas (D7 non-existent).
Pourquoi D est faux — Adjust Current Balance n'est pas un issue ; c'est un ajustement de stock sans imputation à un consommateur. Cela cacherait l'usage légitime sous un ajustement, ce qui violerait l'audit (où sont passés les 5 unités ? Loss ? Damage ? FOUND ?). Mauvaise app pour ce cas (D6 wrong-app).
4 Issue To targets dans Maximo
- Work Order (WONUM) : maintenance work, MTBF/MTTR tracking
- Location (LOCATION) : fixed asset operational consumption
- Asset (ASSETNUM) : asset-specific tracking sans WO formel
- GL Account direct : department consumable, no asset link
Cost flow :
- WO/Asset/Location : Dr WOACTUAL ou Asset cost / Cr Inventory
- GL direct : Dr GL_DEBIT_ACCOUNT / Cr Inventory
- 4 Issue To targets : WO, Location, Asset, GL direct
- GL direct = consommable département sans asset
- JAMAIS fake WO ; JAMAIS Adjust Balance
- MATUSETRANS porte le target sélectionné
- [EOTRAG Query 14] Maximo Inventory Transaction Tables — IBM Maximo Manage 9
- master-map.pdf p.876 — Issue To Target options
- IBM Maximo Manage 9 — Inventory Usage Issue To fields
Item Returns

📋 Objectifs IBM
- Comment retourner des items
- Comment retourner un rotating item
- Comment réintégrer un found item dans Inventory via Inventory Usage
💡 Points clés
- Return = transaction inverse de l'issue. Le matériel revient au storeroom ; le coût se retire du WO/asset/GL ; l'inventory balance augmente. Géré dans Inventory Usage application avec Document Type = RETURN ou en ajoutant une row de type Return dans un usage record.
- Return preserve l'original cost — quand un item est retourné, son cost reverts au prix auquel il avait été émis (pas l'AVGCOST courant, qui peut avoir changé entre temps). Maintient la symétrie comptable issue/return.
- Return rotating asset (SAM Q7) : OBLIGATOIRE via Inventory Usage avec Return type row + ITEMNUM + ASSETNUM. C'est le seul chemin qui restaure full value (cost + audit + GL). Asset Move, Adjust Balance, ou new asset record ne suffisent pas.
- Return rotating workflow : Inventory Usage > New Inventory Usage > Document Type = RETURN > ajouter ligne avec ITEM (rotating) + ASSETNUM + qty=1 > status COMPLETE → MATUSETRANS row ISSUETYPE=RETURN + asset back in STORES.
- Return condition-enabled item : sélectionner la condition au retour. Si la pièce a été dégradée pendant l'usage, retourner sous condition USED même si elle a été émise NEW. Cost rate adjusted accordingly.
- Return lotted item : sélectionner le lot d'origine pour réintégrer correctement l'expiration tracking.
- Found item via Inventory Usage : si une pièce était précédemment émise (cost transferred to WO) et est physiquement retrouvée, on peut la retourner via Inventory Usage Return — elle réintègre le storeroom à son original issue cost. Pour les pièces JAMAIS dans le système (no historical issue), utiliser Adjust Current Balance + reason FOUND (vu en lesson 3-2).
- GL postings au return : Dr Inventory / Cr WO Cost (ou GL Debit account utilisé à l'issue). Annule l'écriture initiale.
- Partial return : possible. Issue de 10, retour de 3 ; 7 restent imputés au WO. MATUSETRANS row Return porte qty=3.
- Retour via Issues and Transfers RBA : workflow simplifié pour storekeeper. Scan WO ou item → option Return → confirmer.
- Return constraints : item doit avoir été émis (avoir un MATUSETRANS row ISSUE). Maximo lie le Return au issue source pour l'audit. Sans issue source, pas de return — c'est un Adjust Current Balance + reason FOUND.
- Return multi-bin : si l'issue était split sur plusieurs bins, le return peut consolider en une seule bin (default storeroom bin) ou splitter à nouveau selon préférence.
- Audit trail return : chaque return génère MATUSETRANS row avec ISSUETYPE=RETURN, lié au record original par ISSUEORIGREF. Permet de retrouver le issue source qui motive le return.
- Cost reversal symmetry : si issue était à 12 $/unit et que l'AVGCOST est passé à 14 $, le return reste à 12 $/unit (preserve original cost). Sinon, on créerait un gain artificiel à chaque issue/return cycle.
flowchart TD TRIGGER["L'opérateur ouvre l'application
Inventory Usage
(ou la Issues and Transfers RBA)"]:::start WHICH{"Quel scénario de return ?
(STU §4.2)"}:::decision N1["Branche 1 — Return Item
Item non-rotating
précédemment issué"]:::action N2["Ajouter une ligne Return type
référencer l'issue originale
saisir la qty à retourner"]:::action N3["balance += qty
actuals WO -= qty
INVTRANS type=RETURN"]:::ok R1["Branche 2 — Return Rotating Item
(SAM Q7 — réponse D)"]:::action R2["Ajouter une ligne Return type
préciser l'ASSETNUM
à la pleine valeur (couche NEW cost)"]:::action R3["Ligne ASSETMOVE
+ balance += 1
+ INVTRANS type=RETURN
asset de retour au storeroom"]:::ok F1["Branche 3 — Réintégrer un Found Item
précédemment perdu / écrit off"]:::action F2["Ajouter une ligne Return type
SANS référence d'issue
note audit = found"]:::action F3["balance += qty
INVTRANS type=RETURN
(reason code = FOUND)"]:::ok END["Statut Inventory Usage
= COMPLETE
(chaîne audit MATUSETRANS)"]:::endNode TRIGGER --> WHICH WHICH -- "Return d'item standard" --> N1 --> N2 --> N3 --> END WHICH -- "Return de rotating item" --> R1 --> R2 --> R3 --> END WHICH -- "Réintégration d'un found item" --> F1 --> F2 --> F3 --> END classDef start fill:#3B82F6,stroke:#1E40AF,color:#FFFFFF,font-weight:600; classDef decision fill:#F59E0B,stroke:#B45309,color:#FFFFFF; classDef action fill:#FFFFFF,stroke:#94A3B8,color:#0F172A; classDef ok fill:#D1FAE5,stroke:#178A66,color:#0F172A; classDef endNode fill:#1D9E75,stroke:#178A66,color:#FFFFFF,font-weight:600;
⚠️ Piège IBM
Return rotating asset — quel chemin choisir ? SAM Q7 teste cette question précisément. Il y a 4 options apparentes ; une seule est correcte.
- Inventory Usage + Return type + asset number ← LA SEULE BONNE RÉPONSE. Restaure full value, audit complet, GL symétrique.
- Asset Move/Modify : déplace l'asset mais sans le retour comptable (pas de GL voucher Cost Reversal). L'asset est à son emplacement mais le coût reste imputé au WO.
- Adjust Balance Inventory : modifie un nombre, ne traite pas le serial. Brise la traçabilité asset.
- New asset record : crée un doublon, perd l'historique de l'asset original.
🎯 Carte mémoire
Q. Un technicien finit un WO et veut retourner 2 unités d'un consumable item non utilisé. Comment procède-t-il ?
Afficher la réponse
Inventory Usage application > sélectionner le Inventory Usage record du WO original (ou en créer un new avec Document Type=ISSUE et ajouter une row Return), > ajouter une row avec ISSUETYPE=RETURN + ITEM + qty=2 + WO source > status COMPLETE. MATUSETRANS row porte ISSUETYPE=RETURN, qty=−2 (ou positive selon vue), cost = original issue cost. Storeroom balance augmente de 2 ; WO actual cost baisse du même montant. GL voucher : Dr Inventory / Cr WO Cost.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :D
Pourquoi cette question existe — c'est SAM verbatim Q7, publié par IBM. Le piège central est que les 4 options sonnent toutes plausibles à un FA junior. Seule l'option D restaure le full value (cost original + GL symétrique + audit) ; les 3 autres laissent des trous comptables ou d'audit.
Le contexte théorique d'abord — pour un rotating asset, le « return at full value » signifie : (1) l'asset retrouve son emplacement storeroom (status STORES) ; (2) son INVCOST par-asset est restauré dans la table Inventory ; (3) le coût qui avait été imputé au WO est annulé (GL voucher Cost Reversal) ; (4) un audit row dans MATUSETRANS lie le return au issue original. Aucune autre procédure ne couvre ces 4 dimensions ensemble. ISO 14224 (collecting reliability data) et SOX § 404 (internal controls) imposent ce niveau de symétrie [EOTRAG Query 6].
Ce que Maximo en fait — version opérationnelle — Inventory Usage application > New > Document Type = ISSUE (le record peut contenir issue ET return rows) ou simplement ouvrir le record original. Ajouter une row : ISSUETYPE = RETURN + ITEM = MOT-5HP (rotating) + ASSETNUM = SN-X (le serial à retourner) + qty = 1. Le storekeeper sélectionne le serial spécifique parmi les assets de cet item actuellement out (status WO ou ISSUED). Maximo récupère l'INVCOST de SN-X (qui inclut purchase + cumul repair) et l'utilise comme RETURNCOST. Status COMPLETE → MATUSETRANS row ISSUETYPE=RETURN, qty=1, ASSETNUM=SN-X, cost=INVCOST. GL : Dr Inventory / Cr WO Cost. SN-X status passe à STORES. Master-map.pdf p.880 Return Rotating Item.
Exemple chiffré — SN-X cost actuel 6 200 $ (5 000 $ purchase + 1 200 $ repair). Issue à WO-101 le mois dernier à 6 200 $. Now retour : Inventory Usage row Return, ASSETNUM=SN-X, qty=1, cost auto-pulled à 6 200 $. MATUSETRANS porte cost=6 200 $. GL : Dr Inventory 6 200 / Cr WO-101 Cost 6 200. WO actual cost baisse de 6 200 $. Storeroom INVCOST de SN-X = 6 200 $ (full value preserved).
Analogie quotidienne — comme retourner un livre à la bibliothèque : vous ne créez pas un nouveau livre identique ; vous ne modifiez pas le « current balance » des livres ; vous ne déplacez pas le livre vers une étagère par un mouvement physique non-tracé. Vous SCANNEZ le livre au desk (la bibliothécaire enregistre le retour avec son ID), votre prêt se ferme (audit), et le livre retrouve sa place avec son histoire (toutes les annotations précédentes intactes).
Pourquoi A est faux — créer un nouveau asset record introduit un doublon SN-X' alors que SN-X existe déjà. L'audit montre 2 assets pour 1 unité physique. L'historique de SN-X (purchase, repairs, prior issues) est perdu (le nouveau SN-X' part fresh). Les rapports MTBF par asset deviennent erronés. Cette procédure crée un référentiel pollué (D7 non-existent comme bonne pratique — possible techniquement mais inacceptable opérationnellement).
Pourquoi B est faux — Update Current Balance dans Inventory app modifie un nombre numérique. Pour un rotating, la balance n'est PAS un nombre mais un set de serials. De plus, cette action n'écrit aucune GL voucher Cost Reversal — le coût reste imputé au WO. L'audit comptable sera déséquilibré (asset présent mais expense non annulée). C'est l'application d'une procédure non-rotating à un rotating (D6 wrong-app).
Pourquoi C est faux — Asset Move/Modify dans Assets app déplace l'asset à un nouveau location (storeroom) MAIS sans transaction d'inventaire ni GL voucher. Le serial est physiquement « rangé » mais le coût reste sur le WO ; INVCOST n'est pas mis à jour ; aucun MATUSETRANS row n'est généré. Audit trail incomplet. C'est partial-truth : déplace OUI mais pas avec full value et pas via le canal officiel return (D4 partial-truth).
Return rotating — comparaison des 4 chemins
| Chemin | Asset moved | GL reversal | Audit | INVCOST |
|---|---|---|---|---|
| Inv Usage Return + ASSETNUM | OUI | OUI | OUI | OUI |
| New asset record | NON (doublon) | NON | BRISÉ | NEW only |
| Update Current Balance | NON | NON | BRISÉ | NON |
| Asset Move/Modify | OUI | NON | PARTIEL | NON |
- Return rotating = Inventory Usage Return type + ASSETNUM
- Préserve full value (cost cumulé)
- GL voucher Cost Reversal écrit
- SAM Q7 verbatim IBM
- [EOTRAG Query 6] Rotating Items / Return-to-store of a rotating asset — IBM Maximo Manage 9
- master-map.pdf p.880 — Return Rotating Item via Inventory Usage
- SAM C1000-208 Q7 — IBM published sample question
Correct :C
Pourquoi cette question existe — la préservation du cost original au return est un principe comptable subtil mais essentiel. IBM teste si le candidat comprend que le return doit symétriquement annuler l'issue, pas créer un mouvement comptable artificiel.
Le contexte théorique d'abord — la symétrie issue/return en comptabilité d'inventaire est un principe fondamental : un return est l'annulation comptable d'un issue passé. Si l'issue avait imputé 50 $ au WO, le return doit re-créditer exactement 50 $ — pas 70 $ (gain artificiel pour le WO) ni 30 $ (perte artificielle). Sinon, on pourrait gérer un cycle infini d'issues/returns pour réaliser des gains ou pertes synthétiques. Cette règle est universelle dans tous les systèmes ERP/EAM (SAP, Oracle, Infor) et alignée avec IFRS/GAAP. Maximo conserve l'original cost dans l'INVUSELINE pour permettre cette symétrie [EOTRAG Query 4].
Ce que Maximo en fait — version opérationnelle — quand un item est émis, MATUSETRANS row ISSUE est écrit avec ISSUEUNITCOST = AVGCOST_at_issue_date. Cette valeur est gravée. Quand le return est effectué (via Inventory Usage Return type row pointing au original issue), Maximo lit l'ISSUEUNITCOST de la row ISSUE source et l'utilise comme RETURNCOST sur la row RETURN. Aucun recalcul à la valeur AVGCOST courante. Master-map.pdf p.882 Return Cost Preservation.
Exemple chiffré — issue date Jan 15 : 10 unités à AVGCOST_then = 10 $/unit. WO-201 reçoit 100 $ d'expense. AVGCOST monte progressivement à 14 $ avec les receipts d'avril. Return date April 20 : 5 unités. RETURNCOST = ISSUEUNITCOST original = 10 $. WO-201 cost reverse = 5 × 10 = 50 $ (pas 5 × 14 = 70 $). Inventory balance regagne 5 unités à valeur 50 $, intégrées dans le INVCOST courant (qui mixe les couches anciennes et récentes selon cost type). GL : Dr Inventory 50 / Cr WO Cost 50.
Analogie quotidienne — vous achetez un T-shirt 30 $ chez Zara en mars. En mai, le prix a monté à 35 $. Vous retournez le T-shirt avec votre reçu : Zara vous rembourse 30 $ (le prix payé), pas 35 $ (le prix actuel). Sinon le commerce serait truqué. Maximo fait pareil : le return rembourse au prix d'achat initial.
Pourquoi A est faux — utiliser AVGCOST courant ($14) sur le return créerait un gain artificiel pour le WO ($14−$10 = $4 par unit × 5 = $20 gain). Le WO « gagnerait » de l'argent juste en retournant des items dont le marché a monté. Comptablement absurde et non symmetrical (D9 near-synonym, AVGCOST existe mais mauvais usage).
Pourquoi B est faux — moyenne de issue cost et current AVGCOST ($12) est une mécanique fabriquée. Aucun système ERP n'utilise cette moyenne pour return. Cela ressemble à WAC mais appliqué au mauvais endroit (D2 invented).
Pourquoi D est faux — user-entered cost sur la return line est un override possible dans certaines configurations Maximo (avec security access élevé), mais pas le default behavior. Le standard est cost auto-pulled de l'issue source. Suggérer que c'est l'utilisateur qui saisit reflète une mauvaise compréhension de la symétrie automatique (D7 non-existent comme default).
Cost preservation au return — règle universelle
- RETURNCOST = ISSUEUNITCOST de la row source (gravée)
- Pas recalculé à AVGCOST courant
- Symmetrie comptable : annule exactement l'issue
- Évite les gains/pertes synthétiques sur cycles I/R
Cas spéciaux
- FIFO/LIFO : return rentre dans une nouvelle layer à RETURNCOST (pas réintégré dans la layer source si fermée)
- Rotating ASSET : return reprend l'INVCOST par-asset (qui inclut repairs)
- STANDARD cost : return à standard, pas à actual
- RETURNCOST = ISSUEUNITCOST original
- Préservation = symmetrie comptable
- Pas d'AVGCOST courant pour return
- Évite gains/pertes synthétiques
- [EOTRAG Query 4] Cost Methods / Returns preserve original cost — Infor EAM Guide (transposable Maximo)
- master-map.pdf p.882 — Return Cost Preservation
- IBM Maximo Manage 9 — Inventory Usage Return type rows
Correct :A
Pourquoi cette question existe — IBM teste si le candidat comprend que les retours partiels sont supportés natively et constituent le cas le plus fréquent en réalité (rares sont les WOs où 100% des items sont consommés exactement comme prévu).
Le contexte théorique d'abord — la philosophie de gestion d'inventaire dans Maximo accepte que les estimations préalables (qty réservée, qty issued) ne soient pas exactes. Le système supporte les ajustements en aval : returns partiels, transferts retours, et splits. La granularité par row dans MATUSETRANS permet de tracer chaque mouvement (issue +10, return +4) et de calculer les actuals (consumed = issue − return = 6). Cette flexibilité reflète la réalité opérationnelle : un technicien découvre sur le terrain que la pièce était plus simple à remplacer ou qu'elle a été surcommandée [EOTRAG Query 14].
Ce que Maximo en fait — version opérationnelle — Inventory Usage app > ouvrir le record original (ou nouveau) > ajouter une row avec ISSUETYPE = RETURN + ITEM + qty=4 + WO source. Status COMPLETE → MATUSETRANS row : qty=4, ISSUETYPE=RETURN, lié à la row ISSUE source via ISSUEORIGREF. Le WO actual = sum(MATUSETRANS) = 10 issued − 4 returned = 6 consumed. Le storeroom récupère 4 unités à RETURNCOST = ISSUEUNITCOST original. Master-map.pdf p.884 Partial Return.
Exemple chiffré — issue Jan 15 : 10 unités × 12 $ = 120 $ → WO-301 actual cost +120. Return April 5 : 4 unités × 12 $ (cost preserved) = 48 $ → WO-301 actual cost +120 − 48 = 72 $. Storeroom balance regagne 4 unités à 12 $ chaque (intégrées dans cost layer courante selon cost type). Le rapport WO Material Actuals montre 6 unités consumed × 12 $ = 72 $ — cohérent avec ce que le technicien a réellement utilisé.
Analogie quotidienne — vous achetez 10 ampoules pour rénover votre cuisine. Vous en utilisez 6, vous remboursez les 4 restantes au magasin. Vous ne refaites pas l'achat à 6 ; vous returnez juste les 4 surplus avec votre reçu. La compta du magasin et la vôtre sont alignées : vous avez payé 6 net (10 achetées − 4 retournées).
Pourquoi B est faux — annuler tout l'issue puis re-issuer 6 est une procédure plausible-but-wrong (deux mouvements pour faire ce qu'un partial return fait en un). Pollue l'audit (issue −10 + new issue +6 vs un seul partial return +4). Plus de transactions, plus de complexité, même résultat comptable mais audit illisible (D10 procedure-plausible).
Pourquoi C est faux — adjuster manuellement les WO Material Actuals bypass les MATUSETRANS et les inventory balance updates. Le WO actuals serait 6 mais le storeroom balance ne reflète pas le retour des 4 unités (elles seraient « perdues » comptablement). Procédure plausible-but-wrong qui crée un déséquilibre (D10 procedure-plausible).
Pourquoi D est faux — Maximo permet les returns sur WOs même en status COMP (complete). Tant que le WO n'est pas en status CLOSE, les returns sont autorisés. Cette option fabrique une contrainte qui n'existe pas (D7 non-existent).
Partial return mechanics
- Issue MATUSETRANS row : ITEM, qty=10, cost=120
- Return MATUSETRANS row : ITEM, qty=4, cost=48, ISSUETYPE=RETURN
- Net consumed = 10 − 4 = 6 ; cost net = 120 − 48 = 72
- WO actual = sum(MATUSETRANS) net
- Storeroom balance regagne 4 unités à RETURNCOST
Quand return possible :
- WO status WAPPR, APPR, INPRG, COMP : OUI
- WO status CLOSE : NON (verrouillé)
- Issue source row deleted : NON (lien brisé)
- Partial return = Inventory Usage Return type, qty partielle
- WO actual = issue qty − return qty
- RETURNCOST preserved (original issue cost)
- Partial returns supportés sur WO status < CLOSE
- [EOTRAG Query 14] Maximo Inventory Transaction Tables / MATUSETRANS Return rows — IBM Maximo Manage 9
- master-map.pdf p.884 — Partial Return mechanics
- IBM Maximo Manage 9 — Inventory Usage Return type
Correct :B
Pourquoi cette question existe — STU 4.2 inclut « add a found item back to Inventory through Inventory Usage ». IBM teste la subtilité : si l'item a un issue source documenté, le bon chemin est Inventory Usage Return (pour préserver la symétrie comptable), pas Adjust Current Balance.
Le contexte théorique d'abord — la distinction « item retrouvé avec issue traçable » vs « item retrouvé sans issue préalable » détermine le bon chemin Maximo. Si l'item existait dans le système (a été émis sur un WO connu), le retour doit pointer vers ce WO pour annuler la charge. Sinon, le coût reste imputé au WO et le storeroom regagne juste un nombre — créant un déséquilibre. Pour les items sans historique d'issue (qui n'ont jamais été dans le système), Adjust Current Balance + reason FOUND est correct car il n'y a pas d'issue à annuler. STU 4.2 cible précisément le premier cas (« through Inventory Usage »), impliquant que les items retrouvés avec historique d'issue sont retournés par cette voie [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — investigation : storekeeper trouve les 8 unités, identifie WO-512 comme source via étiquette/checking issue history. Si WO-512 est CLOSE, demande de réouverture (action More Actions > Reopen). Une fois en COMP, ouvrir Inventory Usage app > New > Return type row + ITEM + qty=8 + WONUM=512. Status COMPLETE → MATUSETRANS Return row + GL Cost Reversal. WO-512 actual cost baisse de l'équivalent (8 × ISSUEUNITCOST original). Re-close WO-512. Master-map.pdf p.886 Found Items via Inventory Usage.
Exemple chiffré — WO-512 closed avec actual material cost = $1 200 (incluait 8 × $20 pour ces items + autres). Reopen WO-512, status passes to COMP. Return 8 units : MATUSETRANS Return qty=8, cost=$160 (8×20 preserved). WO-512 actual baisse à 1 200 − 160 = $1 040. Storeroom balance regagne 8 × $20 = $160 of inventory value. Re-close WO-512. Audit : KPI maintenance cost de l'asset associé est ajusté ; les rapports passe-trough sont cohérents.
Analogie quotidienne — vous trouvez un sac de courses oublié 6 semaines après votre retour de vacances. Au lieu de le jeter ou de réagir comme si c'était un nouveau sac, vous identifiez quelle dépense de carte de crédit y correspondait, vous vérifiez si elle est encore disputable, et vous demandez le remboursement (ou réintégration). Sinon, vous payez deux fois (pour les courses jamais consommées + pour leur remplacement).
Pourquoi A est faux — Adjust Current Balance + FOUND ajoute 8 unités au stock mais ne touche pas au WO-512 : le WO continue d'avoir 8 × $20 = $160 sur ses actuals pour rien. Le maintenance cost de l'asset est gonflé. C'est partial-truth : vrai pour les items « jamais émis », faux pour les items avec issue source connue (D4 partial-truth).
Pourquoi C est faux — discard les items est inacceptable : ce sont des stocks valides à $20 × 8 = $160. Cette option fabrique une procédure d'abandon qui n'existe pas en gestion sérieuse (D2 invented).
Pourquoi D est faux — fake PO à coût 0 est une procédure plausible-but-wrong : crée une fake transaction commerciale (vendor non payé, AP impacté), pollue les vendor KPIs (lead time, on-time delivery), et n'annule pas le WO-512 cost. Vue dans des sites mal gérés (D10 procedure-plausible).
Found item — décision tree
- Item a-t-il un issue source identifiable ?
- Si OUI : Inventory Usage Return + WO source (réouvrir WO si closed)
- Si NON : Adjust Current Balance + reason FOUND
Pourquoi privilégier Return :
- Annule le coût injustement imputé au WO
- Préserve la symétrie comptable issue/return
- Maintenance cost de l'asset reste juste
- Audit trail complet (issue → return → balance)
- Found item avec issue source = Inventory Usage Return
- Found item sans issue source = Adjust Current Balance + FOUND
- Si WO closed : reopen → return → reclose
- STU 4.2 « through Inventory Usage »
- [EOTRAG Query 12] Inventory Usage workflows — IBM Maximo Manage 9
- master-map.pdf p.886 — Found Items via Inventory Usage
- STU 4.2 — Add a found item back to Inventory through Inventory Usage
Correct :C
Pourquoi cette question existe — IBM teste la combinaison return + condition codes. Quand un item est dégradé pendant son usage, il revient sous une autre condition que celle d'issue, avec un coût ajusté en conséquence. Cette mécanique est crucial pour les sites refurbissant des composants.
Le contexte théorique d'abord — un item condition-enabled maintient des balances séparées par condition. Au return, l'item physique réintègre la balance de la condition QU'IL A AU MOMENT DU RETOUR, pas celle qu'il avait à l'issue. Si la pièce s'est dégradée (NEW → REFURB), elle réintègre REFURB. Le cost reflète cette dégradation : NEW_cost × condition_rate du retour. Cela permet de valoriser correctement le stock résiduel : un REFURB ne doit pas être valorisé comme un NEW. C'est aligné avec IFRS IAS 2 § 9 (lower of cost and net realizable value) [EOTRAG Query 9].
Ce que Maximo en fait — version opérationnelle — Inventory Usage Return row offre un dropdown CONDITIONCODE. Le storekeeper sélectionne la condition courante (REFURB) au lieu de la condition d'issue (NEW). Maximo : (1) calcule RETURNCOST = NEW_AVGCOST × REFURB_rate ; (2) inserts MATUSETRANS Return row avec qty + CONDITIONCODE=REFURB + cost ajusté ; (3) le storeroom balance REFURB augmente de 1 ; balance NEW reste inchangée (car la pièce n'est plus NEW). GL : Dr Inventory (REFURB sub-account) / Cr WO Cost. Master-map.pdf p.888 Return Condition-Enabled Items.
Exemple chiffré — issue NEW : 1 × $200 → WO-401 actual +$200, balance NEW −1. Pendant l'usage, dégradation. Return REFURB : RETURNCOST = 200 × 0.70 = $140. WO-401 actual baisse de $140 (résidu net = $200 issued − $140 returned = $60 consumed cost). Storeroom : balance REFURB +1 (à $140), balance NEW unchanged. Le WO « consomme » l'équivalent de la dégradation NEW→REFURB ($60 = $200 NEW − $140 REFURB residual value).
Analogie quotidienne — vous louez une voiture neuve. Vous la rapportez avec une rayure mineure et 5 000 km de plus. La compagnie ne la facture pas comme « nouvelle voiture » mais comme « voiture occasion récente » avec valeur dépréciée. La différence (dépréciation) reste à votre charge. Maximo conditions reflètent cette même mécanique pour les pièces.
Pourquoi A est faux — return as NEW à $200 ignore la dégradation réelle. La pièce serait re-stockée comme neuve mais elle ne l'est plus. Au prochain issue, elle sortirait à $200 (NEW) alors qu'elle vaut $140 — créant un cost gonflé pour le WO suivant. C'est partial-truth (cost preservation = vrai pour items non-dégradés) (D4 partial-truth).
Pourquoi B est faux — Maximo permet le return sous toute condition disponible. Scrapper une pièce REFURB qui est encore utilisable (juste à $140 au lieu de $200) est un gaspillage. Cette option fabrique une contrainte qui n'existe pas (D7 non-existent).
Pourquoi D est faux — moyenne des conditions est une fonctionnalité fabriquée. Maximo applique exactement le rate de la condition sélectionnée, pas une moyenne (D2 invented).
Return condition mismatch — règles
- Condition au return = condition courante (peut diverger de issue)
- RETURNCOST = NEW_AVGCOST × condition_rate du retour
- Balance impactée = celle de la condition au retour
- WO actual = différence (cost issued − cost returned)
- WO « consomme » la dépréciation
Cas pratiques
- NEW → REFURB : usage normal, retourné dégradé
- REFURB → USED : usage intensif
- NEW → NEW : pas utilisé, retour à pleine valeur
- USED → SCRAP (si condition existe) : end-of-life
- Return condition = condition courante (au moment retour)
- Cost = NEW × condition_rate
- WO consomme la dépréciation (NEW − REFURB)
- Balance ventilée par condition
- [EOTRAG Query 9] Condition-Enabled Items — IBM Maximo Manage 9
- master-map.pdf p.888 — Return Condition-Enabled Items
- IFRS IAS 2 § 9 — Valeur la plus faible entre le coût et la valeur nette de réalisation
Correct :A
Pourquoi cette question existe — comprendre l'écriture comptable d'un return est essentiel pour les FAs Maximo qui interfacent avec finance. La symétrie issue/return doit être maîtrisée.
Le contexte théorique d'abord — pour comprendre le GL de return, il faut d'abord rappeler le GL d'issue : Dr WO Cost / Cr Inventory (l'issue débite le WO et crédite l'inventaire car asset baisse). Le return est l'inverse : Dr Inventory (asset remonte) / Cr WO Cost (l'expense du WO est annulée). Cette polarité préserve la double-entrée et l'égalité débits = crédits. Aucune écriture supplémentaire (pas de Cash, pas de Adjustment) car aucune transaction commerciale externe n'est impliquée [EOTRAG Query 14].
Ce que Maximo en fait — version opérationnelle — au status COMPLETE de l'Inventory Usage Return, Maximo : (1) écrit MATUSETRANS row avec ISSUETYPE=RETURN, qty, cost, GL_DEBIT_ACCOUNT=Inventory account du storeroom, GL_CREDIT_ACCOUNT=WO Cost account ; (2) génère les vouchers GL via le batch ou immédiatement selon configuration. Master-map.pdf p.890 Return GL Postings.
Exemple chiffré — return 5 × $20 = $100. MATUSETRANS row : qty=5, cost=$100, GL_DEBIT=Inventory, GL_CREDIT=WO-405-Cost. Vouchers :
Dr Inventory $100
Cr WO Cost $100
Effets : Inventory account (asset) +$100, WO actuals materiel −$100. Net consumed sur le WO = ce qui a été issued − ce qui a été returned.
Analogie quotidienne — vous remboursez 100 $ que vous aviez emprunté à un ami. Dans votre journal personnel : Dr « Cash » 100 (vous remettez l'argent) / Cr « Loan from Friend » 100 (la dette baisse). Le return Maximo fait pareil : asset Inventory remonte / expense WO baisse, par contrepartie symétrique.
Pourquoi B est faux — c'est l'écriture d'un ISSUE (Dr WO / Cr Inventory), polarité opposée du RETURN. Le candidat qui répond ceci confond issue et return — l'erreur la plus classique. C'est exactement l'inverse de ce qu'on veut (D3 inverse).
Pourquoi C est faux — Dr Inventory / Cr Inventory Adjustment Gain est l'écriture d'un Adjust Current Balance + FOUND, où on découvre du stock sans WO source. Pour un return avec WO source, on doit créditer le WO (annuler son expense), pas Inventory Adjustment Gain (qui serait un gain non lié à un WO). Mauvaise app comptable pour le contexte (D6 wrong-app — Adjustment Gain existe mais pour autre cas).
Pourquoi D est faux — Cash n'a aucun rôle dans un return d'inventory : aucun argent ne change de mains avec le vendor (le return est interne). Confondre return inventory avec un remboursement vendor (Receipt Void avec Cash) reflète une mauvaise compréhension des transactions Maximo (D6 wrong-app).
| Transaction | Dr | Cr |
|---|---|---|
| Issue → WO | WO Cost | Inventory |
| Return ← WO | Inventory | WO Cost |
| Receipt PO | Inventory | AP |
| Void Receipt | AP | Inventory |
| Cycle Count + variance | Inventory ou Variance | Inventory ou Adj Gain |
| Found item (no issue source) | Inventory | Inventory Adjustment Gain |
- Return GL : Dr Inventory / Cr WO Cost
- Symétrie inverse de l'issue
- Pas d'Adjustment Gain (pas de FOUND)
- Pas de Cash (transaction interne)
- [EOTRAG Query 14] MATUSETRANS Return GL postings — IBM Maximo Manage 9
- master-map.pdf p.890 — Return GL Postings
- IBM Maximo Manage 9 — GL configuration Inventory accounts
Correct :B
Pourquoi cette question existe — comprendre les limites du Return est essentiel pour utiliser le bon outil. Sans issue source, le Return n'a pas de cible de reversal et devient un Adjust déguisé.
Le contexte théorique d'abord — un Return Inventory Usage est conceptuellement « l'inverse d'un issue ». Sans issue source, il n'y a rien à inverser ; le mouvement est unilatéral (asset apparaît dans le stock sans contrepartie). Comptablement, c'est un Adjust : Dr Inventory / Cr Inventory Adjustment Gain. Maximo refuse les Returns sans issue source pour préserver la cohérence : sinon, on aurait des Returns « orphelins » qui ne réversent rien et créent confusion dans les rapports MATUSETRANS [EOTRAG Query 14].
Ce que Maximo en fait — version opérationnelle — à la création d'une Return row dans Inventory Usage, le system requiert le pointage à un issue source via WO/asset/location/GL. Si aucun n'est sélectionnable (pas d'historique d'issue), Maximo bloque la transaction. La bonne procédure pour ce cas est Adjust Current Balance + reason FOUND. Master-map.pdf p.892 Return Source Requirement.
Exemple chiffré — storekeeper trouve 8 unités sans issue source. Tentative Inventory Usage Return : Maximo échoue avec erreur « Issue source not found ». Bonne procédure : Inventory app > sélectionner item > More Actions > Adjust Current Balance > +8 unités + reason FOUND + GL accounts. MATUSETRANS row CURBALADJ avec REASONCODE=FOUND. GL : Dr Inventory $160 (8×20 AVGCOST) / Cr Inventory Adjustment Gain $160. Stock balance regagne 8 unités, gain comptable de $160.
Analogie quotidienne — vous trouvez un objet dans la rue sans identification du propriétaire. Vous ne pouvez pas le rendre à quelqu'un en particulier (no source). Vous le déclarez comme objet trouvé aux autorités — c'est un nouveau record indépendant, pas le retour à un emprunt. Maximo : Adjust Current Balance + FOUND est l'équivalent.
Pourquoi A est faux — Maximo ne crée jamais de transactions synthétiques retroactives. Cela violerait l'audit trail (transactions inventées sans real-world event). Cette option fabrique un comportement magique inexistant (D2 invented).
Pourquoi C est faux — il n'existe pas de « orphan return » dans Maximo. Toute Return doit pointer à un issue source. Le system bloque les rows sans cible. Cette option fabrique une fonctionnalité inexistante (D7 non-existent).
Pourquoi D est faux — créer un fake WO juste pour faire la return pollue les WO actuals et fausse les KPIs maintenance cost. Procédure plausible-but-wrong vue dans des sites mal gérés (D10 procedure-plausible).
Return vs Adjust — quand utiliser quoi
| Cas | App + Action | GL |
|---|---|---|
| Item avec issue source | Inventory Usage Return + WO source | Dr Inv / Cr WO Cost |
| Item sans issue source (found) | Inventory Adjust Current Balance + FOUND | Dr Inv / Cr Adj Gain |
| Cycle count variance | Reconcile Balances | Dr/Cr Variance |
| Damage / write-off | Adjust Current Balance + DAMAGE | Dr Variance Loss / Cr Inv |
- Return = nécessite issue source
- Sans source → Adjust Current Balance + FOUND
- JAMAIS fake WO ; JAMAIS orphan return
- Maximo bloque les Returns sans cible
- [EOTRAG Query 14] Maximo Inventory Transaction Tables — IBM Maximo Manage 9
- master-map.pdf p.892 — Return Source Requirement
- IBM Maximo Manage 9 — Inventory Usage Return constraints
Item Transfers

📋 Objectifs IBM
- Transfer d'Item non-rotating entre storerooms (même site / sites différents)
- Transfer de Rotating Item entre storerooms
- Tool Transfer
- Shipment Transfer pour Item / Tool
- Utiliser la Issues and Transfers RBA pour réaliser un Item / Tool Transfer
💡 Points clés
- Transfer = mouvement de stock entre 2 storerooms. Géré dans Inventory Usage app avec Document Type = TRANSFER (même site) ou TRANSFEROUT (cross-site/cross-org via Shipment).
- Transfer même site (intra-site) : direct, instantané. Décrément du storeroom source + incrément du storeroom destination dans la même transaction. Rows MATUSETRANS : 1 OUT (source) + 1 IN (destination). GL inchangé (asset déplacé dans la même Org).
- Transfer inter-site / inter-org : requiert un Shipment. Le source crée un Shipment record (TRANSFEROUT) ; les items sont en transit ; le destination reçoit le Shipment via Shipment Receiving (vu en leçon 4-4). MATUSETRANS au source au départ ; MATRECTRANS au destination à la réception.
- Rotating item transfer : sélection du serial spécifique. À l'arrivée, l'asset garde son ASSETNUM mais sa LOCATION change (nouveau storeroom). INVCOST par-asset transféré.
- Tool transfer : similaire à item transfer mais le tool flag impose track-by-person si l'usage est temporaire. Pour transfert permanent storeroom-to-storeroom, le track person n'est pas obligatoire (le tool change de location, pas de propriétaire opérationnel).
- Shipment record fields : SHIPMENTNUM, FROMSITEID, TOSITEID, FROMSTOREROOM, TOSTOREROOM, SHIPDATE, EXPECTEDDATE, CARRIER. Status workflow : OPEN → SHIPPED → RECEIVED → CLOSED (or VOIDED).
- Coût entre organisations — quand un item transfère entre 2 organisations avec cost types différents, l'Org destination reévalue selon SA méthode (FIFO, LIFO, AVG, STD, ASSET). Variance possible entre coût source et coût destination, postée en Cost Adjustment GL.
- Stock Transfer Order (STO) — pour transferts internes entre storerooms hub-et-rayons avec parent storeroom. Génère un Internal PR qui devient Internal Transfer.
- Issues and Transfers RBA pour transfer : workflow simplifié, scan source storeroom + items + destination storeroom. Plus rapide pour les opérations terrain.
- GL Transfer même-site : aucun voucher GL si même Org (juste changement de compte inventory si compte spécifique au storeroom). Si les comptes Inventory diffèrent par storeroom : Dr Inventory dest / Cr Inventory source.
- Transfer GL cross-org : Org source : Dr Intercompany AR / Cr Inventory. Org destination : Dr Inventory / Cr Intercompany AP. Inter-company elimination en consolidation.
- Lotted item transfer : le LOTNUM voyage avec l'item. Expiration tracking préservé.
- Condition transfer : la condition voyage avec l'item. Un REFURB transferé reste REFURB au destination (sauf si re-classification volontaire).
- Restrictions vendor / commodity : certains storerooms peuvent restreindre les items qu'ils acceptent (par commodity group, par vendor approuvé). Le transfer échoue si l'item n'est pas autorisé au destination.
flowchart TD START["Besoin de transférer
item / tool du
storeroom A → storeroom B"]:::start Q1{"Même SITE ?"}:::decision DIRECT["Direct Transfer
Inventory app →
Transfer Out / Transfer In
Une seule ligne MATRECTRANS
Balance déplacée immédiatement"]:::ok SHIPMENT["Shipment Transfer
(obligatoire cross-site)
1 — Créer un shipment record
2 — Ship out (balance −A)
3 — En transit (Holding)
4 — Réception au destination
5 — Inspection si requise
6 — Balance +B"]:::warn END["Transaction journalisée dans
MATRECTRANS / INVTRANS"]:::endNode START --> Q1 Q1 -- Oui --> DIRECT Q1 -- Non --> SHIPMENT DIRECT --> END SHIPMENT --> END classDef start fill:#3B82F6,stroke:#1E40AF,color:#FFFFFF,font-weight:600; classDef decision fill:#F59E0B,stroke:#B45309,color:#FFFFFF; classDef ok fill:#1D9E75,stroke:#178A66,color:#FFFFFF; classDef warn fill:#EF4444,stroke:#991B1B,color:#FFFFFF; classDef endNode fill:#F1F5F9,stroke:#94A3B8,color:#0F172A;
⚠️ Piège IBM
Same-site transfer ≠ cross-site transfer — la mécanique est radicalement différente. IBM teste régulièrement la distinction.
- Même site, même Org : transfer direct, instantané. Pas de Shipment. Type TRANSFER d'Inventory Usage.
- Sites différents, même Org : Shipment requis. Items en transit avec status. Inventory Usage TRANSFEROUT au source + Shipment Receiving au destination.
- Different organizations : Shipment + GL inter-company. Cost re-évalué au destination.
- Ignorer cette différence = items « perdus » en transit ou GL postings incorrects.
🎯 Carte mémoire
Q. Transfer 50 unités d'un item de Storeroom A (site SITE1) vers Storeroom B (site SITE2). Quelle procédure ?
Afficher la réponse
Cross-site transfer ⇒ Shipment requis. Source : Inventory Usage app > New > Document Type = TRANSFEROUT > ITEM + qty=50 + ToStoreroom=B + ToSite=SITE2. Status COMPLETE crée un Shipment record (status SHIPPED) ; MATUSETRANS row OUT au source (qty −50, balance baisse). Destination : Shipment Receiving app > sélectionner Shipment > Receive > MATRECTRANS row IN (qty +50, balance hausse). Status Shipment passes to RECEIVED puis CLOSED.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :A
Pourquoi cette question existe — IBM teste la distinction same-site (direct) vs cross-site (shipment). Confondre les deux est une erreur classique qui mène à des items « perdus » en transit ou à des transactions inutilement complexes.
Le contexte théorique d'abord — un transfer same-site ne nécessite pas de tracking de transit car la distance et la responsabilité sont minimes : un magasinier emmène les items à pied/forklift entre deux bins du même bâtiment. Le risque de perte/dommage est faible. La transaction est instantanée comptablement : le system décrémente le source et incrémente le destination dans la même opération atomique. Inventory accounts dans la même Org sont consolidés ; aucun GL inter-company. SAP, Oracle EAM, Infor adoptent la même philosophie [EOTRAG Query 14].
Ce que Maximo en fait — version opérationnelle — Inventory Usage app > New > Document Type = TRANSFER > ajouter ligne avec ITEM + qty=30 + From Storeroom=CENTRAL + To Storeroom=WEST. Status COMPLETE → Maximo écrit 2 MATUSETRANS rows : (1) qty=-30, FROMBIN=CENTRAL bin, ISSUETYPE=TRANSFER OUT ; (2) qty=+30, TOBIN=WEST bin, ISSUETYPE=TRANSFER IN. Balances adjustment instantané. Pas de Shipment record créé. GL : Dr Inventory_WEST / Cr Inventory_CENTRAL si comptes distincts par storeroom, sinon no-op (asset reste dans la même balance globale Org). Master-map.pdf p.895 Same-Site Transfer.
Exemple chiffré — transfer 30 unités BRG-001 (cost $10/unit). MATUSETRANS row OUT : qty=−30, cost=$300, FROMBIN=BIN-A1 (CENTRAL). MATUSETRANS row IN : qty=+30, cost=$300, TOBIN=BIN-W1 (WEST). Balance CENTRAL passe de 100 à 70 ; balance WEST passe de 50 à 80. Total Org Inventory unchanged ($1500 dans CENTRAL + WEST = $1500). GL postings minimes ou inexistants selon configuration.
Analogie quotidienne — déplacer un livre d'une étagère à une autre dans votre maison : vous ne préparez pas un colis avec adresse expéditeur/destinataire et tracking number. Vous prenez le livre et le posez ailleurs. Le système comptable global de votre maison voit la même collection.
Pourquoi B est faux — créer un Shipment pour un same-site transfer est inutilement complexe et lent. Le Shipment workflow inclut SHIPDATE, EXPECTEDDATE, CARRIER, status SHIPPED → RECEIVED — autant d'overhead non nécessaire pour 30 mètres de marche dans la même usine. C'est partial-truth (Shipment OUI pour cross-site, mais NON same-site) (D4 partial-truth).
Pourquoi C est faux — issue + receive séparé bypass la fonction TRANSFER intégrée. Pollue les rapports avec un faux issue/receive cycle. Procédure plausible-but-wrong qui simule un transfer mais utilise les mauvaises transaction types. Audit ne distingue plus un transfer d'un issue + receive vendor (D10 procedure-plausible).
Pourquoi D est faux — Adjust Current Balance + et − sur deux storerooms : (1) crée 2 transactions ADJUSTMENT au lieu d'1 TRANSFER ; (2) chacune a un reason code ; (3) les rapports inventory transactions ne montrent plus le lien entre les deux ; (4) violation de la double-entrée comptable correcte (l'ajustement est un mécanisme pour erreurs/comptages, pas pour mouvements). Wrong app pour le contexte (D6 wrong-app).
| Scenario | Document Type | Shipment | GL impact |
|---|---|---|---|
| Même site, même Org | TRANSFER | NON | Minimal (storeroom accounts) |
| Sites différents, même Org | TRANSFEROUT | OUI | Comptes inter-sites |
| Different organizations | TRANSFEROUT | OUI | Intercompany AR/AP |
- Same-site = TRANSFER, direct, no shipment
- Cross-site = TRANSFEROUT + Shipment
- 2 MATUSETRANS rows (OUT + IN) atomic
- JAMAIS Adjust Balance pour transfer
- [EOTRAG Query 14] Maximo Inventory Transaction Tables — IBM Maximo Manage 9
- master-map.pdf p.895 — Same-Site Transfer mechanics
- IBM Maximo Manage 9 — Inventory Usage TRANSFER document type
Correct :C
Pourquoi cette question existe — STU 4.3 mentionne explicitement « Shipment Transfer for Item / Tool ». IBM teste la mécanique cross-site qui requiert un Shipment record pour tracer le transit, distincte du same-site direct.
Le contexte théorique d'abord — un transfer cross-site implique un transit physique non-trivial : transport routier, maritime, parfois transfrontalier. Le risque de perte/dommage est significatif ; la durée est mesurable (jours/semaines) ; la responsabilité change (qui répond si le carrier perd la cargaison ?). Le Shipment record matérialise cette phase de transit avec des fields : SHIPDATE, EXPECTEDDATE, CARRIER, TRACKINGNUM, STATUS. Pendant le transit, les items ne sont ni dans le source storeroom (déjà sortis) ni dans le destination (pas encore arrivés) — ils sont in-transit, comptablement isolés [EOTRAG Query 14].
Ce que Maximo en fait — version opérationnelle — Inventory Usage app > New > Document Type = TRANSFEROUT > ITEM + qty + From Storeroom + To Storeroom + To Site. Status COMPLETE : Maximo (1) auto-creates a Shipment record (status SHIPPED) avec les détails ; (2) écrit MATUSETRANS row OUT au source storeroom (qty=−100, ISSUETYPE=TRANSFEROUT) ; (3) decremente source balance. Le Shipment apparaît dans le destination's Shipment Receiving app pour traitement ultérieur. Master-map.pdf p.897 Cross-Site Transfer / Shipment.
Exemple chiffré — transfer 100 valves de SITE1/CENTRAL à SITE2/REMOTE. Status COMPLETE le 2026-04-15 : Shipment SH-001 créé (SHIPDATE 04-15, EXPECTEDDATE 04-22, CARRIER UPS, status SHIPPED). MATUSETRANS row OUT : qty=−100, cost=$5000 (100×$50). Balance CENTRAL passe de 200 à 100. Balance REMOTE inchanged (pas encore reçu). 2026-04-22 : Shipment Receiving app à SITE2 > sélectionner SH-001 > Receive > MATRECTRANS row : qty=+100. Balance REMOTE passe de 50 à 150. Shipment status passes to RECEIVED puis CLOSED.
Analogie quotidienne — envoyer un colis à un proche dans une autre ville : vous emballez (CENTRAL TRANSFEROUT), vous envoyez via Postes Canada (Shipment status SHIPPED, tracking number), il transit pendant 5 jours (in-transit), votre proche reçoit (Shipment Receiving). Vous ne le déposez pas directement chez lui ; il y a une phase de transit avec sa propre traçabilité.
Pourquoi A est faux — TRANSFER (without OUT) est pour same-site direct. Pour cross-site, le system requiert un Shipment record pour tracer le transit. Wrong app/document type pour le contexte (D6 wrong-app).
Pourquoi B est faux — ISSUE + Adjust Balance contourne la fonction TRANSFER intégrée. Les items ne sont pas tracés en transit (pas de Shipment). Si le carrier perd la cargaison, on ne peut pas distinguer entre ISSUE légitime et perte transit. Procédure plausible-but-wrong (D10 procedure-plausible).
Pourquoi D est faux — RETURN serait l'inverse d'un issue. Confondre TRANSFEROUT et RETURN traduit une mauvaise compréhension des document types. Les noms sont distincts dans le dropdown Maximo (D9 near-synonym).
Cross-site transfer workflow complet
- Source : Inventory Usage TRANSFEROUT, status COMPLETE
- Maximo auto-creates Shipment record (status SHIPPED)
- Source balance −, MATUSETRANS row OUT
- Items in transit (logically isolated)
- Destination : Shipment Receiving app, sélection Shipment
- Receive → MATRECTRANS row IN, destination balance +
- Optional inspection (cf lesson 4-4)
- Shipment status passes to RECEIVED puis CLOSED
Cross-org subtlety : cost re-évalué au destination Org selon SA méthode (variance possible posté en Cost Adjustment).
- Cross-site = TRANSFEROUT + Shipment auto-créé
- Same-site = TRANSFER direct, no Shipment
- Items in-transit logiquement isolés
- Receiving = autre app au destination
- [EOTRAG Query 14] Shipment Receiving — IBM Maximo Application Suite (MAS)
- master-map.pdf p.897 — Cross-Site Transfer Shipment
- IBM Maximo Manage 9 — Inventory Usage TRANSFEROUT document type
Correct :B
Pourquoi cette question existe — pour les rotating items en cost type ASSET, l'intégrité du coût par-asset est sacro-sainte. IBM teste si le candidat sait que le transfer ne reset PAS l'INVCOST cumulé.
Le contexte théorique d'abord — l'INVCOST par-asset (achat + cumul des réparations) est l'élément central du modèle ASSET. Reset cet INVCOST à chaque transfer briserait la traçabilité de la valeur capitalisée du serial. Le coût des réparations faites avant le transfer ne disparaît pas magiquement ; il reste capitalisé sur l'asset. Cette continuité est exigée par IFRS IAS 16 (Immobilisations corporelles) pour la cohérence de la valeur comptable [EOTRAG Query 6].
Ce que Maximo en fait — version opérationnelle — au transfer d'un rotating asset, Maximo : (1) déplace l'ASSETNUM de la LOCATION/STOREROOM source vers le destination ; (2) préserve l'INVCOST de l'asset (purchase + cumul repairs) — il voyage avec l'asset ; (3) écrit MATUSETRANS row OUT au source + IN au destination, both with cost = INVCOST de l'asset ; (4) le destination inventory balance regagne l'asset à sa valeur cumulée. Aucun reset, aucune moyenne, aucun zero. Master-map.pdf p.899 Rotating Item Transfer.
Exemple chiffré — SN-MOT-A123 cost actuel $7 000 ($5 000 purchase + $2 000 cumul repairs). Transfer CENTRAL → WEST. INVCOST per-asset stocké dans Inventory : $7 000. Après transfer : SN-MOT-A123 in WEST storeroom, INVCOST=$7 000. Au prochain issue de cet asset depuis WEST, le WO sera chargé $7 000 (preserved). Si l'asset reçoit une autre repair de $500 après transfer, son INVCOST sera $7 500.
Analogie quotidienne — vous déménagez votre voiture d'occasion d'une ville à une autre. La voiture garde son odomètre, son histoire de réparations, sa valeur de marché. Vous ne « réinitialisez » pas la voiture à son prix neuf à chaque déménagement.
Pourquoi A est faux — reset à purchase cost effacerait des repairs capitalisés réels (les $2 000 disparaîtraient comptablement). Les rapports financiers seraient incorrects. Maximo n'a pas ce comportement (D2 invented).
Pourquoi C est faux — moyenner avec d'autres rotating items du destination est une opération absurde pour rotating (chaque serial a son coût). Cette moyenne contredirait le modèle ASSET. Fonctionnalité fabriquée (D2 invented).
Pourquoi D est faux — set à zéro effacerait toute la valeur capitalisée. Comptablement absurde. Fonctionnalité fabriquée (D2 invented).
Rotating asset transfer — règles
- ASSETNUM voyage : même serial, nouveau location/storeroom
- INVCOST préservé (purchase + cumul repairs)
- History (issues, repairs) preserved
- 2 MATUSETRANS rows (OUT + IN) au cost cumulé
- Cross-org : cost re-évalué selon destination Org's cost type
Cas spéciaux
- Cross-org avec ASSET cost type des deux côtés : cost preserved
- Cross-org avec mismatch cost type : variance posted
- Re-classification volontaire : action séparée si requis
- Rotating transfer : INVCOST cumulé preserved
- ASSETNUM unchanged, location only changes
- History continuity essentielle
- JAMAIS reset, JAMAIS moyenne, JAMAIS zero
- [EOTRAG Query 6] Rotating Items / Capital spares — IBM Maximo Manage 9
- master-map.pdf p.899 — Rotating Item Transfer
- IFRS IAS 16 — Valeur comptable des immobilisations corporelles
Correct :A
Pourquoi cette question existe — la nuance Tool issue (à une personne) vs Tool transfer (entre storerooms) est subtile. IBM teste si le candidat ne sur-applique pas la règle « Issue To Person » à toutes les manipulations de tools.
Le contexte théorique d'abord — Issue To Person est requis quand un tool sort temporairement du storeroom pour usage opérationnel (par un technicien sur un WO). La traçabilité personnelle accountability est nécessaire car le tool est consommé/utilisé/retourné par l'individu. En revanche, un transfer entre storerooms est un mouvement permanent sans usage individuel : c'est le storeroom qui « change de main » (de MAIN à EAST), pas une personne qui prend le tool. La track-by-person n'apporte rien dans ce cas. Distinction supportée par les best practices ISO 9001 sur l'asset management [EOTRAG Query 6].
Ce que Maximo en fait — version opérationnelle — Inventory Usage app > Document Type = TRANSFER (same-site) > ITEM=multimeter + qty=15 + From MAIN + To EAST. Le field Issue To Person n'est PAS mandatory pour Document Type=TRANSFER, même si l'item est un Tool. Maximo enforce Issue To Person pour Document Type=ISSUE on tools, pas TRANSFER. Status COMPLETE → MATUSETRANS rows OUT (MAIN) + IN (EAST), pas de PERSON renseignée. Master-map.pdf p.901 Tool Transfer Rules.
Exemple chiffré — transfer 15 multimeters MM-001 de MAIN à EAST. Inventory Usage TRANSFER record, lignes ajoutées sans Issue To Person. Status COMPLETE : balance MAIN −15, balance EAST +15. MATUSETRANS rows : 2 (OUT + IN) sans PERSON. Si plus tard un technicien sort un multimeter de EAST pour un WO, alors là OUI Issue To Person required (Document Type ISSUE).
Analogie quotidienne — la bibliothèque déménage 100 livres de la salle de référence à la salle des sciences. Le bibliothécaire ne fait pas un emprunt avec carte personnelle pour chaque livre ; il les déplace avec un ordre de transfer interne. Vs un visiteur qui emprunte un livre pour le ramener chez lui (Issue To Person équivalent).
Pourquoi B est faux — sur-généralisation : Issue To Person s'applique aux ISSUE de tools, pas à toutes les operations. Suggérer que CHAQUE mouvement requiert Person ignore la distinction issue/transfer (D4 partial-truth — vrai pour ISSUE, faux pour TRANSFER).
Pourquoi C est faux — le Tool flag est défini sur l'Item Master record et ne « disparaît » pas avec un transfer. Le flag est persisten across all storerooms. Cette option fabrique un comportement de perte de flag inexistant (D2 invented).
Pourquoi D est faux — Maximo permet explicitement les transfers de tools entre storerooms. Suggérer un détour issue/return pour faire un transfer est une procédure incorrecte (D7 non-existent comme contrainte).
| Operation | Document Type | Issue To Person tool ? |
|---|---|---|
| Tool issue to WO | ISSUE | OBLIGATOIRE |
| Tool transfer storeroom-to-storeroom | TRANSFER | Optionnel/non requis |
| Retour de tool depuis WO | RETURN | Correspond à la Person d'issue |
| Tool cross-site transfer | TRANSFEROUT | Optionnel |
- Tool ISSUE = Issue To Person obligatoire
- Tool TRANSFER = Issue To Person optionnel
- Tool flag persisten across storerooms
- Distinction usage temporaire vs déplacement permanent
- [EOTRAG Query 6] Rotating Items / Tool issue rules — IBM Maximo Manage 9
- master-map.pdf p.901 — Tool Transfer Rules
- STU 4.3 — Tool Transfer between storerooms
Correct :C
Pourquoi cette question existe — les transferts cross-org avec cost types différents sont un piège classique. IBM teste si le candidat connaît la règle de re-évaluation au destination + variance posting.
Le contexte théorique d'abord — chaque organisation Maximo opère avec son propre cost method (configuré au niveau Org). Quand un item traverse une frontière organisationnelle, l'organisation receveuse applique SA méthode pour valoriser le stock entrant — c'est cohérent avec la souveraineté financière de chaque entité légale. La différence entre cost source et cost destination est inévitable et doit être posté quelque part : le compte « Cost Adjustment » ou « Inter-Company Variance » accueille cette variance. Cette mécanique est universelle dans les ERP multi-org (SAP, Oracle, Maximo) [EOTRAG Query 4].
Ce que Maximo en fait — version opérationnelle — au TRANSFEROUT cross-org, Maximo : (1) Org A : MATUSETRANS row OUT, cost = LIFO source ($13) ; balance Org A baisse de $13 × 50 = $650 ; (2) Shipment in transit ; (3) Org B receiving : MATRECTRANS row IN, cost re-évalué à FIFO Org B logic. Si Org B utilise FIFO et insère une nouvelle layer, le cost de la new layer = receipt cost (peut être différent du source $13) ; (4) variance entre cost transit ($13) et cost receiving Org B logic posté en Cost Adjustment GL. Master-map.pdf p.903 Cross-Org Cost Re-evaluation.
Exemple chiffré — Org A LIFO $13 × 50 = $650 ship out. Org B FIFO : nouvelle couche FIFO avec receipt_cost = $13 (le cost du transit). Mais si Org B avait des couches FIFO existantes (10 unités à $10 + 30 unités à $11), insertion de la nouvelle layer 50 × $13 ne moyenne pas. Au prochain issue de Org B (FIFO oldest first), 10 partent à $10, 30 à $11, 10 à $13. Le cost layering est préservé, mais la valorisation du stock Org B est cohérent avec FIFO. Aucune variance massive si receipt cost = transit cost.
Variance plus complexe : si Org B utilise STANDARD à $11, et le transfer arrive à $13, l'écart $2 × 50 = $100 va en PPV/Cost Adjustment GL.
Analogie quotidienne — vous voyagez du Canada (CAD) à l'Europe (EUR). Vous avez 1 000 CAD en argent. À l'arrivée, vous changez à la banque européenne au taux EUR : vos 1 000 CAD deviennent 700 EUR. La différence (gain/perte de change) est un coût de la conversion entre deux référentiels. Cross-org cost re-évaluation fonctionne pareillement.
Pourquoi A est faux — préserver $13 (LIFO source) ignore la souveraineté financière d'Org B et son cost method. Org B serait forcée d'accepter une valorisation étrangère à sa méthode. Polarité inversée du principe (D3 inverse).
Pourquoi B est faux — moyenne $13 et $10 ($11.50) est une fonctionnalité fabriquée. Maximo ne moyenne pas ; chaque org applique sa méthode (D2 invented).
Pourquoi D est faux — Maximo permet les transferts cross-org avec cost types différents. C'est même la norme (multinationales avec plants en US-GAAP/LIFO et Europe/IFRS-FIFO). Suggérer un blocage est une fonctionnalité inexistante (D7 non-existent).
Cross-org cost re-evaluation logic
- Org A : OUT at source cost (LIFO/FIFO/STD/AVG/ASSET selon Org A)
- Shipment in-transit at source cost
- Org B receiving : recompute selon Org B's cost method
- FIFO/LIFO Org B : insert new layer at receipt cost
- WAC Org B : recompute average per WAC formula
- STD Org B : variance vs standard → PPV / Cost Adjustment
- ASSET Org B (rotating) : INVCOST per-asset preserved
GL inter-company : Org A AR / Org B AP — eliminated en consolidation.
- Cross-org transfer = re-evaluation au destination Org's method
- Variance posté en Cost Adjustment GL
- Inter-company AR/AP éliminés en consolidation
- Rotating ASSET preserve INVCOST par-asset
- [EOTRAG Query 4] Multi-site/org cost subtleties — Materials Management with SAP S/4HANA
- master-map.pdf p.903 — Cross-Org Cost Re-evaluation
- IBM Maximo Manage 9 — Multi-organization cost flow
Correct :D
Pourquoi cette question existe — STU 4.3 inclut « Shipment Transfer for Item / Tool ». IBM teste la connaissance du status workflow OPEN → SHIPPED → RECEIVED → CLOSED. Choisir le bon status pour le moment correct est essentiel pour le suivi.
Le contexte théorique d'abord — un Shipment record dans un EAM moderne suit un cycle de vie similaire à un colis physique : (1) preparation (OPEN, à l'emballage), (2) départ (SHIPPED, en transit), (3) arrivée (RECEIVED, livré), (4) finalisation (CLOSED, paperwork done). Chaque transition correspond à un événement physique vérifiable. Cette granularité permet aux supply chain managers de tracker le pipeline et identifier les retards [EOTRAG Query 14].
Ce que Maximo en fait — version opérationnelle — workflow status Shipment : OPEN (record créé, items pas encore physiquement embarqués) → SHIPPED (items partis du source storeroom, en transit) → RECEIVED (items arrivés au destination, balance updatée) → CLOSED (paperwork final, plus de modifications possibles). VOIDED comme status d'annulation possible avant SHIPPED. Le status SHIPPED est le moment où les items ne sont plus dans le source mais pas encore dans le destination — phase logiquement « in-transit ». Master-map.pdf p.905 Shipment Status Workflow.
Exemple chiffré — 2026-04-15 : TRANSFEROUT créé, Shipment SH-001 status=OPEN brièvement (préparation) puis SHIPPED (items partis, source balance −). 2026-04-15 à 04-22 : items en transit, status=SHIPPED. 2026-04-22 : Shipment Receiving app au destination, status=RECEIVED (balance +). 2026-04-23 après paperwork : status=CLOSED. Pendant SHIPPED, les items sont in-transit ; aucune transaction inventory ne peut être faite sur eux.
Analogie quotidienne — votre colis Amazon : « Préparé » (OPEN) → « Expédié » (SHIPPED) → « Livré » (RECEIVED) → « Confirmé » (CLOSED). Pendant SHIPPED, vous voyez « En transit » dans le tracking, le colis n'est ni chez Amazon ni chez vous.
Pourquoi A est faux — OPEN est le status au moment de la création, avant que les items ne quittent physiquement le source. Pendant le transit, on est passé à SHIPPED. Confondre ces deux statuts initiaux indique une mauvaise séquence (D9 near-synonym, statuts proches).
Pourquoi B est faux — RECEIVED est le status APRÈS arrivée au destination. Pendant le transit, le destination n'a pas encore reçu. C'est le status final transit (D3 inverse, fin du transit).
Pourquoi C est faux — CLOSED est le status après finalisation paperwork, post-RECEIVED. Bien plus tard que le transit. Confondre CLOSED et SHIPPED suggère une mauvaise compréhension du cycle complet (D3 inverse, après le transit).
Shipment status lifecycle
- OPEN : Shipment créé, préparation source
- SHIPPED : Items partis, en transit (source balance −)
- RECEIVED : Items arrivés (destination balance +)
- CLOSED : Paperwork final, archive
- VOIDED : Annulation avant SHIPPED
Trace KPIs
- OPEN to SHIPPED : préparation time
- SHIPPED to RECEIVED : transit lead time
- RECEIVED to CLOSED : paperwork delay
- SHIPPED = en transit (entre OPEN et RECEIVED)
- OPEN → SHIPPED → RECEIVED → CLOSED
- VOIDED = annulation avant SHIPPED
- Pendant SHIPPED, items isolés des deux balances
- [EOTRAG Query 14] Shipment Receiving — IBM Maximo Application Suite
- master-map.pdf p.905 — Shipment Status Workflow
- IBM Maximo Manage 9 — Shipment lifecycle
Correct :B
Pourquoi cette question existe — la traçabilité par lot est essentielle pour les denrées avec péremption ou les industries régulées (pharma, food, aero). IBM teste si le candidat sait que le LOTNUM voyage avec l'item lors d'un transfer.
Le contexte théorique d'abord — la traçabilité par lot serves multiple purposes : (1) péremption (FEFO management), (2) recall (en cas de défaut, identifier toutes les unités d'un lot, peu importe où elles ont été déplacées), (3) régulation (FDA 21 CFR Part 11, EASA Part 145), (4) qualité (tests laboratoire par lot). Si un transfer changeait le lot, la traçabilité serait brisée : on ne pourrait plus retrouver les unités d'un lot affecté par un recall si elles ont migré entre storerooms. C'est pourquoi le LOTNUM est un attribut intrinsèque qui voyage avec les unités physiques [EOTRAG Query 9].
Ce que Maximo en fait — version opérationnelle — Inventory Usage TRANSFER record > ligne avec lotted item > sélection du LOTNUM source. Status COMPLETE : MATUSETRANS rows OUT (FROMBIN=source, LOTNUM=A) + IN (TOBIN=destination, LOTNUM=A). Le destination's INVBALANCES porte une row pour LOTNUM=A avec qty et expiration date inherited. Si le destination avait déjà du stock du même lot (rare), les balances sont mergées. Master-map.pdf p.907 Lotted Item Transfer.
Exemple chiffré — LOT-2026-04-A, exp 2026-08-15, qty 100. Transfer 80 unités de A à B. Source A après : LOT-2026-04-A balance 20, exp 2026-08-15. Destination B après : LOT-2026-04-A balance 80, exp 2026-08-15. Une recall pour LOT-2026-04-A retrouve les 100 unités totales (20+80) avec le même lot identifier dans deux storerooms.
Analogie quotidienne — vous transférez une bouteille de vin de votre cave à un ami. La bouteille garde son millésime (2018), son producteur, son numéro d'embouteillage. Vous ne « réinitialisez » pas ses caractéristiques en la déplaçant. C'est l'identité intrinsèque de la bouteille qui persiste.
Pourquoi A est faux — auto-générer un nouveau lot briserait la traçabilité du lot original. Cette fonctionnalité fabriquée violerait FDA, EASA, et les bonnes pratiques. Maximo ne fait jamais ça (D2 invented).
Pourquoi C est faux — Maximo persiste automatiquement le LOTNUM dans la transaction. Le storekeeper n'a pas à re-saisir manuellement. Cette option fabrique une étape manuelle inexistante (D7 non-existent).
Pourquoi D est faux — l'expiration date est intrinsèque au lot (date production + shelf life), pas re-calculée à chaque transfer. Le délai shelf-life ne « repart à zéro » à chaque déplacement. Comportement fabriqué (D2 invented).
Lotted item transfer — invariants
- LOTNUM voyage avec items (intrinsèque)
- Expiration date préservée
- Recall traceability across storerooms
- Conditions et lots orthogonaux (peuvent coexister)
Cas spéciaux
- Multi-lot transfer : sélection des lots source au transfer
- Bin splitting + lot splitting compatibles
- Cross-org : LOTNUM préservé même cross-org
- LOTNUM voyage avec items à travers transfers
- Expiration date intrinsèque au lot
- Recall traceability across all storerooms
- Compliance FDA, EASA, ISO
- [EOTRAG Query 9] Condition-Enabled / Lots — IBM Maximo Manage 9
- master-map.pdf p.907 — Lotted Item Transfer
- FDA 21 CFR Part 11 — Lot traceability
Correct :A
Pourquoi cette question existe — STU 4.3 inclut « Use Issues and Transfers RBA to perform Item / Tool Transfer ». IBM teste si le candidat distingue les UIs (RBA mobile vs Inventory Usage classic) et comprend que le backend est identique.
Le contexte théorique d'abord — les Role-Based Applications (RBAs) sont des front-end optimisés pour des rôles utilisateurs précis sur des devices spécifiques (tablettes, handhelds). Ils s'appuient sur les MÊMES tables backend et MÊMES services Java/REST que les apps classiques. La valeur ajoutée est purement UI : moins de champs, plus de flow, scanner barcode, touch-friendly. Ceci permet à un même utilisateur d'utiliser la classic app à son bureau (pour des cas complexes avec multi-fields) et la RBA sur le terrain (pour rapidité). Cohérence des data côté backend [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Issues and Transfers RBA > Storekeeper logue → écran simple : « Transfer ». Scan source storeroom barcode (or click), scan items + qty, scan destination storeroom, confirm. Maximo backend : crée Inventory Usage record TRANSFER type, écrit 2 MATUSETRANS rows (OUT + IN), update balances. Identique à si la classic app avait été utilisée. UI optimisée pour 1 transfer en 30 secondes vs 120 secondes en classic. Master-map.pdf p.909 RBA Transfer Workflow.
Exemple chiffré — same transfer 30 unités BRG-001 de CENTRAL à WEST :
Classic Inventory Usage : ~120 secondes (login, navigate, new record TRANSFER, populate fields, items, save, complete).
RBA Issues and Transfers : ~30 secondes (login auto, scan FROM=CENTRAL, scan item+qty, scan TO=WEST, confirm).
4× faster pour les operations terrain. Backend MATUSETRANS rows identiques.
Analogie quotidienne — Excel desktop vs Excel mobile : même fichier, même formules, même résultats. Mais Excel mobile est optimisé pour la saisie rapide sur tablette (less menus, touch-first). Vous ne perdez rien en fonctionnalité backend ; vous gagnez en vitesse UI.
Pourquoi B est faux — bypass des GL postings violerait l'intégrité comptable. Le RBA utilise le même backend service que classic. Comportement inacceptable comptablement (D2 invented).
Pourquoi C est faux — les RBA et classic apps écrivent des MATUSETRANS rows identiques (mêmes colonnes, mêmes valeurs). Aucun « extra field » spécifique à RBA. Suggérer des MATUSETRANS différents fabrique une divergence inexistante (D2 invented).
Pourquoi D est faux — Maximo standard RBA n'a pas de mode offline avec sync différé. Cette fonctionnalité existe dans Maximo Mobile (autre produit), pas dans la RBA core. Confondre RBA et Maximo Mobile traduit une confusion produits IBM (D2 invented dans le contexte RBA).
| Aspect | Classic app | RBA |
|---|---|---|
| UI | Desktop, full features | Mobile-friendly, simplified |
| Cible | Power user, planner | Storekeeper, technician |
| Backend | Identique | Identique |
| MATUSETRANS | Identique | Identique |
| Time-to-action | ~60-120s | ~20-40s |
- RBA = UI rapide + barcode scan
- Backend identique (mêmes MATUSETRANS rows)
- Pas offline (Maximo Mobile pour ça)
- Productivity gain ~70% terrain
- [EOTRAG Query 12] Picking Staging Issue / RBA workflow — IBM Maximo Manage 9
- master-map.pdf p.909 — RBA Transfer Workflow
- STU 4.3 — Use Issues and Transfers RBA
Traitement et Reservations

📋 Objectifs IBM
- Gérer les Item Reservations — Delete ou Modify
- Changer le statut Inventory Usages
- Effectuer le Shipment Receiving pour Item / Tool
- Effectuer la Shipment Inspection
- Effectuer un Void Shipment Receipt
💡 Points clés
- Item Reservation types : HARD (engagement WO approuvé, bloque autres demandes), SOFT (intention plan, ne bloque pas), AUTOMATIC (créée automatiquement par job plan à WO approval). Configurable au niveau item ou WO.
- Modify reservation : Inventory app > sélectionner item > More Actions > Reservations > sélectionner reservation > Modify qty/date/bin. Disponible jusqu'à status COMPLETE de l'usage liée.
- Delete reservation : Inventory app > More Actions > Reservations > Delete. Possible si reservation pas encore consommée. Si déjà partiellement utilisée, modifier qty plutôt que delete.
- Inventory Usage status workflow : ENTERED → IN PROGRESS → STAGED → COMPLETE (ou CANCELLED à tout moment avant COMPLETE). Chaque transition a son impact balance + GL.
- Shipment Receiving app : la destination side de cross-site/cross-org transfers. Liste les Shipments status SHIPPED entrants. User sélectionne, valide qty reçue, écrit MATRECTRANS rows IN, balance destination augmente.
- Shipment Inspection : optional step entre SHIPPED et fully RECEIVED. Si l'item est inspection-required (Item Master flag), les items reçus vont dans une holding location (status WINSP) jusqu'à QA approval. Après inspection accepted → STORES status. After rejected → quarantine.
- Void Shipment Receipt : annule une réception incorrecte. Génère MATRECTRANS row negative qty + reverse GL voucher. Possible si erreur saisie ou item rejeté entièrement.
- Workflow Cron Inventory Status : les cron tasks Maximo peuvent automatiser la transition de statut (ex : auto-approuver les réceptions sans inspection, auto-clore les shipments après RECEIVED). Configurable par site.
- Reservations et ROP : les hard reservations soustraient de l'Available Balance. La comparaison de déclenchement ROP : si (Current − HardRes − Staged + OnOrder) ≤ ROP → reorder.
- Auto reservations sur WO approval : quand un WO is approved (status APPR), Maximo lit le job plan attached et crée auto les reservations pour les items et qty définis. Visible dans Inventory Reservations.
- Reservation date : champ « Required Date » sur la reservation qui dit quand l'item est nécessaire. Drives le picking schedule du storekeeper. Aussi utilisé par ROP forecasting (anticipe les besoins futurs).
- Inventory Usage actions : Cancel (ENTERED → CANCELLED, undo), Generate Picklist (print pour terrain), Stage (move to staging bin), Reverse (annuler après COMPLETE → return rows).
- Réception sans inspection : si le flag Inspection=N sur l'Item Master, le receipt va directement au statut STORES. Row MATRECTRANS IN immédiate. Balance augmente.
- Réception avec inspection : si Inspection=Y, les items reçus vont en holding bin (config sur Site). La balance ne change pas encore. Statut WINSP. Après QA accept : les items se déplacent vers STORES, la balance augmente, statut A. Après reject : la balance reste à 0, items en quarantaine, PR de vendor return généré.
- Void receipt GL impact : reverse de la receipt initiale. Dr AP / Cr Inventory (annule l'increment de balance + AP impact).
| Type | Bloque les autres ? | Impact sur l'available balance | Source typique | Règles d'annulation |
|---|---|---|---|---|
| HARD | Oui — la quantité est engagée et indisponible pour les autres WOs / pick lists. | available_balance −= reserved_qty (soustrait du on-hand pour le ROP et les autres demandes de reservation). |
WO approuvée avec materials list (typiquement créée à l'approbation de la WO via job plan). | Manuelle via l'action Add/Modify Reservations dans l'application Inventory ou sur la WO. Auto-clearée quand l'issue se complète ou que la WO est annulée. |
| SOFT | Non — informationnel uniquement, intention de consommer mais pas d'engagement. | Aucun impact sur l'available balance. Visible sur les rapports de reservation pour planning. | WO en phase pending / planning (pas encore approuvée). Forecast / templates de job plan. | Auto-clearée quand la WO est approuvée (devient HARD) ou annulée. Selon SAM Q4 — réponse B : les items en statut PLANNING peuvent être reorderés, et les SOFT reservations peuvent être prises en compte quand le flag « Reorder includes soft reservations » du storeroom est activé. |
| AUTOMATIC | Dépend des règles Reorder de l'item et de la politique de reservation du storeroom (équivalent HARD une fois déclenché). | Variable — soustrait généralement de l'available balance une fois auto-promue en HARD. | Générée par le système selon le flag auto-reservation de l'item et les triggers ROP. Courant pour les consommables à forte rotation. | Lifecycle géré par Maximo (auto-créée à l'approbation WO, auto-clearée à l'issue ou à l'annulation). Pas créée manuellement — pour override, basculer le flag de l'item. |
Inventory app > Reservations tab > Reservation Type column.⚠️ Piège IBM
Modify vs Delete reservation — IBM teste ce choix selon le contexte. Choisir le mauvais = risque de perte d'audit.
- Modify : si la reservation est partiellement consommée OU si on veut juste changer qty/date. Préserve l'audit chain.
- Delete : si la reservation est totalement non-consommée et plus pertinente. Audit plus brutal mais propre.
- Tenter de Delete une reservation déjà partiellement issued → erreur Maximo « Cannot delete consumed reservation ».
- Modify de qty à 0 ≠ Delete : modify garde le record en archive ; delete le supprime.
🎯 Carte mémoire
Q. Un Shipment SH-001 contient 50 valves arrivées au site. Inspection required. Quel est le workflow de réception complet ?
Afficher la réponse
(1) Shipment Receiving app > sélectionner SH-001 > Receive 50 valves. (2) Items vont en holding location, status WINSP, balance non-encore-incrémentée. (3) Shipment Inspection app > QA reviewe. Si accepted : items déplacés à STORES, balance hausse, status A, MATRECTRANS row IN finalisé. Si rejected : items en quarantine, vendor return PR généré. (4) Shipment status passe à RECEIVED puis CLOSED. Le double-step receiving + inspection assure la qualité avant intégration au stock disponible.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :A
Pourquoi cette question existe — IBM teste le choix Modify vs Delete sur une réservation partiellement consommée. Modify est la bonne réponse car il préserve l'audit ; Delete est interdit sur des réservations consommées.
Le contexte théorique d'abord — une reservation est un engagement de stock vers un consumer (WO, Asset, GL). Tant qu'elle est entièrement non-consumed, elle peut être Delete (rare cas). Dès qu'une partie a été issued, l'audit chain doit conserver le record original ; on ne peut que Modify pour ajuster la qty restante. Cette règle est implémentée dans tous les ERP modernes pour SOX compliance et data integrity [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Inventory app > sélectionner item > More Actions > Reservations. Le tab montre toutes les reservations actives + leur status (qty reserved, qty issued, qty remaining). User sélectionne la row de la reservation à modifier > click Modify. Dialog : modifier qty totale (= already issued + new remaining). Save. Maximo recalcule remaining = total − issued = 5. Audit row enregistré. Si delete tenté sur une reservation avec issued > 0, Maximo bloque avec erreur. Master-map.pdf p.911 Modify Reservation.
Exemple chiffré — reservation initiale qty 20, issued 8, remaining 12. Modify : changer qty totale à 13 (8 issued + 5 remaining). Save. Maximo verify : 8 issued is fixed (audit), 5 remaining now (was 12). Available Balance pour autres demandes augmente de 7 (12−5). Le WO recevra 8+5=13 unités au total au lieu de 20.
Analogie quotidienne — vous avez réservé 20 places à un restaurant pour un événement. 8 invités sont déjà arrivés et installés. Vous appelez pour modifier : « je vais finalement avoir 13 personnes au lieu de 20 ». Le restaurateur garde les 8 déjà servies et libère 7 places (les 5 nouvelles + ajustement). Il ne supprime pas votre réservation initiale ; il la modifie.
Pourquoi B est faux — Delete une reservation déjà partiellement consumed (issued=8) est bloqué par Maximo. Tenter cela échoue avec erreur. Procédure plausible-but-wrong (D9 near-synonym, Delete existe pour reservations vierges).
Pourquoi C est faux — canceler la WO entière pour ajuster une reservation est radical : on perdrait l'historique du WO, des labor entries, des actuals. Procédure plausible-but-wrong (D10 procedure-plausible).
Pourquoi D est faux — Adjust Current Balance ne touche pas aux reservations ; il modifie le stock physique. Reservation et balance sont des concepts distincts. Mauvaise app pour ce cas (D6 wrong-app).
Modify vs Delete reservation — règles
| État reservation | Modify | Delete |
|---|---|---|
| Issued = 0 (vierge) | OUI | OUI |
| Partially issued | OUI (modifier total qty) | NON (audit protect) |
| Fully issued | NON (closed) | NON |
| Cancelled | NON | NON |
- Reservation issued > 0 → Modify only, jamais Delete
- Modify : changer qty totale = issued + new remaining
- Delete : possible seulement si vierge
- Audit preservation = priorité
- [EOTRAG Query 12] Reservations management — IBM Maximo Manage 9
- master-map.pdf p.911 — Modify Reservation
- SOX § 404 — Internal Controls Over Financial Reporting (audit retention)
Correct :C
Pourquoi cette question existe — la distinction HARD vs SOFT reservation est centrale pour comprendre Available Balance et la mécanique d'allocation. IBM teste systématiquement cette nuance.
Le contexte théorique d'abord — la dualité commit/non-commit est un standard MRP/WMS. Une commit reservation (HARD) est un engagement contractuel : le système réserve physiquement le stock, prévient les autres allocations. Une plan reservation (SOFT) est une intention non-contractuelle : visible dans les rapports de planning mais ne bloque pas l'allocation. Cette dualité permet aux planners de planifier des scénarios sans bloquer le stock pour les opérations courantes [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — au niveau item ou WO :
HARD reservation → field HARDRES de INVBALANCES incrémenté → Available Balance baisse → autres reservations refusées si Available insuffisant.
Réservation SOFT → champ SOFTRES tracké mais NON soustrait de Available par défaut → d'autres réservations possibles → le planner peut « over-book » volontairement.
AUTOMATIC reservation : créée by job plan à WO approval → souvent HARD selon configuration.
Master-map.pdf p.913 Reservation Types.
Exemple chiffré — Current Balance 100. WO-A HARD reservation 30. Available = 100−30 = 70. WO-B tente HARD reservation 80 → refusé (70 < 80). WO-B switche en SOFT 80 → success (visibilité planning). Available reste 70 pour autres HARD demands. Si WO-A consume ses 30, Available remonte à 100, WO-B peut convertir SOFT en HARD.
Analogie quotidienne — réserver une table au restaurant : HARD = vous avez confirmé avec carte de crédit, la table est bloquée pour vous. SOFT = vous avez exprimé un intérêt par téléphone, mais d'autres clients peuvent prendre cette table si vous tardez. Au restaurant, on distingue les deux pour gérer les overbooking.
Pourquoi A est faux — SOFT n'a pas l'effet bloquant. C'est l'inverse polaire de HARD. Confondre les deux indique mauvaise compréhension de la dualité commit/non-commit (D3 inverse).
Pourquoi B est faux — PLANNED n'est pas un type de reservation Maximo. Existe parfois dans d'autres ERP (SAP) mais pas dans Maximo. Fonctionnalité fabriquée (D2 invented).
Pourquoi D est faux — ESTIMATED n'est pas un type de reservation Maximo. Confusion avec Estimated Material sur job plan (qty estimée à PM). Fonctionnalité fabriquée (D2 invented).
| Type | Bloque autres ? | Available impact | Cas d'usage |
|---|---|---|---|
| HARD | OUI | − | WO approved, commitment |
| SOFT | NON | 0 (default) | Plan, scenario, intention |
| AUTOMATIC | OUI (typically) | − | Auto-generated par job plan |
- HARD bloque, SOFT informe
- Available = Current − HARD − Staged − Picked
- SOFT non soustrait par default
- AUTOMATIC = HARD auto-créé par job plan
- [EOTRAG Query 12] Reservations / Hard vs Soft — IBM Maximo Manage 9
- master-map.pdf p.913 — Reservation Types
- IBM Maximo Manage 9 — Reservation lifecycle
Correct :B
Pourquoi cette question existe — STU 4.4 inclut « Change Inventory Usages Status ». IBM teste si le candidat connaît le workflow OPEN → PICKED → STAGED → ISSUED et choisit le bon status pour chaque event.
Le contexte théorique d'abord — les pick lists modernes ont un cycle de vie multi-étapes pour reflecter les états physiques distincts du matériel : OPEN (réservation), PICKED (sorti de bin), STAGED (déplacé près du WO), ISSUED (consommé). Chaque transition est traçable, permettant aux supply chain managers d'optimiser les flows et identifier les bottlenecks. Ce concept est universel (SAP WM, Oracle EAM, Manhattan WMS) [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Inventory Usage record > field Status. Workflow : ENTERED (= OPEN, record créé) → IN PROGRESS (= PICKED, items sortis de bin source) → STAGED (items dans staging bin) → COMPLETE (= ISSUED, MATUSETRANS row écrit). Pour la transition vers STAGED, l'Inventory Usage record entry status STAGED ; balance déplacée de main bin vers staging bin. Master-map.pdf p.915 Inventory Usage Status Workflow.
Exemple chiffré — record IU-001 status ENTERED le 10:00. Storekeeper picks items à 10:30 → status passes IN PROGRESS. Items déplacés au staging bin à 11:00 → status passes STAGED. Le lendemain 8:00, technicien ouvre le record et completes → status passes COMPLETE → MATUSETRANS rows écrits. Available balance baisse à STAGED ; current balance baisse à COMPLETE.
Analogie quotidienne — colis Amazon : « Préparation » (ENTERED) → « En préparation » (IN PROGRESS) → « Au point de retrait » (STAGED) → « Récupéré » (COMPLETE). Vous distinguez chaque état pour savoir où en est votre commande.
Pourquoi A est faux — COMPLETE = items déjà consommés sur le WO. C'est trop avancé : les items sont en staging, pas encore issued. Polarité avancée (D3 inverse, après STAGED).
Pourquoi C est faux — ISSUED n'est pas un status Inventory Usage Maximo (Maximo utilise COMPLETE pour ça, pas ISSUED). Le terme est plus pick list générique. Confondre les deux vocabulaires (D9 near-synonym).
Pourquoi D est faux — CANCELLED = abandon volontaire du record. Ne s'applique pas ici (les items sont encore physiquement allocated). Wrong status pour le contexte (D6 wrong-app).
Inventory Usage status workflow
- ENTERED : record créé, données saisies, balance unchanged
- IN PROGRESS : items en cours de picking
- STAGED : items dans staging bin, available baisse
- COMPLETE : MATUSETRANS row écrit, current balance baisse, GL postings
- CANCELLED : abandon, items retournent à main bin (si déjà staged)
Effets balance
- ENTERED : aucun changement
- STAGED : Available − qty (Hard res restored)
- COMPLETE : Current − qty + GL impact
- STAGED = items dans staging bin avant final issue
- Workflow : ENTERED → IN PROGRESS → STAGED → COMPLETE
- Maximo utilise COMPLETE (pas ISSUED)
- Available baisse à STAGED ; current à COMPLETE
- [EOTRAG Query 12] Inventory Usage 4 states / Pick list lifecycle — IBM Maximo Manage 9
- master-map.pdf p.915 — Inventory Usage Status Workflow
- IBM Maximo Manage 9 — Inventory Usage Document Status
Correct :A
Pourquoi cette question existe — STU 4.4 inclut « Perform Shipment Receiving for Item / Tool ». IBM teste la connaissance précise de l'app Shipment Receiving, distincte du PO Receiving classique.
Le contexte théorique d'abord — les Shipments inter-org/inter-site sont des transferts internes (no vendor), distincts des PO (achats vendeur externe). Maximo fournit deux apps de réception distinctes pour ces deux flows : Shipment Receiving pour les transferts internes, Receiving classique pour les PO vendor. Cette séparation reflète les différences comptables (no AP impact pour internal transfer ; AP credit pour vendor PO) et les workflows différents [EOTRAG Query 14].
Ce que Maximo en fait — version opérationnelle — Shipment Receiving app > List shows incoming Shipments status SHIPPED > sélectionner Shipment SH-101 > click Receive. Dialog : valider qty reçue (peut différer de qty shipped si carrier loss/damage), select bin destination, add inspection notes. Save → MATRECTRANS row IN, Shipment status passes to RECEIVED, balance destination augmente. Master-map.pdf p.917 Shipment Receiving Application.
Exemple chiffré — Shipment SH-101 contient 100 valves au cost transit $50 = $5 000. Site clerk dans Shipment Receiving app : sélectionner SH-101, click Receive, qty effective 100 (no loss), bin BIN-V1. MATRECTRANS row : qty=100, cost=$5 000, TOBIN=BIN-V1, SHIPMENTNUM=SH-101. Balance destination valves +100. Shipment status passes RECEIVED puis CLOSED.
Analogie quotidienne — votre maison reçoit deux types de colis : (1) Amazon (PO vendor) → traité au desk « Réception client externe » ; (2) Boîte des ami(e)s (transfert interne familial) → traité au desk « Réception interne ». Les deux ont des paperwork différentes (facture Amazon vs note interne).
Pourquoi B est faux — Inventory app n'a pas de « Receive Shipment » action. Confusion entre les apps. L'option fabrique un menu inexistant (D5 sibling-field — Inventory app a d'autres More Actions, pas Receive Shipment).
Pourquoi C est faux — Receiving (PO Receiving) est pour les vendor PO réceptions, avec AP impact + freight + tax. Pour un shipment interne entre orgs, aucun AP impact ; le bon canal est Shipment Receiving. Wrong app for context (D6 wrong-app).
Pourquoi D est faux — Inventory Usage Document Type RECEIPT n'existe pas. Les Document Types Inventory Usage sont : ISSUE, RETURN, TRANSFER, TRANSFEROUT, SHIPMENT (pour outgoing). Pas RECEIPT. Fonctionnalité fabriquée (D2 invented).
| App | Pour quoi | GL impact |
|---|---|---|
| Shipment Receiving | Internal transfers cross-site/cross-org | Inventory + Inter-Co AP |
| Receiving (PO) | Vendor PO receipts | Inventory + AP vendor |
| Inventory app | Balances, reservations, costs | None direct (au action selon) |
- Shipment Receiving = app dédiée internal transfers
- Receiving (PO) = vendor PO receipts
- 2 apps distinctes pour 2 flows comptables différents
- Status Shipment SHIPPED → RECEIVED via cette app
- [EOTRAG Query 14] Shipment Receiving — IBM Maximo Application Suite
- master-map.pdf p.917 — Shipment Receiving Application
- STU 4.4 — Perform Shipment Receiving for Item / Tool
Correct :C
Pourquoi cette question existe — STU 4.4 inclut « Perform Shipment Inspection ». IBM teste la mécanique du WINSP holding pour les items inspection-required.
Le contexte théorique d'abord — pour les items critiques (valves haute pression, composants aero, médicaments), une inspection QA est obligatoire avant intégration au stock disponible. Pendant cette phase, les items sont physiquement présents mais pas comptablement disponibles. Le concept de holding location (« WINSP » = Waiting Inspection) permet cette séparation : item physically there, balance still 0 in STORES, until QA accepts. Ce mécanisme est universel WMS et conforme ISO 9001 § 8.4.2 (control of externally provided processes/products) [EOTRAG Query 9].
Ce que Maximo en fait — version opérationnelle — Shipment Receiving avec Inspection Required = Y : (1) Receive génère MATRECTRANS row mais avec status WINSP et TOBIN = holding location (configurée dans Site record) ; (2) balance STORES inchanged ; (3) item visible dans Shipment Inspection app ; (4) QA inspecte → if Accepted, transfer du holding au TOBIN final, balance STORES augmente, status A ; if Rejected, vendor return PR auto-generated, items quarantine. Master-map.pdf p.919 Inspection WINSP Holding.
Exemple chiffré — Shipment SH-200, 50 valves. Receive : 50 valves go to holding location HOLD-01, status WINSP. Balance STORES still 0 for ces valves. QA inspect 2 jours plus tard : 48 conformes (passed), 2 défauts (rejected). Action : 48 transferred to STORES (BIN-V1), balance += 48. 2 sent to quarantine, vendor return PR opens for refund. Total balance final = 48 (pas 50).
Analogie quotidienne — comme les bagages à l'aéroport qui passent par la douane avant de devenir disponibles dans le hall : ils sont physiquement arrivés, mais pas encore « libérés » au passager. La douane (QA) inspecte ; si tout va bien, les bagages sortent. Si problème (drogues détectées), ils sont confisqués/quarantine.
Pourquoi A est faux — bypass de l'inspection violerait le requirement Inspection=Y. Items critical sortis sans QA = risque qualité grave. Cette option ignore la flag inspection (D3 inverse — c'est le no-inspection case).
Pourquoi B est faux — les items ne sont pas retournés au vendor pour QA. La vendor inspection se fait BEFORE shipment ; après réception, c'est l'organisation receveuse qui inspecte (Inspection here). Procédure fabriquée (D7 non-existent dans ce contexte).
Pourquoi D est faux — split arbitraire 50/50 n'a aucun fondement. Maximo gère 100% via holding pendant l'inspection ; pas de split. Fonctionnalité fabriquée (D2 invented).
Inspection workflow
- Item Master flag Inspection=Y
- Shipment Receiving avec Inspection activée
- Items go to holding location, status WINSP
- Balance STORES unchanged
- Shipment Inspection app : QA reviews
- If accepted : transfer holding → STORES, balance ++, status A
- If rejected : quarantine, vendor return PR generated
Holding location configuration : Site record fields « Inspection Holding Location » / « Quarantine Location ».
- Inspection=Y → items go to holding, status WINSP
- Balance STORES unchanged jusqu'à QA accept
- QA accept → STORES, status A, balance ++
- QA reject → quarantine + vendor return PR
- [EOTRAG Query 9] Receiving with inspection / WINSP — IBM Maximo Manage 9
- master-map.pdf p.919 — Inspection WINSP Holding
- ISO 9001 § 8.4.2 — Control of externally provided processes/products
Correct :D
Pourquoi cette question existe — STU 4.4 inclut « Perform Void Shipment Receipt ». IBM teste si le candidat connaît cette fonction et ses bénéfices vs les contournements (Adjust Balance, fake issue, SQL delete).
Le contexte théorique d'abord — voider une réception est un cas particulier d'erreur : l'événement n'a jamais eu lieu mais a été enregistré. Pour traiter cela proprement, le système doit créer une transaction inverse (negative) qui annule l'effet original tout en préservant l'audit (trace de l'erreur + correction). Cette mécanique « void = reverse transaction » est universelle (SAP, Oracle) ; supérieure aux contournements (delete row, adjust) car elle préserve l'audit chain [EOTRAG Query 14].
Ce que Maximo en fait — version opérationnelle — Shipment Receiving app > sélectionner Shipment SH-XXX > sélectionner row réception erronée > click Void Receipt. Maximo : (1) crée une nouvelle MATRECTRANS row avec qty=−25 (negative), pointing à la row originale (REVERSALOF field) ; (2) reverse GL voucher : Dr AP / Cr Inventory (annule l'increment original) ; (3) balance baisse de 25 ; (4) Shipment status revert ou special status VOIDED. Master-map.pdf p.921 Void Shipment Receipt.
Exemple chiffré — original receipt : qty=25, cost=$25 × $40 = $1 000. Balance +25, GL Dr Inventory $1 000 / Cr Inter-Co AP $1 000. Void : new MATRECTRANS row qty=−25, cost=$1 000. Balance −25, GL Dr Inter-Co AP $1 000 / Cr Inventory $1 000. Net effect = zero ; mais audit chain montre original receipt + void ensemble (transparency).
Analogie quotidienne — comme annuler une transaction par carte de crédit : la banque ne supprime pas la transaction originale ; elle crée une transaction « refund » qui l'annule. Vous voyez les deux sur votre relevé. Audit propre ; pas de modification rétroactive.
Pourquoi A est faux — Adjust Current Balance −25 baisse la balance mais ne reverse pas le GL voucher original (l'AP reste). On pollue les balances mais on laisse une AP fantasm. Procédure plausible-but-wrong (D10 procedure-plausible).
Pourquoi B est faux — issue à fake WO pollue WO actuals + ne reverse pas l'AP. Procédure plausible-but-wrong (D10 procedure-plausible).
Pourquoi C est faux — SQL delete directe brise l'audit chain (pas de trace de l'erreur), bypass les triggers, laisse la balance désalignée. Inacceptable en environnement contrôlé. Fonctionnalité magique invented (D2 invented dans ce contexte SOX).
Void Shipment Receipt — workflow
- Shipment Receiving app > sélectionner row erronée
- Click Void Receipt
- Maximo crée MATRECTRANS reverse row (qty negative)
- Reverse GL voucher écrit
- Balance ajusté
- Audit chain : receipt + void visibles ensemble
Pourquoi pas Adjust ou Delete
- Adjust : balance OK mais GL pas reverse
- Delete row : audit brisé
- Void : balance + GL + audit cohérents
- Void = reverse transaction (negative row)
- Préserve audit chain
- Reverse GL voucher écrit
- JAMAIS Adjust pour annuler une receipt erronée
- [EOTRAG Query 14] MATRECTRANS reversal — IBM Maximo Manage 9
- master-map.pdf p.921 — Void Shipment Receipt
- STU 4.4 — Perform Void Shipment Receipt
Correct :B
Pourquoi cette question existe — comprendre le flow auto-reservation à WO approval est essentiel pour les FAs Maximo. C'est le mécanisme qui propage les besoins du job plan vers les engagements de stock.
Le contexte théorique d'abord — la cohérence WO ↔ reservation est un principe fondamental d'EAM/CMMS. Un WO « réel » (status APPR) doit avoir ses besoins matériels engagés vers le stock pour : (1) éviter la sur-allocation à d'autres WOs ; (2) déclencher les ROP triggers correctement ; (3) donner visibilité au storekeeper. La création automatique au moment d'approval (transition WAPPR → APPR) automate ce processus, évitant les omissions par planners distrait. Ce comportement est configurable mais le default est l'auto-reservation HARD [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — au passage WO status WAPPR → APPR, Maximo lit le job plan attaché (s'il existe) et la material list du WO. Pour chaque ligne avec ITEM + qty, Maximo crée une row Inventory Reservation : ITEM, qty, WONUM, type=HARD (default), required date = WO planned date. Le HARDRES de chaque item INVBALANCE est incrémenté. Available Balance baisse en conséquence. Master-map.pdf p.923 Auto-Reservation on WO Approval. Configuration : System Properties > mxe.app.invres.autoreserve (Y/N).
Exemple chiffré — WO-501 status WAPPR avec 5 items materials : 10 boulons, 2 valves, 1 motor, 5 joints, 3 fastenings. Approval → 5 reservations créées :
Boulons : HARDRES +10 → balance disponibles boulons baisse de 10.
Valves : HARDRES +2.
Motor (rotating) : HARDRES +1, system reserve un asset specific (FIFO ou closest match).
Joints : HARDRES +5.
Fastenings : HARDRES +3.
Storekeeper voit 5 reservations dans son queue le lendemain matin.
Analogie quotidienne — vous validez votre commande Amazon. Les items « bloquent » dans le warehouse Amazon pour vous (reservation). Ils ne sont pas encore expédiés, mais Amazon ne les vendra pas à un autre client. Si vous annulez, ils retournent dans le pool disponible.
Pourquoi A est faux — Maximo automate ce processus standard. Suggérer que rien ne se passe à l'approval est faux ; ce serait inefficace en operations. Cette option fabrique une absence de fonctionnalité (D7 non-existent — fonctionnalité existe mais option dit qu'elle n'existe pas).
Pourquoi C est faux — Maximo crée des reservations, pas des issues directes. Issuer immediatement violerait le workflow (le storekeeper doit physiquement préparer ; le WO peut être annulé entre approval et issue). Suggérer issue immediate ignore le step intermédiaire (D7 non-existent comme default).
Pourquoi D est faux — par default, les auto-reservations sont HARD (commitment), pas SOFT. SOFT est manuel, pour scenarios de planning. Cette option est partial-truth (vrai dans certains setups, faux par default) (D4 partial-truth).
Auto-reservation lifecycle on WO approval
- WO créée avec material list (job plan ou manual)
- WO status WAPPR (waiting approval)
- Approver passe status à APPR
- Maximo trigger : pour chaque material, create HARD reservation
- HARDRES updated, Available Balance baisse
- Storekeeper voit reservations dans queue
- Picking → staging → issue → MATUSETRANS
Si stock insufficient à approval : reservation créée quand même (HARDRES > Current possible). Storeroom doit reorder ou wait pour replenish.
- WO approval → auto HARD reservations
- Job plan ou manual material list source
- HARDRES incremented, Available baisse
- Configurable mais default = auto HARD
- [EOTRAG Query 12] Reservations / WO approval auto-create — IBM Maximo Manage 9
- master-map.pdf p.923 — Auto-Reservation on WO Approval
- IBM Maximo Manage 9 — Job Plan Material reservations
Inventory Usage : statuts et cycle de vie

📋 Objectifs IBM
- Maîtriser la machine à 4 états OPEN → PICKED → STAGED → ISSUED
- Comprendre l'impact balance à chaque transition d'état
- Distinguer la physical balance de l'available balance à chaque état
- Maîtriser les règles cancel / void à chaque état
- Tracer les documents InvUseLine liés à chaque transition d'état
- Utiliser l'action Restock pour réverser les items aux états antérieurs à ISSUED
💡 Points clés
- 4-state machine canonical : OPEN → PICKED → STAGED → ISSUED. Chaque état correspond à une localisation physique distincte et une mécanique balance distincte.
- OPEN state : la usage line existe sur le pick list, items still in main bin. Hard reservation in place. Available Balance déjà baissé (HARDRES incrémenté). Physical balance unchanged.
- État PICKED : items physiquement sortis de la main bin mais pas encore déplacés vers staging. Le stock reste dans le complexe du storeroom (dans le sous-bucket « picked »). Physical balance inchangée ; Available baissé ; compteur PICKED incrémenté. Utile pour des opérations à fort volume où le picking est tracé séparément.
- État STAGED : items déplacés vers le staging bin du storeroom. Physical balance dans la main bin baissée ; staging bin balance augmentée. Le complexe du storeroom détient toujours les items. Available reste baissé.
- ISSUED state (= COMPLETE Maximo) : items consommés. MATUSETRANS row ISSUE écrit. Storeroom physical balance baissée définitivement. WO actuals augmenté. GL postings.
- Cancel rules par état : cancel possible avant ISSUED. Items en PICKED ou STAGED → reverted to main bin (action Restock). Items en ISSUED → seul Return possible (pas Cancel).
- InvUseLine document : la table backend qui tie pick list line ↔ reservation ↔ inventory transactions. Chaque state transition crée/update une row InvUseLine.
- InvUseSplit : créé quand une ligne consomme depuis plusieurs bins/lots (bin splitting). Une InvUseLine peut avoir N InvUseSplit enfants.
- Restock action : permet de revenir d'un état PICKED ou STAGED à OPEN, retournant les items à la main bin si le WO scope change ou est annulé. Items in ISSUED state requièrent Return formel.
- Status transitions visibility : Inventory Usage record > tab Status History montre la chronologie complète des transitions avec user, timestamp, qty.
- Insight RAG critical : STAGED items reduce available balance even though physically still in storeroom complex. Affecte ROP calculations si non géré correctement.
- Mobile state updates : Maximo Mobile et Quick Reporting permettent au storeroom clerk d'update les pick states depuis un handheld ; barcode scan validates serial/lot.
- Issue avec vs sans réservation : les items peuvent être issued sans réservation préalable (ad-hoc). Maximo crée alors une InvUseLine « sans réservation ». Les réservations sont recommandées pour les WOs planifiés.
- Inventory balance impact summary : ISSUE decremente le storeroom source. TRANSFER decrement source + increment destination.
- GL postings par état : seul ISSUED écrit GL voucher (Dr WO Cost / Cr Inventory). Les états PICKED et STAGED sont purement des mouvements physiques sans impact GL.
stateDiagram-v2 direction LR [*] --> OPEN: Create OPEN --> PICKED: Pick PICKED --> OPEN: Un-pick PICKED --> STAGED: Stage STAGED --> PICKED: Un-stage STAGED --> ISSUED: Issue (INVTRANS) OPEN --> ISSUED: Direct Issue OPEN --> CANCELLED: Cancel ISSUED --> [*] CANCELLED --> [*] note right of OPEN: Nouveau record Inventory Usage\\nAucun impact sur le balance note right of PICKED: Items réservés\\nBalance toujours dans la main bin\\nLe available balance diminue note right of STAGED: Items déplacés vers staging bin\\nLa balance de la main bin diminue\\nLa balance staging bin augmente note right of ISSUED: Décrément permanent\\nGL voucher posté\\nWO actuals mis à jour
⚠️ Piège IBM
STAGED reduces Available Balance even though items are still in storeroom complex — IBM teste cette subtilité directement.
- STAGED items sont physiquement toujours dans le storeroom (juste dans une autre bin appelée staging).
- MAIS comptablement, ils ne sont plus disponibles pour de nouvelles reservations.
- Donc Available Balance baisse à STAGED, alors que Current Balance (= total physique storeroom) reste.
- Conséquence : ROP triggers peuvent se déclencher si STAGED non pris en compte dans Available.
- Confondre les deux balances = mauvaise allocation pour des nouvelles demandes.
🎯 Carte mémoire
Q. Quelle est la différence comptable entre PICKED et STAGED ?
Afficher la réponse
PICKED : items sortis de main bin mais pas encore déplacés ; physical balance dans la bin main reste inchanged ; un compteur PICKED tracks la qty (pour tracking interne). STAGED : items physiquement déplacés vers la staging bin du storeroom ; main bin balance baisse, staging bin balance augmente. Dans les deux états, Available Balance global baisse car les items sont engagés. Aucun GL impact à ces états ; seul ISSUED écrit le GL voucher final.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — la séquence canonique des 4 états est l'élément central de l'objectif STU 4.5. IBM teste si le candidat connaît l'ordre exact (les états ne sont pas interchangeables).
Le contexte théorique d'abord — la séquence OPEN → PICKED → STAGED → ISSUED reflète les phases physiques distinctes du flow d'un item de la main bin à sa consommation. (1) OPEN : la usage line existe mais aucun mouvement physique. (2) PICKED : item physiquement sorti de la main bin (pris en main). (3) STAGED : item placé dans une staging bin near WO site. (4) ISSUED : item consommé par le WO. Chaque transition correspond à un événement physique observable et chaque état a des implications balance/GL distinctes [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Inventory Usage record > field Status. Maximo enforce l'ordre : on ne peut pas passer de OPEN directement à STAGED (sauf si configuré comme allowed transition). Chaque transition est traçable, génère row InvUseLine update, et impact balance comme défini. Master-map.pdf p.925 Pick List 4-State Lifecycle.
Exemple chiffré — usage IU-101, 50 unités. Day 1 OPEN (reservation in place, available baisse). Day 2 morning : PICKED (items in hand). Day 2 noon : STAGED (in staging bin near WO). Day 3 morning : ISSUED (technicien consume → MATUSETRANS écrit, GL voucher). Chaque step traçable avec timestamp + user.
Analogie quotidienne — Amazon order : « Order placed » (OPEN) → « Picking » (PICKED, item taken from shelf) → « Packed » (STAGED, in shipping container) → « Delivered » (ISSUED, customer received). L'ordre est universel ; on ne peut pas passer de « Order placed » directement à « Delivered » sans les states intermédiaires.
Pourquoi A est faux — STAGED avant PICKED inverse la logique physique : on ne peut pas placer un item en staging s'il n'a pas été pris (PICKED) de la main bin d'abord. Polarité inversée (D3 inverse).
Pourquoi B est faux — PICKED avant OPEN est absurde : OPEN représente la création initiale du record (avant tout mouvement physique). Sequence inversed (D3 inverse).
Pourquoi D est faux — ISSUED avant PICKED/STAGED est l'inverse complet de la logique : ISSUED est l'état terminal après consommation. Le placer après OPEN seulement signifierait que le système consomme avant de picker, ce qui est physiquement impossible (D3 inverse).
4-State Lifecycle canonical sequence
- OPEN : usage line exists, no physical move
- PICKED : items sortis de la main bin
- STAGED : items in staging bin near WO
- ISSUED : items consumed, MATUSETRANS row written
L'ordre est obligatoire : les transitions doivent respecter cette séquence (Maximo l'impose).
Point d'annulation : possible avant ISSUED ; après ISSUED nécessite un Return.
- OPEN → PICKED → STAGED → ISSUED
- Sequence physique : create → pull → stage → consume
- Order is enforced
- Cancel possible avant ISSUED
- [EOTRAG Query 12] 4 states of Pick List — IBM Maximo Manage 9
- master-map.pdf p.925 — Pick List 4-State Lifecycle
- IBM Maximo Manage 9 — Inventory Usage Status workflow
Correct :B
Pourquoi cette question existe — c'est l'insight RAG critique de STU 4.5 : « STAGED items reduce available even though physically still in storeroom ». IBM teste cette subtilité car elle est mal comprise et impacte ROP calculations.
Le contexte théorique d'abord — la distinction « physique » vs « comptable » est centrale en gestion de stock. Physical Balance = somme de tous les items physiquement présents dans le storeroom complex (toutes bins confondues, y compris staging). Available Balance = ce qui peut encore être réservé/promis. À STAGED, les items sont physiquement still in storeroom complex (juste dans une autre bin), donc physical Balance unchanged. Mais ils sont déjà committed pour le WO via la usage line, donc Available Balance baisse. Cette dualité prevent les conflits où plusieurs WOs essaient de consumer les mêmes items [EOTRAG Query 12 — RAG insight critical].
Ce que Maximo en fait — version opérationnelle — au passage à STAGED : (1) déplacement de qty entre bins (FROMBIN main / TOBIN staging) ; (2) field STAGED de INVBALANCES incrémenté ; (3) HARDRES inchanged (la reservation reste matérialisée par la usage line) ; (4) CURBAL = sum(bin balances) reste identique car items still in storeroom (juste in staging bin) ; (5) Available = CURBAL − HARDRES − STAGED − PICKED ; comme STAGED augmente, Available baisse. Master-map.pdf p.927 STAGED Balance Mechanics.
Exemple chiffré — avant STAGED : CURBAL=100 (90 main bin + 10 staging bin), HARDRES=30, STAGED=10, PICKED=0. Available = 100 − 30 − 10 − 0 = 60. STAGE 30 unités → main bin baisse de 30, staging bin augmente de 30. CURBAL = 60 + 40 = 100 (unchanged). HARDRES=30 (still). STAGED = 10 + 30 = 40. Available = 100 − 30 − 40 − 0 = 30. Available a baissé de 30, Current unchanged.
Analogie quotidienne — votre frigo a 12 yaourts (current balance). Vous mettez 6 sur l'étagère du salon pour les invités du soir (équivalent staging). Total dans la maison = 12 (unchanged). Mais « disponibles pour grignoter » = 6 dans le frigo (les 6 staged sont engagés pour les invités). Total physique unchanged, dispo baisse.
Pourquoi A est faux — Current Balance ne baisse pas à STAGED car les items sont toujours dans le complexe du storeroom (juste un autre bin). Current ne baisse qu'à ISSUED, quand les items quittent vraiment le storeroom. C'est de la demi-vérité : Available baisse OUI, Current baisse NON (D4 Demi-vérité).
Pourquoi C est faux — il y a UN movement (entre bins), donc impact comptable réel. Available baisse. Cette option fabrique un comportement no-impact (D2 invented).
Pourquoi D est faux — inverse : Current baisse OUI à ISSUED, NON à STAGED. Available baisse OUI à STAGED. Polarité inversée des deux balances (D3 inverse).
| État | Current Balance | Available Balance | Items physically |
|---|---|---|---|
| OPEN | Unchanged | Decreased (HARDRES) | Main bin |
| PICKED | Unchanged | Decreased (PICKED) | Out of bin (in hand) |
| STAGED | Unchanged | Decreased (STAGED) | Staging bin (still storeroom) |
| ISSUED | Decreased | Decreased (consumed) | Out of storeroom (on WO) |
- STAGED : items toujours dans le storeroom (bin différent)
- Current Balance unchanged à STAGED
- Available Balance decreased à STAGED
- Current decreases ONLY à ISSUED
- [EOTRAG Query 12] STAGED items reduce available even though physical still in storeroom — IBM Maximo Manage 9
- master-map.pdf p.927 — STAGED Balance Mechanics
- STU 4.5 RAG insight — STAGED state balance impact
Correct :A
Pourquoi cette question existe — comprendre quand le GL voucher est posté est essentiel pour les FAs qui interfacent avec finance. La règle « only at ISSUED » distingue les mouvements physiques (OPEN/PICKED/STAGED) des transactions financières (ISSUED).
Le contexte théorique d'abord — en comptabilité, une transaction financière reflète un événement économique réel. Le matching principle (matching expenses to revenues) impose que le coût d'un material soit reconnu quand il est consommé sur le WO (= valeur économique extraite), pas quand il est juste préparé (PICKED, STAGED). Reconnaître l'expense plus tôt overstate les actuals d'un WO non encore terminé. Cette philosophie est universelle (IFRS, US-GAAP) et appliquée par tous les ERPs modernes [EOTRAG Query 14].
Ce que Maximo en fait — version opérationnelle — au passage à status COMPLETE (= ISSUED logique), Maximo : (1) écrit MATUSETRANS row avec GL_DEBIT/CREDIT accounts ; (2) génère GL voucher Dr WO Cost / Cr Inventory ; (3) baisse Current Balance définitivement ; (4) augmente WO actuals. Avant COMPLETE, aucun GL voucher écrit même si les balances available et states changent. Master-map.pdf p.929 GL Posting Timing.
Exemple chiffré — usage 50 unités × 10 $ = 500 $. OPEN jour 1 : aucun GL. PICKED jour 2 matin : aucun GL. STAGED jour 2 midi : aucun GL. ISSUED (COMPLETE) jour 3 matin : voucher GL Dr WO Cost 500 $ / Cr Inventory 500 $. Impact P&L au jour 3 uniquement. Si le WO est annulé à l'état STAGED, aucun GL n'a été écrit → facile à reverser via l'action Restock.
Analogie quotidienne — vous achetez en ligne : carte de crédit déclenche le débit seulement à l'expédition (= ISSUED), pas à la mise au panier (OPEN), pas à la préparation (PICKED), pas à l'emballage (STAGED). Les phases intermédiaires ne sont que des préparations physiques sans impact financier. Si vous annulez avant expédition, aucun débit à reverser.
Pourquoi B est faux — OPEN crée une reservation, pas une transaction financière. Reservations sont des engagements physiques, pas des debits/credits GL. Wrong app pour ce qui se passe à OPEN (D6 wrong-app).
Pourquoi C est faux — PICKED est un mouvement physique (out of bin) sans impact financier. Suggérer un GL à PICKED viole le matching principle. Partial-truth (mouvement existe, GL non) (D4 partial-truth).
Pourquoi D est faux — STAGED est un déplacement entre bins du même storeroom, sans valeur économique extraite. Aucun GL impact. Partial-truth (mouvement existe, GL non) (D4 partial-truth).
GL impact summary par état
| État | GL voucher ? | Reason |
|---|---|---|
| OPEN | NON | Just reservation |
| PICKED | NON | Physical pull, same storeroom |
| STAGED | NON | Inter-bin within storeroom |
| ISSUED | OUI | Economic consumption (matching principle) |
| CANCELLED (avant ISSUED) | NON | No reverse needed |
Implication : reverse pre-ISSUED state is « clean » (just balance moves, no GL reversal); reverse ISSUED requires Return.
- GL voucher posted only at ISSUED (COMPLETE)
- OPEN/PICKED/STAGED = physical only, no GL
- Cancel pre-ISSUED = clean, no GL reverse
- Cancel ISSUED = Return + GL reverse
- [EOTRAG Query 14] MATUSETRANS GL postings timing — IBM Maximo Manage 9
- master-map.pdf p.929 — GL Posting Timing
- IFRS / US-GAAP — Matching Principle
Correct :C
Pourquoi cette question existe — STU 4.5 inclut « Cancel/Void rules at each state » et « Restock action ». IBM teste si le candidat connaît cette action spécifique pour reverter pre-ISSUED states sans pollution comptable.
Le contexte théorique d'abord — quand un WO est cancelled avant qu'aucun coût ne soit comptabilisé (= avant ISSUED), il n'y a rien à reverser comptablement. La seule action requise est de remettre les items physiques à leur position originale (main bin) — un mouvement physique sans transaction comptable. La Restock action est désignée pour exactement ce cas. Crucial pour préserver la propreté de l'audit chain (no fake issue/return cycle) [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — Inventory Usage record > sélectionner row(s) en PICKED ou STAGED > click Restock action. Maximo : (1) déplace items de staging/picked sub-bucket vers main bin ; (2) decrement STAGED ou PICKED counter ; (3) Available Balance restaurée ; (4) HARDRES preserved (encore reserved, à supprimer si cancel) ; (5) AUCUN GL voucher écrit. Status revert à OPEN. Master-map.pdf p.931 Restock Action.
Exemple chiffré — usage IU-201 STAGED qty=30. WO cancelled. Click Restock : items deplacés staging bin → main bin. STAGED = 0. Status passes back to OPEN. Available Balance restored (avant : Available = 100−30=70 ; après : Available = 100). Aucun MATUSETRANS row ISSUE généré. Aucun GL voucher. Si on veut aussi delete la reservation, action séparée Delete reservation (since qty 0 issued, allowed).
Analogie quotidienne — Amazon order cancelled avant shipping : le warehouse retourne les items du « picked » bin au shelf, sans vous facturer ni vous rembourser. Pure physical movement reversal.
Pourquoi A est faux — Issue puis Return immediate génère 2 MATUSETRANS rows + 2 GL vouchers (Dr WO/Cr Inv puis Dr Inv/Cr WO). Net effect = zero, but l'audit chain est polluée et les rapports KPI WO sont touchés. Procédure plausible-but-wrong (D10 procedure-plausible).
Pourquoi B est faux — Adjust Current Balance n'est pas the right tool : Current Balance est unchanged à STAGED (les items sont still dans le storeroom). Wrong app (D6 wrong-app).
Pourquoi D est faux — delete le record laisserait les items physiquement dans le staging bin sans le record qui les explique. Inventory désaligné, audit cassé. Suggérer cette option fabrique une procédure destructive inacceptable (D7 non-existent comme bonne pratique).
Cancel rules par état
| État | Cancel action | GL impact |
|---|---|---|
| OPEN | Cancel record + Delete reservation | None |
| PICKED | Restock (back to main bin) | None |
| STAGED | Restock (staging → main bin) | None |
| ISSUED | Return (creates reverse MATUSETRANS) | Reverse GL voucher |
- Restock = annulation pré-ISSUED, sans GL
- Return = annulation post-ISSUED, avec GL
- JAMAIS Issue+Return pour annuler pré-ISSUED
- JAMAIS Adjust Balance pour reverter un état
- [EOTRAG Query 12] Restock action — IBM Maximo Manage 9
- master-map.pdf p.931 — Restock Action
- STU 4.5 — Cancel/Void rules per state
Correct :C
Pourquoi cette question existe — STU 4.5 mentionne le document InvUseLine. IBM teste si le candidat connaît cette table backend qui conserve la traçabilité fine d'une pick list line through all states.
Le contexte théorique d'abord — un FA Maximo expérimenté connaît les tables backend principales : MATUSETRANS (issue/return/transfer), MATRECTRANS (receipts), INVTRANS (adjustments), INVBALANCES (current balances), INVRESERVE (reservations). Le InvUseLine est une table moins connue mais cruciale : c'est le record-mère qui tie a pick list line ↔ reservation source ↔ subsequent inventory transactions à travers les 4 states. Sans InvUseLine, on ne pourrait pas retracer le complete lifecycle d'une pick line [EOTRAG Query 12].
Ce que Maximo en fait — version opérationnelle — quand une Inventory Usage row est créée, une row InvUseLine est créée. À chaque transition state, des updates sont écrits sur cette row : OPENDATE, PICKEDDATE, PICKEDBY, STAGEDDATE, STAGEDBY, ISSUEDDATE, ISSUEDBY. L'InvUseLine porte aussi RESERVATIONNUM (lien à reservation source) et MATUSETRANSID (lien à transaction finale issue). Master-map.pdf p.933 InvUseLine Document. Permet l'audit query : Select * from InvUseLine where ITEM = 'X' and CREATEDATE BETWEEN ... pour retrouver l'historique fine.
Exemple chiffré — pick line IU-301-001 (item BRG-001, qty=20). InvUseLine row created with OPENDATE=2026-04-15 09:00 by JOHN. PICKEDDATE=2026-04-15 10:30 by SAM. STAGEDDATE=2026-04-15 13:00 by SAM. ISSUEDDATE=2026-04-16 08:00 by TONY. MATUSETRANSID=12345. Audit query reveals chronologie complète + accountability per state.
Analogie quotidienne — comme le tracking détaillé d'un colis Amazon : chaque event (préparé, expédié, en transit, livré) est logué avec timestamp et carrier. Une seule entité (le tracking number = InvUseLine) trace tout le cycle.
Pourquoi A est faux — MATUSETRANS contient les transactions consommation finales (issue/return/transfer rows), pas les intermediate states. Une seule row par usage final, pas par state. Sibling-field (D5).
Pourquoi B est faux — INVRESERVE contient les reservations actives, pas les transitions states. Sibling-field (D5).
Pourquoi D est faux — INVTRANS contient les ajustements (cycle counts, manual adjustments), pas les pick list states. Sibling-field (D5).
Maximo backend tables for inventory
- InvUseLine : pick list line lifecycle, ties to reservation, lifecycle states
- InvUseSplit : sub-rows when bin/lot splitting
- MATUSETRANS : final issue/return/transfer transactions
- MATRECTRANS : receipt transactions (PO + shipments)
- INVTRANS : adjustments (cycle count, manual)
- INVBALANCES : current balances by item × storeroom × bin
- INVRESERVE : active reservations
- INVCOST : cost data per item or per asset (rotating)
- InvUseLine = pick lifecycle traceability
- Tie reservation ↔ states ↔ MATUSETRANS final
- Audit query par OPENDATE / PICKEDDATE / STAGEDDATE / ISSUEDDATE
- Backbone du 4-state lifecycle
- [EOTRAG Query 12] InvUseLine document — IBM Maximo Manage 9
- master-map.pdf p.933 — InvUseLine Document
- IBM Maximo Manage 9 — Pick list backend tables
Correct :D
Pourquoi cette question existe — l'insight RAG critique de STU 4.5 est que STAGED affecte ROP. IBM teste si le candidat comprend que les ROP triggers utilisent Available (pas Current), donc STAGED items contribuent à déclencher reorder.
Le contexte théorique d'abord — le ROP (Reorder Point) est conçu pour anticiper la disponibilité future, pas l'inventaire physique présent. Si du stock est physiquement présent mais comptablement engagé (HARDRES, STAGED, PICKED), il ne sert pas pour les futurs besoins. Donc la formule trigger : if (Available + On Order) ≤ ROP → reorder. Available = Current − HARDRES − STAGED − PICKED. Ce mécanisme évite les stockouts paradoxaux où Current semble OK mais Available est ras de la limite [EOTRAG Query 1 + 12].
Ce que Maximo en fait — version opérationnelle — Reorder cron task > loop sur tous les items configured for reorder. Pour chaque item : compute Available + On Order, compare to ROP. If ≤ ROP, generate PR/PO selon configuration. Items en STAGED sont déjà comptés dans STAGED counter, donc Available est correctement diminué. Master-map.pdf p.935 ROP and STAGED items.
Exemple chiffré — Current 100, HARDRES 20, STAGED 30, On Order 0, ROP 50. Available = 100 − 20 − 30 = 50. (Available + On Order) = 50 + 0 = 50. 50 ≤ 50 (the threshold), trigger reorder. PR generated. Si on aurait juste comparé Current vs ROP (100 vs 50), no trigger — but the storeroom would have a stockout when staged items get issued and HARDRES consumed, leaving 50 available for new demand minus those upcoming → potential stockout.
Analogie quotidienne — votre frigo a 12 yaourts mais vous avez promis 10 à votre famille pour la semaine. Disponible pour dépanner = 2. Si votre seuil de réapprovisionnement est 3 (vous re-achetez quand < 3), 2 trigger reorder. Vous ne vous fiez pas au compte total (12) mais au disponible (2).
Pourquoi A est faux — Current Balance n'est pas la métrique pour ROP. ROP utilise Available. Sinon, items en HARDRES/STAGED ne déclencheraient jamais de reorder même si tout le stock est engagé. Partial-truth (Current existe mais pas pour ROP) (D4 partial-truth).
Pourquoi B est faux — ROP utilise Available, pas Current. C'est l'inverse de ce que dit l'option. Polarité inversée (D3 inverse).
Pourquoi C est faux — STAGED items ne sont PAS physiquement enlevés de l'inventory ; ils sont still in storeroom complex. Cette option mentionne le bon résultat (trigger reorder) mais avec une mauvaise raison (D9 near-synonym dans la justification).
ROP trigger logic
if (Available + On Order) ≤ ROP → reorder
Where : Available = Current − HARDRES − STAGED − PICKED
Items contribuant à Available baisse
- HARDRES : réservations approuvées
- STAGED : items dans le staging bin
- PICKED : items sortis de la main bin
- Current Balance ne baisse qu'à ISSUED
Éléments faisant augmenter Available
- On Order : POs ouverts (à venir)
- Receipts : rows MATRECTRANS
- Retours de WO
- ROP compare (Available + On Order) à ROP threshold
- STAGED items font baisser Available, donc trigger reorder possible
- Current ≠ Available pour ROP
- Insight critique : STAGED affecte ROP même si physiquement still in storeroom
- [EOTRAG Query 1] Reorder Point / ROP formulas — IBM Maximo Manage 9
- [EOTRAG Query 12] STAGED affects ROP — RAG insight critical
- master-map.pdf p.935 — ROP and STAGED items
UoM et conversions

📋 Objectifs IBM
- Ajouter et modifier les Units of Measure (UoM) pour Issue Unit et Order Unit
- Définir les UoMs et les Conversions via les actions Add/Modify Units of Measure et Add/Modify Conversions
- Créer des Item-Specific Conversions sur le record Item Master quand une conversion globale ne s'applique pas
- Configurer les UoMs dans Item Master : Order Unit (UoM d'achat) + Issue Unit (UoM de consommation)
- Comprendre comment le Conversion Factor pilote la traduction de quantité entre Order Unit et Issue Unit à la réception
💡 Points clés
- UoM (Unit of Measure) — un code qui définit comment la quantité d'un item se compte (ex. EACH, BOX, CARTON, LITER, METER, KG). Les UoMs sont partagées au niveau Set et réutilisées par tous les items de ce Item Set.
- Issue Unit — l'UoM dans laquelle l'item est consommé contre les work orders. Ex. : un bearing est issué pièce par pièce → Issue Unit = EACH.
- Order Unit — l'UoM utilisée pour passer une PO à un vendor. Ex. : les bearings sont achetés en cartons de 12 → Order Unit = CARTON.
- Conversion Factor — le multiplicateur entre deux UoMs. Ex. : 1 CARTON = 12 EACH → conversion factor = 12.
- Conversions globales vs Item-Specific — par défaut une Conversion est globale (partagée par tous les items utilisant ces deux UoMs). Quand un fournisseur expédie un item en 10 et un autre le même item en 12, une Item-Specific Conversion override la valeur globale pour cet item.
- Paths d'action : Item Master → More Actions → Add/Modify Units of Measure et Add/Modify Conversions. Les item-specific conversions s'ajoutent via Item Master → More Actions → Conversions sur l'item lui-même.
- À la réception, Maximo traduit la quantité reçue en Order Unit vers Issue Units via la conversion active. Si on commande 5 CARTON de 12 bearings, MATRECTRANS enregistre receipt qty = 60 EACH dans INVBALANCES.
- Précision UoM : le conversion factor est un décimal — 1 LITER → 0,264 GALLON, ou 1 METER → 3,281 FEET. Les erreurs d'arrondi sur les UoMs fractionnaires sont un piège classique d'examen.
- Les Service items ont aussi besoin d'une UoM — typiquement HOUR pour la main-d'œuvre ou EACH pour un service forfaitaire. Un « labor service » item avec Issue Unit = HOUR pilote les charges temps sur la WO.
- L'UoM ne peut pas être changée rétroactivement sans réévaluer le stock on-hand — comme les changements de cost-type, les changements d'UoM sont admin-restricted.
- L'Item Master définit l'Order Unit et l'Issue Unit par défaut ; des overrides par storeroom existent sur l'Inventory record mais sont rares.
- Les conversions sont bidirectionnelles : définir 1 CARTON = 12 EACH permet automatiquement à Maximo de calculer 1 EACH = 1/12 CARTON pour une issue partielle.
graph LR PR["PR de 5 CARTON
(Order Unit)
le vendor voit 5 unités"]:::start PO["PO approuvée
5 CARTON commandés"]:::action CONV["Conversion factor
1 CARTON = 12 EACH
(override item-specific)"]:::warn RECV["Réception
5 × 12 = 60 EACH
enregistré au storeroom"]:::ok STORE["Inventory Balance
balance += 60 EACH
(stocké en Issue Unit)"]:::action ISSUE["Issue de 1 EACH
par WO
(Issue Unit)"]:::endNode PR ==> PO ==> CONV ==> RECV ==> STORE ==> ISSUE NOTE[/"Deux unités par Item Master
Order Unit = côté vendor
Issue Unit = côté WO
L'item-specific conversion
override la table UoM globale"/]:::note CONV -.-> NOTE classDef start fill:#3B82F6,stroke:#1E40AF,color:#FFFFFF,font-weight:600; classDef action fill:#FFFFFF,stroke:#94A3B8,color:#0F172A; classDef warn fill:#FEF3C7,stroke:#F59E0B,color:#78350F,font-weight:600; classDef ok fill:#D1FAE5,stroke:#178A66,color:#0F172A; classDef endNode fill:#1D9E75,stroke:#178A66,color:#FFFFFF,font-weight:600; classDef note fill:#F1F5F9,stroke:#94A3B8,color:#475569,font-style:italic;
⚠️ Piège IBM
Confusion Order Unit vs Issue Unit — Les candidats inversent les deux rôles, ou supposent qu'ils doivent être identiques. Ils sont délibérément distincts pour permettre d'acheter en packs vendor-friendly et de consommer en unités shop-floor friendly.
- Piège : penser que Order Unit = comment Maximo stocke le on-hand. Faux — INVBALANCES est toujours en Issue Units.
- Piège : penser que le Conversion Factor est sur l'UoM. Faux — il vit sur le record Conversion (paire d'UoM) ou sur l'Item-Specific Conversion (item + paire d'UoM).
- Piège : supposer qu'un item ne peut avoir qu'une seule Order Unit. En pratique, les scénarios multi-vendor utilisent des item-specific conversions pour gérer le pack de chaque vendor.
🎯 Carte mémoire
Q. Un item a Order Unit = CARTON et Issue Unit = EACH. Le conversion factor est 12. Vous recevez 5 CARTON. Comment la balance on-hand du storeroom est-elle mise à jour ?
Afficher la réponse
Le on-hand du storeroom augmente de 60 EACH (5 CARTON × 12 EACH/CARTON). INVBALANCES stocke toujours les quantités en Issue Unit ; Maximo applique la conversion automatiquement à la réception.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — IBM teste la dissociation entre l'unité d'achat et l'unité de consommation. C'est le concept fondateur de la sous-rubrique 5.1, et c'est aussi le piège le plus classique : les candidats inversent les deux rôles ou supposent qu'ils sont identiques.
Le contexte théorique d'abord — En gestion des stocks, deux UoM (Unit of Measure) coexistent par item. L'Order Unit est l'unité utilisée pour transiger avec le fournisseur sur le bon de commande (PO). L'Issue Unit est l'unité dans laquelle l'item est consommé contre un bon de travail. Le Conversion Factor relie les deux dans la table CONVERSION. Cette dissociation est nécessaire parce que les fournisseurs vendent en formats économiques (carton, palette, baril) tandis que les techniciens consomment à l'unité.
Ce que Maximo en fait — version opérationnelle — Sur Item Master > champs Order Unit et Issue Unit, le planner saisit les deux UoMs. La conversion globale est créée via More Actions → Add/Modify Conversions avec la paire (CARTON, EACH) et le facteur 12. Si un autre fournisseur livre le même item en pack de 10, le planner ajoute une conversion item-specific via Item Master → More Actions → Conversions qui surcharge la valeur globale pour cet item précis. Au moment du receipt PO, MATRECTRANS enregistre la quantité en Issue Unit et INVBALANCES est mis à jour en EACH.
Exemple chiffré — Vous commandez 5 CARTONs (Order Unit) de bearings au prix de 60 $/CARTON. À la réception, Maximo applique le facteur 12 : 5 × 12 = 60 EACH ajoutés au storeroom. Le coût unitaire en Issue Unit est 60 $ / 12 = 5 $/EACH, qui sera la base du calcul WAC sur le prochain receipt.
Analogie quotidienne — Pensez à l'épicerie : vous achetez les œufs par douzaine (Order Unit = DOZEN) mais vous les consommez un à un dans la recette (Issue Unit = EACH). Le frigo affiche 12 œufs, pas "1 douzaine".
Pourquoi A est faux — Option A inverse complètement les rôles. Order Unit = EACH supposerait qu'on commande au fournisseur unité par unité, ce qui contredit le scénario (cartons de 12). Issue Unit = CARTON forcerait le technicien à émettre 1 carton complet contre chaque WO, gaspillant 11 pièces. C'est le pattern D3 (Inverse) classique. Cette configuration aurait du sens uniquement dans le cas inverse : un fournisseur qui livre à l'unité mais où l'usine packagerait elle-même en cartons pour l'expédition vers des sites satellites — scénario très rare.
Pourquoi B est faux — Option B met les deux UoM identiques (EACH/EACH) et tente de placer le facteur 12 sur la conversion EACH→EACH. Cela contredit la mécanique Maximo : un facteur de conversion entre une UoM et elle-même est nécessairement 1. Pattern D4 (Partial-truth) : l'idée d'un facteur 12 est correcte, mais il appartient à la paire (CARTON, EACH), pas à (EACH, EACH). Si appliqué tel quel, Maximo refuserait la validation car deux conversions identiques sur la même paire ne peuvent pas exister.
Pourquoi D est faux — Option D affirme que Order Unit et Issue Unit doivent toujours être identiques, et que le pack est capturé uniquement sur la PO line. C'est l'antithèse même du modèle Maximo. Pattern D7 (Non-existent) : il n'y a aucune contrainte forçant l'égalité des deux UoMs. Mettre la taille de pack sur la PO ligne par ligne fonctionnerait mais perdrait toute la logique de catalogue (chaque PO devrait re-saisir le facteur). C'est précisément ce que la dissociation Order Unit / Issue Unit + Conversion existe pour éviter.
- Order Unit — unité fournisseur (CARTON, BOX, BARREL). Apparaît sur PO et PR.
- Issue Unit — unité technicien (EACH, LITER, METER). Apparaît sur WO, Inv Usage, INVBALANCES.
- Conversion (global) — paire (UoM_from, UoM_to, factor). Partagée par tous les items qui utilisent cette paire.
- Item-Specific Conversion — surcharge locale lorsque le facteur diffère selon l'item (multi-fournisseurs).
- Translation au receipt — qty_issue_unit = qty_order_unit × conversion_factor.
- Order Unit = achat (PO). Issue Unit = consommation (WO).
- Conversion factor lie les deux. Stockage interne en Issue Unit toujours.
- Item-specific conversion = override pour un item particulier.
- STU 5.1 — Add/Modify Units of Measure + Add/Modify Conversions
- master-map.pdf p.787-832 — Inventory module, Item Master UoM section
- [EOTRAG] Query 7 — UNSPSC and Maximo UoM mapping
Correct :B
Pourquoi cette question existe — IBM teste la connaissance du mécanisme d'override item-spécifique. C'est un concept clé de la sous-rubrique 5.1 explicitement listé dans les STU. Beaucoup de candidats ne réalisent pas qu'une conversion globale peut être surchargée localement.
Le contexte théorique d'abord — Dans tout système ERP/EAM, les master data sont organisées en couches : valeurs globales (Item Set ou Organization) puis surcharges locales (Item, Storeroom, Vendor). Cette hiérarchie permet de mutualiser la majorité des cas tout en absorbant les exceptions sans dupliquer le master record. Pour les UoM Conversions, Maximo applique exactement ce pattern : la table CONVERSION contient les facteurs globaux ; quand un item a besoin d'une autre valeur, on insère une ligne dans la table d'overrides item-spécifiques.
Ce que Maximo en fait — version opérationnelle — Le chemin est Item Master → sélectionner l'item → More Actions → Conversions → New Row. On y saisit la paire (CARTON, EACH) avec un facteur 10. Cette ligne devient effective uniquement pour cet item ; tous les autres items utilisant la paire CARTON→EACH continuent d'utiliser le 12 global. Au receipt, Maximo cherche d'abord une conversion item-spécifique pour la paire concernée ; si trouvée, il l'applique ; sinon, il revient à la conversion globale.
Exemple chiffré — Vendor A livre 5 CARTONs (12 EACH chacun) → 60 EACH ajoutés. Vendor B livre 5 CARTONs (10 EACH chacun) → 50 EACH ajoutés grâce à la conversion item-spécifique. Sans l'override, Maximo aurait calculé 5 × 12 = 60 EACH dans les deux cas, créant un écart d'inventaire de 10 unités à chaque receipt du vendor B.
Analogie quotidienne — Le règlement général d'un immeuble dit "un stationnement par appartement". Mais l'unité 502 a obtenu une dérogation pour deux places. Le règlement global reste à 1 ; l'override sur l'unité 502 vaut 2. Les autres unités continuent à 1.
Pourquoi A est faux — Modifier le conversion global de 12 à 10 corromprait toutes les autres références d'items qui utilisent CARTON→EACH avec le pack standard de 12. Les receipts du vendor principal (et tous les autres items en cartons de 12) recevraient désormais 10 EACH au lieu de 12, créant des écarts d'inventaire massifs. Pattern D4 (Partial-truth) : le facteur 10 est juste pour le vendor B, mais l'application au global est destructrice.
Pourquoi C est faux — Créer un Item Master en double avec une UoM "CARTON-10" est une mauvaise pratique de master data. Pattern D10 (Procedure-plausible) : l'idée semble fonctionner mais elle introduit deux ITEMNUM différents pour le même produit physique, casse les agrégations de coût, fausse les ROP, multiplie les erreurs d'écriture sur WO. Maximo a justement créé l'item-specific conversion pour éviter ce duplicata.
Pourquoi D est faux — Convertir manuellement à chaque receipt PO ligne par ligne va contre l'objectif de l'automatisation Maximo. Pattern D7 (Non-existent) : il n'existe pas de champ "manual conversion override" sur la PO line dans le standard ; la conversion est toujours appliquée par référence aux tables CONVERSION ou ITEM_CONVERSION. La saisie manuelle à chaque receipt est une source d'erreur humaine et n'est pas auditable.
- Conversion globale — table CONVERSION. Paire (UoM_from, UoM_to, factor). Partagée Set/Org.
- Item-Specific Conversion — table override par item. Trouvée en priorité par Maximo au receipt.
- Règle de précédence — Item-specific > Global. Maximo cherche le plus spécifique d'abord.
- Cas d'usage type — Multi-fournisseur sur même item avec packs différents.
- Item-specific conversion override le global, JAMAIS l'inverse.
- Ne jamais modifier le global pour résoudre un cas item.
- Ne jamais dupliquer un Item Master pour gérer un pack différent.
- STU 5.1 — Item-Specific Conversions verbatim
- master-map.pdf p.787-832 Inventory / Item Master Conversions tab
- [EOTRAG] cross-cutting synthesis on master data layering
Correct :D
Pourquoi cette question existe — IBM vérifie que vous comprenez la mécanique de translation au receipt et que vous savez où Maximo stocke réellement la quantité on-hand. Beaucoup d'utilisateurs novices pensent qu'INVBALANCES garde l'unité de la PO ou laisse à l'utilisateur le choix.
Le contexte théorique d'abord — Tout système d'inventaire mature stocke ses balances dans une unité canonique par item, parce que les calculs de ROP, EOQ, valuation et issue partent d'une seule UoM stable. Permettre à INVBALANCES de varier entre receipts en différentes Order Units détruirait toute possibilité d'agrégation : on ne pourrait pas additionner 3 CARTONs et 50 EACH du même item. La canonisation à l'Issue Unit est une convention universelle (SAP MM, Oracle Inventory, Infor EAM, Maximo).
Ce que Maximo en fait — version opérationnelle — Au moment du receipt PO, le module Receiving consulte la conversion DRUM→LITER, multiplie la quantité reçue (3 DRUM) par le facteur 200, et écrit 600 LITER dans MATRECTRANS et dans INVBALANCES.QTY. Le coût unitaire est aussi rebasé en LITER : si la DRUM coûte 400 $, le coût en Issue Unit devient 400/200 = 2 $/LITER. Toutes les transactions ultérieures (issue, transfer, count) opèrent en LITER.
Exemple chiffré — 3 DRUM × 200 LITER/DRUM = 600 LITER. Au coût total de 1200 $ (3 × 400 $), le WAC devient 2 $/LITER. Un technicien qui consomme 50 LITER pour un graissage WO chargera 100 $ au WO, sans jamais voir l'unité DRUM.
Analogie quotidienne — Vous achetez 3 caisses de 24 canettes (Order Unit = CASE). Le frigo n'affiche pas "3 caisses" mais "72 canettes". Vous consommez canette par canette, jamais caisse par caisse. Le frigo est l'INVBALANCES.
Pourquoi A est faux — 3 DRUM préserverait l'Order Unit dans INVBALANCES. C'est une vision intuitive ("ce que j'ai reçu, c'est 3 drums") mais incorrecte au niveau système. Pattern D3 (Inverse) : c'est l'inverse de la convention de canonisation. Si Maximo faisait cela, le technicien qui consomme 50 LITER se retrouverait avec une balance fractionnée (2.75 DRUM ?) ce qui briserait à la fois l'UI et les calculs ROP.
Pourquoi B est faux — 200 LITER suppose qu'un seul drum est compté, ignorant que le receipt couvre 3 drums. Pattern D4 (Partial-truth) : la conversion 1 DRUM = 200 LITER est correcte, mais il faut multiplier par la quantité reçue. Cette option teste si le candidat applique la conversion par unité reçue plutôt que en bloc.
Pourquoi C est faux — 3 LITER est absurde et confond le rôle de la quantité reçue avec le rôle du facteur. Pattern D9 (Near-synonym) : "3" ressemble à "3 drums" et "LITER" est l'unité Issue, mais la combinaison ignore complètement le facteur 200. Cette option piège les candidats qui voient les chiffres "3 et 200" et choisissent au hasard.
- INVBALANCES.QTY — toujours en Issue Unit. Convention universelle.
- MATRECTRANS — enregistre la quantité au format Issue Unit, mais conserve trace de l'Order Unit dans RECEIPTQTY/RECEIPTUNIT pour audit.
- Coût unitaire — rebasé : cost_per_issue_unit = cost_per_order_unit / conversion_factor.
- Formule — qty_invbalances = qty_received × conversion(order_unit→issue_unit).
- INVBALANCES est toujours en Issue Unit, jamais en Order Unit.
- 3 DRUM × 200 = 600 LITER. C'est la formule de translation.
- Le coût aussi est rebasé : cost_per_issue_unit = cost_per_order_unit / factor.
- STU 5.1 — UoM at Item Master + Conversion Factor
- master-map.pdf p.787-832 Inventory module
- [EOTRAG] Query 14 — MATRECTRANS / INVBALANCES tables
Correct :A
Pourquoi cette question existe — IBM teste le chemin exact de l'action Add/Modify Units of Measure, qui est listé verbatim dans les STU 5.1. C'est une question de fluence Maximo : connaître les libellés exacts des More Actions évite les pièges D5 (Sibling-field).
Le contexte théorique d'abord — Dans Maximo, les UoM appartiennent à une table partagée au niveau Item Set ou Organization. Définir une UoM est distinct de définir une conversion : la première est un code taxonomique (PALLET, BOX, KG) ; la seconde est une relation arithmétique entre deux UoMs. La séparation reflète le modèle relationnel sous-jacent : UNITSOFMEASURE est une table de référence ; CONVERSION est une table d'associations.
Ce que Maximo en fait — version opérationnelle — Le chemin GUI est Item Master → More Actions → Add/Modify Units of Measure → New Row. On y saisit le code PALLET, son label long, et on sauvegarde. La nouvelle UoM est immédiatement utilisable comme Order Unit ou Issue Unit sur n'importe quel item du même Item Set. Pour qu'elle ait du sens, il faudra ensuite créer une ou plusieurs conversions (PALLET→BOX, PALLET→EACH) via une autre action séparée (Add/Modify Conversions).
Exemple chiffré — Vous ajoutez PALLET via Add/Modify Units of Measure. Vous l'utilisez sur un item de plywood comme Order Unit (commande au fournisseur en palettes). Vous configurez ensuite Add/Modify Conversions avec PALLET→SHEET = 50. Au receipt de 2 PALLETs, INVBALANCES s'incrémente de 100 SHEETs (Issue Unit).
Analogie quotidienne — D'abord on ajoute "litre" au dictionnaire. Ensuite on ajoute "1 litre = 1000 millilitres" dans la table de conversions. Définir l'unité ≠ définir la relation entre unités.
Pourquoi B est faux — Add/Modify Conversions est l'action voisine, utilisée pour créer la relation entre deux UoMs existantes. Pattern D5 (Sibling-field) : c'est le piège typique parce que les deux actions sont dans le même menu More Actions et leur libellé se ressemble. Mais Add/Modify Conversions ne permet pas de créer une nouvelle UoM ; elle ne fait qu'ajouter une ligne dans CONVERSION en référençant deux UoMs existantes.
Pourquoi C est faux — Add Inventory Balance ajuste la quantité on-hand d'un item dans un storeroom donné. Pattern D6 (Wrong-app) : cette action existe mais dans Inventory, pas pour gérer les UoM. Elle est utilisée pour les ajustements manuels (mismatch d'inventaire, écriture initiale en go-live). Aucun lien avec la création d'une UoM.
Pourquoi D est faux — "Manage Stock Categories" n'existe pas comme action standard dans Maximo Manage v9.1. Pattern D7 (Non-existent) : ce libellé fabriqué tente d'évoquer une fonction de classification (commodity codes, ABC, condition codes). Aucune des trois ne correspond. C'est un piège pur.
- Add/Modify Units of Measure — table UNITSOFMEASURE. Crée le code (PALLET, KG, EACH).
- Add/Modify Conversions — table CONVERSION. Crée la relation entre deux UoMs (factor).
- Order de création — UoM d'abord, conversion ensuite. Une UoM peut exister sans conversion.
- Application Item Master — actions accessibles via le menu More Actions.
- Add/Modify Units of Measure = créer une UoM (le code).
- Add/Modify Conversions = créer une relation entre deux UoM (le facteur).
- Item Master > More Actions héberge les deux.
- STU 5.1 — Add/Modify Units of Measure verbatim
- master-map.pdf p.787-832 — Inventory module Item Master More Actions menu
- IBM Maximo Manage 9 documentation — UoM admin actions
Correct :C
Pourquoi cette question existe — Beaucoup de candidats pensent que les UoM ne s'appliquent qu'aux items physiques. Les services (calibrage, audit, contrats) sont aussi des items dans Maximo et exigent des UoMs cohérentes pour générer les coûts et les charges WO correctement.
Le contexte théorique d'abord — Dans la théorie des inventaires, un item est tout ce qui est commandé, reçu et chargé contre un work order : matériel physique, outil, ou service. Les services se distinguent par le fait qu'ils ne s'accumulent pas dans une bin, mais ils ont quand même besoin d'une unité de mesure pour la facturation : un service de calibrage à 500 $ "par instrument" se mesure en EACH, un contrat de maintenance "par heure" se mesure en HOUR.
Ce que Maximo en fait — version opérationnelle — Sur Item Master, le champ "Type" peut être ITEM, SERVICE, TOOL, etc. Pour un SERVICE, on définit Order Unit = EACH (ou HOUR, JOB, VISIT) et Issue Unit identique. La case "Inventoried" est typiquement désactivée pour les services (pas de bin balance). Néanmoins l'UoM est requise car elle est référencée par le PO (qty × cost) et par l'Inv Usage si l'on veut tracer la consommation à un WO.
Exemple chiffré — Item "EQUIP_CALIB" (type SERVICE), Order Unit = EACH, Issue Unit = EACH, prix 500 $. Une PO de 4 instruments à calibrer = 4 EACH × 500 $ = 2000 $. Maximo crée un MATRECTRANS sans incrémenter d'INVBALANCES (non-inventoried) mais charge les 2000 $ sur le compte GL du WO référencé.
Analogie quotidienne — Quand vous payez un plombier "à l'heure", vous achetez en HOUR. Quand vous payez un service de réparation forfaitaire (ex : remplacement écran iPhone 200 $), vous achetez en EACH. La nature du service dicte l'UoM, mais l'UoM est toujours nécessaire pour la facturation.
Pourquoi A est faux — Affirmer que les service-type items ne requièrent pas d'UoM est faux. Pattern D7 (Non-existent) : Maximo exige une UoM sur tout Item Master, indépendamment du type. Sans UoM, la PO ne peut pas calculer un coût total (qty × unit_cost) et le rejet de validation se produirait à la sauvegarde.
Pourquoi B est faux — Il n'existe pas d'UoM réservée nommée "SERVICE" dans Maximo standard. Pattern D2 (Invented) : c'est une UoM fabriquée. Le candidat peut l'imaginer plausible parce que "SERVICE" sonne comme une catégorie spéciale, mais aucun standard out-of-the-box ne le contient. Les services utilisent des UoMs existantes : EACH, HOUR, VISIT, MONTH, etc.
Pourquoi D est faux — Les service-items vivent bien dans Item Master (avec type=SERVICE), pas dans Companies. Pattern D6 (Wrong-app) : Companies stocke les fournisseurs eux-mêmes, pas les services qu'ils fournissent. Un fournisseur "Lab Calibration Inc" est dans Companies, mais le service "EQUIP_CALIB" qu'il fournit est dans Item Master. La distinction est essentielle pour relier PO ligne à un item identifiable et tracer la consommation au niveau item.
- Item Type ITEM — physique, inventoried, UoM EACH/KG/L.
- Item Type SERVICE — non-inventoried, UoM EACH ou HOUR ou VISIT, charge directe au WO.
- Item Type TOOL — outil, peut être rotating, UoM EACH typiquement.
- UoM obligatoire — pour tous les types, sans exception.
- Service-type item = UoM obligatoire (EACH, HOUR, VISIT...).
- Pas d'UoM "SERVICE" réservée — utilise une UoM standard.
- Service vit dans Item Master (type=SERVICE), pas dans Companies.
- STU 5.1 — UoM in Item Master
- STU 5.2 — Using commodity codes against service-type items (related)
- master-map.pdf p.787-832 Inventory / Item Master types
Commodity Groups et codes

📋 Objectifs IBM
- Référencer les items à un Commodity Group et à un Commodity Code (hiérarchie 2 niveaux)
- Maintenir la hiérarchie commodity via l'action Add/Modify Commodity Codes
- Comprendre comment les comptes GL peuvent être reliés aux commodity codes pour la catégorisation des dépenses
- Appliquer des commodity codes aux service-type items (calibration, contrats, inspections)
💡 Points clés
- Hiérarchie commodity — Le modèle de classification Maximo utilise 2 niveaux : Commodity Group (le parent, ex. ELEC) et Commodity Code (l'enfant, ex. ELEC-MOTOR). Les deux sont référencés depuis le record Item Master.
- Path d'action — Item Master → More Actions → Add/Modify Commodity Codes (ou via l'application Inventory pour assignation cross-item).
- Spend analysis — en agrégeant les lignes PO et invoice par commodity code, les équipes procurement identifient les fournisseurs dupliqués, négocient des volume discounts et consolident les achats.
- Mapping GL account — le Commodity Group et/ou le Commodity peuvent être associés à des comptes GL par défaut (Inventory, Expense, COGS). Cela automatise le GL coding sur les lignes PR/PO : quand un acheteur ajoute un item avec commodity ELEC-MOTOR, le compte expense par défaut est rempli automatiquement.
- Alignement UNSPSC — le modèle 2 niveaux Maximo est une projection simplifiée du UNSPSC (United Nations Standard Products and Services Code, 4 niveaux : Segment, Family, Class, Commodity). La plupart des organisations mappent UNSPSC Class au Maximo Commodity Group et UNSPSC Commodity au Maximo Commodity Code [EOTRAG Query 7].
- Les service-type items utilisent aussi les commodity codes — un item « Calibration Service » est classé sous, par ex., SERV / SERV-CAL, permettant la restriction côté vendor (seuls les labos peuvent quoter des POs SERV-CAL).
- Restriction commodity côté Vendor (Companies) — les Companies peuvent être liées aux commodities qu'elles fournissent, pilotant les auto-suggestions sur les PRs et bloquant les vendors non qualifiés.
- Détection des items dupliqués — les items dans le même commodity code avec des descriptions similaires sont flaggés comme candidats à l'harmonisation (qualité master-data).
- Pourquoi deux niveaux et pas quatre — IBM a choisi la simplicité plutôt que les 4 niveaux UNSPSC car les données empiriques montrent que 80% de la spend analysis est utile au niveau Class+Commodity. Les organisations nécessitant une granularité plus fine utilisent des outils MDM externes (Verdantis Harmonize, SwainSmith) [EOTRAG Query 7].
- Reporting et analytics — la plupart des KPI « spend by category » utilisent les commodity codes comme dimension. Sans eux, seule l'agrégation au niveau ITEMNUM est possible — inutile pour le category management.
- Codes de taxe — certaines juridictions lient les taux de taxe aux commodity codes (ex. exemptions PST pour les « lubrifiants à usage industriel »). Maximo supporte l'assignation de tax code par commodity.
graph TD ROOT["Hiérarchie Commodity
2 niveaux FIXÉS
(STU §5.2)"]:::root ELEC["Commodity Group
ELEC — Électrique"]:::group MECH["Commodity Group
MECH — Mécanique"]:::group INSTR["Commodity Group
INSTR — Instrumentation"]:::group EM["Code : ELEC-MOTOR
GL 6210"]:::code EB["Code : ELEC-BEARING
GL 6220"]:::code MP["Code : MECH-PUMP
GL 6310"]:::code MV["Code : MECH-VALVE
GL 6320"]:::code IT["Code : INSTR-TRANS
GL 6410"]:::code ITEM["Record Item Master
référence
Commodity Group + Code"]:::item POPR["PR / PO / Issue
récupère auto
le GL account"]:::flow ROOT --> ELEC ROOT --> MECH ROOT --> INSTR ELEC --> EM ELEC --> EB MECH --> MP MECH --> MV INSTR --> IT EM -.-> ITEM EB -.-> ITEM MP -.-> ITEM MV -.-> ITEM IT -.-> ITEM ITEM --> POPR classDef root fill:#1D9E75,stroke:#178A66,color:#FFFFFF,font-weight:600; classDef group fill:#3B82F6,stroke:#1E40AF,color:#FFFFFF,font-weight:600; classDef code fill:#FFFFFF,stroke:#94A3B8,color:#0F172A; classDef item fill:#FEF3C7,stroke:#F59E0B,color:#78350F; classDef flow fill:#D1FAE5,stroke:#178A66,color:#0F172A,font-weight:600;
⚠️ Piège IBM
Confusion Commodity Group vs Commodity Code — Les candidats pensent souvent qu'ils sont interchangeables ou que l'un est optionnel. Ils sont distincts, hiérarchiques, et les deux sont typiquement renseignés.
- Piège : supposer qu'on ne peut pas assigner de commodity codes aux service items. Faux — les services utilisent les commodities comme les items physiques.
- Piège : penser que les commodity codes pilotent l'ABC analysis. Ils ne le font pas — l'ABC est basée sur la valeur de consommation, calculée séparément.
- Piège : confondre Commodity Group avec Item Set ou Storeroom. Ce sont des abstractions différentes : l'Item Set groupe des records d'item ; le Storeroom groupe des locations ; le Commodity Group classe les items par catégorie.
🎯 Carte mémoire
Q. Quelle est la relation entre Commodity Group et Commodity Code dans Maximo ?
Afficher la réponse
Hiérarchie à 2 niveaux : Commodity Group est le parent (catégorie large comme ELEC = Électrique), Commodity Code est l'enfant (spécifique comme ELEC-MOTOR = moteur électrique). Un item référence les deux champs. Maintenue via l'action Add/Modify Commodity Codes.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — IBM teste la connaissance précise du modèle Commodity de Maximo, qui est explicitement listé dans les STU 5.2 comme "2-level hierarchy". Beaucoup de candidats confondent avec UNSPSC (4 niveaux) ou avec d'autres taxonomies plus profondes utilisées dans des EAM concurrents.
Le contexte théorique d'abord — En Master Data Management, la classification des items est typiquement structurée en arbre avec 3 à 5 niveaux pour permettre des agrégations multi-granulaires. UNSPSC, le standard mondial de GS1 US, utilise 4 niveaux × 2 chiffres = code 8 chiffres : Segment (familles d'industrie) → Family → Class → Commodity (item le plus spécifique). eCl@ss (européen) est encore plus profond. Maximo a choisi un modèle simplifié à 2 niveaux pour rester opérationnel et facile à maintenir, sachant que la profondeur supplémentaire peut être atteinte via codes externes (UNSPSC ID référencé en Alt-ID sur l'item).
Ce que Maximo en fait — version opérationnelle — L'application Item Master expose deux champs : Commodity Group (ELEC, MECH, INSTR, SERV) et Commodity (ELEC-MOTOR, MECH-BEARING, etc.). La maintenance se fait via More Actions → Add/Modify Commodity Codes, qui ouvre un dialog hiérarchique. Lorsqu'on crée un Commodity Code, on doit lui assigner un Commodity Group parent. Cette structure 2-niveaux est fixe dans le data model standard ; l'ajout d'un troisième niveau requiert customization Maximo (non couvert par C1000-208).
Exemple chiffré — Vous créez le groupe ELEC (parent) puis 3 codes : ELEC-MOTOR, ELEC-CABLE, ELEC-PANEL. Sur 5000 items dans Item Master, vous classez 800 items en ELEC dont 200 sous ELEC-MOTOR, 400 sous ELEC-CABLE, 200 sous ELEC-PANEL. Les rapports de spend par groupe agrègent ELEC à 1.2 M $ ; un drill-down distingue ELEC-MOTOR à 600 K $.
Analogie quotidienne — Pensez aux rayons d'épicerie : "Boissons" (group) → "Boissons gazeuses" (commodity code). Le rayonnage ne descend pas au niveau marque ou format individuel ; ces détails sont sur l'item lui-même. Cela donne à un manager une vue exploitable sans le noyer dans 1000 sous-catégories.
Pourquoi A est faux — Option A décrit UNSPSC, pas le modèle Maximo. Pattern D9 (Near-synonym) : le candidat connaît UNSPSC et suppose que Maximo l'implémente directement. C'est faux ; Maximo référence UNSPSC indirectement via mapping mais sa structure native est à 2 niveaux. C'est aussi vrai que la taille des codes UNSPSC (8 chiffres) ne correspond pas aux codes alphanumériques courts utilisés dans Maximo (ELEC-MOTOR, par exemple).
Pourquoi B est faux — Une liste plate sans hiérarchie ne permettrait pas l'agrégation par catégorie, qui est précisément l'usage principal des commodity codes. Pattern D2 (Invented) : ce modèle est plausible pour un système naïf mais ne reflète pas Maximo. La présence du champ Commodity Group distinct du champ Commodity dans Item Master prouve qu'il y a hiérarchie.
Pourquoi D est faux — Trois niveaux Group/Subgroup/Item est un modèle qu'on retrouve dans Infor EAM ou SAP MM mais pas dans Maximo standard. Pattern D7 (Non-existent) : aucune table Maximo n'expose un troisième niveau intermédiaire. Le piège fonctionne sur les candidats qui ont travaillé sur un autre EAM et présument une parité.
- Maximo Commodity — 2 niveaux : Group (ELEC) → Code (ELEC-MOTOR).
- UNSPSC — 4 niveaux : Segment / Family / Class / Commodity.
- Mapping standard — UNSPSC Class → Maximo Group ; UNSPSC Commodity → Maximo Code.
- Maintenance — Item Master → More Actions → Add/Modify Commodity Codes.
- Maximo Commodity = 2 niveaux (Group + Code), PAS 4 (UNSPSC).
- Group = parent ; Code = enfant. Hiérarchie obligatoire.
- Action : Add/Modify Commodity Codes.
- STU 5.2 — Reference items to a Commodity Group and Commodity Code (2-level hierarchy)
- [EOTRAG] Query 7 — UNSPSC vs Maximo 2-level Commodity
- master-map.pdf p.787-832 Inventory / Item Master Commodity fields
Correct :B
Pourquoi cette question existe — Le libellé exact d'action est listé verbatim dans les STU. Cette question teste votre fluence avec les noms d'action Maximo, qui est l'un des terrains de jeu favoris d'IBM pour piéger les candidats.
Le contexte théorique d'abord — Maximo organise ses fonctionnalités d'administration sous des libellés d'action très précis, accessibles via le menu "More Actions" (anciennement "Select Action"). Ces libellés sont stables d'une version à l'autre et constituent une partie de la "langue" Maximo qu'un BA doit maîtriser. La règle d'or : le libellé exact existe dans le menu ou il n'existe pas du tout.
Ce que Maximo en fait — version opérationnelle — Le chemin est Item Master → More Actions → Add/Modify Commodity Codes. Le dialog ouvre une vue arborescente : on sélectionne (ou on crée) un Commodity Group, puis on ajoute un ou plusieurs Commodity Codes en dessous. Les changements sont immédiatement disponibles pour assignation aux items. La même action est aussi accessible via les applications Companies (côté vendor) et Inventory (côté storeroom).
Exemple chiffré — Vous ouvrez Add/Modify Commodity Codes. Vous créez "INSTR" (parent), puis trois enfants : INSTR-PRESS (capteurs de pression), INSTR-TEMP (capteurs de température), INSTR-FLOW (débitmètres). Vous sauvegardez. Sur les 50 items d'instrumentation, vous pouvez maintenant assigner Commodity Group = INSTR et Commodity = INSTR-PRESS (par exemple) en quelques clics, puis lancer un rapport "spend by INSTR" pour identifier les opportunités de consolidation des achats.
Analogie quotidienne — Dans iTunes/Spotify on a "Genre" et "Sous-genre". L'action "Edit Genres" permet de créer la structure ; ensuite chaque chanson est taggée. C'est exactement le même pattern : on définit la taxonomie d'abord, on tagge les éléments ensuite.
Pourquoi A est faux — "Manage Commodity Hierarchy" est un libellé fabriqué qui sonne plausible mais n'existe pas. Pattern D7 (Non-existent) : c'est typique des distracteurs IBM — un nom inventé qui sonne professionnel pour piéger les candidats qui se rappellent vaguement avoir vu quelque chose dans le menu. Toujours vérifier le libellé exact contre la documentation officielle.
Pourquoi C est faux — "Configure Item Categories" évoque vaguement la classification mais ne correspond à aucune action standard Maximo. Pattern D9 (Near-synonym) : "Categories" et "Codes" sonnent similaire dans la sémantique anglaise. Mais Maximo utilise "Commodity Codes" précisément ; le mot "Category" appartient à d'autres modules (ex: Asset Category, GL Category) qui n'ont rien à voir avec les commodities.
Pourquoi D est faux — Set Item Classification dans Organizations app touche aux Item Sets et aux configurations multi-org, pas aux commodity codes. Pattern D6 (Wrong-app) : Organizations contient des configurations administratives globales (Item Sets, Currency, Inventory Defaults) ; les commodity codes ne s'y trouvent pas. La gestion se fait depuis les apps métier (Item Master, Inventory) où le contexte est plus naturel.
- Add/Modify Commodity Codes — l'action canonique. Disponible dans Item Master, Companies, Inventory.
- Add/Modify Conversions / Add/Modify Units of Measure — actions sœurs dans le même menu pour UoM.
- Set Item Classification — différent : configure les Item Sets multi-org.
- Stratégie d'apprentissage — les libellés d'action verbatim sont du par cœur sur l'examen C1000-208.
- Action exacte : Add/Modify Commodity Codes.
- PAS "Manage Hierarchy" ni "Configure Categories" ni "Set Classification".
- Accessible depuis Item Master > More Actions.
- STU 5.2 — Add/Modify Commodity Codes verbatim
- master-map.pdf p.787-832 Item Master More Actions menu
- IBM Maximo Manage 9 — Commodity Codes administration
Correct :A
Pourquoi cette question existe — Le STU 5.2 demande explicitement "How GL accounts can be related to commodity codes". C'est un objectif d'apprentissage à part entière. IBM teste si vous comprenez le mécanisme de défaut GL au niveau Commodity, qui est l'un des avantages organisationnels majeurs des commodity codes.
Le contexte théorique d'abord — En finance, le GL coding (chart of accounts assignment) est un exercice rébarbatif et source d'erreur. Les bonnes pratiques ERP automatisent ce coding via des hiérarchies de défauts : une transaction prend le GL du Storeroom, sinon de l'Item, sinon de la Commodity, sinon du défaut Org. Maximo implémente exactement cette hiérarchie. Les commodity codes deviennent donc un levier majeur de gouvernance financière sans toucher à chaque item individuellement.
Ce que Maximo en fait — version opérationnelle — Sur le record Commodity Code (ouvert via Add/Modify Commodity Codes), un champ GL Account permet d'attacher un compte par défaut. Quand un buyer crée une PR avec un item dont le Commodity = LUBES, et que le storeroom n'a pas de GL forcé, Maximo utilise automatiquement 6201-LUBES en pré-remplissage. Le buyer peut surcharger si nécessaire. La même logique s'applique pour Inventory issues, Item receipts et tous les flux générant une écriture comptable.
Exemple chiffré — Vous avez 200 items "lubricants" classés sous Commodity = LUBES. Sans automation, chaque PR de lubrifiant exige une saisie GL manuelle (200 × ~5 PR/an = 1000 saisies à risque d'erreur). Avec une seule association GL au niveau Commodity, les 1000 PR sont automatiquement codées correctement.
Analogie quotidienne — Quand vous catégorisez vos dépenses bancaires : "épicerie" = compte ALIM, "essence" = compte AUTO. Chaque transaction n'a pas besoin d'être codée manuellement ; la catégorie le fait. Le commodity code dans Maximo joue exactement ce rôle.
Pourquoi B est faux — Hardcoder le GL sur chaque item individuellement est techniquement possible mais opérationnellement insoutenable. Pattern D10 (Procedure-plausible) : un BA débutant peut penser "il suffit de mettre le GL sur l'item record". Mais quand on a 5000 items, le coût de maintenance explose, les erreurs prolifèrent, et les changements de plan comptable deviennent impossibles à propager. La hiérarchie Maximo est explicitement conçue pour éviter ce piège.
Pourquoi C est faux — Affirmer que les GL accounts ne peuvent pas être liés aux commodity codes est faux. Pattern D7 (Non-existent) : c'est précisément le mécanisme listé dans les STU. Le piège fonctionne sur les candidats qui n'ont pas étudié le STU 5.2 en détail et qui supposent que GL = storeroom only. La hiérarchie de précédence GL est : Storeroom > Item > Commodity > Org default — toutes ces couches sont configurables.
Pourquoi D est faux — Un workflow custom pourrait techniquement faire ce que le défaut Commodity fait nativement, mais c'est jeter de la complexité sur un problème déjà résolu out-of-the-box. Pattern D4 (Partial-truth) : oui, les workflows peuvent toucher au GL, mais ils sont over-kill ici. La meilleure pratique est d'utiliser le mécanisme déclaratif (Commodity GL) avant de tomber dans le procedural (workflow). Maximo punit fortement la sur-customization qui vient en lieu et place de la configuration native.
- Hiérarchie de défaut GL — Storeroom > Item > Commodity > Org default.
- GL on Commodity — un seul changement = 200 items couverts. Maintenance simple.
- Surcharge utilisateur — l'utilisateur peut toujours changer manuellement le GL sur la PR/PO line.
- Bonne pratique — utilizer Commodity GL pour 80% des cas, item-level GL pour les exceptions critiques.
- GL peut être attaché au Commodity Group / Code = automatisation pour 200 items en 1 clic.
- Hiérarchie : Storeroom > Item > Commodity > Org.
- Préférer la configuration déclarative (commodity) au workflow procédural.
- STU 5.2 — How GL accounts can be related to commodity codes
- master-map.pdf p.787-832 — Commodity Codes GL field
- IBM Maximo Manage 9 — GL precedence hierarchy
Correct :D
Pourquoi cette question existe — Le STU 5.2 mentionne explicitement "Using commodity codes against service-type items". IBM teste si le candidat comprend que l'usage des commodity codes ne se limite pas au stock physique mais s'applique aussi aux services achetés.
Le contexte théorique d'abord — Dans une entreprise industrielle moderne, les services représentent souvent 30 à 50 % des dépenses MRO (calibration, inspection régulementaire, expertise tierce, contrats de maintenance). La category management des services est aussi importante que celle des items physiques. Sans commodity codes sur les services, le procurement perd la visibilité sur cette portion majeure des dépenses, ce qui empêche la consolidation des fournisseurs et la négociation de tarifs unitaires.
Ce que Maximo en fait — version opérationnelle — Un Item Master de type SERVICE peut renseigner les champs Commodity Group et Commodity Code exactement comme un item physique. La logique GL/spend/vendor restriction s'applique identiquement. Sur une PR pour "Annual Pressure Vessel Inspection", le commodity = SERV-INSP filtre la liste des fournisseurs aux seuls labs accrédités, applique le GL 6300-INSPECTION par défaut, et alimente les rapports de spend par catégorie.
Exemple chiffré — Une usine dépense 800 K $/an en inspections. Avec 15 fournisseurs différents et aucun classement, impossible de négocier. Avec commodity SERV-INSP, le rapport spend révèle que 5 fournisseurs représentent 90 % du volume → consolidation possible vers 2 fournisseurs préférés avec économie de 8-15 % grâce aux volumes consolidés.
Analogie quotidienne — Une famille classe ses dépenses en "alimentation", "transport", "loisirs". Que ce soit un produit (épicerie) ou un service (restaurant), la catégorie capture toutes deux. Les services méritent leur classification autant que les produits.
Pourquoi A est faux — Affirmer que les commodity codes sont réservés aux items physiques contredit le STU explicitement. Pattern D7 (Non-existent) : il n'y a aucune contrainte de type d'item dans le data model des commodity codes ; tout Item Master, quel que soit son type (ITEM, SERVICE, TOOL), peut référencer Commodity Group et Commodity. Cette restriction inventée pourrait sembler logique au candidat qui pense que "code de commodité" implique "marchandise tangible", mais c'est une fausse intuition lexicale.
Pourquoi B est faux — Restriction au type TOOL est arbitraire et fausse. Pattern D4 (Partial-truth) : oui, les TOOL items peuvent avoir des commodity codes, mais cette permission est universelle, pas exclusive. Le piège fonctionne sur les candidats qui se rappellent que TOOL est un type spécial dans Maximo et infèrent (à tort) une contrainte exclusive.
Pourquoi C est faux — Il n'existe pas d'application "Service Items" séparée dans Maximo Manage v9.1. Pattern D6 (Wrong-app) : tous les items, services compris, vivent dans Item Master, identifiés par leur champ Type. La fabrication d'une app séparée est un piège classique pour les candidats qui présument de la séparation par module.
- Item types — ITEM, SERVICE, TOOL — tous dans Item Master.
- Commodity codes universels — applicable à tous les types.
- Service categorization typique — SERV-CAL (calibration), SERV-INSP (inspection), SERV-MAINT (maintenance contracts).
- Bénéfice — spend analysis et vendor restriction sur les services autant que sur les items physiques.
- Service-type items utilisent commodity codes aussi.
- Pas d'app "Service Items" séparée — tout dans Item Master.
- Bénéfice : spend analysis sur 30-50 % des dépenses MRO (services).
- STU 5.2 — Using commodity codes against service-type items
- master-map.pdf p.787-832 Item Master Type field + Commodity fields
- [EOTRAG] Query 7 — Commodity Codes use cases
Correct :B
Pourquoi cette question existe — IBM teste votre compréhension de la cross-application des commodity codes : ils ne vivent pas seulement sur Item Master mais aussi sur Companies (vendors). Cette dualité crée la valeur de catégorisation pour le procurement.
Le contexte théorique d'abord — En procurement, le vendor master record doit déclarer les catégories de produits/services qu'il fournit. C'est la base de la qualification fournisseur (sourcing) et du category management. Sans cette déclaration, on ne peut ni prequalifier les vendors par catégorie, ni restreindre les RFQs aux fournisseurs pertinents, ni produire des rapports de couverture (combien de vendors couvrent chaque catégorie ?). Maximo respecte ce pattern via la table COMPANY_COMMODITIES qui associe vendor ↔ commodity.
Ce que Maximo en fait — version opérationnelle — Dans Companies → ouvrir le vendor → onglet Commodities, on ajoute les commodities supportées (ex : MECH-BRG, MECH-SEAL pour un fournisseur de bearings). Au moment de créer une PR avec un item dont commodity=MECH-BRG, Maximo filtre la liste de selection vendor pour ne montrer que les fournisseurs qui ont déclaré supporter cette commodity. Cela accélère la saisie et applique les règles de gouvernance procurement.
Exemple chiffré — 200 fournisseurs dans Companies. Sans liens commodity, le buyer voit la liste complète sur chaque PR — recherche manuelle, erreurs. Avec liens, sur une PR de bearings, la liste se réduit à 8 fournisseurs qualifiés. Temps de traitement PR -40 %, erreurs de selection vendor -90 %.
Analogie quotidienne — Sur Amazon, chaque vendor déclare les catégories qu'il vend (mode, électronique, livres). Quand vous cherchez "livres", Amazon ne vous montre que les vendors livres. C'est le même mécanisme déclaratif côté fournisseur.
Pourquoi A est faux — L'onglet Vendors d'Item Master existe et permet d'attacher des fournisseurs spécifiques à un item, mais ce n'est pas le bon endroit pour la déclaration au niveau commodity. Pattern D6 (Wrong-app) : on confond l'item-level vendor list (un item, plusieurs vendors qui le fournissent) avec le commodity-level (un vendor, plusieurs commodities qu'il fournit). Les deux sont nécessaires mais distincts. La question demande explicitement le mapping commodity ↔ vendor.
Pourquoi C est faux — Saisir le lien à chaque PR line est inverse de l'objectif d'automatisation. Pattern D5 (Sibling-field) : la PR line a effectivement un champ vendor, mais c'est l'application de la règle, pas sa déclaration. Le sourcing vendor par commodity DOIT être déclaré une fois (Companies) puis utilisé partout (PR, RFQ, contracts).
Pourquoi D est faux — Le storeroom n'a pas d'onglet Vendor au sens de cette question. Pattern D7 (Non-existent) : il y a bien des champs liés à l'approvisionnement sur le storeroom (Internal Vendor pour transferts inter-storeroom) mais pas de gestion commodity-vendor. C'est encore une fois le piège de l'app voisine.
- Companies → Commodities tab — déclaration vendor-side (un vendor, ses commodities).
- Item Master → Vendors tab — déclaration item-side (un item, ses fournisseurs spécifiques).
- Hiérarchie d'inférence — sur PR, Maximo cherche d'abord les vendors item-level, puis les vendors commodity-level.
- Bénéfice — vendor restriction par catégorie + accélération de saisie + gouvernance procurement.
- Vendor ↔ Commodity = Companies app, onglet Commodities.
- Item ↔ Vendor = Item Master app, onglet Vendors.
- Les deux niveaux coexistent et se complètent sur PR.
- STU 5.2 — Reference items to a Commodity Group and Commodity Code
- [EOTRAG] Query 7 — vendor-commodity restriction use case
- master-map.pdf p.787-832 Companies app + Inventory Item Master
Condition Codes

📋 Objectifs IBM
- Configurer les Condition Codes pour les items : créer un identifiant de code et un label
- Expliquer comment un condition rate impacte les coûts d'inventory (cost = NEW × rate)
- Expliquer comment le condition rate impacte le receiving process (downgrade à la réception, balance séparée)
- Marquer les items comme condition-enabled dans Item Master pour activer le tracking par condition
💡 Points clés
- Condition Code — une classification (ex. NEW, REFURBISHED, USED, REBUILT) qui capture l'état physique d'un item, avec un condition rate numérique (un multiplicateur ≤ 1,0 appliqué au coût NEW).
- Sémantique du condition rate — NEW = 1,0 (coût plein), REFURBISHED = 0,7 (70% de NEW), USED = 0,5, REBUILT = 0,6 (exemples typiques). Les rates sont définis au niveau organisation et éditables.
- Formule de coût —
issue_cost = new_cost × condition_rate. Un motor à 100 $ NEW coûte 100 $ ; à REFURBISHED (0,7) il coûte 70 $ ; à USED (0,5) il coûte 50 $. - Où les items deviennent condition-enabled — sur le record Item Master (PAS dans l'application Inventory — voir SAM Q9). Mettre « Condition Enabled = Yes » sur Item Master indique à Maximo de tracer des balances séparées par condition.
- Balances séparées par condition — INVBALANCES a une ligne par (item, storeroom, bin, condition). 5 NEW + 3 REFURBISHED du même item = 2 lignes distinctes.
- Réception avec condition — à la réception PO, le receveur saisit la condition réelle ; si la condition reçue diffère de celle de la PO, Maximo ajuste le coût via le rate. Un « motor NEW à 100 $ » reçu comme REFURBISHED est enregistré à 70 $.
- Holding location pendant l'inspection — les items requérant inspection vivent dans une Holding Location avec statut WINSP (waiting inspection). Après vérification QA de la condition, les items passent à STORES au coût déterminé.
- Logique d'issue — la reservation WO peut spécifier une condition souhaitée (ex. « doit être NEW pour les pièces sécuritaires »). La pick list filtre le stock disponible par condition. Si la reservation est condition-agnostic, Maximo issue en FIFO à travers les conditions.
- Interaction cost methods — les condition rates s'appliquent par-dessus les cost methods (FIFO/AVG/LIFO/STD). Le cost method détermine quelle layer est consommée ; le condition rate ajuste le prix de la layer.
- Changement rétroactif — changer le condition rate d'un item ne re-cost PAS le stock on-hand ; seules les futures issues utilisent le nouveau rate [EOTRAG Query 9].
- Lotted items vs condition-enabled — préoccupations orthogonales. Les lots tracent les batches de fabrication (paint batch 2024-04-A) ; les conditions tracent l'état physique. Les deux peuvent coexister.
- Cas d'usage industriel — les rotating items (motors, pumps) qui passent par des cycles repair/refurb bénéficient particulièrement du tracking par condition ; cela permet de porter des stocks séparés « NEW spare » + « REBUILT-2nd-tier spare » avec un costing précis.
⚠️ Piège IBM
Où active-t-on « condition-enabled » ? — SAM Q9 verbatim. Le flag vit sur Item Master, pas dans Inventory ni dans Condition Codes. Cela trompe les candidats qui confondent le rôle de chaque application.
- Piège : penser que l'application Condition Codes est l'endroit où on active un item. Faux — l'app Condition Codes ne fait que DÉFINIR les codes (NEW/REFURB/...) et leurs rates ; l'activation par item est sur Item Master.
- Piège : supposer que changer le rate rétroactivement re-cost le stock on-hand. Faux — seules les futures issues sont affectées.
- Piège : penser que condition-enabled implique inspection-required. Ce sont des réglages indépendants.
🎯 Carte mémoire
Q. Un bearing REFURBISHED a un condition rate 0,7. Le coût NEW est de 200 $. Quel est le coût d'issue quand ce bearing est consommé sur une WO ?
Afficher la réponse
Coût d'issue = 200 $ × 0,7 = 140 $. Maximo poste 140 $ comme material cost de la WO et réduit la balance de stock REFURBISHED en conséquence. INVBALANCES trace la ligne REFURBISHED séparément de la ligne NEW.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — La formule cost = NEW × condition_rate est le cœur de la sous-rubrique 5.3. IBM teste systématiquement la mécanique de calcul, parce qu'elle a un impact direct sur la valorisation des stocks et sur les charges WO.
Le contexte théorique d'abord — En comptabilité d'inventaire, un item refurbisé n'a pas la même valeur économique qu'un item neuf, même s'il accomplit la même fonction. Le marché secondaire reconnaît cette différence : un moteur "rebuilt" se vend 50-70 % du neuf en ré-utilisation. Le système d'inventaire doit refléter cette réalité économique pour donner une comptabilité juste : sous-évaluer les refurb's = surestimer les profits ; les surévaluer = gonfler artificiellement le bilan. Maximo implémente la comptabilité conditionnelle via une multiplicateur < 1 appliqué au coût NEW.
Ce que Maximo en fait — version opérationnelle — Au moment de l'issue (Inv Usage → onglet Lines), si l'item est condition-enabled, Maximo lit le condition rate de la ligne sélectionnée (REFURB = 0.6), récupère le NEW cost depuis INVCOST, et calcule cost = NEW × rate. Le MATUSETRANS est inséré avec ISSUECOST = 300 $, et le WO actual cost est incrémenté de 300 $ (non 500 $). La balance condition REFURB diminue d'1 unité.
Exemple chiffré — Stock initial : 5 NEW à 500 $/unité (valeur 2500 $) + 3 REFURB à condition rate 0.6 (valeur 3 × 500 × 0.6 = 900 $). Total inventaire = 3400 $. Issue 1 REFURB : MATUSETRANS cost = 300 $ ; WO chargé à 300 $ ; INVBALANCES.qty REFURB = 2 ; valeur après = 3400 - 300 = 3100 $.
Analogie quotidienne — Quand vous achetez une voiture d'occasion, vous payez moins que le prix du neuf — disons 60 % du PDSF. La même voiture en accident-recovered (rebuilt) tomberait à 40 %. Le condition rate Maximo capture exactement cette logique de décote sur l'item.
Pourquoi A est faux — Affirmer que le rate n'impacte que le reporting est faux. Pattern D7 (Non-existent) : Maximo applique réellement la décote sur la transaction, pas seulement dans les rapports. Le piège fonctionne sur les candidats qui supposent que les "codes de classification" sont décoratifs. Erreur : ils sont arithmétiques.
Pourquoi B est faux — 500 + (500 × 0.6) = 800 $ inverse la sémantique du rate. Pattern D3 (Inverse) : un rate de 0.6 implique 60 % du NEW, pas NEW + 60 %. Cette confusion est classique chez les candidats qui ont travaillé avec des "majorations" (uplift) au lieu de décote (markdown).
Pourquoi D est faux — Diviser le NEW par le rate (500 / 0.6 = 833 $) inverse complètement la formule. Pattern D4 (Partial-truth) : le candidat se rappelle qu'il y a une opération arithmétique mais inverse l'opérande. La formule juste est une multiplication, pas une division. Cette confusion vient parfois du calcul TVA inversé (où on divise pour extraire HT du TTC).
- Formule — issue_cost = NEW_cost × condition_rate.
- Rates typiques — NEW=1.0, REFURB=0.7, USED=0.5, REBUILT=0.6.
- Application — au moment de l'issue (MATUSETRANS), pas au receipt.
- Effet WO — le coût WO reflète la réalité économique (refurb moins cher que neuf).
- cost = NEW × rate. Multiplication, JAMAIS division ni addition.
- $500 NEW × 0.6 REFURB = $300 issue cost.
- Le rate impacte la transaction, pas seulement le reporting.
- STU 5.3 — Condition rate impacts inventory costs
- [EOTRAG] Query 9 — Cost impact: cost = NEW × condition_rate
- master-map.pdf p.787-832 — Condition Codes application + Item Master condition-enabled
Correct :C
Pourquoi cette question existe — Cette question (paraphrase de SAM Q9) teste la séparation des responsabilités entre les applications. C'est un piège fréquent : les candidats associent intuitivement "condition" à l'app Inventory ou Condition Codes, alors que l'activation se fait au niveau Master Data (Item Master).
Le contexte théorique d'abord — Dans toute architecture EAM, on distingue trois couches d'applications : (1) Master Data (Item Master, Companies, Locations) qui définit les règles et propriétés intrinsèques d'une entité ; (2) Transactionnel (Inventory, PO, WO) qui exécute les flux ; (3) Référence/Configuration (Condition Codes, Cost Types, Currency) qui fournit les codes utilisés par les Master Data. Activer une fonctionnalité à propos d'un item (être condition-enabled, être rotating, être lotted) appartient à la couche Master Data, pas à la couche transactionnelle.
Ce que Maximo en fait — version opérationnelle — Le chemin est Item Master → ouvrir l'item → checkbox "Condition Enabled" sur le main tab. Une fois cochée, Maximo crée automatiquement les structures pour suivre les balances séparées par condition. L'application Condition Codes est utilisée pour DÉFINIR les codes (NEW, REFURB) et leurs rates, mais ne marque aucun item. L'application Inventory affiche les balances par condition mais ne contrôle pas l'activation. Le storeroom non plus.
Exemple chiffré — Vous voulez gérer 50 motors avec balance séparée NEW/REFURB. Vous ouvrez chacun (ou un batch) dans Item Master et cochez "Condition Enabled". Vous allez ensuite dans Condition Codes pour s'assurer que NEW=1.0 et REFURB=0.7 existent. Vous regardez Inventory pour voir 2 lignes par item (NEW row + REFURB row). Trois apps, trois rôles distincts.
Analogie quotidienne — Pour activer le mode "Économie d'énergie" sur votre frigo, vous cliquez le bouton sur le frigo lui-même (Item Master = la machine). La liste des modes possibles ("Éco", "Boost", "Holiday") est dans le manuel (Condition Codes = la référence). Le contenu du frigo (Inventory) reflète l'effet du mode mais ne le configure pas.
Pourquoi A est faux — Inventory expose les balances par condition (vous y verrez "5 NEW + 3 REFURB" pour un item condition-enabled), mais l'activation s'y fait pas. Pattern D6 (Wrong-app) : c'est le piège le plus fréquent parce que "logiquement", l'inventaire devrait gérer la condition. Mais la séparation Master Data ↔ Inventory exige que l'activation soit au niveau item record, pas au niveau balance.
Pourquoi B est faux — Storerooms gère les locations physiques (bin, holding, etc.) mais pas les propriétés intrinsèques d'un item. Pattern D5 (Sibling-field) : on est dans la même galaxie d'applications mais pas le bon record. Activer condition au niveau storeroom n'aurait pas de sens — un même item dans deux storerooms aurait deux activations contradictoires.
Pourquoi D est faux — Condition Codes définit les codes mais ne lie aucun item. Pattern D8 (Keyword-echo) : "Condition" dans le nom de l'app fait croire au candidat que c'est l'endroit naturel. C'est précisément le type de piège que SAM Q9 tend explicitement, et l'expérience montre que beaucoup de candidats tombent dedans.
- Item Master — checkbox "Condition Enabled" — active la fonctionnalité par item.
- Condition Codes app — définit les codes (NEW, REFURB, USED) et leurs rates.
- Inventory app — affiche les balances séparées par condition (read mostly).
- Storerooms app — gère les locations, pas les propriétés item.
- Condition-enabled = checkbox sur Item Master.
- Condition Codes app = définit les codes, ne marque AUCUN item.
- Inventory app = montre les balances, n'active pas la fonctionnalité.
- STU 1.1 + 5.3 — condition-enabled flag on Item Master (SAM Q9 verbatim is in lesson 1.1)
- [EOTRAG] Query 9 — condition-enabled items management
- master-map.pdf p.787-832 Item Master fields
Correct :B
Pourquoi cette question existe — Le STU 5.3 demande explicitement "how condition rate impacts the receiving process". C'est un objectif distinct de l'impact sur les coûts d'inventaire. IBM teste si vous comprenez que le condition rate s'applique aussi à la réception, pas seulement à l'issue.
Le contexte théorique d'abord — Le receiving est un point de contrôle qualité dans la chaîne d'approvisionnement : ce qui est reçu peut différer de ce qui était commandé (état dégradé, lot mélangé, mauvais modèle). Les bonnes pratiques EAM permettent de capturer cet écart au receipt, en ajustant à la fois la quantité, le coût et la classification. Sans ce mécanisme, on devrait soit refuser le receipt, soit l'accepter au mauvais coût et corriger plus tard via ajustement — deux options coûteuses.
Ce que Maximo en fait — version opérationnelle — Au receipt PO, le receiving clerk ouvre l'écran Select Items for Receipt et peut overrider le condition code de la ligne. Si la PO disait NEW (rate 1.0) à 500 $ et le receveur indique REFURBISHED (rate 0.6), Maximo recalcule cost_at_receipt = 500 × 0.6 = 300 $. Le MATRECTRANS row porte le coût ajusté ; INVBALANCES incrémente la ligne REFURB de cet item (pas la ligne NEW) avec qty=5 et cost=300/unit. La PO de référence reste à 500 $/unité (référence contractuelle), mais l'inventaire reflète la réalité physique. Une variance comptable est typiquement écrite au compte "Purchase Price Variance" pour les 5 × 200 = 1000 $ d'écart.
Exemple chiffré — PO : 5 motors à 500 $ NEW = 2500 $ engagement. Reception : 5 motors REFURB → cost réel = 5 × 300 = 1500 $. INVBALANCES.cost = 1500 $. PPV (variance) = 2500 - 1500 = 1000 $. Ce 1000 $ doit être renégocié avec le fournisseur (downward price adjustment ou crédit) ou écrit en perte si la PO est figée.
Analogie quotidienne — Vous commandez un téléphone neuf à 1000 $ et l'on vous livre un modèle reconditionné. Vous demandez un crédit de 30 % (rate = 0.7). La facture finale = 700 $, c'est ce que vous comptabilisez dans vos dépenses, pas 1000 $. La différence est une "variance" qui s'écrit dans un compte d'ajustement.
Pourquoi A est faux — Préserver le 500 $ original ignore complètement la fonctionnalité de condition rate au receipt. Pattern D7 (Non-existent) : Maximo prévoit la fonctionnalité d'override exactement parce que ce cas se présente. Conserver le coût NEW alors que l'item est REFURB inflerait artificiellement la valeur d'inventaire et fausserait toutes les WOs ultérieures qui consomment cet item.
Pourquoi C est faux — Rejeter le receipt parce que la condition diffère est une approche rigide qui n'existe pas dans Maximo. Pattern D2 (Invented) : le candidat peut imaginer une validation stricte mais Maximo est conçu pour l'agilité — accepter le receipt avec ajustement plutôt que bloquer le flux. Sinon le storeroom serait souvent en attente de re-livraison, ce qui contredirait l'objectif de availability.
Pourquoi D est faux — Recevoir à 0 $ "until manual override" est procéduralement plausible (on pourrait imaginer un workflow d'attente) mais ne correspond pas au comportement standard. Pattern D10 (Procedure-plausible) : Maximo applique automatiquement le rate via la condition sélectionnée, sans passer par un état intermédiaire à 0 $. Ce serait inutile et créerait des bugs comptables temporaires.
- Receipt cost adjustment — cost_at_receipt = PO_unit_cost × condition_rate.
- INVBALANCES split — la quantité va dans la ligne de la condition réellement reçue, pas celle de la PO.
- Purchase Price Variance (PPV) — l'écart entre PO et receipt va dans un compte de variance.
- Renegotiation — la variance peut justifier un crédit fournisseur post-receipt.
- Condition rate s'applique AU RECEIPT et à l'ISSUE.
- 5 motors à 500 $ NEW reçus REFURB (0.6) = 5 × 300 $.
- L'écart va en Purchase Price Variance, pas perdu.
- STU 5.3 — Condition rate impacts receiving process
- [EOTRAG] Query 9 — Receiving with inspection + condition
- master-map.pdf p.787-832 Receiving + Condition Codes
Correct :A
Pourquoi cette question existe — Le RAG insiste explicitement sur ce trap : "changing an item's condition rate retroactively does NOT re-cost existing on-hand stock; it only affects future issues" [EOTRAG Query 9]. C'est un piège classique parce que les candidats supposent que les changements de configuration sont rétroactifs.
Le contexte théorique d'abord — En comptabilité, les principes de stabilité (consistency, conservatism) imposent que les coûts unitaires figés à la transaction restent intangibles. Re-costuer rétroactivement créerait des écritures comptables massives et auditables sans contrepartie réelle (les items physiques sont les mêmes). C'est pourquoi tous les ERP/EAM modernes verrouillent les coûts au niveau transaction : le receipt fixe le coût, l'issue le débourse, la fin. Les ajustements de paramètres futurs n'affectent que le futur.
Ce que Maximo en fait — version opérationnelle — Le rate REFURB est stocké dans la table CONDITIONCODE (au niveau organization). INVBALANCES.UNITCOST par contre est figé à la valeur calculée au moment du receipt. Quand l'admin change le rate de 0.7 à 0.5, seuls les receipts suivants (et leurs issues) appliquent 0.5. Les 4 units à 350 $ chacun restent à 350 $ jusqu'à leur consommation totale. Si un nouvel receipt arrive après le changement, ce nouveau lot est valorisé à 250 $/unit ; une issue après le changement utilisera le coût de la layer FIFO/AVG correspondante (350 ou 250 selon le cas).
Exemple chiffré — Initial : 4 units REFURB à 350 $ = 1400 $. Change rate à 0.5. Nouveau receipt de 2 REFURB → cost = 500 × 0.5 = 250 $/unit, qui s'ajoute à INVBALANCES. Maintenant : 6 units à valeur mixte (4 × 350 + 2 × 250 = 1900 $). Si méthode AVG : avg cost devient 1900/6 = 316.67 $. Si FIFO : prochaine issue draws 350 $/unit jusqu'à épuisement des 4 anciennes. Aucune écriture comptable rétroactive n'est faite.
Analogie quotidienne — Vous achetez 4 livres à 20 $ chacun. Une promo apparaît la semaine suivante : les nouveaux exemplaires se vendent 12 $. Votre bibliothèque ne re-évalue pas les 4 livres déjà achetés ; ils restent à 20 $ dans votre comptabilité personnelle. Seuls les nouveaux achats sont à 12 $.
Pourquoi B est faux — Re-coster automatiquement avec écriture GL est l'inverse de la convention. Pattern D3 (Inverse) : ce serait une opération destructrice, déclenchant des audits internes pour expliquer les "écritures de réajustement", chose que les CFOs détestent. Maximo (et tout ERP sain) interdit cette logique pour préserver l'auditabilité.
Pourquoi C est faux — Bloquer le changement de rate quand stock existe serait excessivement restrictif. Pattern D7 (Non-existent) : Maximo permet le changement à tout moment ; c'est l'effet sur le stock existant qui est nul, pas l'opération elle-même qui est bloquée. Le piège fonctionne sur les candidats qui présument une validation surprotectrice.
Pourquoi D est faux — Écrire off les units en quarantine est une procédure inventée. Pattern D2 (Invented) : il n'existe aucun mécanisme automatique de ce genre. Les changements de paramètres ne touchent jamais aux balances physiques de Maximo.
- Cost figé au receipt — INVBALANCES.UNITCOST stable jusqu'à consommation.
- Rate change = futur seulement — pas de re-cost rétroactif.
- Mix de coûts — possibilité d'avoir des units à 350 $ et 250 $ dans la même balance REFURB après changement.
- Principe comptable — consistency + conservatism = pas de re-cost rétroactif.
- Changement de rate = futur seulement, JAMAIS rétroactif.
- Stock existant garde son coût figé au receipt.
- Si AVG : nouveau receipt mixe ; si FIFO : ancien stock sort en premier.
- STU 5.3 — Condition rate setup
- [EOTRAG] Query 9 — "changing an item's condition rate retroactively does NOT re-cost existing on-hand stock"
- master-map.pdf p.787-832 — Condition Codes admin behaviour
Correct :D
Pourquoi cette question existe — Le RAG cite verbatim ce mécanisme : « Quand une réservation spécifie une condition pour un item, les items qui satisfont l'exigence de condition sont sélectionnés au fur et à mesure du travail sur la liste » [EOTRAG Query 9]. IBM teste si vous comprenez le rôle de la condition dans le workflow de picking, pas seulement dans le costing.
Le contexte théorique d'abord — Pour les items condition-enabled, le système doit non seulement tracer les balances séparément mais aussi permettre la consommation conditionnelle. Sinon, l'effort de séparation serait inutile : on tracerait NEW vs REFURB pour le rapport mais on consommerait au hasard. Maximo lie donc la reservation (la demande) à la condition (la propriété physique requise) pour garantir que le pick list présente uniquement le stock approprié.
Ce que Maximo en fait — version opérationnelle — Quand le planner crée une reservation sur le WO (ou via job plan), il peut sélectionner condition = NEW dans la ligne de réservation. Au moment du picking, l'écran "Issue Items" filtre l'INVBALANCES par condition correspondante : seules les 2 units NEW apparaissent comme disponibles. Les 5 REFURB sont masquées (ou marquées indisponibles pour cette reservation). Le storeroom clerk ne peut physiquement pas issue un REFURB contre cette reservation. Si la reservation ne spécifie pas de condition, Maximo applique FIFO across conditions selon la cost method.
Exemple chiffré — WO safety-critical réserve 1 bearing condition=NEW. Pick list montre seulement 2 units NEW disponibles. Issue se fait sur l'une des 2 NEW, balance NEW = 1, balance REFURB inchangée à 5. Le coût WO = NEW unit cost (ex 200 $), pas refurb cost. Si le planner avait omis condition, Maximo aurait pu issuer un REFURB selon la stratégie FIFO/AVG, ce qui aurait été dangereux pour le critical safety WO.
Analogie quotidienne — En pharmacie, votre prescription dit "comprimés sans gluten". Le pharmacien filtre son inventaire et ne vous présente que les boîtes sans gluten. Les autres existent en stock mais ne vous concernent pas. La reservation Maximo joue ce rôle de filtre.
Pourquoi A est faux — FIFO ignorant la condition est l'inverse du comportement Maximo pour items condition-enabled. Pattern D2 (Invented) : la dépendance sur la vérification visuelle du technicien est précisément ce que Maximo veut éliminer. Le système doit forcer la sélection conditionnelle pour assurer la sécurité, pas la déléguer à l'humain.
Pourquoi B est faux — Créer un item Master en double "NEW-only bearing" duplicate la complexité et casse le tracking unifié. Pattern D10 (Procedure-plausible) : un BA débutant peut imaginer cette workaround mais c'est exactement ce que les conditions sont conçues pour éviter. Un seul Item Master + 2 conditions est plus propre que 2 Items Masters.
Pourquoi C est faux — Affirmer que la condition n'est applicable qu'au receipt contredit l'usage core des condition-enabled items. Pattern D7 (Non-existent) : la fonctionnalité s'applique sur tout le cycle de vie : receipt, issue, return, transfer. Le piège fonctionne sur les candidats qui n'ont étudié qu'un seul aspect (le receipt) sans saisir la portée complète.
- Reservation condition — champ sur WO Materials line. Force le filtrage du pick list.
- Pick list filtering — INVBALANCES filtré par condition au moment du picking.
- Réservation sans condition — Maximo applique FIFO toutes conditions confondues par défaut.
- Use case safety-critical — toujours spécifier condition=NEW pour les WOs régulés.
- Condition sur reservation = filtrage automatique du pick list.
- Le filtrage protège les WOs safety-critical contre l'issue accidentel de refurb.
- Sans condition spécifiée = Maximo applique FIFO toutes conditions confondues.
- STU 5.3 — Condition Codes setup
- [EOTRAG] Query 9 — Reservation condition filtering verbatim
- master-map.pdf p.787-832 Reservations + Pick List
Réception d'Items et Tools

📋 Objectifs IBM
- Réceptionner les Materials, Tools et Items requérant inspection depuis une Purchase Order
- Comprendre les statuts Receiving : WAPPR, WMATL, COMP, WINSP, WASSET
- Réceptionner les Tools depuis une PO avec le même workflow que les items
- Réceptionner les Rotating Items depuis une PO et réaliser l'Asset Serialization
- Appliquer les Item Assembly Structures (IAS) pour auto-créer les child assets à la réception
- Définir le process flow Rotating Items Receipt Status
- Gérer le Shipment Receiving : Partial Shipment Receipts et Shipment Receipt Status
- Décrire le rôle de la Holding Location pour les receipts inspection-required
- Utiliser l'Inventory Receiving Role-Based Application (RBA) pour un receiving rationalisé
💡 Points clés
- Receiving — le processus d'acquittement que les materials/tools/services commandés ont été livrés. Le receipt crée une ligne MATRECTRANS, incrémente INVBALANCES (ou envoie en Holding pour inspection), et peut déclencher la création d'un AP voucher.
- Statuts Receiving (champ RECEIPTSTATUS) : WAPPR = waiting approval, WASSET = waiting asset/serialization, WINSP = waiting inspection (en Holding Location), COMP = complete (item entièrement intégré à l'inventory).
- Items requérant inspection — les items avec flag « Inspection Required » (réglé sur Item Master ou par politique site) vont dans la Holding Location au statut WINSP après réception ; la QA inspecte, approuve ou rejette ; à l'approbation, le statut passe à COMP et INVBALANCES est mis à jour.
- Holding Location — une location storeroom spéciale qui détient les items en transit/inspection. Le stock là-bas n'est PAS encore disponible pour issue. Une fois l'inspection passée, les items passent au bin storeroom final via un transfert automatique.
- Rotating items à la réception — réceptionner un rotating item EXIGE du receveur de réaliser l'Asset Serialization : chaque unité reçue génère un ASSETNUM unique avec un numéro de série. 5 rotating motors reçus = 5 ASSETNUM créés dans l'app Assets.
- Cascade Item Assembly Structure (IAS) — si l'Item Master du rotating item a une IAS définie (ex. MOTOR_ASSY → PUMP, BEARING, SEAL), l'Asset Serialization crée non seulement le parent asset mais aussi les enfants, avec les relations préservées.
- Tools depuis une PO — les tools suivent le même flow de réception que les items d'inventaire mais alimentent les tables de l'application Tools. Les rotating tools sont aussi sérialisés.
- Shipment Receiving — pour les transferts inter-storeroom ou inter-site (Stock Transfer Order). L'acquittement de réception au destination met à jour les balances à la source et au destination via MATUSETRANS à la source + MATRECTRANS au destination [EOTRAG Query 14].
- Partial Shipment Receipts — une ligne PO peut être réceptionnée sur plusieurs shipments. Chaque shipment crée sa propre ligne MATRECTRANS ; la ligne PO trace la qty cumulée jusqu'à COMP.
- Inventory Receiving RBA (Role-Based Application) — une UI rationalisée pour le receiving clerk, avec scan barcode, saisie de ligne simplifiée et lookup PO direct. Alternative modernisée à l'app Receiving classique.
- Coût de réception — par cost method : le receipt met à jour AVGCOST dans la table INVCOST (WAC), ou ajoute une nouvelle layer (FIFO/LIFO), ou est verrouillé au standard (STANDARD).
- Contexte industriel — le projet Maximo à la Centrale d'équipements (MEQ) distingue explicitement les items de grande valeur requérant la sérialisation des consommables [EOTRAG Query 14] : « Les articles de grande valeur ou dont le numéro de série doit être suivi seront des actifs tournants ».
flowchart TD PO["PO créée
(approuvée + envoyée au vendor)"]:::start RECV["Goods physiquement reçus
au dock de réception"]:::action Q1{"Flag item
Inspect on
Receipt ?"}:::decision HOLD["Holding Location
statut = WINSP
(waiting inspection)
PAS dans la balance active"]:::warn QA{"Résultat
inspection QA ?"}:::decision QUAR["Quarantine bin
Statut Receipt : REJECTED
→ Void ou Return-to-Vendor
(selon STU §6.2)"]:::stop STORE["Bin storeroom actif
balance += receipt_qty
statut = STORES"]:::ok Q2{"Flag item
Rotating ?"}:::decision SERIAL["Asset Serialization
1 unité reçue →
1 ASSETNUM créé
(ASSET cost = receipt cost)"]:::action Q3{"Item Assembly
Structure (IAS)
définie ?"}:::decision IAS["Application cascade IAS
auto-création des
ASSETNUM enfants
(BOM déployé en
sub-assets)"]:::action DONE["Receipt complet
ligne MATRECTRANS
+ posting GL"]:::endNode PO --> RECV RECV --> Q1 Q1 -- Oui --> HOLD HOLD --> QA QA -- Reject --> QUAR QA -- Approve --> STORE Q1 -- Non --> STORE STORE --> Q2 Q2 -- Non --> DONE Q2 -- Oui --> SERIAL SERIAL --> Q3 Q3 -- Non --> DONE Q3 -- Oui --> IAS IAS --> DONE classDef start fill:#3B82F6,stroke:#1E40AF,color:#FFFFFF,font-weight:600; classDef decision fill:#F59E0B,stroke:#B45309,color:#FFFFFF; classDef action fill:#FFFFFF,stroke:#94A3B8,color:#0F172A; classDef warn fill:#FEF3C7,stroke:#F59E0B,color:#78350F; classDef ok fill:#1D9E75,stroke:#178A66,color:#FFFFFF; classDef stop fill:#EF4444,stroke:#991B1B,color:#FFFFFF; classDef endNode fill:#F1F5F9,stroke:#94A3B8,color:#0F172A;
⚠️ Piège IBM
Confusion sur la Holding Location — Les candidats oublient souvent que la Holding Location est un point de transit virtuel. Le stock là-bas est RECEIVED mais PAS ENCORE DISPONIBLE pour issue.
- Piège : confondre la Holding Location avec le bin standard du storeroom. Ils sont distincts.
- Piège : penser que l'Asset Serialization est optionnelle pour les rotating items. Elle est obligatoire à la réception — on ne peut pas compléter un receipt PO rotating sans saisir les numéros de série.
- Piège : penser que la cascade IAS auto exige la création manuelle des enfants. Faux — quand une IAS est définie sur l'item parent, Maximo auto-crée les enfants à la sérialisation.
- Piège : supposer que les partial receipts ferment la ligne PO. Elles ne le font pas — la ligne PO reste ouverte jusqu'à ce que la qty cumulée = qty commandée (ou que la PO soit fermée manuellement).
🎯 Carte mémoire
Q. Un rotating item avec IAS définie comme MOTOR_ASSY → 3 enfants (PUMP, BEARING, SEAL) est réceptionné depuis une PO de 1 unité. Combien de records ASSETNUM sont créés ?
Afficher la réponse
4 records ASSETNUM : 1 parent (MOTOR_ASSY) + 3 enfants (PUMP, BEARING, SEAL). L'Asset Serialization à la réception cascade à travers l'IAS, créant l'asset parent et tous les child assets avec les relations parent-enfant correctement préservées dans l'application Assets.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — Le STU 6.1 explicitement liste "Receive Items / Materials / Tools that Require Inspections" et "describe Holding Location". IBM teste votre compréhension du double-stage receipt : staging d'abord, then approval, then activation. C'est un piège classique parce que les candidats supposent un flux direct PO → bin.
Le contexte théorique d'abord — En logistique industrielle, l'inspection à la réception est une étape qualité critique pour les items à risque (matières premières dangereuses, composants critiques, items réglementés). Le contrôle vise à valider la conformité au PO (modèle, quantité), la qualité (état physique, certifications fournies, lot expirations), et la traçabilité (numéros de série, batch IDs). Le standard ISO 9001 exige cette inspection comme jalon documenté. Sans staging intermédiaire, un item non-conforme pourrait être issued à un WO avant inspection, créant un risque safety/quality.
Ce que Maximo en fait — version opérationnelle — Quand un item flag "Inspection Required" est reçu, Maximo crée le MATRECTRANS row avec RECEIPTSTATUS = WINSP. INVBALANCES n'est PAS incrémenté dans la bin standard ; à la place, une row est ajoutée à la Holding Location du storeroom. La quantité disponible pour issue reste à zéro tant que l'inspection n'est pas validée. Le module Inspection (ou QA reviewer) ouvre les receipts WINSP, examine, et marque "Inspect" → COMP. Sur cette transition, Maximo génère automatiquement un transfert de Holding → bin standard, INVBALANCES s'ajuste, et la quantité devient disponible.
Exemple chiffré — PO de 50 valves, inspection required. Reception 50 unités. Holding Location balance = 50 ; storeroom bin balance reste à 0. QA inspecte 50 unités : 48 conformes, 2 défectueuses. QA marque 48 as approved → Holding -= 48, Bin += 48. Pour les 2 défectueuses, vendor return procedure démarrée (return-to-vendor MATRECTRANS reverse). Final state : 48 disponibles, 0 en holding, 0 dans bin (les 2 défectueux), vendor crédite.
Analogie quotidienne — Les colis Amazon arrivent à la salle de tri avant d'aller dans votre boîte aux lettres. La salle de tri est une "holding location". Si le tri détecte un colis abîmé, il ne va pas chez vous tant que résolu. C'est exactement le mécanisme Maximo.
Pourquoi A est faux — Incrémenter immédiatement la bin standard contourne le contrôle qualité et risque l'issue d'items non-conformes. Pattern D4 (Partial-truth) : pour les items SANS inspection required, oui, c'est le flux. Mais avec le flag activé, le passage par Holding est obligatoire. Le candidat qui confond les deux flux choisit cette option.
Pourquoi B est faux — Rejeter le receipt parce que l'inspection ne peut pas avoir lieu au receiving est une réponse trop rigide. Pattern D2 (Invented) : Maximo distingue précisément receipt (acknowledgement physical delivery) de inspection (QA validation). Les deux étapes sont successives, pas concurrentes. Le rejet ne se ferait que sur erreur de PO matching ou écart de quantité fondamental.
Pourquoi D est faux — Auto-création de bin et split sont des inventions. Pattern D7 (Non-existent) : Maximo n'a aucun mécanisme de splitting automatique des receipts par bins multiples. Cette logique sonne plausible mais aucune fonctionnalité standard ne l'implémente. Les bins multiples nécessitent une décision manuelle du storeroom clerk.
- WINSP status — receipt en attente d'inspection. Items dans Holding Location.
- Holding Location — bin de transit, distinct des bins standard du storeroom.
- Approval transition — WINSP → COMP transfère Holding → standard bin.
- Without "Inspection Required" — receipt direct → COMP, balance immédiate.
- Inspection Required + receipt → WINSP en Holding Location.
- Holding Location ≠ bin standard. Quantité non disponible pour issue.
- QA approval = transition WINSP → COMP + transfert auto.
- STU 6.1 — Holding Location + Receiving statuses
- [EOTRAG] Query 9 — Receiving with inspection (Holding bin, status WINSP)
- master-map.pdf p.787-832 Receiving module
Correct :B
Pourquoi cette question existe — Asset Serialization est un objectif STU 6.1 explicite. C'est l'une des différences fondamentales entre rotating et non-rotating items, et c'est pratiquement garanti d'apparaître à l'examen.
Le contexte théorique d'abord — Un rotating item est un item qui existe simultanément comme record d'inventaire (pour le tracking de stock) ET comme record d'asset (pour l'historique de maintenance individuel). Chaque unité physique reçoit un numéro de série unique parce que les coûts cumulatifs (achat, réparations, refurb) doivent être suivis par exemplaire. Sans cette serialization, un motor de 50000 $ tournant ne pourrait pas être distingué d'un autre motor identique, et son historique (15 ans de réparations à 30000 $ cumulés) serait perdu. La serialization est donc le pont entre le module Inventory et le module Assets.
Ce que Maximo en fait — version opérationnelle — Au receipt d'un rotating item PO, Maximo détecte rotating=Y sur Item Master et impose un sub-écran "Asset Serialization". Le receveur doit saisir, pour chaque unité reçue, un ASSETNUM (auto-généré ou manuel selon la config) et un numéro de série fournisseur. Maximo crée alors les records dans la table ASSET avec status NOT READY (puis READY après ajout d'attributs requis), ASSETSPEC linké, et localisation = storeroom default location. Le RECEIPTSTATUS reste WASSET tant que la serialization n'est pas complète, puis passe à COMP.
Exemple chiffré — PO 3 motors (rotating). Receveur clique "Receive" → écran serialization. Saisit ASSET-MOT-001 (serial S/N 24X-9001), ASSET-MOT-002 (S/N 24X-9002), ASSET-MOT-003 (S/N 24X-9003). Sauvegarde. Maximo crée 3 records dans ASSETS, INVBALANCES.qty=3 pour le storeroom (oui, rotating items SONT dans INVBALANCES, comptés comme stock disponible), et chaque ASSETNUM porte son cost spécifique (ASSET cost method).
Analogie quotidienne — Quand vous achetez 3 voitures pour votre flotte, chacune obtient sa plaque, son VIN, son enregistrement individuel. Vous ne pouvez pas les traiter comme "3 voitures fungibles" parce que chacune aura son histoire d'entretien, ses km, ses réparations spécifiques. Maximo applique le même principe aux rotating items.
Pourquoi A est faux — Affirmer aucune différence ignore le concept même de rotating. Pattern D7 (Non-existent) : Maximo a un workflow distinct pour rotating, ne pas le connaître = fail à C1000-208. Le piège fonctionne sur les candidats qui n'ont jamais reçu de rotating items en pratique.
Pourquoi C est faux — Inspection mandatory pour rotating est partial-truth — beaucoup d'organisations exigent inspection pour rotating high-value, mais c'est une politique de site, pas une règle inhérente Maximo. Pattern D4 (Partial-truth) : la serialization, par contre, est inhérente et obligatoire pour tout rotating, peu importe la politique inspection. La question demande l'étape additional inhérente, c'est la serialization.
Pourquoi D est faux — Companies est l'app vendor, pas l'asset. Pattern D6 (Wrong-app) : créer un Companies record par unit serait absurde et impossible (un vendor n'est pas une unité de produit). Cette option est un distractor pur, créé pour piéger les candidats qui ne maîtrisent pas le data model.
- Asset Serialization — étape mandatory au receipt rotating items.
- Status WASSET — receipt en attente de serialization.
- 1 unit = 1 ASSETNUM — pas de partage entre rotating units.
- ASSET cost method — chaque ASSETNUM porte son coût propre (cumul achat + réparations).
- Rotating + receipt = Asset Serialization obligatoire.
- Chaque unit reçue = 1 ASSETNUM unique.
- Status receipt : WASSET → (serialization) → COMP.
- STU 6.1 — Receive Rotating Item from PO + perform Asset Serialization
- [EOTRAG] Query 6 — Rotating items + IAS
- [EOTRAG] Query 14 — Maximo project Centrale d'équipements
Correct :D
Pourquoi cette question existe — Le STU 6.1 explicitement mentionne "apply Item Assembly Structures" lors du receipt rotating. IBM teste votre compréhension de la cascade IAS, qui est l'un des avantages opérationnels majeurs des IAS pour minimiser le data entry.
Le contexte théorique d'abord — Un Item Assembly Structure (IAS) est une nomenclature (BOM) qui décompose un parent rotating en sous-assemblages. Quand vous recevez physiquement un MOTOR_ASSY, vous recevez aussi physiquement les PUMP, BEARING, SEAL qui le composent. Le Maximo data model reflète cela en créant un asset pour chaque composant, lié hiérarchiquement au parent. Sans cette cascade, le receveur devrait créer manuellement 4 assets et coder leurs relationships — work-intensive et erreur-prone.
Ce que Maximo en fait — version opérationnelle — Le RAG cite verbatim : "While you can use any item as the primary level of an item assembly structure, you can apply an item assembly structure to an asset only if you mark the parent item as a rotating item. ... Rather than specifying the component parts on all 10 asset records, you can create the asset records and copy the five-horsepower motor item assembly structure to each record." [EOTRAG Query 6]. Au receipt, après que le receiver renseigne ASSETNUM pour le parent, Maximo cascade automatiquement : crée 3 child ASSETNUM (PUMP-001, BEARING-001, SEAL-001 dans cet exemple), assigne PARENT = MOTOR-ASSY-001, et copie les attributs IAS (criticité, classification, etc.) sur les enfants.
Exemple chiffré — Avant receipt : 0 assets dans le système. PO de 1 MOTOR_ASSY. Asset Serialization au receipt avec IAS cascade : Table ASSETS après receipt :
- MOTOR-ASSY-001 (parent, no PARENT)
- PUMP-001 (child, PARENT = MOTOR-ASSY-001)
- BEARING-001 (child, PARENT = MOTOR-ASSY-001)
- SEAL-001 (child, PARENT = MOTOR-ASSY-001)
Analogie quotidienne — Quand vous achetez un ordinateur portable, vous recevez l'unité (parent) plus le chargeur, la souris, la sacoche (children). Si votre système d'inventaire personnel "auto-cascade", chaque accessoire reçoit son ID dès l'unboxing, sans avoir à les enregistrer un par un.
Pourquoi A est faux — Différer la création des enfants à un usage ultérieur perdrait la traçabilité physique au receipt. Pattern D4 (Partial-truth) : la cascade existe mais s'applique au receipt, pas à l'usage. Si le candidat a déjà vu cette logique pour un BOM Job Plan (où les composants sont créés à l'exécution), il peut transposer à tort cette logique aux IAS.
Pourquoi B est faux — Créer seulement les enfants sans le parent perd la hiérarchie. Pattern D3 (Inverse) : l'IAS conserve toujours le parent comme racine ; les enfants y sont attachés via PARENT field. Sans parent, la hiérarchie est cassée et les rapports d'asset hierarchy ne fonctionnent plus.
Pourquoi C est faux — Affirmer que l'IAS ne fait rien automatiquement nie la valeur core de cette feature. Pattern D7 (Non-existent) : exiger une création manuelle ne servirait à rien — autant ne pas définir d'IAS du tout. La cascade automatique est précisément le bénéfice qui justifie l'effort de définition de l'IAS.
- IAS cascade — au receipt d'un rotating parent, Maximo crée parent + tous les enfants en cascade.
- 1 parent + N enfants = N+1 ASSETNUM par unité reçue.
- Hiérarchie préservée — PARENT field pointe vers le parent.
- Bénéfice — création groupée + traceabilité automatique au receipt.
- IAS cascade au receipt : parent + enfants = N+1 ASSETNUM par unit reçue.
- Hiérarchie automatique via PARENT field.
- Apply IAS au receipt = STU 6.1 explicit objective.
- STU 6.1 — Apply Item Assembly Structures during rotating receipt
- [EOTRAG] Query 6 — IAS verbatim "five-horsepower motor and constituent parts"
- master-map.pdf p.787-832 IAS section
Correct :A
Pourquoi cette question existe — STU 6.1 mentionne "Receiving statuses" et "Define Rotating Items Receipt Status Process". IBM teste votre maîtrise des transitions de statut, qui sont la colonne vertébrale du workflow receiving.
Le contexte théorique d'abord — Un workflow de receipt avec inspection et serialization combine deux gates qualité : (1) inspection — l'item est-il conforme aux specs ? (2) serialization — chaque unité est-elle correctement identifiée comme asset unique ? Les deux gates doivent être franchis avant que l'item ne soit disponible. La séquence dépend de la politique organisationnelle, mais standard Maximo place WINSP avant WASSET parce qu'il est inutile de sérialiser des items qui pourraient être rejetés à l'inspection.
Ce que Maximo en fait — version opérationnelle — Receipt initial : RECEIPTSTATUS = WINSP (Inspection Required item dans Holding). QA inspecte : approuvé → status passe à WASSET (Asset Serialization). Receveur effectue serialization (saisit ASSETNUMs et serials). Cliquant Save → WASSET → COMP. INVBALANCES updated, ASSETS records created, transit to standard bin completed. Quantité disponible pour issue. Le sequence garantit qu'aucune unité serialisée n'est rejetée plus tard (ce qui invaliderait son ASSETNUM).
Exemple chiffré — Receipt PO 2 rotating tools (calibration kits). T0: WINSP. T+2h: QA approve les 2 kits. Status → WASSET. T+2h15: receveur saisit ASSETNUM TOOL-CAL-001 et TOOL-CAL-002 + serials. T+2h20: status → COMP. Holding -2, bin standard +2, 2 ASSETs créés.
Analogie quotidienne — À l'aéroport, votre bagage : check-in (RECEIVED) → security scan (INSPECTION) → tag attaché (SERIALIZATION = serial unique du bagage) → loaded sur l'avion (COMP, disponible pour transport). Si l'inspection rejette, le tag n'est jamais attaché.
Pourquoi B est faux — Sauter inspection et serialization annihile les contrôles. Pattern D7 (Non-existent) : impossible pour un rotating tool requiring inspection. Le piège fonctionne sur les candidats qui pensent que tools = consommables fungibles, mais rotating tools sont serialisés.
Pourquoi C est faux — REJECTED comme défaut est ridicule. Pattern D2 (Invented) : aucun système ne rejette par défaut. Le candidat distrait choisit WAPPR (waiting approval) comme le statut initial, qui existe pour les receipts en attente d'approbation manuelle (rare workflow), pas pour les rotating tools.
Pourquoi D est faux — RECEIVED/INSPECTED/SHIPPED sont des statuts inventés ou de domaines voisins (Shipping uses différents). Pattern D1 (Legacy) : le candidat peut se rappeler de ces termes d'un système ancien (pre-Maximo) ou d'un autre EAM. Maximo Manage v9.1 utilise WINSP, WASSET, COMP — terminologie spécifique.
- Receipt Status Process flow rotating + inspection : WINSP → WASSET → COMP.
- Without inspection rotating : direct WASSET → COMP.
- Without rotating + inspection : WINSP → COMP (no serialization step).
- Plain non-rotating non-inspection : direct COMP.
- Statuts standards : WINSP, WASSET, COMP.
- Rotating + inspection : WINSP → WASSET → COMP (en 3 étapes).
- Inspection avant serialization : pour ne pas serialiser ce qui sera rejeté.
- STU 6.1 — Receiving statuses + Define Rotating Items Receipt Status Process
- [EOTRAG] Query 9 — Shipment inspection statuses
- master-map.pdf p.787-832 — Receiving Status field
Correct :C
Pourquoi cette question existe — Le STU 6.1 explicite "Partial Shipment Receipts". IBM teste si vous comprenez le mécanisme cumulative de receipt qui supporte les multiples shipments contre une même PO line, sans la fermer prématurément.
Le contexte théorique d'abord — En supply chain, les vendor shipments partiels sont la norme, pas l'exception : capacité de production limitée, contraintes logistiques (un seul container à la fois), production échelonnée pour matériel non-stockable. Un EAM doit donc supporter le receipt incrémental contre une seule PO line. La PO line accumule les receipts jusqu'à atteindre la quantité totale ordonnée, puis se ferme automatiquement (ou manuellement si une portion est annulée).
Ce que Maximo en fait — version opérationnelle — Sur Receiving app, ouverture du PO. Receveur saisit qty=60 sur la ligne (ordered=100). Maximo crée un MATRECTRANS row avec RECEIVEDQTY=60. Sur la PO line, le champ Quantity Received passe de 0 à 60 ; Quantity Open reste à 40 (= 100 - 60). PO line status reste ouvert (ou WMATL/INPRG selon les flags). Storeroom INVBALANCES += 60 (ou 60 en Holding si inspection). Quand le second shipment arrive, le receveur ré-ouvre le PO, saisit 40, second MATRECTRANS row, Quantity Received passe à 100, PO line ferme automatiquement à COMP.
Exemple chiffré — PO line : ordered=100, unit cost=$50. Shipment 1 (60 units): MATRECTRANS row1 (qty=60, cost=3000), POline.received=60, POline.open=40. Shipment 2 (40 units, 2 weeks later): MATRECTRANS row2 (qty=40, cost=2000), POline.received=100, POline.open=0, PO line closes. INVBALANCES totale +100 sur la période.
Analogie quotidienne — Vous commandez 100 livres en ligne et le vendeur prévient qu'il enverra 60 maintenant et 40 dans 2 semaines (rupture de stock partielle). Vous ne fermez pas la commande à 60 ni ne créez une nouvelle commande pour 40 — vous attendez, et la commande totale se complète quand le 2e colis arrive.
Pourquoi A est faux — Rejeter parce que qty ne match pas serait absurde si le vendor accepte la livraison partielle. Pattern D2 (Invented) : Maximo n'a pas de règle stricte de matching qty au receipt. Il a une règle de matching à la facture (3-way match invoice/receipt/PO), mais pas au receipt lui-même.
Pourquoi B est faux — Auto-close à 60 + write-off des 40 perdrait le commitment vendor restant. Pattern D7 (Non-existent) : aucune logique automatic write-off ; la fermeture nécessite une décision manuelle (PO close + cancel remaining qty). Le candidat qui pense ainsi confond receipt avec close.
Pourquoi D est faux — Émettre une nouvelle PO pour les 40 restants est inutile et désorganise les engagements vendor. Pattern D10 (Procedure-plausible) : ça pourrait sembler être une bonne pratique organisationnelle ("une PO par shipment") mais c'est exactement ce que le mécanisme partial receipt évite. La PO d'origine reste l'engagement contractuel ; les shipments multiples s'agrègent contre elle.
- Partial receipt — un PO line accepte plusieurs MATRECTRANS rows.
- Cumulative tracking — POline.received += qty à chaque receipt.
- Auto-close — quand received = ordered, PO line passes COMP.
- Manual close — possible si vendor ne complète pas ; write-off ou cancel le reste.
- Partial receipt : PO line reste ouverte, qty cumulative.
- 1 PO line = N MATRECTRANS rows possibles.
- Pas de nouvelle PO nécessaire pour le reste.
- STU 6.1 — Partial Shipment Receipts
- [EOTRAG] Query 14 — MATRECTRANS multiple rows per PO line
- master-map.pdf p.787-832 PO and Receiving
Correct :B
Pourquoi cette question existe — Le STU 6.1 mentionne explicitement "Shipment Receiving: Partial Shipment Receipts · Define Shipment Receipt Status". IBM teste votre maîtrise du flux inter-storeroom, qui est conceptuellement distinct du receipt PO (vendor-side).
Le contexte théorique d'abord — Dans une organisation hub-and-spoke, les transferts inter-storeroom sont fréquents : le hub central commande en gros et redistribue vers les sites satellites. Le mécanisme côté envoi est le Stock Transfer Order (STO) ; côté réception, c'est le Shipment Receiving qui acte la livraison physique au destinataire. Sans cet acknowledgement, les balances seraient désalignées : le source aurait décrémenté mais le destinataire n'aurait pas incrémenté, créant un "stock en transit" mal tracké.
Ce que Maximo en fait — version opérationnelle — Le RAG cite verbatim : « Shipment Receiving : Dans une organisation, vous pouvez transférer des inventory items ou tools entre storerooms au sein du même site ou entre sites et organisations et tracer leur livraison. Vous créez des shipment receipt records pour acter la réception des items transférés et mettre à jour les inventory balances au storeroom destinataire. » [EOTRAG Query 14]. Le receveur au site satellite ouvre l'app Shipment Receiving, recherche le STO en transit, et clique « Receive ». Maximo crée un MATRECTRANS au destinataire (incrément balance) ; au source, un MATUSETRANS row de type ISSUE-TRANSFER avait déjà été créé au moment du shipment (décrément balance). Les deux rows réconcilient le transfert.
Exemple chiffré — Hub central : INVBALANCES item X = 100 units. STO crée pour 25 units → satellite Y. Au shipment : MATUSETRANS au hub (-25), balance hub = 75 ; items en transit. Au satellite reçoit : MATUSETRANS au hub était déjà fait, MATRECTRANS satellite (+25), balance satellite = 25. Reconciliation : Hub 75 + Satellite 25 = 100 (conservation totale).
Analogie quotidienne — Quand votre entreprise vous transfert d'un bureau à un autre, le bureau de départ doit te marker "parti" et le bureau d'arrivée doit te marker "arrivé". Si seul le départ est enregistré, vous êtes "perdu en transit". Le Shipment Receiving = l'acknowledgement d'arrivée.
Pourquoi A est faux — Issue Items consume contre un WO ; ce n'est pas un acknowledgement de transfer. Pattern D6 (Wrong-app) : c'est l'app pour issuer aux WOs, pas pour recevoir des transfers. Le candidat qui choisit ça mélange consume et receive — deux flux distincts.
Pourquoi C est faux — Add Inventory Balance est un ajustement manuel utilisé pour corriger des écarts ou pour des soldes initiaux. Pattern D7 (Non-existent) : utiliser cette option pour un transfer perdrait toute la traçabilité du STO et casserait la réconciliation source-destination. C'est une mauvaise pratique qui contournerait les contrôles audit.
Pourquoi D est faux — Émettre une PO contre le hub central traite le hub comme un vendor externe, ce qui n'est pas le cas dans une org single-entity. Pattern D10 (Procedure-plausible) : pour les organisations multi-org où chaque site est une entité légale séparée, oui, des "internal POs" (intercompany) peuvent exister. Mais dans le scope C1000-208 et pour un STO simple, c'est over-kill et incorrect. STO + Shipment Receiving est le mécanisme natif et léger.
- STO (Stock Transfer Order) — créé au source (hub) pour transférer items vers destination.
- Shipment Receiving — app destinataire pour acker et incrémenter la balance.
- Reconciliation — MATUSETRANS au source + MATRECTRANS au destinataire = transfer complet.
- Partial transfer — supporté comme partial PO receipt.
- Inter-storeroom transfer : STO côté source + Shipment Receiving côté destinataire.
- Shipment Receiving ≠ Receiving (PO vendor) ≠ Issue Items.
- Reconciliation MATUSETRANS source + MATRECTRANS destinataire.
- STU 6.1 — Shipment Receiving + Define Shipment Receipt Status
- [EOTRAG] Query 14 — Shipment Receiving verbatim from MAS Manage
- [EOTRAG] Query 13 — Hub-and-spoke transfers
Correct :A
Pourquoi cette question existe — Le STU 6.1 explicite "Use Inventory Receiving Role Based Application". Les RBAs sont une famille d'applications modernes Maximo conçues spécifiquement pour des rôles précis (technicien terrain, storeroom clerk, planner). IBM teste votre connaissance de leur existence et leur usage.
Le contexte théorique d'abord — Les Role-Based Applications (RBA) Maximo sont une architecture introduite dans les versions modernes pour réduire la complexité de l'UI standard pour les utilisateurs non-experts. Au lieu de naviguer dans une app riche multi-tabs (la full Receiving app pour BAs/admins), un storeroom clerk utilise une RBA simplifiée : 3 boutons gros, scan barcode, validation 1-clic. Le résultat est moins d'erreurs, formation réduite, throughput accru. Maximo a livré plusieurs RBAs : Inventory Receiving, Inventory Counting, Asset Move, Work Order Approval, Inspection.
Ce que Maximo en fait — version opérationnelle — L'application Inventory Receiving RBA ouvre une interface tactile-friendly avec un bouton principal "Scan PO". Le clerk scanne le barcode du shipment manifest, Maximo lookup la PO, présente la list des items à recevoir avec qty pre-filled. Le clerk scanne le barcode item, Maximo confirme matching, le clerk saisit la qty (clavier numérique large), valide. Asset Serialization (si rotating) est intégrée dans le même flow simplifié. La RBA déclenche les mêmes MATRECTRANS et INVBALANCES updates que la full app standard.
Exemple chiffré — Avec full Receiving app : 12 clicks par receipt line, 5 minutes par PO multi-line. Avec RBA : 3 clicks par line, 1.5 minutes par PO. Sur 50 receipts/jour : économie de 50 × 3.5 min = 175 min/jour = 3 heures/jour de productivité storeroom.
Analogie quotidienne — En épicerie self-checkout : interface simplifiée, scanner, paiement, fini. Pas la même UI que la caisse principale (qui gère retours, refus carte, comptes pro). Le RBA Receiving est le self-checkout du storeroom.
Pourquoi B est faux — Companies est l'app de vendor management. Pattern D6 (Wrong-app) : aucun lien avec receipt simplifié. Le candidat qui choisit ça est complètement hors-sujet.
Pourquoi C est faux — Item Master n'a pas de toggle "simplified mode" pour receipt. Pattern D7 (Non-existent) : option fabriquée. Item Master est l'app master data, pas une app transactionnelle de receipt.
Pourquoi D est faux — Mobile Field Worker est une autre app modulaire (mobile-first), mais elle est séparée et ciblée pour les techniciens en mission, pas pour les storeroom clerks au comptoir. Pattern D2 (Invented) : suggérer "separate license" introduit une fausse complexité ; les RBAs sont incluses dans Maximo Manage standard, pas en module add-on.
- Role-Based Applications (RBA) — UI simplifiée par rôle utilisateur.
- Inventory Receiving RBA — flow streamlined receipt, barcode-friendly.
- Inventory Counting RBA — flow simplifié pour count books (lesson 7.3).
- Bénéfice — moins d'erreurs, formation réduite, throughput accru.
- Inventory Receiving RBA = app simplifiée pour storeroom clerks.
- Barcode-friendly, tactile, 3-clicks per line.
- Génère les mêmes MATRECTRANS que la full app.
- STU 6.1 — Use Inventory Receiving Role-Based Application
- master-map.pdf p.787-832 RBA section
- IBM Maximo Manage 9 — Role-Based Applications
Correct :C
Pourquoi cette question existe — Le receipt impacte directement le coût moyen pondéré (WAC) pour les items en cost method = AVERAGE. IBM teste si vous comprenez la formule WAC update au receipt, qui est l'un des sujets de coût les plus testés dans C1000-208.
Le contexte théorique d'abord — Le Weighted Average Cost (WAC) est l'une des 5 méthodes de costing standard de Maximo (avec STANDARD, FIFO, LIFO, ASSET) [EOTRAG Query 4]. Sa formule est : new_avg = (old_qty × old_cost + receipt_qty × receipt_cost) / (old_qty + receipt_qty). Le WAC s'update à CHAQUE receipt, jamais aux issues. Aux issues, l'item sort à l'avg cost en cours, qui ne change pas. C'est cette property "rolling average" qui distingue WAC de FIFO (où chaque layer garde son cost) et de STANDARD (où le cost est fixe).
Ce que Maximo en fait — version opérationnelle — Au receipt, Maximo lit INVCOST.AVGCOST (= 10) et INVBALANCES.QTY (= 50). Il calcule new_avg = (50 × 10 + 30 × 14) / (50 + 30) = (500 + 420) / 80 = 920 / 80 = 11.50. Update INVCOST.AVGCOST = 11.50 et INVBALANCES.QTY = 80. Toute issue ultérieure jusqu'au prochain receipt utilisera 11.50 $/unit. La table INVCOST garde un historique de chaque update pour audit.
Exemple chiffré — Voir question. Le calcul détaillé : (50 × 10) + (30 × 14) = 500 + 420 = 920 $ valeur totale après receipt. 80 units total. Avg = 920/80 = 11.50 $/unit. Inventaire après : 80 units à 11.50 $ = 920 $.
Analogie quotidienne — Vous avez 50 actions Apple à 10 $ moyenne (achetées au fil du temps). Vous achetez 30 actions à 14 $. Votre prix de revient moyen est maintenant 11.50 $, pas 12 $ ni 14 $. C'est pondéré par les quantités, pas une moyenne simple.
Pourquoi A est faux — Locker l'avg cost à la création est faux pour méthode AVERAGE (c'est valid pour STANDARD). Pattern D7 (Non-existent) : la propriété "moving average" est précisément ce qui définit AVG. Le candidat qui pense ainsi confond AVG et STANDARD.
Pourquoi B est faux — Moyenne simple (10+14)/2 = 12 ignore les quantités. Pattern D9 (Near-synonym) : "average" suggère intuitivement la moyenne arithmétique simple, mais en finance et en costing c'est toujours pondéré. Erreur fréquente chez les candidats sans formation comptable.
Pourquoi D est faux — Le receipt cost ne remplace pas l'ancien avg ; il le pondère. Pattern D3 (Inverse) : c'est le comportement d'un cost method "REPLACE" qui n'existe pas dans Maximo (il existe dans certains systèmes de scrap value, mais pas pour inventaire courant). Choisir 14 $ équivaut à oublier les 50 units à 10 $ existants, ce qui n'a aucun sens comptable.
- WAC formula — new_avg = (old_qty × old_cost + receipt_qty × receipt_cost) / (old_qty + receipt_qty).
- Update timing — au receipt seulement, pas à l'issue.
- 5 cost methods — STANDARD, AVERAGE (WAC), FIFO, LIFO, ASSET.
- Issue cost — toujours à l'avg en cours pour AVG ; à la layer pour FIFO/LIFO ; au standard pour STANDARD ; à l'asset cost pour ASSET.
- WAC = pondéré par quantités, JAMAIS moyenne simple.
- Update à chaque receipt, formule (old_qty × old_cost + new_qty × new_cost) / total.
- Issue cost = avg en cours, ne modifie pas l'avg.
- STU 6.1 — Receiving impacts inventory cost
- [EOTRAG] Query 4 — 5 cost methods + WAC formula verbatim
- master-map.pdf p.787-832 INVCOST table
Retour et annulation de Receipts

📋 Objectifs IBM
- Effectuer un Item Return depuis une ligne PO précédemment réceptionnée vers le vendor
- Effectuer le Return d'un Rotating Item avec préservation de la sérialisation
- Compléter le workflow Return incluant le handshake credit memo avec le vendor
- Définir les règles de Voiding Receipts — quand c'est autorisé et quand c'est bloqué
💡 Points clés
- Return — renvoyer au vendor des items réceptionnés. Utilisé quand les items sont défectueux, mauvais modèle, périmés, ou en excès. Crée une ligne MATRECTRANS reverse + déclenche un AP credit voucher.
- Void — annuler entièrement un receipt comme s'il n'avait jamais eu lieu. Utilisé quand un receipt a été saisi par erreur (typo sur qty, mauvaise PO) avant toute transaction downstream.
- Distinction Return vs Void — Return suppose que les items sont physiquement arrivés mais doivent repartir (défectueux, faux) ; Void suppose que le receipt lui-même était logiquement incorrect (erreur de saisie).
- Règles Void — un receipt ne peut être voided QUE si aucune transaction downstream n'existe. Conditions bloquantes : items déjà issués à une WO, déjà transférés vers un autre storeroom, déjà kit-assemblés, AP voucher déjà payé.
- Workflow Return — Receiving app → Select Item for Return → choisir la ligne MATRECTRANS originale → saisir return qty + reason code → Maximo crée une ligne reverse, décrémente INVBALANCES, déclenche le processus vendor return shipment.
- Return d'un rotating item — doit référencer l'ASSETNUM spécifique retourné (chaque unité étant unique). L'historique du record asset est préservé (l'asset n'est pas supprimé, juste passé à un statut « returned to vendor »). Le coût se réverse sur la WO si précédemment imputé.
- Reasons de Return — DEFECTIVE, WRONG-MODEL, OVERSHIPPED, EXPIRED, WRONG-CONDITION. Capturé dans le champ reason code de MATRECTRANS pour les scorecards vendor.
- Une fois issued, voie Return obligatoire — si les items ont été issued à un WO (MATUSETRANS), Maximo n'autorise PAS le Void. L'utilisateur doit d'abord Return-to-Store (réverser l'issue) et seulement ensuite peut tenter le vendor return. Cela protège l'intégrité de la chaîne d'audit [EOTRAG Query 14].
- Credit memo — le vendor return déclenche un crédit attendu. Maximo peut auto-générer une AP credit invoice référençant le return receipt, ou attendre que le vendor émette son propre crédit qui est ensuite 3-way-matched contre le return.
- Partial returns — seule une portion d'un receipt peut être retournée (ex. 5 sur 10 défectueuses). La MATRECTRANS originale garde qty=10 ; la ligne MATRECTRANS de return qty=5 (négatif ou type « return »).
- Voided receipts et audit — un void crée une ligne reverse avec flag VOID = Y, ne supprime jamais l'original. Audit trail préservé.
- Impact GL — un return inverse les postings GL d'origine (debit/credit symétrique) ; un void fait pareil mais avec un reason code « VOID ».
flowchart TD RECEIPT["Ligne MATRECTRANS existe
(receipt complet)"]:::start CHECK{"Ce receipt a-t-il
une transaction downstream ?
(issue / transfert / inspection
terminée / charge WO)"}:::decision VOID_OK["Chemin Void Receipt
(STU §6.2)"]:::ok VOID_TX["MATRECTRANS reverse
balance -= receipt_qty
Statut Receipt = VOIDED
Entry GL receipt reverse"]:::action VOID_END["Receipt effacé des
records actifs
(ligne audit préservée)"]:::endNode RETURN_REQ["Chemin Return obligatoire
void impossible — orphelinerait
les transactions downstream"]:::warn RETURN_TX["Inventory Usage
ligne Return type
balance -= return_qty
INVTRANS type=RETURN
(ou Return-to-Vendor sur ligne PO)"]:::action RETURN_END["Receipt reste valide
return journalisé séparément
(GL reste cohérente)"]:::endNode RECEIPT --> CHECK CHECK -- Non --> VOID_OK --> VOID_TX --> VOID_END CHECK -- Oui --> RETURN_REQ --> RETURN_TX --> RETURN_END classDef start fill:#3B82F6,stroke:#1E40AF,color:#FFFFFF,font-weight:600; classDef decision fill:#F59E0B,stroke:#B45309,color:#FFFFFF; classDef action fill:#FFFFFF,stroke:#94A3B8,color:#0F172A; classDef ok fill:#D1FAE5,stroke:#178A66,color:#0F172A; classDef warn fill:#FEF3C7,stroke:#F59E0B,color:#78350F,font-weight:600; classDef endNode fill:#1D9E75,stroke:#178A66,color:#FFFFFF,font-weight:600;
⚠️ Piège IBM
« Puis-je voider ce receipt ? » — dépend de l'activité downstream. Le piège d'examen le plus courant est de confondre les cas d'usage return et void.
- Piège : supposer qu'on peut voider n'importe quel receipt à volonté. Faux — dès qu'une transaction downstream existe, le void est bloqué.
- Piège : penser que le return supprime la ligne MATRECTRANS originale. Faux — Maximo crée une ligne reverse ; rien n'est supprimé.
- Piège : oublier que les returns rotating doivent référencer l'ASSETNUM spécifique. Le record asset est préservé avec changement de statut.
- Piège : penser que l'AP credit est auto-émis pour n'importe quel return. Pas toujours — dépend de l'accord vendor et de la config Maximo.
🎯 Carte mémoire
Q. Un receipt de 50 unités a été fait hier. 20 de ces unités ont déjà été issuées à une work order aujourd'hui. Le receipt original peut-il maintenant être voided ?
Afficher la réponse
Non. Le void exige qu'AUCUNE transaction downstream (issue, transfer, kit assembly) n'ait eu lieu. Puisque 20 unités ont été issuées, le void est bloqué. L'utilisateur doit plutôt : (1) Return les 20 unités issuées vers le store via une transaction Return-to-Store, puis (2) initier un vendor return pour les 50 unités complètes, OU (3) simplement initier un vendor return pour les 30 restantes en store + prévoir de récupérer les 20 sur la WO si défectueuses.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :B
Pourquoi cette question existe — La distinction Return/Void est un piège classique. Les deux réversent un receipt mais ont des sémantiques distinctes : Void = correction d'erreur de saisie ; Return = rejet d'items physiques. IBM teste cette distinction critique parce qu'elle a des implications GL différentes.
Le contexte théorique d'abord — En comptabilité, on distingue les corrections (annulations d'erreurs) des transactions inverses (retours, échanges). Une correction reflète une réalité qui n'a jamais existé (faute de frappe, sélection erronée) et doit être reversée comme si elle n'avait jamais eu lieu. Un retour reflète une réalité qui a existé et qui est ensuite renversée (les items sont arrivés, puis renvoyés). Cette distinction matters parce que la première ne devrait pas figurer dans les rapports vendor scorecards (ce n'est pas la faute du vendor) ; le second est un signal de qualité qui doit être tracké.
Ce que Maximo en fait — version opérationnelle — Si la condition "no downstream transaction" est remplie, le clerk peut Void le receipt original (50 units). Maximo crée un MATRECTRANS row inversant intégralement le précédent (qty=-50, cost=-X, VOID flag = Y). INVBALANCES revient à l'état pre-receipt. Le clerk peut alors re-enter le receipt correct (5 units). La PO line revient à open + 0 received, puis devient open + 5 received. Aucun signal vendor scorecard n'est généré (il n'y a pas eu de problème de qualité vendor).
Exemple chiffré — Avant void : INVBALANCES.qty = 50, valeur = 50 × 10 = 500 $. Void : MATRECTRANS row(-50, -500). INVBALANCES.qty = 0. Re-enter correct : MATRECTRANS row (+5, +50). INVBALANCES.qty = 5. Net : 5 units à 50 $, comme prévu. L'erreur des 45 unités fictives est nettoyée sans laisser de trace de "qualité vendor".
Analogie quotidienne — Vous tapez "achat 500 $" au lieu de "achat 50 $" dans votre app banking. Vous corrigez en annulant l'écriture (void) et en ré-entrant 50 $. Vous ne faites pas un transfer pour rebrancher 450 $ vers votre compte (= return). Les deux opérations sont arithmétiquement équivalentes pour la balance finale, mais sémantiquement différentes pour l'audit.
Pourquoi A est faux — Effectuer un Return de 45 unités traiterait l'erreur comme un problème vendor (45 unités physiques à renvoyer). Pattern D9 (Near-synonym) : Return et Void semblent interchangeables au novice mais ne le sont pas. Le piège fonctionne sur les candidats qui pensent que toute opération réversive est un return. Conséquence : le vendor reçoit un signal de "défaut qualité" injuste, et un return shipment fictif est lancé pour des items qui n'existaient pas physiquement.
Pourquoi C est faux — Adjust Inventory Balance manuellement contourne la traçabilité du process receipt. Pattern D10 (Procedure-plausible) : ça réglerait le solde en apparence mais le rapport "ce qui a été reçu" continuerait de montrer 50 vs PO de 5, créant une discrepancy permanente. C'est aussi une mauvaise pratique audit : Maximo distingue intentionnellement les ajustements (raison documentée) des transactions normales.
Pourquoi D est faux — Supprimer la row de la base est interdit en système comptable. Pattern D7 (Non-existent) : Maximo n'a aucune commande "delete MATRECTRANS row". Le principe de l'audit immutable exige que toute écriture reste, même fausse ; seul un row inversant peut la neutraliser.
- Void — correction d'erreur de saisie. Reversing row, no vendor scorecard impact.
- Return — rejet d'items physiques. Reversing row + vendor scorecard signal + return shipment.
- Adjust Inventory Balance — pour écarts physiques (count variance, perte). Pas pour erreurs de saisie.
- Delete — interdit. Audit immutable.
- Erreur de saisie = Void.
- Items arrivés mais défectueux = Return.
- Jamais de DELETE direct ; toujours via reversing row.
- STU 6.2 — Void Receipts: define rules for voiding receipts
- [EOTRAG] Query 14 — Reversal: receipts can be voided (creates a reversing row)
- master-map.pdf p.787-832 Receiving Void/Return procedures
Correct :C
Pourquoi cette question existe — Le STU 6.2 explicite "define rules for voiding receipts". L'une des règles fondamentales : pas de void si downstream transaction. IBM teste systématiquement cette règle parce qu'elle protège l'intégrité de la chaîne audit.
Le contexte théorique d'abord — Dans tout système comptable transactionnel, les écritures forment une chaîne causale : receipt → issue → cost actuals. Si on permettait de void le receipt après issue, on briserait la causalité : les MATUSETRANS (issue) référenceraient un MATRECTRANS qui n'existe plus. C'est inacceptable pour l'audit, le 3-way match facture, et le coût analytique. C'est pourquoi tous les ERP/EAM matures bloquent void downstream — il faut d'abord défaire la chaîne dans l'ordre inverse.
Ce que Maximo en fait — version opérationnelle — Quand le clerk clique "Void" sur le receipt, Maximo vérifie l'existence de MATUSETRANS référençant cette MATRECTRANS row. Si oui, message d'erreur : "Cannot void receipt — items have been issued. Reverse issue first." Le clerk doit alors aller sur le WO, exécuter Return-to-Store pour les 30 units (MATUSETRANS row de type RETURN), retourner les 30 units en stock, puis revenir sur le receipt et tenter Void à nouveau. Cette fois, aucune downstream transaction "active", void permis, reversing row créé pour les 100 units.
Exemple chiffré — Initial : MATRECTRANS (+100), MATUSETRANS (-30 vers WO-001). INVBALANCES = 70. Tentative void → bloqué. Step 1 : Return-to-Store sur WO-001 → MATUSETRANS (+30 retour vers stock). INVBALANCES = 100. WO actuals -=30. Step 2 : Void MATRECTRANS → reversing row (-100). INVBALANCES = 0. Tout est nettoyé en cascade dans l'ordre inverse.
Analogie quotidienne — Vous voulez retourner un livre à la bibliothèque, mais vous l'avez prêté à un ami. La bibliothèque ne peut pas accepter le retour direct ; vous devez d'abord récupérer le livre de votre ami, puis le retourner. La règle "no void if downstream" est exactement la même.
Pourquoi A est faux — Auto-reverser le WO issue serait dangereux et incompréhensible pour le planner. Pattern D2 (Invented) : Maximo n'a aucun mécanisme cascade de void downstream. C'est intentionnel : le clerk receveur n'a pas autorité pour décider de retourner items déjà consumés. La décision appartient au planner WO.
Pourquoi B est faux — Voider partiellement (70 vs 30) est plus subtil mais pas standard Maximo. Pattern D4 (Partial-truth) : le concept de "void what's still in stock" n'existe pas. Maximo void tout-ou-rien à la granularité de la MATRECTRANS row. Pour voider les 70 et garder les 30, il faudrait splitter le receipt original, ce qui n'est pas un workflow standard.
Pourquoi D est faux — Créer une inventory balance négative est une catastrophe comptable. Pattern D7 (Non-existent) : Maximo bloque ce comportement. Une balance négative casse les contrôles physiques (le stock physique ne peut pas être négatif), les rapports de valeur, et les calculs de cost. C'est précisément pour éviter cela que la règle "no void downstream" existe.
- Void rule — bloqué si MATUSETRANS / MATRECTRANS aval existent.
- Cascade dans l'ordre inverse — Reverse issue → Reverse transfer → ... → Void receipt.
- Erreur message — "Cannot void receipt — items have been issued/transferred."
- Audit chain integrity — c'est la motivation de la règle.
- Void bloqué si downstream transaction existe.
- Solution : réverser les transactions downstream d'abord, puis voider.
- Pas d'auto-cascade ; chaque étape demande action manuelle.
- STU 6.2 — Void Receipts rules
- [EOTRAG] Query 14 — Reversal MATRECTRANS / MATUSETRANS audit chain
- master-map.pdf p.787-832 Receiving Void rules
Correct :D
Pourquoi cette question existe — Le STU 6.2 mentionne "Perform return of a Rotating Item". Les rotating items ont des règles spécifiques au return parce que chaque unit est unique (ASSETNUM). IBM teste votre capacité à appliquer ces règles spécifiques.
Le contexte théorique d'abord — Pour les non-rotating items, un retour de 1 unit sur 3 reçus est fungible : peu importe quelle unit physique est retournée, l'inventory balance et le cost se réduisent uniformément. Pour les rotating items, chaque unit a son ASSETNUM, son serial, son cost spécifique, son histoire. Il est donc impossible de "retourner 1 unit" sans préciser laquelle. Cette précision est aussi cruciale comptablement : la valeur du retour = cost spécifique de cet ASSETNUM, qui peut différer des autres si refurb costs accumulated.
Ce que Maximo en fait — version opérationnelle — Sur Receiving app → Select Item for Return → Maximo affiche pour les rotating items la liste des ASSETNUMs reçus de la PO. Le clerk sélectionne le ASSETNUM précis du motor endommagé (ex MOT-001). Maximo crée un MATRECTRANS reversing row pour cet ASSETNUM (qty=-1, cost=-asset_cost). L'asset record dans la table ASSETS n'est PAS supprimé — son STATUS passe à RETURNED-TO-VENDOR (ou similar custom status), sa LOCATION devient nulle, mais l'historique reste pour audit. INVBALANCES.qty -= 1 sur la ligne rotating de cet item.
Exemple chiffré — Initial : 3 motors reçus, ASSETs : MOT-001 ($500), MOT-002 ($500), MOT-003 ($500). INVBALANCES qty=3, valeur=1500 $. MOT-001 endommagé. Return : MATRECTRANS (-1, -500), MOT-001.STATUS = RETURNED-TO-VENDOR, INVBALANCES qty=2, valeur=1000 $. Le record MOT-001 reste dans ASSETS avec son histoire intacte. Le vendor reçoit l'asset à crédit le coût correspondant.
Analogie quotidienne — Vous achetez 3 voitures pour votre flotte avec leurs VIN. Une est défectueuse. Vous ne dites pas "je retourne une voiture" au concessionnaire ; vous spécifiez "VIN ABC123 est défectueuse". Le record DMV de cette voiture reste, mais le statut passe à "returned to dealer". Les VIN des 2 autres restent inchangés.
Pourquoi A est faux — Supprimer le record asset avant le return ferait perdre tout l'historique de cet asset (réceptions, certifications, mesures, etc.). Pattern D7 (Non-existent) : Maximo n'autorise pas la suppression des assets ; le record est preserved as audit trail. Cette option contredit les principes de traçabilité industrielle.
Pourquoi B est faux — Return FIFO pour rotating items est conceptuellement invalide. Pattern D2 (Invented) : Maximo n'applique pas FIFO sur rotating parce que chaque unit est unique. La sélection de l'ASSETNUM est obligatoire. Le piège fonctionne sur les candidats qui transposent les règles non-rotating aux rotating.
Pourquoi C est faux — Affirmer que return n'est pas permis pour rotating est faux. Pattern D3 (Inverse) : c'est précisément ce que le STU 6.2 mentionne explicitement : "Perform return of a Rotating Item". Le piège fonctionne sur les candidats qui confondent return-to-vendor et repair workflow (les deux existent, et sont différents).
- Rotating return — sélection ASSETNUM mandatory.
- Asset preserved — record reste avec status=RETURNED-TO-VENDOR.
- Cost specific — la valeur du retour = cost de cet ASSETNUM précis.
- vs Repair workflow — la return = vendor-side ; repair = internal lifecycle.
- Rotating return = ASSETNUM précis, pas FIFO.
- Asset record preserved, status change.
- Audit trail respect Article : ne JAMAIS delete asset.
- STU 6.2 — Perform Return of a Rotating Item
- [EOTRAG] Query 6 — Rotating items asset management
- master-map.pdf p.787-832 Rotating return rules
Correct :A
Pourquoi cette question existe — IBM teste votre compréhension du modèle audit-trail Maximo. Les transactions d'inventaire sont immutable : nulle row n'est jamais supprimée ; les annulations passent toujours par des reversing rows. C'est essentiel pour SOX/IFRS compliance.
Le contexte théorique d'abord — Le principe d'audit immutable (write-once, reversible-by-counter-write) est fondamental en comptabilité informatisée. Il garantit que toute action peut être tracée et reconstituée à n'importe quelle date. Effacer une row = effacer une preuve d'audit, ce qui est interdit par les normes SOX (Sarbanes-Oxley), IFRS, GAAP. Maximo applique strictement ce principe sur MATRECTRANS / MATUSETRANS / INVTRANS.
Ce que Maximo en fait — version opérationnelle — Quand un void est exécuté, Maximo : (1) garde la row originale intacte (qty=+50, cost=+500, VOID=N), (2) insère une row inversante (qty=-50, cost=-500, VOID=Y, REASON=VOID-CORRECTION), (3) update les champs de référence pour lier les deux rows (RELATEDRECTRANSID). INVBALANCES est mise à jour en net : +50 (de la row 1) -50 (de la row 2) = 0 net effet final. Tout le sequence est visible dans les rapports d'audit avec timestamps et user IDs.
Exemple chiffré — Avant void : MATRECTRANS row 1 (qty=+50, cost=500, VOID=N, datestamp=2026-04-26). Void exécuté. Après : row 1 inchangée + row 2 (qty=-50, cost=-500, VOID=Y, datestamp=2026-04-27, REASON=Data entry error, RELATEDRECTRANSID=1). INVBALANCES net : 0 unités. Rapport audit : "Receipt of 50 units 2026-04-26, voided 2026-04-27 by user JDUPONT, reason: data entry error".
Analogie quotidienne — Comptabilité bancaire : si vous voulez "annuler" un virement déjà passé, la banque ne supprime pas la ligne ; elle ajoute une "écriture de contrepassation" qui annule la première. Les deux écritures restent visibles sur votre relevé. C'est le même principe.
Pourquoi B est faux — Supprimer la row originale serait une violation directe de l'audit. Pattern D2 (Invented) : aucun ERP/EAM mature n'autorise cette opération. Le candidat qui choisit ça pense en termes de base de données simple ("delete row"), pas en termes de modèle comptable.
Pourquoi C est faux — Modifier la row originale (set VOID=Y) est aussi inacceptable. Pattern D7 (Non-existent) : update destructeur d'une row déjà postée brisèrait l'audit. Maximo INSERT toujours, jamais UPDATE sur les transaction rows.
Pourquoi D est faux — Archiver dans une table séparée est une fausse architecture. Pattern D2 (Invented) : Maximo n'a pas de table VOIDS séparée ; tout reste dans MATRECTRANS avec le flag VOID. La séparation des roles audit vs operational est gérée par RBAC sur la même table, pas par physical separation.
- Audit immutable — INSERT only, never UPDATE/DELETE on transaction rows.
- Reversing row — créée pour annuler ; les deux rows coexistent.
- VOID flag — Y sur la reversing row indique que c'est une annulation.
- RELATEDRECTRANSID — lien entre original et reversing.
- Void = 2 rows dans MATRECTRANS (original + reversing).
- Original JAMAIS supprimé. Audit immutable.
- VOID flag = Y sur la reversing row.
- STU 6.2 — Void Receipts rules and audit
- [EOTRAG] Query 14 — Audit query pattern + reversal mechanism
- master-map.pdf p.787-832 Audit immutable transaction model
Correct :B
Pourquoi cette question existe — Le STU 6.2 exige "Perform an Item Return". IBM teste votre compréhension du return partiel : on n'est pas obligé de void/return l'intégralité d'un receipt si seulement une portion pose problème.
Le contexte théorique d'abord — En supply chain, les défauts manufacturiers se manifestent souvent sur une partie d'un lot, pas sur tout. Le return partiel permet de garder les bons items et renvoyer les défectueux dans la même transaction de return. Cette granularité est essentielle pour préserver la valeur (les 15 bonnes valves restent disponibles pour le production), tracer la non-conformité (vendor scorecard reflète exactement 5/20 = 25% defective rate), et déclencher le crédit vendor approprié.
Ce que Maximo en fait — version opérationnelle — Sur Receiving app → Select Item for Return → choisir le receipt de 20 valves → entrer return qty = 5 + reason = DEFECTIVE. Maximo crée un MATRECTRANS reversing row (qty=-5, cost=-5×unit_cost, REASON=DEFECTIVE, RELATEDRECTRANSID=original receipt). Le MATRECTRANS original reste à qty=+20, mais la balance nette du receipt est now 15 (effective). INVBALANCES.qty -= 5. Vendor scorecard incrémente "DEFECTIVE returns count" sur ce vendor. Trigger AP credit memo expectation pour le coût des 5 unités.
Exemple chiffré — Receipt original : 20 valves @ 100 $ = 2000 $. INVBALANCES = 20. Partial return 5 defective : reversing row (-5, -500). INVBALANCES = 15. Vendor scorecard : "1 receipt with partial DEFECTIVE return, defective rate 25%". AP credit attendu : 500 $.
Analogie quotidienne — Vous achetez 20 oranges au marché, 5 sont pourries. Vous retournez les 5 au marchand, gardez les 15 bonnes, et le marchand vous donne un crédit pour 5 oranges. Vous ne rendez pas tout le sac et n'achetez pas un nouveau sac de 15.
Pourquoi A est faux — Void total + ré-entrée serait inutilement complexe. Pattern D10 (Procedure-plausible) : ça donnerait le même résultat final mais perdrait la traçabilité du défaut (le vendor scorecard ne refléterait pas la "DEFECTIVE return"). Aussi, le void d'un receipt déjà ancien (semaine passée) peut être bloqué si downstream transactions existent (issues, transferts).
Pourquoi C est faux — Adjust manuel pour 15 units perd le lien avec le receipt original et avec le vendor. Pattern D7 (Non-existent) : Adjust Inventory Balance n'a pas de mécanisme pour pointer vers une vendor return ; il s'agit d'un ajustement neutre (perte, vol, mismatch count) qui ne déclencherait aucun crédit AP.
Pourquoi D est faux — Issuer à un WO scrap est une mauvaise pratique : ça consume les items en interne et perd l'opportunité de crédit vendor. Pattern D6 (Wrong-app) : c'est un workflow de write-off, pas de return. Si le defective est de la responsabilité vendor, le retour à eux est l'action correcte ; le scrap interne est utilisé pour des items déjà acceptés et qui se sont dégradés en stockage (exp expiré, dommage interne).
- Partial return — qty < original receipt qty.
- Reversing row — référence l'original via RELATEDRECTRANSID.
- Reason codes — DEFECTIVE, WRONG-MODEL, OVERSHIPPED, etc. — alimentent vendor scorecards.
- Distinction — Return = vendor responsibility ; Scrap WO = internal write-off.
- Partial return possible : qty < original.
- Reason code obligatoire (DEFECTIVE, WRONG-MODEL...).
- Vendor scorecard alimenté + AP credit attendu.
- STU 6.2 — Perform an Item Return
- [EOTRAG] Query 14 — MATRECTRANS reversing rows
- master-map.pdf p.787-832 Return procedures
Correct :C
Pourquoi cette question existe — Le STU 6.2 explicite "Complete Return". Cela inclut non seulement la mécanique du return mais aussi la fermeture financière (credit memo). IBM teste si vous comprenez le handshake AP-Maximo qui clôture le cycle.
Le contexte théorique d'abord — Un cycle de procurement complet en EAM va : PR → PO → Receipt → Invoice → Payment. Pour un return, le cycle inverse est : Return → Credit Memo → Credit Application → Reduced Payment. Le credit memo est l'instrument financier qui formalise le crédit du vendor. En 3-way matching mature (PO + Receipt + Invoice), le 4ème élément (Credit Memo) doit être lié à la return shipping pour boucler le cycle. Sans cette traçabilité, le vendor pourrait être surpayé.
Ce que Maximo en fait — version opérationnelle — Maximo (intégré ou couplé à un AP system) supporte les credit memos via l'app Invoices avec type=CREDIT. Quand un return est performed, Maximo peut soit : (a) auto-générer un credit invoice draft référençant le MATRECTRANS reversing row + le PO ligne d'origine + le vendor, à valider par AP avant émission ; (b) attendre le credit memo physique du vendor, qui est ensuite saisi dans Invoices et matché contre le return. Le matching réduit le montant total dû à ce vendor sur la prochaine paiement scheduled.
Exemple chiffré — Vendor a une PO line de 20 valves @ 100 $ = 2000 $ engagement. Receipt 20 → Invoice 2000 $ (à payer). Return 5 defective → Credit Memo expected 500 $. Lors du paiement : 2000 - 500 = 1500 $ payé au vendor. Maximo invoice register : 1 INVOICE 2000 $ (paid 1500), 1 CREDIT 500 $ (matched to return). Net spend = 1500 $.
Analogie quotidienne — Au resto, vous renvoyez le plat (return) et le serveur vous donne un credit slip pour la prochaine fois. Quand vous payez, l'addition reflète le crédit. Le credit slip est l'analogue du credit memo.
Pourquoi A est faux — Affirmer que Maximo ne capture pas les credits est faux. Pattern D7 (Non-existent) : Maximo a une app Invoices riche supportant tous les types de documents AP (Invoice, Credit, Debit, Vendor Charge). Le piège fonctionne sur les candidats qui pensent Maximo comme purely operational sans capacité AP.
Pourquoi B est faux — Émettre une PO avec qty négative est une bidouille fonctionnelle qui sonne plausible mais n'est pas standard. Pattern D10 (Procedure-plausible) : oui, certaines équipes peu matures bricolent ainsi, mais Maximo a un mécanisme propre (CREDIT invoices). C'est une mauvaise pratique d'audit.
Pourquoi D est faux — Absorber silencieusement le crédit dans variance casse le link avec le vendor. Pattern D2 (Invented) : aucun système moderne ne fait cela. Le crédit doit être tracé pour vendor reconciliation et audit.
- Complete Return — Return MATRECTRANS + Credit Invoice = cycle fermé.
- Credit Memo — instrument AP, type=CREDIT dans app Invoices.
- 3+1 way matching — PO + Receipt + Invoice + Credit Memo.
- Net payment — Invoice total - Credit total.
- Complete return = MATRECTRANS reversal + AP credit memo.
- Credit memo référence le return + le PO ligne.
- Net payment = Invoice - Credit.
- STU 6.2 — Complete Return
- master-map.pdf p.787-832 — Invoices app + AP integration
- [EOTRAG] Query 14 — return reverses original GL postings
Fréquence d'inventaire physique (ABC, Count Groups)

📋 Objectifs IBM
- Identifier et expliquer l'ABC Analysis pour la classification d'inventaire par valeur d'usage
- Identifier et expliquer les Inventory Count Groups comme mécanisme de regroupement alternatif
- Configurer les ABC Breakpoints dans l'application Organizations
- Comprendre comment la classe ABC pilote automatiquement les Cycle Count Days
- Surcharger manuellement les ABC categories par item dans l'application Inventory au besoin (SAM Q10)
💡 Points clés
- ABC Analysis — classification basée sur Pareto : 20% des items représentent typiquement 80% de la valeur d'inventaire. Le report Maximo stratifie les items en 3 classes (A, B, C) par year-to-date issued × last cost.
- Formule ABC (verbatim RAG) :
dollar_value = year_to_date_issued × last_cost. Items triés par ordre décroissant ; le pourcentage cumulé pilote l'assignation A/B/C selon les Breakpoints. - ABC Breakpoints — configurés dans Organizations app → Inventory Options → ABC Breakpoints. Trois pourcentages dont la somme fait 100. Typique : A=30%, B=30%, C=40% (defaults IBM). Personnalisable par Org.
- Class N (No category) — items exclus du cycle counting ABC. Utilisé pour les service items, les special-order one-offs, les items hors discipline cycle-count.
- Cycle Count Days auto-stamped — l'exécution du report ABC met automatiquement à jour le champ Cycle Count Days sur chaque item : A=30 jours, B=60 jours, C=90 jours (typique). La discipline cycle-count cascade depuis l'assignation de classe.
- Principe de Pareto — règle 80/20 : 80% de la valeur d'inventaire vient de 20% des items. L'ABC est l'implémentation opérationnelle de ce principe.
- Limites de l'ABC value-only — la valeur dollar pure rate les spares mission-critical à faible valeur (un O-ring qui arrête une usine de 10 M$). Best practice : combiner ABC (valeur) avec VED (Vital/Essential/Desirable) → matrice 9 cellules. L'ABC seul est le scope C1000-208.
- Inventory Count Groups — un schéma de classification ALTERNATIF à l'ABC. Les items peuvent être regroupés par storeroom, criticité, zone de location, département. Utilisé comme filtre de Count Book (leçon 7.2). PAS mutuellement exclusif avec l'ABC — les deux peuvent coexister sur le même item.
- Où l'ABC est défini : visible sur chaque record d'item dans l'application Inventory. Le champ « ABC Type » affiche A/B/C/N.
- Où l'ABC est surchargé manuellement : application Inventory (SAM Q10). Certains items ne rentrent pas dans la classification auto pour des raisons stratégiques (insurance spares à faible valeur mais critiques → déplacer manuellement de C à A) ; l'app Inventory fournit l'override par item.
- Règles empiriques de fréquence cycle counting : A mensuel (12×/an), B trimestriel (4×/an), C annuel (1×/an) — rythme le plus courant, configurable par Org.
- Tolérances par classe : items A souvent ±2%, B ±5%, C ±10% (variance autorisée au count). Items safety/régulés 0%.
Organizations app → Inventory Options → ABC Breakpoints. Les deux coexistent sur des axes différents (item count % vs cumulative value %) et ne se contredisent pas. La cadence de cycle-count cascade automatiquement depuis la classe : items A tous les 30 jours, B tous les 60, C tous les 90. Selon SAM Q10 — réponse a : les ABC categories sont mises à jour manuellement dans l'application Inventory.⚠️ Piège IBM
SAM Q10 : où l'ABC est-il mis à jour manuellement ? — La réponse est l'application Inventory, PAS Reporting, Count Books ou Inventory Usage. Cela trompe les candidats qui confondent la génération de classe (où le report tourne) avec l'override de classe (où le changement manuel est appliqué).
- Piège : penser que les ABC categories se gèrent dans l'app Reporting. Faux — Reporting ne fait qu'afficher le report.
- Piège : penser que l'ABC se règle dans Count Books. Faux — les Count Books CONSOMMENT la classe ABC pour filtrer ; ils ne la gèrent pas.
- Piège : confondre l'ABC avec les Inventory Count Groups. Ce sont des dimensions de classification indépendantes.
- Piège : supposer que la classe N exclut des physical counts. Elle exclut du cycle counting automatique piloté par l'ABC ; les counts manuels ou pilotés par count-book fonctionnent toujours.
🎯 Carte mémoire
Q. Un item à faible coût mais mission-critical (il arrête l'usine s'il manque) est auto-classé C par l'ABC analysis de Maximo. L'ingénieur fiabilité veut que cet item soit compté mensuellement comme un item A. Que doit-il faire, et où ?
Afficher la réponse
Surcharger manuellement la classe ABC de C à A dans l'application Inventory (selon SAM Q10). Le champ Cycle Count Days se met à jour en conséquence. Best practice : combiner cet override manuel avec une classification VED (Vital/Essential/Desirable) documentée séparément, puisque l'ABC dollar-value pur rate les spares mission-critical à faible valeur.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — Le STU 7.1 explicite "Identify and explain ABC Analysis". IBM teste votre compréhension fondamentale du critère de classification, qui est la consommation valorisée annuelle. Beaucoup de candidats confondent ABC avec d'autres taxonomies de l'industrie (commodity codes alphabétiques, criticité, lead time).
Le contexte théorique d'abord — L'analyse ABC découle directement du principe de Pareto, formalisé par Vilfredo Pareto en 1896 : 80 % des effets viennent de 20 % des causes. Appliqué à l'inventaire : 80 % de la valeur consommée vient de 20 % des items. Cette concentration permet de concentrer l'effort opérationnel (cycle counts, control checks, supplier scrutiny) sur le petit nombre d'items qui pèsent. Les items A représentent typiquement 20% en quantité mais 70-80% en valeur ; les B 30-35% en quantité et 15% en valeur ; les C 40-50% en quantité et 5% en valeur [EOTRAG Query 3].
Ce que Maximo en fait — version opérationnelle — Le RAG cite verbatim : « Le rapport Inventory ABC Analysis multiplie la quantité émise YTD courante par le last cost de l'item. ... Type A break point 30%, Type B break point 30%, Type C break point 40%. » [EOTRAG Query 3]. Le rapport, lancé depuis Inventory ou Reporting, parcourt les items, calcule dollar_value = YTD_ISSUED × LASTCOST, trie en ordre décroissant, applique les breakpoints cumulés. Chaque item reçoit son ABC TYPE (A/B/C/N). En même temps, Maximo stamp les Cycle Count Days correspondants.
Exemple chiffré — 1000 items dans le storeroom. YTD_ISSUED × LASTCOST varie de 0 $ à 50 000 $/item. Total = 5 M $/an. Top 200 items représentent 4 M $ (80 % de la valeur) → classés A. Items 201-500 représentent 750 K $ (15 %) → B. Items 501-1000 représentent 250 K $ (5 %) → C. Items à 0 consommation YTD → N. Effort de cycle counting concentré sur les 200 items A (monthly count = 200 × 12 = 2400 counts/an), pas sur les 500 C (annual = 500 counts/an).
Analogie quotidienne — Dans votre garde-robe, vous avez 100 vêtements. Les 20 que vous portez chaque semaine = vos "A". Les 30 que vous portez parfois = "B". Les 50 que vous ne portez jamais = "C". Si vous deviez vérifier l'état de votre garde-robe chaque mois, vous vous concentreriez logiquement sur les A (les plus utilisés et donc les plus à risque d'usure). C'est l'idée d'ABC.
Pourquoi A est faux — Alphabétique est purement lexical, sans rapport avec valeur économique. Pattern D8 (Keyword-echo) : les lettres A/B/C font penser à un alphabet. Mais Maximo's ABC (et tout le standard industriel) est valeur-based, pas alphabetic.
Pourquoi B est faux — Storage location (bin) sert à organiser physiquement, mais ne reflète pas la priorité économique. Pattern D9 (Near-synonym) : "classification" peut se confondre avec "indexation par localisation" pour un candidat distrait, mais ABC adresse la dimension valeur, pas physique.
Pourquoi D est faux — Lead time est une autre dimension de classification (utilisée dans VED ou XYZ analyses), mais pas dans ABC standard. Pattern D2 (Invented) : il y a des extensions ABC qui intègrent lead time, mais Maximo's standard est strict YTD_issued × cost.
- Pareto principle — 80/20 : 20 % des items = 80 % de la valeur.
- Maximo ABC formula — dollar_value = YTD_issued × last_cost.
- 3 classes + N — A (top value), B (middle), C (bottom), N (no category, excluded).
- Auto cycle count days — A=30, B=60, C=90 typical (configurable).
- ABC = consumption value (YTD issued × last cost).
- Pas alphabetic, pas localisation, pas lead time.
- Drives cycle count frequency automatically.
- STU 7.1 — Identify and explain ABC Analysis
- [EOTRAG] Query 3 — ABC Analysis verbatim from IBM Maximo SysAdmin Guide
- master-map.pdf p.787-832 ABC Analysis report
Correct :A
Pourquoi cette question existe — Les ABC breakpoints sont des paramètres organisationnels qui s'appliquent globalement à tous les items et tous les storerooms d'une organization. IBM teste votre connaissance précise du chemin de configuration, qui est dans Organizations app, pas dans Inventory ni Reporting.
Le contexte théorique d'abord — En architecture EAM, les paramètres globaux (currency, cost types, ABC thresholds, cycle count rules) vivent au niveau Organization parce qu'ils standardisent la pratique pour tous les sites/storerooms de l'org. Cela évite que chaque storeroom configure ses propres breakpoints, ce qui rendrait la comparaison cross-site impossible. Le principe : configurations rares et stratégiques au niveau Org ; configurations fréquentes et opérationnelles au niveau Site/Storeroom/Item.
Ce que Maximo en fait — version opérationnelle — Le chemin est : Organizations app → ouvrir l'org → tab Inventory Options → section ABC Breakpoints. On y saisit les 3 percentages : Type A break point, Type B break point, Type C break point (somme = 100%). Sauvegarder applique les nouveaux thresholds dès la prochaine exécution du report ABC Analysis. Les item records existants conservent leur classification jusqu'au prochain run.
Exemple chiffré — Default IBM : A=30%, B=30%, C=40%. L'admin override pour adapter à un usage où la valeur est plus concentrée : A=20%, B=30%, C=50%. Cela classera moins d'items en A (20% au lieu de 30%) et plus en C — réduisant l'effort cycle count sur les A à 20% × 1000 = 200 items × 12 counts = 2400 counts/an au lieu de 30% × 1000 = 300 × 12 = 3600 counts/an.
Analogie quotidienne — Les standards globaux d'une entreprise (ex: durée congés, niveau de rémunération minimum) sont définis au siège, pas dans chaque agence locale. ABC breakpoints sont l'analogue : un seul réglage corporate, appliqué partout.
Pourquoi B est faux — Inventory app gère les items individuellement, pas la configuration globale. Pattern D6 (Wrong-app) : Inventory app expose la classe ABC sur chaque item, mais ne configure pas les seuils. Le piège fonctionne sur les candidats qui pensent "ABC = inventaire = Inventory app".
Pourquoi C est faux — Reporting app exécute le rapport mais ne configure pas les paramètres permanents. Pattern D5 (Sibling-field) : sur la fenêtre de lancement du rapport, on peut peut-être ajuster les paramètres pour ce run-là, mais les seuils permanents sont stockés au niveau Org. Le piège fonctionne sur les candidats qui confondent "lancer un rapport" avec "configurer les règles".
Pourquoi D est faux — Count Books utilise les classes ABC, ne les configure pas. Pattern D7 (Non-existent) : Count Books n'a pas de "Settings tab" pour ABC. Le piège fonctionne sur les candidats qui voient le lien ABC ↔ count counting et présument que la config se fait en aval.
- Org-level config — Organizations app → Inventory Options.
- 3 breakpoints — A%, B%, C% summing to 100.
- Default IBM — 30/30/40 (typical).
- Effect — applied next ABC report run, not retroactive.
- ABC Breakpoints = Organizations app, Inventory Options.
- Pas dans Inventory app (item-level), Reporting (rapport seulement), Count Books (consumer).
- 3 percentages somme 100.
- STU 7.1 — Identify and explain ABC Analysis
- [EOTRAG] Query 3 — Organizations app ABC Breakpoints
- master-map.pdf p.787-832 ABC Breakpoints config
Correct :C
Pourquoi cette question existe — Le STU 7.1 explicite "Define Physical Count Frequency". Le lien entre classe ABC et cycle count days est le mécanisme operational central qui justifie l'effort de classification. IBM teste si vous comprenez la logique : plus haute valeur = plus de fréquence de comptage.
Le contexte théorique d'abord — La logique du cycle counting frequency est inversement proportionnelle à la stabilité de la balance : les items A à haut volume de transactions risquent plus d'erreurs (mis-pick, mis-receipt) parce qu'ils tournent vite ; il faut donc les compter plus souvent pour détecter les écarts tôt. Les items C à faible volume ne génèrent pas beaucoup d'erreurs cumulatives ; un comptage annuel suffit. C'est l'inverse du sens "high value = important = compté souvent" qui est intuitivement attirant mais imprécis ; le vrai driver est la fréquence de transactions, qui correlate avec la consumption value.
Ce que Maximo en fait — version opérationnelle — Le RAG cite verbatim : "Type A cycle counts can be 30 days, type B cycle counts 60 days, and type C cycle counts 90 days." [EOTRAG Query 3]. Le rapport ABC Analysis update CYCLECNTDAYS sur chaque item record selon sa classe. Le storeroom clerk peut ensuite voir la "Next Count Date" sur chaque item (= LASTCOUNTDATE + CYCLECNTDAYS). Les Count Books peuvent filtrer par "items due for count today" pour générer la liste de la journée.
Exemple chiffré — Item X classé A → CYCLECNTDAYS=30. LASTCOUNTDATE=2026-04-01. Next count due = 2026-05-01. Sur 1000 items dans le storeroom : 200 A × (365/30) = 2400 counts/an + 300 B × 4 = 1200 + 500 C × 1 = 500. Total ~4100 counts/an, distributed mostly on A (~58%).
Analogie quotidienne — Vous vérifiez le solde de votre compte courant (haute fréquence d'opérations = A) toutes les semaines. Votre compte épargne (transactions rares = C), vous le checkez tous les 3 mois. Vous ne consacrez pas le même temps de vérification aux deux.
Pourquoi A est faux — Counter tout annuellement défait l'objectif de l'ABC. Pattern D7 (Non-existent) : si tout était annuel, ABC n'apporterait aucune valeur opérationnelle.
Pourquoi B est faux — Inverser les fréquences (A annuellement, C mensuellement) est l'opposé du standard. Pattern D3 (Inverse) : c'est le piège classique parce que certains candidats raisonnent "C est rare donc important". Faux : C est rare donc à risque faible cumulatif.
Pourquoi D est faux — Affirmer pas d'auto-set est faux. Pattern D7 (Non-existent) : Maximo auto-stamp CYCLECNTDAYS via le rapport ABC. La configuration manuelle est possible (override per-item) mais le mécanisme automatique est le standard.
- Classe A — valeur de consommation élevée → cycle count ~30 jours (12×/an).
- Classe B — moyenne → ~60-90 jours (4-6×/an).
- Classe C — faible → ~90-365 jours (1-4×/an).
- Auto-stamp — le rapport ABC met à jour CYCLECNTDAYS sur le record item.
- A monthly, B quarterly, C annual.
- Higher consumption value = more frequent cycle count.
- Pas l'inverse (le piège D3).
- STU 7.1 — Define Physical Count Frequency
- [EOTRAG] Query 3 — A=30, B=60, C=90 verbatim
- [EOTRAG] Query 5 — Cycle counting strategies
Correct :A
Pourquoi cette question existe — C'est le SAM Q10 verbatim. IBM teste votre maîtrise du data-model Maximo : la classe ABC est un attribut au niveau item, géré dans l'application qui possède l'item record côté inventaire — l'app Inventory. Beaucoup de candidats échouent en confondant "où le rapport est lancé" (Reporting) avec "où la classe est éditée" (Inventory).
Le contexte théorique d'abord — En architecture EAM, chaque attribut métier est édité dans son application "owner". Les attributs cycle de vie d'un item sont éditables dans l'app qui héberge la perspective opérationnelle : Item Master pour les attributs maître (description, UoM, commodity), et Inventory pour les attributs storeroom-spécifiques (qty, ROP, EOQ, lead time, ABC class, cycle count days). Cette séparation reflète le fait qu'un même item peut avoir une classe ABC différente dans chaque storeroom (consommation locale différente).
Ce que Maximo en fait — version opérationnelle — Sur Inventory app, ouvrir l'item, le champ "ABC Type" est éditable directement. L'utilisateur peut le passer de C à A pour cet item dans ce storeroom. La sauvegarde update INVENTORY.ABCTYPE. Le rapport ABC Analysis exécuté ultérieurement RECALCULERA cette classe (et risque de la repasser à C). Pour empêcher l'override d'être écrasé, certaines orgs ajoutent un flag "ABC manual override" qui bloque l'auto-update — mais c'est une customization, pas standard.
Exemple chiffré — Item ROND-O-001 (joint torique critique) : YTD_issued = 5 unités × cost 2 $ = 10 $/an → auto-classé C. Reliability engineer ouvre Inventory → ROND-O-001 → change ABC TYPE = A → save. Maintenant CYCLECNTDAYS = 30 (cycle count mensuel), au lieu de 365. Cet item, malgré son très faible consumption value, est désormais counté chaque mois pour empêcher rupture catastrophique (le joint stoppe la centrale).
Analogie quotidienne — Votre compte épargne a peu de transactions (auto-classé "low priority"). Mais vous savez qu'il contient un montant critique pour un projet majeur. Vous décidez manuellement de le surveiller chaque semaine, pas trimestriellement. Le système peut prédire la priorité par défaut, mais l'humain a le dernier mot.
Pourquoi B est faux — Reporting app permet de lancer le rapport ABC Analysis qui auto-classifie, mais ne permet pas l'édition d'un item individuel. Pattern D6 (Wrong-app) : c'est le piège natural pour qui pense "ABC = ABC report = Reporting". Le rapport calcule, l'Inventory app édite.
Pourquoi C est faux — Count Books utilise la classe ABC pour filtrer les items à compter, mais ne permet pas son édition. Pattern D6 (Wrong-app) : downstream consumer, pas owner. Le piège fonctionne sur les candidats qui pensent "ABC = cycle count = Count Books".
Pourquoi D est faux — Inventory Usage est l'app pour issue/return material, sans rapport avec la classification ABC. Pattern D6 (Wrong-app) : son nom contient "Inventory" mais son scope est différent (transactions issue, pas master classification).
- SAM Q10 answer — Inventory app for manual ABC override.
- Trap D6 — Reporting (calc) ≠ Count Books (consume) ≠ Inv Usage (transactions) ≠ Inventory (edit).
- Risque d'override — la prochaine exécution du rapport ABC peut écraser. Ajouter un flag manuel si nécessaire.
- Use case — insurance spares, mission-critical low-value items, regulatory items.
- SAM Q10 : manual ABC update = Inventory app.
- Pas Reporting, pas Count Books, pas Inv Usage.
- L'edit se fait sur le record item dans Inventory.
- SAM Q10 — verbatim
- STU 7.1 — Identify and explain ABC Analysis
- [EOTRAG] Query 3 — Maximo ABC application
Correct :B
Pourquoi cette question existe — Le STU 7.1 mentionne explicitement "Identify and explain Inventory Count Groups". C'est une dimension de classification distincte de ABC, et IBM teste si vous savez qu'elle existe et son cas d'usage.
Le contexte théorique d'abord — ABC est dimension valeur ; les Inventory Count Groups sont dimension métier libre (zone, fonction, criticité, propriétaire). Les deux sont orthogonales : un item peut être ABC=A ET Count Group=ZONE-A. Le bénéfice : permet aux Count Books de filtrer par autre critère que la valeur. Cas typique : "compter aujourd'hui la zone A" plutôt que "compter aujourd'hui les items A". Optimisation logistique (déplacement physique du clerk), pas optimisation valeur.
Ce que Maximo en fait — version opérationnelle — Sur Inventory app, le champ "Count Group" peut être assigné à chaque item. Les valeurs sont définies par l'organisation (ex : ZONE-A, ZONE-B, ZONE-C ; ou CRIT-HIGH, CRIT-MED, CRIT-LOW). Au moment de générer un Count Book (lesson 7.2), le clerk peut filtrer par Count Group au lieu de ABC. Sample type ICG (Inventory Count Group) dans les Sample Types est précisément le mécanisme qui consomme cette classification.
Exemple chiffré — Storeroom 1 : 1000 items répartis 3 zones physiques. Count Group ZONE-A = 350 items, ZONE-B = 350, ZONE-C = 300. Le clerk fait un Count Book "Zone A weekly walk-through" : ICG=ZONE-A → génère 350 lignes à compter en marchant cette zone seule, sans aller-retour. Plus efficient qu'un Count Book ABC=A qui pourrait éparpiller le clerk dans 3 zones.
Analogie quotidienne — Vous organisez vos courses : par "produit nécessaire" (ABC = par priorité, lait avant cookies) OU par "rayon" (Count Group = par zone, tout le rayon laitier d'un coup). Les deux dimensions co-existent dans votre liste mentale.
Pourquoi A est faux — ABC custom breakpoints reste sur la même dimension (valeur). Pattern D8 (Keyword-echo) : "ABC analysis" est mentionné dans la question (cycle count) mais la question demande une grouping "regardless of ABC". Ce n'est pas une variante d'ABC qu'on cherche.
Pourquoi C est faux — Commodity Codes classifient par catégorie produit (ELEC, MECH, INSTR), pas par zone physique. Pattern D9 (Near-synonym) : commodity et count group sont tous deux des classifications, mais leur usage diffère. Commodity = procurement focus, Count Group = counting focus.
Pourquoi D est faux — Item Sets sont au niveau Org (groupes d'items partageant le même catalogue), pas une dimension de count grouping. Pattern D6 (Wrong-app) : Item Sets gère la mutualisation cross-org, pas le counting.
- ABC vs Count Group — orthogonal dimensions ; coexistent.
- Use cases Count Group — zone physique, criticité, équipe propriétaire, fonction.
- Sample type ICG — utilise Count Group dans Count Books (lesson 7.2).
- Bénéfice — count walk-route efficiency.
- Inventory Count Groups = grouping orthogonal à ABC.
- Cas d'usage : zone physique, criticité, équipe.
- Sample type ICG dans Count Books exploite cette classification.
- STU 7.1 — Identify and explain Inventory Count Groups
- master-map.pdf p.787-832 Count Group field on Inventory record
- STU 7.2 — Sample type ICG verbatim
Correct :C
Pourquoi cette question existe — Le RAG explicitement mentionne "Type N (no category) excludes the item from ABC — used for service items, special-order items, items not under cycle-count discipline" [EOTRAG Query 3]. IBM teste votre connaissance de ce 4ème "rang" caché du système ABC.
Le contexte théorique d'abord — Tous les items ne devraient pas suivre la discipline cycle counting. Les service items (calibration, inspections), les special-order items (achetés une seule fois, jamais re-stockés), les items en discontinuation ne devraient pas générer de cycle count. Les compter ne donnerait aucune valeur — il n'y a pas d'inventory à vérifier ou la consommation est si erratique que la fréquence ABC est inappropriée. Maximo prévoit la classe N pour les exclure proprement, sans hacker le système avec un C trop générique.
Ce que Maximo en fait — version opérationnelle — Sur Inventory app, ABC TYPE = N. CYCLECNTDAYS reste vide (ou 0). Les Count Books générés via sample type CNTFREQ excluent automatiquement les N. Le clerk peut quand même counter manuellement un item N via Count Book sample type ALL ou ITEM, mais ce n'est pas auto-scheduled.
Exemple chiffré — Sur 1000 items : 200 A, 300 B, 400 C, 100 N. Cycle counts auto-générés : 200 × 12 + 300 × 4 + 400 × 1 = 4000 counts/an. Les 100 N ne génèrent aucun count automatique = ressources économisées sur des items où ça n'apporte rien.
Analogie quotidienne — Dans une bibliothèque, certains livres (ouvrages de référence rare consultés sur place) ne sont jamais empruntés. Les compter chaque jour serait inutile. On les marque "non-empruntables" → ils sortent du suivi quotidien des emprunts.
Pourquoi A est faux — Classer en C compterait l'item annuellement, ce que le planner veut éviter. Pattern D4 (Partial-truth) : C est la classe "lowest priority" mais pas "exclusion totale". Le piège fonctionne sur les candidats qui ne savent pas que N existe.
Pourquoi B est faux — Z n'existe pas dans Maximo. Pattern D2 (Invented) : la lettre Z sonne plausible (en fin d'alphabet, suggérant exclusion) mais c'est inventé. Le standard ABC est ABC + N.
Pourquoi D est faux — Affirmer pas d'exclusion est faux. Pattern D7 (Non-existent) : la classe N existe précisément pour ce cas. Le piège fonctionne sur les candidats qui n'ont vu que A/B/C dans la documentation.
- 4 classes effectives — A, B, C, N.
- N = No category — exclude from auto cycle counting.
- Use cases — service items, special-order, discontinued, low-volume sporadic.
- Manuel count toujours possible via sample types ALL/ITEM.
- ABC = A, B, C, N (4 classes).
- N = exclu des cycle counts auto-générés.
- Pas de classe Z ni de C comme exclusion par défaut.
- STU 7.1 — Identify and explain ABC Analysis
- [EOTRAG] Query 3 — Type N excludes from ABC verbatim
- master-map.pdf p.787-832 ABC TYPE field values
Correct :B
Pourquoi cette question existe — Le RAG mentionne explicitement le complément VED comme best practice industrie : "Pure dollar-value ABC misses mission-critical low-value spares. Industry best practice is dual classification: ABC (value) + VED (Vital/Essential/Desirable, criticality) → 9-cell matrix." [EOTRAG Query 3]. IBM peut tester cette best practice même si Maximo standard n'implémente pas VED nativement.
Le contexte théorique d'abord — VED est un système de classification développé pour le spare parts inventory dans les industries process/heavy : Vital = item critique, son absence stoppe la production immédiatement (e.g. pompe principale d'une raffinerie) ; Essential = item nécessaire, mais bypass possible 24-72h ; Desirable = nice-to-have, optionnel. La combinaison ABC × VED donne 9 cellules : un item AV est high-value + vital (ex : turbine de 500 K $), un CV est low-value + vital (ex : joint torique de 5 $ qui stoppe le plant). Les CV sont précisément les items "manqués par ABC seul" qui méritent un override manual.
Ce que Maximo en fait — version opérationnelle — Maximo standard ne livre pas VED nativement. Les organisations matures custom-isent : ajout d'un champ "Criticality" (V/E/D) sur Inventory record (via Application Designer), ou usage du field PRIORITY existant. Le rapport ABC est complété par un rapport custom "ABC × VED matrix" pour identifier les CV/EV qui méritent attention manuelle. Cette pratique est citée dans la littérature ISO 55001 et MRO Best Practices [EOTRAG Query 15].
Exemple chiffré — 1000 items. ABC : 200 A, 300 B, 400 C, 100 N. VED : 50 V, 200 E, 750 D. Matrix : AV=20, AE=80, AD=100, BV=15, BE=60, BD=225, CV=15, CE=60, CD=325. Les 15 items CV sont les "low-value vital" — souvent les O-rings, fasteners, joints critiques. Maximo override manuel ABC → A pour ces 15 = cycle count monthly. Coût : 15 × 12 = 180 counts/an. Bénéfice : prévention rupture catastrophique.
Analogie quotidienne — Votre liste de courses peut être triée par prix (ABC) ou par criticité ("besoin vital pour le repas de ce soir" vs "nice-to-have"). Les deux dimensions co-existent : si vous ne pouvez tracker qu'un seul, vous risquez de manquer le sel (criticality V, value C) tout en focussant sur le steak (value A, criticality V).
Pourquoi A est faux — UNSPSC commodity codes classent par catégorie produit, pas par criticité. Pattern D6 (Wrong-app) : utile pour spend analysis, pas pour spare parts criticality. Le piège fonctionne sur les candidats qui pensent toute classification = même usage.
Pourquoi C est faux — Cost type STANDARD est une méthode de costing, pas une classification de criticité. Pattern D6 (Wrong-app) : aucun lien avec criticality decision.
Pourquoi D est faux — Issue Unit standardization concerne UoM, pas criticité. Pattern D6 (Wrong-app) : confusion entre catégorisation criticité et harmonisation UoM.
- VED — Vital / Essential / Desirable classification.
- ABC × VED matrix — 9 cells, identifies CV (low-value-vital) items.
- Maximo standard — n'implémente pas VED nativement, custom field commun.
- Use cases — spare parts à criticité dissociée de la valeur.
- ABC seul = aveugle aux items low-value mais critiques.
- ABC + VED = matrix 9 cellules pour gestion riche.
- VED non native Maximo, mais best practice citée ISO 55001.
- STU 7.1 — Limit of pure value-based ABC
- [EOTRAG] Query 3 — ABC + VED dual classification
- [EOTRAG] Query 15 — Spare parts criticality (Slater Sparesology)
Exécuter les inventaires physiques (Count Books, Sample Types)

📋 Objectifs IBM
- Mettre à jour le Physical Count dans l'application Inventory pour des corrections ad-hoc d'un item unique
- Reconcile Balances après une session de count
- Créer un Count Book pour rassembler les SKUs d'une session de count (rotating + non-rotating)
- Décrire les 7 Sample Types : ALL · BIN · CNTFREQ · ICG · ITEM · ROTATING · TOOLS
- Exécuter le Physical Counting et le workflow Reconcile / Unreconcile
💡 Points clés
- Count Book — un document Maximo qui rassemble une liste d'items à compter dans une seule session. Workflow : générer → imprimer/assigner → comptage physique → saisir les counts → reconcile → close.
- Sample Types (7) — le critère utilisé par Maximo pour peupler le Count Book avec des items :
- ALL — tous les items du storeroom (ou filtrer par storeroom + plage de bins). Utilisé pour les inventaires physiques complets.
- BIN — items localisés dans un bin spécifique (ou liste de bins). Utilisé pour le comptage zone par zone.
- CNTFREQ (Count Frequency) — items dus pour count selon les cycle count days de la classe ABC. Utilisé pour le cycle counting de routine.
- ICG (Inventory Count Group) — items appartenant à un Count Group spécifique (leçon 7.1). Utilisé pour grouper par zone, criticité ou département.
- ITEM — une liste d'items saisie manuellement par ITEMNUM. Utilisé pour les audits ad-hoc.
- ROTATING — uniquement les rotating items (asset-tracked). Utilisé pour les audits d'existence d'assets.
- TOOLS — items définis comme tools (TOOL type). Utilisé pour les audits d'inventaire d'outils.
- Update Physical Count (ad-hoc) — pour une correction d'un item unique, l'utilisateur peut directement mettre à jour le physical count dans l'app Inventory (champ item-level), en contournant le mécanisme Count Book. Utile pour les corrections ponctuelles après découverte.
- Count entry — les counts sont saisis contre chaque ligne du Count Book. Chaque ligne capture la qty COUNTED vs la qty EXPECTED (balance système au moment du count).
- Reconciliation — comparer COUNTED vs EXPECTED pour chaque ligne. Dans la tolérance : auto-posté (ajustement INVTRANS généré). Hors tolérance : flagué pour recount ou approbation supervisor.
- Reconcile Balances — l'action qui déclenche le calcul de reconciliation. Génère des lignes INVTRANS de type CYCLECOUNT et poste les ajustements GL.
- Unreconcile — réverse une reconciliation postée si des erreurs sont détectées a posteriori. Journalisée pour audit.
- Tolerance — configurable par classe ABC ou par item. Items A typiquement ±2%, B ±5%, C ±10% [EOTRAG Query 5].
- Séparation des tâches (SOX) — le floor counter ne peut pas poster son propre count ; supervisor ou stock manager valide et poste. Imposé par RBAC/security groups.
- Workflow Recount — les counts hors tolérance déclenchent un statut « recount required » ; second count saisi ; s'il correspond, posté ; s'il diverge encore, escalade au manager.
- Mobile counting — Maximo Mobile + Inventory Counting RBA permettent le scan handheld des bins ; counts saisis sur place, validés immédiatement contre la tolérance.
| Sample type | Critère de filtre | Cas d'usage |
|---|---|---|
ALL |
Tout item actif du storeroom peu importe la catégorie. | Inventaire physique annuel complet. |
BIN |
Items dans un numéro de bin spécifique (ou liste de bins). | Recount ciblé quand un bin spécifique montre une variance. |
CNTFREQ |
Items dont la Cycle Count Frequency est due selon le date stamp. | Cycle counting de routine ; combiné avec l'ABC, pilote le calendrier. |
ICG |
Items appartenant à un Inventory Count Group spécifique. | Counts pilotés par groupe (par criticité, projet, location). |
ITEM |
Un item number spécifique (ou liste définie). | Spot-count après historique de transactions suspect. |
ROTATING |
Uniquement les items avec flag Rotating? = true. | Audit asset — vérifier que chaque rotating asset est physiquement présent. |
TOOLS |
Uniquement les items de type Tool. | Audit du tool crib ; les tools sont à haut risque de perte et exigent des counts fréquents. |
⚠️ Piège IBM
Les 7 Sample Types sont ciblés à l'examen. IBM teste votre capacité à les nommer et à choisir le bon pour un scénario donné.
- Piège : confondre CNTFREQ (cycle count days pilotés par l'ABC) avec ICG (Count Groups, classification alternative).
- Piège : confondre BIN (location de bin spécifique) avec ALL (storeroom entier).
- Piège : penser que ROTATING et TOOLS sont identiques — ce sont des types séparés car les tools ne sont pas toujours rotating, et les rotating items ne sont pas toujours des tools.
- Piège : supposer qu'Update Physical Count dans l'app Inventory fait la même chose qu'une saisie de Count Book. L'update dans Inventory est une correction de ligne unique ; le Count Book est une session structurée avec workflow de reconciliation.
🎯 Carte mémoire
Q. Un storeroom manager veut un Count Book listant uniquement les items dus pour count aujourd'hui, selon leur classe ABC. Quel Sample Type doit être utilisé ?
Afficher la réponse
CNTFREQ (Count Frequency). Il sélectionne les items où la date d'aujourd'hui ≥ LASTCOUNTDATE + CYCLECNTDAYS. ICG groupe par Count Group (zone/dept), BIN par bin physique, ALL par storeroom entier, ITEM par liste manuelle. Seul CNTFREQ filtre par cycle de count piloté par l'ABC.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :C
Pourquoi cette question existe — Le STU 7.2 explicite "describe Sample Types : ALL · BIN · CNTFREQ · ICG · ITEM · ROTATING · TOOLS". CNTFREQ est l'un des 7 sample types et c'est le plus fréquemment utilisé en routine cycle counting. IBM teste votre capacité à mapper un cas d'usage business à le sample type correct.
Le contexte théorique d'abord — En cycle counting routinier, on veut compter chaque jour seulement les items qui sont DUE pour un count à cette date. Cela évite la double counting (items déjà counted récemment) et le blocage de stock (items pas encore due gagnent du temps). Le mécanisme : chaque item a son CYCLECNTDAYS (driven by ABC class) et LASTCOUNTDATE. Item due = today >= LASTCOUNTDATE + CYCLECNTDAYS. CNTFREQ filtre exactement sur cette condition.
Ce que Maximo en fait — version opérationnelle — Sur Inventory Counting RBA → Create Count Book → Sample Type = CNTFREQ → Storeroom = WH-MAIN. Maximo query INVENTORY where (CYCLECNTDAYS not null) AND (today >= LASTCOUNTDATE + CYCLECNTDAYS interval). Liste résultat : tous les items dont c'est l'heure de compter aujourd'hui. Le Count Book est généré avec ces lignes ; print, send to handheld du clerk. Après reconciliation, LASTCOUNTDATE = today pour ces items, donc next count = today + CYCLECNTDAYS.
Exemple chiffré — Storeroom 1000 items. ABC distribution : 200 A (count every 30 days = 7 due/day average), 300 B (every 60 days = 5 due/day), 400 C (every 90 days = 4-5 due/day). Total ~17 items due/day en moyenne. Count Book CNTFREQ généré chaque matin = 17 lignes typically. Workload prévisible, distribué dans le temps.
Analogie quotidienne — Votre dentiste vous appelle pour un rendez-vous : "Patients due for checkup this month". Pas "tous les patients" (= ALL), pas "patients du quartier nord" (= ICG par zone), pas "patients que je nomme à la main" (= ITEM). C'est filtré par "fréquence de visite × date du dernier RDV", exactement comme CNTFREQ.
Pourquoi A est faux — ALL counterait tous les items du storeroom, ignorant la cycle frequency. Pattern D9 (Near-synonym) : ALL est utilisé pour les inventaires annuels totaux, pas pour le routine cycle counting.
Pourquoi B est faux — ICG filtre par Inventory Count Group (zone, dept), pas par cycle frequency. Pattern D9 (Near-synonym) : les deux sont des classifications mais sur dimensions différentes. ICG est dimension "où physiquement", CNTFREQ est dimension "quand temporellement".
Pourquoi D est faux — ITEM est une liste manuelle. Pattern D9 (Near-synonym) : pour un cycle counting routinier auto-piloté, manuel = inefficient. ITEM serait pour un audit spécifique sur quelques items précis.
- CNTFREQ — items due for cycle count based on CYCLECNTDAYS + LASTCOUNTDATE.
- ICG — items in a specific Count Group (zone, dept, criticality).
- ALL — entire storeroom, ignoring cycle frequency.
- ITEM — manual list, ad-hoc audit.
- CNTFREQ = items due based on ABC-driven cycle count.
- Le sample type le plus fréquent en routine cycle counting.
- Driven by CYCLECNTDAYS + LASTCOUNTDATE.
- STU 7.2 — Sample Types verbatim
- [EOTRAG] Query 5 — Cycle counting strategies
- master-map.pdf p.787-832 Count Books Sample Types
Correct :A
Pourquoi cette question existe — IBM teste votre capacité à distinguer ROTATING vs TOOLS, qui sont des dimensions distinctes même si elles peuvent se chevaucher. Tous les rotating ne sont pas des tools, et inversement.
Le contexte théorique d'abord — Un rotating item est défini par rotating=Y sur Item Master ; il existe simultanément comme record d'inventory et comme record d'asset (sériali sé). Les motors, pumps, valves principales sont typiquement rotating. Les tools sont une catégorie distincte (Item Type = TOOL) qui peut être rotating (ex : couple wrench calibrated, with serial number for calibration tracking) ou non-rotating (ex : screwdriver, fungible). Le RAG cite "perform Asset Serialization" pour les rotating items et "Receive Tools from a PO" comme topic distinct [EOTRAG STU 6.1]. Pour un auditor, vérifier "tous les rotating dans le warehouse" inclut les motors, pumps, etc., qu'ils soient tools ou non.
Ce que Maximo en fait — version opérationnelle — Sample Type = ROTATING génère un Count Book avec tous les items où ITEM.ROTATING=Y dans le storeroom. Pour chaque item rotating, le Count Book liste les ASSETNUMs spécifiques (puisque chaque unit est unique). Le clerk va à chaque bin, scanne le serial du motor, et le compare au manifest. Existence audit complete.
Exemple chiffré — Storeroom 1000 items dont 50 rotating (motors, pumps, gearboxes) et 200 tools (dont 20 tools rotating). Sample Type ROTATING génère 50 lignes (les 50 rotating). Sample Type TOOLS génère 200 lignes (les 200 tools, dont 20 rotating + 180 non-rotating). Les 20 rotating tools sont counted dans les deux types — overlap normal.
Analogie quotidienne — Dans un parking d'entreprise : sample type "voitures de société" (= ROTATING, suivies individuellement) vs "outillage de jardin" (= TOOLS, peut inclure tondeuse rotating + sécateur non-rotating). Pour audit "toutes les voitures de société existent ?" → sample voitures, pas outillage.
Pourquoi B est faux — TOOLS filtre uniquement les items type=TOOL, manquant les rotating non-tool (ex : motors, pumps installés comme spares). Pattern D9 (Near-synonym) : "ROTATING" et "TOOLS" sont deux types distincts dans Maximo, malgré leur chevauchement possible. Si l'auditor veut tous les rotating (peu importe tool ou pas), TOOLS est insuffisant.
Pourquoi C est faux — ALL counterait tout le storeroom, énorme over-effort. Pattern D4 (Partial-truth) : ALL inclut bien les rotating, mais aussi les 950 non-rotating qui n'ont pas besoin d'audit unique pour ce besoin précis.
Pourquoi D est faux — CNTFREQ filtre par due-date, pas par rotating-ness. Pattern D5 (Sibling-field) : c'est un autre sample type du même menu mais avec critère différent.
- ROTATING vs TOOLS — dimensions distinctes ; chevauchement possible.
- ROTATING — ITEM.ROTATING=Y. Inclut motors, pumps, valves, rotating tools.
- TOOLS — ITEM.TYPE=TOOL. Inclut tools rotating et non-rotating.
- Use case ROTATING — audit existence ASSETNUMs en stock.
- ROTATING ≠ TOOLS. Dimensions séparées.
- Audit asset existence → ROTATING.
- Audit tools inventory → TOOLS.
- STU 7.2 — Sample Types ROTATING and TOOLS
- [EOTRAG] Query 5 — Why count rotating items?
- [EOTRAG] Query 6 — Rotating definition
Correct :C
Pourquoi cette question existe — Le STU 7.2 explicite "Reconcile Balances". Le mécanisme tolerance + recount workflow est l'un des aspects les plus testés du physical counting parce qu'il combine technique (calcul variance) et organisationnel (separation of duties).
Le contexte théorique d'abord — Le RAG mentionne explicitement : "Counts within tolerance auto-post; counts outside trigger recount workflow" [EOTRAG Query 5]. Cette dualité est le cœur du processus : minimiser le travail (auto-post les bonnes) et maximiser le contrôle (escalate les variances). Les variances peuvent venir de vraies erreurs (perte, vol, mis-pick) ou d'erreurs de count (mauvaise unité, item confondu) — d'où la nécessité d'un recount avant adjustment final. La séparation de duties (SOX) ajoute que le clerk qui count ne peut pas posté son own variance ; supervisor must approve.
Ce que Maximo en fait — version opérationnelle — Reconcile Balances calcule la variance pour chaque ligne : variance = COUNTED - EXPECTED. Tolerance check : |variance| / EXPECTED < tolerance? Si oui : auto-post. Maximo crée INVTRANS row type CYCLECOUNT avec adjustment qty. INVBALANCES updated. GL posted (Inventory Adjustment Gain ou Loss). Si non : line status passes "PENDING RECOUNT". Le clerk (ou supervisor) doit re-counter, ré-entrer, et re-tenter Reconcile. Si re-count match book → auto-post. Si encore variance → escalation manager + manual override avec audit trail.
Exemple chiffré — Item X : EXPECTED 100, COUNTED 110. Variance = +10, +10%. Tolerance = ±10%. 10% n'est pas < 10%, donc OUT. Status = PENDING RECOUNT. Item Y : EXPECTED 50, COUNTED 49. Variance = -1, -2%. Tolerance ±10%. 2% < 10% → AUTO POST. INVTRANS row generated for Y, balance updated. X attend.
Analogie quotidienne — Vous comparez votre relevé bancaire avec votre carnet de chèques. Les écarts <5 $ sont absorbés (auto-post comme "frais"). Les écarts >5 $ vous appellent la banque (recount + escalation). Vous ne réconciliez pas tout aveuglément ni ne rejetez tout sur 1 erreur.
Pourquoi A est faux — Auto-post tout sans tolerance check brisrait le contrôle qualité. Pattern D7 (Non-existent) : Maximo a précisément le mécanisme tolerance pour éviter cela. Le piège fonctionne sur les candidats qui pensent "Reconcile = tout passe".
Pourquoi B est faux — Rejeter tous les 30 parce que 2 sont mauvais est rigide et inutile. Pattern D3 (Inverse) : ce serait une régression versus le but de l'efficience. Maximo permet le partial post précisément pour avancer sur les bonnes lignes pendant qu'on enquête sur les mauvaises.
Pourquoi D est faux — Silently écrire off les variances violerait l'audit. Pattern D2 (Invented) : Maximo n'absorbe jamais silencieusement ; tous les écarts vont en INVTRANS avec trace, et les hors tolerance demandent une décision documentée.
- Reconcile Balances — calc variance + tolerance check + post in-tolerance + flag out.
- Tolerance par classe ABC — A ±2%, B ±5%, C ±10% (typique).
- INVTRANS row — type CYCLECOUNT, qty = variance (positif ou négatif).
- Recount workflow — out-of-tolerance → PENDING RECOUNT → supervisor approval.
- Reconcile = auto-post in-tolerance + flag out-of-tolerance.
- JAMAIS auto-post hors tolerance, JAMAIS rejet total, JAMAIS write-off silencieux.
- Out-of-tolerance → recount + supervisor.
- STU 7.2 — Reconcile Balances
- [EOTRAG] Query 5 — Tolerances per ABC class
- [EOTRAG] Query 10 — Variance accounting
Correct :B
Pourquoi cette question existe — Le STU 7.2 explicite "Update Physical Count in Inventory app". C'est l'un des objectifs séparés de "Create Count Book". IBM teste votre capacité à choisir le bon mécanisme selon le scope de la correction (single line vs structured session).
Le contexte théorique d'abord — Les Count Books sont conçus pour des sessions de counting structurées (multiple items, workflow reconciliation, tolerance check). Pour une correction ad-hoc d'un seul item, ce serait du sur-équipement : créer un Count Book pour 1 ligne, le valider, le réconcilier serait inefficient. Maximo prévoit donc une action lightweight : "Update Physical Count" directement sur le record item, avec le même backend (génère INVTRANS row type CYCLECOUNT, met à jour balance, post GL adjustment).
Ce que Maximo en fait — version opérationnelle — Sur Inventory app → ouvrir l'item → action "Update Physical Count". Saisit la new physical qty (ou variance). Maximo crée INVTRANS row (qty = new - old, type CYCLECOUNT, REASON = manual update), update INVBALANCES, post GL. Audit trail capture qui (user), quand (datetime), pourquoi (reason free text). Pas besoin de Count Book document.
Exemple chiffré — Item X : INVBALANCES.QTY = 100. Clerk discovers 5 extra units in corner bin → physical = 105. Update Physical Count = 105. INVTRANS row : qty=+5, type=CYCLECOUNT, REASON="Found in unmapped bin during inspection 2026-04-27". INVBALANCES.QTY = 105. GL : credit Inventory Asset, debit Inventory Adjustment Gain pour 5 × cost.
Analogie quotidienne — Vous trouvez 20 $ dans la poche d'un vieux manteau. Vous ne lancez pas un audit complet de votre comptabilité personnelle ; vous ajoutez 20 $ à votre solde mental "trésor de poche". Pareil ici : correction simple, action simple.
Pourquoi A est faux — Attendre le prochain Count Book trimestriel laisserait la balance fausse pendant des mois, créant des risques opérationnels (mauvais ROP, mauvais issue planning) et financiers (sous-évaluation actif). Pattern D10 (Procedure-plausible) : ça sonne discipliné mais c'est inefficient.
Pourquoi C est faux — Créer un PO pour des items qu'on a déjà serait absurde. Pattern D6 (Wrong-app) : PO sert à acheter, pas à reconnaître stock existant.
Pourquoi D est faux — Issuer à un WO fictif est une fraude comptable. Pattern D2 (Invented) : aucun système ne tolère cela. C'est le genre de pratique qui mène à des audits SOX faillis et des poursuites.
- Update Physical Count — action sur Inventory record. Pour single-line correction.
- Count Book — pour sessions multi-lignes, structured workflow.
- Both génèrent INVTRANS row — backend identique, frontend différent.
- Use case — Update : ad-hoc spot correction. Count Book : routine ou audit complet.
- Update Physical Count = correction ad-hoc single-line dans Inventory app.
- Count Book = session structurée multi-lignes.
- Backend identique (INVTRANS), UX différent.
- STU 7.2 — Update Physical count in Inventory app
- master-map.pdf p.787-832 Update Physical Count action
- [EOTRAG] Query 14 — INVTRANS adjustment transactions
Correct :D
Pourquoi cette question existe — Le STU 7.2 liste explicitement les 7 Sample Types. ICG est l'un d'entre eux et le seul qui consomme la classification Inventory Count Group définie dans la lesson 7.1. IBM teste votre capacité à mapper le concept business (Count Groups) au mécanisme technique (Sample Type).
Le contexte théorique d'abord — Les Count Groups sont une classification orthogonale à ABC, généralement zone physique ou criticality (lesson 7.1). Pour les exploiter, il faut un mécanisme qui filtre les Count Books par cette dimension. Sample Type ICG (= Inventory Count Group) est exactement ce mécanisme. Sans lui, les Count Groups seraient documentaires sans usage opérationnel.
Ce que Maximo en fait — version opérationnelle — Sur Create Count Book → Sample Type = ICG → spécifier Count Group = ZONE-B. Maximo query INVENTORY where COUNTGROUP = 'ZONE-B' AND STOREROOM = 'WH1'. Liste générée : tous les items dans ZONE-B. Le clerk fait sa walking-route en ZONE-B sans devoir traverser le warehouse pour des items hors zone, gain d'efficience considérable.
Exemple chiffré — Storeroom 1000 items répartis 4 zones physiques. ZONE-B = 250 items. Sample Type ICG ZONE-B → 250 lignes. Clerk va en zone B avec son handheld, scan chaque bin de la zone, validate counts. 1.5 hour walk vs 4 hours si dispersé multi-zones.
Analogie quotidienne — Stocking inventory dans un grand magasin. Plutôt que de compter "tous les vêtements" (par catégorie), le manager dit "compte la zone Mode Femme". Le clerk reste dans cette zone, plus efficient.
Pourquoi A est faux — BIN filtre par bin physique précis (ex BIN-A101), pas par Count Group abstrait. Pattern D5 (Sibling-field) : BIN et ICG sont tous deux des sample types "spatiaux" mais à granularités différentes. BIN = très fin, ICG = group of bins/items.
Pourquoi B est faux — CNTFREQ filtre par due-date driven by ABC, pas par Count Group. Pattern D9 (Near-synonym) : c'est une autre dimension (temporelle), pas spatiale.
Pourquoi C est faux — ITEM est une liste manuelle d'ITEMNUMs. Pattern D5 (Sibling-field) : sample type voisin mais demande à l'utilisateur de saisir manuellement les items, ce qui contourne l'avantage de la classification ICG.
- ICG (Inventory Count Group) — sample type qui filtre par COUNTGROUP field.
- ICG vs BIN — ICG = group abstrait, BIN = bin physique précis.
- ICG vs CNTFREQ — ICG = dimension spatiale, CNTFREQ = dimension temporelle.
- Use case — walking-route counting par zone, criticité par groupe, etc.
- ICG = Inventory Count Group sample type.
- Filtre par COUNTGROUP field défini sur Inventory record.
- Distinct de BIN (bin physique) et CNTFREQ (cycle frequency).
- STU 7.2 — Sample type ICG verbatim
- STU 7.1 — Inventory Count Groups
- master-map.pdf p.787-832 Count Book Sample Types
Correct :A
Pourquoi cette question existe — Le STU 7.2 explicite "Reconcile · Unreconcile". L'Unreconcile est le mécanisme de correction post-fact, important pour les erreurs détectées après posting. IBM teste si vous savez que cette action existe.
Le contexte théorique d'abord — Toute opération comptable peut nécessiter correction post-fact : un clerc qui s'est trompé d'unit (12 par carton vs 12 par boîte), un comptage qui était wrong, une variance basée sur EXPECTED outdated. Sans mécanisme de reverse, soit on accepte des erreurs définitives (mauvais), soit on bidouille (encore pire). Maximo prévoit l'action Unreconcile pour réverser proprement, avec audit trail.
Ce que Maximo en fait — version opérationnelle — Sur Count Book → ouvrir le book réconcilié → action « Unreconcile ». Sélectionner les lignes à reverser. Maximo crée des INVTRANS rows réversantes (qty négative, type CYCLECOUNT-REVERSAL, REASON = correction d'erreur cléricale). INVBALANCES revient à l'état pré-réconciliation. L'ajustement GL est posté pour reverser l'impact GL précédent. L'audit log capture user/timestamp/reason. Le book peut ensuite être re-réconcilié avec les bonnes valeurs.
Exemple chiffré — Reconcile yesterday : 3 items, variance +20, +15, -5 unités, posted INVTRANS rows 1, 2, 3. Discovered : the +20 was actually +1 (UoM error entered as units instead of cartons of 12). Unreconcile row 1 → INVTRANS row 4 reversing (qty=-20). Then re-enter correct count (qty=1). Net adjust = +1 instead of +20. Audit trail : 2026-04-26 reconcile +20 by clerc, 2026-04-27 unreconcile +20 by supervisor (UoM error), 2026-04-27 reconcile +1 by clerc.
Analogie quotidienne — Vous validez un paiement bancaire de 1200 $ par erreur (au lieu de 120 $). La banque permet "annulation/reversal" du paiement, créant une écriture inverse, puis vous re-faites le bon paiement. Mêmes mécanismes ici.
Pourquoi B est faux — Supprimer un Count Book entier perdrait l'historique. Pattern D2 (Invented) : Maximo n'autorise pas delete sur les transaction documents postés. La trace est sacrée pour audit.
Pourquoi C est faux — SQL edit direct sur INVBALANCES casse complètement l'audit trail. Pattern D7 (Non-existent) : c'est interdit by design dans tout EAM mature, et serait détecté par DBA controls. Aucun BA ne devrait suggérer cela.
Pourquoi D est faux — Affirmer pas de reverse est faux. Pattern D7 (Non-existent) : Unreconcile est explicitement fournie par Maximo. Le piège fonctionne sur les candidats qui n'ont pas étudié cette action spécifique.
- Unreconcile — reverse prior reconcile, generates reversing INVTRANS rows.
- Audit-logged — user, timestamp, reason captured.
- Use cases — clerical errors, wrong UoM, EXPECTED was outdated.
- Pattern — Reconcile → discover error → Unreconcile → Re-reconcile correctly.
- Unreconcile = action standard Maximo pour reverse a posted reconcile.
- Crée INVTRANS reversing rows, audit-logged.
- JAMAIS delete document, JAMAIS SQL direct.
- STU 7.2 — Reconcile · Unreconcile
- master-map.pdf p.787-832 Count Book actions
- [EOTRAG] Query 14 — Audit immutable transaction model
Correct :C
Pourquoi cette question existe — Sample Type ALL est l'un des 7 explicitement listés dans le STU 7.2. C'est utilisé pour les inventaires totaux (annual physical, year-end audit). IBM teste votre maîtrise des 7 sample types et votre capacité à choisir ALL pour un audit complet.
Le contexte théorique d'abord — L'inventaire complet périodique (typiquement annuel) est exigé par les principes comptables et SOX/IFRS pour validation finale du balance sheet. Pendant cette opération, le storeroom est typiquement bloqué (pas d'issue, pas de receipt) pour éviter les mouvements pendant le count. Sample Type ALL génère un Count Book exhaustif : tous les items du storeroom (ou perimeter défini), peu importe ABC, count groups, due dates ou type. C'est l'inverse du cycle counting (qui est progressif et évite le blockage du storeroom).
Ce que Maximo en fait — version opérationnelle — Sur Inventory Counting RBA → Create Count Book → Sample Type = ALL → Storeroom = WH-MAIN. Maximo query INVENTORY where STOREROOM = 'WH-MAIN' (no other filter). Liste : tous les items, n=1000. Document Count Book généré. Plusieurs clerks assignés (parallel counting), supervisor coordinates. Toutes les lignes reconciled à fin du process. Inventory accuracy KPI calculated : lines_within_tolerance / 1000. Si 970/1000 in tolerance → 97% accuracy (world-class).
Exemple chiffré — Annual physical : Storeroom 1000 items. Sample Type ALL → 1000 lignes. 5 clerks pendant 1 jour, ~200 items/clerc. Reconciliation : 980 in-tolerance auto-post, 20 out-of-tolerance pour recount day 2. Final accuracy 980/1000 = 98%. Total INVTRANS rows ≈ 200 (where variance ≠ 0).
Analogie quotidienne — Année comptable dans une PME : à fin décembre, "tout le monde fait inventaire" — tout le stock physique est compté, pas seulement les items "due". C'est ALL.
Pourquoi A est faux — CNTFREQ filtre par due-date, manquant les items pas encore due. Pattern D4 (Partial-truth) : utile pour cycle counting routinier mais pas pour audit complet annuel.
Pourquoi B est faux — ROTATING ne couvre que les rotating items, manquant tous les non-rotating. Pattern D4 (Partial-truth) : pour un audit total, il faut TOUT, pas seulement rotating.
Pourquoi D est faux — ICG filtre par Count Group, ne couvrant pas les items hors group ou avec group différent. Pattern D4 (Partial-truth) : utile pour zone counting mais pas pour audit total.
- ALL — sample type pour annual physical / total audit.
- ROTATING — only rotating items.
- TOOLS — only tool-type items.
- CNTFREQ / ICG / BIN / ITEM — variations partielles.
- Cas d'usage ALL — annual physical inventory, year-end audit, post-incident full reconciliation.
- ALL = audit complet, pas de filtre.
- Pour annual physical / year-end / total audit.
- Storeroom typically blocked during ALL count.
- STU 7.2 — Sample Type ALL verbatim
- [EOTRAG] Query 5 — Periodic / annual count strategy
- master-map.pdf p.787-832 Count Books
Réconcilier les écarts de comptage

📋 Objectifs IBM
- Comprendre la Counting Role-Based Application (RBA) pour saisie et réconciliation de comptage simplifiées
- Utiliser le Reconciliation Mismatched tab pour identifier les items en écart
- Interpréter les flèches vertes/rouges sur le Reconciliation Mismatched tab (SAM Q5)
- Configurer le Counter Variance Threshold pour auto-réconcilier vs exiger approbation
- Générer l'INVTRANS d'ajustement avec la quantité de variance
💡 Points clés
- Counting RBA — l'Inventory Counting Role-Based Application de Maximo est une UI épurée et tactile-friendly pour les clerks de storeroom. Inclut barcode scanning, bin-by-bin walkthrough, mismatched tab pour réconciliation.
- Reconciliation Mismatched tab — dans la Counting RBA, liste TOUS les items où le last physical count diffère du current calculated balance. Affiche variance qty, direction et impact valeur.
- Flèche verte montante ↑ (réponse verbatim SAM Q5) — indique que le last physical count est PLUS ÉLEVÉ que le current balance. Traduction : le clerk a trouvé PLUS d'items que ce que le système attendait (variance positive, surplus).
- Flèche rouge descendante ↓ — indique que le last physical count est INFÉRIEUR au current balance. Traduction : le clerk a trouvé MOINS d'items (variance négative, déficit). Souvent causé par vol, dommage, mis-pick ou issue non enregistrée.
- Convention de polarité directionnelle — Up = surplus (bonne nouvelle pour l'asset side, mais soulève des questions sur la cause) ; Down = déficit (mauvaise nouvelle, souvent investigué pour fraude/erreur).
- Counter Variance Threshold — pourcentage configurable qui détermine quand une variance s'auto-réconcilie vs exige approbation manuelle. Items dans le threshold postent automatiquement ; au-delà déclenchent un workflow d'approbation.
- Comptabilité de variance — variance positive (flèche Up) = credit Inventory, debit Inventory Adjustment Gain. Variance négative (flèche Down) = debit Inventory Variance Loss, credit Inventory.
- INVTRANS d'ajustement — type CYCLECOUNT, qty = variance (positive ou négative). Auto-générée au posting de la réconciliation.
- Investigation root-cause — variance chronique sur le même SKU = problème de processus, pas aléatoire. Best practices : investiguer les erreurs de receiving, kitting sans backflush, inexactitudes de BOM, stock caché « squirrel store » [EOTRAG Query 10].
- Calculated value — ce que le système pense devoir être on hand basé sur receipts/issues. Pas nécessairement 0 même après issue — peut inclure POs ouverts, transferts in-transit, etc.
- Hard reserved quantity — items réservés pour des WOs actifs (ne peuvent pas être issued ailleurs). Distinct du current balance et du physical count.
- KPI Inventory accuracy — dérivé de la réconciliation : lines_within_tolerance / lines_counted × 100%. Cibles industrie : 95% acceptable, 97% world-class, 99% obligatoire pour items de sécurité [EOTRAG Query 5].
⚠️ Piège IBM
SAM Q5 : polarité de la flèche verte montante — Up = « le last physical count a plus d'items que le current balance ». Le piège est d'inverser la comparaison ou de confondre current balance avec hard reserved ou calculated value.
- Piège : penser que Up = current balance plus élevé que count (polarité inverse).
- Piège : confondre « current balance » avec « hard reserved quantity ».
- Piège : penser que Up = items commandés depuis le last count (ça c'est l'angle calculated value).
- Piège : supposer que les flèches sur Reconciliation Mismatched sont décoratives ; ce sont des indicateurs fonctionnels.
🎯 Carte mémoire
Q. Que signifie une flèche verte montante sur une ligne d'item dans le Reconciliation Mismatched tab ?
Afficher la réponse
Le last physical count a PLUS d'items que le current balance — le clerk a trouvé des unités supplémentaires (variance positive, surplus). La réconciliation va incrémenter INVBALANCES et créditer Inventory Adjustment Gain. Causes : receipt précédemment non enregistré, issues mal comptées, items retournés mais non saisis, items trouvés dans des bins non mappés.
Questions d’examen de style IBM. Cliquez une option, puis « Vérifier ma réponse ». Progression enregistrée localement.
Correct :B
Pourquoi cette question existe — C'est le SAM Q5 verbatim. IBM teste votre maîtrise précise de la polarité des indicateurs visuels dans le Counting RBA. C'est un piège visuel-sémantique qui sépare ceux qui ont étudié la doc IBM de ceux qui devinent.
Le contexte théorique d'abord — Dans toute interface de reconciliation, les indicateurs directionnels (flèches up/down, couleurs) doivent suivre une convention claire et consistante. La convention industrielle est : up = positive variance = surplus = "found more" ; down = negative variance = deficit = "found less". Le mot "current balance" désigne ce que le système pense actuel, calculé à partir des derniers receipts/issues postés. Le "last physical count" est le nombre que le clerk a saisi lors du dernier comptage. Le delta = count - balance. Si delta > 0 (count surplus), arrow up (vert = bon news pour l'asset side, mais demande investigation pour la cause).
Ce que Maximo en fait — version opérationnelle — Le Counting RBA → Reconciliation Mismatched tab affiche une liste d'items où count ≠ balance. Pour chaque ligne : ITEM, LAST PHYSICAL COUNT, CURRENT BALANCE, VARIANCE qty, ARROW (up green ou down red), VARIANCE % vs threshold. Le manager peut filter, drill into chaque ligne pour voir l'historique transactions, et décider : auto-reconcile (within threshold) ou recount (above threshold).
Exemple chiffré — Item X : LAST PHYSICAL = 105, CURRENT BALANCE = 100. Variance = +5 (surplus). Arrow = green up. Reason analysis : possible unrecorded receipt, found in corner bin, return non-saisi. Item Y : LAST PHYSICAL = 95, CURRENT BALANCE = 100. Variance = -5 (deficit). Arrow = red down. Reason : possible theft, damage, unrecorded issue. Reconciliation : Item X auto-post si dans threshold, INVTRANS row +5, INVBALANCES = 105. Item Y : si dans threshold, INVTRANS row -5, INVBALANCES = 95.
Analogie quotidienne — Vous comptez les billets dans votre portefeuille (last physical count). Vous regardez votre app de tracking de dépenses (current balance). Si physical > app : vous avez plus de cash que prévu (surplus, up arrow vert) — peut-être un remboursement oublié. Si physical < app : vous avez moins (deficit, down arrow rouge) — peut-être une dépense non saisie. La même logique de polarité.
Pourquoi A est faux — Comparer count à hard reserved quantity n'est pas la sémantique de l'arrow. Hard reserved = items réservés pour WOs actifs, distinct du current balance. Pattern D5 (Sibling-field) : c'est un autre champ de la même app mais pas celui qui drive l'arrow. Le piège fonctionne sur les candidats qui voient "reserved" et présument que c'est la référence.
Pourquoi C est faux — Inverser la polarité (current balance > physical count) ferait la flèche descendante, pas montante. Pattern D3 (Inverse) : le piège classique d'inverser un > en <. À mémoriser absolument : up = on en a trouvé plus, current balance est le côté inférieur.
Pourquoi D est faux — "Calculated value with items ordered since count" évoque le concept de pipeline (open POs, in-transit) qui est encore une autre dimension. Pattern D5 (Sibling-field) : ces concepts existent dans Maximo (calculated value = balance + on order - hard reserved, par exemple) mais ne sont pas le driver de l'arrow on Mismatched tab. L'arrow utilise count vs balance, pas count vs calculated.
- Polarity convention — up = surplus (count > balance) ; down = deficit (count < balance).
- Color — vert (up, surplus) ; rouge (down, deficit).
- Comparison — last physical count vs current balance, pas hard reserved ni calculated.
- Action — within threshold = auto-post ; outside = approval/recount.
- SAM Q5 : Green up arrow = last physical count > current balance.
- Up = surplus / found more. Down = deficit / found less.
- Comparison : count vs balance (PAS hard reserved, PAS calculated).
- SAM Q5 — verbatim
- STU 7.3 — Counting RBA Reconciliation Mismatched tab
- [EOTRAG] Query 10 — Variance accounting positive/negative
Correct :C
Pourquoi cette question existe — Le STU 7.3 implique la connaissance de l'impact comptable des reconciliations. IBM teste si vous comprenez que les variances génèrent des écritures GL spécifiques (gain/loss accounts), pas juste des updates qty.
Le contexte théorique d'abord — Le RAG cite verbatim : « variance positive (plus on hand que book) frappe credit Inventory / debit Inventory Adjustment Gain ; variance négative frappe debit Inventory Variance Loss / credit Inventory » [EOTRAG Query 5]. Cette dualité reflète le principe d'écriture comptable : tout changement d'asset (compte Inventory) doit avoir une contrepartie dans un autre compte. Pour les surplus, la contrepartie est un compte de « Gain » (revenus exceptionnels) ; pour les déficits, un compte de « Loss » (charges exceptionnelles). Ces comptes sont des sous-catégories du compte de résultat, distincts des achats normaux ou des coûts d'opération.
Ce que Maximo en fait — version opérationnelle — Au reconcile, Maximo crée :
- INVTRANS row : ITEM=X, qty=+10, type=CYCLECOUNT, REASON=variance positive
- INVBALANCES update : qty was 100, now 110
- GL voucher : DEBIT Inventory Asset (1500-INV) $500, CREDIT Inventory Adjustment Gain (4900-INVGAIN) $500
Exemple chiffré — Variance +10 × $50 = +$500 valeur. GL : Inventory Asset balance += $500 ; Inventory Adjustment Gain += $500. Effet net : asset balance plus élevée, P&L gain ponctuel.
Analogie quotidienne — Vous trouvez 100 $ oubliés dans un manteau. Comptablement (vie personnelle) : votre actif "cash" augmente de 100 $, et votre compte "windfall" (revenu exceptionnel) augmente de 100 $. Ce n'est pas un revenu d'activité régulière, mais c'est un gain.
Pourquoi A est faux — Inverser : c'est le pattern pour les négatifs (down arrow). Pattern D3 (Inverse) : critical de bien associer up = gain, down = loss. Pour up arrow, le compte impacté est Adjustment Gain, pas Variance Loss.
Pourquoi B est faux — Affirmer pas de GL impact est faux. Pattern D7 (Non-existent) : Maximo intégré GL update systématique. Sinon les états financiers seraient désalignés avec l'inventaire réel.
Pourquoi D est faux — Cash n'est pas impacté par une variance d'inventaire physique. Pattern D6 (Wrong-app) : le piège fonctionne sur les candidats qui pensent que toute variance touche le cash, alors que cash n'est touché qu'au receipt/payment, pas au count.
- Positive variance (Up arrow) — Debit Inventory, Credit Adjustment Gain.
- Negative variance (Down arrow) — Debit Variance Loss, Credit Inventory.
- Symétrie — Chaque ajustement génère une écriture GL équilibrée (debit = credit).
- Impact P&L — Adjustment Gain ou Loss en « autres gains/pertes opérationnels ».
- Up arrow + post = Debit Inventory + Credit Adjustment Gain.
- Down arrow + post = Debit Variance Loss + Credit Inventory.
- Toujours un GL impact, jamais "qty only".
- STU 7.3 — Reconciliation Mismatched tab GL impact
- [EOTRAG] Query 5 — Variance accounting verbatim
- [EOTRAG] Query 10 — Inventory Adjustment Gain / Loss
Correct :A
Pourquoi cette question existe — Le Counter Variance Threshold est le mécanisme central de gouvernance des reconciliations. IBM teste si vous comprenez son rôle de gate entre auto-post et manual approval. C'est exactement la SOX-style separation of duties appliquée à l'inventory.
Le contexte théorique d'abord — Le threshold tolerance ABC class est paramétré pour réduire le coût administratif (auto-post les ajustements mineurs) sans perdre le contrôle (escalate les ajustements significatifs). 5% threshold = "les variances jusqu'à 5% sont considérées comme normales, posting OK ; au-delà = anomalie potentielle, supervisor doit valider". Cette gating empêche les fraudes simples (clerc qui ajusterait régulièrement +5 unités à un item pour vol caché) en forçant une review pour tout ce qui est significatif.
Ce que Maximo en fait — version opérationnelle — Au reconcile, Maximo calcule variance % = |variance| / EXPECTED × 100. Compare à threshold (5%). Si variance% < threshold : auto-post (INVTRANS + GL). Si >= threshold : status = PENDING APPROVAL (ou PENDING RECOUNT). Le supervisor reçoit task notification, ouvre la ligne, peut : (a) approve (post manuelle), (b) request recount, (c) reject (pas de post, count à refaire). Audit trail complet de qui a fait quoi quand.
Exemple chiffré — EXPECTED = 100, COUNTED = 110. Variance = 10. Variance % = 10/100 × 100 = 10%. Threshold = 5%. 10% >= 5%, flaggé pour approbation. Status = PENDING APPROVAL. Le supervisor investigue, découvre que 10 unités ont été retournées d'un WO hier mais la transaction Return-to-Store n'a pas été postée — c'est une explication légitime. Supervisor approuve, le post se fait, INVBALANCES = 110.
Analogie quotidienne — Banking : tout dépôt < 1000 $ se fait sans paperwork ; au-delà, formulaire de provenance demandé. Le threshold = même logique de gate.
Pourquoi B est faux — Threshold ignoré sur positifs serait une faille majeure (les vols/erreurs de receiving cachés derrière surplus apparent passeraient inaperçus). Pattern D7 (Non-existent) : Maximo applique threshold uniformément sur les deux directions.
Pourquoi C est faux — Rejet automatique sans option de approve serait trop rigide. Pattern D2 (Invented) : Maximo permet supervisor approval avec contexte. Pas tous les out-of-tolerance sont des erreurs ; certains ont des explications légitimes.
Pourquoi D est faux — Capper la variance à threshold serait une falsification. Pattern D2 (Invented) : aucun système ne fait cela. Si le clerc count 110 et le système écrit 105, le physical et le book divergent à nouveau immédiatement.
- Counter Variance Threshold — gate entre auto-post et approval-required.
- Within threshold — auto-post, INVTRANS + GL automatique.
- Outside threshold — PENDING APPROVAL, supervisor décide.
- Configurable — au niveau Org, Storeroom, ou Item (selon level de granularité voulu).
- Variance % < threshold → auto-post.
- Variance % >= threshold → supervisor approval required.
- SOX-style gate, audit-logged.
- STU 7.3 — Counter Variance Threshold
- [EOTRAG] Query 10 — Tolerance per ABC class + recount workflow
- master-map.pdf p.787-832 Threshold configuration
Correct :D
Pourquoi cette question existe — Le RAG est explicit : "chronic variance on the same SKU = process problem, not random. Investigate, don't just adjust" [EOTRAG Query 10]. C'est l'un des best practices fondamentaux du cycle counting. IBM teste si vous comprenez la dimension management du counting, pas seulement la mécanique.
Le contexte théorique d'abord — La théorie statistique distingue erreurs aléatoires (noise, distributed normalement, threshold-friendly) des erreurs systématiques (bias, distribution skewed, signal de problème upstream). Quand un même SKU montre toujours le même biais (toujours négatif, toujours -3% à -5%), c'est un signal d'erreur systématique. Reconciler aveuglément cache le problème en l'absorbant dans Variance Loss month après month, mais ne le résout pas. Le RAG identifie 4 root causes typiques : receiving errors (qty saisie wrong), kitting without backflush (kit issued sans décrément des composants), BOM inaccuracies (sub-assembly mal definition), squirrel store (hidden cache au shop floor).
Ce que Maximo en fait — version opérationnelle — Maximo lui-même ne détecte pas auto-magiquement les chronic variances (sauf via reports custom ou Maximo Inventory Insights ML). Mais le Counting RBA expose l'historique : drill-down sur l'item montre la timeline des variances. Le manager peut filter "items with variance > 3 of last 6 counts" et investiguer. Pour chaque chronic, audit transaction (MATUSETRANS + MATRECTRANS) pour voir le pattern : si toujours -3% au même moment du mois, c'est probablement un kit issue récurrent qui ne backflush pas correctement.
Exemple chiffré — Item Y : 6 last counts → variances -2.8%, -3.5%, -3.2%, -3.0%, -3.4%, -3.1%. Pattern systematic. Investigation : un kit "Quarterly Maintenance Kit" est issued chaque mois mais le BOM kit est mal config — il liste 3 unités du sub-component Y mais physiquement on consume 4. Chaque issue cache 1 unit qui n'est pas decrémenté → -1 unit/issue × 3-5 issues/mois = -3-5%. Fix : update BOM. Variance disparait next quarter.
Analogie quotidienne — Votre balance pèse 2 kg de pommes mais le ticket de caisse en charge 2.2 kg systematiquement. Si 1 fois = peut-être erreur. Si toujours, c'est la balance qui est mal calibrée — root cause à fixer, pas accepter la différence à chaque visite.
Pourquoi A est faux — Considérer chronic comme random est précisément le piège. Pattern D2 (Invented) : il n'y a pas de noise random qui produit un biais consistant. Le candidat qui choisit ça néglige le management view du counting.
Pourquoi B est faux — System clock n'a aucun lien avec inventory variance. Pattern D7 (Non-existent) : c'est une fausse piste sans rapport avec inventory mechanics.
Pourquoi C est faux — Threshold trop élevé ferait passer des variances inappropriées en auto-post, mais ne crée pas la variance elle-même. Pattern D4 (Partial-truth) : threshold gate impacte ce qui est posted vs flagged, pas pourquoi les variances existent. Le candidat confond cause et seuil.
- Random vs Systematic variance — random = noise (auto-post OK) ; systematic = bias (investigate).
- 4 root causes typiques — receiving errors, kit issue without backflush, BOM inaccuracies, squirrel store.
- Best practice — investigate chronic, fix root cause, don't just adjust.
- Detection — pattern visible in count history (drill-down by item).
- Chronic variance = process problem, NOT random.
- Investigate root cause (receiving, kit, BOM, squirrel store).
- Fix upstream, don't keep absorbing in Variance Loss account.
- STU 7.3 — Reconcile Count Variances
- [EOTRAG] Query 10 — Lessons learned: chronic variance = process problem
- [EOTRAG] Query 1 — Squirrel-store trap
Correct :B
Pourquoi cette question existe — IBM teste votre maîtrise du data model Maximo des transactions. INVTRANS est la table dédiée aux ajustements (cycle count, manual adjustments, write-offs). Les autres tables (MATRECTRANS = receipts, MATUSETRANS = issues/transfers) sont distinctes.
Le contexte théorique d'abord — Le RAG cite verbatim : "INVTRANS: stores inventory adjustment transactions (cycle count adjustments, manual adjustments, write-offs, condition changes). Captures: ITEMNUM, OLDQTY, NEWQTY, ADJUSTMENT, REASONCODE." [EOTRAG Query 14]. La séparation MATRECTRANS / MATUSETRANS / INVTRANS reflète le data model relationnel : chaque catégorie de transaction a sa propre table avec ses fields spécifiques. Mélanger les types violerait la normalisation et casserait les rapports analytiques (qui filtrent par type).
Ce que Maximo en fait — version opérationnelle — Au reconcile post, Maximo INSERT dans INVTRANS : ITEMNUM, STOREROOM, OLDQTY=100, NEWQTY=93, ADJUSTMENT=-7, TYPE=CYCLECOUNT, REASONCODE=USER_ENTERED, COUNTER_USER, TRANSDATE. Trigger : INVBALANCES.QTY=93. Trigger : GL voucher (debit Variance Loss, credit Inventory). Maximo ne touche pas à MATRECTRANS ni MATUSETRANS — ce serait incorrect car il n'y a pas eu de receipt/issue physique.
Exemple chiffré — INVTRANS row inserted : ITEMNUM=X, STOREROOM=WH-MAIN, OLDQTY=100, NEWQTY=93, ADJUSTMENT=-7, UNITCOST=$50, TYPE=CYCLECOUNT, REASONCODE=COUNT-VARIANCE, TRANSDATE=2026-04-27, ENTERBY=JDUPONT, VOID=N. Cost impact = -7 × $50 = -$350 (reduction asset value).
Analogie quotidienne — Dans votre app banking, les ajustements (frais bancaires, intérêts, corrections) sont dans une catégorie "Adjustments" distincte des "Deposits" et "Withdrawals". Même structure conceptuelle.
Pourquoi A est faux — Type=ISSUE serait incorrect car ce n'est pas une vraie issue (pas de WO réel). Pattern D2 (Invented) : créer un WO synthetic est un workaround dirty pas standard.
Pourquoi C est faux — INVBALANCES seulement sans INVTRANS perdrait l'audit trail. Pattern D7 (Non-existent) : Maximo respecte audit immutable, JAMAIS update direct sur INVBALANCES sans transaction trace.
Pourquoi D est faux — MATRECTRANS est pour les receipts vendor, pas pour les ajustements de count. Pattern D6 (Wrong-app) : confondre les rôles des 3 tables transactionnelles est un piège classique.
- 3 transaction tables — MATRECTRANS (receipts), MATUSETRANS (issues/transfers/returns), INVTRANS (adjustments).
- INVTRANS use cases — cycle count adjustments, manual adjustments, write-offs, condition changes.
- Type CYCLECOUNT — le type pour reconciliation count variances.
- Fields clés — OLDQTY, NEWQTY, ADJUSTMENT, REASONCODE.
- Reconciliation = INVTRANS row, type=CYCLECOUNT.
- Pas MATRECTRANS (receipts), pas MATUSETRANS (issues).
- Audit trail toujours, JAMAIS direct INVBALANCES update.
- STU 7.3 — adjustment INVTRANS verbatim
- [EOTRAG] Query 14 — INVTRANS table fields
- [EOTRAG] Query 5 — Reconciliation generates INVTRANS row of type CYCLECOUNT
Correct :C
Pourquoi cette question existe — Inventory Accuracy KPI est le métrique de performance le plus reconnu dans le warehouse management. IBM teste votre connaissance de la formule et des benchmarks industriels. Le RAG mentionne explicitement les targets : 95% acceptable, 97% world-class, 99% safety [EOTRAG Query 5].
Le contexte théorique d'abord — Inventory Accuracy = mesure de fiabilité du système d'inventaire. Le RAG cite verbatim : "Inventory accuracy formula: accuracy = lines_within_tolerance / lines_counted × 100%. Common targets: 95% acceptable, 97% world-class, 99% mandatory for safety/regulated items" [EOTRAG Query 10]. C'est pas la précision absolue (qty exacte) mais la précision tolerée (qty within tolerance). C'est une distinction critique : un storeroom à 99.5% qty exact est rare ; à 97% within ±5% est réaliste world-class.
Ce que Maximo en fait — version opérationnelle — Maximo génère des reports de Inventory Accuracy automatiquement après chaque count session. Le rapport montre lines_counted, lines_within_tolerance, lines_out_of_tolerance, accuracy %. Le manager track la trend over quarters/years. Cible operationelle : maintenir >= 95%, target world-class à 97%, tolérance 0% pour items réglementés (safety, hazmat). Si accuracy chute < 95%, signal d'alerte → root cause analysis (training, process, technologies barcoding).
Exemple chiffré — 1000 items counted. 970 in tolerance. Accuracy = 970/1000 × 100 = 97%. World-class ! 30 items out of tolerance vont en recount workflow. Si 99% target safety items et le storeroom fait des PPE, 99% est mandatory — 97% global, mais split par category : 99.5% sur PPE specifically (50 items, 49 in tol = 98% — sous target, action required spécifiquement sur PPE).
Analogie quotidienne — Une cuisine de restaurant : 100 commandes, 97 servies dans les 15 minutes (within tolerance), 3 retardées. Service accuracy = 97%. Les 3 retardées vont en analysis : pourquoi ? Comment fix ?
Pourquoi A est faux — 3% est le taux d'échec (out-of-tolerance), pas le KPI accuracy. Pattern D3 (Inverse) : confond positive et négative. Le KPI mainstream est positif (accuracy = success rate).
Pourquoi B est faux — 100% counted ≠ 100% accurate. Pattern D9 (Near-synonym) : le candidat confond completeness (tous countés) avec accuracy (countés correctement).
Pourquoi D est faux — La formule "out / 10" est inventée. Pattern D2 (Invented) : aucun standard. La formule est lines_within_tolerance / lines_counted × 100.
- Formule — Accuracy = lines_within_tolerance / lines_counted × 100%.
- Targets industriels — 95% acceptable, 97% world-class, 99% safety/regulated.
- Tolerance — define within tolerance per ABC class (lesson 7.2).
- Trend tracking — KPI rapporté trimestriellement, action sur déclin.
- Inventory Accuracy = within-tolerance / total counted × 100.
- 97% = world-class.
- 970/1000 = 97% — target met.
- STU 7.3 — Reconcile Count Variances
- [EOTRAG] Query 5 — Inventory accuracy KPI: 97% world-class
- [EOTRAG] Query 10 — Accuracy formula verbatim